Nel panorama in evoluzione della produzione, il potere di trasformazione dell’intelligenza artificiale e del machine learning (ML) è evidente, guidando una rivoluzione digitale che semplifica le operazioni e aumenta la produttività. Tuttavia, questo progresso introduce sfide uniche per le aziende che utilizzano soluzioni basate sui dati. Le strutture industriali sono alle prese con enormi volumi di dati non strutturati, provenienti da sensori, sistemi di telemetria e apparecchiature disperse lungo le linee di produzione. I dati in tempo reale sono fondamentali per applicazioni come la manutenzione predittiva e il rilevamento di anomalie, ma lo sviluppo di modelli ML personalizzati per ciascun caso d'uso industriale con tali dati di serie temporali richiede tempo e risorse considerevoli da parte dei data scientist, ostacolandone un'adozione diffusa.
AI generativa utilizzando grandi modelli di fondazione pre-addestrati (FM) come Claude può generare rapidamente una varietà di contenuti, dal testo colloquiale al codice informatico basato su semplici istruzioni di testo, note come suggerimento dello scatto zero. Ciò elimina la necessità che i data scientist sviluppino manualmente modelli ML specifici per ciascun caso d’uso e quindi democratizza l’accesso all’intelligenza artificiale, a vantaggio anche dei piccoli produttori. I lavoratori aumentano la produttività grazie agli insight generati dall'intelligenza artificiale, gli ingegneri possono rilevare in modo proattivo le anomalie, i responsabili della supply chain ottimizzano gli inventari e la leadership dello stabilimento prende decisioni informate e basate sui dati.
Tuttavia, i FM autonomi devono affrontare limitazioni nella gestione di dati industriali complessi con vincoli di dimensione del contesto (tipicamente meno di 200,000 token), il che pone delle sfide. Per risolvere questo problema, è possibile utilizzare la capacità dell'FM di generare codice in risposta a query in linguaggio naturale (NLQ). Agli agenti piace Panda AI entrano in gioco, eseguendo questo codice su dati di serie temporali ad alta risoluzione e gestendo gli errori utilizzando FM. PandasAI è una libreria Python che aggiunge funzionalità di intelligenza artificiale generativa a panda, il popolare strumento di analisi e manipolazione dei dati.
Tuttavia, NLQ complessi, come l'elaborazione di dati di serie temporali, l'aggregazione multilivello e le operazioni di tabelle pivot o congiunte, possono produrre una precisione incoerente dello script Python con un prompt zero-shot.
Per migliorare la precisione della generazione del codice, proponiamo la costruzione dinamica istruzioni per lo scatto multiplo per gli NLQ. I suggerimenti multi-shot forniscono ulteriore contesto all'FM mostrando diversi esempi di output desiderati per prompt simili, aumentando la precisione e la coerenza. In questo post, i prompt multi-shot vengono recuperati da un incorporamento contenente codice Python eseguito correttamente su un tipo di dati simile (ad esempio, dati di serie temporali ad alta risoluzione da dispositivi Internet of Things). Il prompt multi-shot costruito dinamicamente fornisce il contesto più rilevante per FM e potenzia le capacità di FM nel calcolo matematico avanzato, nell'elaborazione dei dati di serie temporali e nella comprensione degli acronimi dei dati. Questa risposta migliorata facilita i lavoratori aziendali e i team operativi nel interagire con i dati, ricavando informazioni approfondite senza richiedere competenze approfondite di data science.
Oltre all’analisi dei dati delle serie temporali, i FM si rivelano preziosi in varie applicazioni industriali. I team di manutenzione valutano lo stato delle risorse e acquisiscono immagini per Rekognition di Amazonriepiloghi delle funzionalità basate su e analisi delle cause principali delle anomalie utilizzando ricerche intelligenti con Recupero generazione aumentata (STRACCIO). Per semplificare questi flussi di lavoro, AWS ha introdotto Roccia Amazzonica, consentendoti di creare e scalare applicazioni di intelligenza artificiale generativa con FM preaddestrati all'avanguardia come Claudio v2. Con Basi di conoscenza per Amazon Bedrock, è possibile semplificare il processo di sviluppo RAG per fornire un'analisi più accurata delle cause delle anomalie per i lavoratori dell'impianto. Il nostro post presenta un assistente intelligente per casi d'uso industriali basato su Amazon Bedrock, che affronta le sfide NLQ, genera riepiloghi delle parti dalle immagini e migliora le risposte FM per la diagnosi delle apparecchiature attraverso l'approccio RAG.
Panoramica della soluzione
Il diagramma seguente illustra l'architettura della soluzione.

Il flusso di lavoro include tre casi d'uso distinti:
Caso d'uso 1: NLQ con dati di serie temporali
Il flusso di lavoro per NLQ con dati di serie temporali è costituito dai seguenti passaggi:
- Utilizziamo un sistema di monitoraggio delle condizioni con funzionalità ML per il rilevamento di anomalie, come ad esempio Amazon Monitor, per monitorare lo stato delle apparecchiature industriali. Amazon Monitron è in grado di rilevare potenziali guasti alle apparecchiature dalle misurazioni delle vibrazioni e della temperatura dell'apparecchiatura.
- Raccogliamo dati di serie temporali mediante elaborazione Amazon Monitor dati attraverso Flussi di dati di Amazon Kinesis ed Amazon Data Firehose, convertendolo in un formato CSV tabellare e salvandolo in un file Servizio di archiviazione semplice Amazon (Amazon S3) secchio.
- L'utente finale può iniziare a chattare con i dati delle serie temporali in Amazon S3 inviando una query in linguaggio naturale all'app Streamlit.
- L'app Streamlit inoltra le query degli utenti a Modello di incorporamento del testo di Amazon Bedrock Titan per incorporare questa query ed esegue una ricerca di somiglianza all'interno di un file Servizio Amazon OpenSearch indice, che contiene NLQ precedenti e codici di esempio.
- Dopo la ricerca per similarità, i principali esempi simili, tra cui domande NLQ, schema di dati e codici Python, vengono inseriti in un prompt personalizzato.
- PandasAI invia questo prompt personalizzato al modello Amazon Bedrock Claude v2.
- L'app utilizza l'agente PandasAI per interagire con il modello Amazon Bedrock Claude v2, generando codice Python per l'analisi dei dati di Amazon Monitron e le risposte NLQ.
- Dopo che il modello Amazon Bedrock Claude v2 restituisce il codice Python, PandasAI esegue la query Python sui dati Amazon Monitron caricati dall'app, raccogliendo gli output del codice e affrontando eventuali tentativi necessari per le esecuzioni non riuscite.
- L'app Streamlit raccoglie la risposta tramite PandasAI e fornisce l'output agli utenti. Se l'output è soddisfacente, l'utente può contrassegnarlo come utile, salvando il codice Python generato da NLQ e Claude nel servizio OpenSearch.
Caso d'uso 2: generazione riepilogativa di parti malfunzionanti
Il nostro caso d'uso per la generazione di riepilogo prevede i seguenti passaggi:
- Dopo che l'utente ha individuato quale asset industriale presenta un comportamento anomalo, può caricare le immagini della parte malfunzionante per identificare se c'è qualcosa di fisicamente sbagliato in questa parte in base alle sue specifiche tecniche e alle condizioni operative.
- L'utente può utilizzare il API Amazon Recognition DetectText per estrarre dati di testo da queste immagini.
- I dati di testo estratti vengono inclusi nel prompt per il modello Amazon Bedrock Claude v2, consentendo al modello di generare un riepilogo di 200 parole della parte malfunzionante. L'utente può utilizzare queste informazioni per eseguire un'ulteriore ispezione della parte.
Caso d'uso 3: diagnosi della causa principale
Il nostro caso d'uso per la diagnosi della causa principale prevede i seguenti passaggi:
- L'utente ottiene dati aziendali in vari formati di documenti (PDF, TXT e così via) relativi ad asset malfunzionanti e li carica in un bucket S3.
- Una base di conoscenza di questi file viene generata in Amazon Bedrock con un modello di incorporamento di testo Titan e un archivio vettoriale OpenSearch Service predefinito.
- L'utente pone domande relative alla diagnosi della causa principale del malfunzionamento delle apparecchiature. Le risposte vengono generate attraverso la knowledge base Amazon Bedrock con un approccio RAG.
Prerequisiti
Per seguire questo post, è necessario soddisfare i seguenti prerequisiti:
Distribuire l'infrastruttura della soluzione
Per configurare le risorse della soluzione, completare i seguenti passaggi:
- Distribuire il AWS CloudFormazione modello opensearchsagemaker.yml, che crea una raccolta e un indice del servizio OpenSearch, Amazon Sage Maker istanza notebook e bucket S3. Puoi denominare questo stack AWS CloudFormation come:
genai-sagemaker. - Apri l'istanza notebook SageMaker in JupyterLab. Troverai quanto segue Repository GitHub già scaricato su questa istanza: sbloccare il potenziale dell’intelligenza artificiale generativa nelle operazioni industriali.
- Eseguire il notebook dalla seguente directory in questo repository: sbloccare-il-potenziale-dell-ai-generativa-nelle-operazioni-industriali/SagemakerNotebook/nlq-vettoriale-rag-embedding.ipynb. Questo notebook caricherà l'indice del servizio OpenSearch utilizzando il notebook SageMaker per archiviare coppie chiave-valore dal file 23 esempi NLQ esistenti.
- Carica documenti dalla cartella dati assetpartdoc nel repository GitHub nel bucket S3 elencato negli output dello stack CloudFormation.

Successivamente, creerai la knowledge base per i documenti in Amazon S3.
- Sulla console Amazon Bedrock, scegli Knowledge Base nel pannello di navigazione.
- Scegli Crea una base di conoscenza.
- Nel Nome della base di conoscenza, inserisci un nome.
- Nel Ruolo di runtime, selezionare Crea e utilizza un nuovo ruolo del servizio.
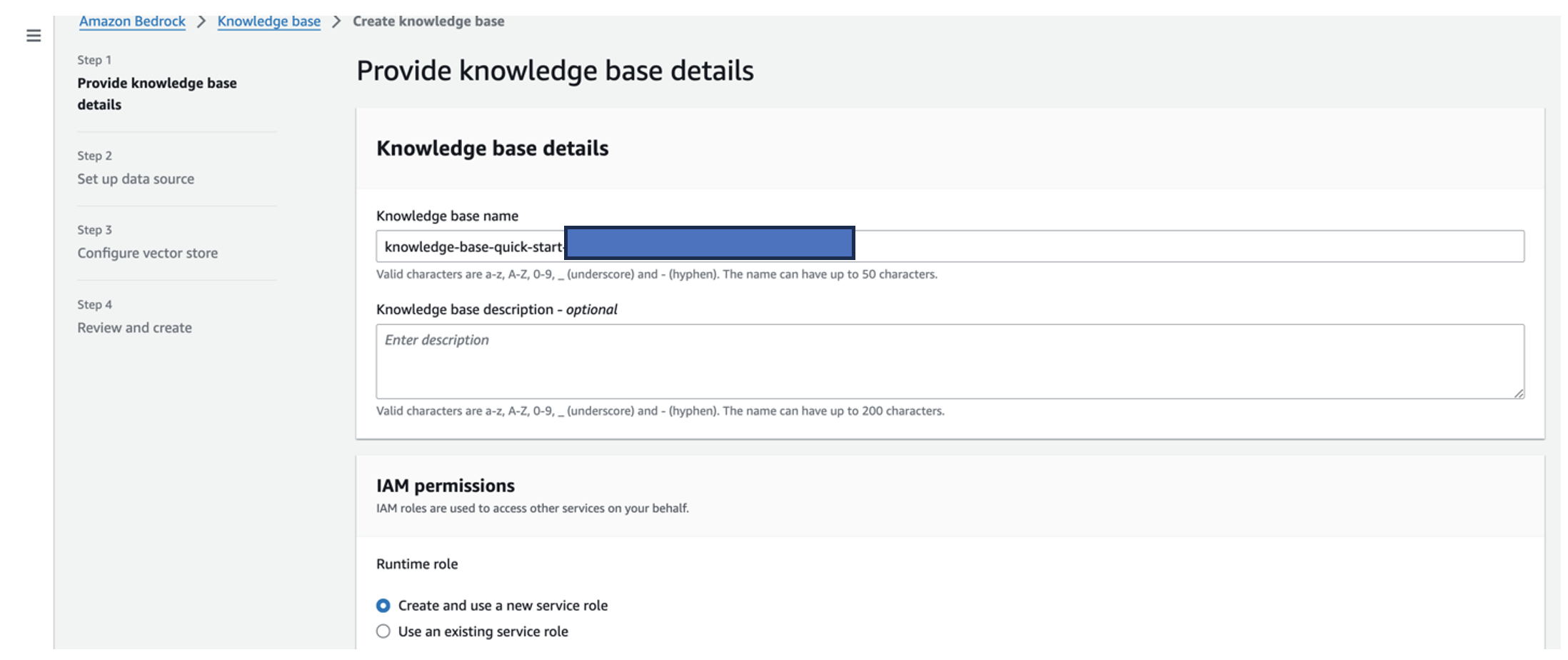
- Nel Nome dell'origine dati, inserisci il nome dell'origine dati.
- Nel URI S3, inserisci il percorso S3 del bucket in cui hai caricato i documenti della causa principale.
- Scegli Avanti.
 Il modello di incorporamenti Titan viene selezionato automaticamente.
Il modello di incorporamenti Titan viene selezionato automaticamente. - Seleziona Crea rapidamente un nuovo archivio vettoriale.
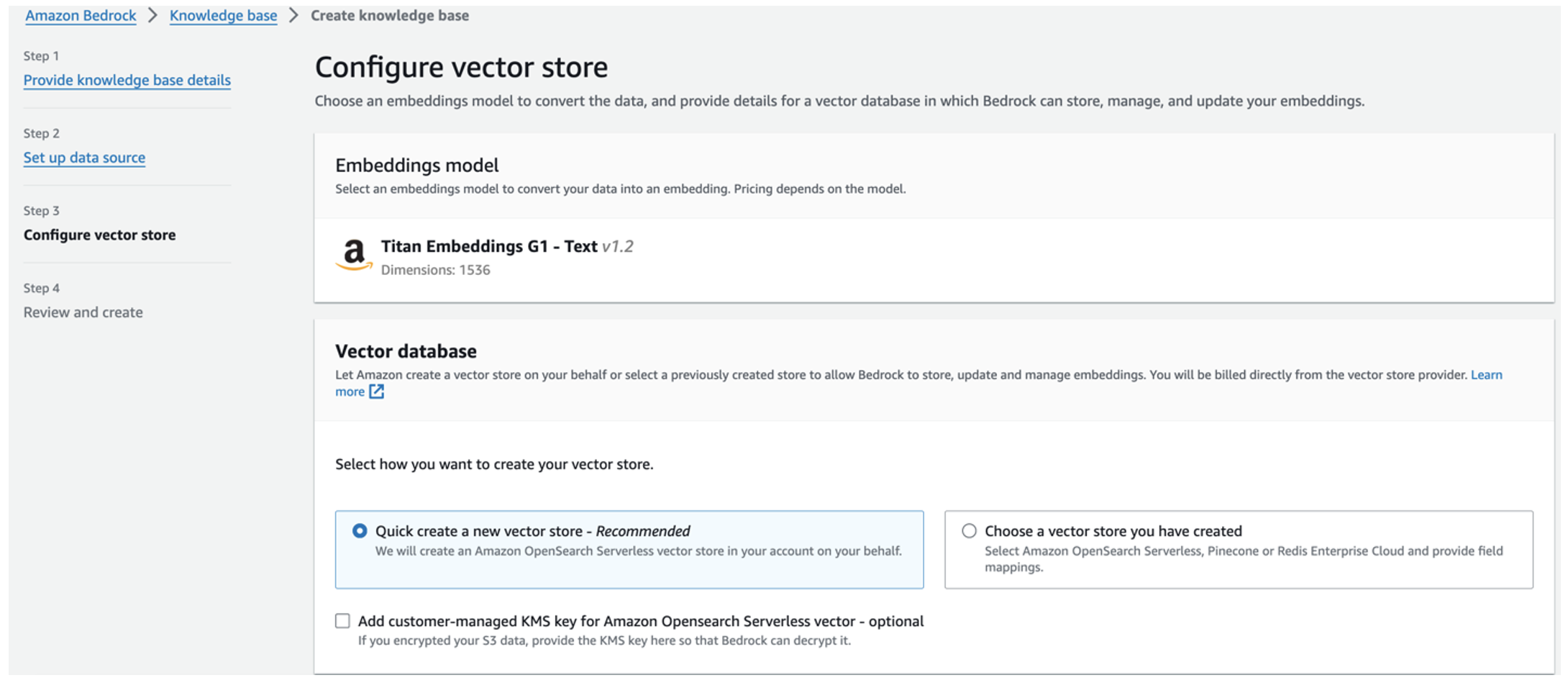
- Rivedi le tue impostazioni e crea la knowledge base scegliendo Crea una base di conoscenza.
- Dopo aver creato correttamente la knowledge base, scegli Sincronizza per sincronizzare il bucket S3 con la knowledge base.

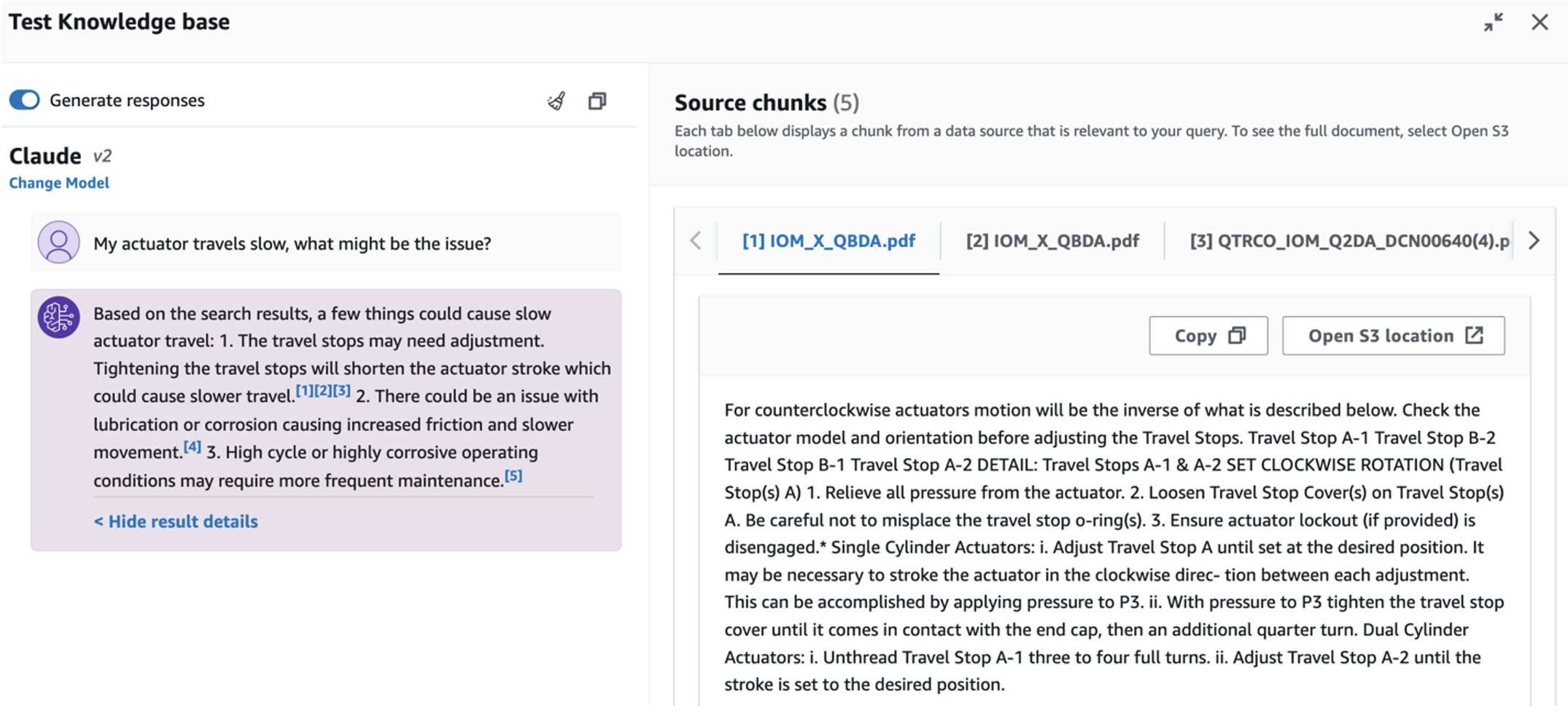
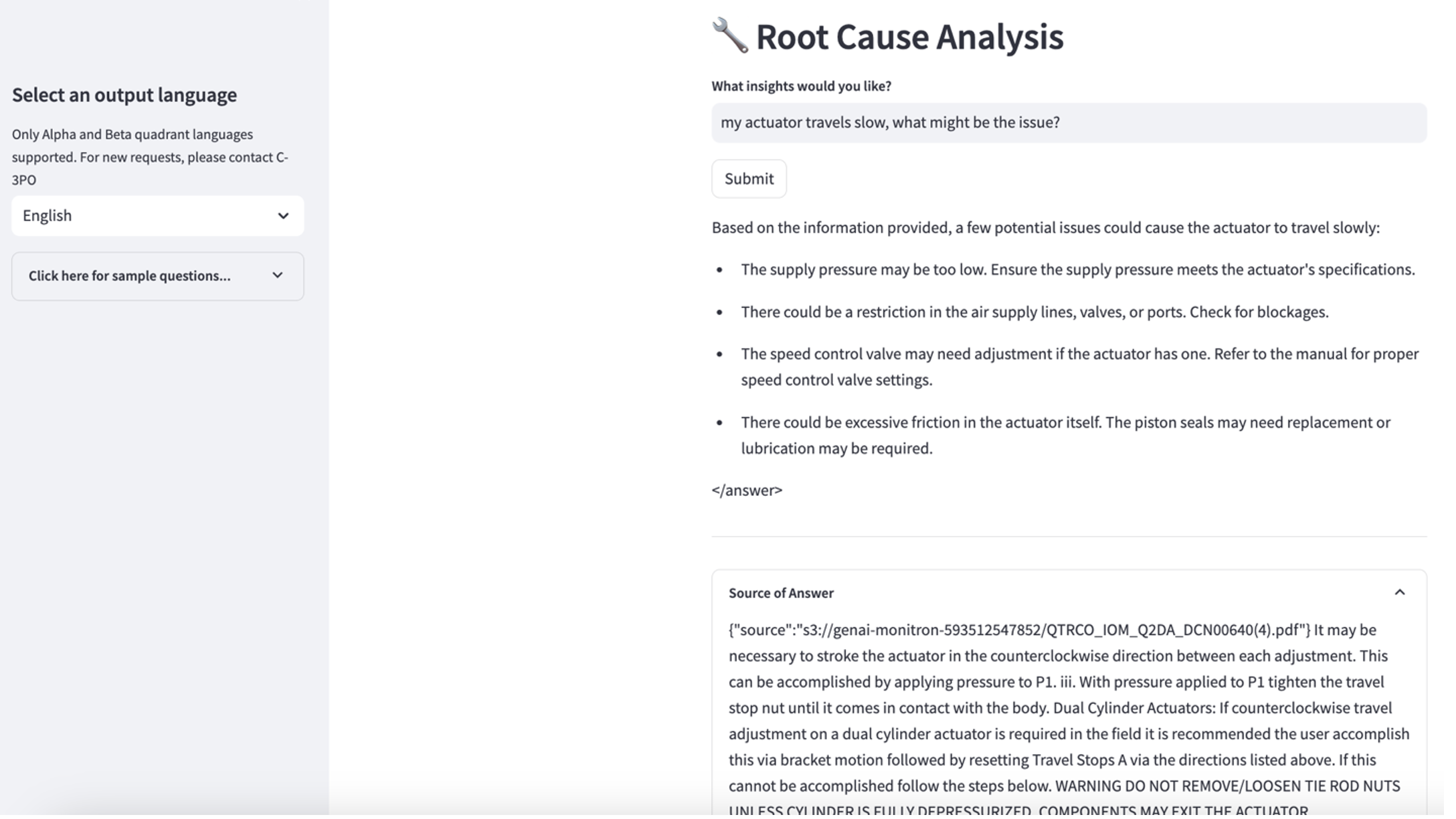
- Dopo aver impostato la knowledge base, puoi testare l'approccio RAG per la diagnosi della causa principale ponendo domande come "Il mio attuatore viaggia lentamente, quale potrebbe essere il problema?"
Il passaggio successivo consiste nel distribuire l'app con i pacchetti di libreria richiesti sul tuo PC o su un'istanza EC2 (Ubuntu Server 22.04 LTS).
- Configura le tue credenziali AWS con l'AWS CLI sul tuo PC locale. Per semplicità, puoi utilizzare lo stesso ruolo di amministratore utilizzato per distribuire lo stack CloudFormation. Se utilizzi Amazon EC2, allegare un ruolo IAM adatto all'istanza.
- clone Repository GitHub:
- Cambia la directory in
unlocking-the-potential-of-generative-ai-in-industrial-operations/srce gestisci ilsetup.shscript in questa cartella per installare i pacchetti richiesti, inclusi LangChain e PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Esegui l'app Streamlit con il seguente comando:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Fornisci l'ARN della raccolta del servizio OpenSearch creato in Amazon Bedrock dalla fase precedente.
Chatta con il tuo assistente per la salute delle risorse
Dopo aver completato la distribuzione end-to-end, puoi accedere all'app tramite localhost sulla porta 8501, che apre una finestra del browser con l'interfaccia web. Se hai distribuito l'app su un'istanza EC2, consentire l'accesso alla porta 8501 tramite la regola in entrata del gruppo di sicurezza. È possibile accedere a diverse schede per vari casi d'uso.
Esplora il caso d'uso 1
Per esplorare il primo caso d'uso, scegli Analisi dei dati e grafico. Inizia caricando i dati delle serie temporali. Se non disponi di un file di dati di serie temporali esistente da utilizzare, puoi caricare quanto segue file CSV di esempio con dati anonimi del progetto Amazon Monitron. Se hai già un progetto Amazon Monitron, fai riferimento a Genera informazioni utili per la gestione della manutenzione predittiva con Amazon Monitron e Amazon Kinesis per trasmettere i tuoi dati Amazon Monitron su Amazon S3 e utilizzare i tuoi dati con questa applicazione.
Una volta completato il caricamento, inserisci una query per avviare una conversazione con i tuoi dati. La barra laterale sinistra offre una serie di domande di esempio per la tua comodità. Gli screenshot seguenti illustrano la risposta e il codice Python generato dal FM quando si inserisce una domanda come "Dimmi il numero univoco di sensori per ciascun sito mostrato rispettivamente come Avviso o Allarme?" (una domanda di livello difficile) o "Per i sensori che mostrano un segnale di temperatura come NON sano, puoi calcolare la durata in giorni per ciascun sensore che mostra un segnale di vibrazione anomalo?" (una domanda a livello di sfida). L'app risponderà alla tua domanda e mostrerà anche lo script Python di analisi dei dati eseguito per generare tali risultati.


Se sei soddisfatto della risposta, puoi contrassegnarla come Utile, salvando il codice Python generato da NLQ e Claude in un indice del servizio OpenSearch.

Esplora il caso d'uso 2
Per esplorare il secondo caso d'uso, scegli il Riepilogo delle immagini catturate scheda nell'app Streamlit. Puoi caricare un'immagine della tua risorsa industriale e l'applicazione genererà un riepilogo di 200 parole delle sue specifiche tecniche e delle condizioni operative in base alle informazioni dell'immagine. Lo screenshot seguente mostra il riepilogo generato da un'immagine di una trasmissione a cinghia. Per testare questa funzionalità, se ti manca un'immagine adatta, puoi utilizzare quanto segue immagine di esempio.
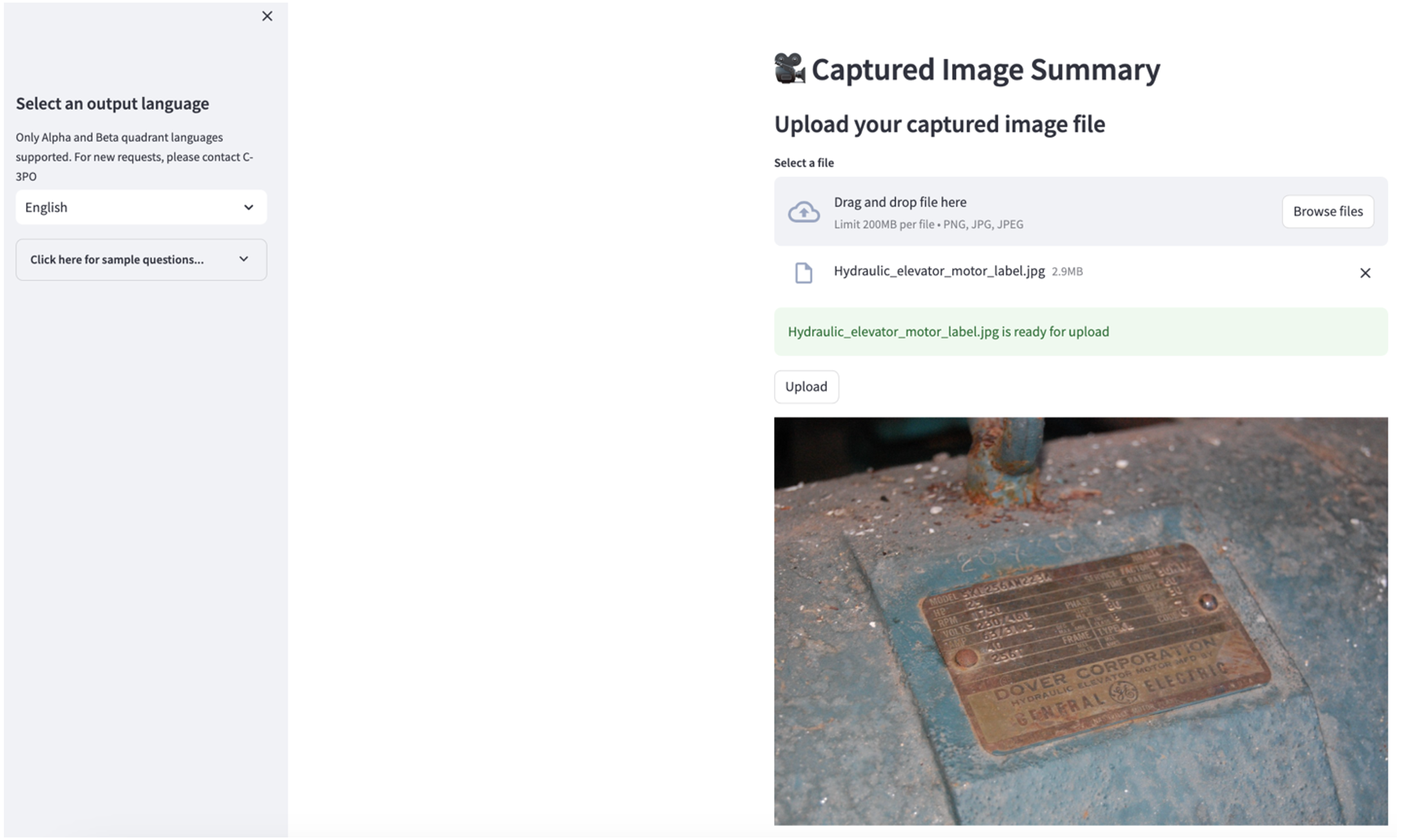
Etichetta del motore dell'ascensore idraulico" di Clarence Risher è concesso in licenza con CC BY-SA 2.0.

Esplora il caso d'uso 3
Per esplorare il terzo caso d'uso, scegli il Diagnosi della causa principale scheda. Inserisci una domanda relativa alla tua risorsa industriale rotta, ad esempio "Il mio attuatore viaggia lentamente, quale potrebbe essere il problema?" Come illustrato nello screenshot seguente, l'applicazione fornisce una risposta con l'estratto del documento di origine utilizzato per generare la risposta.
Caso d'uso 1: dettagli di progettazione
In questa sezione vengono discussi i dettagli di progettazione del flusso di lavoro dell'applicazione per il primo caso d'uso.
Creazione di prompt personalizzati
La query in linguaggio naturale dell'utente presenta diversi livelli di difficoltà: facile, difficile e sfida.
Le domande semplici possono includere le seguenti richieste:
- Seleziona valori univoci
- Contare i numeri totali
- Ordina i valori
Per queste domande, PandasAI può interagire direttamente con FM per generare script Python per l'elaborazione.
Le domande difficili richiedono operazioni di aggregazione di base o analisi di serie temporali, come le seguenti:
- Selezionare prima il valore e raggruppare i risultati in modo gerarchico
- Eseguire le statistiche dopo la selezione iniziale dei record
- Conteggio timestamp (ad esempio, min e max)
Per le domande difficili, un modello di prompt con istruzioni dettagliate passo dopo passo aiuta i FM a fornire risposte accurate.
Le domande a livello di sfida richiedono calcoli matematici avanzati ed elaborazione di serie temporali, come le seguenti:
- Calcolare la durata dell'anomalia per ciascun sensore
- Calcolare i sensori di anomalia per il sito su base mensile
- Confrontare le letture del sensore in condizioni di funzionamento normale e anomale
Per queste domande è possibile utilizzare gli scatti multipli in una richiesta personalizzata per migliorare la precisione della risposta. Tali riprese multiple mostrano esempi di elaborazione avanzata di serie temporali e calcoli matematici e forniranno il contesto affinché il FM possa eseguire inferenze rilevanti su analisi simili. Inserire dinamicamente gli esempi più rilevanti da una banca di domande NLQ nel prompt può essere una sfida. Una soluzione è costruire incorporamenti da esempi di domande NLQ esistenti e salvare questi incorporamenti in un archivio vettoriale come OpenSearch Service. Quando una domanda viene inviata all'app Streamlit, la domanda verrà vettorizzata da Incorporamenti nella roccia. I primi N incorporamenti più rilevanti per quella domanda vengono recuperati utilizzando opensearch_vettoriale_ricerca.similarity_search e inserito nel modello di prompt come prompt a più riprese.
Il diagramma seguente illustra questo flusso di lavoro.
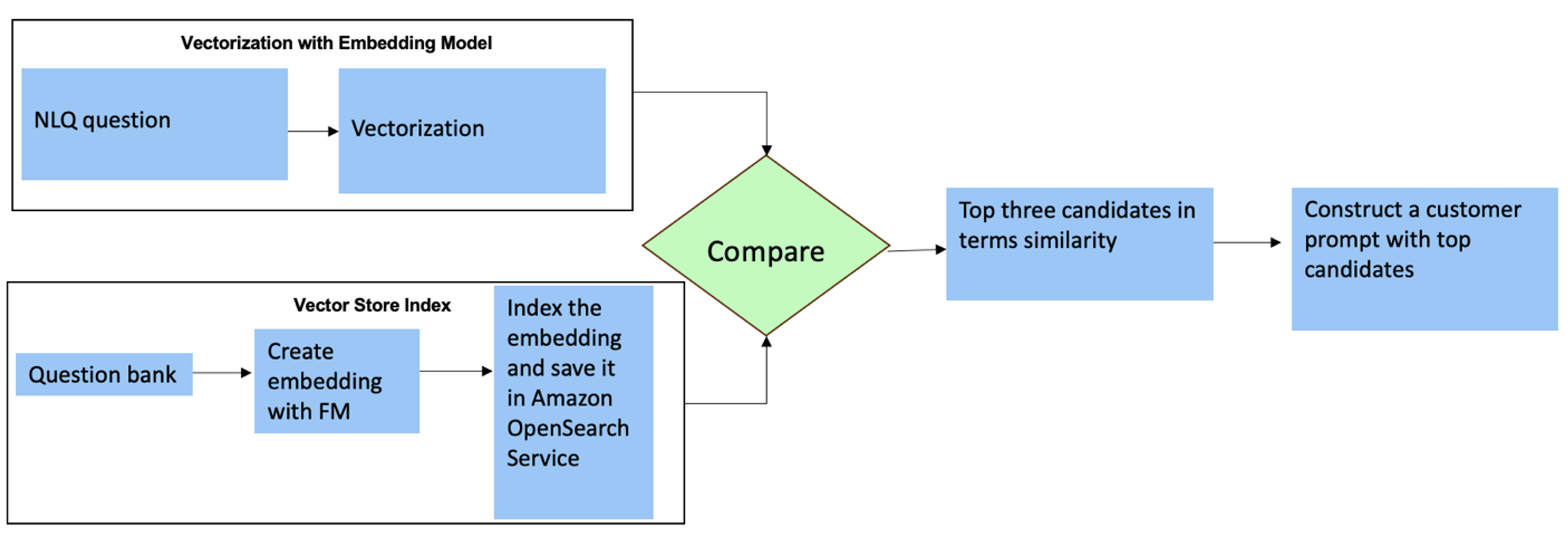
Lo strato di incorporamento è costruito utilizzando tre strumenti chiave:
- Modello degli incastri – Utilizziamo Amazon Titan Embeddings disponibile tramite Amazon Bedrock (amazon.titan-embed-text-v1) per generare rappresentazioni numeriche di documenti testuali.
- Negozio di vettori – Per il nostro archivio vettoriale, utilizziamo il servizio OpenSearch tramite il framework LangChain, semplificando l'archiviazione degli incorporamenti generati dagli esempi NLQ in questo notebook.
- Indice – L’indice del servizio OpenSearch svolge un ruolo fondamentale nel confrontare gli incorporamenti di input con gli incorporamenti di documenti e nel facilitare il recupero dei documenti rilevanti. Poiché i codici di esempio Python sono stati salvati come file JSON, sono stati indicizzati nel servizio OpenSearch come vettori tramite un file OpenSearchVevtorSearch.fromtexts Chiamata API.
Raccolta continua di esempi verificati da esseri umani tramite Streamlit
All'inizio dello sviluppo dell'app, abbiamo iniziato con solo 23 esempi salvati nell'indice del servizio OpenSearch come incorporamenti. Quando l'app diventa operativa sul campo, gli utenti iniziano a inserire i propri NLQ tramite l'app. Tuttavia, a causa degli esempi limitati disponibili nel modello, alcuni NLQ potrebbero non trovare richieste simili. Per arricchire continuamente questi incorporamenti e offrire suggerimenti utente più pertinenti, puoi utilizzare l'app Streamlit per raccogliere esempi controllati da esseri umani.
All'interno dell'app, la seguente funzione serve a questo scopo. Quando gli utenti finali trovano utile l'output e lo selezionano Utile, l'applicazione segue questi passaggi:
- Utilizza il metodo di callback di PandasAI per raccogliere lo script Python.
- Riformatta lo script Python, la domanda di input e i metadati CSV in una stringa.
- Controlla se questo esempio NLQ esiste già nell'indice corrente del servizio OpenSearch utilizzando opensearch_vettoriale_ricerca.similarity_search_with_score.
- Se non esiste un esempio simile, questo NLQ viene aggiunto all'indice del servizio OpenSearch utilizzando opensearch_vettoriale_ricerca.add_texts.
Nel caso in cui un utente selezioni Non d'aiuto, non viene intrapresa alcuna azione. Questo processo iterativo garantisce che il sistema migliori continuamente incorporando esempi forniti dagli utenti.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Incorporando il controllo umano, la quantità di esempi nel servizio OpenSearch disponibili per l'incorporamento immediato aumenta man mano che l'app aumenta l'utilizzo. Questo set di dati di incorporamento ampliato comporta una maggiore precisione della ricerca nel tempo. Nello specifico, per gli NLQ impegnativi, la precisione della risposta del FM raggiunge circa il 90% quando si inseriscono dinamicamente esempi simili per costruire prompt personalizzati per ciascuna domanda NLQ. Ciò rappresenta un notevole aumento del 28% rispetto agli scenari senza istruzioni multi-scatto.
Caso d'uso 2: dettagli di progettazione
Sull'app Streamlit Riepilogo delle immagini catturate scheda, puoi caricare direttamente un file immagine. Ciò avvia l'API Amazon Rekognition (rileva_testo API), estraendo il testo dall'etichetta dell'immagine che descrive in dettaglio le specifiche della macchina. Successivamente, i dati di testo estratti vengono inviati al modello Amazon Bedrock Claude come contesto di un prompt, ottenendo un riepilogo di 200 parole.
Dal punto di vista dell'esperienza utente, abilitare la funzionalità di streaming per un'attività di riepilogo del testo è fondamentale, consentendo agli utenti di leggere il riepilogo generato da FM in blocchi più piccoli anziché attendere l'intero output. Amazon Bedrock facilita lo streaming tramite la sua API (bedrock_runtime.invoke_model_with_response_stream).
Caso d'uso 3: dettagli di progettazione
In questo scenario, abbiamo sviluppato un'applicazione chatbot focalizzata sull'analisi delle cause profonde, utilizzando l'approccio RAG. Questo chatbot attinge da più documenti relativi alle apparecchiature per cuscinetti per facilitare l'analisi delle cause principali. Questo chatbot per l'analisi delle cause profonde basato su RAG utilizza basi di conoscenza per generare rappresentazioni di testo vettoriale o incorporamenti. Knowledge Base per Amazon Bedrock è una funzionalità completamente gestita che ti aiuta a implementare l'intero flusso di lavoro RAG, dall'acquisizione al recupero e all'implementazione rapida, senza dover creare integrazioni personalizzate per le origini dati o gestire i flussi di dati e i dettagli di implementazione RAG.
Quando sei soddisfatto della risposta della knowledge base di Amazon Bedrock, puoi integrare la risposta della causa principale dalla knowledge base all'app Streamlit.
ripulire
Per risparmiare sui costi, elimina le risorse che hai creato in questo post:
- Elimina la knowledge base da Amazon Bedrock.
- Elimina l'indice del servizio OpenSearch.
- Elimina lo stack CloudFormation genai-sagemaker.
- Arresta l'istanza EC2 se hai utilizzato un'istanza EC2 per eseguire l'app Streamlit.
Conclusione
Le applicazioni di intelligenza artificiale generativa hanno già trasformato vari processi aziendali, migliorando la produttività e le competenze dei lavoratori. Tuttavia, i limiti dei FM nella gestione dell’analisi dei dati delle serie temporali ne hanno ostacolato il pieno utilizzo da parte dei clienti industriali. Questo vincolo ha impedito l’applicazione dell’intelligenza artificiale generativa al tipo di dati predominante elaborato quotidianamente.
In questo post abbiamo introdotto una soluzione applicativa di intelligenza artificiale generativa progettata per alleviare questa sfida per gli utenti industriali. Questa applicazione utilizza un agente open source, PandasAI, per rafforzare la capacità di analisi delle serie temporali di un FM. Invece di inviare dati di serie temporali direttamente ai FM, l’app utilizza PandasAI per generare codice Python per l’analisi di dati di serie temporali non strutturati. Per migliorare la precisione della generazione del codice Python, è stato implementato un flusso di lavoro personalizzato per la generazione di prompt con controllo umano.
Potendo contare su informazioni approfondite sullo stato delle loro risorse, i lavoratori dell’industria possono sfruttare appieno il potenziale dell’intelligenza artificiale generativa in vari casi d’uso, tra cui la diagnosi delle cause principali e la pianificazione della sostituzione delle parti. Con le Knowledge Base per Amazon Bedrock, la soluzione RAG è semplice da creare e gestire per gli sviluppatori.
La traiettoria della gestione e delle operazioni dei dati aziendali si sta inequivocabilmente spostando verso una più profonda integrazione con l’intelligenza artificiale generativa per ottenere informazioni complete sullo stato operativo. Questo cambiamento, guidato da Amazon Bedrock, è notevolmente amplificato dalla crescente robustezza e potenziale dei LLM come Base rocciosa dell'Amazzonia Claude 3 per elevare ulteriormente le soluzioni. Per saperne di più visita consultare il Documentazione di Amazon Bedrocke mettiti alla prova con Laboratorio Amazon Bedrock.
Circa gli autori
 Giulia Hu è un Senior AI/ML Solutions Architect presso Amazon Web Services. È specializzata in intelligenza artificiale generativa, data science applicata e architettura IoT. Attualmente fa parte del team Amazon Q ed è un membro/mentore attivo nella community del settore tecnico del machine learning. Lavora con clienti, dalle start-up alle imprese, per sviluppare alcune soluzioni di intelligenza artificiale generativa. È particolarmente appassionata nello sfruttare i modelli linguistici di grandi dimensioni per l'analisi avanzata dei dati e nell'esplorare applicazioni pratiche che affrontano le sfide del mondo reale.
Giulia Hu è un Senior AI/ML Solutions Architect presso Amazon Web Services. È specializzata in intelligenza artificiale generativa, data science applicata e architettura IoT. Attualmente fa parte del team Amazon Q ed è un membro/mentore attivo nella community del settore tecnico del machine learning. Lavora con clienti, dalle start-up alle imprese, per sviluppare alcune soluzioni di intelligenza artificiale generativa. È particolarmente appassionata nello sfruttare i modelli linguistici di grandi dimensioni per l'analisi avanzata dei dati e nell'esplorare applicazioni pratiche che affrontano le sfide del mondo reale.
 Sudeesh Sasidharan è Senior Solutions Architect presso AWS, all'interno del team Energy. Sudeesh ama sperimentare nuove tecnologie e costruire soluzioni innovative che risolvano sfide aziendali complesse. Quando non progetta soluzioni o non armeggia con le ultime tecnologie, lo puoi trovare sul campo da tennis a lavorare sul rovescio.
Sudeesh Sasidharan è Senior Solutions Architect presso AWS, all'interno del team Energy. Sudeesh ama sperimentare nuove tecnologie e costruire soluzioni innovative che risolvano sfide aziendali complesse. Quando non progetta soluzioni o non armeggia con le ultime tecnologie, lo puoi trovare sul campo da tennis a lavorare sul rovescio.
 Neil Desai è un dirigente tecnologico con oltre 20 anni di esperienza nel campo dell'intelligenza artificiale (AI), della scienza dei dati, dell'ingegneria del software e dell'architettura aziendale. In AWS, è a capo di un team di architetti di soluzioni specialistiche di servizi di intelligenza artificiale a livello mondiale che aiutano i clienti a creare soluzioni innovative basate sull'intelligenza artificiale generativa, a condividere le migliori pratiche con i clienti e a guidare la roadmap dei prodotti. Nei suoi precedenti ruoli presso Vestas, Honeywell e Quest Diagnostics, Neil ha ricoperto ruoli di leadership nello sviluppo e nel lancio di prodotti e servizi innovativi che hanno aiutato le aziende a migliorare le proprie operazioni, ridurre i costi e aumentare i ricavi. È appassionato di utilizzo della tecnologia per risolvere problemi del mondo reale ed è un pensatore strategico con una comprovata esperienza di successo.
Neil Desai è un dirigente tecnologico con oltre 20 anni di esperienza nel campo dell'intelligenza artificiale (AI), della scienza dei dati, dell'ingegneria del software e dell'architettura aziendale. In AWS, è a capo di un team di architetti di soluzioni specialistiche di servizi di intelligenza artificiale a livello mondiale che aiutano i clienti a creare soluzioni innovative basate sull'intelligenza artificiale generativa, a condividere le migliori pratiche con i clienti e a guidare la roadmap dei prodotti. Nei suoi precedenti ruoli presso Vestas, Honeywell e Quest Diagnostics, Neil ha ricoperto ruoli di leadership nello sviluppo e nel lancio di prodotti e servizi innovativi che hanno aiutato le aziende a migliorare le proprie operazioni, ridurre i costi e aumentare i ricavi. È appassionato di utilizzo della tecnologia per risolvere problemi del mondo reale ed è un pensatore strategico con una comprovata esperienza di successo.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

