Questo è un guest post scritto in collaborazione da Ajay K Gupta, Jean Felipe Teotonio e Paul A Churchyard di HSR.health.
HSR.Salute è una società di analisi dei rischi sanitari geospaziali la cui visione è che le sfide sanitarie globali siano risolvibili attraverso l'ingegno umano e l'applicazione mirata e accurata dell'analisi dei dati. In questo post presentiamo un approccio per la prevenzione delle malattie zoonotiche che utilizza Funzionalità geospaziali di Amazon SageMaker creare uno strumento che fornisca informazioni più accurate sulla diffusione delle malattie agli scienziati sanitari per aiutarli a salvare più vite, più rapidamente.
Le malattie zoonotiche colpiscono sia gli animali che gli esseri umani. La transizione di una malattia dall'animale all'uomo, nota come spillover, è un fenomeno che si verifica continuamente sul nostro pianeta. Secondo organizzazioni sanitarie come i Centri per il controllo e la prevenzione delle malattie (CDC) e l'Organizzazione mondiale della sanità (OMS), un evento di ricaduta in un mercato umido a Wuhan, in Cina, ha molto probabilmente causato la malattia da coronavirus 2019 (COVID-19). Gli studi suggeriscono che un virus trovato nei pipistrelli della frutta ha subito mutazioni significative, permettendogli di infettare gli esseri umani. Il paziente iniziale, o “paziente zero”, di COVID-19 probabilmente ha dato origine a una successiva epidemia locale che alla fine si è diffusa a livello internazionale. HSR.SaluteL'indice di rischio di spillover zoonotico mira a contribuire all'identificazione di queste epidemie precoci prima che attraversino i confini internazionali e provochino un impatto globale diffuso.
L’arma principale che la sanità pubblica ha contro la propagazione delle epidemie regionali è la sorveglianza delle malattie: un intero sistema interconnesso di segnalazione, indagine e comunicazione dei dati tra i diversi livelli di un sistema sanitario pubblico. Questo sistema dipende non solo dai fattori umani, ma anche dalla tecnologia e dalle risorse per raccogliere dati sulle malattie, analizzare modelli e creare un flusso coerente e continuo di trasferimento di dati dalle autorità sanitarie locali a quelle regionali e centrali.
La velocità con cui il COVID-19 è passato da un’epidemia locale a una malattia globale presente in ogni singolo continente dovrebbe essere un esempio che fa riflettere sulla disperata necessità di sfruttare tecnologie innovative per creare sistemi di sorveglianza delle malattie più efficienti e accurati.
Il rischio di diffusione di malattie zoonotiche è fortemente correlato a molteplici fattori sociali, ambientali e geografici che influenzano la frequenza con cui gli esseri umani interagiscono con la fauna selvatica. HSR.salute L’indice di rischio di spillover delle malattie zoonotiche utilizza oltre 20 distinti fattori geografici, sociali e ambientali storicamente noti per influenzare il rischio di interazione uomo-fauna selvatica e quindi il rischio di spillover di malattie zoonotiche. Molti di questi fattori possono essere mappati attraverso una combinazione di immagini satellitari e telerilevamento.
In questo post, esploriamo come HSR.Salute utilizza le capacità geospaziali di SageMaker per recuperare caratteristiche rilevanti dalle immagini satellitari e dal telerilevamento per sviluppare l'indice di rischio. Le funzionalità geospaziali di SageMaker consentono ai data scientist e agli ingegneri del machine learning (ML) di creare, addestrare e distribuire facilmente modelli utilizzando dati geospaziali. Con le funzionalità geospaziali di SageMaker, puoi trasformare o arricchire in modo efficiente set di dati geospaziali su larga scala, accelerare la creazione di modelli con modelli ML preaddestrati ed esplorare previsioni di modelli e dati geospaziali su una mappa interattiva utilizzando grafica 3D accelerata e strumenti di visualizzazione integrati.
Utilizzo di dati ML e geospaziali per la mitigazione del rischio
Il machine learning è molto efficace per il rilevamento di anomalie su dati spaziali o temporali grazie alla sua capacità di apprendere dai dati senza essere esplicitamente programmato per identificare tipi specifici di anomalie. I dati spaziali, che riguardano la posizione fisica e la forma degli oggetti, spesso contengono modelli e relazioni complessi che potrebbero essere difficili da analizzare per gli algoritmi tradizionali.
L’integrazione del machine learning con i dati geospaziali migliora la capacità di rilevare sistematicamente anomalie e modelli insoliti, il che è essenziale per i sistemi di allerta precoce. Questi sistemi sono cruciali in settori quali il monitoraggio ambientale, la gestione delle catastrofi e la sicurezza. La modellazione predittiva che utilizza dati geospaziali storici consente alle organizzazioni di identificare e prepararsi per potenziali eventi futuri. Questi eventi vanno da disastri naturali e interruzioni del traffico a, come discusso in questo post, epidemie.
Rilevamento dei rischi di spillover zoonotico
Per prevedere i rischi di spillover zoonotici, HSR.Salute ha adottato un approccio multimodale. Utilizzando una combinazione di tipi di dati, tra cui informazioni ambientali, biogeografiche ed epidemiologiche, questo metodo consente una valutazione completa delle dinamiche della malattia. Una prospettiva così sfaccettata è fondamentale per sviluppare misure proattive e consentire una risposta rapida alle epidemie.
L’approccio include i seguenti componenti:
- Dati su malattie ed epidemie – HSR.Salute utilizza i dati estesi su malattie ed epidemie forniti da Gideon e l’Organizzazione Mondiale della Sanità (OMS), due fonti attendibili di informazioni epidemiologiche globali. Questi dati costituiscono un pilastro fondamentale nel quadro di analisi. Per Gideon, è possibile accedere ai dati tramite un’API e per l’OMS, HSR.Salute ha creato un modello linguistico di grandi dimensioni (LLM) per estrarre i dati sulle epidemie dai rapporti sulle epidemie passate.
- Dati di osservazione della Terra – I fattori ambientali, l’analisi dell’uso del territorio e l’individuazione dei cambiamenti dell’habitat sono componenti integranti nella valutazione del rischio zoonotico. Queste informazioni possono essere ricavate dai dati di osservazione della Terra basati sui satelliti. HSR.Salute è in grado di semplificare l'uso dei dati di osservazione della Terra utilizzando le funzionalità geospaziali di SageMaker per accedere e manipolare set di dati geospaziali su larga scala. SageMaker geospatial offre un ricco catalogo di dati, inclusi set di dati di USGS Landsat-8, Sentinel-1, Sentinel-2 e altri. È anche possibile importare altri set di dati, come immagini ad alta risoluzione di Planet Labs.
- Determinanti sociali del rischio – Al di là dei fattori biologici e ambientali, il team di HSR.Salute hanno considerato anche i determinanti sociali, che comprendono vari indicatori socioeconomici e demografici, e svolgono un ruolo fondamentale nel modellare le dinamiche di spillover zoonotico.
Da questi componenti, HSR.Salute hanno valutato una serie di fattori diversi e le seguenti caratteristiche sono state identificate come influenti per identificare i rischi di spillover zoonotici:
- Habitat animali e zone abitabili – Comprendere gli habitat dei potenziali ospiti zoonotici e le loro zone abitabili è fondamentale per valutare il rischio di trasmissione.
- Centri abitati – La vicinanza ad aree densamente popolate è una considerazione chiave perché influenza la probabilità di interazioni uomo-animale.
- Perdita di habitat – Il degrado degli habitat naturali, in particolare attraverso la deforestazione, può accelerare gli eventi di spillover zoonotici.
- Interfaccia uomo-natura – Le aree in cui gli insediamenti umani si intersecano con gli habitat della fauna selvatica sono potenziali punti caldi per la trasmissione zoonotica.
- Caratteristiche sociali – I fattori socioeconomici e culturali possono avere un impatto significativo sul rischio zoonotico e sull’HSR.Salute esamina anche questi.
- Caratteristiche della salute umana – Lo stato di salute delle popolazioni umane locali è una variabile essenziale perché influenza la suscettibilità e la dinamica di trasmissione.
Panoramica della soluzione
HSR.SaluteIl flusso di lavoro di comprende la preelaborazione dei dati, l'estrazione delle funzionalità e la creazione di visualizzazioni informative utilizzando tecniche ML. Ciò consente una chiara comprensione dell'evoluzione dei dati dalla loro forma grezza a informazioni fruibili.
Quella che segue è una rappresentazione visiva del flusso di lavoro, a partire dai dati di input di Gideon, dai dati di osservazione della Terra e dai dati sul determinante sociale del rischio.
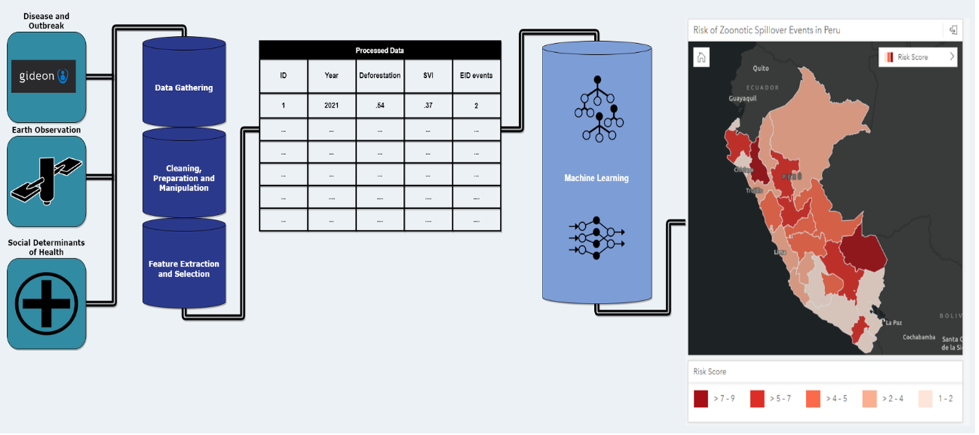
Recupera ed elabora immagini satellitari utilizzando le funzionalità geospaziali di SageMaker
I dati satellitari costituiscono una pietra angolare dell’analisi effettuata per costruire l’indice di rischio, fornendo informazioni critiche sui cambiamenti ambientali. Per generare approfondimenti dalle immagini satellitari, HSR.Salute usa Lavori di osservazione della Terra (EOJ). Gli EOJ consentono l'acquisizione e la trasformazione di dati raster raccolti dalla superficie terrestre. Un EOJ ottiene immagini satellitari da una fonte di dati designata, ad esempio una costellazione di satelliti, su un'area e un periodo di tempo specifici. Quindi applica uno o più modelli alle immagini recuperate.
Inoltre, Amazon Sage Maker Studio offre un notebook geospaziale preinstallato con le librerie geospaziali di uso comune. Questo notebook consente la visualizzazione e l'elaborazione diretta dei dati geospaziali all'interno di un ambiente notebook Python. Gli EOJ possono essere creati nell'ambiente notebook geospaziale.
Per configurare un EOJ, vengono utilizzati i seguenti parametri:
- Configurazione input – La configurazione dell'input specifica le origini dati e i criteri di filtraggio da utilizzare durante l'acquisizione dei dati:
- RasterDataCollectionArn – Specifica il satellite da cui raccogliere i dati.
- Area d'interesse – L'area geografica di interesse (AOI) definisce i confini del poligono per la raccolta delle immagini.
- Filtro intervallo di tempo – La fascia oraria di interesse:
{StartTime: <string>, EndTime: <string>}. - ProprietàFiltri – Filtri di proprietà aggiuntivi, come la percentuale accettabile di copertura nuvolosa o gli angoli di azimut del sole desiderati.
- JobConfig – Questa configurazione definisce il tipo di lavoro da applicare ai dati dell'immagine satellitare recuperati. Supporta operazioni come la matematica delle bande, il ricampionamento, il geomosaico o la rimozione delle nuvole.
Il codice di esempio seguente mostra l'esecuzione di un EOJ per la rimozione del cloud, rappresentativo dei passaggi eseguiti da HSR.Salute:
HSR.Salute ha utilizzato diverse operazioni per preelaborare i dati ed estrarre le caratteristiche rilevanti. Ciò include operazioni come la classificazione della copertura del suolo, la mappatura delle variazioni di temperatura e gli indici di vegetazione.
Un indice di vegetazione rilevante per indicare la salute della vegetazione è il Normalized Difference Vegetation Index (NDVI). L’NDVI quantifica la salute della vegetazione utilizzando la luce del vicino infrarosso, che la vegetazione riflette, e la luce rossa, che la vegetazione assorbe. Il monitoraggio dell’NDVI nel tempo può rivelare cambiamenti nella vegetazione, come l’impatto delle attività umane come la deforestazione.
Il seguente frammento di codice mostra come calcolare un indice di vegetazione come l'NDVI in base ai dati passati attraverso la rimozione delle nuvole:
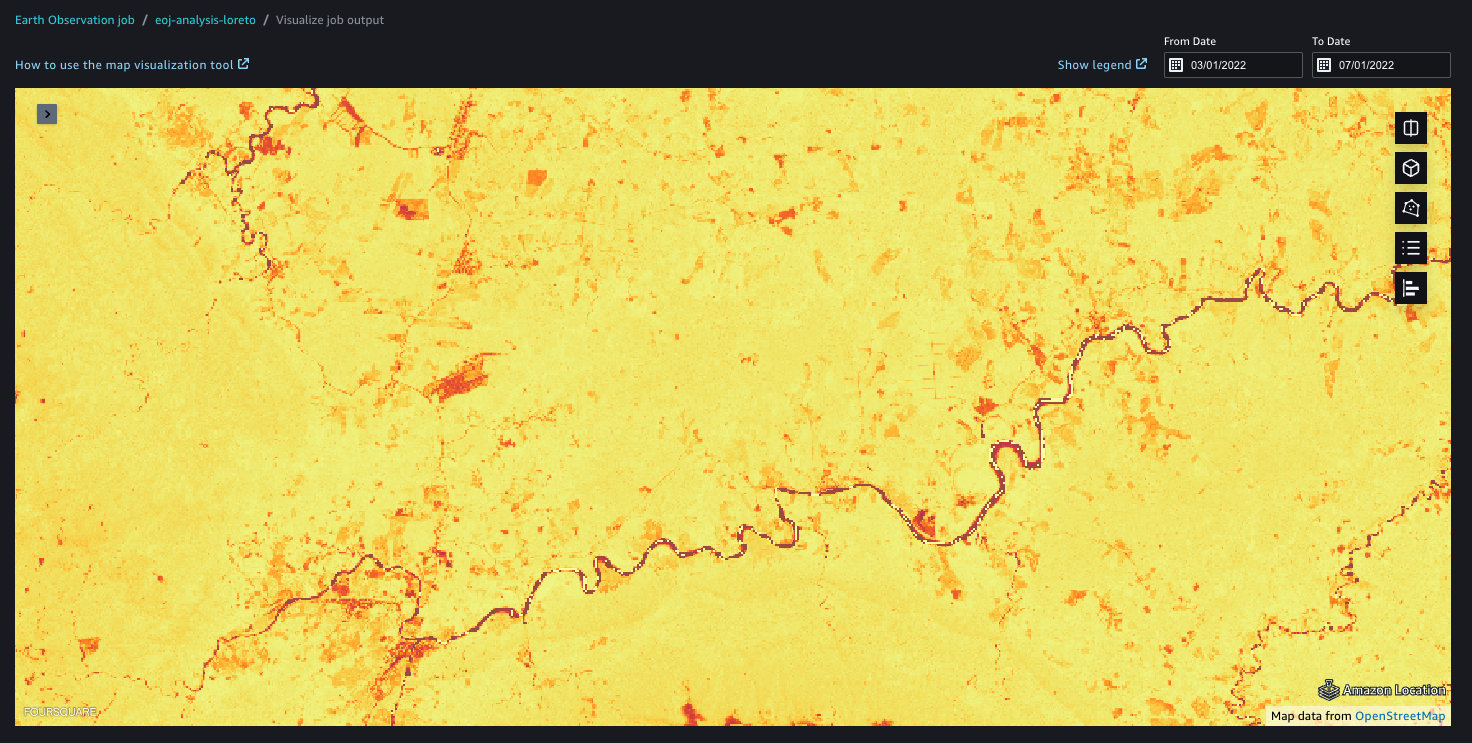
Possiamo visualizzare l'output del lavoro utilizzando le funzionalità geospaziali di SageMaker. Le funzionalità geospaziali di SageMaker possono aiutarti a sovrapporre le previsioni del modello su una mappa di base e fornire una visualizzazione a più livelli per facilitare la collaborazione. Con il visualizzatore interattivo basato su GPU e i notebook Python, è possibile esplorare milioni di punti dati in un'unica visualizzazione, facilitando l'esplorazione collaborativa di approfondimenti e risultati.
I passaggi descritti in questo post dimostrano solo una delle tante funzionalità basate su raster offerte da HSR.Salute ha estratto per creare l’indice di rischio.
Combinazione di funzionalità basate su raster con dati sanitari e sociali
Dopo aver estratto le funzionalità rilevanti in formato raster, HSR.Salute ha utilizzato statistiche zonali per aggregare i dati raster all'interno dei poligoni di confine amministrativo a cui sono assegnati i dati sociali e sanitari. L'analisi incorpora una combinazione di dati geospaziali raster e vettoriali. Questo tipo di aggregazione consente la gestione dei dati raster in un geodataframe, che ne facilita l'integrazione con i dati sanitari e sociali per produrre l'indice di rischio finale.
Il seguente frammento di codice dimostra come aggregare i dati raster ai confini del vettore amministrativo:
Per valutare in modo efficace le funzionalità estratte, i modelli ML vengono utilizzati per prevedere i fattori che rappresentano ciascuna funzionalità. Uno dei modelli utilizzati è una Support Vector Machine (SVM). Il modello SVM aiuta a rivelare modelli e associazioni all’interno dei dati che informano le valutazioni del rischio.
L’indice rappresenta una valutazione quantitativa dei livelli di rischio, calcolata come media ponderata di questi fattori, per aiutare a comprendere i potenziali eventi di ricaduta in varie regioni.
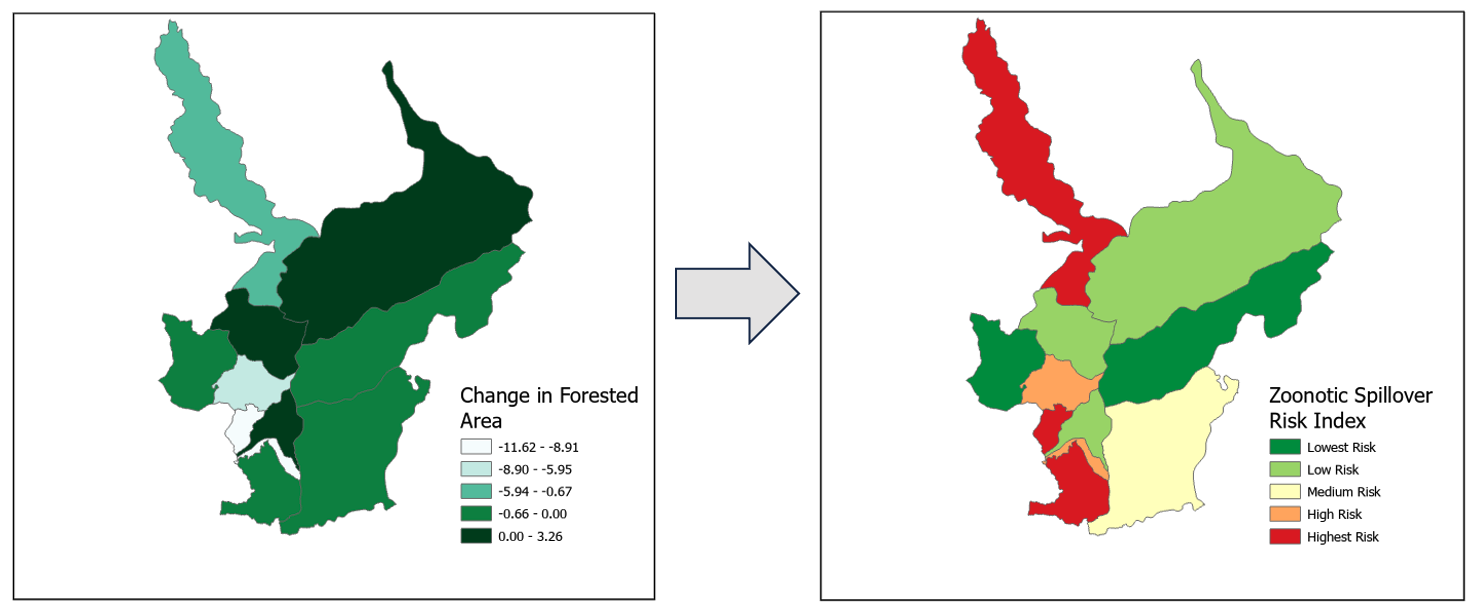
La figura seguente a sinistra mostra l'aggregazione della classificazione delle immagini dalla scena dell'area test nel Perù settentrionale aggregata al livello amministrativo distrettuale con la variazione calcolata nell'area forestale tra il 2018 e il 2023. La deforestazione è uno dei fattori chiave che determinano il rischio di spillover zoonotico. La figura a destra evidenzia i livelli di gravità del rischio di spillover zoonotico all’interno delle regioni coperte, che vanno dal rischio più alto (rosso) a quello più basso (verde scuro). L'area è stata scelta come una delle aree di formazione per la classificazione delle immagini a causa della diversità della copertura del suolo catturata nella scena, tra cui: urbano, foresta, sabbia, acqua, praterie e agricoltura, tra gli altri. Inoltre, questa è una delle tante aree di interesse per potenziali eventi di spillover zoonotici dovuti alla deforestazione e all’interazione tra uomo e animali.
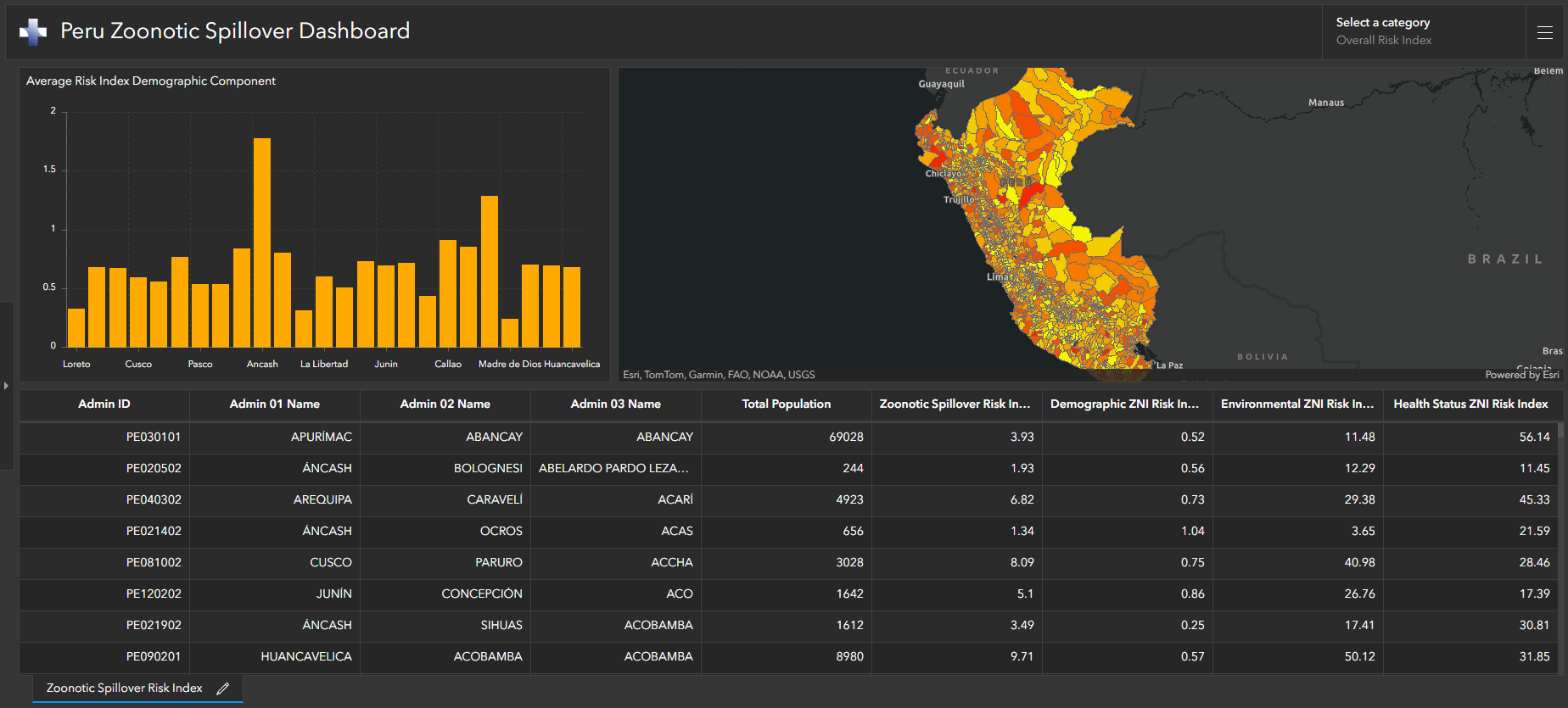
Adottando questo approccio multimodale, che comprende dati storici sull’epidemia, dati di osservazione della Terra, determinanti sociali e tecniche di machine learning, possiamo comprendere e prevedere meglio il rischio di spillover zoonotico, indirizzando in definitiva le strategie di sorveglianza e prevenzione della malattia verso le aree a maggior rischio di epidemia. Lo screenshot seguente mostra un dashboard dei risultati di un'analisi del rischio di spillover zoonotico. Questa analisi del rischio evidenzia dove possono essere implementate le risorse e la sorveglianza per nuovi potenziali focolai zoonotici in modo che la prossima malattia possa essere contenuta prima che diventi endemica o una nuova pandemia.
Un nuovo approccio alla prevenzione della pandemia
Nel 1998, lungo il fiume Nipah in Malesia, tra l'autunno del 1998 e la primavera del 1999, 265 persone furono infettate da un virus allora sconosciuto che causò encefalite acuta e gravi difficoltà respiratorie. 105 di loro morirono, un tasso di mortalità del 39.6%. Il tasso di mortalità non trattato per COVID-19, invece, è del 6.3%. Da allora, il virus Nipah, come viene ora soprannominato, è uscito dal suo habitat forestale e ha causato oltre 20 epidemie mortali, soprattutto in India e Bangladesh.
Virus come Nipah emergono ogni anno, ponendo sfide alla nostra vita quotidiana, in particolare nei paesi in cui è più difficile stabilire sistemi forti, duraturi e robusti per la sorveglianza e il rilevamento delle malattie. Questi sistemi di rilevamento sono fondamentali per ridurre i rischi associati a tali virus.
Le soluzioni che utilizzano dati geospaziali e di machine learning, come lo Zoonotic Spillover Risk Index, possono aiutare le autorità sanitarie pubbliche locali a dare priorità all’allocazione delle risorse nelle aree a più alto rischio. In questo modo, possono stabilire misure di sorveglianza mirate e localizzate per individuare e arrestare le epidemie regionali prima che si estendano oltre i confini. Questo approccio può limitare significativamente l’impatto di un’epidemia e salvare vite umane.
Conclusione
Questo post ha dimostrato come HSR.Salute ha sviluppato con successo lo Zoonotic Spillover Risk Index integrando dati geospaziali, salute, determinanti sociali e ML. Utilizzando SageMaker, il team ha creato un flusso di lavoro scalabile in grado di individuare le minacce più sostanziali di una potenziale futura pandemia. Una gestione efficace di questi rischi può portare a una riduzione del carico globale di malattie. I sostanziali vantaggi economici e sociali derivanti dalla riduzione del rischio pandemico non possono essere sopravvalutati, con benefici che si estendono a livello regionale e globale.
HSR.Salute ha utilizzato le capacità geospaziali di SageMaker per un’implementazione iniziale dello Zoonotic Spillover Risk Index e sta ora cercando partenariati, nonché supporto da parte dei paesi ospitanti e fonti di finanziamento, per sviluppare ulteriormente l’indice ed estenderne l’applicazione ad altre regioni del mondo. Per ulteriori informazioni sull'HSR.Salute e l'indice del rischio di spillover zoonotico, visitare www.hsr.health.
Scopri il potenziale dell'integrazione dei dati di osservazione della Terra nelle tue iniziative sanitarie esplorando le funzionalità geospaziali di SageMaker. Per ulteriori informazioni, fare riferimento a Funzionalità geospaziali di Amazon SageMakero interagire con ulteriori esempi per fare esperienza pratica.
Informazioni sugli autori
 Ajay K Gupta è co-fondatore e CEO di HSR.health, un'azienda che rivoluziona e innova l'analisi dei rischi sanitari attraverso la tecnologia geospaziale e le tecniche di intelligenza artificiale per prevedere la diffusione e la gravità delle malattie. E fornisce queste informazioni all’industria, ai governi e al settore sanitario in modo che possano anticipare, mitigare e trarre vantaggio dai rischi futuri. Fuori dal lavoro, puoi trovare Ajay dietro il microfono che fa scoppiare i timpani mentre canta a squarciagola i suoi brani pop preferiti degli U2, Sting, George Michael o Imagine Dragons.
Ajay K Gupta è co-fondatore e CEO di HSR.health, un'azienda che rivoluziona e innova l'analisi dei rischi sanitari attraverso la tecnologia geospaziale e le tecniche di intelligenza artificiale per prevedere la diffusione e la gravità delle malattie. E fornisce queste informazioni all’industria, ai governi e al settore sanitario in modo che possano anticipare, mitigare e trarre vantaggio dai rischi futuri. Fuori dal lavoro, puoi trovare Ajay dietro il microfono che fa scoppiare i timpani mentre canta a squarciagola i suoi brani pop preferiti degli U2, Sting, George Michael o Imagine Dragons.
 Jean Felipe Teotonio è un medico motivato ed esperto appassionato di qualità sanitaria ed epidemiologia delle malattie infettive, Jean Felipe guida il team di sanità pubblica HSR.health. Lavora per l’obiettivo condiviso di migliorare la salute pubblica riducendo il carico globale delle malattie sfruttando gli approcci GeoAI per sviluppare soluzioni per le più grandi sfide sanitarie del nostro tempo. Al di fuori del lavoro, i suoi hobby includono leggere libri di fantascienza, fare escursioni, giocare la Premier League inglese e suonare il basso.
Jean Felipe Teotonio è un medico motivato ed esperto appassionato di qualità sanitaria ed epidemiologia delle malattie infettive, Jean Felipe guida il team di sanità pubblica HSR.health. Lavora per l’obiettivo condiviso di migliorare la salute pubblica riducendo il carico globale delle malattie sfruttando gli approcci GeoAI per sviluppare soluzioni per le più grandi sfide sanitarie del nostro tempo. Al di fuori del lavoro, i suoi hobby includono leggere libri di fantascienza, fare escursioni, giocare la Premier League inglese e suonare il basso.
 Paolo Un sagrato, CTO e ingegnere capo geospaziale per HSR.health, utilizza le sue ampie competenze e competenze tecniche per costruire l'infrastruttura principale dell'azienda, nonché la sua piattaforma GeoMD brevettata e proprietaria. Inoltre, lui e il team di data science incorporano analisi geospaziali e tecniche AI/ML in tutti gli indici di rischio sanitario prodotti da HSR.health. Al di fuori del lavoro, Paul è un DJ autodidatta e adora la neve.
Paolo Un sagrato, CTO e ingegnere capo geospaziale per HSR.health, utilizza le sue ampie competenze e competenze tecniche per costruire l'infrastruttura principale dell'azienda, nonché la sua piattaforma GeoMD brevettata e proprietaria. Inoltre, lui e il team di data science incorporano analisi geospaziali e tecniche AI/ML in tutti gli indici di rischio sanitario prodotti da HSR.health. Al di fuori del lavoro, Paul è un DJ autodidatta e adora la neve.
 Janosch Woschitz è un Senior Solutions Architect presso AWS, specializzato in AI/ML geospaziale. Con oltre 15 anni di esperienza, supporta i clienti a livello globale nello sfruttamento dell'intelligenza artificiale e del machine learning per soluzioni innovative che sfruttano i dati geospaziali. La sua esperienza spazia dall'apprendimento automatico, all'ingegneria dei dati e ai sistemi distribuiti scalabili, arricchita da un forte background nell'ingegneria del software e dalla competenza nel settore in settori complessi come la guida autonoma.
Janosch Woschitz è un Senior Solutions Architect presso AWS, specializzato in AI/ML geospaziale. Con oltre 15 anni di esperienza, supporta i clienti a livello globale nello sfruttamento dell'intelligenza artificiale e del machine learning per soluzioni innovative che sfruttano i dati geospaziali. La sua esperienza spazia dall'apprendimento automatico, all'ingegneria dei dati e ai sistemi distribuiti scalabili, arricchita da un forte background nell'ingegneria del software e dalla competenza nel settore in settori complessi come la guida autonoma.
 Emmett Nelson è un Account Executive presso AWS che supporta i clienti della ricerca no-profit nei settori verticale Sanità e scienze della vita, Scienze della terra/ambientali e Istruzione. Il suo obiettivo principale è consentire casi d'uso di analisi, intelligenza artificiale/ML, calcolo ad alte prestazioni (HPC), genomica e imaging medico. Emmett è entrato in AWS nel 2020 e ha sede ad Austin, Texas.
Emmett Nelson è un Account Executive presso AWS che supporta i clienti della ricerca no-profit nei settori verticale Sanità e scienze della vita, Scienze della terra/ambientali e Istruzione. Il suo obiettivo principale è consentire casi d'uso di analisi, intelligenza artificiale/ML, calcolo ad alte prestazioni (HPC), genomica e imaging medico. Emmett è entrato in AWS nel 2020 e ha sede ad Austin, Texas.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/how-hsr-health-is-limiting-risks-of-disease-spillover-from-animals-to-humans-using-amazon-sagemaker-geospatial-capabilities/

