검색이 NLP에서 가장 큰 문제라는 것을 깨닫는 데 오랜 시간이 걸렸습니다. Google, Amazon 및 Bing을 살펴보십시오. 이들은 강력한 검색 엔진으로 인해 수십억 달러 규모의 비즈니스가 가능합니다.
검색에 대한 나의 초기 생각은 감독되지 않은 ML을 중심으로했지만 Microsoft 해커 톤 2018 Bing을 위해 딥 러닝으로 검색 엔진을 만들 수있는 다양한 방법을 알게되었습니다.
이 기사에서 다루는 주제는 다음과 같습니다.
NLP 애플리케이션에 대한 심층적 인 기술 교육이 유용하다고 생각하십니까? 새로운 관련 콘텐츠를 공개 할 때 업데이트하려면 아래를 구독하십시오..
클래식 검색 엔진
검색 프로세스는 4 단계로 나눌 수 있습니다.
- 검색어 자동 완성 — 입력 한 첫 문자를 기반으로 검색어 제안
- 쿼리 필터링 — 토큰 제거, 형태소 분석 및 낮추기
- 쿼리 기능 보강 — 동의어 및 약어 수축 / 확장 추가
- 문서 채점 — 점수 매기기 메커니즘에 따른 점수 (문서 | 쿼리) BM25
이제 이러한 단계를 설명하는 데 시간을 허비하지 않고 가장 인기있는 검색 엔진 인 Lucene과 같은 클래식 검색 엔진의 단점에 대해 논의하기 시작합니다.
문제 1 : 토큰 매칭
최고의 책을 찾는 데 관심이 있다고 상상해보십시오 역 전파. 사용자 리뷰에 따르면, Ian Goodfellow et al. 주제와 주제를 둘러싼 다른 사람들에게 최고로 간주됩니다. 그러나 사이에 단어가 완전히 일치하지 않습니다. 쿼리 : 역 전파 및 문서 제목 : 딥 러닝. 다음은 amazon.com의 결과입니다. 딥 러닝 북은 없습니다!

'Backpropagation'쿼리 결과
딥 러닝을 검색하면 맨 위에 책이 표시됩니다.

'딥 러닝'쿼리 결과
이것은 하드 토큰 매칭의 문제입니다.
문제 2 : 맥락화
위의 예제는 쿼리 딥 러닝과 함께 작동합니다. 이론을 읽는 대신 실용적인 예를 가진 책을 읽는 것을 좋아한다면 어떨까요? 이것은 우리를 주제로 상황 별 검색. 이 경우이 책들은 나에게 완벽했습니다. 그렇지 않습니까?

'신경망'학습을위한 실용적인 책

'신경망'학습을위한 또 다른 실용적인 책
NLP를 검색 할 때 왜 NLP (Neuuro-Languistic Programming)에 관한 책을 보는가? 상황에 맞는 검색으로 해결할 수 있습니다. 검색 엔진이 컴퓨터 과학에 관한 책을 구매한다는 사실을 알게되면 자연어 처리에 대한 책을 대신 보여줄 것입니다.

And I get these when I search GAN. Again an issue of non-personalisation.

문제 3 : 쿼리 오해
검색어 : x가 y에 미치는 영향 첫 학술 논문 결과 : x에 대한 a의 영향
즉, 학문에 대한 Bernhard의 영향을 찾는 것이 아니라 첫 번째 논문은 Herbart의 Bernhard에 대한 영향에 관한 것입니다.

14 년 2019 월 XNUMX 일에 검색 됨
토큰 일치 엔진은 단어 순서를 고려하지 않기 때문에 잘못된 결과가 발생할 수 있습니다. 😞
그러나 Google의 유사한 검색어 제안이 더 좋습니다!

14 년 2019 월 XNUMX 일에 검색 됨
문제 4 : 이미지 검색
마지막으로, 텍스트로 이미지를 검색 할 수있는 유일한 방법은 설명이나 태그가있는 모든 이미지의 메타 데이터를 생성하는 것입니다. 실제로는 불가능합니다.
측정 항목에 미치는 영향은 무엇입니까?
이로 인해 지표가 악영향을받습니다.
하드 토큰 일치 → LESS RECALL
문맥 부재 → LESS PRECISION
검색을위한 딥 러닝 🔥
토큰 일치와 관련된 문제점을 이해 했으므로 딥 러닝을 사용하여 검색하는 방법에 대해 논의 할 수 있습니다. 내 생각은 책을 기반으로 검색을위한 딥 러닝 Tommaso Teofili가 작성했습니다.
해결 방법 1 : 동의어 생성
Elasticsearch의 사용자 지정 사전을 통해 동의어 단어로 단어를 보강하면 토큰 일치 문제를 해결할 수 있습니다. 이를 위해 동의어가 필요한 단어를 수동으로 찾아서 동의어도 찾아야합니다. 시작하기는 쉽지만 유지 관리가 어렵습니다. 대신 여기에서 딥 러닝을 활용할 수 있습니다! 먼저 Spacy와 같은 라이브러리를 사용하여 POS (Part of speech)를 찾고 POS (Part of speech)를 명사, 동사 또는 형용사로 사용하는 단어와 동의어를 얻습니다. 동의어가 너무 많거나 관련되지 않도록 유사한 단어를 선택하기 위해 코사인 유사성을 차단해야합니다.
동의어 확대 기능을 사용하면 리콜을 개선하는 데 도움이 될 수 있지만 정밀도도 떨어질 수 있습니다.
주의 ❌
여기에서는 특정 단어를 보강하지 않도록주의해야합니다. 놀랍게도 word2vec에 따라 'good'에 가장 가까운 단어는 'bad'와 'poor'입니다. 특정 경우 결과가 변경 될 수 있습니다. 😅
당신은 시도 할 수 있습니다 https://projector.tensorflow.org
word2vec에 따라 '놀라운'에 가장 가까운 단어는 '어메이징 스파이더 맨'영화에서 나오는 '거미'입니다. 이것은 놀라운 결과를 초래할 수 있습니다
해결 방법 2 : 쿼리 자동 완성
완성 된 쿼리가 빈 결과를 내지 않도록 입력하는 동안 사용자가 쿼리를 바로 완료하도록 도와주십시오. Elasticsearch에는 쿼리 자동 완성 기능이 있지만 유한 자동 마타입니다. 색인에 표시되지 않은 문자 순서를 입력하면 결과가 표시되지 않습니다. 언어 모델 (LM)의 경우 생성이 유한하지 않습니다. (모델이 짧은 시퀀스에 대해 훈련 된 경우 더 긴 쿼리에 대해 LM 생성에 실패 할 수 있음)
결과가 비어 있지 않은 쿼리를 자동 완성하는 기능은 사용자 경험을 크게 변경하고 이탈을 피할 수 있습니다.
속임수 : 결과를 제공하지 않는 쿼리를 제안 할 필요가 없기 때문에 빈 결과를 반환하는 교육에서 해당 쿼리를 제거합니다.
해결 방법 3 : 대체 쿼리 생성
사용자 세션의 쿼리 로그가 있으면 생성 모델을 생성하여 다음 쿼리 | 현재 쿼리를 생성 할 수 있습니다. 세션의 모든 쿼리가 서로 유사하다는 가설이 있습니다. 로그는 이와 같을 수 있습니다.
- 인공 지능
- 텐서 플로우
- 신경망
- ...
교육 데이터 (x, y) (인공 지능, Tensorflow) (Tensorflow, 신경망)
쿼리 생성은 사용자의 구매 의도를 이해함으로써 관련 쿼리를 제안하는 데 도움이 될 수 있습니다.
해결 방법 4 : 단어 및 문서 임베딩 사용
사용자가 입력 한 쿼리를 one-hot 또는 TF-IDF 정규화 형식으로 표시하는 대신 몇 가지 접근 방식을 사용하여 단어, 문장 및 문서를 벡터화 할 수 있습니다.
- 간단한 임베딩 평균
- IDF 값을 곱하여 가중 포함 평균
- 유추, USE (Universal 문장 엔코더), 문장-버트와 같은 모델을 사용하여 문장 삽입
- seq2seq 자동 인코더
이것은 모든 토큰을 시맨틱 및 압축 어휘 크기에 상관없이 고정된 크기의 벡터 형태입니다. 이를 위해서는 모델을 사용하여 벡터화하는 일회성 오버헤드가 필요하지만 이후의 모든 검색은 n차원의 벡터 검색이 됩니다. 벡터 검색의 최신 기술은 다음과 같습니다.&nb
sp;밀 버스. 용 대략적인 가장 가까운 이웃 당신은 측면과 성가신을 사용할 수 있습니다.
솔루션 5 : 상황화
상황 별 / 맞춤 설정을 위해 검색 엔진에서 고려해야 할 요소
- 사용자 이력 — 과거 검색의 관심사 및 과거에 동일한 검색을 한 경우 클릭 한 항목
- 사용자 지리 — '대통령'이라는 단어를 검색하면 '람 나스 코빈 트'가 나옵니다 → 현재 인도 대통령
- 정보의 일시적인 변화 — 쿼리 '대통령'의 결과는 시간이 지남에 따라 변경됩니다
각 클릭을 고정 벡터로 인코딩하고 점수를 생성하여 사용자 기록을 사용할 수 있습니다 (document | history + query)
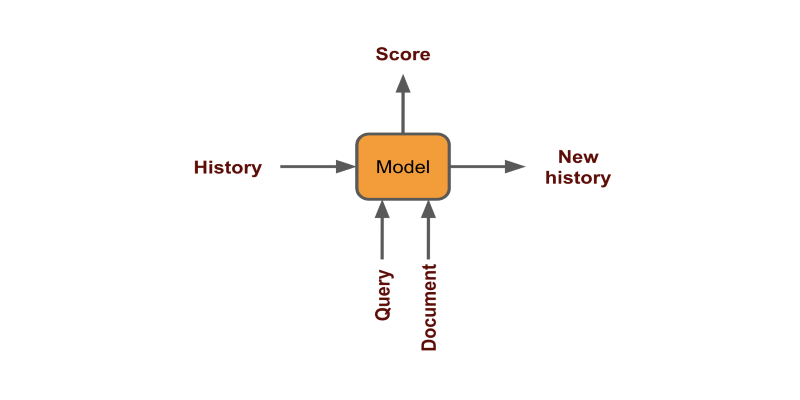
지리 및 시간은 모델을 학습하는 동안 기능을 필터링하거나 기능으로 추가하여 처리 할 수 있습니다.
맞춤 설정을 통해 사용자에게 인간 수준의 제안을 제공하여 전환을 개선 할 수 있습니다.
해결책 6 : 순위를 정하는 법
TF-IDF 체계에서 토큰 매칭의 결함으로 인해, 결과를 재평가 할 수있는 계층이 실제로 필요합니다. 이 체계는 드문 단어에 대한 편견이 높으며 기사의 변환 가능성을 설명하지 않습니다. 사용자 쿼리 로그와 검색 결과에서 클릭 한 내용이있는 경우 모델 순위를 지정하여 문서 순위를 지정할 수 있습니다. 데이터는 다음과 같습니다. (x, y) (인공 지능, 제 2 권 제목) (Tensorflow, 제 1 권 제목) (Neural Networks, 제 4 권 제목) 다음에 결과를 보여주고 싶을 때, 저렴한 토큰 매칭 프로세스에서 먼저 최상위 x 결과를 얻습니다. TF-IDF / BM25를 통해 대부분 Elasticsearch를 통해 모든 쌍에 대한 점수를 생성합니다. (x, y)
- (조회, 제목 1) → 1 점
- (조회, 제목 2) → 2 점
- ...
그런 다음 제목별로 점수를 정렬하고 상위 결과를 표시합니다. 내 BERT를 사용 하여이 구현을 찾을 수 있습니다. github.

NSP 헤드가있는 BERT
문제를 BERT NextSentencePrediction 문제 (일명 수반 문제)로 평가하는 학습을 정의 할 수 있습니다.
해결책 7 : 앙상블
대부분의 경우 두 가지 접근 방식을 모두 활용하는 것이 좋습니다. 이 책에서는 워드 벡터와 BM25의 조합 된 점수를 사용하는 것이 가장 효과적이라고 언급합니다.

'검색을위한 심층 학습'에서
Ensemble을 사용하면 접근 방식이 어려운 토큰 일치 + 의미를 모두 활용할 수 있습니다.
해결 방법 8 : 다국어 검색
접근법 1

응용 프로그램이 지역 전체에있는 경우 사용자의 언어가 문서와 다를 수 있습니다. 다른 언어의 토큰이 일치 할 수 없으므로 고전적인 검색 방식으로는 이러한 검색이 불가능합니다. 이를 위해서는 딥 러닝을 통한 기계 번역의 도움이 필요합니다.
- 사용자 쿼리 언어 감지 (예 : 프랑스어)
- 문서가있는 모든 언어로 쿼리 번역 (프랑스어, 영어, 독일어 및 스페인어)
- 문서 검색
- 최고 점수를받은 모든 문서를 사용자 언어로 번역합니다 (영어, 독일어 및 스페인어를 프랑스어로)
접근법 2
대신 다국어 문장 인코더를 사용하여 모든 언어의 텍스트를 유사한 벡터로 나타낼 수 있습니다. 이 접근 방식을 자세히 살펴 보겠습니다.
다국어 범용 문장 인코더
POC를 수행하기 위해 다음 구성 요소를 사용하고 있습니다.
- 모델 — 다국어 범용 문장 인코더
- 벡터 검색 — 파이스
- Data — Quora 질문 쌍 카글
USE에 대한 자세한 내용은 이 종이. 16 개 언어를 지원합니다.
1 단계. 데이터로드
먼저 데이터를 읽겠습니다. quora 데이터 세트는 방대하고 많은 시간이 걸리기 때문에 데이터의 1 % 만 사용합니다. 인코딩 및 인덱싱에는 약 3 분이 걸립니다. 4000 개의 질문이 있습니다.
df = pd.read_csv('quora-question-pairs/train.csv')
df = df.sample(frac=0.01, random_state=1)
df.dropna(inplace=True)
questions = df.question1.values
2 단계. 인코더 만들기
모델을로드하고 인코딩 방법을 갖는 인코더 클래스를 만들어 봅시다. 사용할 수있는 다른 모델에 대한 클래스를 만들었습니다. 모든 모델은 영어로 작동하며 다국어 사용은 다른 언어와 만 작동합니다.
USE는 512 크기의 고정 벡터로 텍스트를 인코딩합니다.
모델을로드하기 위해 TFHub를 USE로 사용하고 BERT를 위해 Flair를 사용하고 있습니다.
class TFEncoder(metaclass=ABCMeta): """Base encoder to be used for all encoders.""" def __init__(self, model_path:str): self.model = hub.load(model_path) @abstractmethod def encode(self, text:list): """Encodes text. Text: should be a list of strings to encode """ class USE(TFEncoder): """Universal sentence encoder""" def __init__(self, model_path): super().__init__(model_path) def encode(self, text): return self.model(text).numpy() class USEQA(TFEncoder): """Universal sentence encoder trained on Question Answer pairs""" def __init__(self, model_path): super().__init__(model_path) def encode(self, text): return self.model.signatures['question_encoder'](tf.constant(s))['outputs'].numpy() class BERT(): """BERT models""" def __init__(self, model_name, layers="-2", pooling_operation="mean"): self.embeddings = BertEmbeddings(model_name, layers=layers, pooling_operation=pooling_operation) self.document_embeddings = DocumentPoolEmbeddings([self.embeddings], fine_tune_mode='nonlinear') def encode(self, text): sentence = Sentence(text) self.document_embeddings.embed(sentence) return sentence.embedding.detach().numpy().reshape(1, -1) model_path = "https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3" encoder = USE(model_path)
3 단계. 색인 작성
이제 빠른 벡터 검색을 위해 모든 임베딩을 효율적으로 저장하는 FAISS 인덱서 클래스를 만듭니다.
class FAISS: def __init__(self, dimensions:int): self.dimensions = dimensions self.index = faiss.IndexFlatL2(dimensions) self.vectors = {} self.counter = 0 def add(self, text:str, v:list): self.index.add(v) self.vectors[self.counter] = (text, v) self.counter += 1 def search(self, v:list, k:int=10): distance, item_index = self.index.search(v, k) for dist, i in zip(distance[0], item_index[0]): if i==-1: break else: print(f'{self.vectors[i][0]}, %.2f'%dist)
4 단계. 인코딩과 색인
모든 질문에 대한 임베딩을 만들어 FAISS에 저장합시다. 우리는 검색어가 주어진 k 개의 유사한 결과를 보여주는 검색 방법을 정의합니다.
d = encoder.encode(['hello']).shape[-1] # get dimension of emb index = FAISS(d) #index all questions for q in tqdm(questions): emb = encoder.encode([q]) index.add(q, emb) # embed and search a question def search(s, k=10): emb = encoder.encode([s]) index.search(emb, k)
5 단계. 검색
아래에서 모델의 결과를 볼 수 있습니다. 먼저 영어로 질문을 작성하면 예상되는 결과를 얻을 수 있습니다. 그런 다음 Google Translate를 사용하여 쿼리를 다른 언어로 변환하면 결과가 다시 훌륭합니다. 비록 'lose'대신 'loose'를 쓰는 철자 실수를했지만 모델은 그것이 하위 단어 수준에서 작동하고 상황에 따라 이해합니다.

보시다시피 결과는 인상적이므로 모델을 생산할 가치가 있습니다.
당신은 완전한 코드를 찾을 수 있습니다 내 콜라 보 노트북. 에서 데이터를 다운로드 할 수 있습니다 여기에서 지금 확인해 보세요..
더 나은 모델을 만들려면 전이 학습을 사용하여 데이터의 언어 모델을 조정해야합니다. 당신은 내에서 그것에 대해 더 읽을 수 있습니다 마지막 기사.
Audiencegain과 여기에서 지금 확인해 보세요. 시맨틱 검색을 위해 텍스트를 인코딩하기위한 다양한 모델에 대해 자세히 읽을 수 있습니다.
결론
최근 Google은 검색 결과를 향상시키기 위해 프로덕션에서 BERT 기반 구현을 추진했음을 이미 알고있을 것입니다. 시맨틱 검색이 증가하고 있으며 검색을위한 딥 러닝 활용에 대한 이해가 높아짐에 따라 업계에서 일반적으로 사용될 것으로 보입니다.
이 도움말은 원래 매체 (일부 1 및 일부 2) 및 저자의 허가를 받아 TOPBOTS에 다시 게시했습니다.
이 기사를 즐기십니까? 더 많은 AI 및 NLP 업데이트에 가입하십시오.
보다 심층적 인 기술 교육을 발표 할 때 알려 드리겠습니다.

