
Immagine dell'editore
La scienza dei dati è un campo che è cresciuto enormemente negli ultimi cento anni grazie ai progressi compiuti nel campo dell’informatica. Con la riduzione dei costi di archiviazione su computer e cloud, ora siamo in grado di archiviare grandi quantità di dati a un costo molto basso rispetto a qualche anno fa. Con l’aumento della potenza computazionale, possiamo eseguire algoritmi di apprendimento automatico su grandi quantità di dati e trasformarli per produrre informazioni approfondite. Con i progressi nel networking, possiamo generare e trasmettere dati su Internet alla velocità della luce. Di conseguenza, viviamo in un’era in cui ogni secondo vengono generati abbondanti dati. Disponiamo di dati sotto forma di e-mail, transazioni finanziarie, contenuti di social media, pagine Web su Internet, dati di clienti per aziende, cartelle cliniche di pazienti, dati di fitness da smartwatch, contenuti video su Youtube, telemetria da dispositivi intelligenti ed elenco continua. Questa abbondanza di dati sia in formato strutturato che non strutturato ci ha fatto approdare in un campo chiamato Data Mining.
Data Mining è il processo di scoperta di modelli, anomalie e correlazioni da grandi set di dati per prevedere un risultato. Sebbene le tecniche di data mining possano essere applicate a qualsiasi forma di dati, uno di questi rami del data mining lo è Estrazione di testo che si riferisce alla ricerca di informazioni significative da dati testuali non strutturati. In questo articolo mi concentrerò su un'attività comune nel Text Mining per trovare la somiglianza dei documenti.
Somiglianza del documento aiuta nel recupero efficiente delle informazioni. Le applicazioni della somiglianza dei documenti includono: rilevamento di plagio, risposta efficace alle query di ricerca sul Web, raggruppamento di documenti di ricerca per argomento, ricerca di articoli di notizie simili, raggruppamento di domande simili in un sito di domande e risposte come Quora, StackOverflow, Reddit e raggruppamento di prodotti su Amazon in base alla descrizione , ecc. La somiglianza dei documenti viene utilizzata anche da aziende come DropBox e Google Drive per evitare di archiviare copie duplicate dello stesso documento, risparmiando così tempi di elaborazione e costi di archiviazione.
Esistono diversi passaggi per calcolare la somiglianza dei documenti. Il primo passo è rappresentare il documento in formato vettoriale. Possiamo quindi utilizzare funzioni di similarità a coppie su questi vettori. Una funzione di somiglianza è una funzione che calcola il grado di somiglianza tra una coppia di vettori. Esistono diverse funzioni di somiglianza a coppie come: Distanza euclidea, Somiglianza coseno, Somiglianza Jaccard, correlazione di Pearson, correlazione di Spearman, Tau di Kendall e così via [2]. Una funzione di somiglianza a coppie può essere applicata a due documenti, due query di ricerca o tra un documento e una query di ricerca. Sebbene le funzioni di somiglianza a coppie siano adatte per confrontare un numero minore di documenti, esistono altre tecniche più avanzate come Doc2Vec, BERT che si basano su tecniche di deep learning e vengono utilizzate dai motori di ricerca come Google per un efficiente recupero delle informazioni in base alla query di ricerca. In questo articolo mi concentrerò sulla somiglianza di Jaccard, sulla distanza euclidea, sulla somiglianza del coseno, sulla somiglianza del coseno con TF-IDF, Doc2Vec e BERT.
Pre-elaborazione
Un passaggio comune per calcolare la distanza tra documenti o le somiglianze tra documenti è eseguire una pre-elaborazione sul documento. La fase di pre-elaborazione include la conversione di tutto il testo in minuscolo, la tokenizzazione del testo, la rimozione delle stop word, la rimozione dei segni di punteggiatura e la lemmatizzazione delle parole[4].
Tokenizzazione: Questo passaggio prevede la scomposizione delle frasi in unità più piccole per l'elaborazione. Un token è il più piccolo atomo lessicale in cui può essere scomposta una frase. Una frase può essere suddivisa in token utilizzando lo spazio come delimitatore. Questo è un modo di tokenizzare. Ad esempio, una frase del formato "la tokenizzazione è un passaggio davvero interessante" è suddivisa in token del formato ['tokenizzazione', "è", a, "davvero", "interessante", "passaggio"]. Questi token costituiscono gli elementi costitutivi del Text Mining e sono uno dei primi passi nella modellazione dei dati testuali.
Minuscolo: Anche se in alcuni casi speciali potrebbe essere necessario preservare i casi, nella maggior parte dei casi vogliamo trattare le parole con maiuscole e minuscole diverse come se fossero una sola. Questo passaggio è importante per ottenere risultati coerenti da un set di dati di grandi dimensioni. Ad esempio, se un utente sta cercando la parola "India", vogliamo recuperare i documenti pertinenti che contengono parole in maiuscole e minuscole diverse come "India", "INDIA" e "India" se sono pertinenti alla query di ricerca.
Rimozione della punteggiatura: La rimozione dei segni di punteggiatura e degli spazi aiuta a focalizzare la ricerca su parole e simboli importanti.
Rimozione delle stop word: Le stop word sono un insieme di parole comunemente utilizzate nella lingua inglese e la rimozione di tali parole può aiutare a recuperare documenti che corrispondono a parole più importanti che trasmettono il contesto della query. Ciò aiuta anche a ridurre la dimensione del vettore delle caratteristiche, aiutando così con i tempi di elaborazione.
Lemmatizzazione: La lemmatizzazione aiuta a ridurre la scarsità mappando le parole sulla loro parola radice. Ad esempio "Gioca", "Giocato" e "Gioco" sono tutti mappati per giocare. In questo modo riduciamo anche la dimensione del set di funzionalità e abbiniamo tutte le variazioni di una parola tra diversi documenti per visualizzare il documento più pertinente.
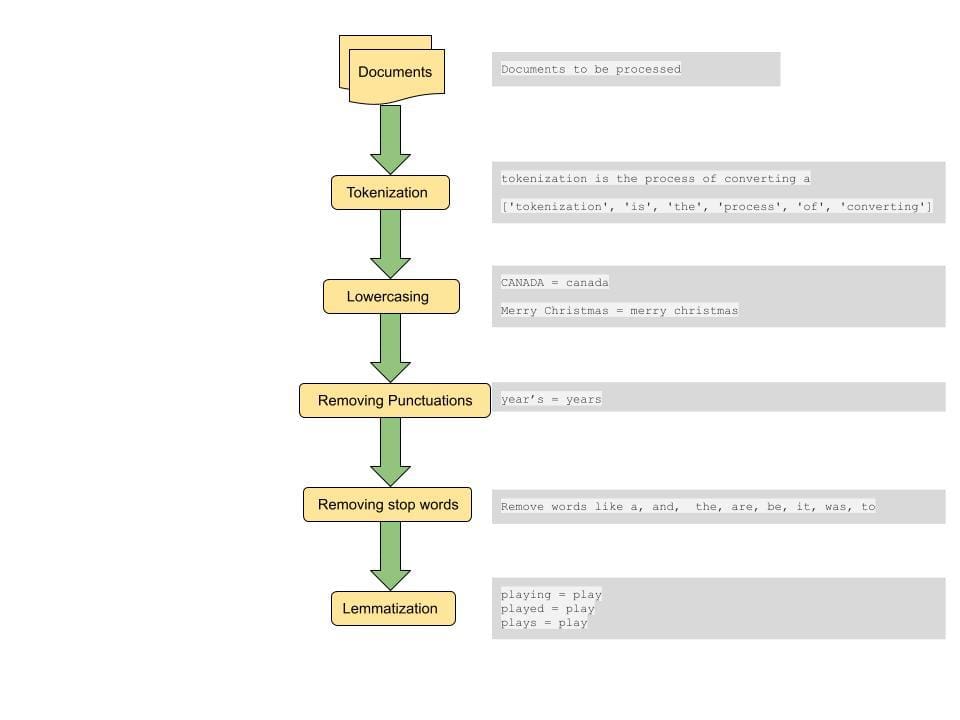
Questo metodo è uno dei metodi più semplici. Tokenizza le parole e calcola la somma del conteggio dei termini condivisi sulla somma del numero totale di termini in entrambi i documenti. Se i due documenti sono simili il punteggio è uno, se i due documenti sono diversi il punteggio è zero [3].
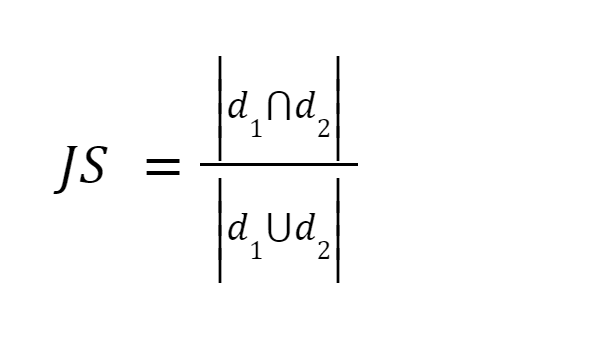
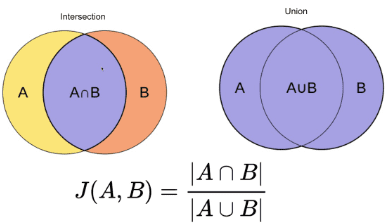
Fonte immagine: O'Reilly
Sommario: Questo metodo presenta alcuni inconvenienti. All’aumentare della dimensione del documento, aumenterà il numero di parole comuni, anche se i due documenti sono semanticamente diversi.
Dopo aver pre-elaborato il documento, convertiamo il documento in un vettore. Il peso del vettore può essere la frequenza del termine in cui contiamo il numero di volte in cui il termine appare nel documento, oppure può essere la frequenza del termine relativa in cui calcoliamo il rapporto tra il conteggio del termine e il numero totale di termini nel documento [3].
Siano d1 e d2 due documenti rappresentati come vettori di n termini (che rappresentano n dimensioni); possiamo quindi calcolare la distanza più breve tra due documenti utilizzando il teorema di Pitagora per trovare una linea retta tra due vettori. Maggiore è la distanza, minore è la somiglianza; minore è la distanza, maggiore è la somiglianza tra due documenti.
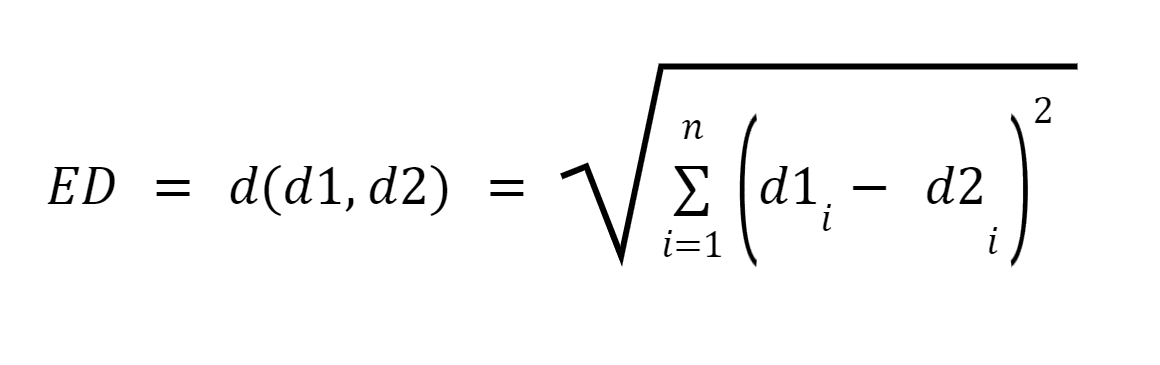
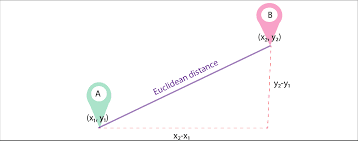
Fonte immagine: Medium.com
Sommario: Il principale svantaggio di questo approccio è che quando i documenti differiscono per dimensioni, la distanza euclidea darà un punteggio inferiore anche se i due documenti sono di natura simile. Documenti più piccoli daranno come risultato vettori con grandezza minore mentre documenti più grandi daranno come risultato vettori con grandezza maggiore poiché la grandezza del vettore è direttamente proporzionale al numero di parole nel documento, aumentando così la distanza complessiva.
La somiglianza del coseno misura la somiglianza tra i documenti misurando il coseno dell'angolo tra i due vettori. I risultati della somiglianza del coseno possono assumere valori compresi tra 0 e 1. Se i vettori puntano nella stessa direzione, la somiglianza è 1, se i vettori puntano in direzioni opposte, la somiglianza è 0. [6].
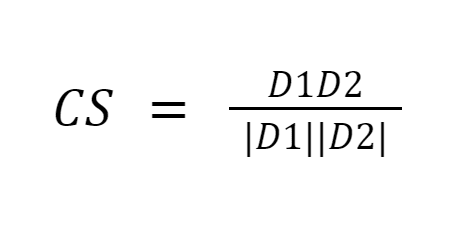
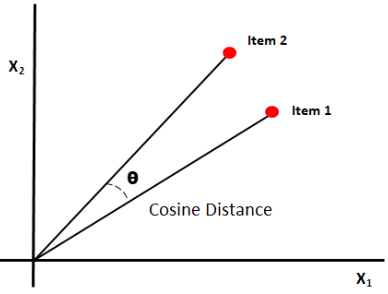
Fonte immagine: Medium.com
Sommario: L'aspetto positivo della somiglianza del coseno è che calcola l'orientamento tra i vettori e non la grandezza. Pertanto catturerà la somiglianza tra due documenti simili nonostante abbiano dimensioni diverse.
Lo svantaggio fondamentale dei tre approcci precedenti è che la misurazione non riesce a trovare documenti simili in base alla semantica. Inoltre, tutte queste tecniche possono essere eseguite solo in coppia, richiedendo quindi più confronti.
Questo metodo per trovare la somiglianza dei documenti viene utilizzato nelle implementazioni di ricerca predefinite di ElasticSearch ed è in circolazione dal 1972 [4]. tf-idf sta per frequenza del documento inversa alla frequenza. Per prima cosa calcoliamo il termine frequenza utilizzando questa formula
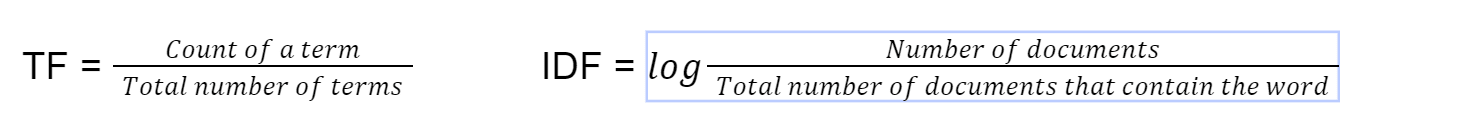
Infine calcoliamo tf-idf moltiplicando TF*IDF. Utilizziamo quindi la somiglianza del coseno sul vettore con tf-idf come peso del vettore.
Sommario: moltiplicare la frequenza del termine per la frequenza inversa del documento aiuta a compensare alcune parole che appaiono più frequentemente in generale nei documenti e a concentrarsi sulle parole che sono diverse tra i documenti. Questa tecnica aiuta a trovare documenti che corrispondono a una query di ricerca concentrando la ricerca su parole chiave importanti.
Anche se l'utilizzo di singole parole (BOW – Bag of Words) dai documenti da convertire in vettori potrebbe essere più semplice da implementare, non dà alcun significato all'ordine delle parole in una frase. Doc2Vec è costruito sopra Word2Vec. Mentre Word2Vec rappresenta il significato di una parola, Doc2Vec rappresenta il significato di un documento o paragrafo [5].
Questo metodo viene utilizzato per convertire un documento nella sua rappresentazione vettoriale preservando il significato semantico del documento. Questo approccio converte testi di lunghezza variabile come frasi o paragrafi o documenti in vettori [5]. Viene quindi addestrata la modalità doc2vec. L'addestramento dei modelli è simile all'addestramento di altri modelli di machine learning selezionando set di addestramento e documenti di set di test e regolando i parametri di ottimizzazione per ottenere risultati migliori.
Sommario: Una forma così vettoriale del documento preserva il significato semantico del documento poiché i paragrafi con contesto o significato simile saranno più vicini tra loro durante la conversione in vettoriale.
BERT è un modello di machine learning basato su trasformatore utilizzato nelle attività di PNL, sviluppato da Google.
Con l'avvento di BERT (Bidirection Encoder Representations from Transformers), i modelli PNL vengono addestrati con enormi corpora di testo senza etichetta che esaminano un testo sia da destra a sinistra che da sinistra a destra. BERT utilizza una tecnica chiamata “Attenzione” per migliorare i risultati. Il ranking di ricerca di Google è migliorato notevolmente dopo aver utilizzato BERT [4]. Alcune delle caratteristiche uniche di BERT includono
- Pre-addestrato con articoli di Wikipedia in 104 lingue.
- Guarda il testo sia da sinistra a destra che da destra a sinistra
- Aiuta a comprendere il contesto
Sommario: Di conseguenza, BERT può essere ottimizzato per molte applicazioni come la risposta a domande, la parafrasi di frasi, il classificatore di spam, il rilevamento del linguaggio di creazione senza modifiche sostanziali dell'architettura specifiche dell'attività.
È stato fantastico scoprire come vengono utilizzate le funzioni di somiglianza per trovare la somiglianza dei documenti. Attualmente spetta allo sviluppatore scegliere la funzione di somiglianza che meglio si adatta allo scenario. Ad esempio, tf-idf è attualmente lo stato dell'arte per la corrispondenza dei documenti mentre BERT è lo stato dell'arte per le ricerche di query. Sarebbe fantastico creare uno strumento in grado di rilevare automaticamente quale funzione di somiglianza è più adatta in base allo scenario e quindi scegliere una funzione di somiglianza ottimizzata per memoria e tempo di elaborazione. Ciò potrebbe essere di grande aiuto in scenari come l'abbinamento automatico dei curriculum alle descrizioni delle mansioni, il raggruppamento di documenti per categoria, la classificazione dei pazienti in diverse categorie in base alle cartelle cliniche dei pazienti, ecc.
In questo articolo ho trattato alcuni algoritmi importanti per calcolare la somiglianza dei documenti. Non si tratta assolutamente di un elenco esaustivo. Esistono molti altri metodi per trovare somiglianze tra documenti e la decisione di scegliere quello giusto dipende dallo scenario e dal caso d'uso particolari. Semplici metodi statistici come tf-idf, Jaccard, Euclidien, Cosine similarity sono adatti per casi d'uso più semplici. È possibile configurare facilmente le librerie esistenti disponibili in Python, R e calcolare il punteggio di somiglianza senza richiedere macchine pesanti o capacità di elaborazione. Algoritmi più avanzati come BERT dipendono da reti neurali pre-addestrate che possono richiedere ore ma produrre risultati efficienti per l'analisi che richiede la comprensione del contesto del documento.
Riferimento
[1] Heidarian, A. e Dinneen, M. J. (2016). Un approccio geometrico ibrido per misurare il livello di somiglianza tra documenti e clustering di documenti. Seconda conferenza internazionale dell'IEEE 2016 sui servizi e sulle applicazioni di Big Data Computing (BigDataService)1-5. https://doi.org/10.1109/bigdataservice.2016.14
[2] Kavitha Karun A, Philip, M. e Lubna, K. (2013). Analisi comparativa delle misure di somiglianza nel clustering di documenti. Conferenza internazionale del 2013 sull'informatica verde, la comunicazione e la conservazione dell'energia (ICGCE)1-4. https://doi.org/10.1109/icgce.2013.6823554
[3] Lin, Y.-S., Jiang, J.-Y., & Lee, S.-J. (2014). Una misura di somiglianza per la classificazione e il clustering del testo. Transazioni IEEE su conoscenza e ingegneria dei dati, 26(7), 1575-1590. https://doi.org/10.1109/tkde.2013.19
[4] Nishimura, M. (2020 settembre 9). Il miglior algoritmo di somiglianza dei documenti nel 2020: una guida per principianti – Verso la scienza dei dati. Medio. https://towardsdatascience.com/the-best-document-similarity-algorithm-in-2020-a-beginners-guide-a01b9ef8cf05
[5] Sharaki, O. (2020, 10 luglio). Rilevare la somiglianza dei documenti con Doc2vec – Verso la scienza dei dati. Medio. https://towardsdatascience.com/detecting-document-similarity-with-doc2vec-f8289a9a7db7
[6] Lüthe, M. (2019, 18 novembre). Calcola la somiglianza: le metriche più rilevanti in poche parole - Verso la scienza dei dati. Medio. https://towardsdatascience.com/calculate-similarity-the-most-relevant-metrics-in-a-nutshell-9a43564f533e
[7] S. (2019 ottobre 27). Misure di somiglianza: punteggio degli articoli testuali: verso la scienza dei dati. Medio. https://towardsdatascience.com/similarity-measures-e3dbd4e58660
Poornima Muthukumar è un Senior Technical Product Manager presso Microsoft con oltre 10 anni di esperienza nello sviluppo e nella fornitura di soluzioni innovative per vari settori come il cloud computing, l'intelligenza artificiale, i sistemi distribuiti e di big data. Ho un Master in Data Science presso l'Università di Washington. Detengo quattro brevetti presso Microsoft specializzati in sistemi AI/ML e Big Data e sono stato il vincitore del Global Hackathon nel 2016 nella categoria Intelligenza Artificiale. Ho avuto l'onore di far parte del comitato di revisione della Grace Hopper Conference per la categoria Ingegneria del software quest'anno 2023. È stata un'esperienza gratificante leggere e valutare i contributi di donne di talento in questi campi e contribuire al progresso delle donne anche nella tecnologia. come imparare dalle loro ricerche e intuizioni. Sono stato anche membro del comitato per la conferenza Microsoft Machine Learning AI and Data Science (MLADS) di giugno 2023. Sono anche ambasciatrice presso la Women in Data Science Worldwide Community e la Women Who Code Data Science Community.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/evaluating-methods-for-calculating-document-similarity?utm_source=rss&utm_medium=rss&utm_campaign=evaluating-methods-for-calculating-document-similarity

