Ik ben in 2017 overgestapt van development naar data engineering. Daarvoor had ik tien jaar gewerkt in desktop development, backend (voornamelijk Java), en een klein beetje frontend. Ondanks mijn sterke IT-ervaring was het in het begin niet eenvoudig om erachter te komen wat data-engineers doen, hoe ze verschillen van databasebeheerders, hoe ze verbonden zijn met data-analyse en wat ze met Big Data te maken hebben.
Het was de magie van de uitdrukking "Big Data" die bepaalde wat ik nu doe (dit link biedt een gevestigde definitie van Big Data met de triade "Volume, Variety, Velocity" + een informatieve video van Amazon AWS). Voor mij leek het Big Data-veld een uitdaging die ik moest aangaan.
Ik raakte meer geïnteresseerd in gedistribueerde systemen, schaalbare technologieën en clouds, en ging naar conferenties waar relevante Big Data-producten zoals Hadoop, Kafka, Spark, etc. werden geanalyseerd. Collega's die met Big Data werkten verschenen om me heen en ik overspoelde ze met vragen. Soms waren de antwoorden die ik kreeg niet helemaal duidelijk, wat mijn nieuwsgierigheid alleen maar aanwakkerde.

De eerste release van Hadoop, het eerste openbaar beschikbare platform voor het opslaan en verwerken van reeksen gegevens uit gedistribueerde bronnen, berekend in petabytes, vond plaats in 2006. Al snel begonnen bedrijven Big Data te beschouwen als iets dat in de praktijk toepasbaar was. In het komende decennium, de meeste zakelijke media noemde Big Data niets minder dan een 'revolutie' en een 'staatsgreep'.
Maar de afgelopen twee of drie jaar is de magische invloed van Big Data afgezwakt: data-engineering heeft dit gebied eigenlijk geabsorbeerd en gemeengoed gemaakt, althans onder IT-specialisten. Big Data is overal, en als bedrijfsgegevens vandaag niet Big zijn, worden ze morgen Big. Tegelijkertijd is de aandacht voor databeroepen alleen maar gegroeid en er is niet minder vraag naar dan bijvoorbeeld Java-ontwikkelaars. Bovendien verdienen data-engineers gemiddeld meer dan backend-ontwikkelaars (datawetenschappers worden nog hoger gewaardeerd, en we zullen later in dit artikel begrijpen waarom).
Vandaag zie ik ontwikkelaars en andere IT-specialisten om me heen die dezelfde vragen hebben over data engineering die ik 6-7 jaar geleden had. Hier heb ik geprobeerd de meest populaire te beantwoorden, en op een toegankelijke manier. Ik pretendeer niet inclusief te zijn, en ik begrijp heel goed dat andere mensen al vollediger en interessanter hebben geschreven over sommige aspecten van het beroep - daarom zijn er zoveel links in de tekst.
Ik hoop dat mijn antwoorden nuttig zullen zijn voor beginnende data-engineers en iedereen die geïnteresseerd is in data-engineering.
Een data engineer is iemand die data toegankelijk maakt voor de klant. Om dit te doen, begrijpt de data-engineer precies hoe de benodigde gegevens moeten worden verzameld en zet hij een proces op dat het volgende kan omvatten:
- gegevensverzameling: banktransacties, registraties van loyaliteitssystemen, geolocatie van klanten, sensormetingen in vliegtuigen, enz.;
- gegevens wissen van fouten en herhalingen — zorgen voor de vereiste gegevenskwaliteit;
- datatransformatie en -aggregatie;
- gegevens opslag;
- correcte en snelle levering op vraag van de klant.
Het sleutelconcept hier is een datawarehouse: we uploaden er gegevens naar, transformeren het daar en laden het van daaruit uit voor analyse. In de regel is de opslag relationeel, maar in tegenstelling tot transactionele databasebeheersystemen, wordt het gebruikt voor analytische belastingen (OLAP).
Wat betekent dit? Transactionele belasting wordt gekenmerkt door relatief kleine hoeveelheden geschreven gegevens en lezen, samen met een potentieel groot aantal gebruikers. Bij analytische belasting is de situatie het tegenovergestelde: er zijn grote hoeveelheden geschreven gegevens en lezen, samen met een beperkt aantal gebruikers. Dit is een van de nuances van het beroep.
Er zijn veel opties voor het modelleren van repositories, zoals klassiek, Kimball of Inmon-organisatie, of meer moderne methoden, zoals Gegevenskluis. Er zijn ook niet-strikt relationele opslagopties, zoals Data Lake of Huis aan het meer — voor hen moet u afzonderlijke pijplijnen bouwen voor het verzamelen van gegevens, en voor hun pre-vorming en laden in opslag.
De keuze van opslag, hulpmiddelen voor het werken met gegevens, gegevensverwerkingssnelheid en schaalmogelijkheden zijn allemaal de zorgen van een data-engineer. De gegevensbeheerder is meestal degene die ervoor zorgt dat de geconfigureerde pijplijn een maand, een jaar en langer zonder onderbrekingen werkt. Deze persoon lost problemen op en verbetert de productiviteit. De meeste data-engineers kunnen dit ook, maar idealiter is het niet hun verantwoordelijkheid.
Hoe de gegevens na verstrekking precies zullen worden gebruikt, zou idealiter ook niet de zorg van een data-engineer moeten zijn. Het belangrijkste is om de opslag aan te passen aan de dagelijkse belasting en het type gegevens.
Vergeet niet dat data-engineers data toegankelijk maken. Ze verzamelen gegevens uit verschillende bronnen, systematiseren het, verwerken het en zeggen: "Hier zijn de gegevens, wie heeft het nodig - haal het hier vandaan." Zo kunnen zakelijke gebruikers, zoals managers, de gegevens meenemen. Maar idealiter zou een data-analist eerst de data nemen.
De taak van een data-analist is het interpreteren en visualiseren van gegevens, om erachter te komen welke bedrijfswaarde kan worden geëxtraheerd. Gegevensanalisten gebruiken patronen in gegevens om zakelijke vragen te beantwoorden, prognoses te maken en aanbevelingen te doen. We kunnen zeggen dat data-analisten de zakelijke besluitvorming rechtstreeks beïnvloeden.
Dienovereenkomstig stellen data-analisten taken op voor de data-engineer, zoals waar de gegevens voor analyse kunnen worden opgehaald, wat moet worden opgeschoond en wat moet worden gecorrigeerd. Soms voert een data-engineer de primaire interpretatie van gegevens uit en bereidt een data-analist zijn of haar eigen gegevens voor. Maar vaak overlappen deze bevoegdheden elkaar niet. Desalniettemin begrijpt een hooggekwalificeerde data-analist ongestructureerde data, weet hoe hij complexe SQL-query's moet schrijven en schrijft een beetje code in R of Python.
Over het algemeen kan een data-engineer een beetje een data-analist zijn, en vice versa. Werkt de data-analist alleen met Excel-draaitabellen, dan heeft hij of zij niets met data-engineering te maken.
De focus van een BI-engineer ligt op rapportage. Voor grote klanten bepaalt de BI-engineer welke BI-tools hij gebruikt, zoals Tableau, Qlik, Power BI, Looker, Sisense, etc., en configureert deze. Dankzij een BI-engineer krijgen de bedrijfsleiders een visueel dashboard waarop realtime te zien is hoe het er in het bedrijf aan toe gaat: binnen 10 seconden is duidelijk waar de zwaktes van het bedrijf zitten. Als de manager wil, kan hij het rapport omzetten in een presentatie.
En wie configureert de levering van de benodigde gegevens aan het BI-systeem? Juist, een data engineer.
In kleine bedrijven met een kleine dataset – zonder platform of een basisplatform zoals MySQL of Oracle – configureert de BI-engineer de pijplijn echter onafhankelijk. Over het algemeen is een BI-engineer vanuit vaardigheidsoogpunt een mix tussen een data-engineer en een data-analist: deze persoon begrijpt de basis van data-integratie, verwerking en data-analyse en kan kennis in de praktijk toepassen.
Aan de andere kant zal bijna elke data engineer een dashboard bouwen in bijvoorbeeld Tableau, ook al heeft hij of zij niet genoeg ervaring om alle mogelijkheden van zelfs de meest gangbare BI-systemen te kennen. Bovendien heeft elk systeem een levenscyclus, inclusief BI-systemen: ze evolueren en moeten worden gecontroleerd en bijgewerkt. Een data engineer heeft hier meestal geen tijd voor, maar het monitoren en updaten van het systeem is een prioriteit voor een BI engineer.
Kortom, ze hebben praktisch niets met elkaar gemeen, behalve dat de data-engineer (nu krijg je een déja vu) een pijplijn met gegevens opzet die de datawetenschapper nodig heeft. De datawetenschapper heeft deze gegevens voornamelijk nodig voor het trainen van modellen met behulp van neurale netwerken en machine learning-algoritmen.
Modellen worden in het bedrijfsleven gebruikt voor prognoses en het maken van automatische reacties. Ze kunnen bijvoorbeeld een antwoord geven aan een beursvennootschap om Apple-aandelen te kopen of te verkopen.
Het onderwerp van een datawetenschapper omvat AI, ML en DL. Zelfs een senior data engineer komt zelden aan deze dingen toe in zijn of haar werk. Naast programmeervaardigheden moeten datawetenschappers ook beschikken over sterke wiskundige vaardigheden en kennis van statistiek.
Een data-engineer is dus een beetje een databeheerder, een data-analist en een BI-engineer. Een data-analist, een BI-engineer en een databeheerder kunnen ook een beetje een data-engineer zijn. En datawetenschappers zijn een apart universum: ze hebben een andere productiecyclus, een andere theoretische basis en andere kwalificatievereisten.
Ik adviseer beginnende data-ingenieurs om de theoretische basis - relationele algebra en gedistribueerd computergebruik - niet te verwaarlozen.
Beginners moeten uitzoeken wat ETL en ELT zijn, en wat de verschillenstaan tussen hen in, naast een andere volgorde van de woorden Extract, Transform en Load. Ze moeten de verschil tussen SQL en NoSQL. Ze moeten vertrouwd raken met de klassen van data-engineeringtaken en op het basisniveau ten minste één reguliere tool uit elke klas demonteren:
- gegevens opslag;
- gedistribueerde gegevensverwerking;
- orkestratie.
Ook is het handig om de levenscyclus van softwareontwikkeling: hoe requirements worden verzameld en gedocumenteerd, en hoe de software wordt ontwikkeld, getest en geïmplementeerd. Vooruitkijkend schrijven veel data-engineers code en schrijven autotests, met andere woorden, ze redden het zonder testers.
Data-engineers communiceren vrij veel rechtstreeks met klanten, waarbij bedrijfsanalisten worden omzeild. Dit is wat er gebeurt in mijn huidige project: de data-engineers vertalen zelfstandig taken van de taal van het bedrijfsleven naar de taal van de technologie. Dit betekent dat er vanaf het begin een gemeenschappelijk begrip moet zijn van welke gegevens bedrijven nodig hebben en hoe banken, medicijnen, detailhandel, telecom, verzekeringsmaatschappijen en de toeristische sector deze gebruiken. Je redt het niet zonder geavanceerde soft skills en goed gesproken Engels. Je hebt een Engels niveau nodig dat niet lager is dan Intermediate.
Om te beginnen kun je de Engelstalige blogs lezen van de makers van technologieën en tools voor data engineering. In dit artikel leiden de meeste links gewoon naar blogs zoals MongoDB, Qlik, AWS, etc.
Als je al een platform hebt gekozen dat je onder de knie gaat krijgen, is het logisch om naar het trainingsmateriaal van de leverancier te kijken. Zulke reguliere, zelfvoorzienende platforms als Sneeuwvlok en Databricks hebben tal van hoogwaardige materialen van verschillende niveaus van complexiteit voor beginners, middenpersonen en architecten. Ze benadrukken natuurlijk wel hun eigen producten.
Data-engineers hebben hun eigen bijbel — DMBOK (Gegevensbeheer Body of Knowledge). Gestandaardiseerde gegevensbeheermethoden en best practices worden hier beschreven.
Dit serieuze en misschien wel saaie boek is bedoeld voor senioren en hoger. Het is handig voor beginners om als naslagwerk te gebruiken. DMBOK zal gebieden uitlichten die het ontdekken waard zijn - daarna kun je naar de leveranciersblogs gaan, waar alles op een leukere en toegankelijkere manier wordt beschreven.
Veel data-engineers weten hoe ze code moeten schrijven. De overgrote meerderheid van de klanten verwacht dat de data-engineer SQL en een van deze talen perfect kent, in ieder geval op scriptniveau: Python, Scala, Java, JavaScript, C#.
Sommigen van ons gebruiken low-code platforms om een datapijplijn samen te stellen uit kant-en-klare tools (tools voor gegevensintegratie). In dit geval worden ze soms ETL-ontwikkelaars, Data Integration Engineers of iets anders genoemd. In wezen zijn deze mensen ook data-engineers, alleen met een specialisatie in data-integratie.
Ze kennen sommige nuances van het beroep misschien niet. Als u bijvoorbeeld de productiviteit met 10 keer moet verhogen, zullen er zeker problemen zijn als u geen specifieke tool voor schaalvergroting geeft en zegt: "Doe dit."
Kortom, je kunt een data-engineer zijn, ook al kun je maar op een minimaal niveau programmeren. Tegelijkertijd kan een data-engineer die alleen C#-scripts kent, nog steeds een hoger niveau en hoger bereiken, net als een QA-engineer die niet weet hoe hij moet programmeren (in tegenstelling tot een QAA).
Ik kan hier alleen praten over de ervaringen van mijn persoonlijke vrienden en collega's, die niet noodzakelijkerwijs de situatie in het algemeen weerspiegelen. Ik heb maar zelden mensen ontmoet die het vak helemaal "from scratch" zijn begonnen - de meesten waren ontwikkelaars of dataspecialisten. Verder ken ik geen gevallen waarin DevOps-engineers zijn gemigreerd naar data-engineering. Misschien houden ze gemiddeld meer van hun werk dan andere beroepen in de IT, en zijn ze tegelijkertijd ongelooflijk in trek.
Veel data-engineers zijn begonnen als databasebeheerders of data-analisten. Ze kenden SQL, BI al en begrepen hoe ze met data moesten omgaan. Met zo'n achtergrond kun je de taken van een data engineer op een aantal vlakken in een half jaar volledig oplossen.
Ik kan ervan uitgaan dat het makkelijker en sneller is om data engineer te worden voor een backend developer die Java en/of Python kent. Als je Scala, Airflow of Spark kent, zit je echt goed.
Bijna alle bedrijven hebben databases waarmee ze van tijd tot tijd werken: ze uploaden daar iets, laden iets anders uit en gebruiken de database op de een of andere manier, afhankelijk van hun behoeften. Zo schrijft een Python-ontwikkelaar een platform, analyseren een business analist en een marketeer data, en schakelen soms een systeembeheerder in. Als duidelijk wordt dat er een systematische aanpak nodig is en er genoeg werk is voor één heel mens, dan wordt een data engineer ingeschakeld.
Ze komen naar ons toe en zeggen: “We hebben onze eigen database, maar die kan deze belasting niet aan. We willen een opslagoplossing waar we alles kunnen plaatsen en grote, zware verzoeken kunnen doen” (er zijn trouwens ook omgekeerde gevallen: er is niet genoeg opslagruimte en u moet uitzoeken wat u ermee moet doen) .
Oké, we begrijpen dat de gegevens naar de interne opslag moeten worden overgebracht en beschikbaar moeten worden gemaakt. Om de toegestane belasting hoger te maken, moet u schalen. We verduidelijken de nuances: moeten we de gegevens valideren of komen ze schoon bij ons binnen? Hoe vaak moeten we gegevens bijwerken/verwerken - is het genoeg om dit één keer per dag te doen, of is het proces continu? Er kunnen tientallen vergelijkbare vereisten zijn.
Nadat we de vereisten hebben verzameld, gaan we over tot het ontwerp van het systeem. We laten zien hoe we het probleem technologisch gaan oplossen, met welke stack. Soms is de klant niet zeker van zijn beslissing — in dit geval laten we alternatieve opties zien en beschrijven we de voor- en nadelen van elk. Het komt voor dat de klant klaar is om verder te gaan dan het toegewezen budget als hij een optie ziet die nuttiger is voor het bedrijfsleven.
We moeten begrijpelijk zijn voor het bedrijfsleven en de taal spreken. Als de klant technologisch onderlegd is en het heel goed begrijpt hoe Data Warehouse verschilt van Data Lake, dan geven we meer technische details. Zo niet, dan richten we ons op fundamentele zaken: hoeveel het kost, hoe veilig de opslag is en hoe gemakkelijk het is om over te stappen naar een oplossing van een andere leverancier.
We zullen zeker praten over hoe we zullen handelen in noodsituaties en hoe lang zo'n reactie zal duren.
Zoals in bijna elk beroep, kan groei zowel expansief (uitgroeiend) als binnenin (grotere diepte) zijn. Je kunt één stapel zo goed beheersen dat je als een halfgod wordt gezien, op een buiging gaat en vraagt om iets op te zetten, terwijl niemand anders het kan bedenken. Je kunt ook je managementvaardigheden oppompen, teamleider worden, enz.
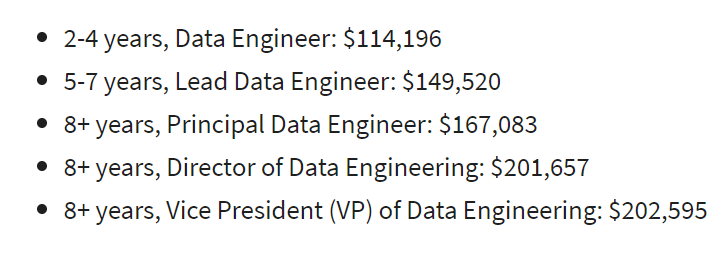
Loopbaantraject van een data-engineer in de VS, volgens Glassdoor
De manier waarop een data engineer zich ontwikkelt, samen met het eisenpakket dat aan de data engineer wordt gesteld, verschilt van bedrijf tot bedrijf. In mijn bedrijf ziet de carrièreladder er zo uit: Data Engineer ? Teamleider Data Engineer? Gegevens technisch architect? Architect voor gegevensoplossingen (DSA).
Gegevens ingenieur. Kent de basisprincipes van datamanagement: datamodellering, ELT/ETL, datakwaliteit, datawarehouse/lake-modellen, gedistribueerde systemen. Werkt vol vertrouwen met ten minste één stack: AWS, Azure, Snowflake, Apache Hadoop, enz. SQL is vereist, plus ten minste één taal: Scala, Python, Java, C#.
Teamleider Data Engineer. Deze persoon kent de basis van datamanagement en engineering op hoog niveau. Sterke communicatieve en probleemoplossende vaardigheden. Weet projecten, leveringen en wijzigingen te managen.
Gegevens technisch architect. In de regel is dit een persoon die een DSA-functie ambieert, maar het ontbreekt aan ervaring en technologische eruditie. Hij of zij kent minimaal één stack goed en kan onder begeleiding van de DSA de technische details van de oplossingsimplementatie uitwerken.
Architect voor gegevensoplossingen. Expert in datamanagement en data-engineering. Deze persoon kent de huidige technologieën van het werken met data op architectenniveau en kan nieuwe technologieën snel eigen maken. Deze persoon heeft vaardigheden op het gebied van leiderschap, project- en verandermanagement, plus technisch management, zoals het beheer van teams en technische afdelingen.
Grote IT-bedrijven creëren vaak competentiecentra voor de ontwikkeling van harde en zachte vaardigheden. Zo werken er nu bijna 200 dataspecialisten in DataArt, waarvan meerdere mensen in het Centre of Excellence zitten (waaronder ikzelf). Ons belangrijkste doel is om collega's te helpen bij het kiezen van de richting waarin ze professioneel willen groeien en hen te helpen nieuwe technologieën onder de knie te krijgen. We geven dataspecialisten de kans om hun volledige potentieel te bereiken als mentor, spreker, technisch expert en klantenservicespecialist.
Het lijkt mij dat er steeds meer aandacht komt voor datamanagement, of Gegevensbeheer. Voorheen kon een bedrijf gegevens dumpen in Data Lakes, die uiteindelijk veranderden in "moerassen van gegevens": sommige onbegrijpelijke gegevens, waarvan het moeilijk is om erachter te komen wie wat heeft geplaatst, en waarom. Nu, op architectuurniveau, beschouwt dit bedrijf gegevensbeheer vanuit verschillende gezichtspunten en beschrijft het hoe te zorgen Datakwaliteit, en hoe om te gaan met metadata, masterdata en referentiedata etc. Dit is veel moeilijker dan bijvoorbeeld het bouwen van een ETL-pijplijn.
Een van de trends is de overgang naar cloud-managed systemen. Dat wil zeggen, we zetten geen systeem thuis in, maar kopen een kant-en-klaar systeem, geassembleerd in de cloud. We kunnen een pool van verzoeken hebben voor ten minste 10 machines, maar we hoeven helemaal niet na te denken over hoe alles daar wordt gedistribueerd en geschaald.
Zo'n serverloze trend is heel belangrijk voor data-engineering. Big Data verliest daardoor zijn magische charme omdat Big Data vooral draait om horizontaal schalen. Dankzij de clouds verschuift de focus van data-engineers van schaalvergroting naar databeheer. Conceptueel gezien is de juistere vraag nu niet hoe je met big data moet werken, maar hoe je data in het algemeen moet beheren.
Het aantal technologieën is opgeblazen en er zijn steeds meer analogen van verschillende tools. Het is bijna onmogelijk om een specialist te vinden met een 100% match op de technische stack. Dat betekent bijvoorbeeld dat een data engineer van elk niveau in de praktijk de nodige kennis moet opdoen en dat is normaal.
Ilja Mosjkov is Senior Data Engineer en lid van DataArt's Data Center of Excellence

