Oggi, i clienti di tutti i settori, che si tratti di servizi finanziari, sanità e scienze della vita, viaggi e ospitalità, media e intrattenimento, telecomunicazioni, software come servizio (SaaS) e persino fornitori di modelli proprietari, utilizzano modelli linguistici di grandi dimensioni (LLM) per creare applicazioni come chatbot con domande e risposte (QnA), motori di ricerca e basi di conoscenza. Questi IA generativa le applicazioni non vengono utilizzate solo per automatizzare i processi aziendali esistenti, ma hanno anche la capacità di trasformare l'esperienza dei clienti che utilizzano queste applicazioni. Con i progressi compiuti con LLM come il Mixtral-8x7B Istruzione, derivato di architetture come la miscela di esperti (MoE), i clienti sono alla continua ricerca di modi per migliorare le prestazioni e la precisione delle applicazioni di intelligenza artificiale generativa, consentendo loro di utilizzare in modo efficace una gamma più ampia di modelli chiusi e open source.
In genere vengono utilizzate numerose tecniche per migliorare la precisione e le prestazioni dell'output di un LLM, come la messa a punto con regolazione fine efficiente dei parametri (PEFT), apprendimento per rinforzo dal feedback umano (RLHF), e l'esecuzione distillazione della conoscenza. Tuttavia, quando si creano applicazioni di intelligenza artificiale generativa, è possibile utilizzare una soluzione alternativa che consenta l'incorporazione dinamica della conoscenza esterna e di controllare le informazioni utilizzate per la generazione senza la necessità di mettere a punto il modello di base esistente. È qui che entra in gioco la Retrieval Augmented Generation (RAG), in particolare per le applicazioni di intelligenza artificiale generativa in contrapposizione alle alternative di messa a punto più costose e robuste di cui abbiamo discusso. Se stai implementando applicazioni RAG complesse nelle tue attività quotidiane, potresti incontrare sfide comuni con i tuoi sistemi RAG come recupero impreciso, aumento delle dimensioni e della complessità dei documenti e overflow del contesto, che possono avere un impatto significativo sulla qualità e l'affidabilità delle risposte generate .
Questo post discute i modelli RAG per migliorare l'accuratezza della risposta utilizzando LangChain e strumenti come il document retriever principale oltre a tecniche come la compressione contestuale per consentire agli sviluppatori di migliorare le applicazioni di intelligenza artificiale generativa esistenti.
Panoramica della soluzione
In questo post, dimostriamo l'uso della generazione di testo Instruct Mixtral-8x7B combinata con il modello di incorporamento BGE Large En per costruire in modo efficiente un sistema RAG QnA su un notebook Amazon SageMaker utilizzando lo strumento di recupero dei documenti principali e la tecnica di compressione contestuale. Il diagramma seguente illustra l'architettura di questa soluzione.
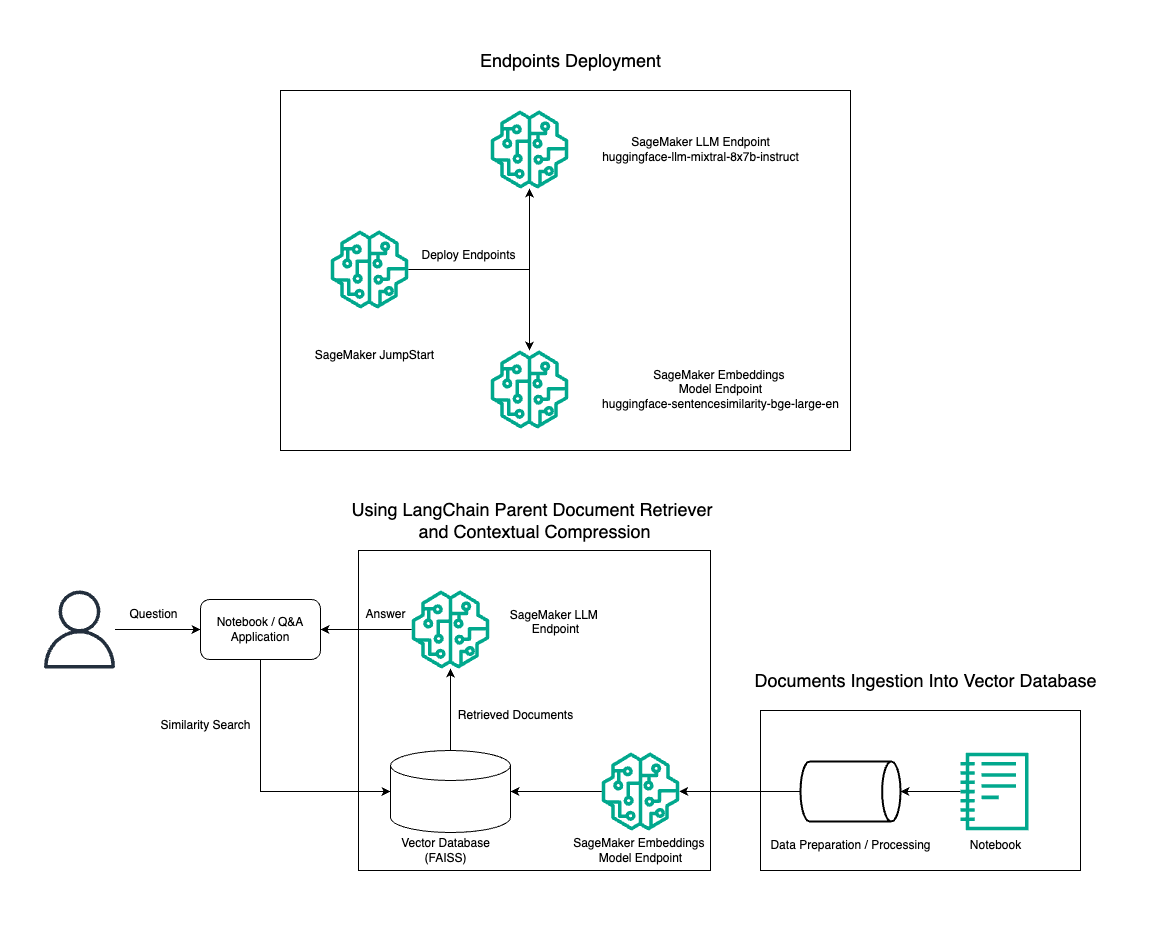
Puoi implementare questa soluzione con pochi clic utilizzando JumpStart di Amazon SageMaker, una piattaforma completamente gestita che offre modelli di base all'avanguardia per vari casi d'uso come scrittura di contenuti, generazione di codice, risposta a domande, copywriting, riepilogo, classificazione e recupero di informazioni. Fornisce una raccolta di modelli preaddestrati che puoi distribuire rapidamente e con facilità, accelerando lo sviluppo e la distribuzione di applicazioni di machine learning (ML). Uno dei componenti chiave di SageMaker JumpStart è il Model Hub, che offre un vasto catalogo di modelli pre-addestrati, come Mixtral-8x7B, per una varietà di attività.
Mixtral-8x7B utilizza un'architettura MoE. Questa architettura consente a diverse parti di una rete neurale di specializzarsi in compiti diversi, dividendo efficacemente il carico di lavoro tra più esperti. Questo approccio consente la formazione e l'implementazione efficienti di modelli più ampi rispetto alle architetture tradizionali.
Uno dei principali vantaggi dell'architettura MoE è la sua scalabilità. Distribuendo il carico di lavoro tra più esperti, i modelli MoE possono essere addestrati su set di dati più grandi e ottenere prestazioni migliori rispetto ai modelli tradizionali della stessa dimensione. Inoltre, i modelli MoE possono essere più efficienti durante l’inferenza perché solo un sottoinsieme di esperti deve essere attivato per un dato input.
Per ulteriori informazioni su Mixtral-8x7B Instruct su AWS, fare riferimento a Mixtral-8x7B è ora disponibile in Amazon SageMaker JumpStart. Il modello Mixtral-8x7B è reso disponibile sotto la permissiva licenza Apache 2.0, per un utilizzo senza restrizioni.
In questo post, discutiamo di come è possibile utilizzare LangChain per creare applicazioni RAG efficaci e più efficienti. LangChain è una libreria Python open source progettata per creare applicazioni con LLM. Fornisce un quadro modulare e flessibile per combinare LLM con altri componenti, come basi di conoscenza, sistemi di recupero e altri strumenti di intelligenza artificiale, per creare applicazioni potenti e personalizzabili.
Esaminiamo la costruzione di una pipeline RAG su SageMaker con Mixtral-8x7B. Utilizziamo il modello di generazione del testo Mixtral-8x7B Instruct con il modello di incorporamento BGE Large En per creare un sistema QnA efficiente utilizzando RAG su un notebook SageMaker. Utilizziamo un'istanza ml.t3.medium per dimostrare la distribuzione di LLM tramite SageMaker JumpStart, a cui è possibile accedere tramite un endpoint API generato da SageMaker. Questa configurazione consente l'esplorazione, la sperimentazione e l'ottimizzazione di tecniche RAG avanzate con LangChain. Illustriamo inoltre l'integrazione dell'archivio FAIISS Embedding nel flusso di lavoro RAG, evidenziando il suo ruolo nell'archiviazione e nel recupero degli incorporamenti per migliorare le prestazioni del sistema.
Eseguiamo una breve panoramica del notebook SageMaker. Per istruzioni più dettagliate e dettagliate, fare riferimento a Modelli RAG avanzati con Mixtral sul repository GitHub Jumpstart di SageMaker.
La necessità di modelli RAG avanzati
I modelli RAG avanzati sono essenziali per migliorare le attuali capacità dei LLM nell'elaborazione, comprensione e generazione di testo simile a quello umano. Con l'aumento delle dimensioni e della complessità dei documenti, la rappresentazione di più aspetti del documento in un unico incorporamento può portare a una perdita di specificità. Sebbene sia essenziale catturare l'essenza generale di un documento, è altrettanto fondamentale riconoscere e rappresentare i vari sottocontesti al suo interno. Questa è una sfida che spesso devi affrontare quando lavori con documenti di grandi dimensioni. Un'altra sfida con RAG è che durante il recupero non si è a conoscenza delle query specifiche che il sistema di archiviazione dei documenti dovrà gestire al momento dell'acquisizione. Ciò potrebbe far sì che le informazioni più rilevanti per una query vengano sepolte sotto il testo (overflow del contesto). Per mitigare gli errori e migliorare l'architettura RAG esistente, è possibile utilizzare modelli RAG avanzati (recupero documenti principali e compressione contestuale) per ridurre gli errori di recupero, migliorare la qualità delle risposte e consentire la gestione di domande complesse.
Con le tecniche discusse in questo post, puoi affrontare le principali sfide associate al recupero e all'integrazione della conoscenza esterna, consentendo alla tua applicazione di fornire risposte più precise e contestualmente consapevoli.
Nelle sezioni seguenti, esploriamo come recuperatori di documenti principali ed compressione contestuale può aiutarti ad affrontare alcuni dei problemi di cui abbiamo discusso.
Recupero documenti genitore
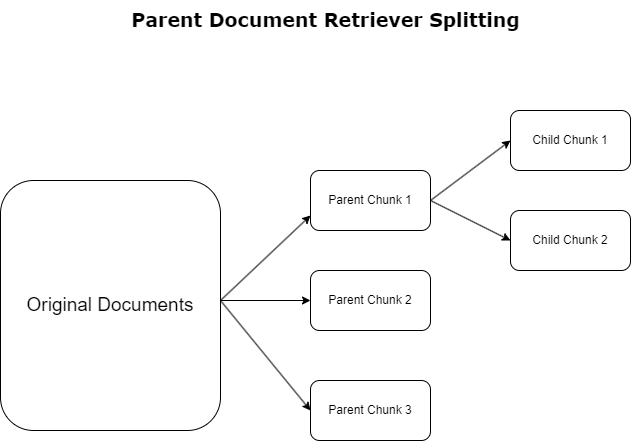
Nella sezione precedente, abbiamo evidenziato le sfide che le applicazioni RAG incontrano quando gestiscono documenti di grandi dimensioni. Per affrontare queste sfide, recuperatori di documenti principali classificare e designare i documenti in entrata come documenti dei genitori. Questi documenti sono riconosciuti per la loro natura completa ma non vengono utilizzati direttamente nella loro forma originale per gli incorporamenti. Invece di comprimere un intero documento in un singolo incorporamento, i document retriever principali sezionano questi documenti principali documenti del bambino. Ogni documento figlio cattura aspetti o argomenti distinti dal documento principale più ampio. Dopo l'identificazione di questi segmenti figli, a ciascuno vengono assegnati incorporamenti individuali, cogliendone la specifica essenza tematica (vedere il diagramma seguente). Durante il recupero, viene richiamato il documento principale. Questa tecnica fornisce funzionalità di ricerca mirate ma ad ampio raggio, fornendo al LLM una prospettiva più ampia. I recuperatori di documenti principali forniscono ai LLM un duplice vantaggio: la specificità degli incorporamenti di documenti secondari per il recupero di informazioni precise e pertinenti, insieme all'invocazione di documenti principali per la generazione di risposte, che arricchisce gli output di LLM con un contesto stratificato e approfondito.
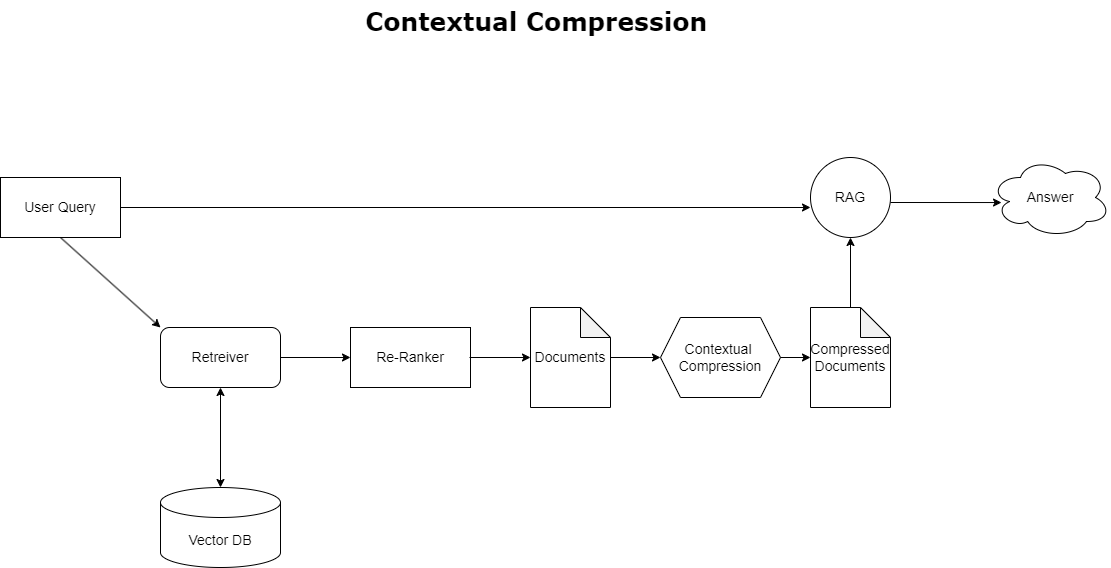
Compressione contestuale
Per risolvere il problema dell'overflow del contesto discusso in precedenza, è possibile utilizzare compressione contestuale per comprimere e filtrare i documenti recuperati in linea con il contesto della query, in modo che vengano conservate ed elaborate solo le informazioni pertinenti. Ciò si ottiene attraverso una combinazione di un retriever di base per il recupero iniziale dei documenti e di un compressore di documenti per perfezionare questi documenti riducendone il contenuto o escludendoli completamente in base alla pertinenza, come illustrato nel diagramma seguente. Questo approccio semplificato, facilitato dal recupero della compressione contestuale, migliora notevolmente l'efficienza dell'applicazione RAG fornendo un metodo per estrarre e utilizzare solo ciò che è essenziale da una massa di informazioni. Affronta direttamente il problema del sovraccarico di informazioni e dell'elaborazione dei dati irrilevanti, portando a una migliore qualità della risposta, operazioni LLM più convenienti e un processo di recupero complessivo più fluido. Essenzialmente, è un filtro che adatta le informazioni alla query in questione, rendendolo uno strumento molto necessario per gli sviluppatori che mirano a ottimizzare le proprie applicazioni RAG per migliori prestazioni e soddisfazione dell'utente.
Prerequisiti
Se non conosci SageMaker, fai riferimento a Guida allo sviluppo di Amazon SageMaker.
Prima di iniziare con la soluzione, creare un account AWS. Quando crei un account AWS, ottieni un'identità Single Sign-On (SSO) che ha accesso completo a tutti i servizi e le risorse AWS nell'account. Questa identità è chiamata account AWS utente root.
Accesso al Console di gestione AWS utilizzando l'indirizzo e-mail e la password utilizzati per creare l'account avrai accesso completo a tutte le risorse AWS nel tuo account. Ti consigliamo vivamente di non utilizzare l'utente root per le attività quotidiane, anche quelle amministrative.
Attenersi invece al migliori pratiche di sicurezza in Gestione dell'identità e dell'accesso di AWS (IAM), e creare un utente e un gruppo amministrativo. Quindi blocca in modo sicuro le credenziali dell'utente root e usale per eseguire solo alcune attività di gestione di account e servizi.
Il modello Mixtral-8x7b richiede un'istanza ml.g5.48xlarge. SageMaker JumpStart fornisce un modo semplificato per accedere e distribuire oltre 100 diversi modelli open source e di terze parti. In modo da avviare un endpoint per ospitare Mixtral-8x7B da SageMaker JumpStart, potrebbe essere necessario richiedere un aumento della quota del servizio per accedere a un'istanza ml.g5.48xlarge per l'utilizzo dell'endpoint. Puoi richiedere aumenti della quota del servizio attraverso la console, Interfaccia della riga di comando di AWS (AWS CLI) o API per consentire l'accesso a tali risorse aggiuntive.
Configura un'istanza notebook SageMaker e installa le dipendenze
Per iniziare, crea un'istanza notebook SageMaker e installa le dipendenze richieste. Fare riferimento al Repository GitHub per garantire una configurazione di successo. Dopo aver configurato l'istanza notebook, puoi distribuire il modello.
Puoi anche eseguire il notebook localmente sul tuo ambiente di sviluppo integrato (IDE) preferito. Assicurati di avere installato Jupyter Notebook Lab.
Distribuire il modello
Distribuisci il modello Mixtral-8X7B Instruct LLM su SageMaker JumpStart:
Distribuisci il modello di incorporamento BGE Large En su SageMaker JumpStart:
Configura LangChain
Dopo aver importato tutte le librerie necessarie e aver distribuito il modello Mixtral-8x7B e il modello di incorporamento BGE Large En, ora puoi configurare LangChain. Per istruzioni dettagliate, fare riferimento a Repository GitHub.
Preparazione dei dati
In questo post, utilizziamo diversi anni di lettere agli azionisti di Amazon come corpus di testi su cui eseguire domande di risposta. Per passaggi più dettagliati per preparare i dati, fare riferimento a Repository GitHub.
Risposta alla domanda
Una volta preparati i dati, è possibile utilizzare il wrapper fornito da LangChain, che avvolge l'archivio vettoriale e accetta input per LLM. Questo wrapper esegue i seguenti passaggi:
- Accetta la domanda di input.
- Crea un incorporamento di domande.
- Recupera i documenti rilevanti.
- Incorpora i documenti e la domanda in un prompt.
- Richiamare il modello con il prompt e generare la risposta in modo leggibile.
Ora che l'archivio vettoriale è a posto, puoi iniziare a porre domande:
Catena da riporto regolare
Nello scenario precedente, abbiamo esplorato il modo rapido e semplice per ottenere una risposta sensibile al contesto alla tua domanda. Ora diamo un'occhiata a un'opzione più personalizzabile con l'aiuto di RetrievalQA, in cui puoi personalizzare il modo in cui i documenti recuperati devono essere aggiunti al prompt utilizzando il parametro chain_type. Inoltre, per controllare quanti documenti rilevanti devono essere recuperati, puoi modificare il parametro k nel codice seguente per visualizzare output diversi. In molti scenari, potresti voler sapere quali documenti di origine hanno utilizzato LLM per generare la risposta. È possibile ottenere tali documenti nell'output utilizzando return_source_documents, che restituisce i documenti aggiunti al contesto del prompt LLM. RetrievalQA consente inoltre di fornire un modello di prompt personalizzato che può essere specifico per il modello.
Facciamo una domanda:
Catena di recupero documenti padre
Diamo un'occhiata a un'opzione RAG più avanzata con l'aiuto di ParentDocumentRetriever. Quando si lavora con il recupero dei documenti, è possibile che si verifichi un compromesso tra l'archiviazione di piccole parti di un documento per incorporamenti accurati e documenti più grandi per preservare più contesto. Il document retriever principale raggiunge questo equilibrio suddividendo e archiviando piccole porzioni di dati.
Noi usiamo a parent_splitter per dividere i documenti originali in pezzi più grandi chiamati documenti principali e a child_splitter per creare documenti secondari più piccoli dai documenti originali:
I documenti secondari vengono quindi indicizzati in un archivio vettoriale utilizzando gli incorporamenti. Ciò consente il recupero efficiente di documenti secondari rilevanti in base alla somiglianza. Per recuperare le informazioni rilevanti, il document retriever principale recupera prima i documenti secondari dall'archivio vettoriale. Quindi cerca gli ID principali per i documenti secondari e restituisce i corrispondenti documenti principali più grandi.
Facciamo una domanda:
Catena di compressione contestuale
Diamo un'occhiata a un'altra opzione RAG avanzata chiamata compressione contestuale. Una sfida con il recupero è che di solito non conosciamo le query specifiche che il tuo sistema di archiviazione dei documenti dovrà affrontare quando inserisci i dati nel sistema. Ciò significa che le informazioni più rilevanti per una query potrebbero essere sepolte in un documento con molto testo irrilevante. Passare l'intero documento attraverso la tua domanda può portare a chiamate LLM più costose e risposte più scadenti.
Il contextual compression retriever affronta la sfida di recuperare informazioni rilevanti da un sistema di archiviazione di documenti, dove i dati pertinenti potrebbero essere sepolti all'interno di documenti contenenti molto testo. Comprimendo e filtrando i documenti recuperati in base al contesto della query fornita, vengono restituite solo le informazioni più rilevanti.
Per utilizzare il compression retriever contestuale, avrai bisogno di:
- Un documentalista di base – Questo è il retriever iniziale che recupera i documenti dal sistema di archiviazione in base alla query
- Un compressore di documenti – Questo componente prende i documenti inizialmente recuperati e li accorcia riducendo il contenuto dei singoli documenti o eliminando del tutto i documenti irrilevanti, utilizzando il contesto della query per determinare la pertinenza
Aggiunta di compressione contestuale con un estrattore di catena LLM
Per prima cosa, avvolgi il tuo base retriever con a ContextualCompressionRetriever. Aggiungerai un LLMChainExtractor, che eseguirà un'iterazione sui documenti inizialmente restituiti ed estrarrà da ciascuno solo il contenuto pertinente alla query.
Inizializza la catena utilizzando il file ContextualCompressionRetriever con LLMChainExtractor e passare il prompt tramite il file chain_type_kwargs discussione.
Facciamo una domanda:
Filtra i documenti con un filtro catena LLM
I LLMChainFilter è un compressore leggermente più semplice ma più robusto che utilizza una catena LLM per decidere quali dei documenti inizialmente recuperati filtrare e quali restituire, senza manipolare il contenuto del documento:
Inizializza la catena utilizzando il file ContextualCompressionRetriever con LLMChainFilter e passare il prompt tramite il file chain_type_kwargs discussione.
Facciamo una domanda:
Confronta i risultati
La tabella seguente confronta i risultati di diverse query in base alla tecnica.
| Tecnica | Domanda 1 | Domanda 2 | Confronto |
| Come si è evoluto AWS? | Perché Amazon ha successo? | ||
| Uscita catena Retriever regolare | AWS (Amazon Web Services) si è evoluto da un investimento inizialmente non redditizio a un'attività con un fatturato annuo di 85 miliardi di dollari con una forte redditività, offrendo un'ampia gamma di servizi e funzionalità e diventando una parte significativa del portafoglio di Amazon. Nonostante lo scetticismo e le difficoltà a breve termine, AWS ha continuato a innovare, ad attrarre nuovi clienti e a migrare i clienti attivi, offrendo vantaggi quali agilità, innovazione, efficienza dei costi e sicurezza. AWS ha inoltre ampliato i propri investimenti a lungo termine, compreso lo sviluppo di chip, per fornire nuove funzionalità e cambiare ciò che è possibile per i propri clienti. | Amazon ha successo grazie alla sua continua innovazione ed espansione in nuove aree come i servizi di infrastruttura tecnologica, i dispositivi di lettura digitale, gli assistenti personali a comando vocale e nuovi modelli di business come il mercato di terze parti. Anche la sua capacità di scalare rapidamente le operazioni, come dimostrato dalla rapida espansione delle sue reti di logistica e trasporto, contribuisce al suo successo. Inoltre, l'attenzione di Amazon all'ottimizzazione e all'aumento di efficienza nei suoi processi ha portato a miglioramenti della produttività e riduzioni dei costi. L'esempio di Amazon Business evidenzia la capacità dell'azienda di sfruttare i propri punti di forza nell'e-commerce e nella logistica in diversi settori. | Sulla base delle risposte della normale catena di retriever, notiamo che, sebbene fornisca risposte lunghe, soffre di overflow del contesto e non riesce a menzionare alcun dettaglio significativo dal corpus in merito alla risposta alla query fornita. La normale catena di recupero non è in grado di catturare le sfumature con profondità o intuizione contestuale, potenzialmente tralasciando aspetti critici del documento. |
| Output del document retriever principale | AWS (Amazon Web Services) ha iniziato con il lancio iniziale, con poche funzionalità, del servizio Elastic Compute Cloud (EC2) nel 2006, fornendo una sola dimensione di istanza, in un data center, in una regione del mondo, con solo istanze del sistema operativo Linux e senza molte funzionalità chiave come monitoraggio, bilanciamento del carico, scalabilità automatica o archiviazione persistente. Tuttavia, il successo di AWS ha consentito loro di iterare e aggiungere rapidamente le funzionalità mancanti, espandendosi infine per offrire varie tipologie, dimensioni e ottimizzazioni di elaborazione, archiviazione e rete, oltre a sviluppare i propri chip (Graviton) per spingere ulteriormente prezzo e prestazioni . Il processo di innovazione iterativo di AWS ha richiesto investimenti significativi in risorse finanziarie e umane nell'arco di 20 anni, spesso con largo anticipo rispetto ai risultati ottenuti, per soddisfare le esigenze dei clienti e migliorare l'esperienza dei clienti a lungo termine, la fidelizzazione e i rendimenti per gli azionisti. | Amazon ha successo grazie alla sua capacità di innovare costantemente, adattarsi alle mutevoli condizioni del mercato e soddisfare le esigenze dei clienti in vari segmenti di mercato. Ciò è evidente nel successo di Amazon Business, che è cresciuto fino a generare circa 35 miliardi di dollari di vendite lorde annualizzate offrendo selezione, valore e convenienza ai clienti aziendali. Gli investimenti di Amazon nelle capacità di e-commerce e logistica hanno anche consentito la creazione di servizi come Acquista con Prime, che aiuta i commercianti con siti Web diretti al consumatore a incrementare la conversione dalle visualizzazioni agli acquisti. | Il document retriever principale approfondisce le specifiche della strategia di crescita di AWS, compreso il processo iterativo di aggiunta di nuove funzionalità in base al feedback dei clienti e il percorso dettagliato da un lancio iniziale con poche funzionalità a una posizione di mercato dominante, fornendo al contempo una risposta ricca di contesto . Le risposte coprono un'ampia gamma di aspetti, dalle innovazioni tecniche e strategia di mercato all'efficienza organizzativa e all'attenzione al cliente, fornendo una visione olistica dei fattori che contribuiscono al successo insieme ad esempi. Ciò può essere attribuito alle capacità di ricerca mirate ma ad ampio raggio del parent document retriever. |
| Estrattore catena LLM: output di compressione contestuale | AWS si è evoluto partendo come un piccolo progetto all'interno di Amazon, richiedendo investimenti di capitale significativi e affrontando lo scetticismo sia all'interno che all'esterno dell'azienda. Tuttavia, AWS aveva un vantaggio sui potenziali concorrenti e credeva nel valore che avrebbe potuto offrire ai clienti e ad Amazon. AWS si è impegnata a lungo termine a continuare a investire, con il lancio di oltre 3,300 nuove funzionalità e servizi nel 2022. AWS ha trasformato il modo in cui i clienti gestiscono la propria infrastruttura tecnologica ed è diventata un'azienda con un fatturato annuo di 85 miliardi di dollari e una forte redditività. AWS ha inoltre migliorato continuamente le proprie offerte, ad esempio potenziando EC2 con funzionalità e servizi aggiuntivi dopo il suo lancio iniziale. | Sulla base del contesto fornito, il successo di Amazon può essere attribuito alla sua espansione strategica da piattaforma di vendita di libri a mercato globale con un vivace ecosistema di venditori di terze parti, investimenti tempestivi in AWS, innovazione nell'introduzione di Kindle e Alexa e crescita sostanziale di fatturato annuo dal 2019 al 2022. Questa crescita ha portato all’espansione dell’area del centro logistico, alla creazione di una rete di trasporto dell’ultimo miglio e alla costruzione di una nuova rete di centri di smistamento, ottimizzati per la produttività e la riduzione dei costi. | L'estrattore di catena LLM mantiene un equilibrio tra la copertura completa dei punti chiave e l'evitare profondità non necessarie. Si adatta dinamicamente al contesto della query, quindi l'output è direttamente pertinente e completo. |
| Filtro catena LLM: output di compressione contestuale | AWS (Amazon Web Services) si è evoluto lanciando inizialmente prodotti poveri di funzionalità ma eseguendo rapidamente l'iterazione in base al feedback dei clienti per aggiungere le funzionalità necessarie. Questo approccio ha consentito ad AWS di lanciare EC2 nel 2006 con caratteristiche limitate e di aggiungere poi continuamente nuove funzionalità, come dimensioni di istanze aggiuntive, data center, regioni, opzioni del sistema operativo, strumenti di monitoraggio, bilanciamento del carico, scalabilità automatica e archiviazione persistente. Nel corso del tempo, AWS si è trasformata da un servizio con poche funzionalità a un business multimiliardario concentrandosi sulle esigenze dei clienti, sull'agilità, sull'innovazione, sull'efficienza dei costi e sulla sicurezza. AWS ora ha un fatturato annuo di 85 miliardi di dollari e offre oltre 3,300 nuove funzionalità e servizi ogni anno, rivolgendosi a un'ampia gamma di clienti, dalle start-up alle società multinazionali e alle organizzazioni del settore pubblico. | Amazon ha successo grazie ai suoi modelli di business innovativi, ai continui progressi tecnologici e ai cambiamenti organizzativi strategici. L'azienda ha costantemente rivoluzionato i settori tradizionali introducendo nuove idee, come una piattaforma di e-commerce per vari prodotti e servizi, un mercato di terze parti, servizi di infrastruttura cloud (AWS), l'e-reader Kindle e l'assistente personale vocale Alexa. . Inoltre, Amazon ha apportato modifiche strutturali per migliorare la propria efficienza, come la riorganizzazione della propria rete logistica statunitense per ridurre costi e tempi di consegna, contribuendo ulteriormente al suo successo. | Simile all'estrattore di catena LLM, il filtro di catena LLM garantisce che, sebbene i punti chiave siano coperti, l'output sia efficiente per i clienti che cercano risposte concise e contestuali. |
Confrontando queste diverse tecniche, possiamo vedere che in contesti come descrivere dettagliatamente la transizione di AWS da un semplice servizio a un'entità complessa, multimiliardaria, o spiegare i successi strategici di Amazon, la normale catena di recupero non ha la precisione offerta dalle tecniche più sofisticate, portando a informazioni meno mirate. Sebbene siano visibili pochissime differenze tra le tecniche avanzate discusse, sono di gran lunga più informative delle normali catene di retriever.
Per i clienti di settori quali sanità, telecomunicazioni e servizi finanziari che desiderano implementare RAG nelle proprie applicazioni, i limiti della normale catena di retriever nel fornire precisione, evitare ridondanze e comprimere efficacemente le informazioni la rendono meno adatta a soddisfare queste esigenze rispetto a al più avanzato document retriever genitore e alle tecniche di compressione contestuale. Queste tecniche sono in grado di distillare grandi quantità di informazioni negli insight concentrati e di grande impatto di cui hai bisogno, contribuendo al tempo stesso a migliorare il rapporto prezzo-prestazioni.
ripulire
Una volta terminata l'esecuzione del notebook, eliminare le risorse create per evitare l'accumulo di addebiti per le risorse in uso:
Conclusione
In questo post, abbiamo presentato una soluzione che consente di implementare le tecniche di document retriever padre e catena di compressione contestuale per migliorare la capacità degli LLM di elaborare e generare informazioni. Abbiamo testato queste tecniche RAG avanzate con i modelli Mixtral-8x7B Instruct e BGE Large En disponibili con SageMaker JumpStart. Abbiamo anche esplorato l'utilizzo dell'archiviazione persistente per incorporamenti e blocchi di documenti e l'integrazione con archivi dati aziendali.
Le tecniche che abbiamo eseguito non solo perfezionano il modo in cui i modelli LLM accedono e incorporano la conoscenza esterna, ma migliorano anche significativamente la qualità, la pertinenza e l'efficienza dei loro risultati. Combinando il recupero da corpora di testo di grandi dimensioni con capacità di generazione del linguaggio, queste tecniche RAG avanzate consentono agli LLM di produrre risposte più concrete, coerenti e adeguate al contesto, migliorando le loro prestazioni in varie attività di elaborazione del linguaggio naturale.
SageMaker JumpStart è al centro di questa soluzione. Con SageMaker JumpStart, puoi accedere a un vasto assortimento di modelli open e closed source, semplificando il processo di avvio con il machine learning e consentendo una rapida sperimentazione e implementazione. Per iniziare a distribuire questa soluzione, vai al notebook nel file Repository GitHub.
Informazioni sugli autori
 Niithiyn Vijeaswaran è un Solutions Architect presso AWS. La sua area di interesse è l'intelligenza artificiale generativa e gli acceleratori di intelligenza artificiale AWS. Ha conseguito una laurea in Informatica e Bioinformatica. Niithiyn lavora a stretto contatto con il team Generative AI GTM per supportare i clienti AWS su più fronti e accelerare la loro adozione dell'intelligenza artificiale generativa. È un fan sfegatato dei Dallas Mavericks e gli piace collezionare scarpe da ginnastica.
Niithiyn Vijeaswaran è un Solutions Architect presso AWS. La sua area di interesse è l'intelligenza artificiale generativa e gli acceleratori di intelligenza artificiale AWS. Ha conseguito una laurea in Informatica e Bioinformatica. Niithiyn lavora a stretto contatto con il team Generative AI GTM per supportare i clienti AWS su più fronti e accelerare la loro adozione dell'intelligenza artificiale generativa. È un fan sfegatato dei Dallas Mavericks e gli piace collezionare scarpe da ginnastica.
 Sebastiano Bustillo è un Solutions Architect presso AWS. Si concentra sulle tecnologie AI/ML con una profonda passione per l'intelligenza artificiale generativa e gli acceleratori di calcolo. In AWS, aiuta i clienti a sbloccare il valore aziendale attraverso l'intelligenza artificiale generativa. Quando non è al lavoro, gli piace preparare una perfetta tazza di caffè speciale ed esplorare il mondo con sua moglie.
Sebastiano Bustillo è un Solutions Architect presso AWS. Si concentra sulle tecnologie AI/ML con una profonda passione per l'intelligenza artificiale generativa e gli acceleratori di calcolo. In AWS, aiuta i clienti a sbloccare il valore aziendale attraverso l'intelligenza artificiale generativa. Quando non è al lavoro, gli piace preparare una perfetta tazza di caffè speciale ed esplorare il mondo con sua moglie.
 Armando diaz è un Solutions Architect presso AWS. Si concentra su intelligenza artificiale generativa, intelligenza artificiale/ML e analisi dei dati. In AWS, Armando aiuta i clienti a integrare funzionalità di intelligenza artificiale generativa all'avanguardia nei loro sistemi, promuovendo l'innovazione e il vantaggio competitivo. Quando non è al lavoro, gli piace passare il tempo con la moglie e la famiglia, fare escursioni e viaggiare per il mondo.
Armando diaz è un Solutions Architect presso AWS. Si concentra su intelligenza artificiale generativa, intelligenza artificiale/ML e analisi dei dati. In AWS, Armando aiuta i clienti a integrare funzionalità di intelligenza artificiale generativa all'avanguardia nei loro sistemi, promuovendo l'innovazione e il vantaggio competitivo. Quando non è al lavoro, gli piace passare il tempo con la moglie e la famiglia, fare escursioni e viaggiare per il mondo.
 Dottor Farooq Sabir è Senior Artificial Intelligence and Machine Learning Specialist Solutions Architect presso AWS. Ha conseguito un dottorato di ricerca e un master in ingegneria elettrica presso l'Università del Texas ad Austin e un master in informatica presso il Georgia Institute of Technology. Ha oltre 15 anni di esperienza lavorativa e gli piace anche insegnare e fare da mentore agli studenti universitari. In AWS, aiuta i clienti a formulare e risolvere i loro problemi aziendali in data science, machine learning, visione artificiale, intelligenza artificiale, ottimizzazione numerica e domini correlati. Con sede a Dallas, in Texas, lui e la sua famiglia amano viaggiare e fare lunghi viaggi.
Dottor Farooq Sabir è Senior Artificial Intelligence and Machine Learning Specialist Solutions Architect presso AWS. Ha conseguito un dottorato di ricerca e un master in ingegneria elettrica presso l'Università del Texas ad Austin e un master in informatica presso il Georgia Institute of Technology. Ha oltre 15 anni di esperienza lavorativa e gli piace anche insegnare e fare da mentore agli studenti universitari. In AWS, aiuta i clienti a formulare e risolvere i loro problemi aziendali in data science, machine learning, visione artificiale, intelligenza artificiale, ottimizzazione numerica e domini correlati. Con sede a Dallas, in Texas, lui e la sua famiglia amano viaggiare e fare lunghi viaggi.
 Marco Punio è un Solutions Architect focalizzato sulla strategia di intelligenza artificiale generativa, soluzioni di intelligenza artificiale applicata e sulla conduzione di ricerche per aiutare i clienti a espandersi su AWS. Marco è un consulente cloud nativo digitale con esperienza nei settori FinTech, Sanità e scienze della vita, Software-as-a-service e, più recentemente, nei settori delle telecomunicazioni. È un tecnologo qualificato con una passione per l'apprendimento automatico, l'intelligenza artificiale e le fusioni e acquisizioni. Marco vive a Seattle, WA e nel tempo libero ama scrivere, leggere, esercitarsi e creare applicazioni.
Marco Punio è un Solutions Architect focalizzato sulla strategia di intelligenza artificiale generativa, soluzioni di intelligenza artificiale applicata e sulla conduzione di ricerche per aiutare i clienti a espandersi su AWS. Marco è un consulente cloud nativo digitale con esperienza nei settori FinTech, Sanità e scienze della vita, Software-as-a-service e, più recentemente, nei settori delle telecomunicazioni. È un tecnologo qualificato con una passione per l'apprendimento automatico, l'intelligenza artificiale e le fusioni e acquisizioni. Marco vive a Seattle, WA e nel tempo libero ama scrivere, leggere, esercitarsi e creare applicazioni.
 AJ Dhimine è un Solutions Architect presso AWS. È specializzato in intelligenza artificiale generativa, elaborazione serverless e analisi dei dati. È un membro/mentore attivo nella comunità del campo tecnico del machine learning e ha pubblicato numerosi articoli scientifici su vari argomenti di intelligenza artificiale/ML. Lavora con clienti, dalle start-up alle imprese, per sviluppare soluzioni di intelligenza artificiale generativa AWSome. È particolarmente appassionato nello sfruttare i modelli linguistici di grandi dimensioni per l'analisi avanzata dei dati e nell'esplorare applicazioni pratiche che affrontano le sfide del mondo reale. Al di fuori del lavoro, AJ ama viaggiare e attualmente è presente in 53 paesi con l'obiettivo di visitare tutti i paesi del mondo.
AJ Dhimine è un Solutions Architect presso AWS. È specializzato in intelligenza artificiale generativa, elaborazione serverless e analisi dei dati. È un membro/mentore attivo nella comunità del campo tecnico del machine learning e ha pubblicato numerosi articoli scientifici su vari argomenti di intelligenza artificiale/ML. Lavora con clienti, dalle start-up alle imprese, per sviluppare soluzioni di intelligenza artificiale generativa AWSome. È particolarmente appassionato nello sfruttare i modelli linguistici di grandi dimensioni per l'analisi avanzata dei dati e nell'esplorare applicazioni pratiche che affrontano le sfide del mondo reale. Al di fuori del lavoro, AJ ama viaggiare e attualmente è presente in 53 paesi con l'obiettivo di visitare tutti i paesi del mondo.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

