15년 2024월 XNUMX일(나노 워크 뉴스) 병리학적 성대 질환이 있거나 후두암 수술에서 회복 중인 사람을 포함하여 음성 장애가 있는 사람은 말하는 것이 어렵거나 불가능할 수 있습니다. 그것은 곧 바뀔 수도 있습니다. UCLA 엔지니어 팀은 성대 기능 장애가 있는 사람들이 음성 기능을 회복할 수 있도록 목 바깥쪽 피부에 부착할 수 있는 1평방인치가 조금 넘는 크기의 부드럽고 얇고 신축성이 있는 장치를 발명했습니다. 그들의 진전은 일지에 자세히 설명되어 있습니다. 자연 통신 (“머신러닝 기반 웨어러블 감지 작동 시스템을 사용해 성대 없이 말하기”). UCLA Samueli 공과대학의 생명공학 조교수인 Jun Chen과 그의 동료들이 개발한 새로운 생체전기 시스템은 기계의 도움을 받아 사람의 후두 근육의 움직임을 감지하고 그 신호를 가청 음성으로 변환할 수 있습니다. 학습 기술 — 거의 95%의 정확도. 이번 혁신은 장애인을 돕기 위한 Chen의 노력 중 가장 최근에 이루어진 것입니다. 그의 팀은 이전에 ASL 사용자가 수화 방법을 모르는 사람들과 의사소통할 수 있도록 돕기 위해 미국 수화를 실시간으로 영어 음성으로 번역할 수 있는 웨어러블 장갑을 개발했습니다. 작은 새 패치형 장치는 두 가지 구성 요소로 구성됩니다. 하나는 자체 전력 감지 구성 요소로, 근육 움직임에 의해 생성된 신호를 감지하고 충실도가 높은 분석 가능한 전기 신호로 변환합니다. 이러한 전기 신호는 기계 학습 알고리즘을 사용하여 음성 신호로 변환됩니다. 다른 하나는 작동 구성요소로 이러한 음성 신호를 원하는 음성 표현으로 변환합니다. 두 구성 요소는 각각 탄성 특성을 지닌 생체 적합성 실리콘 화합물인 폴리디메틸실록산(PDMS) 층과 구리 유도 코일로 만들어진 자기 유도 층이라는 두 개의 층을 포함합니다. 두 구성 요소 사이에는 자기장을 생성하는 미세 자석과 혼합된 PDMS를 포함하는 다섯 번째 층이 있습니다.
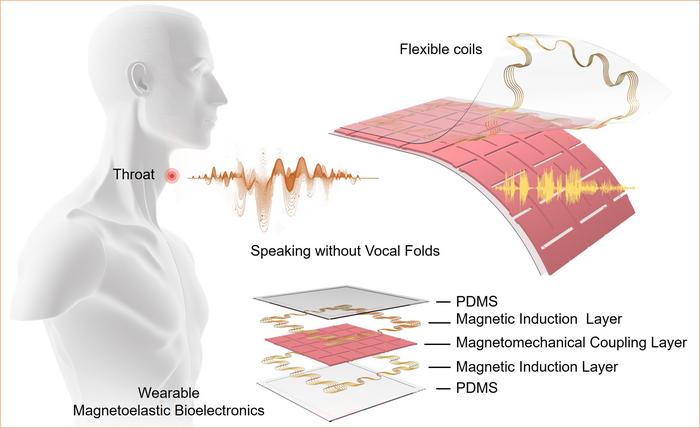 장치의 2021개 구성 요소와 XNUMX개 층으로 구성된 이 장치는 근육 움직임을 전기 신호로 전환할 수 있으며, 이는 기계 학습의 도움을 받아 궁극적으로 음성 신호와 가청 음성 표현으로 변환됩니다. (이미지: Jun Chen Lab/UCLA) Chen 팀이 XNUMX년에 개발한 연자기탄성 감지 메커니즘을 활용(자연 재료, “생체전자공학용 소프트 시스템의 거대한 자기탄성 효과”), 장치는 기계적 힘(이 경우 후두 근육의 움직임)의 결과로 자기장이 변경될 때 자기장의 변화를 감지할 수 있습니다. 자기탄성층에 내장된 구불구불한 유도 코일은 감지 목적을 위해 충실도가 높은 전기 신호를 생성하는 데 도움이 됩니다. 각 측면의 길이는 1.2인치이고 무게는 약 7g이며 두께는 0.06인치에 불과합니다. 양면 생체적합성 테이프를 사용하여 개인의 목구멍 성대 근처에 쉽게 부착할 수 있으며 필요에 따라 테이프를 다시 부착하여 재사용할 수 있습니다. 음성 장애는 모든 연령층과 인구통계학적 그룹에 걸쳐 널리 퍼져 있습니다. 연구에 따르면 거의 30%의 사람들이 일생 동안 적어도 한 번은 그러한 장애를 경험하게 되는 것으로 나타났습니다. 그러나 외과적 개입 및 음성 치료와 같은 치료적 접근 방식을 사용하면 음성 회복이 XNUMX개월에서 XNUMX년까지 길어질 수 있으며, 일부 침습적 기술에서는 수술 후 상당한 기간의 필수 음성 휴식이 필요합니다. UCLA의 웨어러블 생체전자 공학 연구 그룹을 이끌고 있으며 XNUMX년 동안 세계에서 가장 많이 인용되는 연구자 중 한 명으로 선정된 Chen은 "휴대용 전기후두 장치 및 기관식도 천자 절차와 같은 기존 솔루션은 불편하거나 침습적이거나 불편할 수 있습니다"라고 말했습니다. 행. "이 새로운 장치는 음성 장애에 대한 치료 전 기간과 치료 후 회복 기간 동안 환자의 의사소통을 도울 수 있는 착용 가능한 비침습적 옵션을 제공합니다."
장치의 2021개 구성 요소와 XNUMX개 층으로 구성된 이 장치는 근육 움직임을 전기 신호로 전환할 수 있으며, 이는 기계 학습의 도움을 받아 궁극적으로 음성 신호와 가청 음성 표현으로 변환됩니다. (이미지: Jun Chen Lab/UCLA) Chen 팀이 XNUMX년에 개발한 연자기탄성 감지 메커니즘을 활용(자연 재료, “생체전자공학용 소프트 시스템의 거대한 자기탄성 효과”), 장치는 기계적 힘(이 경우 후두 근육의 움직임)의 결과로 자기장이 변경될 때 자기장의 변화를 감지할 수 있습니다. 자기탄성층에 내장된 구불구불한 유도 코일은 감지 목적을 위해 충실도가 높은 전기 신호를 생성하는 데 도움이 됩니다. 각 측면의 길이는 1.2인치이고 무게는 약 7g이며 두께는 0.06인치에 불과합니다. 양면 생체적합성 테이프를 사용하여 개인의 목구멍 성대 근처에 쉽게 부착할 수 있으며 필요에 따라 테이프를 다시 부착하여 재사용할 수 있습니다. 음성 장애는 모든 연령층과 인구통계학적 그룹에 걸쳐 널리 퍼져 있습니다. 연구에 따르면 거의 30%의 사람들이 일생 동안 적어도 한 번은 그러한 장애를 경험하게 되는 것으로 나타났습니다. 그러나 외과적 개입 및 음성 치료와 같은 치료적 접근 방식을 사용하면 음성 회복이 XNUMX개월에서 XNUMX년까지 길어질 수 있으며, 일부 침습적 기술에서는 수술 후 상당한 기간의 필수 음성 휴식이 필요합니다. UCLA의 웨어러블 생체전자 공학 연구 그룹을 이끌고 있으며 XNUMX년 동안 세계에서 가장 많이 인용되는 연구자 중 한 명으로 선정된 Chen은 "휴대용 전기후두 장치 및 기관식도 천자 절차와 같은 기존 솔루션은 불편하거나 침습적이거나 불편할 수 있습니다"라고 말했습니다. 행. "이 새로운 장치는 음성 장애에 대한 치료 전 기간과 치료 후 회복 기간 동안 환자의 의사소통을 도울 수 있는 착용 가능한 비침습적 옵션을 제공합니다."
 웨어러블 기술은 피부 아래 후두 근육의 활동을 포착하고 함께 움직일 수 있을 만큼 유연하도록 설계되었습니다. (이미지 : Jun Chen Lab/UCLA)
머신러닝으로 웨어러블 기술을 구현하는 방법
실험에서 연구원들은 94.68명의 건강한 성인을 대상으로 웨어러블 기술을 테스트했습니다. 그들은 후두 근육 움직임에 대한 데이터를 수집하고 기계 학습 알고리즘을 사용하여 결과 신호를 특정 단어와 연관시켰습니다. 그런 다음 장치의 작동 구성 요소를 통해 해당 출력 음성 신호를 선택했습니다. 연구팀은 참가자들에게 "안녕, 레이첼, 오늘은 어때?"를 포함해 XNUMX개의 문장(안녕하세요, 레이첼, 잘 지내세요?)을 큰소리로, 무성적으로 발음하게 하여 시스템의 정확성을 입증했습니다. 그리고 난 당신을 사랑합니다!" 모델의 전체 예측 정확도는 XNUMX%였으며, 참가자의 음성 신호는 작동 구성요소에 의해 증폭되어 감지 메커니즘이 후두 움직임 신호를 인식하고 참가자가 말하고 싶은 해당 문장과 일치함을 입증했습니다. 연구팀은 앞으로도 머신러닝을 통해 장치의 어휘력을 지속적으로 확장하고 언어 장애가 있는 사람들을 대상으로 테스트할 계획이다.
웨어러블 기술은 피부 아래 후두 근육의 활동을 포착하고 함께 움직일 수 있을 만큼 유연하도록 설계되었습니다. (이미지 : Jun Chen Lab/UCLA)
머신러닝으로 웨어러블 기술을 구현하는 방법
실험에서 연구원들은 94.68명의 건강한 성인을 대상으로 웨어러블 기술을 테스트했습니다. 그들은 후두 근육 움직임에 대한 데이터를 수집하고 기계 학습 알고리즘을 사용하여 결과 신호를 특정 단어와 연관시켰습니다. 그런 다음 장치의 작동 구성 요소를 통해 해당 출력 음성 신호를 선택했습니다. 연구팀은 참가자들에게 "안녕, 레이첼, 오늘은 어때?"를 포함해 XNUMX개의 문장(안녕하세요, 레이첼, 잘 지내세요?)을 큰소리로, 무성적으로 발음하게 하여 시스템의 정확성을 입증했습니다. 그리고 난 당신을 사랑합니다!" 모델의 전체 예측 정확도는 XNUMX%였으며, 참가자의 음성 신호는 작동 구성요소에 의해 증폭되어 감지 메커니즘이 후두 움직임 신호를 인식하고 참가자가 말하고 싶은 해당 문장과 일치함을 입증했습니다. 연구팀은 앞으로도 머신러닝을 통해 장치의 어휘력을 지속적으로 확장하고 언어 장애가 있는 사람들을 대상으로 테스트할 계획이다.
장치의 2021개 구성 요소와 XNUMX개 층으로 구성된 이 장치는 근육 움직임을 전기 신호로 전환할 수 있으며, 이는 기계 학습의 도움을 받아 궁극적으로 음성 신호와 가청 음성 표현으로 변환됩니다. (이미지: Jun Chen Lab/UCLA) Chen 팀이 XNUMX년에 개발한 연자기탄성 감지 메커니즘을 활용(자연 재료, “생체전자공학용 소프트 시스템의 거대한 자기탄성 효과”), 장치는 기계적 힘(이 경우 후두 근육의 움직임)의 결과로 자기장이 변경될 때 자기장의 변화를 감지할 수 있습니다. 자기탄성층에 내장된 구불구불한 유도 코일은 감지 목적을 위해 충실도가 높은 전기 신호를 생성하는 데 도움이 됩니다. 각 측면의 길이는 1.2인치이고 무게는 약 7g이며 두께는 0.06인치에 불과합니다. 양면 생체적합성 테이프를 사용하여 개인의 목구멍 성대 근처에 쉽게 부착할 수 있으며 필요에 따라 테이프를 다시 부착하여 재사용할 수 있습니다. 음성 장애는 모든 연령층과 인구통계학적 그룹에 걸쳐 널리 퍼져 있습니다. 연구에 따르면 거의 30%의 사람들이 일생 동안 적어도 한 번은 그러한 장애를 경험하게 되는 것으로 나타났습니다. 그러나 외과적 개입 및 음성 치료와 같은 치료적 접근 방식을 사용하면 음성 회복이 XNUMX개월에서 XNUMX년까지 길어질 수 있으며, 일부 침습적 기술에서는 수술 후 상당한 기간의 필수 음성 휴식이 필요합니다. UCLA의 웨어러블 생체전자 공학 연구 그룹을 이끌고 있으며 XNUMX년 동안 세계에서 가장 많이 인용되는 연구자 중 한 명으로 선정된 Chen은 "휴대용 전기후두 장치 및 기관식도 천자 절차와 같은 기존 솔루션은 불편하거나 침습적이거나 불편할 수 있습니다"라고 말했습니다. 행. "이 새로운 장치는 음성 장애에 대한 치료 전 기간과 치료 후 회복 기간 동안 환자의 의사소통을 도울 수 있는 착용 가능한 비침습적 옵션을 제공합니다."
웨어러블 기술은 피부 아래 후두 근육의 활동을 포착하고 함께 움직일 수 있을 만큼 유연하도록 설계되었습니다. (이미지 : Jun Chen Lab/UCLA)
머신러닝으로 웨어러블 기술을 구현하는 방법
실험에서 연구원들은 94.68명의 건강한 성인을 대상으로 웨어러블 기술을 테스트했습니다. 그들은 후두 근육 움직임에 대한 데이터를 수집하고 기계 학습 알고리즘을 사용하여 결과 신호를 특정 단어와 연관시켰습니다. 그런 다음 장치의 작동 구성 요소를 통해 해당 출력 음성 신호를 선택했습니다. 연구팀은 참가자들에게 "안녕, 레이첼, 오늘은 어때?"를 포함해 XNUMX개의 문장(안녕하세요, 레이첼, 잘 지내세요?)을 큰소리로, 무성적으로 발음하게 하여 시스템의 정확성을 입증했습니다. 그리고 난 당신을 사랑합니다!" 모델의 전체 예측 정확도는 XNUMX%였으며, 참가자의 음성 신호는 작동 구성요소에 의해 증폭되어 감지 메커니즘이 후두 움직임 신호를 인식하고 참가자가 말하고 싶은 해당 문장과 일치함을 입증했습니다. 연구팀은 앞으로도 머신러닝을 통해 장치의 어휘력을 지속적으로 확장하고 언어 장애가 있는 사람들을 대상으로 테스트할 계획이다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.nanowerk.com/news2/robotics/newsid=64863.php

