
Ik ga het script voor dit bericht omdraaien, wat ik zelden doe. Ik begin met waar ik denk dat het nuttige inhoudssysteem vanaf hier naartoe kan gaan en geef daarna het waarom (voor degenen die wat achtergrondinformatie over de bestraffende algoritme-updates van Google beter willen begrijpen).
Daar gaan we. Ik denk dat het nuttige inhoudssysteem van Google vanaf hier een aantal verschillende kanten op kan gaan:
- Google zou eenvoudigweg de ernst van de HCU-classificatie kunnen verminderen. Het zou nog steeds voor de hele site gelden, maar sites zouden niet zo vaak naar beneden worden gesleept. Het zou zeker je aandacht trekken, en misschien net erg genoeg als je nog steeds grote veranderingen wilt implementeren vanuit een inhoudelijk en UX-oogpunt.
- Ten tweede zou het behulpzame inhoudssysteem misschien gedetailleerder kunnen worden (zoals Penguin in het verleden deed). De classificatie kan zwaarder worden toegepast op pagina's die als nutteloos worden beschouwd, in plaats van op een degradatie voor de hele site. Dit zou site-eigenaren natuurlijk een serieuze aanwijzing geven over welke delen van de inhoud als “niet nuttig” worden beschouwd, maar zou spammers ook een aanwijzing geven over waar de drempel ligt (wat een reden zou kunnen zijn dat Google deze weg niet zou inslaan).
- Ten derde zou het nuttige inhoudssysteem kunnen blijven zoals het is wat betreft de ernst ervan, en ook een signaal voor de hele site kunnen zijn, maar zou het beter in staat zijn zich te richten op grootschalige sites met veel nutteloze inhoud. We weten dat dit een probleem is bij een aantal krachtige, grootschalige sites, maar ze zijn niet echt beïnvloed door de verschillende HCU's, aangezien het merendeel van hun inhoud NIET als 'niet nuttig' zou worden geclassificeerd. De enorme dalingen waarvan veel kleinere nichesites getuige waren, zouden dus door grotere en meer gevestigde sites kunnen worden gezien als Google deze weg inslaat.
- Ten vierde verandert Google misschien de kracht van het UX-gedeelte van de HCU. Misschien is de HCU in de toekomst bijvoorbeeld niet zo gevoelig voor agressieve en ontwrichtende reclame. Of aan de andere kant: misschien verhoogt Google die ernst en wordt het zelfs nog agressiever. Ik heb in mijn bericht over de September HCU(X) hoe Google pagina-ervaring opnam in de nuttige inhoudsdocumentatie in april 2023 (een voorafschaduwing van wat we zagen met de HCU van september). En veel sites werden geteisterd met een combinatie van van nutteloze inhoud EN een vreselijke UX (vaak van agressieve advertenties). Dus in de toekomst zou Google altijd de kracht van de UX-component kunnen veranderen, wat een groot effect zou kunnen hebben op sites met nutteloze inhoud...
- En ten slotte zou Google het nuttige inhoudssysteem gewoon kunnen laten draaien zoals het nu is. Ik denk niet dat dit het geval zal zijn, op basis van al het kritiek dat Google te horen krijgt over de HCU(X) van september, maar het is heel goed mogelijk. Maar als Google, op basis van de enorme hoeveelheid gegevens die Google in de loop van de tijd evalueert, van mening is dat de zoekkwaliteit beter is als het behulpzame inhoudssysteem draait zoals het is, dan verandert er niets. Ik geloof echt dat we veranderingen zullen zien bij de volgende HCU, maar dit scenario is heel goed mogelijk.
Als je nu wilt weten waarom ik denk dat dit mogelijke scenario's zijn voor het nuttige inhoudssysteem in de toekomst, zou je de rest van mijn bericht moeten lezen. Ik bespreek de evolutie van de bestraffende algoritme-updates van Google, die site-eigenaren die getroffen zijn door de verschillende HCU's, kunnen helpen beter te begrijpen waarom ze werden getroffen, hoe de vorige systemen in de loop van de tijd zijn geëvolueerd en wat ze in de toekomst kunnen verwachten.
De HCU(X) van september, hooivorken, fakkels en schreeuwende bloedmoord:
Er zijn veel mensen die daar zwaar over klagen Nuttige inhoudsupdate van september van Google, hoe zwaar hun sites zijn getroffen, dat geen enkele site zich heeft hersteld van de HCU(X) van september, en meer. Ik begrijp hun frustratie volledig, maar ik denk ook dat veel site-eigenaren meer moeten begrijpen over de evolutie van eerdere Google-updates voor bestraffende algoritmen.
Ter verduidelijking: er zijn algoritme-updates die ernaar kijken promoten sites en inhoud, en vervolgens algoritme-updates die ernaar kijken degraderen sites en inhoud. Het eindresultaat van beide typen systemen zou er hetzelfde uit kunnen zien (grote dalingen), maar er is een verschil tussen de twee. En op basis van de manier waarop eerdere updates van bestraffende algoritmen in de loop van de tijd zijn geëvolueerd, hebben we misschien enkele aanwijzingen over hoe het nuttige inhoudssysteem van Google zich ook zou kunnen ontwikkelen.
Het nuttige inhoudssysteem van Google:
Voordat Google de eerste nuttige inhoudsupdate, kon ik Danny Sullivan van Google bellen om het systeem, de classificator en meer te bespreken. Danny legde uit dat het systeem alle inhoud van een site zou evalueren, en als het van mening was dat de site een aanzienlijke hoeveelheid ‘niet-nuttige inhoud’ bevatte, zou er een classificatie op de site worden toegepast. En die classificatie zou de ranglijst van de hele site (en niet alleen van de nutteloze inhoud) naar beneden kunnen halen. Het is dus een classificatie op siteniveau die enorme problemen op het gebied van de ranking kan veroorzaken.
Nadat ik tijdens dat telefoontje over de HCU had gehoord, zei ik dat het een soort Google Panda op steroïden zou kunnen zijn. De eerste paar HCU's veroorzaakten geen wijdverbreide dalingen, maar de HCU(X) van september deed dat wel (en was Panda-achtig voor veel niche-uitgevers). Binnenkort meer over Panda.
Het nuttige inhoudssysteem is dus a straffend systeem. Het lijkt te straffen en te degraderen. Ik haat het om het op deze manier te moeten zeggen, maar het is de waarheid.
Een definitie van bestraffend:
“het opleggen van of bedoeld als straf.”

En dat is precies wat de HCU van Google doet. Voor degenen die niet bekend zijn met de dalingen die veel site-eigenaren ervaren nadat ze getroffen zijn, zijn hier slechts een paar. Het is catastrofaal geweest voor die sites:
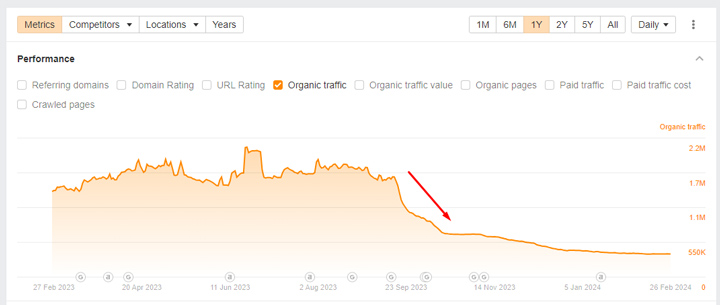
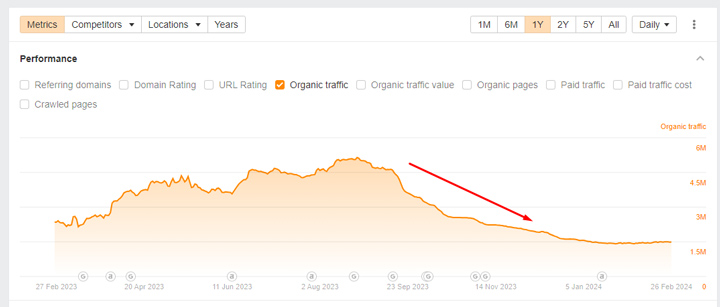
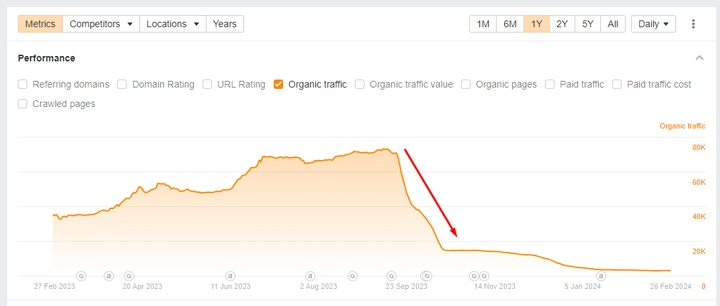
Ja, het zijn enge dingen. Het is vermeldenswaard dat ik meer dan 700 sites heb gedocumenteerd die zwaar getroffen zijn door de verschillende HCU's en de meeste zijn wat ik zou beschouwen als kleinere nichesites. Bijvoorbeeld een paar honderd pagina's geïndexeerd tot enkele duizenden pagina's. Het zijn vaak kleine sites die zich richten op een heel specifiek onderwerp. Het behulpzame inhoudssysteem van Google heeft de classificatie op die sites geplaatst nadat alle inhoud op elke site is geëvalueerd en als een Significante hoeveelheid van die inhoud ‘niet nuttig’ (of geschreven voor Zoeken versus mensen).
Herstel van de HCU:
Vanuit hersteloogpunt is vanaf het begin Google legde uit dat het niet gemakkelijk of snel zou zijn. Google legde bijvoorbeeld tijdens een telefoongesprek met mij in augustus 2022 uit dat sites zouden moeten bewijzen dat ze hun inhoud aanzienlijk hebben verbeterd om behulpzaam en geschreven te zijn voor mensen om te kunnen herstellen. En bovendien zou Google deze veranderingen moeten doorvoeren gedurende maanden voordat een site zich kon herstellen. Ik weet dat er de laatste tijd enige verwarring is geweest over de duur van het herstel, maar Google heeft vanaf het begin ‘maanden’ uitgelegd en niet ‘weken’.
Naar mijn mening is dit de reden dat niemand ook maar één site kan vinden die hersteld is van de HCU van september 2023. Het is gewoon te vroeg. Zelfs als een site bijvoorbeeld aanzienlijke wijzigingen heeft aangebracht en deze wijzigingen al in november of december zijn doorgevoerd, zijn we nog maar een paar maanden verwijderd van de daadwerkelijke wijzigingen. Dat is vanuit mijn perspectief gewoon niet genoeg tijd.
Er zijn enkele herstelacties geweest van eerdere HCU's, maar deze zijn zeldzaam. Bij het controleren van veel sites die getroffen zijn door de HCU's van augustus of december 2022, is de realiteit dat niet veel sites inhoudelijk zijn verbeterd. Dat zou dus een belangrijke reden kunnen zijn waarom veel sites die getroffen waren door eerdere HCU's, zich niet hebben hersteld. En om eerlijk te zijn, ik ben er zeker van dat Google daar blij mee zou zijn als de site-eigenaren die sites zouden bouwen voor zoekverkeer (en het genereren van inkomsten) in plaats van mensen te helpen. Dat is vrijwel de reden waarom het nuttige inhoudssysteem is gemaakt. Vergeet niet dat het een bestraffende algoritme-update. Het degradeert en bevordert niet.
Wanneer Google een groot probleem in de SERP’s moet aanpakken, wordt het PUNITIVE.
Toen ik sprak met site-eigenaren die zwaar getroffen waren door de HCU, kwam ik erachter dat sommigen niet bekend waren met eerdere Google-algoritme-updates die ook bestraffend waren. En nadat ze de evolutie van die eerdere bestraffende algoritme-updates hadden uitgelegd, waarom ze waren gemaakt, hoe ze werkten en meer, leken de site-eigenaren een beter begrip te hebben van het nuttige inhoudssysteem in het algemeen.
Kortom, wanneer Google in de loop van de tijd een groot probleem ziet groeien dat een negatieve invloed heeft op de kwaliteit van de zoekresultaten, kan het algoritme-updates maken die dat specifieke probleem aanpakken. Bij de HCU is het niet anders. Hieronder bespreek ik enkele van de bekendere systemen die bestraffend waren (sites straffen versus promoten).
Eerst een opmerking over algoritme-updates die BELONEN versus degraderen:
Ik werk veel met site-eigenaren die zwaar getroffen zijn door brede kernupdates. Wanneer een site negatief wordt beïnvloed door een brede kernupdate, kan dit voor sommige sites extreem zijn (en sommige met meer dan 60% naarmate de update wordt uitgerold). Maar het is belangrijk op te merken dat brede kernupdates bedoeld zijn om de hoogste kwaliteit en meest relevante inhoud naar voren te brengen. Het gaat niet om het straffen van sites, het gaat om het belonen ervan (alhoewel als je aan de verkeerde kant van een kernupdate belandt, het op een straf kan lijken.)
Het goede nieuws is dat als je zwaar getroffen bent door een brede kernupdate vanwege kwaliteitsproblemen, je kunt zeker herstellen. Als een site bijvoorbeeld in de loop van de tijd de kwaliteit aanzienlijk heeft verbeterd, kan deze verbeteringen zien tijdens daaropvolgende brede kernupdates. Het is ook vermeldenswaard dat Paul Haahr van Google mij tijdens de Webmaster Conference in 2019 uitlegde dat Google altijd algoritmen ontkoppelen van brede kernupdates en voer ze afzonderlijk uit. We hebben dat de afgelopen jaren een aantal keren zien gebeuren, maar nogmaals, sites typisch hebben nog een kernupdate nodig voordat ze herstel kunnen zien.

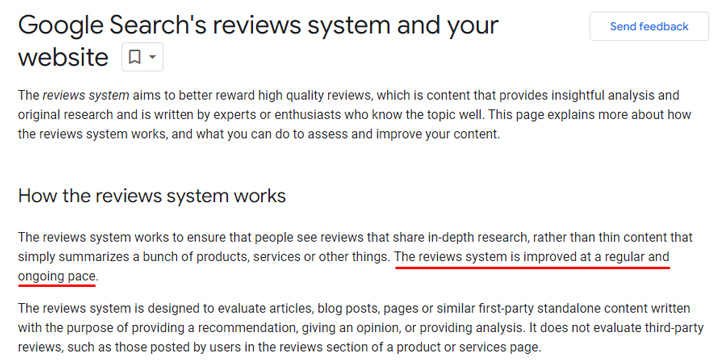
En dan is er nog die van Google beoordelingen systeem. Dat bevordert ook en degradeert niet. Maar nogmaals, als je aan de verkeerde kant van de update staat, kan het op een zware straf lijken. Veel bedrijven hebben contact met mij opgenomen nadat ze waren uitgewist door een recensie-update. Je kunt mijn bericht over de langetermijneffecten van het beoordelingssysteem voor meer informatie over hoeveel sites het hebben gedaan sinds de uitrol van deze updates. Tip, het is niet mooi...
Bovendien wordt het beoordelingssysteem vanaf de recensie-update van november 2023 “in een regelmatig en voortdurend tempo verbeterd”. Google zal dus geen specifieke recensiesupdates meer aankondigen. Dat was een grote verandering met de recensie-update van november 2023 (wat misschien wel de laatste officiële update is waar we over horen). Deze stap deed me denken aan het moment waarop Panda in 2016 in het kernrangschikkingsalgoritme van Google werd ingebakken, om er nooit meer iets van te horen. Ik zal binnenkort meer over Panda vertellen.
Nu zal ik enkele eerdere algoritme-updates bespreken die bestraffend waren. En als u getroffen bent door een HCU, kunnen bepaalde aspecten van elke update heel bekend in de oren klinken.
Google-pinguïn:
In 2012 had Google er eindelijk genoeg van dat sites zich via onnatuurlijke links een weg baanden naar de top van de zoekresultaten. Het spel met PageRank was krankzinnig in de aanloop naar 2012 en Google moest er iets aan doen. Dus creëerde het het Penguin-algoritme, dat sites die Google spamden via onnatuurlijke links zwaar degradeerde. Het was een degradatie op siteniveau en zorgde ervoor dat veel sites in de ranglijst kelderden. Veel site-eigenaren gingen failliet nadat ze door Penguin waren getroffen. Het was zeker een vervelende algoritme-update.
En net als bij de HCU waren de drops van Penguin extreem. Sommige sites kelderden van de ene op de andere dag met 80-90% en bleven achter met het uitzoeken wat ze moesten doen. Je kunt mijn bericht lezen Penguin 1.0 bevindingen nadat ik me zwaar had verdiept in de getroffen sites. Het duurde niet lang voordat we erachter kwamen wat het doelwit was. De linkprofielen van de getroffen sites waren gevuld met spam-achtige exacte match- en rich anchor-tekstlinks. En als ik zeg gevuld, bedoel ik ook GEVULD.
Hier is een voorbeeld van de distributie van ankerteksten van een Penguin-slachtoffer destijds. Het is volkomen onnatuurlijk:
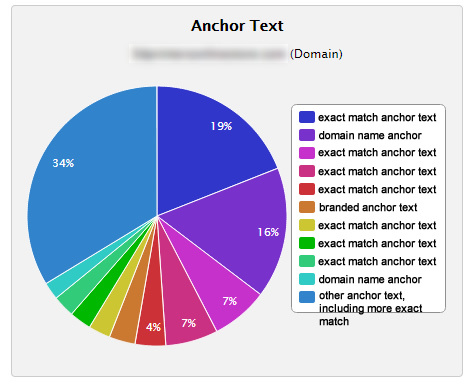
Ik kreeg veel telefoontjes van site-eigenaren die volledig in paniek raken nadat ze zijn geraakt. Een van de meest memorabele telefoontjes betrof een site-eigenaar die mij verwoed vroeg om de situatie voor hem uit te zoeken. Ik vroeg snel om de domeinnaam, zodat ik het linkprofiel kon controleren. Hij zei: "Wat bedoel je, ik heb 400 sites die je moet controleren." Ja, hij had 400 websites van één pagina die links naar de hel waren gespamd, allemaal bovenaan de zoekresultaten, en veel daarvan waren met elkaar verbonden. Hij verdiende met die opzet een flink bedrag per maand, dat van de ene op de andere dag daalde tot bijna $ 0. Penguin 1.0 was een zeer slechte dag voor zijn bedrijf.
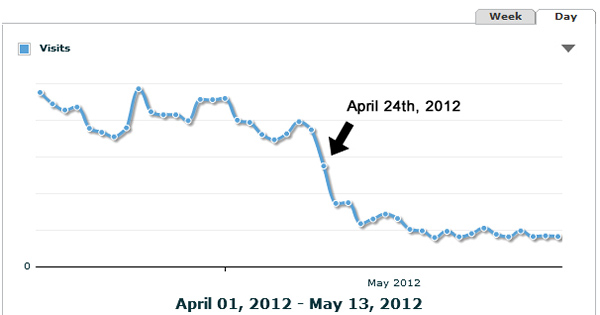
Hier is een daling van Penguin 1.0. Nogmaals, de drops waren extreem, net als bij de HCU:
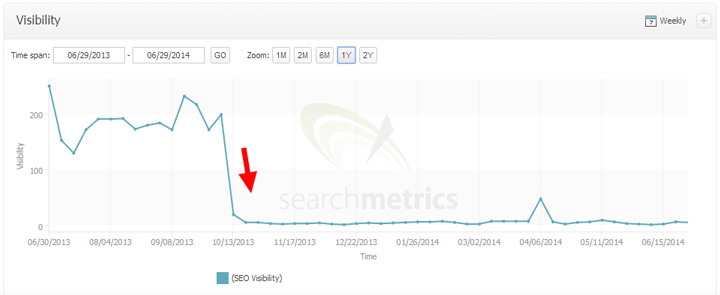
En hier is een druppel uit Penguin 2.1. De zoekzichtbaarheid daalt wanneer de update wordt uitgerold:
Wat het herstel betreft, waren er in de loop van de tijd niet veel. Klinkt veel als de HCU, toch? Waarom waren er niet veel terugvorderingen? Nou, als de meeste links op een site spam waren, dan was het moeilijk om al die links te verwijderen, en zelfs als je dat wel deed, bleef er een handvol links over die daadwerkelijk telden. De afwijzingstool is niet vrijgegeven tot oktober 2012, dus site-eigenaren die eerder door Penguin waren getroffen, probeerden verwoed spam-links te verwijderen, ze te laten nofollowen, of in het ergste geval de pagina's op hun sites te verwijderen die deze links ontvingen. Het was een complete puinhoop.
Dus voor degenen die klagen over de HCU: je moet weten dat Penguin niet veel beter was. Het was bestraffend en bestrafte veel site-eigenaren voor het gamen van de algoritmen van Google. Het maakte Google niet uit of die sites zich snel herstelden. Eigenlijk waren Penguin-updates vaak zo ver uit elkaar verspreid dat het duidelijk was dat het Google helemaal niets kon schelen. Er zat bijna twee jaar tussen Penguin 3.1 en 4. Ja, bijna twee jaar. Bovendien draaide Penguin pas in december 2014 continu, dus je had tot die tijd nog een Penguin-update nodig om te herstellen. En nogmaals, de meesten herstelden niet van de klap.
De hele situatie werd zo erg dat Google besloot Penguin op zijn kop te zetten en spam-achtige links te devalueren in plaats van ze te bestraffen. Dat is wat Bij Penguin 4.0 ging het allemaal om, en het was een belangrijke dag in de evolutie van Penguin. En kort daarna kon je de Penguin-onderdrukking op veel sites zien optreden. Het was behoorlijk wild om te zien. Trouwens, als ik het me goed herinner, speelde Gary Illyes van Google een belangrijke rol bij de overstap naar Penguin 4.0 (devaluatie versus bestraffing). Ik weet niet zeker of hij daarvoor naar mijn mening voldoende krediet heeft gekregen.
Hier is een tweet van mij die veranderingen in de zichtbaarheid van zoekresultaten laat zien op basis van de uitrol van Penguin 4.0:
Penguin was dus een vervelende en bestraffende algoritme-update die veel problemen veroorzaakte voor de getroffen site-eigenaren. Het zorgde ervoor dat veel sites failliet gingen, hoewel het wel een enorme hap uit de situatie met onnatuurlijke links nam. Dus ik vermoed dat Google het als succesvol beschouwde. En die beweging naar devalueren in plaats van bestraffen heeft ertoe geleid dat SpamBrain nu onnatuurlijke links hanteert (het negeert ongewenste, spamachtige links op internet). Het is een van de redenen waarom ik zo duidelijk heb gezegd dat 99.99% van de site-eigenaren links niet hoeft af te wijzen (tenzij ze willens en wetens onnatuurlijke links hebben opgezet, voor links hebben betaald of deel uitmaken van een linkprogramma). Als dat niet het geval is, laat SpamBrain dan zijn ding doen en stap af van de disavow-tool.
De evolutie van Penguin:
- Bestraffend algoritme verlaagt sites die onnatuurlijke links gamen zwaar.
- Eerst overgestapt op continu draaien na een periodieke vernieuwing (die nogal wat, zelfs jaren) kon duren.
- Ga in 2016 over op het devalueren van links in plaats van ze te bestraffen met Penguin 4.0 (een enorme verandering in de manier waarop Penguin werkte).
- Google heeft het Penguin-systeem buiten gebruik gesteld en ik neem aan dat delen ervan in SpamBrain zijn ingebakken, dat nu onnatuurlijke links verwerkt (door ze te neutraliseren).
Google Panda:
Voordat Google Penguin op het toneel verscheen, was Panda de grote algoritme-update waar iedereen het over had. Het werd gelanceerd in februari 2011 en had tot doel sites met veel dunne inhoud van lage kwaliteit te degraderen. Het algoritme is ontwikkeld op basis van een groeiend probleem, dat werd aangewakkerd door content farms. Veel sites publiceerden een hoop inhoud van extreem lage kwaliteit en dunne inhoud, die uiteindelijk goed scoorde. En afgezien van alleen maar dunne inhoud, waren die pagina's vaak bezaaid met een heleboel advertenties. Of erger nog: de artikelen waren verdeeld over dertig gepagineerde pagina's vol advertenties.
Google wist dat er iets moest gebeuren. En Panda werd geboren. Hier is een citaat uit de originele blogpost aankondiging van de algoritme-update:
“Deze update is ontworpen om de rankings voor sites van lage kwaliteit te verlagen – sites die weinig toegevoegde waarde hebben voor gebruikers, inhoud kopiëren van andere websites of sites die gewoon niet erg nuttig zijn.”
Ik kon meteen aan de Panda-analyse beginnen, aangezien een nieuwe publicatieklant van mij destijds 60 sites wereldwijd had (en ~30 zwaar werd getroffen door de eerste Panda-update). Ik kwam op die sites allerlei soorten lage kwaliteit en dunne inhoud tegen en stuurde de bevindingen in snel tempo door naar mijn cliënt.
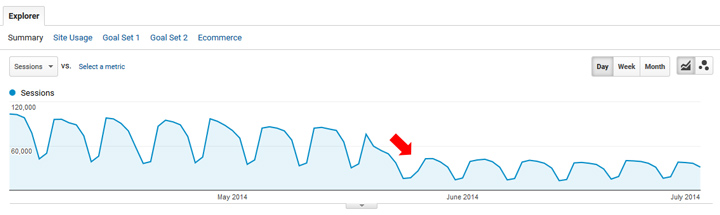
Hier is een voorbeeld van een grote Panda-hit. Deze site daalde van de ene op de andere dag met ongeveer 60%...
Hoewel de Panda-hits enorm konden zijn, was het goede nieuws dat Panda-updates doorgaans elke zes tot acht weken uitkwamen (en je technisch gezien bij elke volgende update de kans had om te herstellen als je genoeg had gedaan om te herstellen). Ik heb in de loop van de tijd veel bedrijven geholpen te herstellen van Panda-updates, en dat in veel branches. Dus hoewel Panda een bestraffende algoritme-update was, herstelden veel sites zich als ze de juiste wijzigingen doorvoerden om de kwaliteit in de loop van de tijd aanzienlijk te verbeteren.
Hier is een voorbeeld van een groot Panda-herstel, waarbij de site enorm groeit nadat er in de loop van de tijd hard aan is gewerkt om de kwaliteit te verbeteren. Dus nogmaals, herstel was heel goed mogelijk.
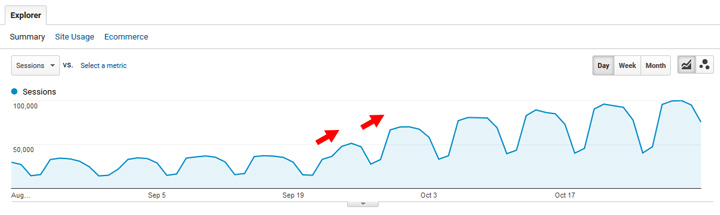
Dat is anders dan bij de HCU (althans tot nu toe), maar nogmaals: veel van de sites die door de HCU werden getroffen, waren kleinere nichesites. Ze hebben over het algemeen niet veel inhoud, en naar mijn mening moeten velen hun inhoud, gebruikerservaring volledig vernieuwen, agressieve advertenties verminderen, enz.
Panda werd uiteindelijk in 2013 gewijzigd en voor het eerst gestart wordt maandelijks en langzaam uitgerold, gedurende een periode van tien dagen. Dat betekende dat er nog meer grotere veranderingen zouden komen, en dat gebeurde uiteindelijk in 2016 toen Panda in het kernalgoritme van Google werd ingebakken, om nooit meer te worden gezien. Ik weet zeker dat delen van Panda nu deel uitmaken van de brede kernupdates van Google, maar de middeleeuwse Panda zwerft niet meer op internet (in de vorm van vóór 2013). Bovendien, en dit was interessant om meer over te weten te komen, legde HJ Kim van Google dat uit aan Barry Schwartz Panda evolueerde naar Coati op een gegeven moment (en is een onderdeel van het belangrijkste ranking-algoritme van Google). Trouwens, Danny Goodwin net heeft een geweldig bericht gepubliceerd terugkijkend op Panda (aangezien we net 13 jaar zijn verstreken sinds de lancering ervan).
Panda's evolutie:
- Bestraffend algoritme dat sites met veel lage kwaliteit of dunne inhoud zwaar kan degraderen.
- In 10 is de implementatie maandelijks, en langzaam, over een periode van tien dagen doorgevoerd.
- Panda werd uiteindelijk in 2016 ingebakken in het kernalgoritme van Google, om nooit meer te zien.
- Panda evolueerde in januari 2016 naar Coati en maakt nog steeds deel uit van het belangrijkste ranking-algoritme van Google (hoewel dit niet is hoe de middeleeuwse Panda er vroeger uitzag).
- Google heeft het Panda-systeem buiten gebruik gesteld en verwerkt inhoud van lagere kwaliteit op andere manieren (waarvan er één via het behulpzame inhoudssysteem is).
Terugkerend naar het nuttige inhoudssysteem: waar zou het vanaf hier naartoe kunnen gaan?
Oké, ik begon het bericht met waar ik dacht dat het nuttige inhoudssysteem vanaf hier naartoe zou kunnen gaan, daarna behandelde ik bestraffende algoritme-updates, en nu keer ik weer terug naar het nuttige inhoudssysteem. Nu u meer weet over waarom Google soms bestraffend moet optreden, en hoe Google dat in het verleden heeft gedaan, gaan we de oorspronkelijke punten nog eens bekijken.
Naar mijn mening zijn hier enkele scenario's die laten zien waar het behulpzame inhoudsysteem vanaf hier naartoe kan gaan. Ik geef eenvoudigweg de opsommingen vanaf het begin van dit artikel:
- Google zou eenvoudigweg de ernst van de HCU-classificatie kunnen verminderen. Het zou nog steeds voor de hele site gelden, maar sites zouden niet zo vaak naar beneden worden gesleept. Het zou zeker je aandacht trekken, en misschien net erg genoeg als je nog steeds grote veranderingen wilt implementeren vanuit een inhoudelijk en UX-oogpunt.
- Ten tweede zou het behulpzame inhoudssysteem misschien gedetailleerder kunnen worden (zoals Penguin in het verleden deed). De classificatie kan zwaarder worden toegepast op pagina's die als nutteloos worden beschouwd, in plaats van op een degradatie voor de hele site. Dit zou site-eigenaren natuurlijk een serieuze aanwijzing geven over welke delen van de inhoud als “niet nuttig” worden beschouwd, maar zou spammers ook een aanwijzing geven over waar de drempel ligt (wat een reden zou kunnen zijn dat Google deze weg niet zou inslaan).
- Ten derde zou het nuttige inhoudssysteem kunnen blijven zoals het is wat betreft de ernst ervan, en ook een signaal voor de hele site kunnen zijn, maar zou het beter in staat zijn zich te richten op grootschalige sites met veel nutteloze inhoud. We weten dat dit een probleem is bij een aantal krachtige, grootschalige sites, maar ze zijn niet echt beïnvloed door de verschillende HCU's, aangezien het merendeel van hun inhoud NIET als 'niet nuttig' zou worden geclassificeerd. De enorme dalingen waarvan veel kleinere nichesites getuige waren, zouden dus door grotere en meer gevestigde sites kunnen worden gezien als Google deze weg inslaat.
- Ten vierde verandert Google misschien de kracht van het UX-gedeelte van de HCU. Misschien is de HCU in de toekomst bijvoorbeeld niet zo gevoelig voor agressieve en ontwrichtende reclame. Of aan de andere kant: misschien verhoogt Google die ernst en wordt het zelfs nog agressiever. Ik heb in mijn bericht over de September HCU(X) hoe Google pagina-ervaring opnam in de nuttige inhoudsdocumentatie in april 2023 (een voorafschaduwing van wat we zagen met de HCU van september). En veel sites werden geteisterd met een combinatie van van nutteloze inhoud EN een vreselijke UX (vaak van agressieve advertenties). Dus in de toekomst zou Google altijd de kracht van de UX-component kunnen veranderen, wat een groot effect zou kunnen hebben op sites met nutteloze inhoud...
- En ten slotte zou Google het nuttige inhoudssysteem gewoon kunnen laten draaien zoals het nu is. Ik denk niet dat dit het geval zal zijn, op basis van al het kritiek dat Google te horen krijgt over de HCU(X) van september, maar het is heel goed mogelijk. Maar als Google, op basis van de enorme hoeveelheid gegevens die Google in de loop van de tijd evalueert, van mening is dat de zoekkwaliteit beter is als het behulpzame inhoudssysteem draait zoals het is, dan verandert er niets. Ik geloof echt dat we veranderingen zullen zien bij de volgende HCU, maar dit scenario is heel goed mogelijk.
Welke veranderingen zal de volgende HCU met zich meebrengen? Alleen Google weet...
We verwachten binnenkort weer een nuttige inhoudsupdate (HCU), dus het zal interessant zijn om te zien hoe de impact eruit ziet, hoeveel sites zich herstellen, of grotere sites getroffen worden, en meer. Nogmaals, er zijn veel sites die getroffen zijn door eerdere HCU's die willen herstellen, dus velen kijken reikhalzend uit naar de volgende update. Op dat moment zullen site-eigenaren ontdekken of ze genoeg hebben gedaan om te herstellen, of dat een systeemverfijning hen in staat stelt te herstellen. Ik zal het nauwlettend in de gaten houden, dat is zeker.
GG
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.gsqi.com/marketing-blog/google-helpful-content-system-evolution/

