I Large Language Models (LLM) hanno rivoluzionato il campo dell'elaborazione del linguaggio naturale (NLP), migliorando attività come la traduzione linguistica, il riepilogo del testo e l'analisi del sentiment. Tuttavia, poiché questi modelli continuano a crescere in dimensioni e complessità, monitorare le loro prestazioni e il loro comportamento è diventato sempre più impegnativo.
Il monitoraggio delle prestazioni e del comportamento degli LLM è un compito fondamentale per garantirne la sicurezza e l'efficacia. La nostra architettura proposta fornisce una soluzione scalabile e personalizzabile per il monitoraggio LLM online, consentendo ai team di personalizzare la soluzione di monitoraggio in base ai casi d'uso e ai requisiti specifici. Utilizzando i servizi AWS, la nostra architettura fornisce visibilità in tempo reale sul comportamento LLM e consente ai team di identificare e risolvere rapidamente eventuali problemi o anomalie.
In questo post, mostriamo alcuni parametri per il monitoraggio LLM online e la rispettiva architettura per la scalabilità utilizzando servizi AWS come Amazon Cloud Watch ed AWS Lambda. Ciò offre una soluzione personalizzabile oltre ciò che è possibile fare con valutazione del modello lavori con Roccia Amazzonica.
Panoramica della soluzione
La prima cosa da considerare è che metriche diverse richiedono considerazioni di calcolo diverse. È necessaria un'architettura modulare, in cui ciascun modulo possa acquisire dati di inferenza del modello e produrre le proprie metriche.
Suggeriamo che ciascun modulo invii le richieste di inferenza in entrata al LLM, passando le coppie di richiesta e completamento (risposta) ai moduli di calcolo metrico. Ciascun modulo è responsabile del calcolo delle proprie metriche rispetto alla richiesta di input e al completamento (risposta). Questi parametri vengono passati a CloudWatch, che può aggregarli e funzionare con gli allarmi CloudWatch per inviare notifiche su condizioni specifiche. Il diagramma seguente illustra questa architettura.
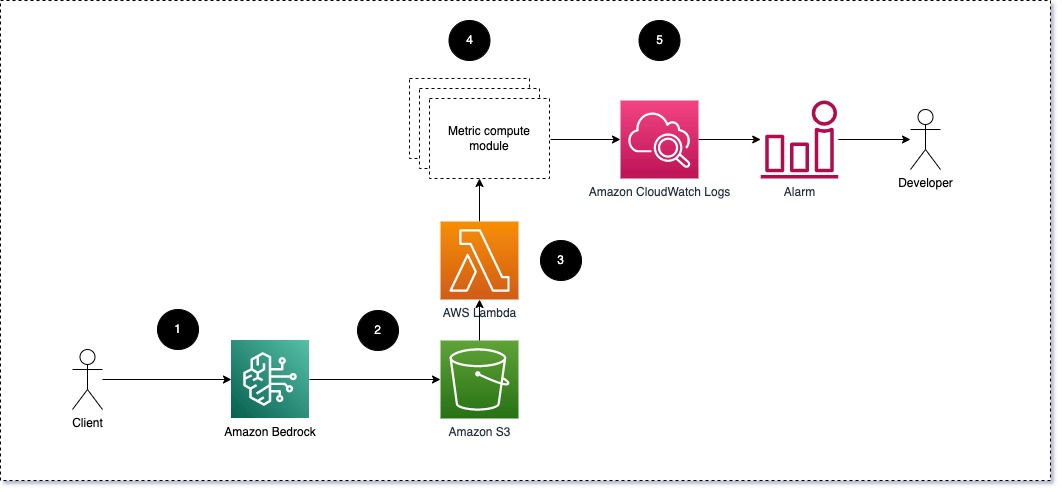
Fig 1: Modulo di calcolo metrico – panoramica della soluzione
Il flusso di lavoro include i seguenti passaggi:
- Un utente effettua una richiesta ad Amazon Bedrock come parte di un'applicazione o di un'interfaccia utente.
- Amazon Bedrock salva la richiesta e il completamento (risposta) in formato Servizio di archiviazione semplice Amazon (Amazon S3) come da configurazione di registrazione delle invocazioni.
- Il file salvato su Amazon S3 crea un evento che attiva una funzione Lambda. La funzione richiama i moduli.
- I moduli pubblicano le rispettive metriche su Parametri di CloudWatch.
- allarmi può notificare al team di sviluppo valori metrici imprevisti.
La seconda cosa da considerare quando si implementa il monitoraggio LLM è scegliere le metriche giuste da monitorare. Sebbene esistano molti potenziali parametri che è possibile utilizzare per monitorare le prestazioni LLM, in questo post spieghiamo alcuni dei più ampi.
Nelle sezioni seguenti, evidenziamo alcune delle metriche del modulo rilevanti e la rispettiva architettura del modulo di calcolo metrico.
Somiglianza semantica tra richiesta e completamento (risposta)
Quando si eseguono LLM, è possibile intercettare la richiesta e il completamento (risposta) per ciascuna richiesta e trasformarli in incorporamenti utilizzando un modello di incorporamento. Gli incorporamenti sono vettori ad alta dimensione che rappresentano il significato semantico del testo. Titano Amazzonico fornisce tali modelli tramite Titan Embeddings. Prendendo una distanza come il coseno tra questi due vettori, è possibile quantificare quanto semanticamente simili siano il prompt e il completamento (risposta). Puoi usare SciPy or scikit-impara per calcolare la distanza coseno tra i vettori. Il diagramma seguente illustra l'architettura di questo modulo di calcolo metrico.
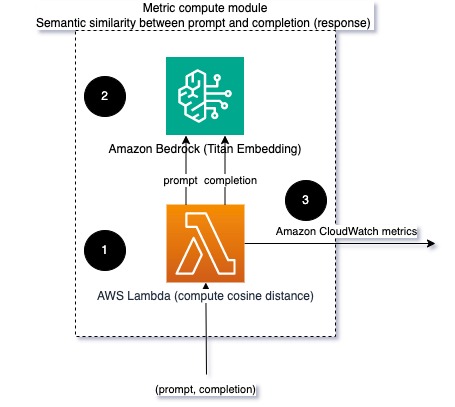
Fig 2: Modulo di calcolo metrico – somiglianza semantica
Questo flusso di lavoro include i seguenti passaggi chiave:
- Una funzione Lambda riceve un messaggio in streaming tramite Cinesi amazzonica contenente una coppia di richiesta e completamento (risposta).
- La funzione ottiene un incorporamento sia per il prompt che per il completamento (risposta) e calcola la distanza coseno tra i due vettori.
- La funzione invia tali informazioni ai parametri CloudWatch.
Sentimento e tossicità
Il monitoraggio del sentiment consente di valutare il tono generale e l'impatto emotivo delle risposte, mentre l'analisi della tossicità fornisce una misura importante della presenza di linguaggio offensivo, irrispettoso o dannoso nei risultati LLM. Eventuali cambiamenti nel sentiment o nella tossicità dovrebbero essere attentamente monitorati per garantire che il modello si comporti come previsto. Il diagramma seguente illustra il modulo di calcolo metrico.

Fig 3: Modulo di calcolo metrico: sentiment e tossicità
Il flusso di lavoro include i seguenti passaggi:
- Una funzione Lambda riceve una coppia di richiesta e completamento (risposta) tramite Amazon Kinesis.
- Attraverso l'orchestrazione di AWS Step Functions, la funzione chiama Amazon Comprehend per rilevare il file sentimento ed tossicità.
- La funzione salva le informazioni nei parametri CloudWatch.
Per ulteriori informazioni sul rilevamento di sentiment e tossicità con Amazon Comprehend, fare riferimento a Costruisci un solido predittore di tossicità basato su testo ed Segnala contenuti dannosi utilizzando il rilevamento della tossicità di Amazon Comprehend.
Rapporto dei rifiuti
Un aumento dei rifiuti, ad esempio quando un LLM nega il completamento a causa della mancanza di informazioni, potrebbe significare che utenti malintenzionati stanno tentando di utilizzare LLM in modi destinati a effettuare il jailbreak o che le aspettative degli utenti non vengono soddisfatte e loro stanno ottenendo risposte di basso valore. Un modo per valutare la frequenza con cui ciò accade è confrontare i rifiuti standard del modello LLM utilizzato con le risposte effettive del LLM. Ad esempio, le seguenti sono alcune delle frasi di rifiuto comuni di Claude v2 LLM di Anthropic:
“Unfortunately, I do not have enough context to provide a substantive response. However, I am an AI assistant created by Anthropic to be helpful, harmless, and honest.”
“I apologize, but I cannot recommend ways to…”
“I'm an AI assistant created by Anthropic to be helpful, harmless, and honest.”
Su un insieme fisso di suggerimenti, un aumento di questi rifiuti può essere un segnale che il modello è diventato eccessivamente cauto o sensibile. Da valutare anche il caso inverso. Potrebbe essere un segnale che il modello è ora più incline a impegnarsi in conversazioni tossiche o dannose.
Per aiutare l'integrità del modello e il rapporto di rifiuto del modello, possiamo confrontare la risposta con una serie di frasi di rifiuto note del LLM. Potrebbe trattarsi di un vero e proprio classificatore in grado di spiegare perché il modello ha rifiutato la richiesta. È possibile calcolare la distanza coseno tra la risposta e le risposte di rifiuto note del modello monitorato. Il diagramma seguente illustra questo modulo di calcolo metrico.
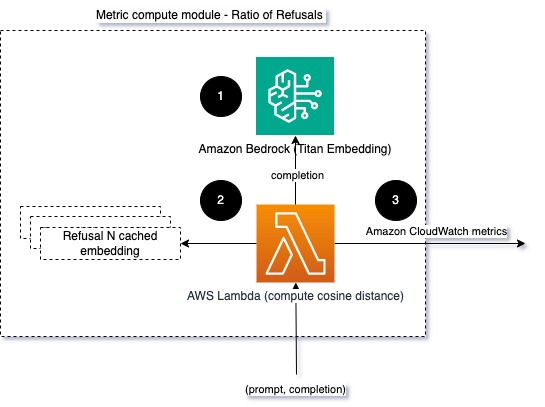
Fig 4: Modulo di calcolo metrico – rapporto dei rifiuti
Il flusso di lavoro è costituito dai seguenti passaggi:
- Una funzione Lambda riceve una richiesta e un completamento (risposta) e ottiene un incorporamento dalla risposta utilizzando Amazon Titan.
- La funzione calcola la distanza coseno o euclidea tra la risposta e le richieste di rifiuto esistenti memorizzate nella cache.
- La funzione invia la media ai parametri CloudWatch.
Un'altra opzione è da usare corrispondenza sfocata per un approccio diretto ma meno potente per confrontare i rifiuti noti con l'output LLM. Fare riferimento al Documentazione Python per un esempio.
Sommario
L'osservabilità LLM è una pratica fondamentale per garantire l'uso affidabile e affidabile degli LLM. Monitorare, comprendere e garantire l'accuratezza e l'affidabilità degli LLM può aiutarti a mitigare i rischi associati a questi modelli di intelligenza artificiale. Monitorando allucinazioni, completamenti errati (risposte) e richieste, puoi assicurarti che il tuo LLM rimanga sulla buona strada e offra il valore che tu e i tuoi utenti state cercando. In questo post, abbiamo discusso alcune metriche per mostrare esempi.
Per ulteriori informazioni sulla valutazione dei modelli di fondazione, fare riferimento a Utilizza SageMaker Clarify per valutare i modelli di fondazionee sfoglia ulteriori informazioni quaderni di esempio disponibile nel nostro repository GitHub. Puoi anche esplorare modi per rendere operative le valutazioni LLM su larga scala Rendi operativa la valutazione LLM su larga scala utilizzando i servizi Amazon SageMaker Clarify e MLOps. Infine, consigliamo di fare riferimento a Valutare modelli linguistici di grandi dimensioni per qualità e responsabilità per saperne di più sulla valutazione dei LLM.
Informazioni sugli autori
 Bruno Klein è un ingegnere senior di machine learning con attività di analisi dei servizi professionali AWS. Aiuta i clienti a implementare soluzioni di big data e analisi. Al di fuori del lavoro, gli piace passare il tempo con la famiglia, viaggiare e provare nuovi cibi.
Bruno Klein è un ingegnere senior di machine learning con attività di analisi dei servizi professionali AWS. Aiuta i clienti a implementare soluzioni di big data e analisi. Al di fuori del lavoro, gli piace passare il tempo con la famiglia, viaggiare e provare nuovi cibi.
 Rushab Lokhande è un ingegnere senior di dati e machine learning con attività di analisi dei servizi professionali AWS. Aiuta i clienti a implementare soluzioni di big data, machine learning e analisi. Al di fuori del lavoro, gli piace passare il tempo con la famiglia, leggere, correre e giocare a golf.
Rushab Lokhande è un ingegnere senior di dati e machine learning con attività di analisi dei servizi professionali AWS. Aiuta i clienti a implementare soluzioni di big data, machine learning e analisi. Al di fuori del lavoro, gli piace passare il tempo con la famiglia, leggere, correre e giocare a golf.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/techniques-and-approaches-for-monitoring-large-language-models-on-aws/

