Je hebt net een project voltooid dat Python gebruikte. De code is schoon en leesbaar, maar uw prestatiebenchmark voldoet niet. Je verwachtte een resultaat in milliseconden, en in plaats daarvan kreeg je seconden. Wat doe je?
Als je dit artikel aan het lezen bent, weet je waarschijnlijk al dat Python een geïnterpreteerde programmeertaal is met dynamische semantiek en hoge leesbaarheid. Dat maakt het gemakkelijk te gebruiken en te lezen, maar niet snel genoeg voor veel praktijksituaties.
Er kunnen dus meerdere manieren zijn om uw Python-code te versnellen, inclusief maar niet beperkt tot het gebruik van efficiënte datastructuren en snelle en efficiënte algoritmen. Sommige Python-bibliotheken maken ook gebruik van C of C++ eronder om de berekening te versnellen.
Wat als je al deze opties hebt uitgeput? Hier komt parallelle verwerking en een stap verder is gedistribueerd computergebruik. In dit bericht leer je over de drie populaire frameworks in gedistribueerd computergebruik in een machine learning-context: PySpark, Dask en Ray.
PySpark is, zoals de naam al doet vermoeden, een interface van Apache Spark binnen Python. Het stelt de gebruiker in staat om Spark-programma's te schrijven met behulp van Python API's en biedt de PySpark-shell voor interactieve gegevensanalyse in een gedistribueerde omgeving. Het ondersteunt bijna alle functies van Spark, zoals Streaming, MLlib, Spark SQL, DataFrame en Spark Core, zoals hieronder weergegeven:

1. streaming
De streamingfunctie in Apache Spark is gebruiksvriendelijk en foutbestendig en draait bovenop Spark. Het drijft intuïtieve en analytische systemen aan voor zowel streaming als historische gegevens.
2. MLlib
MLlib is een schaalbare machine learning-bibliotheek die bovenop het Spark-framework is gebouwd. Het biedt een consistente set API's op hoog niveau om schaalbare machine learning-pijplijnen te creëren en af te stemmen.
3. Spark-SQL en DataFrame
Het is een Spark-module voor gegevensverwerking in tabelvorm. Het biedt een abstractielaag boven de gegevens in tabelvorm die bekend staat als DataFrame en kan fungeren als een query-engine in SQL-stijl in een gedistribueerde opstelling.
4. Vonkkern
Spark Core is de algemene uitvoeringsengine waarop alle andere functionaliteit is gebouwd. Het biedt een veerkrachtige gedistribueerde dataset (RDD) en berekening in het geheugen.
5. Panda's API op Spark
Pandas API is een module die schaalbare verwerking van functies en methoden van panda's mogelijk maakt. De syntaxis is net als panda's en vereist niet dat de gebruiker op een nieuwe module traint. Het biedt een naadloze en geïntegreerde codebase voor panda's (datasets van kleine/enkele machines) en Spark (grote gedistribueerde datasets).
Dask is een veelzijdige open-sourcebibliotheek voor gedistribueerd computergebruik die een vertrouwde gebruikersinterface biedt voor Panda's, Scikit-learn en NumPy.
Het stelt API's op hoog en laag niveau bloot waarmee gebruikers aangepaste algoritmen parallel kunnen uitvoeren op enkele of gedistribueerde machines.
Het heeft twee componenten:
- Big data-verzamelingen omvatten High-Level-verzamelingen zoals Dask Array of geparalleliseerde NumPy-arrays, Dask Bag of geparalleliseerde lijsten, Dask DataFrame of geparalleliseerde Panda's DataFrames en Parallelized Scikit-learn. Ze bevatten ook Low-Level collecties zoals Delayed en Futures die parallelle en real-time implementatie van aangepaste taken vergemakkelijken.
- Dynamische taakplanning maakt het mogelijk om taakgrafieken parallel op te schalen tot clusters van duizenden knooppunten.
Ray is een enkel platformframework dat wordt gebruikt in algemeen gedistribueerde Python en door AIML aangedreven applicaties. Het vormt een kern gedistribueerde runtime en een toolkit van bibliotheken (Ray AI Runtime) voor het parallelliseren van AIML-berekeningen zoals weergegeven in het onderstaande diagram:
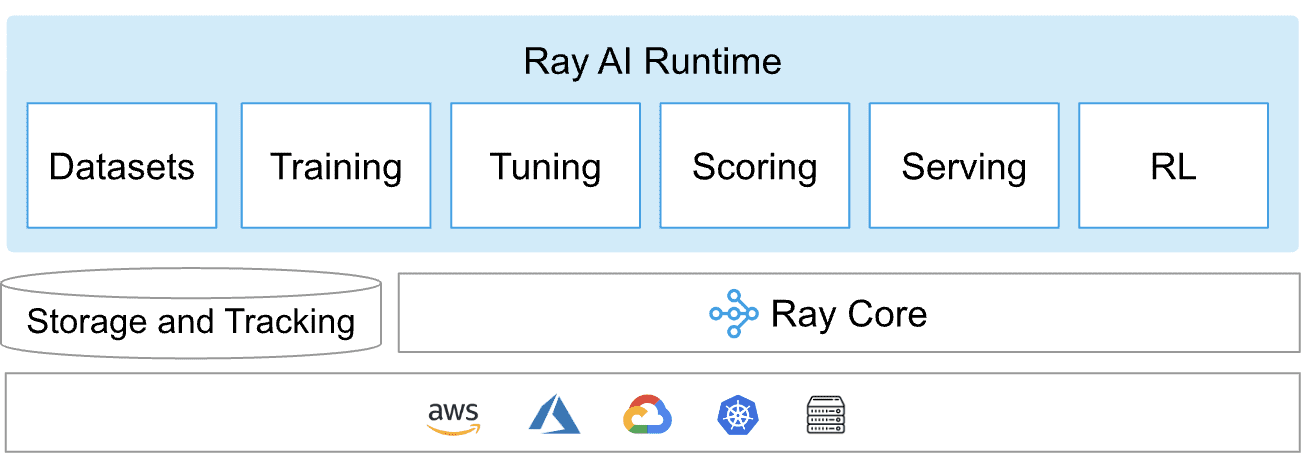
Ray AI-runtime
Ray AIR of Ray AI Runtime is een allesomvattende toolkit voor gedistribueerde ML-applicaties waarmee individuele en end-to-end workflows eenvoudig kunnen worden geschaald. Het bouwt voort op Ray's bibliotheken voor een breed scala aan taken, zoals voorverwerking, scoren, trainen, afstemmen, bedienen, enz.
Straal Kern
Ray Core biedt kernprimitieven zoals taken (staatloze functies die in het cluster worden uitgevoerd), actoren (stateful werkprocessen die in het cluster zijn gemaakt) en objecten (onveranderlijke waarden die toegankelijk zijn in het hele cluster) om schaalbare gedistribueerde applicaties te bouwen.
Ray schaalt machine learning-workloads met Ray AIR en bouwt en implementeert gedistribueerde applicaties met Ray Core en Ray Clusters.
Nu u uw opties kent, is de natuurlijke vraag welke u moet kiezen. Het antwoord hangt af van een aantal factoren, zoals de specifieke zakelijke behoefte, de kernsterkte van het ontwikkelingsteam, enz.
Laten we eens kijken welk raamwerk geschikt is voor de onderstaande specifieke vereisten:
- MAAT: PySpark is het meest capabel als het gaat om het omgaan met ultragrote workloads (TB's en meer), terwijl Dask en Ray het redelijk goed doen met middelgrote workloads.
- Algemeen: Ray loopt voorop als het gaat om generieke oplossingen, gevolgd door PySpark. Terwijl Dask puur gericht is op het schalen van ML-pijplijnen.
- Snelheid: Ray is de beste optie voor NLP- of tekstnormalisatietaken waarbij GPU's worden gebruikt om de berekening te versnellen. Dask biedt daarentegen toegang tot het snel lezen van gestructureerde bestanden naar DataFrame-objecten, maar loopt achter als het gaat om het samenvoegen en samenvoegen ervan. Hier scoort de Spark SQL goed.
- Bekendheid: Voor teams die meer geneigd zijn tot Panda's manier om gegevens op te halen en te filteren, lijkt Dask een go-to-optie te zijn, terwijl PySpark voor die teams is die op zoek zijn naar een SQL-achtige query-interface.
- Makkelijk te gebruiken: Alle drie de tools zijn gebouwd op verschillende platforms. Hoewel PySpark voornamelijk op Java en C++ is gebaseerd, is Dask puur Python, wat betekent dat uw ML-team inclusief datawetenschappers gemakkelijk foutmeldingen kan traceren als er iets kapot gaat. Ray daarentegen is C ++ in de kern, maar is redelijk Pythonisch als het gaat om de AIML-module (Ray AIR).
- Installatie en onderhoud: Ray en Dask scoren even goed als het gaat om onderhoudsoverhead. Spark-infrastructuur daarentegen is behoorlijk complex en moeilijk te onderhouden.
- Populariteit en ondersteuning: PySpark is de meest volwassen van allemaal en geniet van ondersteuning door de ontwikkelaarscommunity, terwijl Dask op de tweede plaats komt. Ray is veelbelovend in termen van functies die beschikbaar zijn in de bètatestfase.
- Toepasbaar op: Hoewel PySpark goed integreert met het Apache-ecosysteem, geleert Dask vrij goed met Python- en ML-bibliotheken.
Dit bericht besprak hoe Python-code sneller kan worden gemaakt dan de gebruikelijke keuze van datastructuren en algoritmen. De post concentreerde zich op drie bekende frameworks en hun componenten. De post is bedoeld om de lezer te helpen door de beschikbare keuzes af te wegen op een reeks van bepaalde attributen en zakelijke contexten.
Vidhi Chugh is een bekroonde AI/ML-innovatieleider en een AI-ethicus. Ze werkt op het snijvlak van datawetenschap, product en onderzoek om zakelijke waarde en inzichten te leveren. Ze is een pleitbezorger voor datacentrische wetenschap en een vooraanstaand expert in datagovernance met een visie om betrouwbare AI-oplossingen te bouwen.

