개요
정밀성과 신뢰성에 대한 끊임없는 탐구 인공 지능 (AI)는 판도를 바꾸는 혁신을 가져왔습니다. 이러한 전략은 생성 모델을 선도하여 다양한 질문에 대한 관련 답변을 제공하는 데 매우 중요합니다. 다양한 정교한 애플리케이션에서 Generative AI를 사용하는 데 있어 가장 큰 장벽 중 하나는 환각입니다. 메타AI리서치가 최근 발표한 논문 '검증 체인은 대규모 언어 모델에서 환각을 줄입니다."에서는 텍스트를 생성할 때 환각을 직접적으로 줄이는 간단한 기술에 대해 설명합니다.
이 기사에서는 환각 문제에 대해 알아보고 논문에서 언급된 CoVe의 개념과 LLM, LangChain Framework 및 LangChain Expression Language(LCEL)를 사용하여 이를 구현하여 맞춤형 체인을 만드는 방법을 살펴봅니다.
학습 목표
- LLM의 환각 문제를 이해합니다.
- 환각을 완화하기 위한 CoVe(Chain of Verification) 메커니즘에 대해 알아보세요.
- CoVe의 장점과 단점에 대해 알아보세요.
- LangChain을 사용하여 CoVe를 구현하는 방법을 배우고 LangChain 표현 언어를 이해하세요.
이 기사는 데이터 과학 블로그.
차례
LLM의 환각 문제는 무엇입니까?
먼저 LLM의 환각 문제에 대해 알아보겠습니다. LLM 모델은 자동 회귀 생성 접근 방식을 사용하여 이전 컨텍스트가 주어지면 다음 단어를 예측합니다. 빈번한 테마의 경우, 모델은 토큰을 수정할 높은 확률을 자신 있게 할당할 만큼 충분한 예를 확인했습니다. 그러나 모델이 특이하거나 익숙하지 않은 주제에 대해 훈련되지 않았기 때문에 높은 신뢰도로 부정확한 토큰을 전달할 수 있습니다. 이로 인해 그럴듯하게 들리지만 잘못된 정보에 대한 환각이 발생합니다.
다음은 Open AI의 ChatGPT에 있는 환각의 예 중 하나입니다. 인도 작가가 2020년에 출판한 "Economics of Small Things"라는 책에 대해 질문했지만 모델은 자신감을 갖고 잘못된 대답을 내뱉고 다른 책과 혼동했습니다. 노벨상 수상자 Abhijit Banerjee의 '가난한 경제학'.

CoVe(검증 체인) 기술
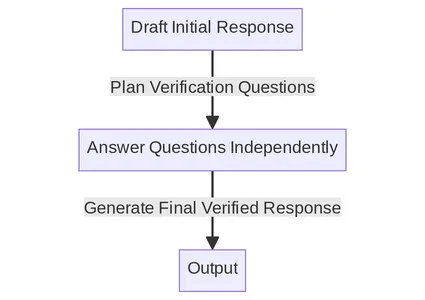
CoVe 메커니즘은 메시지 표시와 일관성 검사를 결합하여 LLM에 대한 자체 확인 시스템을 만듭니다. 다음은 문서에 나열된 주요 단계입니다. 우리는 각 단계를 하나씩 자세히 이해하려고 노력할 것입니다.
체인 프로세스 개요
- 기준 응답 생성: 쿼리가 주어지면 LLM을 사용하여 응답을 생성합니다.
- 계획 확인: 쿼리와 기본 응답이 모두 주어지면 원래 응답에 실수가 있는지 자체 분석하는 데 도움이 될 수 있는 확인 질문 목록을 생성합니다.
- 검증 실행: 각 확인 질문에 차례로 답하고 원래 응답과 비교하여 답변을 확인하여 불일치나 실수가 있는지 확인하십시오.
- 최종 확인된 응답 생성: 발견된 불일치(있는 경우)를 고려하여 검증 결과를 통합하는 수정된 응답을 생성하십시오.
상세한 예시를 통한 체인 프로세스 이해
초기 응답 생성
먼저 초기 응답을 생성하라는 특별한 메시지 없이 쿼리를 LLM에 전달합니다. 이는 CoVe 프로세스의 출발점 역할을 합니다. 이와 같은 기본 반응은 흔히 환각을 일으키기 쉽기 때문에 CoVe 기술은 이후 단계에서 이러한 오류를 발견하고 수정하려고 합니다.
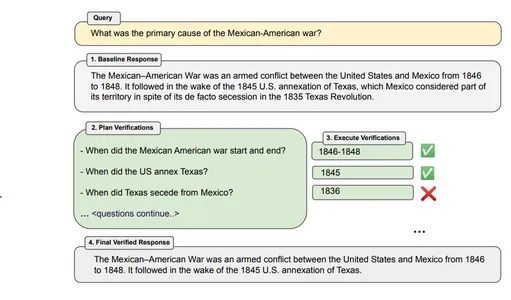
예 - “멕시코-미국 전쟁의 주요 원인은 무엇입니까?”
봇 대응 – 멕시코-미국 전쟁은 1846년부터 1848년까지 미국과 멕시코 간의 무력 충돌입니다. 1845년 미국이 텍사스를 합병한 이후에 일어났습니다. 텍사스는 사실상의 영토임에도 불구하고 영토의 일부로 간주되었습니다. 1835년 텍사스 혁명으로 탈퇴.
계획 검증
기본 응답의 사실적 주장을 조사할 수 있는 쿼리 및 기본 답변을 기반으로 확인 질문을 만듭니다. 이를 구현하기 위해 쿼리와 기본 응답을 기반으로 일련의 확인 질문을 모델에 표시할 수 있습니다. 확인 질문은 유연할 수 있으며 원본 텍스트와 정확히 일치할 필요는 없습니다.
예 – 멕시코-미국 전쟁은 언제 시작되고 끝났나요? 미국은 언제 텍사스를 합병했나요? 텍사스는 언제 멕시코로부터 독립했는가?
검증 실행
검증 질문을 계획하고 나면 이러한 질문에 개별적으로 답변할 수 있습니다. 이 문서에서는 검증을 실행하는 4가지 방법에 대해 설명합니다.
1. 공동 – 여기서는 확인 질문의 계획 및 실행이 단일 프롬프트에서 수행됩니다. 질문과 답변은 동일한 LLM 프롬프트에서 제공됩니다. 이 방법은 확인 응답이 환각에 빠질 수 있으므로 일반적으로 권장되지 않습니다.
2. 2단계 - 계획과 실행은 별도의 LLM 프롬프트를 통해 두 단계로 개별적으로 수행됩니다. 먼저 확인 질문을 생성한 다음 해당 질문에 답변합니다.
3. 인수분해 - 여기서 각 확인 질문은 동일한 큰 응답이 아닌 독립적으로 답변되며 기본 원래 응답은 포함되지 않습니다. 다양한 확인 질문 간의 혼란을 방지하는 데 도움이 되며 더 많은 질문을 처리할 수도 있습니다.
4. 인수분해 + 수정 – 이 방법에는 추가 단계가 추가됩니다. 모든 확인 질문에 답변한 후 CoVe 메커니즘은 답변이 원래 기준 응답과 일치하는지 확인합니다. 이 작업은 추가 프롬프트를 사용하여 별도의 단계로 수행됩니다.
외부 도구 또는 자체 LLM: 우리의 응답을 확인하고 확인 답변을 제공할 도구가 필요합니다. 이는 LLM 자체 또는 외부 도구를 사용하여 수행할 수 있습니다. 더 높은 정확성을 원한다면 LLM에 의존하는 대신 사용 사례에 따라 인터넷 검색 엔진, 참조 문서 또는 웹 사이트와 같은 외부 도구를 사용할 수 있습니다.
최종 확인된 답변
이 마지막 단계에서는 개선되고 검증된 응답이 생성됩니다. 몇 번의 프롬프트가 사용되며 기본 응답 및 확인 질문 답변의 모든 이전 컨텍스트가 포함됩니다. "Factor+Revise" 방법을 사용한 경우 교차 검사된 불일치의 출력도 제공됩니다.
CoVe 기술의 한계
Chain of Verification은 간단하지만 효과적인 기술인 것처럼 보이지만 여전히 몇 가지 제한 사항이 있습니다.
- 환각이 완전히 제거되지 않음: 반응에서 환각이 완전히 제거되는 것을 보장하지 않으므로 오해의 소지가 있는 정보가 생성될 수 있습니다.
- 컴퓨팅 집약적: 응답 생성과 함께 검증을 생성하고 실행하면 계산 오버헤드와 비용이 추가될 수 있습니다. 따라서 프로세스 속도가 느려지거나 컴퓨팅 비용이 증가할 수 있습니다.
- 모델별 제한사항: 이 CoVe 방법의 성공 여부는 모델의 기능과 실수를 식별하고 수정하는 능력에 크게 좌우됩니다.
CoVe의 LangChain 구현
알고리즘의 기본 개요
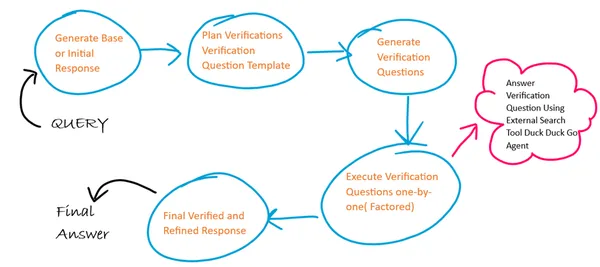
여기서는 CoVe의 4개 단계 각각에 대해 4개의 서로 다른 프롬프트 템플릿을 사용하고 각 단계에서 이전 단계의 출력이 다음 단계의 입력으로 사용됩니다. 또한 검증 질문 실행에 있어 요소화된 접근 방식을 따릅니다. 우리는 확인 질문에 대한 답변을 생성하기 위해 외부 인터넷 검색 도구 에이전트를 사용합니다.
1단계: 라이브러리 설치 및 로드
!pip install langchain duckduckgo-search2단계: LLM 인스턴스 생성 및 초기화
여기서는 무료로 제공되는 Langchain의 Google Palm LLM을 사용하고 있습니다. 이를 사용하여 Google Palm용 API 키를 생성할 수 있습니다. 링크 Google 계정을 사용하여 로그인하세요.
from langchain import PromptTemplate
from langchain.llms import GooglePalm
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
API_KEY='Generated API KEY'
llm=GooglePalm(google_api_key=API_KEY)
llm.temperature=0.4
llm.model_name = 'models/text-bison-001'
llm.max_output_tokens=2048
3단계: 초기 기준 응답 생성
이제 초기 기준 응답을 생성하기 위한 프롬프트 템플릿을 생성하고 이 템플릿을 사용하여 기준 응답 LLM 체인을 생성합니다.
LLM 체인은 LangChain 표현 언어를 사용하여 체인을 구성합니다. 여기서는 LLM 모델(|)과 연결된 프롬프트 템플릿(|)을 제공하고 마지막으로 출력 파서를 제공합니다.
BASELINE_PROMPT = """Answer the below question which is asking for a concise factual answer. NO ADDITIONAL DETAILS.
Question: {query}
Answer:"""
# Chain to generate initial response
baseline_response_prompt_template = PromptTemplate.from_template(BASELINE_PROMPT)
baseline_response_chain = baseline_response_prompt_template | llm | StrOutputParser()4단계: 확인 질문에 대한 질문 템플릿 생성
이제 다음 단계에서 확인 질문을 생성하는 데 도움이 되는 확인 질문 템플릿을 구성하겠습니다.
VERIFICATION_QUESTION_TEMPLATE = """Your task is to create a verification question based on the below question provided.
Example Question: Who wrote the book 'God of Small Things' ?
Example Verification Question: Was book [God of Small Things] written by [writer]? If not who wrote [God of Small Things] ?
Explanation: In the above example the verification question focused only on the ANSWER_ENTITY (name of the writer) and QUESTION_ENTITY (book name).
Similarly you need to focus on the ANSWER_ENTITY and QUESTION_ENTITY from the actual question and generate verification question.
Actual Question: {query}
Final Verification Question:"""
# Chain to generate a question template for verification answers
verification_question_template_prompt_template = PromptTemplate.from_template(VERIFICATION_QUESTION_TEMPLATE)
verification_question_template_chain = verification_question_template_prompt_template | llm | StrOutputParser()5단계: 확인 질문 생성
이제 위에 정의된 확인 질문 템플릿을 사용하여 확인 질문을 생성하겠습니다.
VERIFICATION_QUESTION_PROMPT= """Your task is to create a series of verification questions based on the below question, the verfication question template and baseline response.
Example Question: Who wrote the book 'God of Small Things' ?
Example Verification Question Template: Was book [God of Small Things] written by [writer]? If not who wrote [God of Small Things]?
Example Baseline Response: Jhumpa Lahiri
Example Verification Question: 1. Was God of Small Things written by Jhumpa Lahiri? If not who wrote God of Small Things ?
Explanation: In the above example the verification questions focused only on the ANSWER_ENTITY (name of the writer) and QUESTION_ENTITY (name of book) based on the template and substitutes entity values from the baseline response.
Similarly you need to focus on the ANSWER_ENTITY and QUESTION_ENTITY from the actual question and substitute the entity values from the baseline response to generate verification questions.
Actual Question: {query}
Baseline Response: {base_response}
Verification Question Template: {verification_question_template}
Final Verification Questions:"""
# Chain to generate the verification questions
verification_question_generation_prompt_template = PromptTemplate.from_template(VERIFICATION_QUESTION_PROMPT)
verification_question_generation_chain = verification_question_generation_prompt_template | llm | StrOutputParser()
6단계: 확인 질문 실행
여기서는 외부 검색 도구 에이전트를 사용하여 확인 질문을 실행해 보겠습니다. 이 에이전트는 LangChain의 에이전트 및 도구 모듈과 DuckDuckGo 검색 모듈을 사용하여 구성됩니다.
참고 – 요청 간 시간 제한으로 인해 여러 요청이 오류를 초래할 수 있으므로 검색 에이전트에는 시간 제한이 있으므로 신중하게 사용해야 합니다.
from langchain.agents import ConversationalChatAgent, AgentExecutor
from langchain.tools import DuckDuckGoSearchResults
#create search agent
search = DuckDuckGoSearchResults()
tools = [search]
custom_system_message = "Assistant assumes no knowledge & relies on internet search to answer user's queries."
max_agent_iterations = 5
max_execution_time = 10
chat_agent = ConversationalChatAgent.from_llm_and_tools(
llm=llm, tools=tools, system_message=custom_system_message
)
search_executor = AgentExecutor.from_agent_and_tools(
agent=chat_agent,
tools=tools,
return_intermediate_steps=True,
handle_parsing_errors=True,
max_iterations=max_agent_iterations,
max_execution_time = max_execution_time
)
# chain to execute verification questions
verification_chain = RunnablePassthrough.assign(
split_questions=lambda x: x['verification_questions'].split("n"), # each verification question is passed one by one factored approach
) | RunnablePassthrough.assign(
answers = (lambda x: [{"input": q,"chat_history": []} for q in x['split_questions']])| search_executor.map() # search executed for each question independently
) | (lambda x: "n".join(["Question: {} Answer: {}n".format(question, answer['output']) for question, answer in zip(x['split_questions'], x['answers'])]))# Create final refined response
7단계: 최종적으로 정제된 응답 생성
이제 프롬프트 템플릿과 LLM 체인을 정의하는 최종 정제된 답변을 생성하겠습니다.
FINAL_ANSWER_PROMPT= """Given the below `Original Query` and `Baseline Answer`, analyze the `Verification Questions & Answers` to finally provide the refined answer.
Original Query: {query}
Baseline Answer: {base_response}
Verification Questions & Answer Pairs:
{verification_answers}
Final Refined Answer:"""
# Chain to generate the final answer
final_answer_prompt_template = PromptTemplate.from_template(FINAL_ANSWER_PROMPT)
final_answer_chain = final_answer_prompt_template | llm | StrOutputParser()8단계: 모든 체인을 함께 연결
이제 이전에 정의한 모든 체인을 모아 한 번에 순서대로 실행합니다.
chain = RunnablePassthrough.assign(
base_response=baseline_response_chain
) | RunnablePassthrough.assign(
verification_question_template=verification_question_template_chain
) | RunnablePassthrough.assign(
verification_questions=verification_question_generation_chain
) | RunnablePassthrough.assign(
verification_answers=verification_chain
) | RunnablePassthrough.assign(
final_answer=final_answer_chain
)
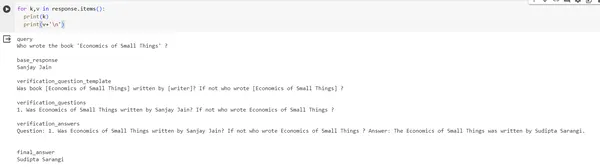
response = chain.invoke({"query": "Who wrote the book 'Economics of Small Things' ?"})
print(response)#output of response
{'query': "Who wrote the book 'Economics of Small Things' ?", 'base_response': 'Sanjay Jain', 'verification_question_template': 'Was book [Economics of Small Things] written by [writer]? If not who wrote [Economics of Small Things] ?', 'verification_questions': '1. Was Economics of Small Things written by Sanjay Jain? If not who wrote Economics of Small Things ?', 'verification_answers': 'Question: 1. Was Economics of Small Things written by Sanjay Jain? If not who wrote Economics of Small Things ? Answer: The Economics of Small Things was written by Sudipta Sarangi n', 'final_answer': 'Sudipta Sarangi'}출력 이미지:
결론
본 연구에서 제안하는 CoVe(Chain-of-Verification) 기법은 큰 언어 모델을 구축하고, 응답에 대해 보다 비판적으로 생각하고, 필요한 경우 스스로 수정하는 것을 목표로 하는 전략입니다. 이는 이 방법이 확인을 더 작고 관리하기 쉬운 쿼리로 나누기 때문입니다. 또한 모델이 이전 응답을 검토하지 못하도록 금지하면 오류나 "환각"이 반복되는 것을 방지하는 데 도움이 되는 것으로 나타났습니다. 모델이 답변을 다시 확인하도록 요구하는 것만으로도 결과가 크게 향상됩니다. CoVe에 외부 소스에서 정보를 가져올 수 있는 등 더 많은 기능을 제공하는 것은 효율성을 높이는 한 가지 방법일 수 있습니다.
주요 요점
- 체인 프로세스는 응답의 다양한 부분을 확인할 수 있는 다양한 기술 조합을 갖춘 유용한 도구입니다.
- 많은 장점 외에도 다양한 도구와 메커니즘을 사용하여 완화할 수 있는 체인 프로세스의 특정 제한 사항이 있습니다.
- 우리는 LangChain 패키지를 활용하여 이 CoVe 프로세스를 구현할 수 있습니다.
자주 묻는 질문
A. 다양한 수준에서 환각을 줄이는 방법에는 프롬프트 수준(생각의 나무, 생각의 사슬), 모델 수준(대비 레이어에 의한 DoLa 디코딩) 및 자체 검사(CoVe) 등 여러 가지 방법이 있습니다.
A. Google 검색 API 등과 같은 외부 검색 도구의 지원을 사용하여 CoVe의 확인 프로세스를 개선할 수 있으며 도메인 및 사용자 정의 사용 사례의 경우 RAG와 같은 검색 기술을 사용할 수 있습니다.
A. 현재 이 메커니즘을 구현하는 즉시 사용 가능한 오픈 소스 도구는 없지만 Serp API, Google Search 및 Lang Chains의 도움을 받아 자체적으로 구축할 수 있습니다.
A. 검색 증강 생성(RAG) 기술은 LLM이 이 도메인별 데이터 검색을 기반으로 사실적으로 정확한 응답을 생성할 수 있는 도메인별 사용 사례에 사용됩니다.
A. 이 논문에서는 Llama 65B 모델을 LLM으로 사용한 다음 몇 가지 예시를 사용하는 프롬프트 엔지니어링을 사용하여 질문을 생성하고 모델에 지침을 제공했습니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/12/chain-of-verification-implementation-using-langchain-expression-language-and-llm/

