작성자 별 이미지
Python은 단순성과 가독성으로 잘 알려진 초보자 친화적이고 다재다능한 프로그래밍 언어입니다. 그러나 그 우아한 구문은 숙련된 Python 개발자라도 놀라게 할 수 있는 특이한 점으로부터 면역되지 않습니다. 버그 없는 코드를 작성하거나 고통 없이 디버깅하려면 이러한 점을 이해하는 것이 필수적입니다.
이 튜토리얼에서는 변경 가능한 기본값, 루프 및 이해의 변수 범위, 튜플 할당 등 몇 가지 문제를 살펴봅니다. 간단한 예제를 코딩해 보겠습니다. why 사물은 자신이 하는 방식대로 작동하며, 방법 우리는 이것을 피할 수 있습니다(실제로 할 수 있다면 🙂).
그럼 시작합시다!
Python에서는 변경 가능한 기본값이 일반적인 날카로운 모서리입니다. 목록이나 사전과 같은 변경 가능한 개체를 기본 인수로 사용하여 함수를 정의할 때마다 예상치 못한 동작이 발생하게 됩니다.
기본값은 함수가 정의될 때 한 번만 평가되며, 함수가 호출될 때마다 평가되지는 않습니다.. 함수 내에서 기본 인수를 변경하면 예기치 않은 동작이 발생할 수 있습니다.
예를 들어 보자.
def add_to_cart(item, cart=[]):
cart.append(item)
return cart
이 예에서, add_to_cart 항목을 가져와 목록에 추가하는 함수입니다. cart. 기본값 cart 빈 목록입니다. 추가할 항목 없이 함수를 호출하면 빈 카트가 반환된다는 의미입니다.
다음은 몇 가지 함수 호출입니다.
# User 1 adds items to their cart
user1_cart = add_to_cart("Apple")
print("User 1 Cart:", user1_cart)
Output >>> ['Apple']
이것은 예상대로 작동합니다. 하지만 지금은 어떻게 되나요?
# User 2 adds items to their cart
user2_cart = add_to_cart("Cookies")
print("User 2 Cart:", user2_cart)
Output >>>
['Apple', 'Cookies'] # User 2 never added apples to their cart!
기본 인수는 목록(변경 가능한 객체)이기 때문에 함수 호출 간에도 상태를 유지합니다. 그래서 전화할 때마다 add_to_cart, 함수 정의 중에 생성된 동일한 목록 객체에 값을 추가합니다. 이 예에서는 모든 사용자가 동일한 카트를 공유하는 것과 같습니다.
피하는 방법
해결 방법으로 다음을 설정할 수 있습니다. cart 에 None 다음과 같이 함수 내에서 카트를 초기화합니다.
def add_to_cart(item, cart=None):
if cart is None:
cart = []
cart.append(item)
return cart
따라서 이제 각 사용자는 별도의 카트를 갖게 됩니다. 🙂
Python 함수 및 함수 인수에 대해 다시 살펴보고 싶다면 다음을 읽어보세요. Python 함수 인수: 결정적인 가이드.
Python의 이상한 범위에는 자체 튜토리얼이 필요합니다. 하지만 여기서는 그러한 이상한 점 하나를 살펴보겠습니다.
다음 스니펫을 살펴보세요.
x = 10
squares = []
for x in range(5):
squares.append(x ** 2)
print("Squares list:", squares)
# x is accessible here and is the last value of the looping var
print("x after for loop:", x)
변수 x 10으로 설정되어 있습니다. 그러나 x 또한 루핑 변수이기도 합니다. 하지만 우리는 루핑 변수의 범위가 for 루프 블록으로 제한된다고 가정하겠습니다. 그렇죠?
출력을 살펴보겠습니다.
Output >>>
Squares list: [0, 1, 4, 9, 16]
x after for loop: 4
우리는 그것을 본다 x 이제 4는 루프에서 취하는 최종 값이며 우리가 설정한 초기 값 10이 아닙니다.
이제 for 루프를 이해 표현식으로 바꾸면 어떤 일이 발생하는지 살펴보겠습니다.
x = 10
squares = [x ** 2 for x in range(5)]
print("Squares list:", squares)
# x is 10 here
print("x after list comprehension:", x)
여기 x 10은 이해 표현식 이전에 설정한 값입니다.
Output >>>
Squares list: [0, 1, 4, 9, 16]
x after list comprehension: 10피하는 방법
예기치 않은 동작을 방지하려면 루프를 사용하는 경우 나중에 액세스하려는 다른 변수와 동일한 루프 변수 이름을 지정하지 않도록 하세요.
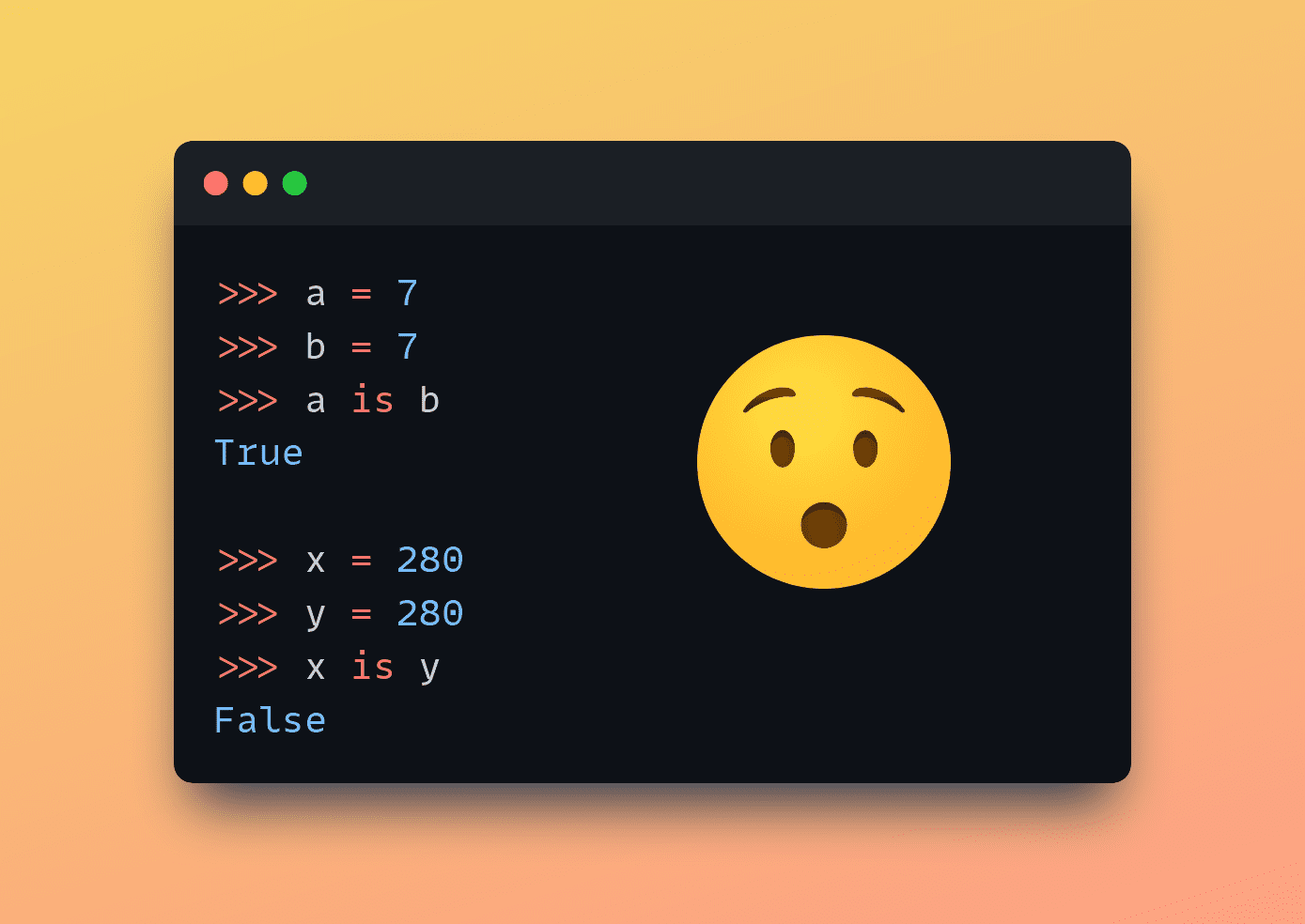
Python에서는 다음을 사용합니다. is 객체 동일성을 확인하기 위한 키워드입니다. 이는 두 변수가 메모리에서 동일한 객체를 참조하는지 확인한다는 의미입니다. 그리고 동등성을 확인하기 위해 다음을 사용합니다. == 운영자. 예?
이제 Python REPL을 시작하고 다음 코드를 실행합니다.
>>> a = 7
>>> b = 7
>>> a == 7
True
>>> a is b
True
이제 다음을 실행하세요.
>>> x = 280
>>> y = 280
>>> x == y
True
>>> x is y
False
잠깐, 왜 이런 일이 일어나는 걸까요? 음, 이는 Python의 표준 구현인 CPython의 "정수 캐싱" 또는 "인턴" 때문입니다.
C파이썬 정수 객체를 캐시합니다. -5 ~ 256 범위입니다. 이 범위 내의 정수를 사용할 때마다 Python은 메모리에서 동일한 객체를 사용한다는 의미입니다. 따라서 이 범위 내의 두 정수를 비교할 때 is 키워드 결과는 True 왜냐하면 그들은 메모리에 있는 동일한 객체를 참조.
그래서 a is b 반품 True. 인쇄하여 확인할 수도 있습니다. id(a) 과 id(b).
그러나 이 범위를 벗어나는 정수는 캐시되지 않습니다. 그리고 그러한 정수가 발생할 때마다 메모리에 새로운 객체가 생성됩니다.
따라서 다음을 사용하여 캐시된 범위 밖의 두 정수를 비교할 때 is 키워드(예, x 과 y 이 예에서는 둘 다 280으로 설정됨) 결과는 다음과 같습니다. False 왜냐하면 그것들은 실제로 메모리에 있는 두 개의 다른 객체이기 때문입니다.
피하는 방법
이 동작은 다음을 사용하지 않는 한 문제가 되지 않습니다. is 두 개체의 동등성을 비교하는 데 사용됩니다. 따라서 항상 == 두 Python 객체가 동일한 값을 가지고 있는지 확인하는 연산자입니다.
Python의 내장 데이터 구조에 익숙하다면 튜플이 다음과 같다는 것을 알고 있을 것입니다. 불변의. 그래서 당신은 그 자리에서 수정하세요. 반면에 목록이나 사전과 같은 데이터 구조는 변하기 쉬운. 당신을 의미 그 자리에서 바꾸세요.
하지만 하나 이상의 변경 가능한 객체를 포함하는 튜플은 어떻습니까?
Python REPL을 시작하고 다음 간단한 예제를 실행하는 것이 도움이 됩니다.
>>> my_tuple = ([1,2],3,4)
>>> my_tuple[0].append(3)
>>> my_tuple
([1, 2, 3], 3, 4)
여기서 튜플의 첫 번째 요소는 두 요소가 있는 목록입니다. 첫 번째 목록에 3을 추가해 보았는데 잘 작동합니다! 글쎄, 방금 튜플을 수정했나요?
이제 목록에 두 개의 요소를 더 추가해 보겠습니다. 이번에는 += 연산자를 사용합니다.
>>> my_tuple[0] += [4,5]
Traceback (most recent call last):
File "", line 1, in
TypeError: 'tuple' object does not support item assignment
예, 튜플 객체가 항목 할당을 지원하지 않는다는 TypeError가 발생합니다. 예상되는 것입니다. 하지만 튜플을 확인해 보겠습니다.
>>> my_tuple
([1, 2, 3, 4, 5], 3, 4)
요소 4와 5가 목록에 추가된 것을 볼 수 있습니다! 프로그램이 오류를 발생시키면서 동시에 성공했습니까?
+= 연산자는 내부적으로 다음을 호출하여 작동합니다. __iadd__() 내부 추가를 수행하고 목록을 수정하는 메서드입니다. 할당으로 인해 TypeError 예외가 발생했지만 목록 끝에 요소를 추가하는 데 이미 성공했습니다. +=는 아마도 가장 날카로운 모서리일 것입니다!
피하는 방법
프로그램에서 이러한 이상한 점을 피하려면 튜플을 사용해 보십시오. 만 불변 컬렉션의 경우. 그리고 가능한 한 가변 객체를 튜플 요소로 사용하지 마세요.
가변성은 지금까지 우리의 논의에서 반복되는 주제였습니다. 따라서 이 튜토리얼을 마무리하는 또 다른 것이 있습니다.
때로는 목록의 독립적인 복사본을 만들어야 할 수도 있습니다. 하지만 다음과 유사한 구문을 사용하여 복사본을 생성하면 어떻게 될까요? list2 = list1 어디에 list1 목록이 원본인가요?
생성되는 얕은 복사본입니다. 따라서 목록의 원래 요소에 대한 참조만 복사합니다. 얕은 복사본을 통해 요소를 수정하면 영향을 받습니다. 두 원래 목록 과 얕은 사본.
다음 예를 들어보겠습니다.
original_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Shallow copy of the original list
shallow_copy = original_list
# Modify the shallow copy
shallow_copy[0][0] = 100
# Print both the lists
print("Original List:", original_list)
print("Shallow Copy:", shallow_copy)
얕은 복사본의 변경 사항이 원본 목록에도 영향을 미치는 것을 볼 수 있습니다.
Output >>>
Original List: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]
Shallow Copy: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]
여기서는 얕은 복사본에서 첫 번째 중첩 목록의 첫 번째 요소를 수정합니다. shallow_copy[0][0] = 100. 그러나 수정 사항이 원본 목록과 얕은 복사본 모두에 영향을 미친다는 것을 알 수 있습니다.
피하는 방법
이를 방지하려면 다음과 같이 전체 복사본을 만들 수 있습니다.
import copy
original_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Deep copy of the original list
deep_copy = copy.deepcopy(original_list)
# Modify an element of the deep copy
deep_copy[0][0] = 100
# Print both lists
print("Original List:", original_list)
print("Deep Copy:", deep_copy)
이제 전체 복사본을 수정하면 원본 목록이 변경되지 않습니다.
Output >>>
Original List: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
Deep Copy: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]그리고 그것은 마무리입니다! 이 튜토리얼에서는 변경 가능한 기본값의 놀라운 동작부터 얕은 복사 목록의 미묘함까지 Python의 몇 가지 이상한 점을 살펴보았습니다. 이것은 Python의 기이함에 대한 소개일 뿐이며 결코 완전한 목록은 아닙니다. 모든 코드 예제를 찾을 수 있습니다 GitHub에서.
Python에서 더 오랫동안 코딩을 계속하고 언어를 더 잘 이해하게 되면 아마도 이러한 것들을 더 많이 접하게 될 것입니다. 계속해서 코딩하고 탐색해 보세요!
아, 그리고 이 튜토리얼의 후속편을 읽고 싶다면 댓글로 알려주시기 바랍니다.
발라 프리야 C 인도 출신의 개발자이자 기술 작가입니다. 그녀는 수학, 프로그래밍, 데이터 과학, 콘텐츠 제작의 교차점에서 일하는 것을 좋아합니다. 그녀의 관심 분야와 전문 분야에는 DevOps, 데이터 과학, 자연어 처리가 포함됩니다. 그녀는 읽기, 쓰기, 코딩, 커피를 즐깁니다! 현재 그녀는 튜토리얼, 방법 가이드, 의견 등을 작성하여 개발자 커뮤니티에서 자신의 지식을 학습하고 공유하는 데 힘쓰고 있습니다. Bala는 또한 매력적인 리소스 개요와 코딩 튜토리얼을 만듭니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/5-common-python-gotchas-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=5-common-python-gotchas-and-how-to-avoid-them

