Introductie
In het midden van data science leugensstatistieken, die al eeuwen bestaan en toch van fundamenteel belang blijven in het huidige digitale tijdperk. Waarom? Omdat fundamentele statistische concepten de ruggengraat vormen van data-analyse, waardoor we inzicht kunnen krijgen in de enorme hoeveelheden gegevens die dagelijks worden gegenereerd. Het is net als praten met data, waarbij statistieken ons helpen de juiste vragen te stellen en de verhalen te begrijpen die data proberen te vertellen.
Van het voorspellen van toekomstige trends en het nemen van beslissingen op basis van data tot het testen van hypothesen en het meten van prestaties: statistieken zijn het instrument dat de inzichten achter datagestuurde beslissingen aanstuurt. Het is de brug tussen ruwe data en bruikbare inzichten, waardoor het een onmisbaar onderdeel is van datawetenschap.
In dit artikel heb ik de top 15 fundamentele statistische concepten samengesteld die elke data science-beginner zou moeten kennen!

Inhoudsopgave
1. Statistische bemonstering en gegevensverzameling
We zullen enkele fundamentele statistische concepten leren, maar begrijpen waar onze gegevens vandaan komen en hoe we deze verzamelen is essentieel voordat we diep in de oceaan van gegevens duiken. Dit is waar populaties, steekproeven en verschillende bemonsteringstechnieken een rol gaan spelen.
Stel je voor dat we de gemiddelde lengte van mensen in een stad willen weten. Het is praktisch om iedereen te meten, dus nemen we een kleinere groep (steekproef) die de grotere populatie vertegenwoordigt. De truc ligt in de manier waarop we dit monster selecteren. Technieken zoals willekeurige, gestratificeerde of clustersteekproeven zorgen ervoor dat onze steekproef goed wordt vertegenwoordigd, waardoor vertekening wordt geminimaliseerd en onze bevindingen betrouwbaarder worden.
Door populaties en steekproeven te begrijpen, kunnen we met vertrouwen onze inzichten van de steekproef uitbreiden naar de hele populatie, waardoor we weloverwogen beslissingen kunnen nemen zonder dat we iedereen hoeven te ondervragen.
2. Soorten gegevens en meetschalen
Gegevens zijn er in verschillende smaken, en het kennen van het soort gegevens waarmee u te maken heeft, is van cruciaal belang voor het kiezen van de juiste statistische hulpmiddelen en technieken.
Kwantitatieve en kwalitatieve gegevens
- Kwantitatieve gegevens: Bij dit soort gegevens draait alles om cijfers. Het is meetbaar en kan worden gebruikt voor wiskundige berekeningen. Kwantitatieve gegevens vertellen ons ‘hoeveel’ of ‘hoeveel’, zoals het aantal gebruikers dat een website bezoekt of de temperatuur in een stad. Het is eenvoudig en objectief en geeft een duidelijk beeld via numerieke waarden.
- Kwalitatieve data: Omgekeerd gaan kwalitatieve gegevens over kenmerken en beschrijvingen. Het gaat over ‘welk type’ of ‘welke categorie’. Zie het als de gegevens die kwaliteiten of attributen beschrijven, zoals de kleur van een auto of het genre van een boek. Deze gegevens zijn subjectief en gebaseerd op observaties in plaats van metingen.
Vier meetschalen
- Nominale schaal: Dit is de eenvoudigste meetvorm die wordt gebruikt voor het categoriseren van gegevens zonder een specifieke volgorde. Voorbeelden hiervan zijn soorten keuken, bloedgroepen of nationaliteit. Het gaat om etikettering zonder enige kwantitatieve waarde.
- Ordinale schaal: Gegevens kunnen hier worden geordend of gerangschikt, maar de intervallen tussen waarden zijn niet gedefinieerd. Denk aan een tevredenheidsonderzoek met opties als tevreden, neutraal en ontevreden. Het vertelt ons de volgorde, maar niet de afstand tussen de ranglijsten.
- Intervalschaal: Intervalschalen rangschikken gegevens en kwantificeren het verschil tussen invoer. Er is echter geen echt nulpunt. Een goed voorbeeld is de temperatuur in Celsius; het verschil tussen 10°C en 20°C is hetzelfde als tussen 20°C en 30°C, maar 0°C betekent niet dat er geen temperatuur is.
- Verhoudingsschaal: De meest informatieve schaal heeft alle eigenschappen van een intervalschaal plus een betekenisvol nulpunt, waardoor een nauwkeurige vergelijking van grootheden mogelijk is. Voorbeelden hiervan zijn gewicht, lengte en inkomen. Hier kunnen we zeggen dat iets twee keer zoveel is als een ander.
3. Beschrijvende statistieken
Imagine beschrijvende statistieken als je eerste date met je gegevens. Het gaat erom dat je de basis leert kennen, de grote lijnen die beschrijven wat je te wachten staat. Beschrijvende statistiek kent twee hoofdtypen: centrale tendens- en variabiliteitsmetingen.
Maatregelen van centrale tendens: Deze vormen het zwaartepunt van de data. Ze geven ons een enkele waarde die typisch of representatief is voor onze dataset.
Gemeen: Het gemiddelde wordt berekend door alle waarden bij elkaar op te tellen en te delen door het aantal waarden. Het is net als de algemene beoordeling van een restaurant op basis van alle beoordelingen. De wiskundige formule voor het gemiddelde wordt hieronder gegeven:

Mediaan: De middelste waarde wanneer de gegevens zijn gerangschikt van klein naar groot. Als het aantal waarnemingen even is, is dit het gemiddelde van de twee middelste getallen. Het wordt gebruikt om het middelpunt van een brug te vinden.
Als n even is, is de mediaan het gemiddelde van de twee centrale getallen.
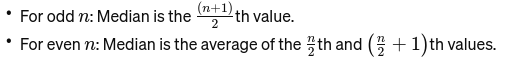
Mode: Het is de meest voorkomende waarde in een dataset. Zie het als het populairste gerecht in een restaurant.
Maatregelen van variabiliteit: Terwijl maatstaven van centrale tendens ons naar het centrum brengen, vertellen maatstaven van variabiliteit ons over de spreiding of spreiding.
Bereik: Het verschil tussen de hoogste en laagste waarden. Het geeft een basisidee van de verspreiding.
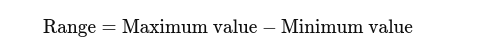
Variantie: Meet hoe ver elk getal in de set verwijderd is van het gemiddelde en dus van elk ander getal in de set. Voor een voorbeeld wordt het als volgt berekend:
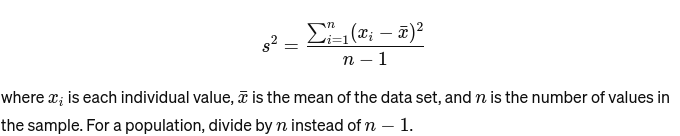
Standaardafwijking: De vierkantswortel van de variantie geeft een maatstaf voor de gemiddelde afstand tot het gemiddelde. Het is alsof je de consistentie van de taartformaten van een bakker beoordeelt. Het wordt weergegeven als:
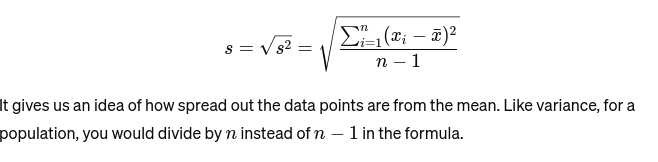
Voordat we naar het volgende basisstatistiekconcept gaan, volgt hier een Beginnersgids voor statistische analyse te creëren voor u!
4. Gegevensvisualisatie
Data visualisatie is de kunst en wetenschap van het vertellen van verhalen met data. Het verandert complexe resultaten uit onze analyse in iets tastbaars en begrijpelijks. Het is van cruciaal belang voor verkennende data-analyse, waarbij het doel is om patronen, correlaties en inzichten uit data te ontdekken zonder nog formele conclusies te trekken.
- Grafieken en grafieken: Beginnend met de basis bieden staafdiagrammen, lijngrafieken en cirkeldiagrammen fundamentele inzichten in de gegevens. Ze zijn het ABC van datavisualisatie, essentieel voor elke dataverteller.
Hieronder vindt u een voorbeeld van een staafdiagram (links) en een lijndiagram (rechts).
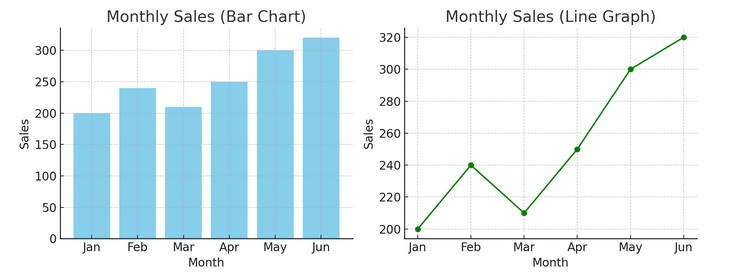
- Geavanceerde visualisaties: Naarmate we dieper duiken, maken hittekaarten, spreidingsdiagrammen en histogrammen een meer genuanceerde analyse mogelijk. Deze tools helpen bij het identificeren van trends, distributies en uitschieters.
Hieronder ziet u een voorbeeld van een spreidingsdiagram en een histogram

Visualisaties vormen een brug tussen ruwe data en menselijke cognitie, waardoor we complexe datasets snel kunnen interpreteren en begrijpen.
5. Basisbeginselen van waarschijnlijkheid
Waarschijnlijkheid is de grammatica van de taal van de statistiek. Het gaat over de kans of waarschijnlijkheid dat gebeurtenissen plaatsvinden. Het begrijpen van concepten in waarschijnlijkheid is essentieel voor het interpreteren van statistische resultaten en het maken van voorspellingen.
- Onafhankelijke en afhankelijke gebeurtenissen:
- Onafhankelijke evenementen: De uitkomst van de ene gebeurtenis heeft geen invloed op de uitkomst van een andere gebeurtenis. Net als bij het opgooien van een munt, verandert het krijgen van kop bij één worp niets aan de kansen voor de volgende worp.
- Afhankelijke gebeurtenissen: De uitkomst van de ene gebeurtenis beïnvloedt het resultaat van een andere. Als u bijvoorbeeld een kaart uit een stapel trekt en deze niet vervangt, veranderen uw kansen om nog een specifieke kaart te trekken.
Waarschijnlijkheid vormt de basis voor het maken van conclusies over gegevens en is van cruciaal belang voor het begrijpen van statistische significantie en het testen van hypothesen.
6. Gemeenschappelijke waarschijnlijkheidsverdelingen
Kansverdelingen zijn als verschillende soorten in het statistische ecosysteem, elk aangepast aan hun niche van toepassingen.
- Normale verdeling: Deze verdeling wordt vanwege zijn vorm vaak de belcurve genoemd en wordt gekenmerkt door zijn gemiddelde en standaarddeviatie. Het is een gebruikelijke aanname bij veel statistische tests, omdat veel variabelen in de echte wereld van nature op deze manier zijn verdeeld.
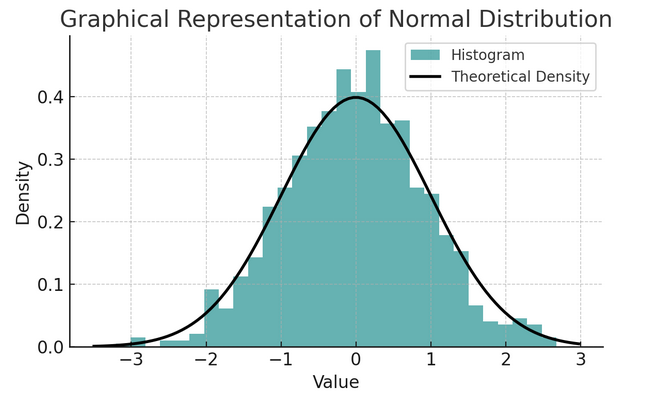
Een reeks regels die bekend staat als de empirische regel of de 68-95-99.7-regel vat de kenmerken van een normale verdeling samen, die beschrijft hoe gegevens rond het gemiddelde worden verspreid.
68-95-99.7 Regel (Empirische regel)
Deze regel is van toepassing op een volkomen normale verdeling en schetst het volgende:
- 68% van de gegevens valt binnen één standaardafwijking (σ) van het gemiddelde (μ).
- 95% van de gegevens binnen twee standaarddeviaties van het gemiddelde valt.
- Ongeveer 99.7% van de gegevens binnen drie standaarddeviaties van het gemiddelde valt.
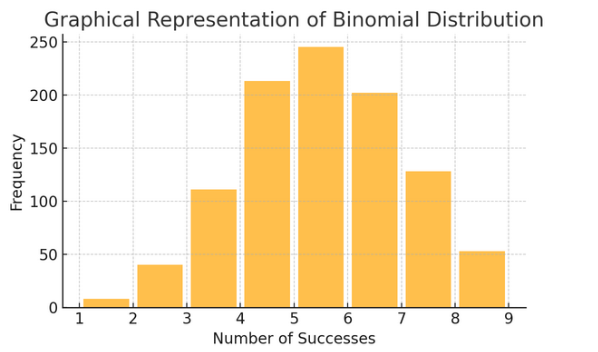
Binominale verdeling: Deze verdeling is van toepassing op situaties met twee uitkomsten (zoals succes of mislukking) die meerdere keren worden herhaald. Het helpt bij het modelleren van gebeurtenissen zoals het opgooien van een munt of het afleggen van een waar/niet waar-test.
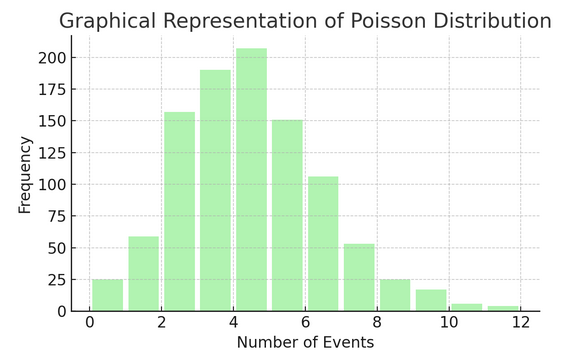
Poisson Distributie telt het aantal keren dat iets gebeurt gedurende een specifiek interval of een bepaalde ruimte. Het is ideaal voor situaties waarin gebeurtenissen onafhankelijk en voortdurend plaatsvinden, zoals de dagelijkse e-mails die u ontvangt.
Elke distributie heeft zijn eigen reeks formules en kenmerken, en het kiezen van de juiste hangt af van de aard van uw gegevens en wat u probeert te achterhalen. Door deze verdelingen te begrijpen, kunnen statistici en datawetenschappers fenomenen uit de echte wereld modelleren en toekomstige gebeurtenissen nauwkeurig voorspellen.
7. Hypothese testen
Denken hypothesetesten als speurwerk in de statistiek. Het is een methode om te testen of een bepaalde theorie over onze gegevens waar zou kunnen zijn. Dit proces begint met twee tegengestelde hypothesen:
- Nulhypothese (H0): Dit is de standaardaanname, die duidt op een effect of verschil. Er staat: 'Niet' is hier nieuw.'
- Al “alternatieve hypothese (H1 of Ha): Dit daagt de status quo uit en stelt een effect of een verschil voor. Er wordt beweerd: “Er is iets interessants aan de hand.”
Voorbeeld: Testen of een nieuw dieetprogramma leidt tot gewichtsverlies in vergelijking met het niet volgen van een dieet.
- Nulhypothese (H0): Het nieuwe dieetprogramma leidt niet tot gewichtsverlies (geen verschil in gewichtsverlies tussen degenen die het nieuwe dieetprogramma volgen en degenen die dat niet doen).
- Alternatieve hypothese (H1): Het nieuwe dieetprogramma leidt tot gewichtsverlies (een verschil in gewichtsverlies tussen degenen die het volgen en degenen die dat niet doen).
Het testen van hypothesen houdt in dat je tussen deze twee moet kiezen op basis van het bewijsmateriaal (onze gegevens).
Type I en II fout- en significantieniveaus:
- Type I-fout: Dit gebeurt wanneer we de nulhypothese ten onrechte verwerpen. Het veroordeelt een onschuldig persoon.
- Type II-fout: Dit gebeurt wanneer we er niet in slagen een valse nulhypothese te verwerpen. Het laat een schuldige vrijuit gaan.
- Betekenisniveau (α): Dit is de drempel om te beslissen hoeveel bewijs voldoende is om de nulhypothese te verwerpen. Deze wordt vaak ingesteld op 5% (0.05), wat wijst op een risico van 5% op een Type I-fout.
8. Betrouwbaarheidsintervallen
Betrouwbaarheidsintervallen geef ons een bereik van waarden waarbinnen we verwachten dat de geldige populatieparameter (zoals een gemiddelde of proportie) zal vallen met een bepaald betrouwbaarheidsniveau (gewoonlijk 95%). Het is alsof je de eindscore van een sportteam met een foutmarge voorspelt; we zeggen: “We zijn er 95% zeker van dat de werkelijke score binnen dit bereik zal liggen.”
Het construeren en interpreteren van betrouwbaarheidsintervallen helpt ons de nauwkeurigheid van onze schattingen te begrijpen. Hoe groter het interval, hoe minder nauwkeurig onze schatting is, en omgekeerd.
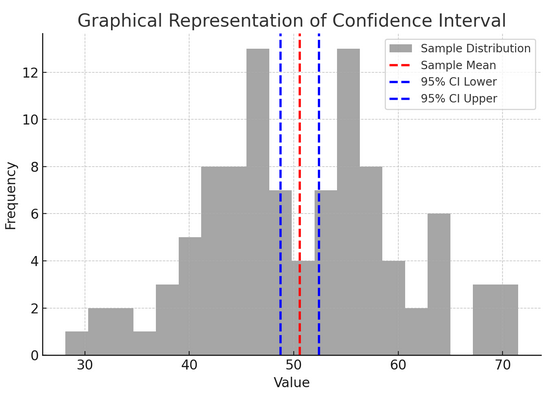
De bovenstaande figuur illustreert het concept van een betrouwbaarheidsinterval (CI) in statistieken, met behulp van een steekproefverdeling en het 95% betrouwbaarheidsinterval rond het steekproefgemiddelde.
Hier is een overzicht van de kritische componenten in de figuur:
- Monsterverdeling (grijs histogram): Dit vertegenwoordigt de verdeling van 100 gegevenspunten die willekeurig zijn gegenereerd op basis van een normale verdeling met een gemiddelde van 50 en een standaarddeviatie van 10. Het histogram geeft visueel weer hoe de gegevenspunten rond het gemiddelde zijn verspreid.
- Steekproefgemiddelde (rode stippellijn): Deze lijn geeft de gemiddelde (gemiddelde) waarde van de voorbeeldgegevens aan. Het dient als de puntschatting waarrond we het betrouwbaarheidsinterval construeren. In dit geval vertegenwoordigt dit het gemiddelde van alle monsterwaarden.
- 95% betrouwbaarheidsinterval (blauwe stippellijnen): Deze twee lijnen markeren de onder- en bovengrenzen van het 95%-betrouwbaarheidsinterval rond het steekproefgemiddelde. Het interval wordt berekend met behulp van de standaardfout van het gemiddelde (SEM) en een Z-score die overeenkomt met het gewenste betrouwbaarheidsniveau (1.96 voor 95% betrouwbaarheid). Het betrouwbaarheidsinterval suggereert dat we er 95% zeker van zijn dat het populatiegemiddelde binnen dit bereik ligt.
9. Correlatie en oorzakelijk verband
Correlatie en oorzakelijk verband worden vaak door elkaar gehaald, maar ze zijn verschillend:
- Correlatie: Geeft een relatie of associatie aan tussen twee variabelen. Als de een verandert, verandert de ander meestal ook. De correlatie wordt gemeten met een correlatiecoëfficiënt variërend van -1 tot 1. Een waarde dichter bij 1 of -1 duidt op een sterke relatie, terwijl 0 duidt op geen verband.
- Oorzaak: Het houdt in dat veranderingen in de ene variabele direct veranderingen in de andere veroorzaken. Het is een robuustere bewering dan correlatie en vereist rigoureuze tests.
Het feit dat twee variabelen met elkaar gecorreleerd zijn, betekent niet dat de een de ander veroorzaakt. Dit is een klassiek geval van het niet verwarren van ‘correlatie’ met ‘oorzakelijk verband’.
10. Eenvoudige lineaire regressie
Eenvoudig lineaire regressie is een manier om de relatie tussen twee variabelen te modelleren door een lineaire vergelijking aan te passen aan waargenomen gegevens. Eén variabele wordt beschouwd als een verklarende variabele (onafhankelijk), en de andere is een afhankelijke variabele.
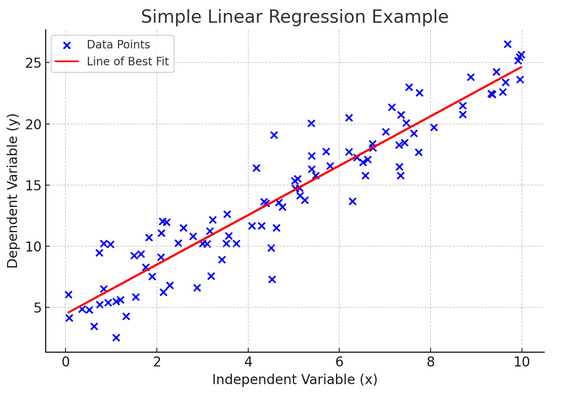
Eenvoudige lineaire regressie helpt ons te begrijpen hoe veranderingen in de onafhankelijke variabele de afhankelijke variabele beïnvloeden. Het is een krachtig hulpmiddel voor voorspellingen en vormt de basis voor veel andere complexe statistische modellen. Door de relatie tussen twee variabelen te analyseren, kunnen we weloverwogen voorspellingen doen over de interactie tussen deze variabelen.
Eenvoudige lineaire regressie gaat uit van een lineair verband tussen de onafhankelijke variabele (verklarende variabele) en de afhankelijke variabele. Als de relatie tussen deze twee variabelen niet lineair is, kunnen de aannames van eenvoudige lineaire regressie worden geschonden, wat mogelijk kan leiden tot onnauwkeurige voorspellingen of interpretaties. Het verifiëren van een lineair verband in de gegevens is dus essentieel voordat eenvoudige lineaire regressie wordt toegepast.
11. Meervoudige lineaire regressie
Beschouw meervoudige lineaire regressie als een uitbreiding van eenvoudige lineaire regressie. Maar in plaats van te proberen een uitkomst te voorspellen met één ridder op het witte paard (voorspeller), heb je een heel team. Het is als het upgraden van een één-op-één basketbalspel naar een teamprestatie, waarbij elke speler (voorspeller) unieke vaardigheden met zich meebrengt. Het idee is om te zien hoe verschillende variabelen samen één uitkomst beïnvloeden.
Met een groter team komt echter de uitdaging van het beheren van relaties, ook wel multicollineariteit genoemd. Het treedt op wanneer voorspellers te dicht bij elkaar staan en vergelijkbare informatie delen. Stel je voor dat twee basketbalspelers voortdurend hetzelfde schot proberen te maken; ze kunnen elkaar in de weg zitten. Regressie kan het moeilijk maken om de unieke bijdrage van elke voorspeller te zien, waardoor ons begrip van welke variabelen significant zijn mogelijk wordt vertekend.
12. Logistieke regressie
Terwijl lineaire regressie continue resultaten voorspelt (zoals temperatuur of prijzen), logistische regressie wordt gebruikt als het resultaat definitief is (zoals ja/nee, winnen/verliezen). Stel je voor dat je probeert te voorspellen of een team zal winnen of verliezen op basis van verschillende factoren; logistische regressie is uw go-to-strategie.
Het transformeert de lineaire vergelijking zodat de output tussen 0 en 1 valt, wat de waarschijnlijkheid vertegenwoordigt om tot een bepaalde categorie te behoren. Het is alsof je een magische lens hebt die continue scores omzet in een duidelijk 'dit of dat'-beeld, waardoor we categorische uitkomsten kunnen voorspellen.
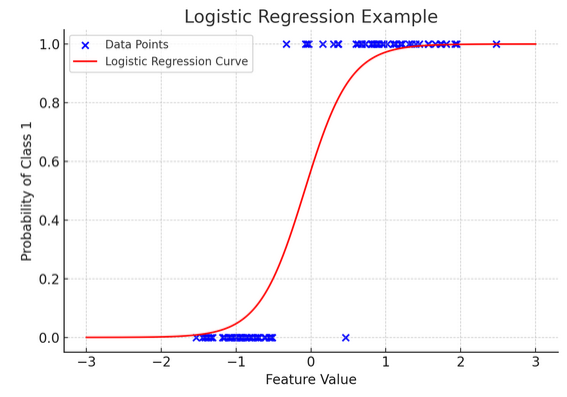
De grafische weergave illustreert een voorbeeld van logistische regressie toegepast op een synthetische binaire classificatiegegevensset. De blauwe stippen vertegenwoordigen de gegevenspunten, waarbij hun positie langs de x-as de kenmerkwaarde aangeeft en de y-as de categorie aangeeft (0 of 1). De rode curve vertegenwoordigt de voorspelling van het logistieke regressiemodel van de waarschijnlijkheid om tot klasse 1 te behoren (bijvoorbeeld 'winnen') voor verschillende kenmerkwaarden. Zoals u kunt zien, gaat de curve soepel over van de waarschijnlijkheid van klasse 0 naar klasse 1, wat het vermogen van het model aantoont om categorische uitkomsten te voorspellen op basis van een onderliggend continu kenmerk.
De formule voor logistische regressie wordt gegeven door:

Deze formule gebruikt de logistieke functie om de uitkomst van de lineaire vergelijking om te zetten in een waarschijnlijkheid tussen 0 en 1. Deze transformatie stelt ons in staat de uitkomsten te interpreteren als kansen om tot een bepaalde categorie te behoren, gebaseerd op de waarde van de onafhankelijke variabele xx.
13. ANOVA- en Chi-kwadraattesten
ANOVA (analyse van variantie) en Chi-kwadraattesten zijn als detectives in de statistische wereld en helpen ons verschillende mysteries op te lossen. It stelt ons in staat gemiddelden van meerdere groepen te vergelijken om te zien of ten minste één statistisch verschillend is. Zie het als het proeven van monsters van verschillende batches koekjes om te bepalen of een batch aanzienlijk anders smaakt.
Aan de andere kant wordt de Chi-Square-test gebruikt voor categorische gegevens. Het helpt ons te begrijpen of er een significant verband bestaat tussen twee categorische variabelen. Bestaat er bijvoorbeeld een verband tussen iemands favoriete muziekgenre en zijn/haar leeftijdsgroep? De Chi-Square-test helpt dergelijke vragen te beantwoorden.
14. De centrale limietstelling en het belang ervan in datawetenschap
De Centrale Limietstelling (CLT) is een fundamenteel statistisch principe dat bijna magisch aanvoelt. Het vertelt ons dat als je voldoende steekproeven uit een populatie neemt en hun gemiddelden berekent, deze gemiddelden een normale verdeling zullen vormen (de belcurve), ongeacht de oorspronkelijke verdeling van de populatie. Dit is ongelooflijk krachtig omdat het ons in staat stelt conclusies te trekken over populaties, zelfs als we hun exacte verspreiding niet kennen.
In de datawetenschap ondersteunt de CLT veel technieken, waardoor we tools kunnen gebruiken die zijn ontworpen voor normaal verdeelde gegevens, zelfs als onze gegevens in eerste instantie niet aan die criteria voldoen. Het is alsof je een universele adapter voor statistische methoden vindt, waardoor veel krachtige tools in meer situaties toepasbaar worden.
15. Afweging van bias en variantie
In voorspellende modellen en machine learning vooringenomenheid-variantie afweging is een cruciaal concept dat de spanning benadrukt tussen twee belangrijke soorten fouten die ervoor kunnen zorgen dat onze modellen misgaan. Bias verwijst naar fouten in te simplistische modellen die de onderliggende trends niet goed weergeven. Stel je voor dat je probeert een rechte lijn door een gebogen weg te trekken; je zult het doel missen. Omgekeerd leggen varianties van te complexe modellen ruis in de gegevens vast alsof het een echt patroon is, zoals het volgen van elke bocht en het inslaan van een hobbelig pad, denkend dat dit de weg vooruit is.
De kunst ligt in het balanceren van deze twee om de totale fout te minimaliseren en de goede plek te vinden waar uw model precies goed is: complex genoeg om de nauwkeurige patronen vast te leggen, maar eenvoudig genoeg om de willekeurige ruis te negeren. Het is net als het stemmen van een gitaar; het klinkt niet goed als het te strak of te los zit. De afweging tussen bias en variantie gaat over het vinden van de perfecte balans tussen deze twee. De afweging tussen bias en variantie is de essentie van het afstemmen van onze statistische modellen om hun best te doen bij het nauwkeurig voorspellen van uitkomsten.
Conclusie
Van statistische steekproeven tot de afweging tussen bias en variantie: deze principes zijn niet louter academische begrippen, maar essentiële hulpmiddelen voor inzichtelijke data-analyse. Ze rusten ambitieuze datawetenschappers uit met de vaardigheden om enorme hoeveelheden data om te zetten in bruikbare inzichten, waarbij ze de nadruk leggen op statistieken als de ruggengraat van datagestuurde besluitvorming en innovatie in het digitale tijdperk.
Hebben we enig basisstatistiekconcept gemist? Laat het ons weten in de commentaarsectie hieronder.
Ontdek onze end-to-end statistiekengids zodat datawetenschap meer weet over het onderwerp!
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

