AI speelt een grote rol in de toekomst van softwareontwikkeling. We hebben enkele belangrijke aspecten ervan besproken in dit artikel.
Het ontwikkelen van AI-programma’s kan een zeer gecompliceerde taak zijn. U zult uw due diligence moeten doen om er zeker van te zijn dat u alle technische nuances begrijpt die bij het proces betrokken zijn.
We hebben er al over gesproken enkele van de programmeertalen die kunnen worden gebruikt om big data- en AI-programma's te maken. Python is de beste taal op de lijst. Er zijn echter veel dingen die u moet weten als u een nieuwe taal leert. Een van de dingen waar u zich van bewust moet zijn, is het belang van het gebruik van NLP.
NLP's vormen de basis voor de ontwikkeling van AI-programma's
Natural Language Processing (NLP) loopt voorop op het snijvlak van informatica en taalkunde en speelt een centrale rol in verschillende toepassingen. Een van de belangrijkste componenten is entiteitsextractie een cruciale techniek voor het verzamelen van waardevolle informatie uit ongestructureerde gegevens.
Dit artikel is bedoeld om een diepgaande verkenning te geven van entiteitsextractie in NLP, en biedt technische inzichten en praktische tips voor het beheersen van deze essentiële vaardigheid.
1- De basisprincipes van NLP begrijpen
Voordat we ons verdiepen in de extractie van entiteiten, is het van cruciaal belang om de grondbeginselen van NLP te begrijpen. Duik in de fundamentele concepten, principes en algemene technieken die ten grondslag liggen aan de natuurlijke taalverwerking.
Bekendheid met tokenisatie, part-of-speech-tagging en syntactische parsering legt de basis voor een uitgebreid begrip van de complexiteiten die betrokken zijn bij het extraheren van entiteiten.
Overweeg bijvoorbeeld de Python NLTK-bibliotheek voor de basisprincipes van NLP. Hieronder vindt u een eenvoudig codefragment dat tokenisatie illustreert:
import nltk
from nltk.tokenize import word_tokenize
text = "Entity extraction is a crucial aspect of NLP." tokens = word_tokenize(text)
print(tokens)
Deze code maakt gebruik van NLTK om de gegeven tekst te tokeniseren en op te splitsen in afzonderlijke woorden voor verdere analyse.
2- Het definiëren van entiteitsextractie
Duik in het kernconcept van entiteitsextractie om de betekenis ervan in NLP te begrijpen.
Entiteiten verwijzen naar specifieke stukjes informatie in tekst en strekken zich verder uit dan naar verschillende soorten gegevens, waaronder databases, spreadsheets, afbeeldingen en video's. In dit alomvattende begrip kunnen entiteiten de vorm aannemen van objecten, onderwerpen of elementen die afzonderlijke en identificeerbare informatie bevatten.
Het herkennen en classificeren van deze entiteiten is van fundamenteel belang voor het extraheren van betekenisvolle inzichten uit ongestructureerde gegevens.
Beschouw het volgende voorbeeld met behulp van a hulpmiddel voor tekstannotatie:
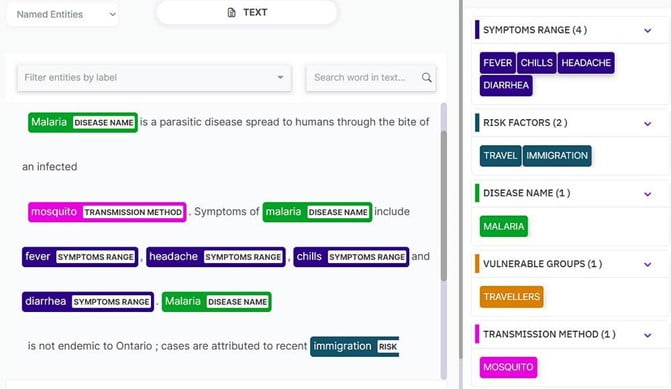
In dit voorbeeld laten we een voorbeeld zien van entiteitsextractie met behulp van KUDRA (NLP-verwerkingstoepassing).
Het gebruik van dergelijke NLP-verwerkingstoepassingen is cruciaal bij het definiëren van entiteitsextractie. Deze tools maken gebruik van geavanceerde algoritmen, machine learning-modellen en op regels gebaseerde systemen om entiteiten in tekst te identificeren en te categoriseren.
NLP-verwerkingstoepassingen spelen een cruciale rol bij het definiëren van entiteitsextractie door:
- Geautomatiseerde herkenning: Deze toepassingen automatiseren de identificatie van entiteiten, waardoor gebruikers geen handmatige extractie hoeven uit te voeren en het proces wordt versneld.
- Multimodale extractie: Entiteiten zijn niet beperkt tot tekst; NLP-toepassingen kunnen informatie uit verschillende gegevenstypen extraheren, waardoor een alomvattend begrip wordt bevorderd.
- Verbeterde nauwkeurigheid: Door gebruik te maken van geavanceerde algoritmen verbeteren deze toepassingen de nauwkeurigheid bij het herkennen en classificeren van entiteiten, waardoor fouten die gepaard gaan met handmatige extractie worden verminderd.
- Aanpassingsvermogen: NLP-toepassingen kunnen zich aanpassen aan evoluerende taalpatronen en diverse gegevensbronnen, waardoor flexibiliteit wordt gegarandeerd bij het definiëren en extraheren van entiteiten.
→ Het integreren van NLP-verwerkingstoepassingen is essentieel voor een robuuste definitie en implementatie van entiteitsextractie, wat efficiëntie, nauwkeurigheid en aanpassingsvermogen biedt bij het omgaan met ongestructureerde gegevens.
3- NLP-technieken voor entiteitsextractie
Ontdek een reeks NLP-technieken die van toepassing zijn op de extractie van entiteiten, waaronder op regels gebaseerde systemen, machine learning-modellen en deep learning-benaderingen. Elke methode heeft zijn sterke en zwakke punten, waardoor het essentieel is om een aanpak te kiezen die is afgestemd op specifieke gebruiksscenario's en gegevenskenmerken.
Overweeg de implementatie van een op regels gebaseerd systeem met behulp van spaCy:
SpaCy onderscheidt zich als een krachtige bibliotheek die efficiëntie en eenvoud combineert. Bij het overwegen van entiteitsextractie biedt spaCy een op regels gebaseerde aanpak die nauwkeurige controle over patronen en taalregels mogelijk maakt.
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Alex Smith was working at Acme Corp Inc." doc = nlp(text)
for ent in doc.ents:
print(f"{ent.text} - {ent.label_}")
4- Het overwinnen van uitdagingen bij het extraheren van entiteiten:
Entiteitsextractie wordt geconfronteerd met uitdagingen zoals ambiguïteit, contextafhankelijkheid en het omgaan met diverse gegevensbronnen. Om deze problemen aan te pakken, is het van cruciaal belang om geavanceerde strategieën te gebruiken, en de integratie van taalmodellen (LLM) biedt een effectieve oplossing.
Overweeg een scenario waarin de entiteit ‘Apple’ zou kunnen verwijzen naar het technologiebedrijf of het fruit. Door LLM's, zoals GPT-3, op te nemen in het entiteitsextractieproces, kunnen we een meer genuanceerde analyse uitvoeren. Deze modellen
kan de context begrijpen, waardoor de bedoelde betekenis kan worden onderscheiden op basis van de algehele tekst.
5- Op de hoogte blijven van NLP-vooruitgang:
NLP is een snel evoluerend veld, getuige van voortdurende vooruitgang en doorbraken. Blijf op de hoogte van de nieuwste onderzoeksartikelen, modellen en technieken op het gebied van entiteitsextractie.
Controleer platforms zoals arXiv en GitHub regelmatig op de allernieuwste ontwikkelingen, zodat u ervoor kunt zorgen dat uw methoden voor het extraheren van entiteiten voorop blijven lopen op het gebied van NLP-innovatie.
6- Voorbeeld uit de echte wereld
Voorbeeld: Domein Gezondheidszorg
In de gezondheidszorg speelt entiteitsextractie een cruciale rol bij het extraheren van waardevolle informatie uit medische dossiers. Overweeg een scenario waarin een ziekenhuis een grote dataset met patiëntendossiers analyseert om potentiële uitbraken of trends in ziekten te identificeren.
Entiteitsextractie kan helpen bij het herkennen van entiteiten zoals patiëntnamen, medische aandoeningen en medicijnen. Deze informatie kan vervolgens worden gebruikt om de patiëntenzorg te verbeteren, patronen in de verspreiding van ziekten te identificeren en het algehele gezondheidszorgbeheer te verbeteren.
Conclusie
Het beheersen van entiteitsextractie binnen Natural Language Processing (NLP) vereist een solide basis, technische expertise en de toewijding om op de hoogte te blijven van ontwikkelingen. Door deze vijf belangrijke tips op te nemen, kunt u uw vaardigheid in het extraheren van entiteiten vergroten en bijdragen aan het dynamische landschap van natuurlijke taalverwerking. Of het nu gaat om op regels gebaseerde systemen, machine learning-modellen of deep learning-benaderingen, de doordachte en geïnformeerde aanpak, samen met technische expertise, stelt u in staat betekenisvolle inzichten te verkrijgen uit de enorme hoeveelheid ongestructureerde gegevens.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.smartdatacollective.com/tips-master-entity-extraction-in-nlp-for-ai-programming/

