Afbeelding door auteur
In de wereld van vandaag genereren we voortdurend informatie, maar veel daarvan komt voor in ongestructureerde formaten.
Dit omvat het enorme aanbod aan inhoud op sociale media, evenals talloze pdf's en Word-documenten die zijn opgeslagen in organisatienetwerken.
Het verkrijgen van inzichten en waarde uit deze ongestructureerde bronnen, of het nu gaat om tekstdocumenten, webpagina's of updates op sociale media, vormt een aanzienlijke uitdaging.
De opkomst van Large Language Models (LLM’s) zoals GPT of LlaMa heeft echter een volledige revolutie teweeggebracht in de manier waarop we met ongestructureerde gegevens omgaan.
Deze geavanceerde modellen dienen als krachtige instrumenten voor het transformeren van ongestructureerde gegevens in gestructureerde, waardevolle informatie, waardoor op effectieve wijze de verborgen schatten in ons digitale landschap worden ontgonnen.
Laten we vier verschillende manieren bekijken om inzichten uit ongestructureerde gegevens te halen met behulp van GPT 👇🏻
Gedurende deze tutorial zullen we werken met de API van OpenAI. Als je nog geen werkend account hebt, controleer dit dan tutorial over hoe u uw OpenAI API-account kunt krijgen.
Stel je voor dat we e-commerce runnen (Amazon in dit geval 😉), en wij zijn degenen die verantwoordelijk zijn voor het omgaan met de miljoenen recensies die gebruikers achterlaten op onze producten.
Om aan te tonen welke kansen LLM's bieden om met dergelijke soorten gegevens om te gaan, gebruik ik een Kaggle-dataset met Amazon-recensies.

Oorspronkelijke dataset
Gestructureerde gegevens verwijzen naar gegevenstypen die consistent zijn opgemaakt en herhaald. Klassieke voorbeelden zijn onder meer banktransacties, reserveringen voor luchtvaartmaatschappijen, detailhandelsverkopen en telefoongesprekgegevens.
Deze gegevens komen doorgaans voort uit transactionele processen.
Dergelijke gegevens zijn vanwege het uniforme formaat zeer geschikt voor opslag en beheer binnen een conventioneel databasebeheersysteem.
Aan de andere kant wordt tekst vaak gecategoriseerd als ongestructureerde gegevens. Historisch gezien, vóór de ontwikkeling van technieken voor het ondubbelzinnig maken van tekst, was het opnemen van tekst in een standaard databasebeheersysteem een uitdaging vanwege de minder rigide structuur ervan.
En dit brengt ons bij de volgende vraag…
Is tekst echt ongestructureerd, of heeft deze een onderliggende structuur die niet meteen duidelijk is?
Tekst heeft inherent een structuur, maar deze complexiteit komt niet overeen met het conventionele gestructureerde formaat dat door computers wordt herkend. Computers zijn in staat eenvoudige, ongecompliceerde structuren te interpreteren, maar taal, met zijn uitgebreide syntaxis, valt buiten hun begripsveld.
Dit brengt ons dus bij een laatste vraag:
Als computers moeite hebben om ongestructureerde gegevens efficiënt te verwerken, is het dan mogelijk om deze ongestructureerde gegevens om te zetten in een gestructureerd formaat voor een betere verwerking?
Handmatige conversie naar gestructureerde data is tijdrovend en kent een hoog risico op menselijke fouten. Het is vaak een mengelmoes van woorden, zinnen en alinea’s, in een grote verscheidenheid aan formaten, waardoor het voor machines moeilijk wordt om de betekenis ervan te vatten en te structureren.
En dit is precies waar LLM’s een sleutelrol spelen. Het omzetten van ongestructureerde gegevens naar een gestructureerd formaat is essentieel als we deze op de een of andere manier willen bewerken of verwerken, inclusief data-analyse, het ophalen van informatie en kennisbeheer.
Grote taalmodellen (LLM's) zoals GPT-3 of GPT-4 bieden krachtige mogelijkheden voor het extraheren van inzichten uit ongestructureerde gegevens.
Onze belangrijkste wapens zullen dus de OpenAI API zijn en het creëren van onze eigen aanwijzingen om te definiëren wat we nodig hebben. Hier zijn vier manieren waarop u deze modellen kunt gebruiken om gestructureerde inzichten uit ongestructureerde gegevens te verkrijgen:
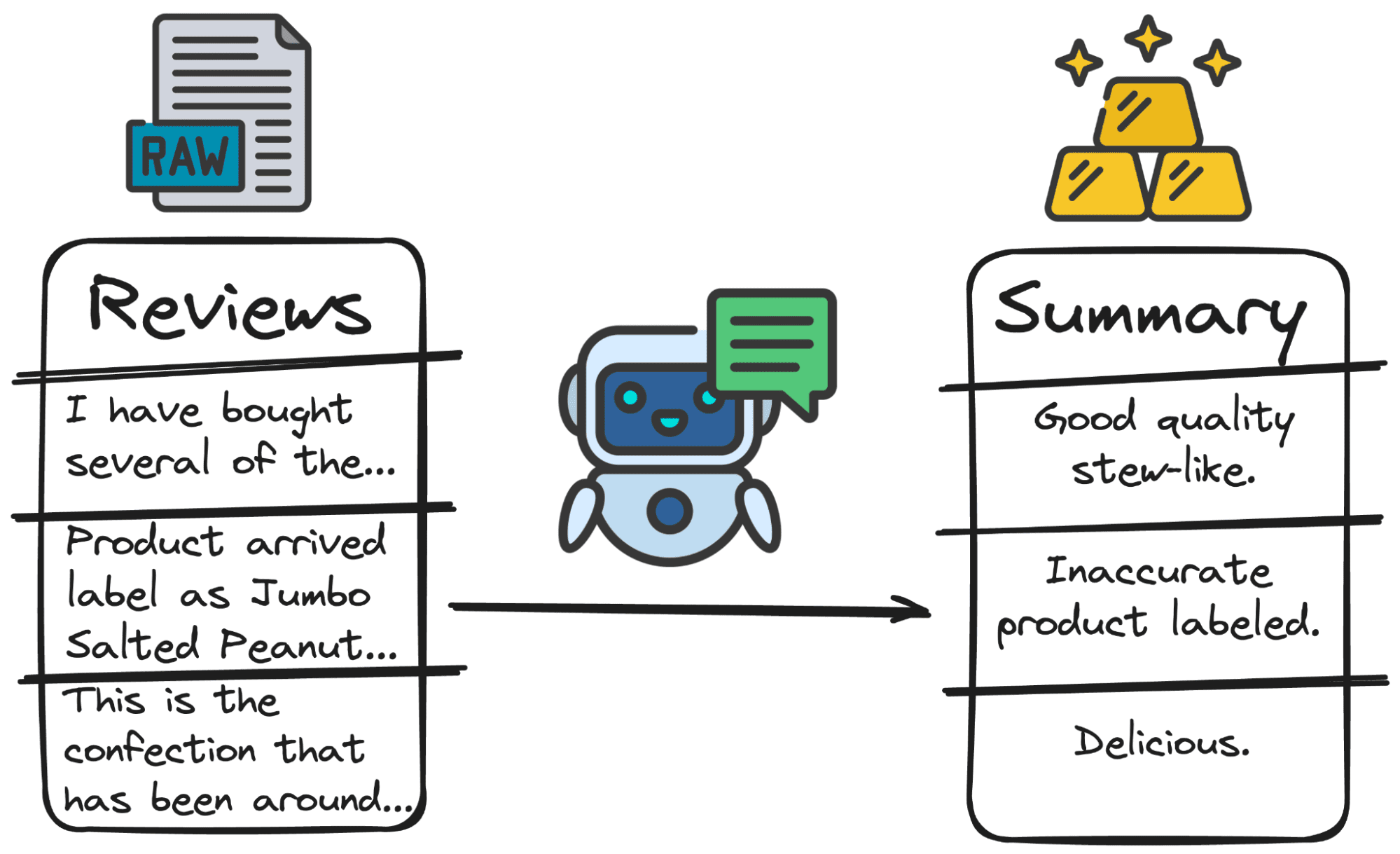
1. Samenvatting van de tekst
LLM's kunnen grote hoeveelheden tekst, zoals rapporten, artikelen of lange documenten, efficiënt samenvatten. Dit kan met name handig zijn voor het snel begrijpen van belangrijke punten en thema's in uitgebreide datasets.
In ons geval is het veel beter om een eerste samenvatting van de recensie te hebben dan de hele recensie. GPT kan het dus binnen enkele seconden afhandelen.
En onze enige – en belangrijkste taak – zal het opstellen van een goede prompt zijn.
In dit geval kan ik GPT opdracht geven om:
Summarize the following review: "{review}" with a 3 words sentence.
Laten we dit dus in de praktijk brengen met een paar regels code.
Code door auteur
En we krijgen zoiets als het volgende...
Afbeelding door auteur
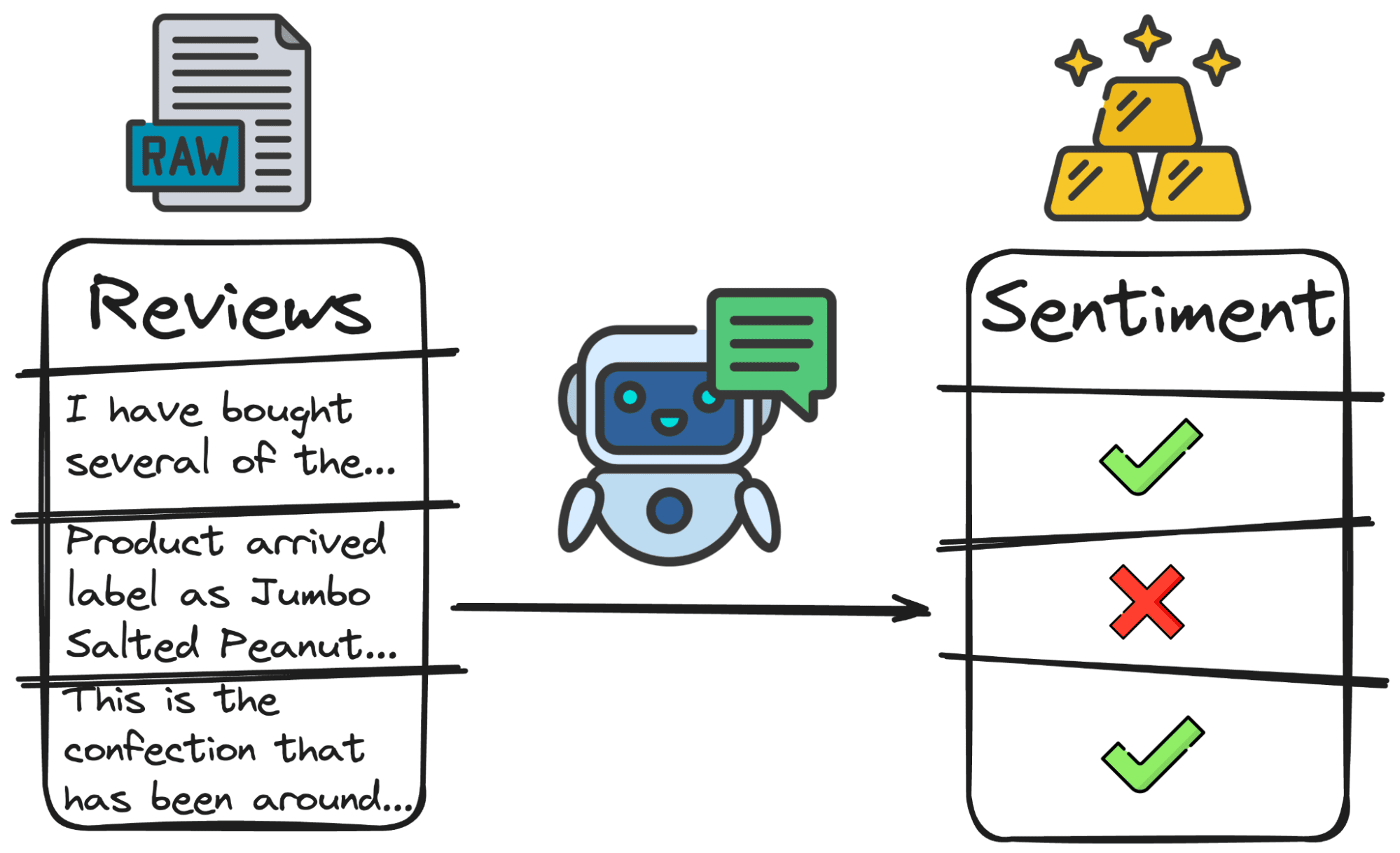
2. Sentimentanalyse
Deze modellen kunnen worden gebruikt voor sentimentanalyse, waarbij de toon en het sentiment van tekstgegevens worden bepaald, zoals klantrecensies, posts op sociale media of feedbackenquêtes.
De meest eenvoudige en toch meest gebruikte classificatie aller tijden is polariteit.
- Positieve recensies of waarom zijn mensen blij met het product.
- Negatieve recensies of waarom zijn ze van streek.
- Neutraal of waarom mensen onverschillig staan tegenover het product.
Door deze gevoelens te analyseren, kunnen bedrijven de publieke opinie, klanttevredenheid en markttrends peilen. Dus in plaats van dat iemand voor elke recensie beslist, kunnen we onze vriend GPT vragen om ze voor ons te classificeren.
De hoofdcode zal dus opnieuw bestaan uit een prompt en een eenvoudige aanroep van de API.
Laten we dit in de praktijk brengen.
Code door auteur
En we zouden iets als volgt verkrijgen:
Afbeelding door auteur
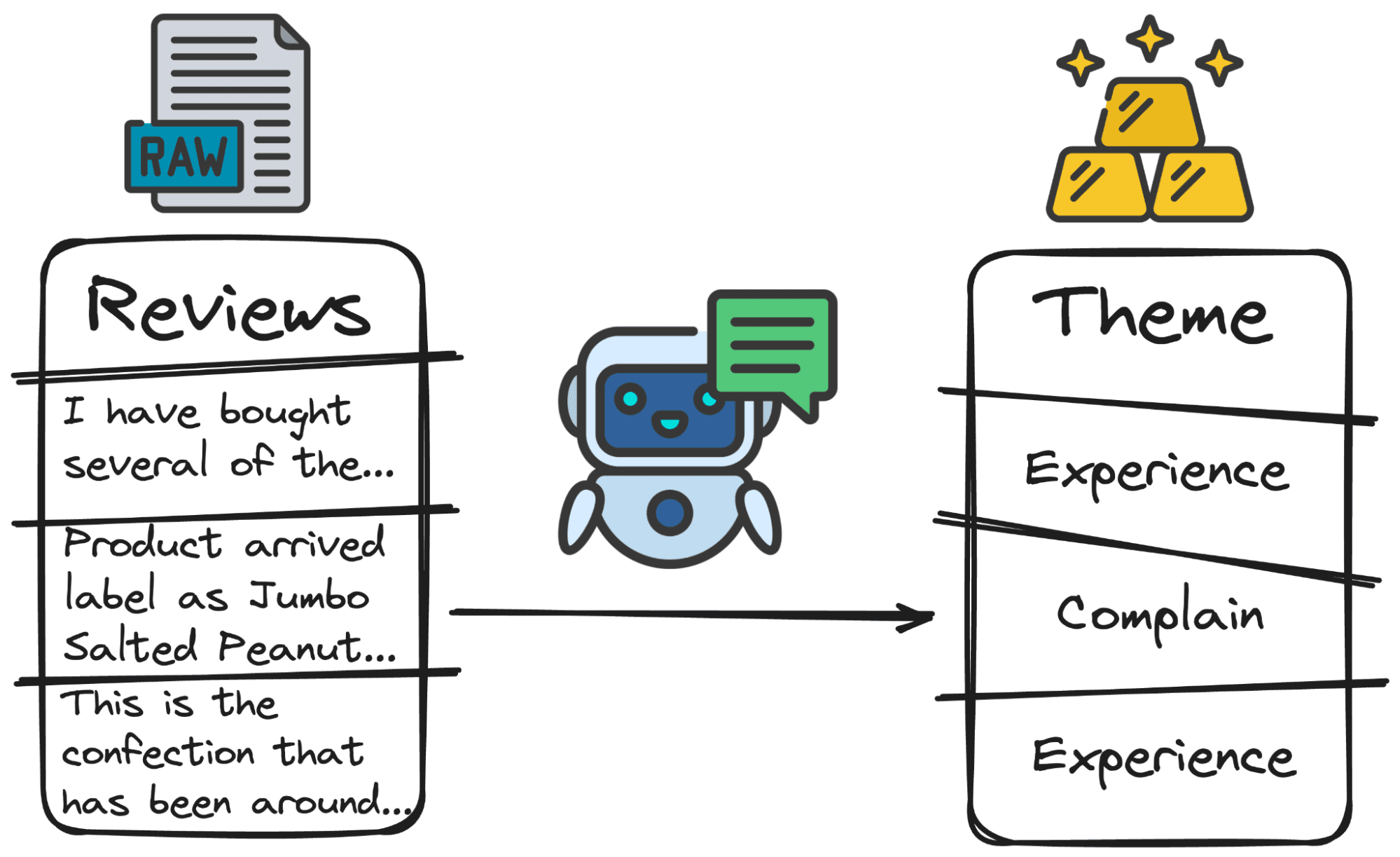
3. Thematische analyse
LLM's kunnen thema's of onderwerpen binnen grote datasets identificeren en categoriseren. Dit is met name handig voor kwalitatieve gegevensanalyse, waarbij u mogelijk grote hoeveelheden tekst moet doorzoeken om gemeenschappelijke thema's, trends of patronen te begrijpen.
Bij het analyseren van beoordelingen kan het nuttig zijn om het hoofddoel van de beoordeling te begrijpen. Sommige gebruikers zullen ergens over klagen (service, kwaliteit, kosten…), sommige gebruikers zullen hun ervaring met het product beoordelen (op een goede of een slechte manier) en weer anderen zullen vragen stellen.
Nogmaals, het handmatig doen van dit werk zou veel uren vergen. Maar met onze vriend GPT zijn er maar een paar regels code nodig:
Code door auteur
Afbeelding door auteur
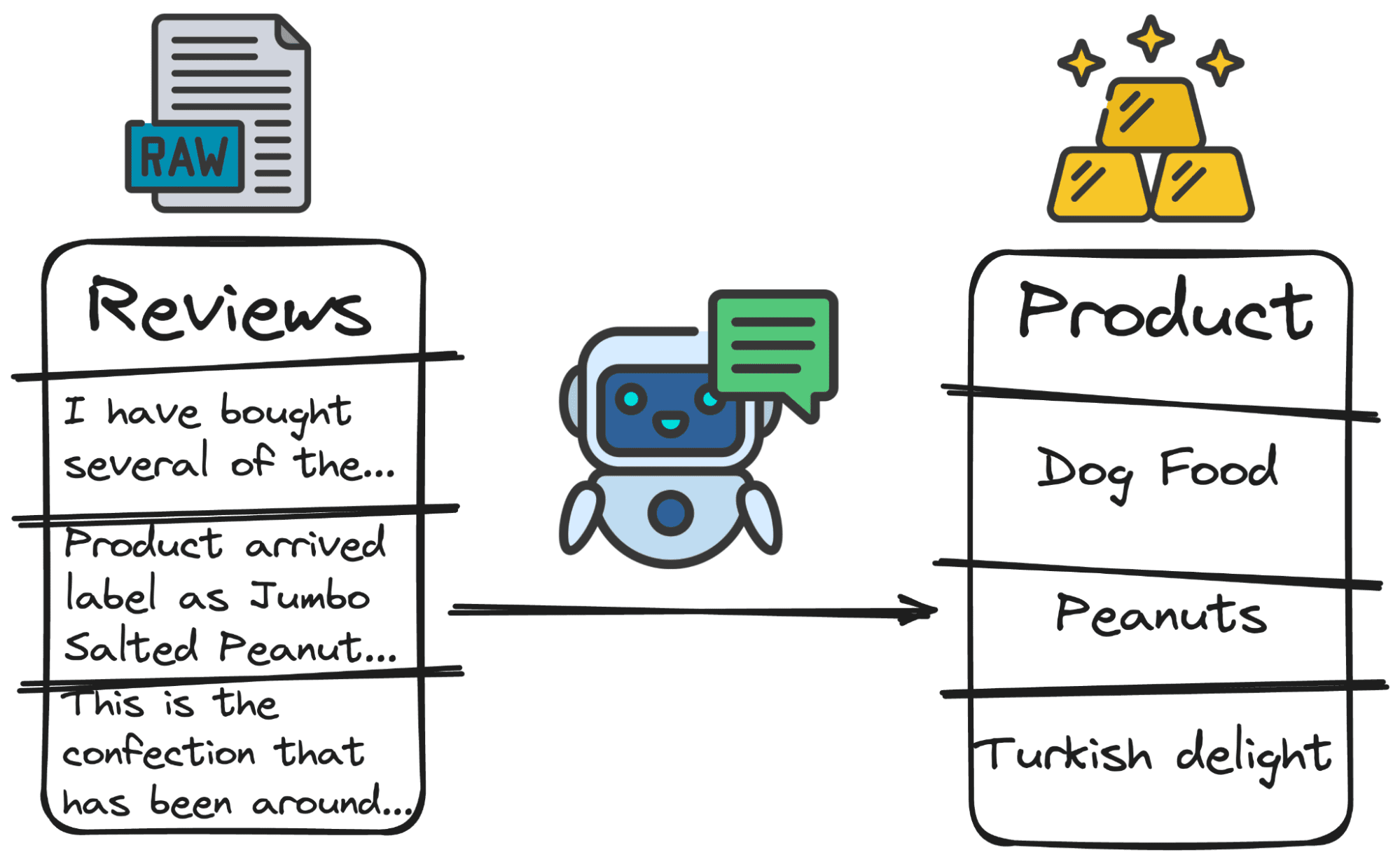
4. Zoekwoordextractie
LLM's kunnen worden gebruikt om trefwoorden te extraheren. Dit betekent dat we elk element detecteren waar we om vragen.
Stel je bijvoorbeeld voor dat we willen weten of het product waar de recensie bij zit, het product is waar de gebruiker het over heeft. Om dit te doen, moeten we detecteren welk product de gebruiker beoordeelt.
En nogmaals… we kunnen ons GPT-model vragen om uit te vinden over welk hoofdproduct de gebruiker het heeft.
Laten we dit dus in de praktijk brengen!
Code door auteur
Afbeelding door auteur
Concluderend kan de transformerende kracht van Large Language Models (LLM's) bij het omzetten van ongestructureerde gegevens in gestructureerde inzichten niet genoeg worden benadrukt. Door deze modellen te benutten, kunnen we betekenisvolle informatie extraheren uit de enorme zee van ongestructureerde gegevens die binnen onze digitale wereld stromen.
De vier besproken methoden – tekstsamenvatting, sentimentanalyse, thematische analyse en trefwoordextractie – demonstreren de veelzijdigheid en efficiëntie van LLM’s bij het omgaan met uiteenlopende data-uitdagingen.
Deze mogelijkheden stellen organisaties in staat een dieper inzicht te krijgen in de feedback van klanten, markttrends en operationele inefficiënties.
Joseph Ferrer is een analytisch ingenieur uit Barcelona. Hij is afgestudeerd in natuurkunde en werkt momenteel op het gebied van datawetenschap toegepast op menselijke mobiliteit. Hij is een parttime contentmaker die zich richt op datawetenschap en -technologie. U kunt contact met hem opnemen via LinkedIn, Twitter or Medium.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/5-ways-of-converting-unstructured-data-into-structured-insights-with-llms?utm_source=rss&utm_medium=rss&utm_campaign=5-ways-of-converting-unstructured-data-into-structured-insights-with-llms

