Introduzione
Nella visione artificiale esistono diverse tecniche per il rilevamento di oggetti vivi, incluso Faster R-CNN, SSDe YOLO. Ogni tecnica ha i suoi limiti e vantaggi. Sebbene la R-CNN più veloce possa eccellere in termini di precisione, potrebbe non funzionare altrettanto bene in scenari in tempo reale, spingendo verso uno spostamento verso Algoritmo YOLO.
Il rilevamento degli oggetti è fondamentale nella visione artificiale, poiché consente alle macchine di identificare e localizzare gli oggetti all'interno di una cornice o di uno schermo. Nel corso degli anni sono stati sviluppati vari algoritmi di rilevamento degli oggetti e YOLO è emerso come uno di quelli di maggior successo. Recentemente è stato introdotto YOLOv8, migliorando ulteriormente le capacità dell'algoritmo.
In questa guida completa, esploriamo tre importanti algoritmi di rilevamento degli oggetti: Faster R-CNN, SSD (Single Shot MultiBox Detector) e YOLOv8. Discutiamo gli aspetti pratici dell'implementazione di questi algoritmi, inclusa la creazione di un ambiente virtuale e lo sviluppo di un'applicazione Streamlit.
Obiettivo di apprendimento
- Comprendi R-CNN, SSD e YOLO più veloci e analizza le differenze tra loro.
- Acquisisci esperienza pratica nell'implementazione di sistemi di rilevamento di oggetti dal vivo utilizzando OpenCV, Supervision e YOLOv8.
- Comprendere il modello di segmentazione delle immagini utilizzando l'annotazione Roboflow.
- Crea un'applicazione Streamlit per un'interfaccia utente semplice.
Esploriamo come eseguire la segmentazione delle immagini con YOLOv8!
Sommario
Questo articolo è stato pubblicato come parte di Blogathon sulla scienza dei dati.
R-CNN più veloce
Faster R-CNN (Faster Region-based Convolutional Neural Network) è un algoritmo di rilevamento di oggetti basato sul deep learning. Viene valutato utilizzando i framework R-CNN e Fast R-CNN e può essere considerato un'estensione di Fast R-CNN.
Questo algoritmo introduce la Region Proposal Network (RPN) per generare proposte regionali, sostituendo la ricerca selettiva utilizzata in R-CNN. L'RPN condivide i livelli convoluzionali con la rete di rilevamento, consentendo un addestramento end-to-end efficiente.
Le proposte della regione generate vengono quindi inserite in una rete Fast R-CNN per il perfezionamento del riquadro di delimitazione e la classificazione degli oggetti.
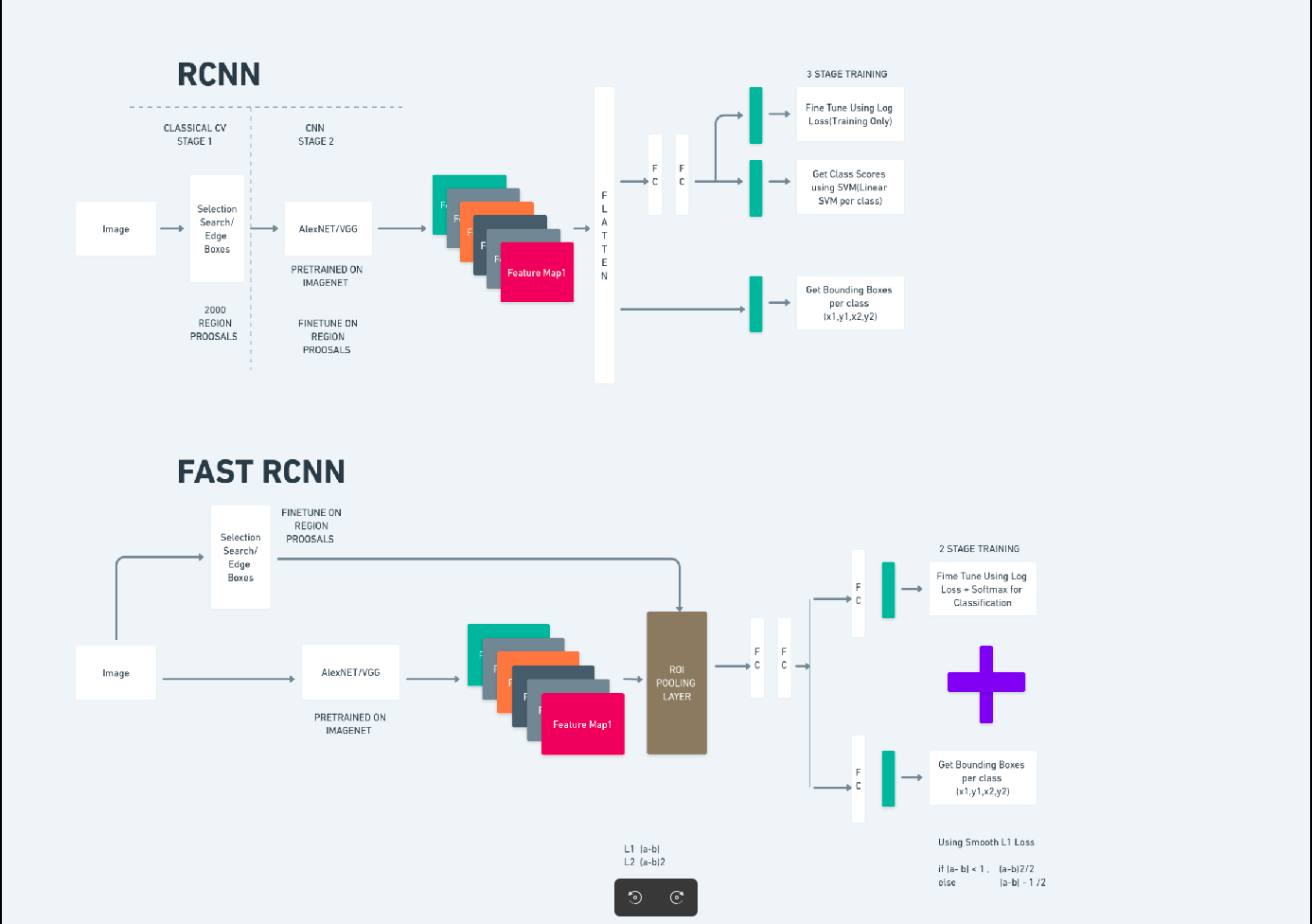
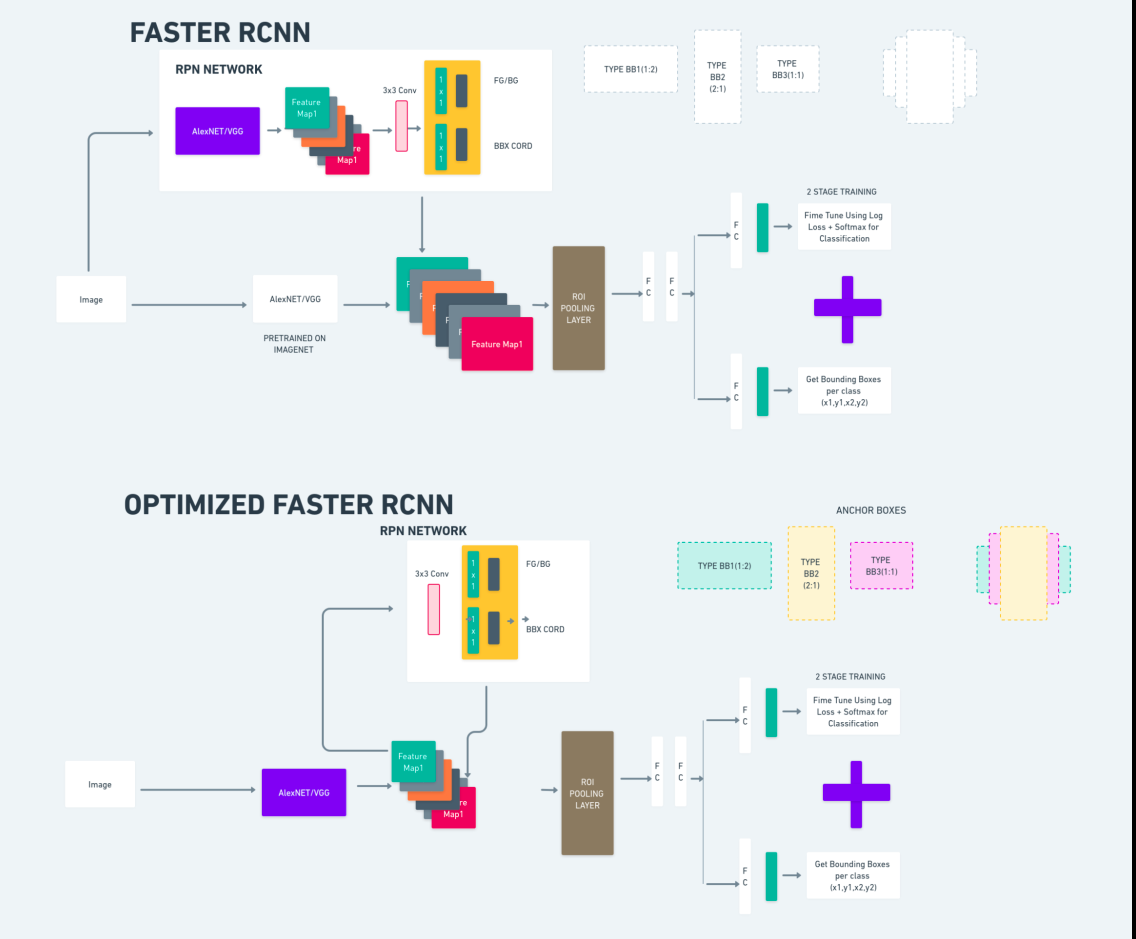
Il diagramma sopra illustra la famiglia Faster R-CNN in modo completo ed è di facile comprensione per la valutazione di ciascun algoritmo.
Rilevatore MultiBox a scatto singolo (SSD)
I Rilevatore MultiBox a scatto singolo (SSD) è popolare nel rilevamento di oggetti e utilizzato principalmente nelle attività di visione artificiale. Nel metodo precedente, Faster R-CNN, abbiamo seguito due passaggi: il primo passaggio riguardava la parte di rilevamento e il secondo riguardava la regressione. Tuttavia, con l'SSD, eseguiamo solo un singolo passaggio di rilevamento. L'SSD è stato introdotto nel 2016 per rispondere all'esigenza di un modello di rilevamento degli oggetti rapido e accurato.

L'SSD presenta numerosi vantaggi rispetto ai metodi di rilevamento degli oggetti precedenti come Faster R-CNN:
- Efficienza: SSD è un rilevatore a stadio singolo, il che significa che prevede direttamente i riquadri di delimitazione e i punteggi delle classi senza richiedere una fase separata di generazione della proposta. Ciò lo rende più veloce rispetto ai rilevatori a due stadi come Faster R-CNN.
- Formazione end-to-end: l'SSD può essere addestrato end-to-end, ottimizzando congiuntamente sia la rete di base che la testa di rilevamento, il che semplifica il processo di formazione.
- Fusione di funzionalità multiscala: l'SSD opera su mappe di funzionalità su più scale, consentendogli di rilevare oggetti di varie dimensioni in modo più efficace.
L'SSD raggiunge un buon equilibrio tra velocità e precisione, rendendolo adatto per applicazioni in tempo reale in cui sia le prestazioni che l'efficienza sono fondamentali.
Guardi solo una volta (YOLOv8)
Nel 2015, You Only Look Once (YOLO) è stato introdotto come algoritmo di rilevamento di oggetti in un documento di ricerca di Joseph Redmon, Santosh Divvala, Ross Girshick e Ali Farhadi. YOLO è un algoritmo single-shot che classifica direttamente un oggetto in un singolo passaggio facendo sì che una sola rete neurale preveda i riquadri di delimitazione e le probabilità di classe utilizzando un'immagine completa come input.
Ora, intendiamo YOLOv8 come progressi all'avanguardia nel rilevamento di oggetti in tempo reale con precisione e velocità migliorate. YOLOv8 ti consente di sfruttare modelli pre-addestrati, già addestrati su un vasto set di dati come COCO (Common Objects in Context). La segmentazione delle immagini fornisce informazioni a livello di pixel su ciascun oggetto, consentendo un'analisi e una comprensione più dettagliate del contenuto dell'immagine.
Sebbene la segmentazione delle immagini possa essere computazionalmente costosa, YOLOv8 integra questo metodo nella sua architettura di rete neurale, consentendo una segmentazione degli oggetti efficiente e accurata.
Principio di funzionamento di YOLOv8
YOLOv8 funziona dividendo prima l'immagine di input in celle della griglia. Utilizzando queste celle della griglia, YOLOv8 prevede i riquadri di delimitazione (bbox) con probabilità di classe.
Successivamente, YOLOv8 utilizza l'algoritmo NMS per ridurre la sovrapposizione. Ad esempio, se nell'immagine sono presenti più auto, risultando in riquadri di delimitazione sovrapposti, l'algoritmo NMS aiuta a ridurre questa sovrapposizione.
Differenza tra le varianti di Yolo V8: YOLOv8 è disponibile in tre varianti: YOLOv8, YOLOv8-L e YOLOv8-X. La differenza principale tra le varianti è la dimensione della rete dorsale. YOLOv8 ha la rete backbone più piccola, mentre YOLOv8-X ha la rete backbone più grande.
Synhydrid tra R-CNN, SSD e YOLO più veloci
| Aspetto | R-CNN più veloce | SSD | YOLO |
|---|---|---|---|
| Architettura | Rivelatore a due stadi con RPN e Fast R-CNN | Rilevatore monostadio | Rilevatore monostadio |
| Proposte regionali | Sì | Non | Non |
| Velocità di rilevamento | Più lento rispetto a SSD e YOLO | Più veloce rispetto a Faster R-CNN, più lento di YOLO | Molto veloce |
| Precisione | Precisione generalmente più elevata | Precisione e velocità bilanciate | Precisione decente, soprattutto per applicazioni in tempo reale |
| Flessibilità | Flessibile, può gestire oggetti di varie dimensioni e proporzioni | Può gestire più scale di oggetti | Può avere difficoltà con la localizzazione accurata di piccoli oggetti |
| Rilevamento unificato | Non | Non | Sì |
| Compromesso tra velocità e precisione | Generalmente sacrifica la velocità per la precisione | Bilancia velocità e precisione | Dà priorità alla velocità mantenendo una precisione decente |
Che cos'è la segmentazione?
Come sappiamo, la segmentazione significa che stiamo dividendo l'immagine grande in gruppi più piccoli in base a determinate caratteristiche. Comprendiamo la segmentazione delle immagini, che è la tecnica di visione artificiale utilizzata per suddividere un'immagine in diversi segmenti o regioni multiple. Poiché le immagini sono costituite da pixel e dalla segmentazione In Image, i pixel vengono raggruppati insieme in base alla somiglianza di colore, intensità, trama o altre proprietà visive.
Ad esempio, se un'immagine contiene alberi, automobili o persone, la segmentazione dell'immagine dividerà l'immagine in diverse classi che rappresentano oggetti o parti significative dell'immagine. La segmentazione delle immagini è ampiamente utilizzata in diversi campi come l'imaging medico, l'analisi delle immagini satellitari, il riconoscimento degli oggetti nella visione artificiale e altro ancora.

Nella parte di segmentazione, creiamo inizialmente il primo modello di segmentazione YOLOv8 utilizzando Robflow. Quindi, importiamo il modello di segmentazione per eseguire l'attività di segmentazione. La domanda sorge spontanea: perché creare il modello di segmentazione quando l’attività potrebbe essere completata solo con un algoritmo di rilevamento?
La segmentazione ci consente di ottenere l'immagine corporea completa di una classe. Mentre gli algoritmi di rilevamento si concentrano sul rilevamento della presenza di oggetti, la segmentazione fornisce una comprensione più precisa delineando i confini esatti degli oggetti. Ciò porta a una localizzazione e comprensione più accurata degli oggetti presenti nell'immagine.
Tuttavia, la segmentazione comporta in genere una maggiore complessità temporale rispetto agli algoritmi di rilevamento perché richiede passaggi aggiuntivi come la separazione delle annotazioni e la creazione del modello. Nonostante questo inconveniente, la maggiore precisione offerta dalla segmentazione può superare il costo computazionale nelle attività in cui la delineazione precisa degli oggetti è cruciale.
Rilevamento live passo dopo passo e segmentazione delle immagini con YOLOv8
In questo concetto esploreremo i passaggi per creare un ambiente virtuale utilizzando conda, attivando venv e installando i pacchetti dei requisiti utilizzando pip. creando prima il normale script Python, quindi creiamo l'applicazione streamlit.
Passaggio 1: crea un ambiente virtuale utilizzando Conda
conda create -p ./venv python=3.8 -yPassaggio 2: attivare l'ambiente virtuale
conda activate ./venv
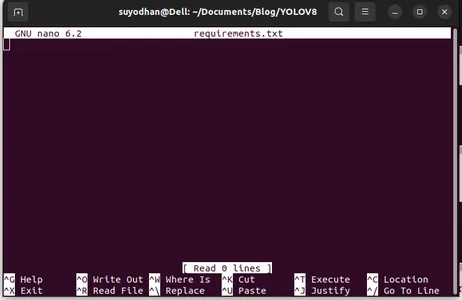
Passaggio 3: crea i requisiti.txt
Apri il terminale e incolla lo script seguente:
touch requirements.txtPassaggio 4: utilizzare il comando Nano e modificare i requisiti.txt
Dopo aver creato i requisiti.txt, scrivi il seguente comando per modificare i requisiti.txt
nano requirements.txtDopo aver eseguito lo script precedente puoi vedere questa interfaccia utente.
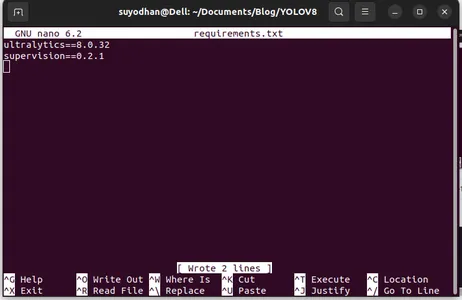
Scrivi i suoi pacchetti richiesti.
ultralytics==8.0.32
supervision==0.2.1
streamlitQuindi premere il tasto “ctrl+o”(questo comando salva la parte di modifica), quindi premere il tasto "Accedere"
Dopo aver premuto il "Ctrl+x”. puoi uscire dal file. e andando sul sentiero principale.
Passaggio 5: installazione del file require.txt
pip install -r requirements.txtPassaggio 6: crea lo script Python
Nel terminale scrivi il seguente script o possiamo dire comando.
touch main.pyDopo aver creato main.py apri il codice vs usi il comando scrivi nel terminale,
code Passaggio 7: scrivere lo script Python
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Dopo aver eseguito questo comando puoi vedere che la videocamera è aperta e rileva una parte di te. come le parti di genere e di sfondo.
Passaggio 7: crea un'app ottimizzata
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
In questo script, stiamo creando l'applicazione streamlit e creando il pulsante in modo che dopo aver premuto il pulsante la fotocamera del dispositivo sia aperta e rilevi la parte nell'inquadratura.
Esegui questo script utilizzando questo comando.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Dopo aver eseguito il comando precedente, supponiamo che tu abbia ricevuto l'errore di raggiungimento del tipo,
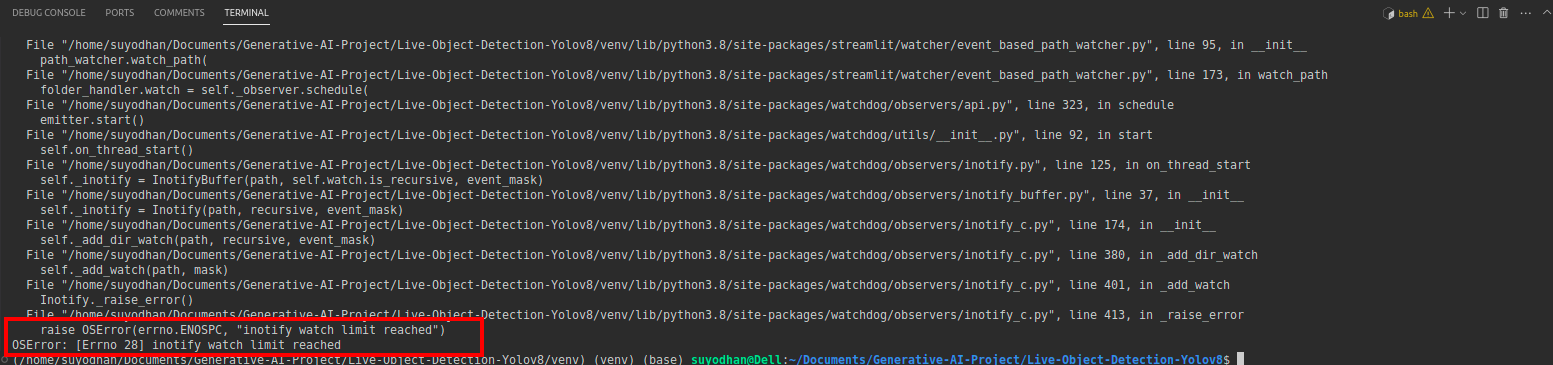
quindi premi questo comando,
sudo sysctl fs.inotify.max_user_watches=524288Dopo aver premuto il comando con cui vuoi scrivere la tua password perché stiamo usando il comando sudo sudo is god :)
Esegui nuovamente lo script. e puoi vedere l'applicazione streamlit.
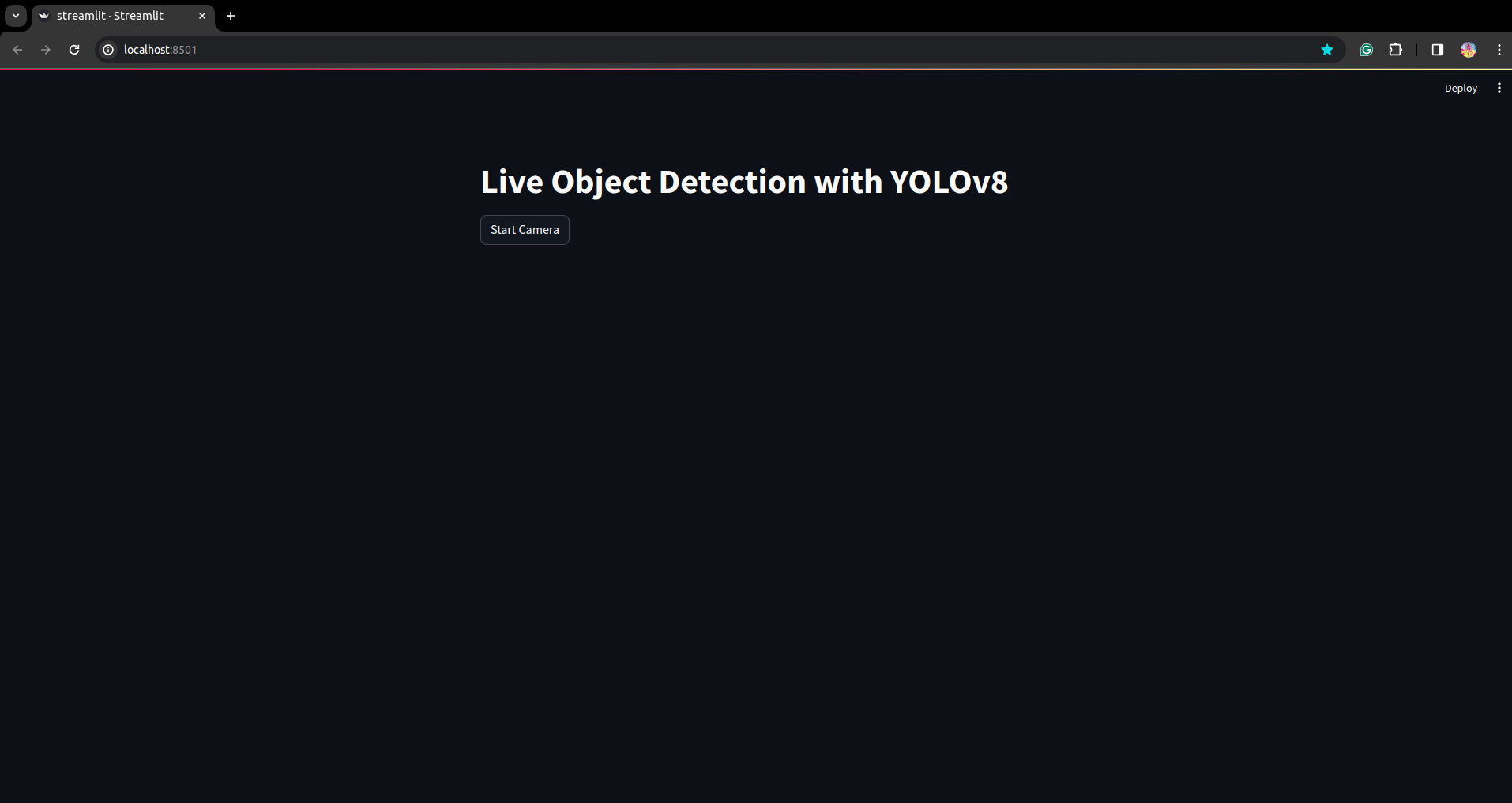
Qui possiamo creare un'applicazione di rilevamento live di successo, nella parte successiva vedremo la parte di segmentazione.
Passaggi per l'annotazione
Passaggio 1: configurazione di Roboflow
Dopo aver effettuato l'accesso al "Crea progetto”. qui puoi creare il progetto e il gruppo di annotazioni.

Passaggio 2: download del set di dati
Qui consideriamo il semplice esempio ma vuoi usarlo nella dichiarazione del tuo problema, quindi sto usando qui il set di dati duck.
Vai a questo link e scarica il set di dati delle papere.

Estrai la cartella lì puoi vedere le tre cartelle: treno, prova e val.
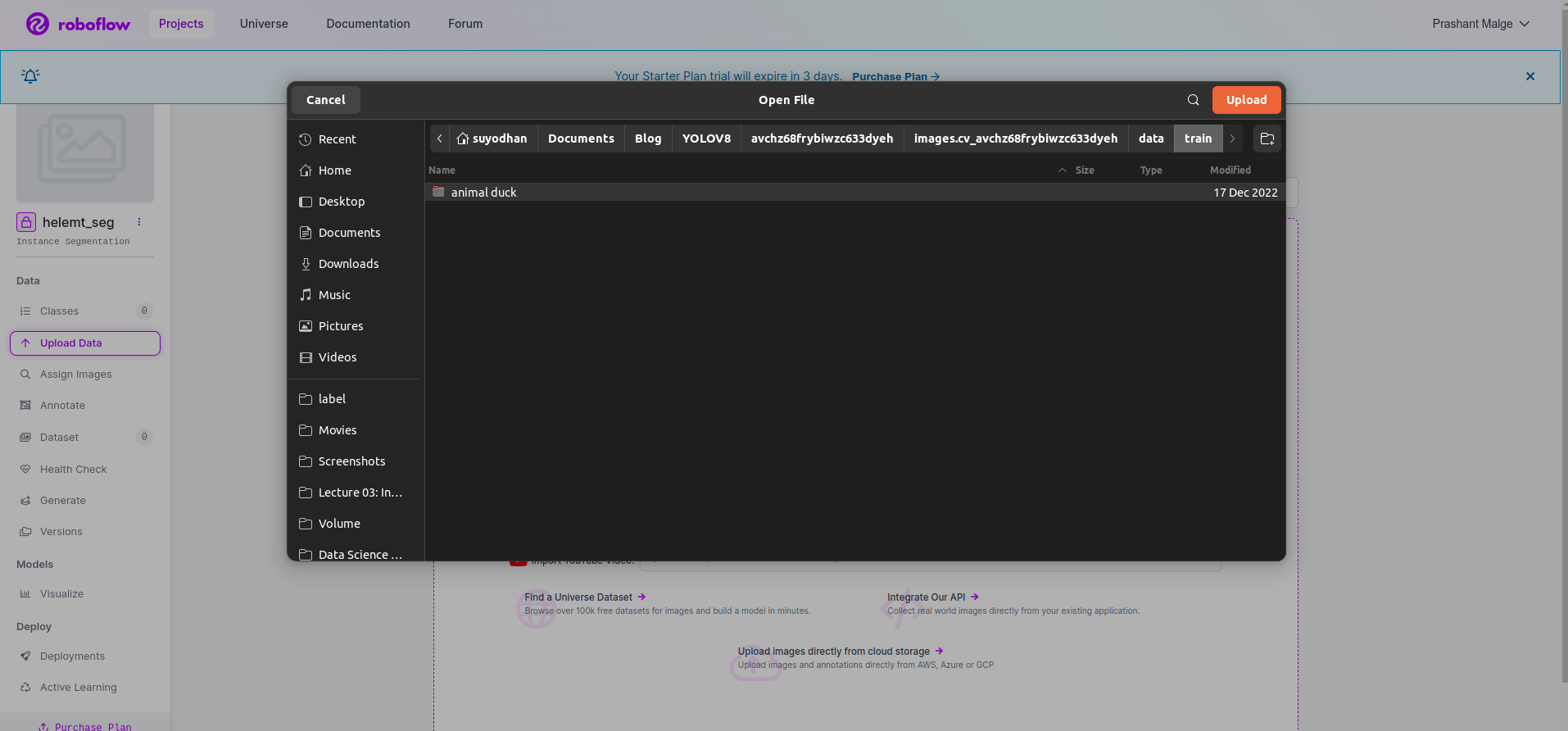
Passaggio 3: caricamento del set di dati su roboflow
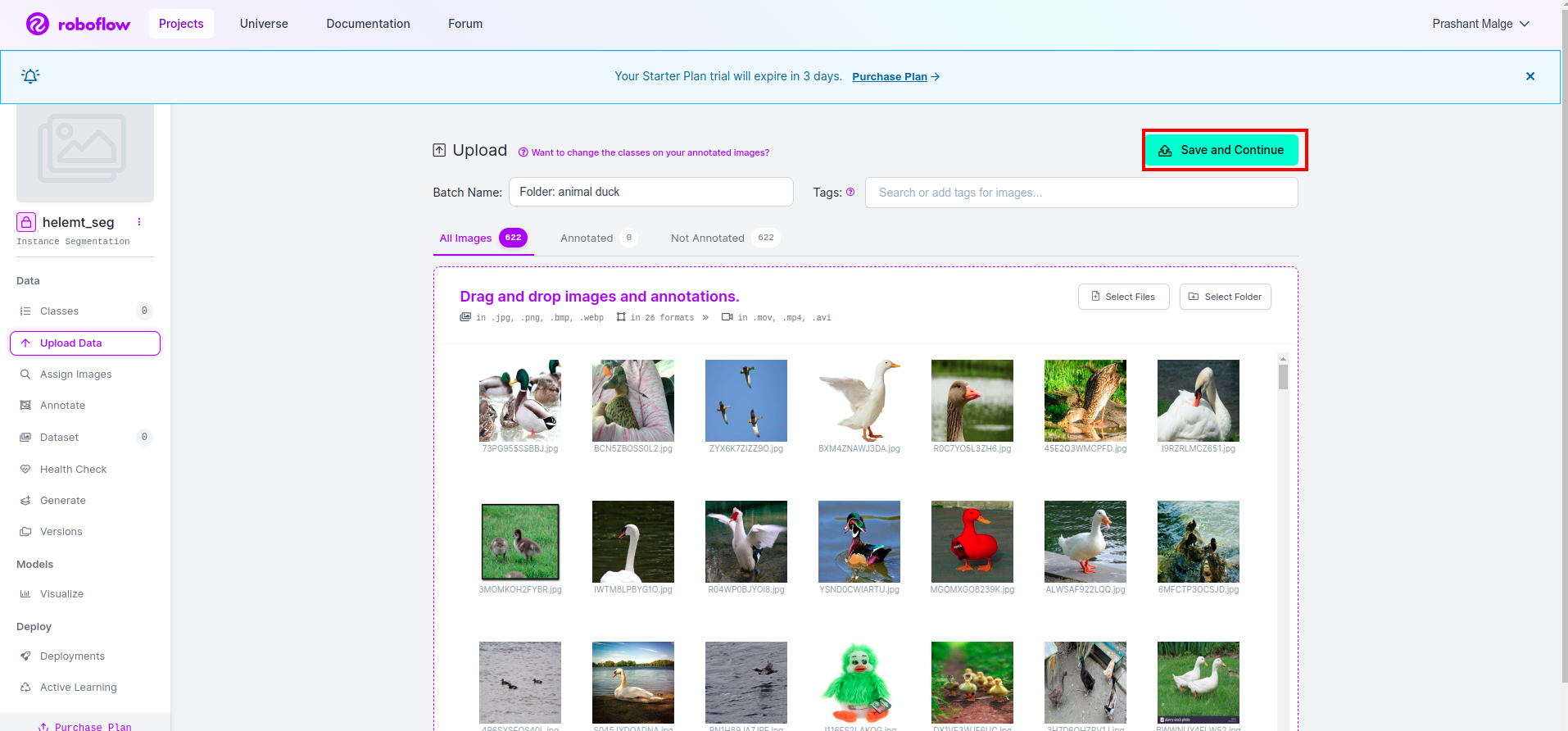
Dopo aver creato il progetto in roboflow puoi vedere questa interfaccia utente qui puoi caricare il tuo set di dati, quindi stai caricando solo le immagini delle parti del treno seleziona "seleziona cartella" opzione.
Quindi fare clic su "salva e continua" opzione come contrassegno in una casella rettangolare rossa
Passaggio 4: aggiungi il nome della classe
Quindi vai al parte di classe sul lato sinistro seleziona la casella rossa. e scrivi il nome della classe come anatra, dopo aver cliccato sulla casella verde.
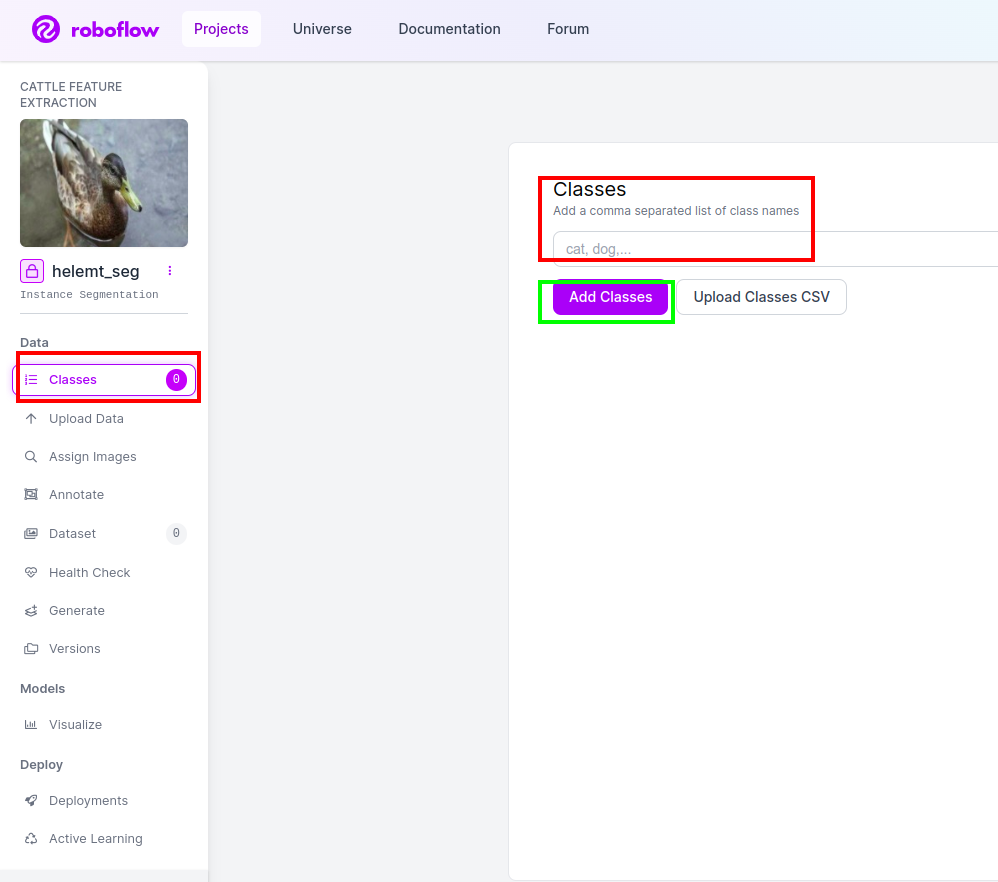
Ora la nostra configurazione è completa e anche la parte successiva, come la parte delle annotazioni, è semplice.
Passaggio 5: avviare il parte di annotazione
Vai opzione di annotazione Ho contrassegnato nella casella rossa, quindi ho fatto clic su Avvia la parte dell'annotazione come ho contrassegnato nella casella verde.
Fai clic sulla prima immagine in cui puoi vedere questa interfaccia utente. Dopo averlo visto, fai clic sull'opzione di annotazione manuale.
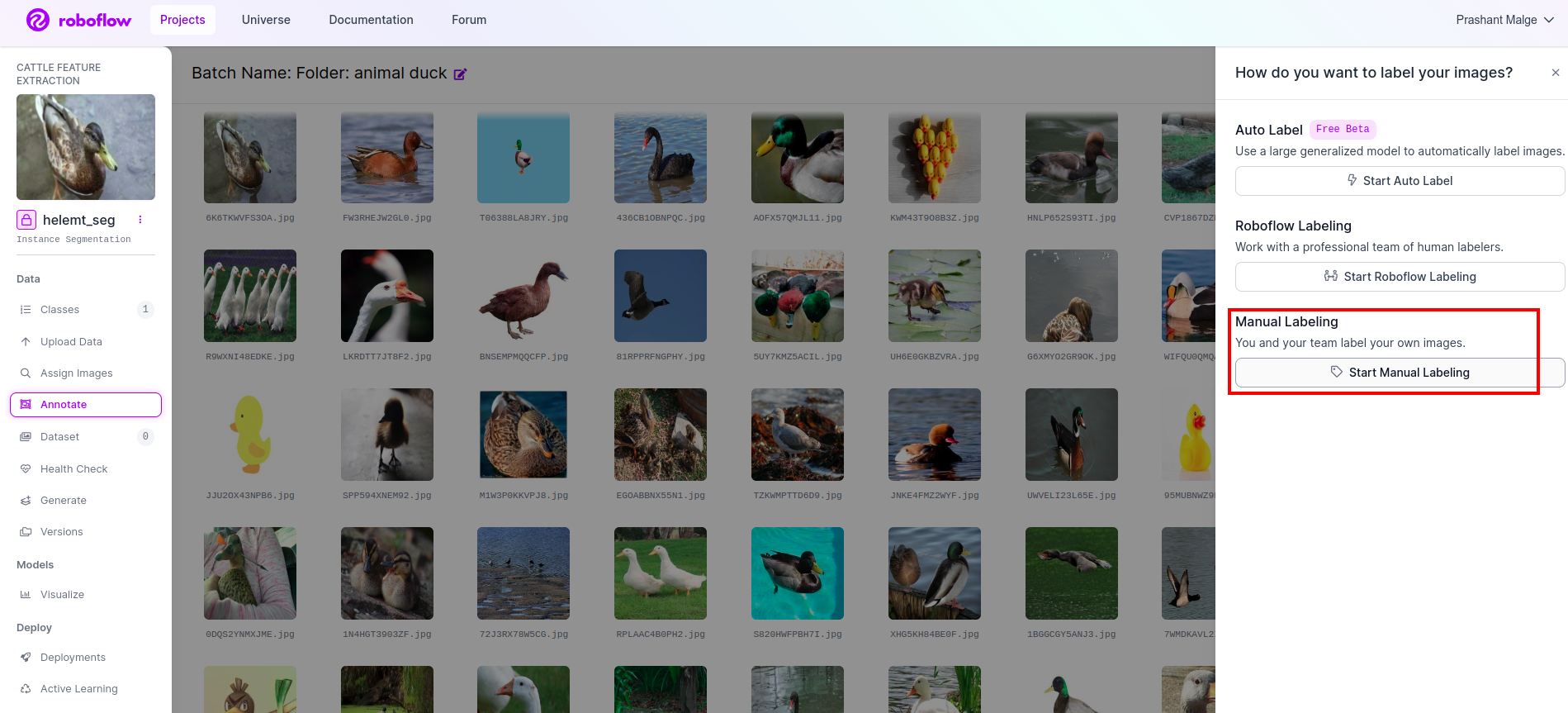
Quindi aggiungi il tuo ID e-mail o il nome del tuo compagno di squadra in modo da poter assegnare l'attività.
Fai clic sulla prima immagine in cui puoi vedere questa interfaccia utente. qui fare clic sul riquadro rosso in modo da poter selezionare il modello multipolinomiale.
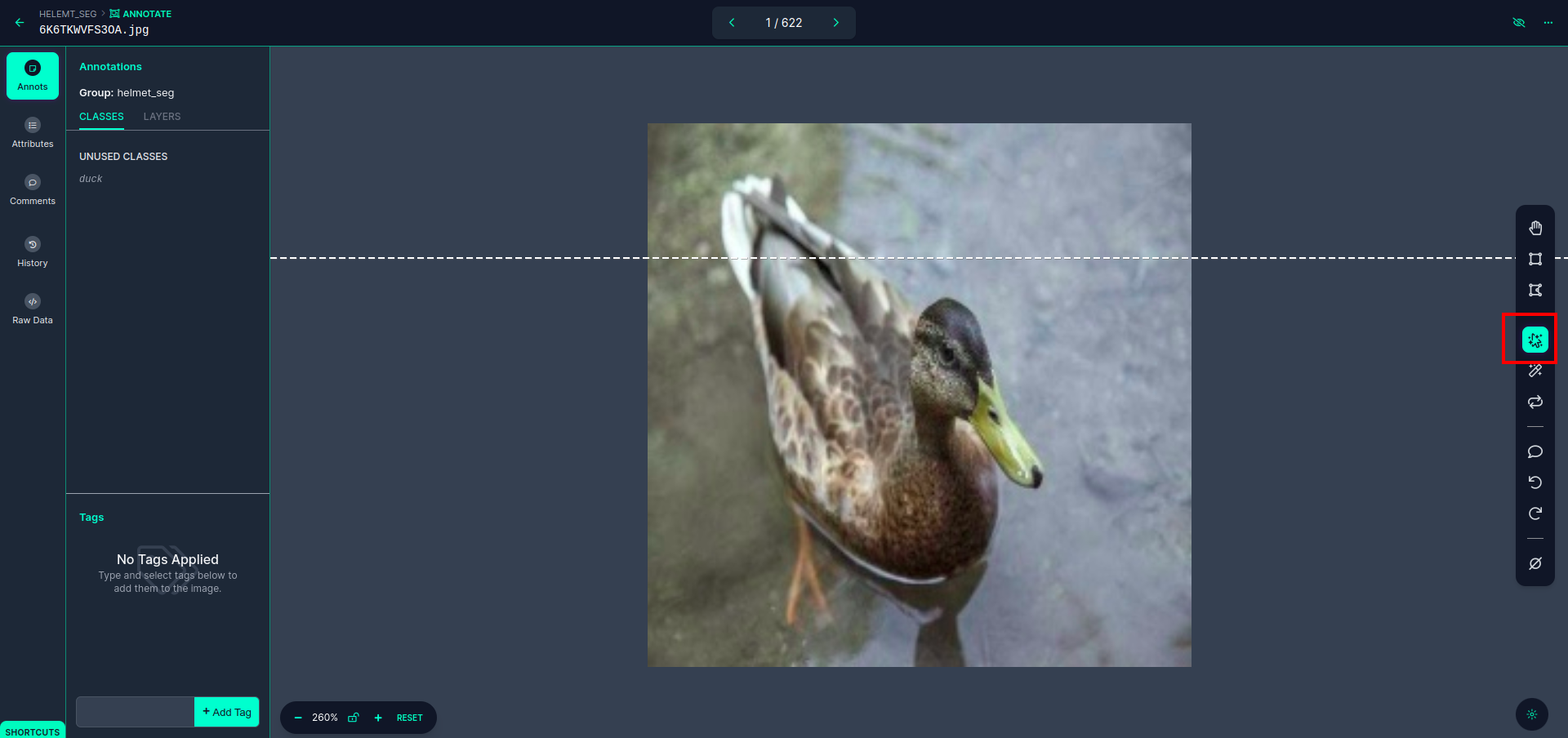
Dopo aver fatto clic sulla casella rossa, seleziona il modello predefinito e fai clic sull'oggetto papera. Questo segmenterà automaticamente l'immagine. Quindi, fai clic sulla parte successiva e salvala. Vedrai quindi il lato sinistro contrassegnato in un riquadro rosso, dove puoi vedere il nome della classe.
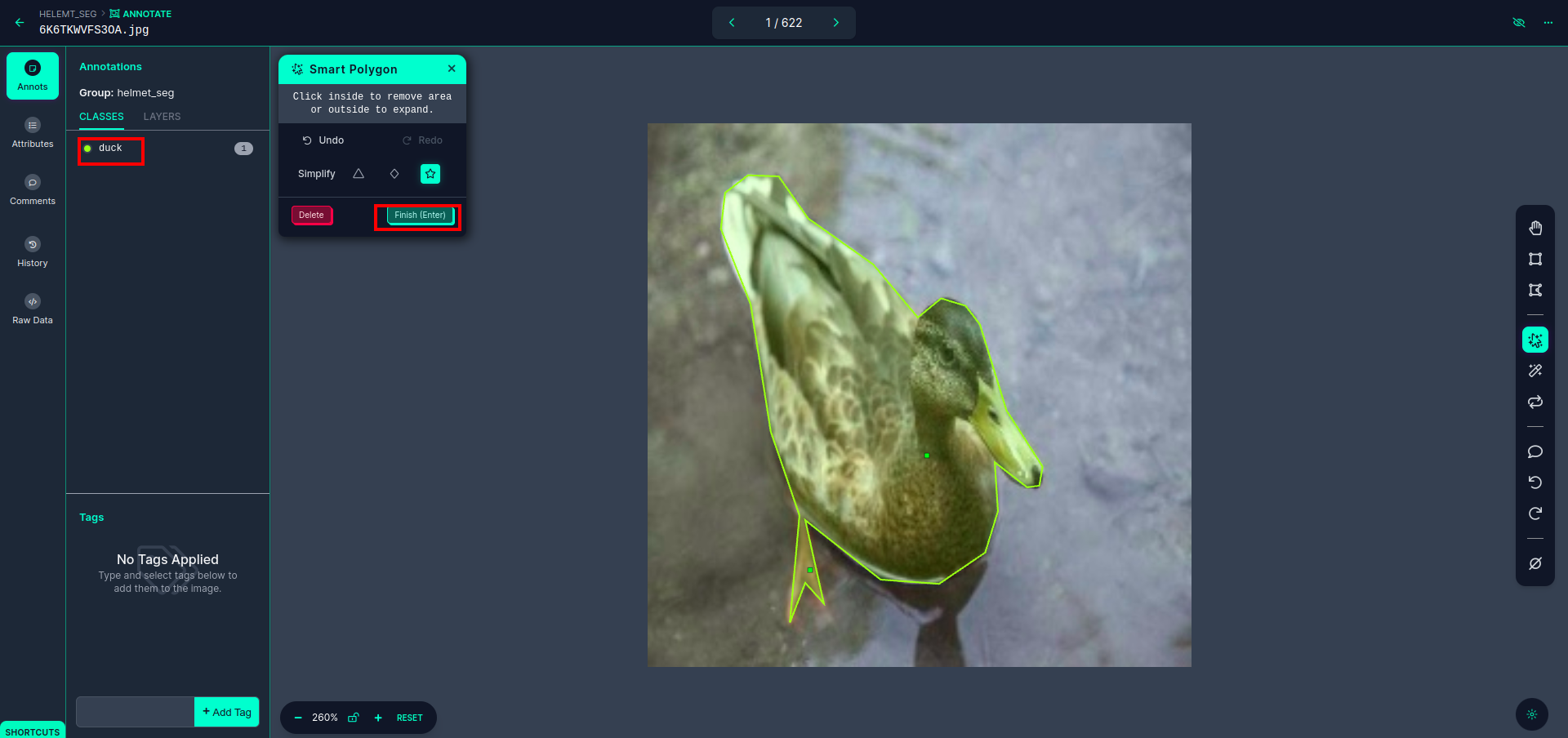
Clicca su salva e inserisci opzione. annotare tutte le immagini.
Aggiungi le immagini per il formato YOLOv8. Sul lato destro vedrai l'opzione per aggiungere immagini nella sezione delle annotazioni. Qui vengono create due parti: una per le immagini annotate e una per le immagini senza annotazioni.
- Innanzitutto, fai clic sul lato sinistro "annotare" opzione quindi aggiungere le immagini al set di dati.
- Quindi fare clic su successivo “Aggiungi immagini".
Infine, creiamo il set di dati, quindi fai clic sull'opzione "Genera" sul lato sinistro, quindi seleziona l'opzione e premi l'opzione Conitune.
Quindi ottieni l'interfaccia utente dell'opzione di divisione del set di dati qui puoi controllare le cartelle train, test e val in cui le loro immagini vengono divise automaticamente. e fare clic sulla casella rossa sopra Opzione Esporta set di dati e scarica il file zip. la struttura delle cartelle dei file zip è come...
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Passaggio 6: scrivere lo script per addestrare il modello di segmentazione delle immagini
In questa parte innanzitutto crei il file Google Collab utilizzando Drive, quindi carichi il tuo set di dati. e sposta Google Drive utilizzando Google Collab.
1. Usa questo comando per Monta Google Drive
from google.colab import drive
drive.mount('/content/gdrive')2. Definire la directory dei dati Utilizza la variabile Costante.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Installazione del pacchetto richiesto, Installa gli ultralitici
!pip install ultralytics4. Importazione delle librerie
import os
from ultralytics import YOLO5. Carica YOLOv8 pre-addestrato modello(qui abbiamo modelli diversi controlla anche la documentazione ufficiale lì puoi vedere i diversi modelli)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Allena il modello
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together No, controlla l'unità. La cartella del nome del modello viene creata e il modello viene salvato per la previsione che vogliamo per questo modello.
7. Prevedere il modello
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Qui puoi vedere l'immagine di segmentazione salvata.

Ora finalmente possiamo costruire sia modelli di rilevamento in tempo reale che di segmentazione delle immagini.
Conclusione
In questo blog esploriamo il rilevamento di oggetti dal vivo e la segmentazione delle immagini con YOLOv8. Per il rilevamento dal vivo, importiamo un modello YOLOv8 pre-addestrato e utilizziamo la libreria di visione artificiale, OpenCV, per aprire la fotocamera e rilevare oggetti. Inoltre, creiamo un'applicazione Streamlit per un'interfaccia utente attraente.
Successivamente, approfondiremo la segmentazione delle immagini con YOLOv8. Importiamo un modello pre-addestrato ed eseguiamo l'apprendimento del trasferimento su un set di dati personalizzato. In precedenza, abbiamo esplorato Roboflow per l'annotazione dei set di dati, fornendo un'alternativa facile da usare a strumenti come EtichettaImg.
Infine, prevediamo un'immagine contenente un'anatra. Sebbene l'oggetto nell'immagine sembri essere un uccello, specifichiamo il nome della classe come "anatra" a scopo dimostrativo.
Punti chiave
- Conoscere i modelli di rilevamento degli oggetti come Faster R-CNN, SSD e l'ultimo YOLOv8.
- Comprendere lo strumento di annotazione Roboflow e il suo ruolo nella creazione di set di dati per modelli di segmentazione YOLOv8.
- Esplorare il rilevamento di oggetti dal vivo utilizzando OpenCV (cv2) e Supervision, migliorando le abilità pratiche.
- Formazione e implementazione di un modello di segmentazione utilizzando YOLOv8, acquisendo esperienza pratica.
Domande frequenti
R. Il rilevamento degli oggetti implica l'identificazione e la localizzazione di più oggetti all'interno di un'immagine, in genere disegnando riquadri di delimitazione attorno ad essi. La segmentazione dell'immagine, d'altro canto, divide un'immagine in segmenti o regioni in base alla somiglianza dei pixel, fornendo una comprensione più dettagliata dei confini dell'oggetto.
R. YOLOv8 migliora rispetto alle versioni precedenti incorporando progressi nell'architettura di rete, nelle tecniche di formazione e nell'ottimizzazione. Può offrire migliore precisione, velocità ed efficienza rispetto a YOLOv3.
R. YOLOv8 può essere utilizzato per il rilevamento di oggetti in tempo reale su dispositivi incorporati, a seconda delle capacità hardware e dell'ottimizzazione del modello. Tuttavia, potrebbe richiedere ottimizzazioni come l'eliminazione del modello o la quantizzazione per ottenere prestazioni in tempo reale su dispositivi con risorse limitate.
R. Roboflow offre strumenti di annotazione intuitivi, funzionalità di gestione dei set di dati e supporto per vari formati di annotazioni. Semplifica il processo di annotazione, consente la collaborazione e fornisce il controllo della versione, semplificando la creazione e la gestione di set di dati per progetti di visione artificiale.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

