
결정 트리는 기계 학습 세계에서 가장 간단한 비선형 감독 알고리즘 중 하나입니다. 이름에서 알 수 있듯이 ML 용어로 결정을 내리는 데 사용되며 분류라고 합니다(회귀에도 사용할 수 있음).
결정 트리에는 단방향 트리 구조가 있습니다. 즉, 모든 노드에서 알고리즘은 특정 중지 기준에 따라 자식 노드로 분할하기로 결정합니다. 가장 일반적으로 DT는 엔트로피, 정보 획득, 지니 지수 등을 사용합니다.
ID3, C4.5, CART, C5.0, CHAID, QUEST, CRUISE와 같은 DT에는 몇 가지 알려진 알고리즘이 있습니다. 이 기사에서는 가장 단순하고 가장 오래된 것인 ID3에 대해 논의할 것입니다.
ID3, 또는 Iternative Dichotomizer는 Ross Quinlan이 개발한 세 가지 결정 트리 구현 중 첫 번째입니다.
알고리즘은 일련의 행/객체 및 기능 사양에서 시작하여 하향식 방식으로 트리를 구축합니다. 트리의 각 노드에서 개체 집합을 분할하기 위해 엔트로피 최소화 또는 정보 이득 최대화를 기반으로 하나의 기능이 테스트됩니다. 이 프로세스는 주어진 노드의 집합이 동종일 때까지 계속됩니다(즉, 노드에 동일한 범주의 개체가 포함됨). 알고리즘은 욕심 많은 검색을 사용합니다. 정보 획득 기준을 사용하여 테스트를 선택한 다음 대체 선택 가능성을 탐색하지 않습니다.
단점 :
- 모델이 과적합되었을 수 있습니다.
- 범주형 기능에서만 작동
- 누락된 값을 처리하지 않습니다.
- 저속
- 가지 치기를 지원하지 않습니다
- 부스트를 지원하지 않습니다
하나의 알고리즘의 많은 단점, 왜 우리는 이것을 논의하고 있습니까?
대답: 트리 알고리즘에 대한 직관을 개발하는 것은 간단하고 훌륭합니다.
Rain이 Johny/Arthur가 밖에서 연주할지 여부를 결정하는 가장 인기 있는 동요 중 하나가 오늘 샘플입니다. 유일한 변화는 비뿐만 아니라 악천후도 아이의 놀이에 영향을 미치고 우리는 DT를 사용하여 아이가 밖에 있는지 예측한다는 것입니다.

출처 : Wikipedia
데이터는 다음과 같습니다.
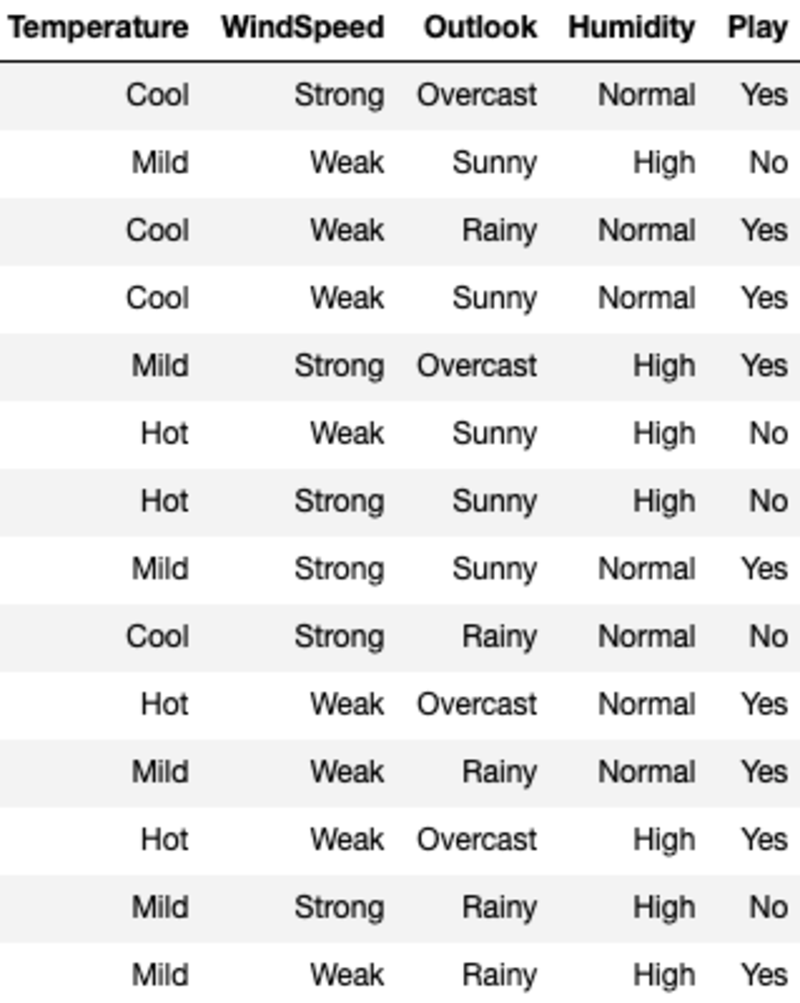
'Temperature', 'WindSpeed', 'Outlook', 'Humidity'는 특성이고 'Play'는 대상 변수입니다. 범주형 데이터만 있고 누락된 값이 없다는 것은 ID3를 사용할 수 있음을 의미합니다.
알고리즘 자체로 이동하기 전에 분할 기준을 살펴보겠습니다. 간단히 하기 위해 이진 분류 사례에 대해서만 각 기준을 설명합니다.
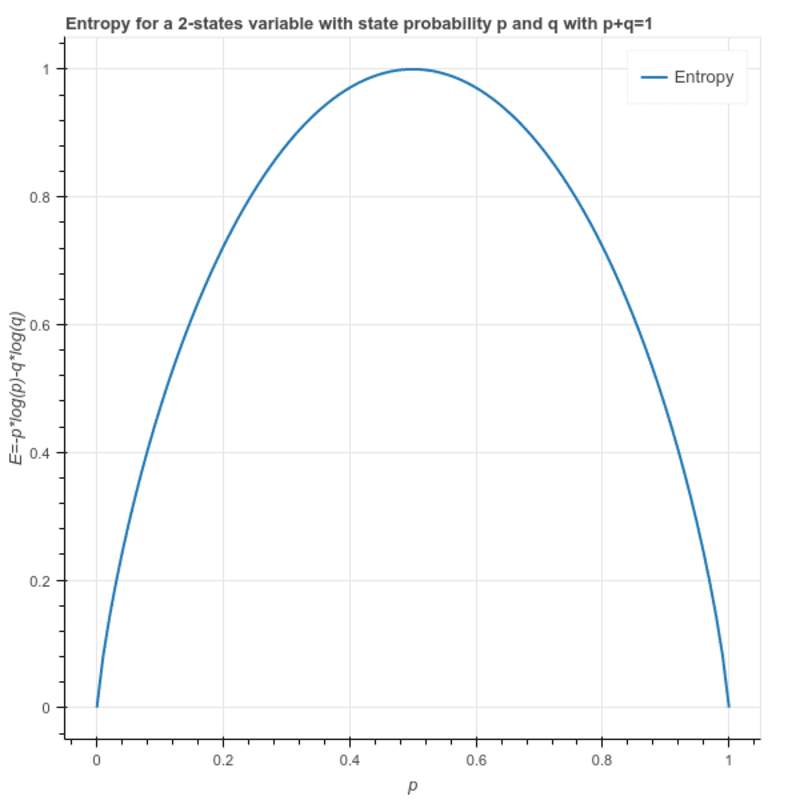
엔트로피 : 이것은 샘플의 이질성을 계산하는 데 사용되며 그 값은 0과 1 사이에 있습니다. 샘플이 동질인 경우 엔트로피는 0이고 샘플이 모든 클래스의 동일한 비율을 갖는 경우 엔트로피는 1입니다.
S = -(p * log₂p + q * log₂q)
어디에 p 과 q 샘플에서 두 클래스의 각각의 비율입니다.
다음과 같이 작성할 수도 있습니다. S = -(p * log₂p + (1-p)* log₂(1-p))
정보 획득: 노드의 엔트로피와 자식 노드의 모든 값에 대한 평균 엔트로피의 차이입니다. 최대 정보 이득을 제공하는 기능이 분할을 위해 선택됩니다.
루트 노드의 엔트로피: (9 — 예 및 5 — 아니요)
S = -(9/14)*log(9/14) — (5/14) * log(5/14) = 0.94
루트 노드를 분할하는 방법에는 4가지가 있습니다. ('온도', '풍속', '전망' 및 '습도'). 따라서 위 중 하나를 선택하면 자식 노드의 가중 평균 엔트로피를 계산합니다.
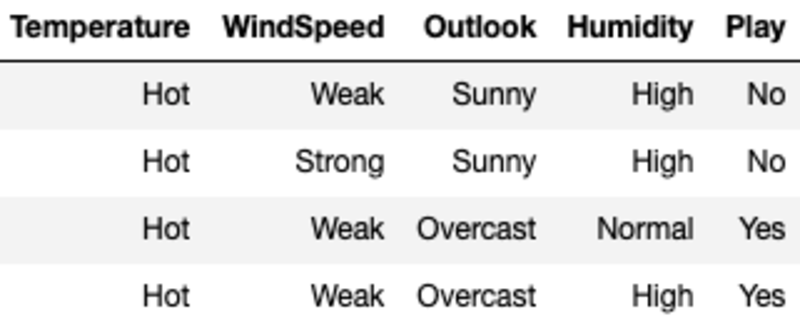
I(Temperature) = Hot*E(Temperature=Hot) + Mild*E(Temperature=Mild) + Cool*E(Temperature=Cool)
여기서 Hot, Mild 및 Cool은 데이터에서 3개 값의 비율을 나타냅니다.
I(Temperature) = (4/14)*1 + (6/14)*0.918 + (4/14)*0.811 = 0.911
여기에서 각 값에 대한 엔트로피는 기능 값을 사용하여 샘플을 필터링한 다음 엔트로피 공식을 사용하여 계산됩니다. 예를 들어, E(Temperature=Hot)는 Temperature가 Hot인 원래 샘플을 필터링하여 계산됩니다(이 경우 Yes와 No의 수가 동일하여 Entropy가 1임을 의미함).
루트 노드 엔트로피에서 온도에 대한 평균 엔트로피를 빼서 온도 분할의 정보 이득을 계산합니다.
G(Temperature) = S — I(Temperature) = 0.94–0.911 = 0.029
마찬가지로 1개의 모든 기능에서 게인을 계산하고 게인이 최대인 XNUMX을 선택합니다.
G(WindSpeed) = S — I(WindSpeed) = 0.94–0.892 =0.048
G(Outlook) = S — I(Outlook) = 0.94–0.693 =0.247
G(Humidity) = S — I(Humidity) = 0.94–0.788 =0.152
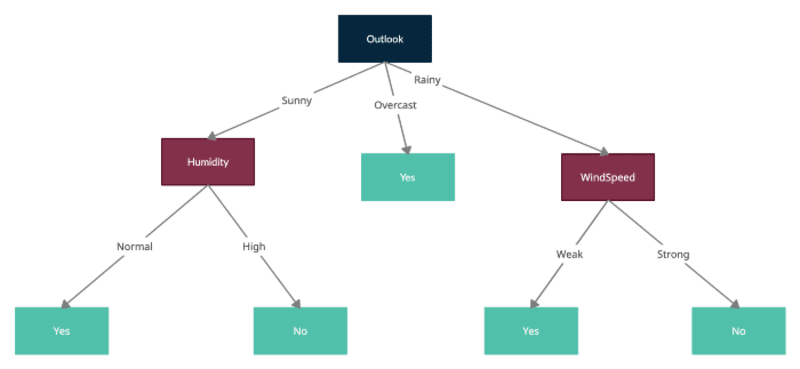
Outlook에는 최대 정보 이득이 있으므로 Outlook에서 루트 노드를 분할하고 각 자식 노드는 Outlook 값(예: Sunny, Overcast 및 Rainy) 중 하나로 필터링된 샘플을 나타냅니다.
이제 필터링된 샘플을 사용하여 루트 노드로 형성된 새 노드를 처리하고 각각에 대한 엔트로피를 계산하고 각 추가 분할에 대한 평균 엔트로피를 계산하고 현재 노드 엔트로피에서 이를 빼서 분할을 테스트하여 동일한 프로세스를 반복하여 정보 이득을 얻습니다. ID3는 하위 노드를 분할하기 위해 이미 사용된 기능을 사용할 수 없습니다. 따라서 각 기능은 분할을 위해 트리에서 한 번만 사용할 수 있습니다.
모든 분할에 의해 형성된 최종 트리는 다음과 같습니다.
Python 코드를 사용한 간단한 구현을 찾을 수 있습니다. 여기에서 지금 확인해 보세요.
결론
ID3 작동에 대해 최선을 다해 설명했지만 궁금한 점이 있을 수 있습니다. 댓글로 알려주시면 모두 기꺼이 받아드리겠습니다.
읽어 주셔서 감사합니다!
안킷 말리크 마케팅, 공급망, 소매, 광고 및 프로세스 자동화와 같은 여러 도메인에 걸쳐 확장 가능한 AI/ML 솔루션을 구축하고 있습니다. 그는 Fortune 500대 기업의 선도적인 데이터 과학 프로젝트에서 여러 신생 기업의 데이터 과학 인큐베이터의 창립 멤버가 되기까지 스펙트럼의 양쪽 끝에서 일했습니다. 그는 다양한 혁신적인 제품과 서비스를 개척했으며 섬기는 리더십을 신봉합니다.
실물. 허가를 받아 다시 게시했습니다.

