작성자 별 이미지
ChatGPT의 급속한 발전을 목격하고 있습니다. 오픈 소스 대안, 그러나 아무도 멀티모달을 제공하는 GPT-4 대안에 대해 작업하지 않습니다. GPT-4는 이미지와 텍스트를 입력으로 받아들이고 텍스트 응답을 출력하는 강력한 고급 멀티모달 모델입니다. 복잡한 문제를 더 정확하게 풀고 실수로부터 배울 수 있습니다.
이 게시물에서는 OpenAI의 GPT-4에 대한 오픈 소스 대안인 MiniGPT-4에 대해 알아보겠습니다. OpenAI의 GPT-XNUMX는 경량이면서 시각적 및 텍스트 컨텍스트를 모두 이해할 수 있습니다.
GPT-4와 유사하게 MiniGPT-4는 자세한 이미지 설명 생성을 표시하고 이미지를 사용하여 스토리를 작성하고 손으로 그린 사용자 인터페이스를 사용하여 웹 사이트를 만들 수 있습니다. 보다 발전된 대규모 언어 모델(LLM)을 활용하여 이를 달성합니다.
데모를 통해 직접 경험할 수 있습니다. MiniGPT-4 – Vision-CAIR의 안면 공간.
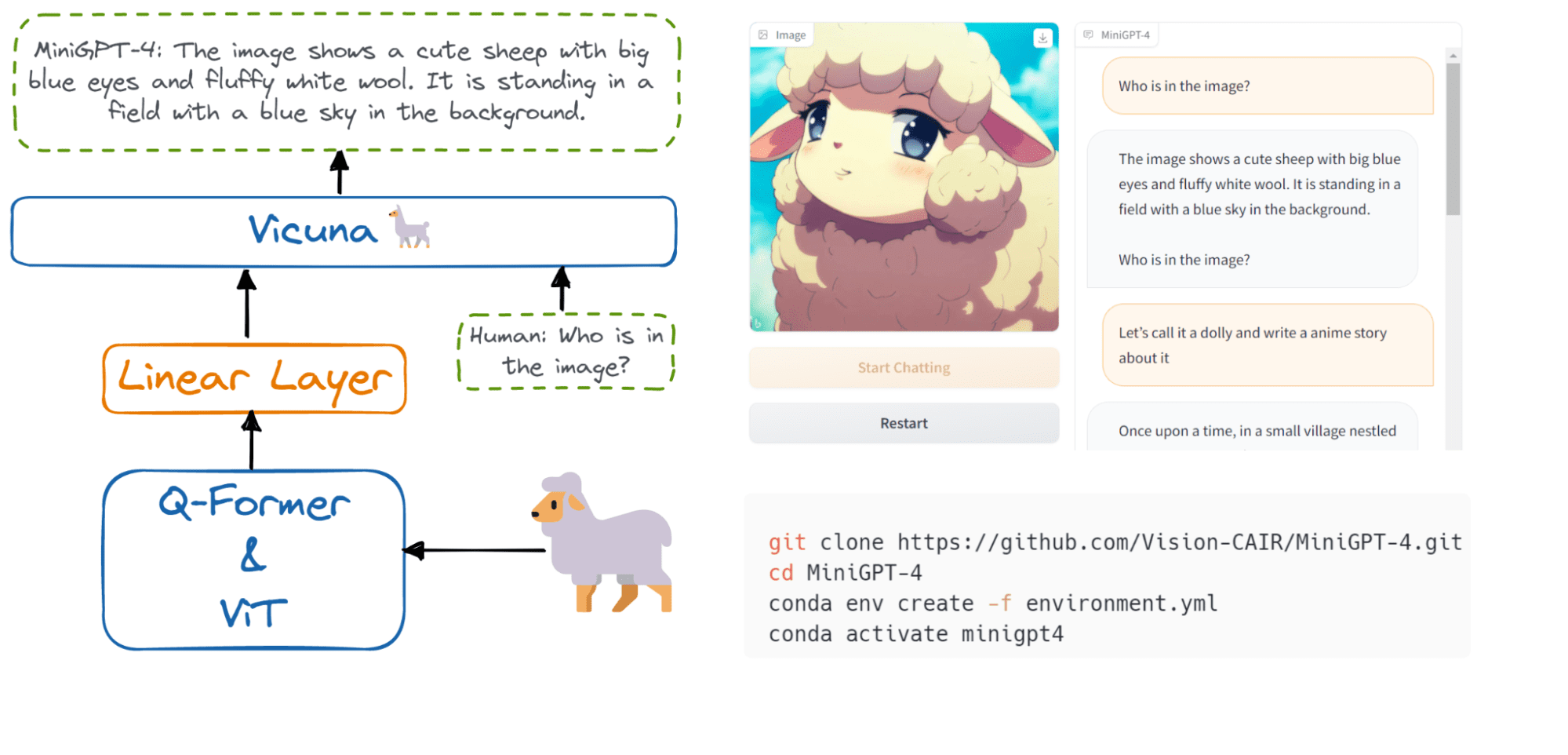
작성자 이미지 | MiniGPT-4 데모
의 저자 MiniGPT-4: 고급 대형 언어 모델로 시각 언어 이해 향상 원시 이미지-텍스트 쌍에 대한 사전 교육은 반복 및 조각난 문장을 포함하여 일관성이 부족한 좋지 않은 결과를 생성할 수 있음을 발견했습니다. 이 문제를 해결하기 위해 그들은 고품질의 잘 정렬된 데이터 세트를 선별하고 대화형 템플릿을 사용하여 모델을 미세 조정했습니다.
MiniGPT-4 모델은 약 5만 개의 정렬된 이미지-텍스트 쌍을 활용하는 프로젝션 레이어만 훈련했기 때문에 계산 효율성이 매우 높습니다.
MiniGPT-4는 단 하나의 프로젝션 레이어를 사용하여 Vicuna라는 고정된 LLM과 고정된 시각적 인코더를 정렬합니다. 시각적 인코더는 단일 선형 프로젝션 계층을 통해 고급 Vicuna 대규모 언어 모델에 연결된 사전 훈련된 ViT 및 Q-Former 모델로 구성됩니다.
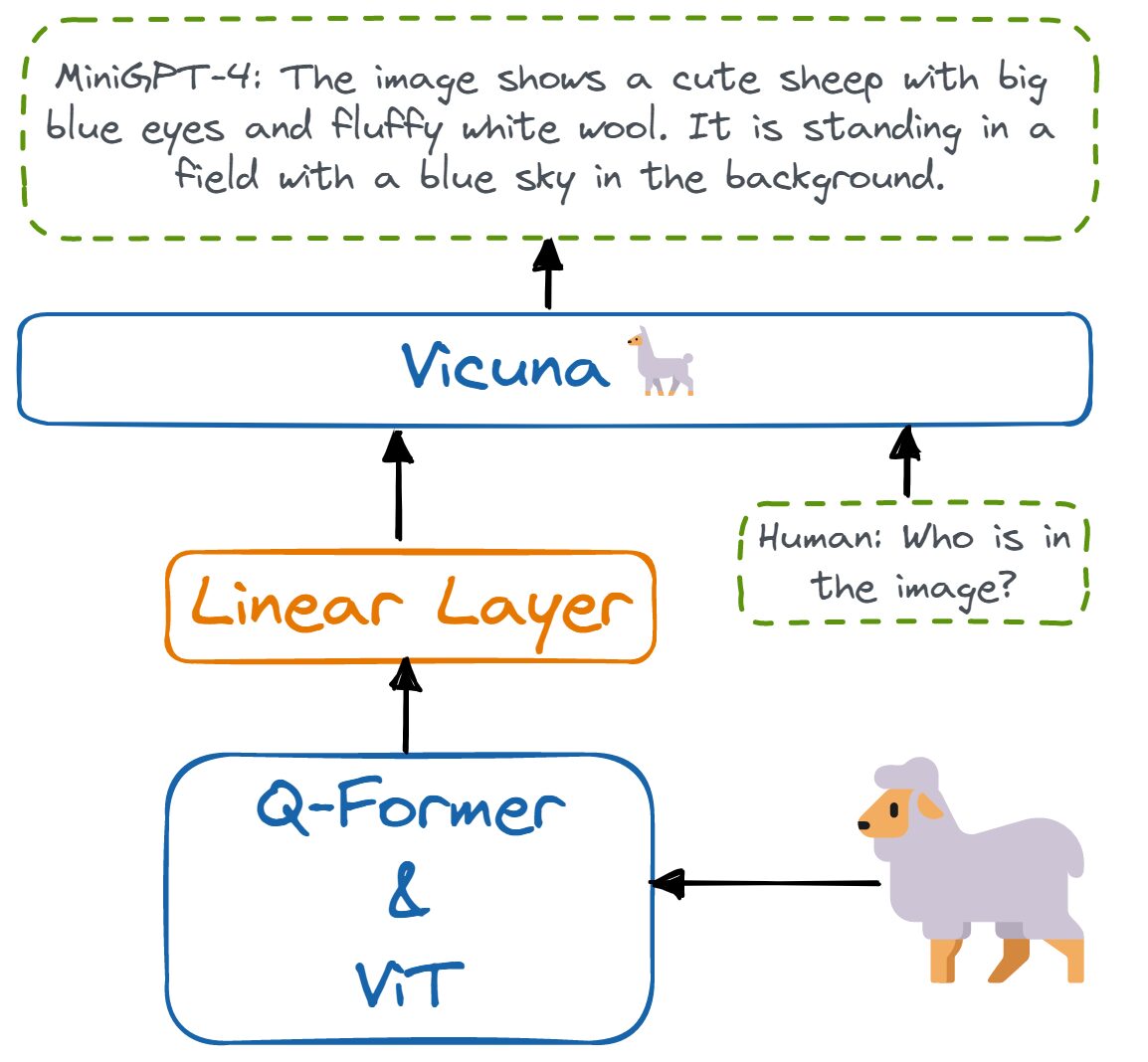
작성자 이미지 | MiniGPT-4의 아키텍처.
MiniGPT-4는 Vicuna와 시각적 기능을 정렬하기 위해 선형 계층을 훈련하기만 하면 됩니다. 따라서 가볍고 계산 리소스가 덜 필요하며 GPT-4와 유사한 결과를 생성합니다.
공식 결과를 보면 miniigpt-4.github.io, 작성자가 손으로 그린 UI를 업로드하고 HTML/JS 웹 사이트를 작성하도록 요청하여 웹 사이트를 만든 것을 볼 수 있습니다. MiniGPT-4는 컨텍스트를 이해하고 HTML, CSS 및 JS 코드를 생성했습니다. 놀랍습니다.
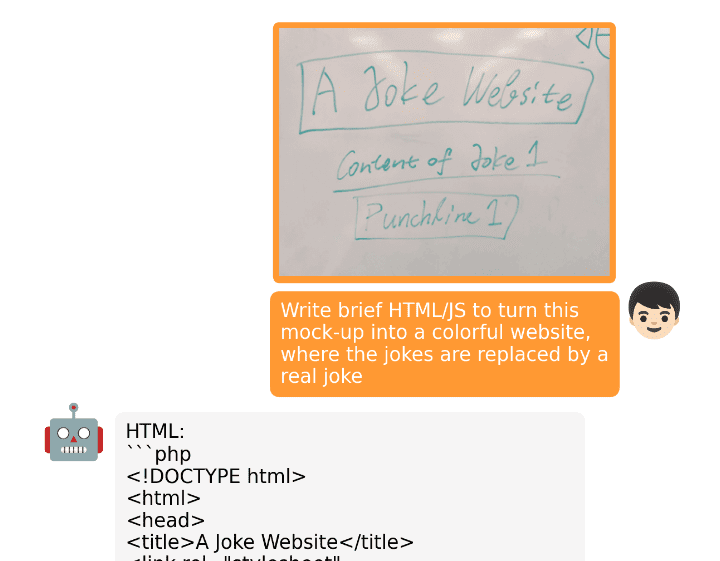

이미지 출처 : miniigpt-4.github.io
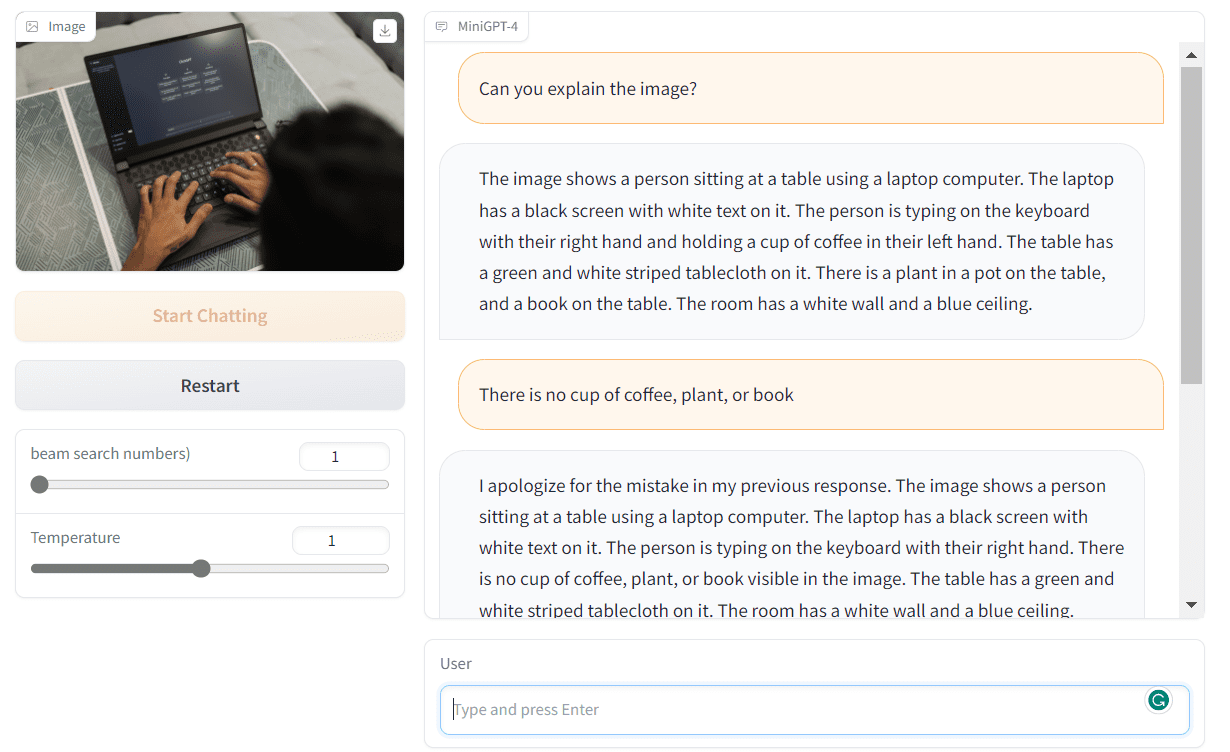
또한 모델을 사용하여 음식 이미지 제공, 제품 광고 작성, 복잡한 이미지 설명, 그림 설명 등을 통해 레시피를 생성하는 방법을 보여주었습니다.
다음으로 이동하여 직접 시도해 봅시다. 미니GPT-4 데모. 보시다시피 저는 Bing AI가 생성한 이미지를 제공하고 MiniGPT-4에게 이를 사용하여 스토리를 작성하도록 요청했습니다. 결과는 놀랍습니다.
이야기는 일관성이 있습니다.
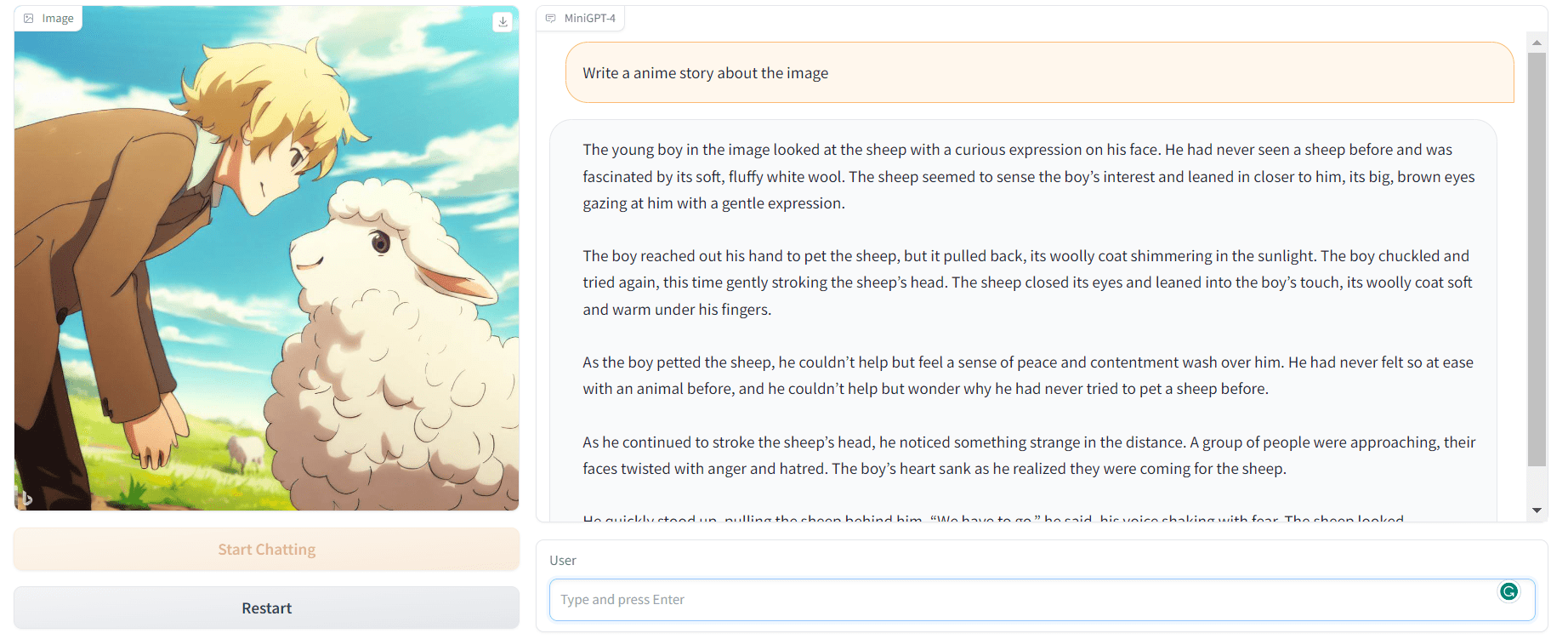
작성자 이미지 | MiniGPT-4 데모
더 알고 싶어서 계속 써달라고 했더니 AI 챗봇처럼 계속 줄거리를 써주더라고요.
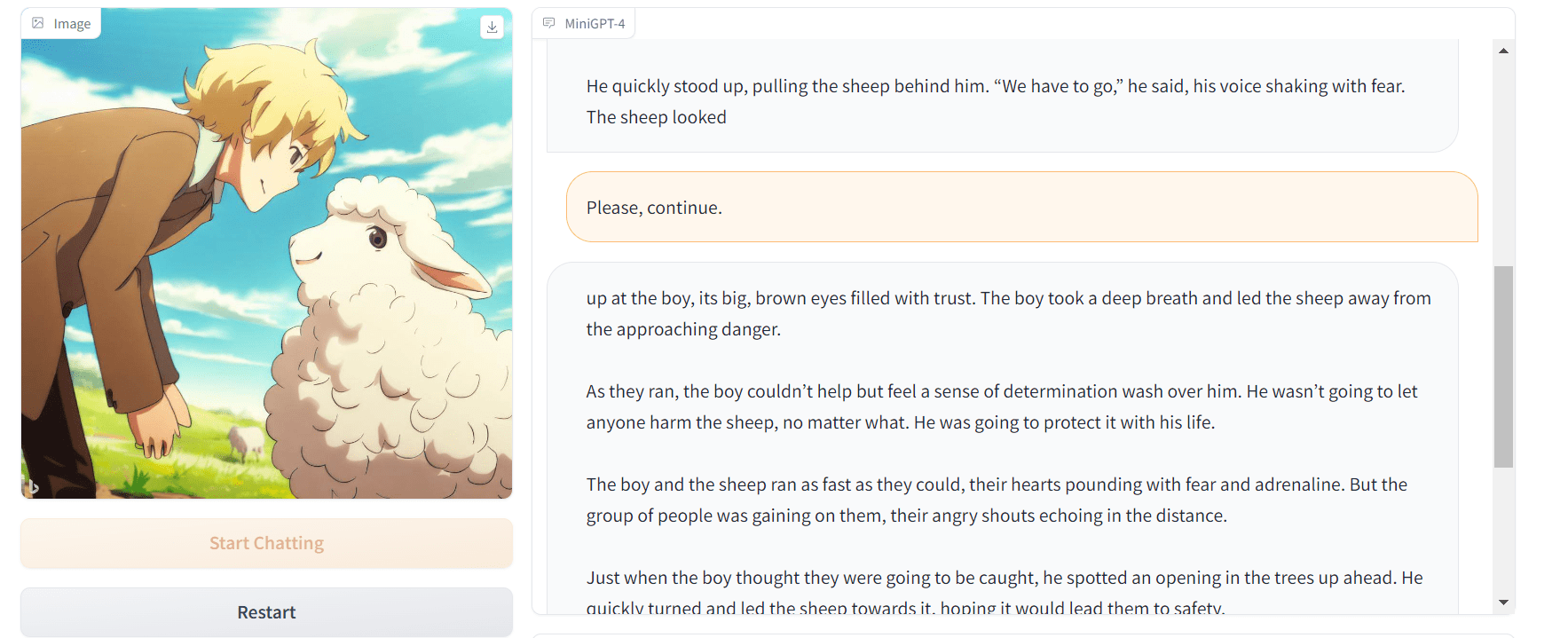
작성자 이미지 | MiniGPT-4 데모
두 번째 예에서는 이미지 디자인을 개선하는 데 도움을 요청한 다음 이미지를 사용하여 블로그용 자막을 생성하도록 요청했습니다.
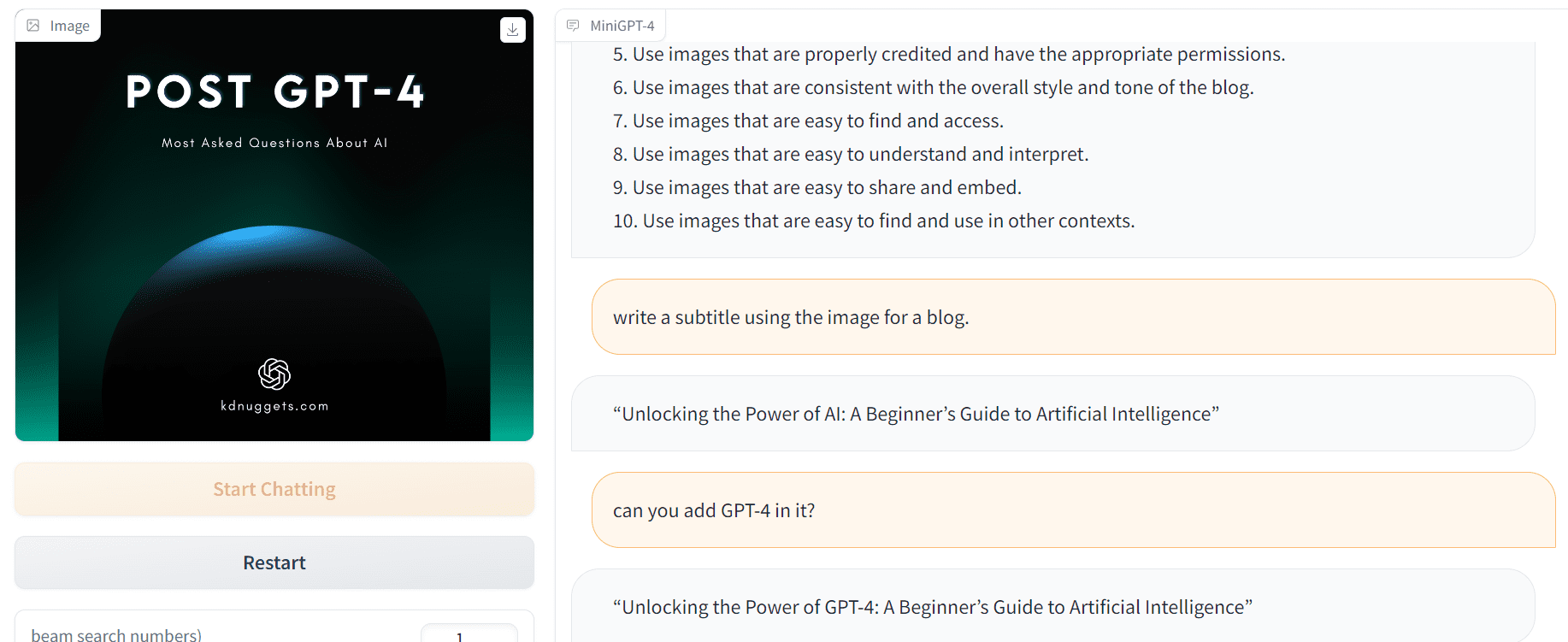
작성자 이미지 | MiniGPT-4 데모
MiniGPT-4는 놀랍습니다. 실수로부터 배우고 고품질 응답을 생성합니다.
MiniGPT-4에는 많은 고급 비전 언어 기능이 있지만 여전히 몇 가지 제한 사항에 직면해 있습니다.
- 현재 고급 GPU를 사용해도 모델 추론이 느려 결과가 느려질 수 있습니다.
- 이 모델은 LLM을 기반으로 하므로 신뢰할 수 없는 추론 능력과 존재하지 않는 지식을 환각하는 것과 같은 한계를 물려받습니다.
- 이 모델은 시각적 인식이 제한되어 있으며 이미지의 자세한 텍스트 정보를 인식하는 데 어려움을 겪을 수 있습니다.
이 프로젝트에는 소스 코드의 교육, 미세 조정 및 추론이 함께 제공됩니다. 또한 공개적으로 사용 가능한 모델 가중치, 데이터 세트, 연구 논문, 데모 비디오 및 Hugging Face 데모 링크가 포함되어 있습니다.
해킹을 시작하거나 데이터 세트에서 모델 미세 조정을 시작하거나 공식 페이지에서 공식 데모의 다양한 인스턴스를 통해 모델을 경험할 수 있습니다.
모델의 첫 번째 버전입니다. 앞으로 더욱 개선된 버전을 만나보실 수 있으니 계속 지켜봐 주시기 바랍니다.
아비드 알리 아완 (@1abidaliawan)은 기계 학습 모델 구축을 좋아하는 공인 데이터 과학자 전문가입니다. 현재 그는 콘텐츠 제작에 집중하고 있으며 머신 러닝 및 데이터 과학 기술에 대한 기술 블로그를 작성하고 있습니다. Abid는 기술 관리 석사 학위와 통신 공학 학사 학위를 보유하고 있습니다. 그의 비전은 정신 질환으로 고생하는 학생들을 위해 그래프 신경망을 사용하여 AI 제품을 만드는 것입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 미래 만들기 w Adryenn Ashley. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/04/minigpt4-lightweight-alternative-gpt4-enhanced-visionlanguage-understanding.html?utm_source=rss&utm_medium=rss&utm_campaign=minigpt-4-a-lightweight-alternative-to-gpt-4-for-enhanced-vision-language-understanding

