이 기사는 데이터 과학 Blogathon.
SQL로
XNUMX대였을 때 나는 상점에서 살 물건을 종이에 나열했는데, 여기서는 데이터라고 합니다. 오늘날 우리는 미디어를 통해 많은 데이터를 얻습니다. 방대한 양의 데이터를 저장합니까? 그 모든 데이터를 책에 기록하는 것은 불가능합니다. 책을 사용하여 해당 데이터를 저장한다고 가정해 보겠습니다. 그것은 시간적인 조건이나 불행입니다. 따라서 데이터를 저장하고 쉽게 검색하거나 업데이트할 수 있는 시스템이 필요합니다.
SQL 서버 및 데이터베이스
데이터베이스는 데이터의 저장소입니다. 데이터 추가, 수정 및 쿼리 기능을 제공합니다. DBMS(데이터베이스 관리 시스템)은 데이터베이스를 관리하는 소프트웨어입니다. DBMS의 한 유형은 RDBMS입니다. 관계형 데이터베이스 관리 시스템. 데이터 액세스, 구성 및 저장을 제어하는 소프트웨어 도구 세트입니다. 특히 은행과 의료 기관은 이 RDBMS를 사용합니다. RDBMS의 예로는 MySQL, Oracle Database, IBM DB2, DB2 Express 및 Cache가 있습니다.
모든 데이터 모델은 데이터베이스와 유사합니다. 가장 많이 사용되는 데이터 모델은 관계형 모델입니다. 데이터 독립성을 허용합니다. 여기서 데이터는 테이블에 저장됩니다. 논리적 데이터 독립성, 물리적 데이터 독립성 및 물리적 스토리지 독립성을 제공합니다. 엔터티-관계 데이터 모델은 관계형 데이터 모델의 대안입니다.
엔티티 관계 데이터 모델: 여기서 엔터티는 다른 엔터티와 독립적으로 존재하는 개체입니다. 엔터티에는 엔터티를 설명하는 데이터 요소인 속성이 있습니다.
예를 들어, 책은 실체입니다. 에디션, 연도, 가격, 제목 등이 속성입니다. 엔터티는 테이블이 되고 해당 속성은 열입니다.
그림 1. 엔터티-관계 데이터 모델
엔티티를 테이블에 매핑: 데이터베이스 설계를 위한 기본 토대 ERD(Entity-Relationship Diagram)로 시작하여 ERD를 테이블에 매핑합니다. 여기서 엔터티는 테이블이 되고 속성은 엔터티와 속성을 구분하는 열입니다.
예를 들어,

관계형 모델의 빌딩 블록은 집합과 관계입니다.
관계는 두 부분으로 구성됩니다.
1) 관계형 스키마
2) 관계형 인스턴스
관계형 스키마 다음을 지정합니다: 관계 스키마의 이름, 각 속성의 이름 및 유형.
관계 인스턴스: 행과 열로 구성된 테이블입니다. 여기서 열은 속성이고 행은 튜플입니다.
차수 = 속성의 수
카디널리티 = 튜플의 수
관계형 모델 제약 조건
두 관계 사이에 데이터 무결성을 설정하는 메커니즘이 있습니다. 관계형 데이터베이스에서는 참조. 관계형 테이블의 기본 키는 테이블의 각 행을 고유하게 식별합니다. 외래 키는 다른 테이블의 기본 키를 참조하는 열 집합입니다. 기본 키를 포함하는 테이블은 하나 이상의 외래 키와 관련됩니다. 종속 테이블은 하나 이상의 외래 키로 구성됩니다.
비즈니스에서 데이터는 종종 특정 제한 사항을 준수해야 합니다. 제약. 제약 조건은 비즈니스 규칙을 구현하는 데 도움이 됩니다.
다음은 XNUMX가지 제약 조건입니다.
1. 엔티티 무결성 제약: 기본 키는 각 행 또는 튜플을 식별하는 고유한 값입니다. 기본 키에 참여하는 속성은 null 값을 허용하지 않아야 합니다.
예를 들어, BOOK_ID는 고유해야 하며 아래 표에서 null 값이 아니어야 하는 기본 키입니다.
| BOOK_ID | BOOK_NAME | BOOK_PRICE |
| B101 | 해리 포터 | 1200.00 |
| B102 | 나의 여행 | 360.00 |
| B103 | 작은 꽃 | 950.00 |
2. 참조 무결성에 대한 제약: 테이블 간의 관계를 정의하고 유효한 상태를 유지합니다. 데이터의 유효성은 기본 키와 외래 키의 조합을 사용하여 적용됩니다.
럭셔리

3. 의미 무결성 제약: 데이터의 정확성과 관련이 있습니다.
예를 들어, 모든 열은 아래 표에서 @, *, % 등과 같은 가비지 값을 포함하지 않아야 합니다.
| BOOK_ID | BOOK_NAME | BOOK_PRICE |
| B101 | 해리 포터 | 1200.00 |
| B102 | 나의 여행 | 360.00 |
| B103 | 작은 꽃 | 950.00 |
4. 도메인 제약: 주어진 속성에 유효한 값을 허용합니다.
예를 들어, 아래 표에서 BOOK_NAME은 문자여야 하고 BOOK_PRICE는 숫자여야 합니다.
| BOOK_ID | BOOK_NAME | BOOK_PRICE |
| B101 | 해리 포터 | 1200.00 |
| B102 | 나의 여행 | 360.00 |
| B103 | 작은 꽃 | 950.00 |
5. 널 제약 조건: 속성 값은 null일 수 없습니다.
예를 들어, BOOK_NAME은 아래 표에서 null이 아니어야 합니다.
| BOOK_ID | BOOK_NAME | BOOK_PRICE |
| B101 | 해리 포터 | 1200.00 |
| B102 | 나의 여행 | 360.00 |
| B103 | 작은 꽃 | 950.00 |
6. 제약 조건 확인: 조건에 따라 테이블에 삽입(또는 업데이트)된 데이터 값을 확인하는 데 도움이 되는 규칙 또는 규칙 집합입니다.
예를 들어, BOOK_PRICE는 아래 표에서 음수 값이 아니어야 합니다.
| BOOK_ID | BOOK_NAME | BOOK_PRICE |
| B101 | 해리 포터 | 1200.00 |
| B102 | 나의 여행 | 360.00 |
| B103 | 작은 꽃 | 950.00 |
SQL 문의 유형
SQL 문, 즉 DDL 및 DML.
1. DDL(데이터 정의 언어): 이러한 문은 테이블과 같은 데이터베이스 개체를 생성, 수정 또는 삭제하는 데 사용됩니다. 예를 들면 생성, 변경, 자르기 및 삭제가 있습니다.
나. 만들다: 이 문은 테이블을 만들고 해당 열을 정의하는 데 사용됩니다. SQL에서 사용하는 기본 데이터 유형은 char, varchar, number, date, clob입니다.
구문 :
테이블 생성
(column_name_1 데이터 유형 optional_parameters, column_ name_2 데이터 유형, ……………., 컬럼 name_n 데이터 유형) 암호: 테이블 생성(PRODID 번호(4) 기본 키, PRODNAME varchar(10) not null, 수량 번호(3) 확인(수량 > 0), 설명 varchar(20));출력:

ii. 바꾸다: 이 문은 열 추가 및 삭제, 데이터 유형 수정을 포함하여 테이블을 변경하는 데 사용됩니다.구문 : 변경 tableadd column_name 데이터 유형;암호:
테이블 제품 추가 MODEL_NO varchar(10) not null;출력:

iii. 자르기: 이 문은 테이블 자체가 아닌 테이블의 데이터를 삭제하는 데 사용됩니다.
구문 : 테이블 자르기; 암호: 테이블 자르기 테스트; iv. 하락: 이 문은 테이블 자체를 삭제하는 데 사용됩니다.구문 : 드롭 테이블;암호: 드롭 테이블 테스트;
2. DML(데이터 조작 언어): 이 문은 테이블의 데이터를 수정하는 데 사용됩니다. DML의 예는 생성, 읽기, 업데이트 및 삭제입니다.나. 문 삽입: 테이블을 데이터로 채웁니다. 데이터를 읽고 수정하는 데 사용되는 데이터 조작 언어 문입니다.구문 : () 값에 삽입 ();
암호:
제품(PRODID, PRODNAME, QTY_ AVAILABLE, DESCRIPTION) 값에 삽입(1002, '노트북', 23, 'Dell')
출력:

ii. Select 문 및 where 절: 데이터를 읽고 수정하는 데 사용되는 데이터 조작 언어입니다.
구문 : *에서 선택암호: emp에서 *를 선택하십시오.출력:

iii. 업데이트 문: 데이터를 읽고 수정하는 데 사용되는 데이터 조작 언어 문입니다.구문 : 업데이트 세트 [[열 이름]=[값]] 여기서암호: emp 세트 sal=sal+200, comm=100 업데이트 empno = 7369;출력:

iv. 문 삭제: 데이터를 읽고 수정하는 데 사용되는 데이터 조작 언어입니다. 구문 : 어디에서 삭제암호: 테스트에서 *를 선택하십시오.출력:

암호: empno=7934인 테스트에서 삭제합니다.출력:

그룹 기능 및 그룹화1. 그룹 기능: 5개의 그룹 기능이 있습니다. 그들은 합계, 최대, 최소, 평균 및 개수입니다.
- sum: 총 값을 반환합니다.
- max: 최대값을 반환합니다.
- min: 최소값을 반환합니다.
- avg: 평균값을 반환합니다.
- count: 레코드 수를 반환합니다.
암호:
emp에서 max(SAL), min(SAL), sum(SAL)을 선택합니다. 출력:
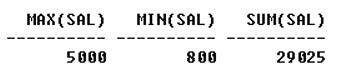
그룹 기능에 이름을 지정할 수 있습니다.암호: emp에서 max(SAL)를 "high"로, min(SAL)을 "low"로, sum(SAL)을 "total"로 선택합니다.출력:

2. 그룹화: 하나 이상의 열을 기준으로 집계하여 집계를 계산하는 프로세스입니다. 그룹화는 'group by' 절을 사용하여 생성됩니다. 구문 : 선택 , , ..., [그룹 기능] by group by , ..,암호: DEPTNO로 emp 그룹에서 DEPTNO, sum(SAL)을 선택합니다.출력:
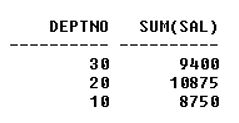
3. have, where 절 및 순서: 'have' 그룹화된 데이터를 필터링하는 데 사용되며 '어디' 그룹화되지 않은 데이터를 필터링하는 데 사용됩니다. '어디' 전에 사용해야합니다 그룹화 절 및 데 후에 사용해야합니다 그룹화 절. '주문' 구문의 끝에 사용됩니다.
구문 : 정렬 기준으로 그룹화에서 [열 이름]을 선택하십시오.암호: emp에서 job, max(sal)를 선택합니다. 여기서 deptno 30은 max(sal)>1500 order by 2인 작업별로 그룹화합니다.출력:
결론
Id
- 방법 지도 엔티티 및 속성 으로 테이블.
- 우리는 보았다 관계형 모델 및 그 제약 테이블에 데이터를 추가하기 위한 규칙입니다.
- 또한 다음을 사용하여 스키마에서 필요한 변경을 수행하는 방법을 배웠습니다. DDL 진술 및 DML s
- 데이터 분석을 위해.
이 기사가 유용했기를 바랍니다. Python, R, Scala 및 SAS와 같은 여러 프로그래밍 언어는 SQL 구문을 사용합니다. Data Analytics는 분석에 SQL을 사용합니다. 기계 학습 알고리즘에서도 SQL을 사용할 수 있습니다. 내 다음 기사에서 이것을 볼 수 있기를 바랍니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.

