고성능 딥 러닝 : 더 작고 빠르며 더 나은 모델을 훈련하는 방법 – 3 부
이제 올바른 소프트웨어 및 하드웨어 도구를 사용하여 고급 딥 러닝 모델을 효율적으로 구축 할 준비가되었으므로 모델 품질을 개선하고 조직이 원하는 성능을 얻기 위해 이러한 노력을 구현하는 데 관련된 기술을 탐색해야합니다.

이전 부분 (파트 1 & 파트 2), 우리는 딥 러닝 모델이 최적의 고성능 모델을 달성하기 위해 효율성이 중요한 이유와 딥 러닝의 효율성을위한 초점 영역에 대해 논의했습니다. 이제 이러한 초점 영역에 해당하는 도구와 기술의 예를 더 자세히 살펴 보겠습니다.
압축 기술
앞에서 언급했듯이 압축 기술은 가능한 품질 균형을 유지하면서 신경망에서 하나 이상의 계층을보다 효율적으로 표현하는 데 도움이되는 일반적인 기술입니다. 효율성은 모델 크기, 추론 지연 시간, 컨버전스에 필요한 훈련 시간 등과 같은 하나 이상의 풋 프린트 메트릭을 개선하여 가능한 한 적은 품질 손실을 줄 수 있습니다. 종종 모델이 초과 매개 변수화 될 수 있습니다. 이러한 경우 이러한 기술은 보이지 않는 데이터에 대한 일반화도 개선하는 데 도움이됩니다.
전정: 널리 사용되는 압축 기술 중 하나는 Pruning입니다. 치다 중요하지 않은 네트워크 연결로 인해 네트워크가 부족한. LeCun et al. Optimal Brain Damage라는 논문에서 [1]은 추론 속도와 일반화를 모두 높이면서 신경망의 매개 변수 (계층 간 연결) 수를 XNUMX 배 줄였습니다.

신경망에서 가지 치기의 그림.
유사한 접근법이 Hassibi et al.의 Optimal Brain Surgeon 작업 (OBD)에 이어졌습니다. [2] 및 Zhu et al. [삼]. 이러한 방법은 합리적인 품질로 사전 훈련 된 네트워크를 가져온 다음 가장 낮은 매개 변수를 반복적으로 제거합니다. 현출 특정 연결의 중요성을 측정하여 유효성 손실에 대한 영향을 최소화합니다. 가지 치기가 끝나면 나머지 매개 변수를 사용하여 네트워크가 미세 조정됩니다. 네트워크가 원하는 수준으로 정리 될 때까지 프로세스가 반복됩니다.
가지 치기에 대한 다양한 작업 중에서 다음과 같은 차원에서 차이가 발생합니다.
- 돌출: 정리할 연결을 결정하기위한 휴리스틱입니다. 이는 손실 함수에 대한 연결 가중치의 1 차 도함수 [2, 3], 연결 가중치의 크기 [XNUMX] 등을 기반으로 할 수 있습니다.
- 비정형 vs 구조화 : 가장 유연한 가지 치기 방법은 모든 주어진 매개 변수가 동일하게 처리되는 구조화되지 않은 (또는 무작위) 가지 치기입니다. 구조적 가지 치기에서 매개 변수는 크기가 1보다 큰 블록에서 잘라냅니다 (예 : 가중치 행렬에서 행 단위로 잘라 내기 또는 컨볼 루션 필터에서 채널 단위로 잘라 내기 (예 : [4,5])). 구조화 된 잘라내기를 사용하면 추론 시간을 더 쉽게 활용할 수 있습니다. 정리 된 매개 변수 블록은 저장 및 추론을 위해 지능적으로 건너 뛸 수 있기 때문에 크기와 지연 시간이 증가합니다.

각각 가중치 행렬의 구조화되지 않은 대 구조화 된 가지 치기.
- 콘텐츠 배급: 각 레이어에 대해 동일한 가지 치기 예산을 설정하거나 레이어별로 할당 할 수 있습니다 [6]. 직관은 특정 레이어가 다른 레이어보다 가지 치기가 더 쉽다는 것입니다. 예를 들어, 종종 처음 몇 개의 레이어는 상당한 희소성을 견딜 수 없을 정도로 이미 충분히 작습니다 [7].
- 예약: 그러나 추가 기준은 가지 치기 할 양과시기입니다. 매 라운드마다 동일한 수의 매개 변수를 가지 치기를 원합니까 [8] 아니면 처음에는 더 높은 속도로 가지 치기를하고 점차적으로 느리게합니까 [9]?
- 재성장: 어떤 경우에는 네트워크가 프 루닝 된 연결을 다시 늘릴 수 있도록 허용하여 [9] 네트워크가 프 루닝 된 동일한 비율의 연결로 지속적으로 작동합니다.
실제 사용 측면에서 의미있는 블록 크기의 구조적 정리는 지연 시간을 개선하는 데 도움이 될 수 있습니다. Elsen et al. [7] 동일한 Top-1.3 정확도를 유지하면서 매개 변수의 ≈ 2.4 %를 사용하여 고밀도 대응 네트워크를 66 – 1 배 능가하는 희소 합성 곱 네트워크를 구성합니다. 이들은 라이브러리를 통해이를 수행하여 NHWC (채널-마지막) 표준 밀도 표현을 특수 NCHW (채널 우선) '블록 압축 스파 스 행'(BCSR) 표현으로 변환합니다. 이는 ARM에서 빠른 커널을 사용하는 빠른 추론에 적합합니다. 장치, WebAssembly 등. [10]. 또한 가속 할 수있는 희소 네트워크의 종류에 대한 몇 가지 제약을 도입합니다. 전반적으로 이것은 프 루닝 된 네트워크를 사용하는 풋 프린트 메트릭의 실질적인 개선을 향한 유망한 단계입니다.
양자화 : 양자화는 또 다른 인기있는 압축 기술입니다. 일반적인 네트워크의 거의 모든 가중치가 32 비트 부동 소수점 값이라는 아이디어를 이용하며, 일부 모델 품질 (정확성, 정밀도, 재현율 등)을 잃어도 괜찮다면 이러한 값을 저장할 수 있습니다. 낮은 정밀도 형식 (16 비트, 8 비트, 4 비트 등).
예를 들어 모델이 지속되면 가중치 행렬의 최소값을 0으로, 최대 값을 2로 매핑 할 수 있습니다.b-1 (여기서 b는 정밀도의 비트 수), 그 사이의 모든 값을 정수 값으로 선형 외삽합니다. 종종 이것은 모델 크기를 줄이는 목적으로 충분할 수 있습니다. 예를 들어 b = 8이면 32 비트 부동 소수점 가중치를 8 비트 부호없는 정수로 매핑합니다. 이로 인해 공간이 4 배 감소합니다. 추론 (모델 예측 계산)을 수행 할 때 양자화 된 값과 배열의 최소 및 최대 부동 소수점 값을 사용하여 원래 부동 소수점 값 (반올림 오류로 인해)의 손실 표현을 복구 할 수 있습니다. 이 단계를 무게 양자화 모델의 가중치를 정량화하고 있기 때문입니다.

연속 고정밀 값을 개별 저 정밀도 정수 값에 매핑합니다. 출처
손실 표현과 반올림 오류는 많은 수의 매개 변수로 인해 중복성이 내장 된 대규모 네트워크에서는 괜찮을 수 있지만 더 작은 네트워크에서는 정확도가 떨어질 수 있으며 이러한 오류에 민감 할 수 있습니다.
훈련 중 가중치 양자화의 반올림 동작을 시뮬레이션하여이 문제를 실험적 방식으로 해결할 수 있습니다. 이를 위해 활성화 및 가중치 행렬을 양자화 및 역 양자화하는 모델 학습 그래프에 노드를 추가하여 신경망 작업에 대한 학습 시간 입력이 추론 단계에서 갖는 것과 동일하게 보입니다. 이러한 노드를 Fake Quantization 노드라고합니다. 이러한 방식으로 훈련하면 추론 모드에서 양자화 동작에 대해 네트워크가 더욱 강력 해집니다. 우리는 활성화 양자화 지금 훈련 중에 가중치 양자화와 함께. 이 훈련 시간 시뮬레이션 양자화 단계는 Jacob et al. 및 Krishnamoorthi et al. [11,12]

원본 모델 학습 그래프와 가짜 양자화 노드가있는 그래프. 출처
가중치와 활성화는 모두 시뮬레이션 된 양자화 모드에서 실행되기 때문에 모든 계층이 낮은 정밀도로 표현 될 수있는 입력을 수신하고 모델이 학습 된 후에는 낮은 정밀도로 직접 수학 연산을 수행 할 수있을만큼 충분히 견고해야합니다. 예를 들어, 8 비트 도메인에서 양자화를 복제하도록 모델을 훈련하면 모델을 배포하여 8 비트 정수로 행렬 곱셈 및 기타 작업을 수행 할 수 있습니다.
리소스가 제한된 장치 (예 : 모바일, 임베디드 및 IoT 장치)에서 8 비트 작업은 Neon intrinsics와 같은 가속화를위한 하드웨어 지원에 의존하는 GEMMLOWP [1.5]와 같은 라이브러리를 사용하여 2 – 13 배 사이에서 가속화 될 수 있습니다. ARM 프로세서 [14]. 또한 Tensorflow Lite와 같은 프레임 워크를 통해 사용자는 하위 수준 구현에 대해 신경 쓰지 않고도 양자화 된 작업을 직접 사용할 수 있습니다.
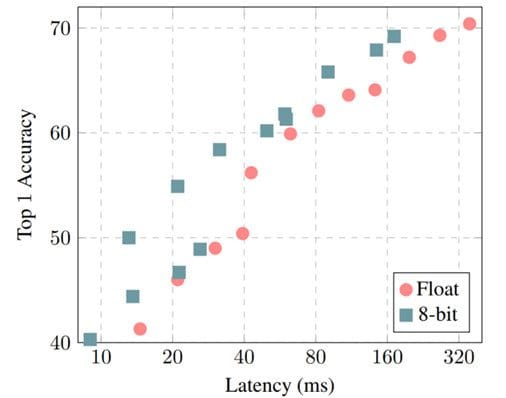
양자화가 있거나없는 모델에 대한 Top-1 정확도 vs. 모델 지연 시간. 출처
Pruning 및 Quantization 외에도 모델 압축에 적극적으로 사용되는 Low-Rank Matrix Factorization, K-Means Clustering, Weight-Sharing 등과 같은 다른 기술이 있습니다 [15].
전반적으로 우리는 압축 기술을 사용하여 모델의 풋 프린트 (크기, 지연 시간 등)를 줄이고 일부 품질 (정확성, 정밀도, 재현율 등)을 대가로 교환 할 수 있음을 확인했습니다.
학습 기법
증류: 앞서 언급했듯이 학습 기술은 더 나은 성능을 얻기 위해 모델을 다르게 학습하려고합니다. 예를 들어, Hinton et al. [16] 그들의 중요한 연구에서, 어떻게 더 작은 네트워크가 추출하도록 가르 칠 수 있는지 탐구했습니다. 어두운 지식 더 큰 모델 / 큰 모델의 앙상블에서. 그들은 더 큰 교사 모델 레이블이 지정된 기존 데이터에 소프트 레이블을 생성합니다.
소프트 레이블은 원래 데이터의 하드 이진 값 대신 가능한 각 클래스에 확률을 할당합니다. 직관은 이러한 소프트 라벨이 모델이 학습 할 수있는 여러 클래스 간의 관계를 포착한다는 것입니다. 예를 들어 트럭은 사과보다 자동차에 더 유사하며 모델은 하드 라벨에서 직접 학습 할 수 없습니다. 학생 네트워크는 원래의 실제 하드 라벨과 함께 이러한 소프트 라벨의 교차 엔트로피 손실을 최소화하는 방법을 배웁니다. 이러한 손실 함수 각각의 가중치는 실험 결과를 기반으로 조정될 수 있습니다.

더 큰 사전 훈련 된 교사 모델에서 더 작은 학생 모델을 추출합니다.
논문에서 Hinton et al. [16]은 음성 인식 작업을위한 10 개 모델 앙상블의 정확도를 단일 증류 모델과 거의 일치시킬 수있었습니다. 작은 모델의 모델 품질이 크게 향상되었음을 보여주는 다른 포괄적 인 연구 [17,18]가 있습니다. 예를 들어, Sanh. et al. [18]은 BERT-Base 성능의 97 %를 유지하면서 CPU에서 40 % 더 작고 60 % 더 빠른 학생 모델을 추출 할 수있었습니다.
데이터 보강: 일반적으로 대규모 모델 및 복잡한 작업의 경우 데이터가 많을수록 모델 성능을 향상시킬 가능성이 높아집니다. 그러나 고품질의 레이블이 지정된 데이터를 얻는 것은 일반적으로 루프에 사람이 필요하므로 느리고 비용이 많이 듭니다. 사람이 라벨링 한이 데이터에서 학습하는 것을지도 학습이라고합니다. 레이블에 대한 비용을 지불 할 자원이있을 때 매우 잘 작동하지만 더 잘할 수 있고해야합니다.
데이터 확장은 모델의 성능을 향상시키는 멋진 방법입니다. 일반적으로 레이블을 다시 지정할 필요가 없도록 데이터를 변환하는 작업이 포함됩니다 (레이블 고정 변환). 예를 들어, 신경망에 개나 고양이가 포함 된 이미지를 분류하도록 가르치는 경우 이미지를 회전해도 레이블이 변경되지 않습니다. 다른 변형으로는 가로 / 세로 뒤집기, 늘리기, 자르기, 가우스 노이즈 추가 등이 있습니다. 마찬가지로 주어진 텍스트의 감정을 감지하는 경우 오타를 입력해도 레이블이 변경되지 않을 수 있습니다.
이러한 레이블 불변 변환은 널리 사용되는 딥 러닝 모델에서 전반적으로 사용되었습니다. 클래스가 많거나 특정 클래스에 대한 예제가 적을 때 특히 유용합니다.

몇 가지 일반적인 유형의 데이터 증가. 출처
Mixup [19]과 같은 다른 변환이 있는데, 두 가지 다른 클래스의 입력을 가중치 방식으로 혼합하고 레이블을 두 클래스의 유사한 가중치 조합으로 취급합니다. 아이디어는 모델이 두 클래스에 관련된 기능을 추출 할 수 있어야한다는 것입니다.
이러한 기술은 실제로 파이프 라인에 데이터 효율성을 도입하고 있습니다. 아이들에게 다른 맥락에서 실제 물건을 식별하도록 가르치는 것과 크게 다르지 않습니다.
자기 주도 학습: 데이터에서 의미를 추출하기위한 라벨의 필요성을 완전히 건너 뛰는 일반 모델을 배울 수있는 인접 영역에서 빠른 진전이 있습니다. 대조 학습 [20]과 같은 방법을 사용하면 입력에 대한 표현을 학습하도록 모델을 훈련 할 수 있습니다. 따라서 유사한 입력은 유사한 표현을 가지지 만 관련없는 입력은 매우 다른 표현을 가져야합니다. 이러한 표현은 n 차원 벡터 (임베딩)로, 처음부터 모델을 훈련시키기에 충분한 데이터가 없을 수있는 다른 작업의 기능으로 유용 할 수 있습니다. 레이블이 지정되지 않은 데이터를 사용하는 첫 번째 단계를 다음과 같이 볼 수 있습니다. 사전 훈련 다음 단계는 미세 조정.

대조적 학습. 출처
레이블이 지정되지 않은 데이터에 대한 사전 교육과 레이블이 지정된 데이터에 대한 미세 조정의이 21 단계 프로세스는 NLP 커뮤니티에서도 빠르게 수용되었습니다. ULMFiT [XNUMX]는 모델이 주어진 문장에서 다음 단어를 예측하는 작업을 해결하는 방법을 학습하는 범용 언어 모델을 훈련하는 아이디어를 개척했습니다.
저자는 WikiText-103 (영어 위키 백과 페이지에서 파생 됨)과 같이 전처리되었지만 레이블이 지정되지 않은 대량의 데이터를 사용하는 것이 사전 훈련 단계에 좋은 선택임을 발견했습니다. 이것은 모델이 언어에 대한 일반적인 속성을 배우기에 충분했습니다. 저자는 이진 분류 문제에 대해 이러한 사전 훈련 된 모델을 미세 조정하는 데 100 개의 레이블이있는 예제 만 필요하다는 것을 발견했습니다 (다른 레이블이 지정된 10,000 개의 예제와 비교).
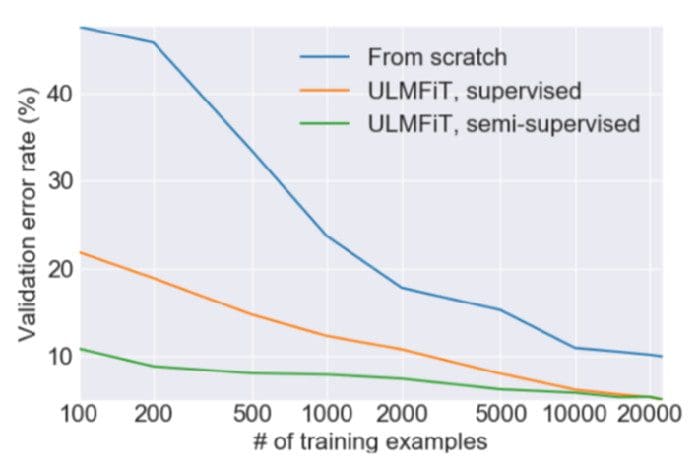
ULMFiT와의 신속한 수렴. 출처
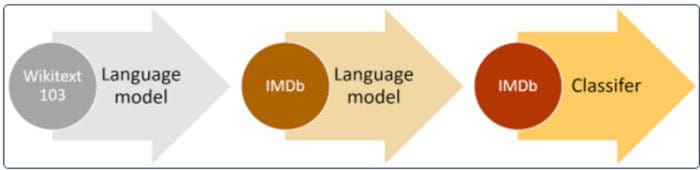
대규모 말뭉치에 대한 사전 훈련 및 관련 데이터 세트에 대한 미세 조정에 대한 높은 수준의 접근 방식. 출처
이 아이디어는 BERT 모델에서도 탐구되었으며, 사전 훈련 단계에는 양방향 마스크 언어 모델 학습이 포함되어 모델이 문장 중간에 누락 된 단어를 예측해야합니다.
전반적으로 학습 기술은 설치 공간에 영향을주지 않고 모델 품질을 개선하는 데 도움이됩니다. 이는 배포를위한 모델 품질을 개선하는 데 사용할 수 있습니다. 원래 모델 품질이 만족 스러우면 실행 가능한 최소 모델 품질로 돌아갈 때까지 네트워크의 매개 변수 수를 간단히 줄여 모델 크기와 지연 시간을 개선하기 위해 새로 발견 된 품질 향상을 교환 할 수도 있습니다.
다음 부분에서는 나머지 세 가지 중점 영역에 맞는 도구와 기술의 예를 계속 살펴 보겠습니다. 또한, 우리의 설문지 이 주제를 자세히 살펴 봅니다.
참고자료
[1] Yann LeCun, John S Denker 및 Sara A Solla. 1990. 최적의 뇌 손상. 신경 정보 처리 시스템의 발전. 598–605.
[2] Babak Hassibi, David G Stork 및 Gregory J Wolff. 1993. 최적의 뇌 외과 의사 및 일반 네트워크 가지 치기. 신경망에 관한 IEEE 국제 회의에서. IEEE, 293–299.
[3] Michael Zhu와 Suyog Gupta. 2018. 가지 치기 또는 가지 치기하지 않기 : 모델 압축을위한 가지 치기의 효능 탐색. 제 6 차 학습 표현에 관한 국제 회의, ICLR 2018, 캐나다 BC 주 밴쿠버, 30 년 3 월 2018 일 – 1 월 XNUMX 일, 워크숍 트랙 절차. OpenReview.net. https://openreview.net/forum?id=SyXNUMXiIDkPM
관련 :
지난 30 일 동안의 주요 기사
|
|
PlatoAi. Web3 재창조. 데이터 인텔리전스 증폭.
출처 : https://www.kdnuggets.com/2021/07/high-performance-deep-learning-part3.html

