Amazon Sage Maker Studio fornisce una soluzione completamente gestita che consente ai data scientist di creare, addestrare e distribuire in modo interattivo modelli di machine learning (ML). Nel processo di lavoro sulle attività di ML, i data scientist in genere iniziano il flusso di lavoro scoprendo origini dati rilevanti e connettendosi ad esse. Quindi utilizzano SQL per esplorare, analizzare, visualizzare e integrare dati provenienti da varie fonti prima di utilizzarli nella formazione e nell'inferenza ML. In precedenza, i data scientist si trovavano spesso a destreggiarsi tra più strumenti per supportare SQL nel loro flusso di lavoro, il che ostacolava la produttività.
Siamo lieti di annunciare che i notebook JupyterLab in SageMaker Studio ora sono dotati del supporto integrato per SQL. I data scientist ora possono:
- Connettiti ai servizi dati più diffusi, inclusi Amazzone Atena, Amazon RedShift, Amazon DataZonee Snowflake direttamente nei taccuini
- Sfoglia e cerca database, schemi, tabelle e visualizzazioni e visualizza in anteprima i dati all'interno dell'interfaccia del notebook
- Combina codice SQL e Python nello stesso notebook per un'esplorazione e una trasformazione efficienti dei dati da utilizzare nei progetti ML
- Utilizza funzionalità di produttività degli sviluppatori come il completamento dei comandi SQL, l'assistenza alla formattazione del codice e l'evidenziazione della sintassi per accelerare lo sviluppo del codice e migliorare la produttività complessiva degli sviluppatori
Inoltre, gli amministratori possono gestire in modo sicuro le connessioni a questi servizi dati, consentendo ai data scientist di accedere ai dati autorizzati senza la necessità di gestire manualmente le credenziali.
In questo post ti guideremo attraverso la configurazione di questa funzionalità in SageMaker Studio e ti guideremo attraverso le varie funzionalità di questa funzionalità. Successivamente mostreremo come migliorare l'esperienza SQL in-notebook utilizzando le funzionalità Text-to-SQL fornite da LLM (Advanced Large Language Model) per scrivere query SQL complesse utilizzando testo in linguaggio naturale come input. Infine, per consentire a un pubblico più ampio di utenti di generare query SQL dall'input in linguaggio naturale nei propri notebook, ti mostriamo come distribuire questi modelli Text-to-SQL utilizzando Amazon Sage Maker endpoint.
Panoramica della soluzione
Con l'integrazione SQL del notebook SageMaker Studio JupyterLab, ora puoi connetterti a origini dati popolari come Snowflake, Athena, Amazon Redshift e Amazon DataZone. Questa nuova funzionalità consente di eseguire varie funzioni.
Ad esempio, puoi esplorare visivamente origini dati come database, tabelle e schemi direttamente dal tuo ecosistema JupyterLab. Se i tuoi ambienti notebook sono in esecuzione su SageMaker Distribution 1.6 o versioni successive, cerca un nuovo widget sul lato sinistro dell'interfaccia JupyterLab. Questa aggiunta migliora l'accessibilità e la gestione dei dati all'interno dell'ambiente di sviluppo.
Se al momento non utilizzi la distribuzione SageMaker suggerita (1.5 o precedente) o un ambiente personalizzato, fai riferimento all'appendice per ulteriori informazioni.
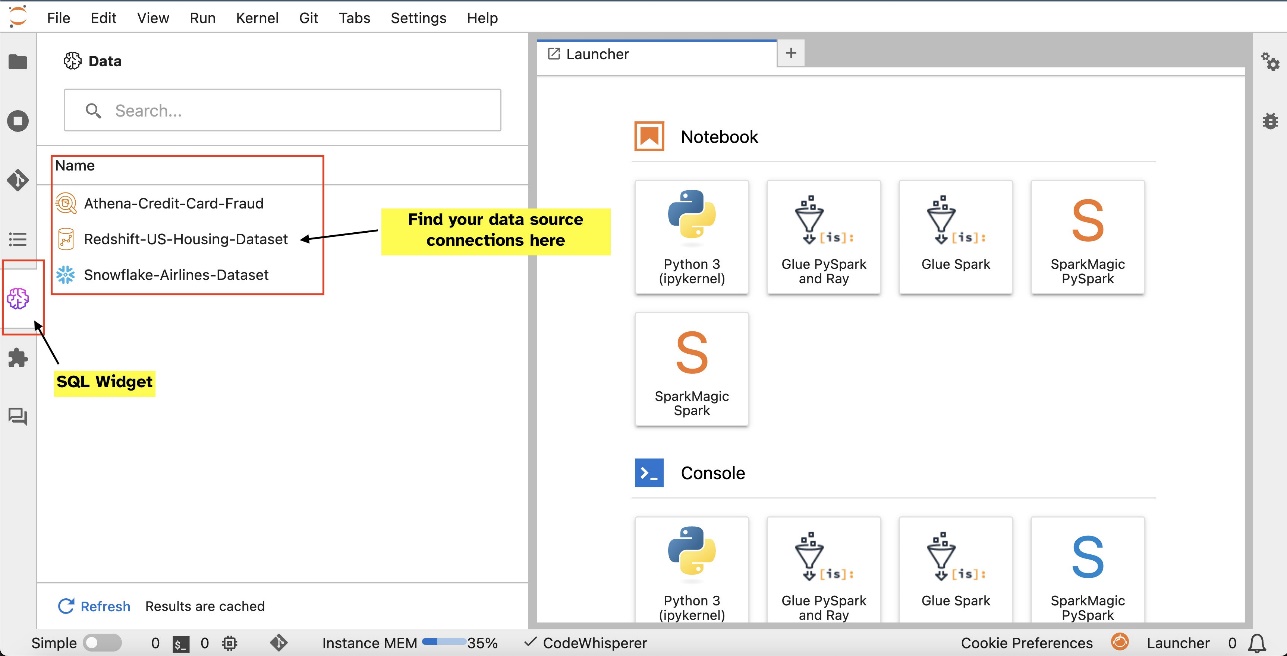
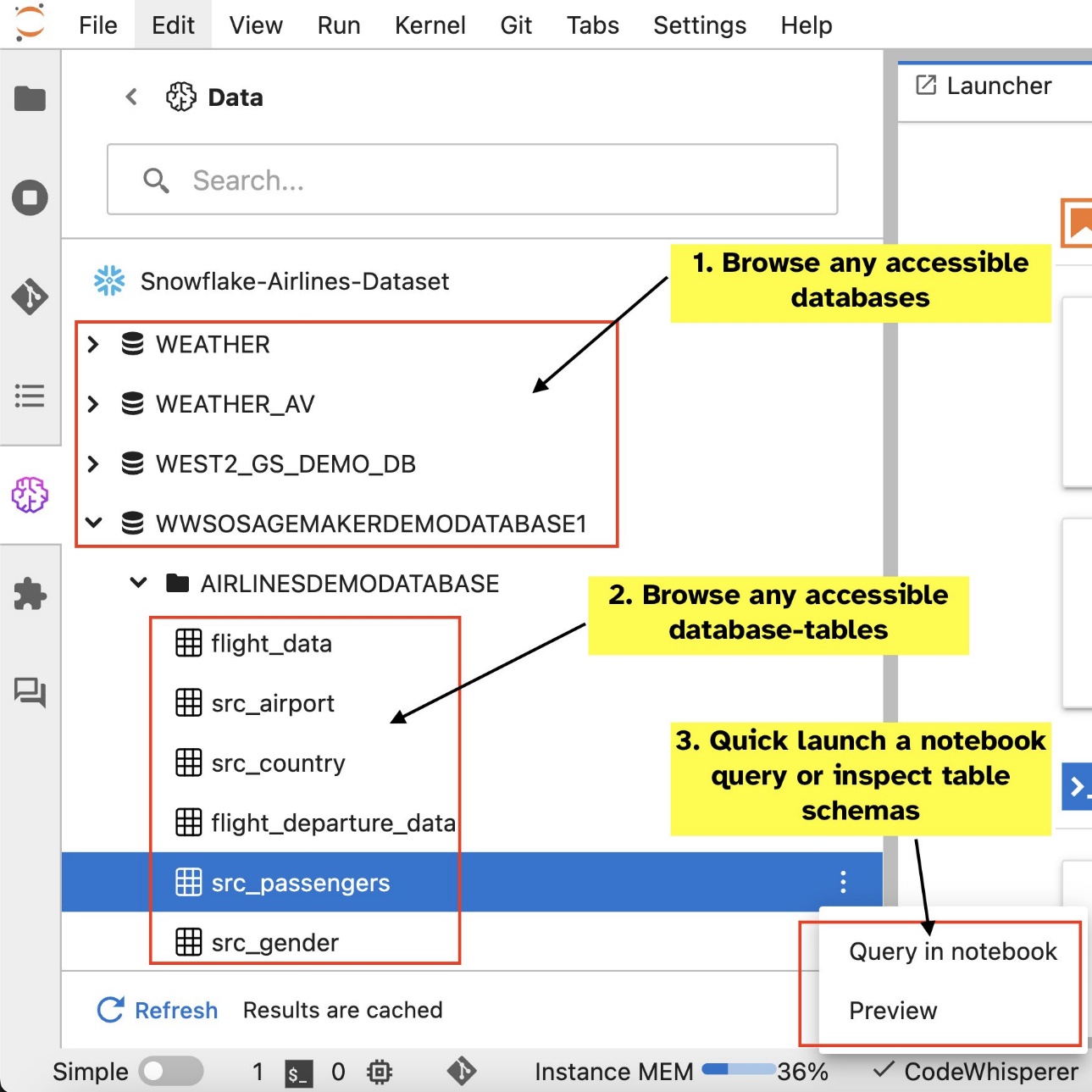
Dopo aver configurato le connessioni (illustrate nella sezione successiva), è possibile elencare le connessioni dati, esplorare database e tabelle e ispezionare gli schemi.
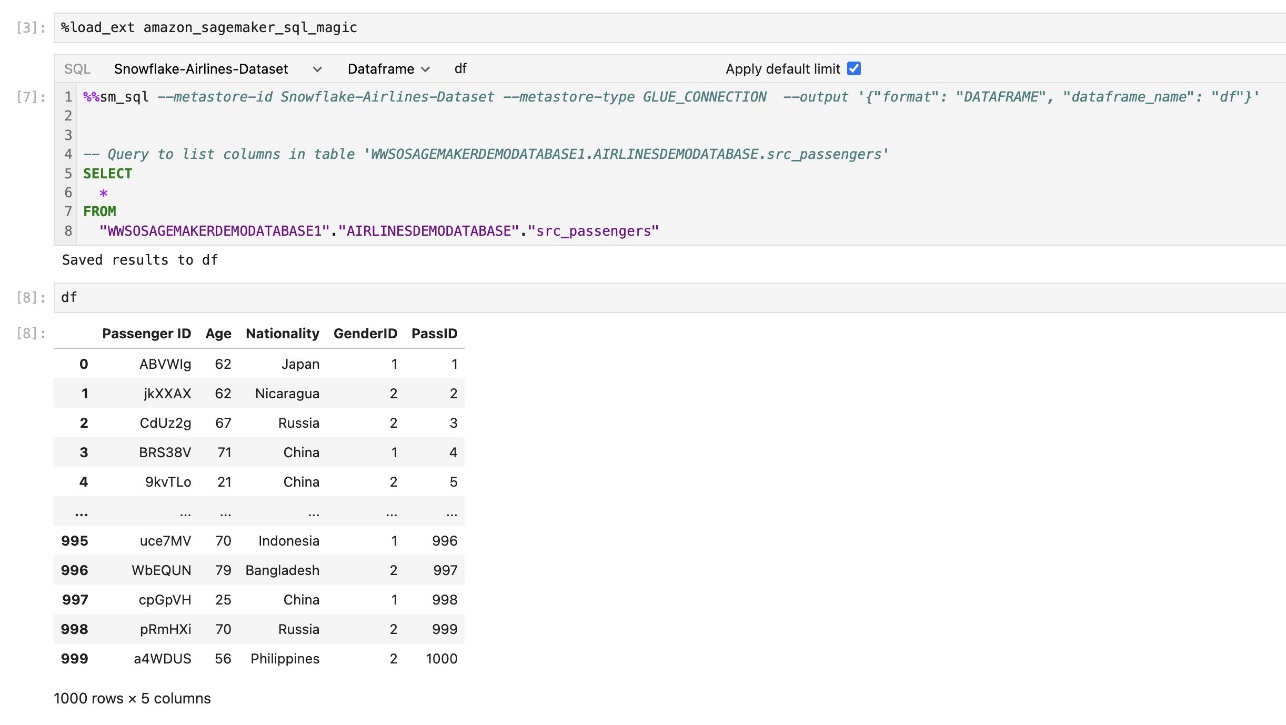
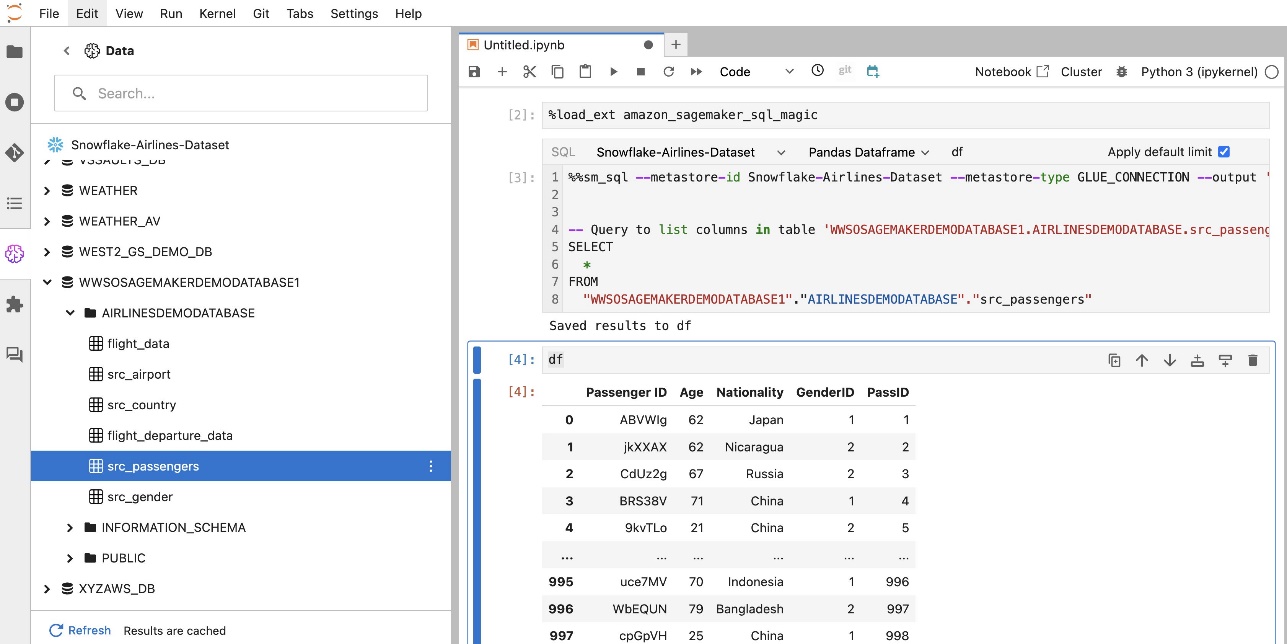
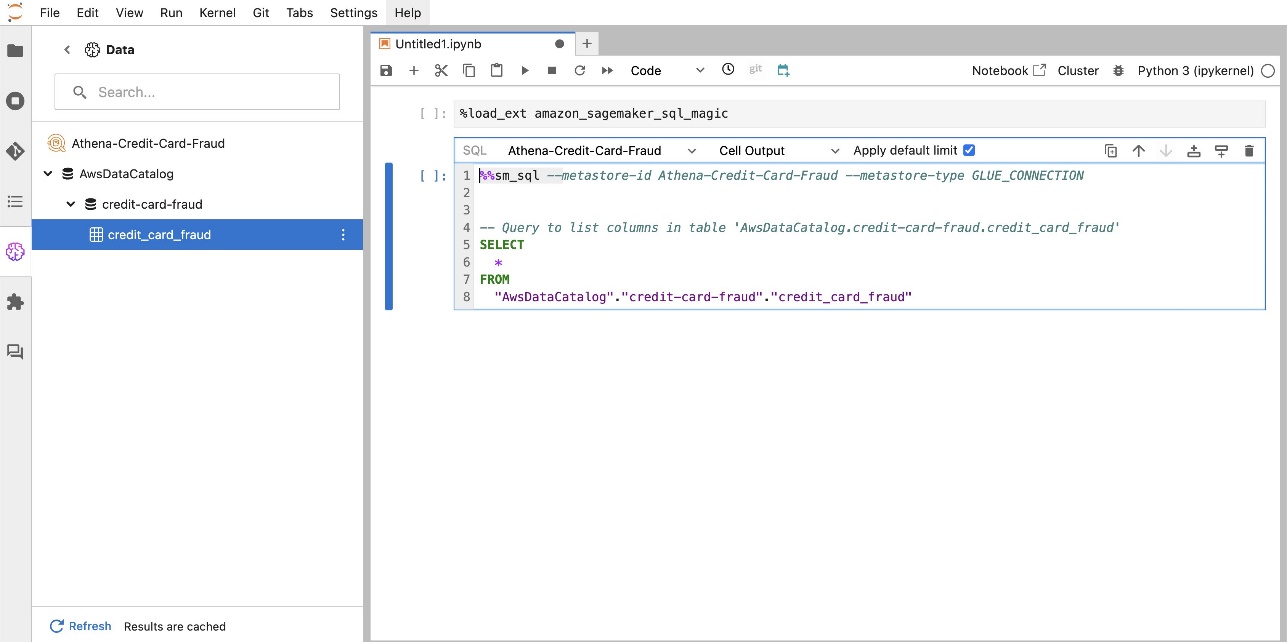
L'estensione SQL integrata di SageMaker Studio JupyterLab consente inoltre di eseguire query SQL direttamente da un notebook. I notebook Jupyter possono distinguere tra codice SQL e Python utilizzando il file %%sm_sql comando magico, che deve essere posizionato nella parte superiore di qualsiasi cella che contenga codice SQL. Questo comando segnala a JupyterLab che le seguenti istruzioni sono comandi SQL anziché codice Python. L'output di una query può essere visualizzato direttamente nel notebook, facilitando la perfetta integrazione dei flussi di lavoro SQL e Python nell'analisi dei dati.
L'output di una query può essere visualizzato visivamente come tabelle HTML, come mostrato nello screenshot seguente.

Possono anche essere scritti in a Panda DataFrame.
Prerequisiti
Assicurati di aver soddisfatto i seguenti prerequisiti per poter utilizzare l'esperienza SQL del notebook SageMaker Studio:
- SageMaker Studio V2 – Assicurati di eseguire la versione più aggiornata del tuo Dominio e profili utente di SageMaker Studio. Se utilizzi attualmente SageMaker Studio Classic, fai riferimento a Migrazione da Amazon SageMaker Studio Classic.
- Ruolo IAM – SageMaker richiede un file Gestione dell'identità e dell'accesso di AWS (IAM) da assegnare a un dominio o a un profilo utente SageMaker Studio per gestire le autorizzazioni in modo efficace. Potrebbe essere necessario un aggiornamento del ruolo di esecuzione per introdurre l'esplorazione dei dati e la funzionalità di esecuzione SQL. La policy di esempio seguente consente agli utenti di concedere, elencare ed eseguire Colla AWS, Atena, Servizio di archiviazione semplice Amazon (Amazon S3), AWS Secrets Managere risorse Amazon Redshift:
- Spazio JupyterLab – È necessario accedere a SageMaker Studio e JupyterLab Space aggiornati con Distribuzione SageMaker v1.6 o versioni successive dell'immagine. Se utilizzi immagini personalizzate per JupyterLab Spaces o versioni precedenti di SageMaker Distribution (v1.5 o precedente), fai riferimento all'appendice per istruzioni su come installare i pacchetti e i moduli necessari per abilitare questa funzionalità nei tuoi ambienti. Per ulteriori informazioni su SageMaker Studio JupyterLab Spaces, fare riferimento a Aumenta la produttività su Amazon SageMaker Studio: presentazione di JupyterLab Spaces e strumenti di intelligenza artificiale generativa.
- Credenziali di accesso all'origine dati – Questa funzionalità del notebook SageMaker Studio richiede l'accesso con nome utente e password a origini dati come Snowflake e Amazon Redshift. Crea un accesso basato su nome utente e password a queste origini dati se non ne hai già una. L'accesso basato su OAuth a Snowflake non è una funzionalità supportata al momento della stesura di questo documento.
- Carica la magia SQL – Prima di eseguire query SQL da una cella del notebook Jupyter, è essenziale caricare l'estensione SQL magics. Usa il comando
%load_ext amazon_sagemaker_sql_magicper abilitare questa funzione. Inoltre, puoi eseguire il file%sm_sql?comando per visualizzare un elenco completo delle opzioni supportate per eseguire query da una cella SQL. Queste opzioni includono, tra le altre cose, l'impostazione di un limite di query predefinito di 1,000, l'esecuzione di un'estrazione completa e l'inserimento di parametri di query. Questa configurazione consente una manipolazione dei dati SQL flessibile ed efficiente direttamente nell'ambiente del notebook.
Creare connessioni al database
Le funzionalità di navigazione ed esecuzione SQL integrate di SageMaker Studio sono migliorate dalle connessioni AWS Glue. Una connessione AWS Glue è un oggetto del catalogo dati di AWS Glue che archivia dati essenziali come credenziali di accesso, stringhe URI e informazioni sul cloud privato virtuale (VPC) per archivi dati specifici. Queste connessioni vengono utilizzate dai crawler, dai processi e dagli endpoint di sviluppo di AWS Glue per accedere a vari tipi di archivi dati. Puoi utilizzare queste connessioni sia per i dati di origine che per quelli di destinazione e persino riutilizzare la stessa connessione su più crawler o processi di estrazione, trasformazione e caricamento (ETL).
Per esplorare le origini dati SQL nel riquadro sinistro di SageMaker Studio, devi prima creare oggetti di connessione AWS Glue. Queste connessioni facilitano l'accesso a diverse origini dati e consentono di esplorare i relativi elementi di dati schematici.
Nelle sezioni seguenti, esamineremo il processo di creazione di connettori AWS Glue specifici per SQL. Ciò ti consentirà di accedere, visualizzare ed esplorare set di dati in una varietà di archivi dati. Per informazioni più dettagliate sulle connessioni AWS Glue, fare riferimento a Connessione ai dati.
Crea una connessione AWS Glue
L'unico modo per portare origini dati in SageMaker Studio è tramite connessioni AWS Glue. È necessario creare connessioni AWS Glue con tipi di connessione specifici. Al momento della stesura di questo documento, l'unico meccanismo supportato per la creazione di queste connessioni è l'utilizzo di Interfaccia della riga di comando di AWS (interfaccia a riga di comando dell'AWS).
File JSON di definizione della connessione
Quando ti connetti a diverse origini dati in AWS Glue, devi prima creare un file JSON che definisca le proprietà di connessione, denominate file di definizione della connessione. Questo file è fondamentale per stabilire una connessione AWS Glue e dovrebbe dettagliare tutte le configurazioni necessarie per accedere all'origine dati. Per le migliori pratiche di sicurezza, è consigliabile utilizzare Secrets Manager per archiviare in modo sicuro informazioni sensibili come le password. Nel frattempo, altre proprietà di connessione possono essere gestite direttamente tramite le connessioni AWS Glue. Questo approccio garantisce che le credenziali sensibili siano protette pur mantenendo la configurazione della connessione accessibile e gestibile.
Di seguito è riportato un esempio di definizione di connessione JSON:
Quando configuri le connessioni AWS Glue per le tue origini dati, ci sono alcune linee guida importanti da seguire per fornire funzionalità e sicurezza:
- Stringificazione delle proprietà – Entro il
PythonPropertieschiave, assicurati che tutte le proprietà lo siano coppie chiave-valore stringate. È fondamentale evitare correttamente le virgolette doppie utilizzando il carattere barra rovesciata () dove necessario. Ciò aiuta a mantenere il formato corretto ed evitare errori di sintassi nel tuo JSON. - Gestione delle informazioni sensibili – Sebbene sia possibile includere tutte le proprietà di connessione al suo interno
PythonProperties, è consigliabile non includere dettagli sensibili come le password direttamente in queste proprietà. Utilizza invece Secrets Manager per gestire le informazioni sensibili. Questo approccio protegge i tuoi dati sensibili archiviandoli in un ambiente controllato e crittografato, lontano dai principali file di configurazione.
Crea una connessione AWS Glue utilizzando AWS CLI
Dopo aver incluso tutti i campi necessari nel file JSON di definizione della connessione, sei pronto per stabilire una connessione AWS Glue per l'origine dati utilizzando AWS CLI e il seguente comando:
Questo comando avvia una nuova connessione AWS Glue in base alle specifiche dettagliate nel file JSON. Quella che segue è una rapida ripartizione dei componenti del comando:
- -regione – Specifica la regione AWS in cui verrà creata la connessione AWS Glue. È fondamentale selezionare la regione in cui si trovano le origini dati e gli altri servizi per ridurre al minimo la latenza e rispettare i requisiti di residenza dei dati.
- –cli-input-json file:///percorso/del/file/connection/definition/file.json – Questo parametro indica all'AWS CLI di leggere la configurazione di input da un file locale che contiene la definizione di connessione in formato JSON.
Dovresti essere in grado di creare connessioni AWS Glue con il comando AWS CLI precedente dal terminale Studio JupyterLab. Sul Compila il menù, scegliere New ed terminal.

Se l' create-connection viene eseguito correttamente, dovresti vedere l'origine dati elencata nel riquadro del browser SQL. Se non vedi l'origine dati elencata, scegli ricaricare per aggiornare la cache.

Crea una connessione Snowflake
In questa sezione ci concentreremo sull'integrazione di un'origine dati Snowflake con SageMaker Studio. La creazione di account, database e magazzini Snowflake non rientra nell'ambito di questo post. Per iniziare con Snowflake, fare riferimento a Guida per l'utente di Fiocco di neve. In questo post, ci concentreremo sulla creazione di un file JSON di definizione Snowflake e sulla creazione di una connessione all'origine dati Snowflake utilizzando AWS Glue.
Crea un segreto di Secrets Manager
Puoi connetterti al tuo account Snowflake utilizzando un ID utente e una password o utilizzando chiavi private. Per connetterti con un ID utente e una password, devi archiviare in modo sicuro le tue credenziali in Secrets Manager. Come accennato in precedenza, sebbene sia possibile incorporare queste informazioni in PythonProperties, non è consigliabile archiviare informazioni sensibili in formato testo semplice. Assicurati sempre che i dati sensibili siano gestiti in modo sicuro per evitare potenziali rischi per la sicurezza.
Per archiviare le informazioni in Secrets Manager, completare i seguenti passaggi:
- Nella console di Secrets Manager, selezionare Memorizza un nuovo segreto.
- Nel Tipo segretoscegli Altro tipo di segreto.
- Per la coppia chiave-valore, scegli plaintext e inserisci quanto segue:
- Inserisci un nome per il tuo segreto, ad esempio
sm-sql-snowflake-secret. - Lascia le altre impostazioni come predefinite o personalizzale se necessario.
- Crea il segreto.
Crea una connessione AWS Glue per Snowflake
Come discusso in precedenza, le connessioni AWS Glue sono essenziali per accedere a qualsiasi connessione da SageMaker Studio. Puoi trovare un elenco di tutte le proprietà di connessione supportate per Snowflake. Di seguito è riportata una definizione di connessione di esempio JSON per Snowflake. Sostituisci i valori del segnaposto con i valori appropriati prima di salvarlo su disco:
Per creare un oggetto di connessione AWS Glue per l'origine dati Snowflake, utilizzare il comando seguente:
Questo comando crea una nuova connessione all'origine dati Snowflake nel riquadro del browser SQL che è sfogliabile ed è possibile eseguire query SQL su di essa dalla cella del notebook JupyterLab.
Crea una connessione Amazon Redshift
Amazon Redshift è un servizio di data warehouse completamente gestito, su scala petabyte, che semplifica e riduce i costi di analisi di tutti i dati utilizzando SQL standard. La procedura per creare una connessione Amazon Redshift rispecchia da vicino quella per una connessione Snowflake.
Crea un segreto di Secrets Manager
Analogamente alla configurazione Snowflake, per connettersi ad Amazon Redshift utilizzando un ID utente e una password, è necessario archiviare in modo sicuro le informazioni segrete in Secrets Manager. Completa i seguenti passaggi:
- Nella console di Secrets Manager, selezionare Memorizza un nuovo segreto.
- Nel Tipo segretoscegli Credenziali per il cluster Amazon Redshift.
- Inserisci le credenziali utilizzate per accedere ad Amazon Redshift come origine dati.
- Scegli il cluster Redshift associato ai segreti.
- Inserisci un nome per il segreto, ad esempio
sm-sql-redshift-secret. - Lascia le altre impostazioni come predefinite o personalizzale se necessario.
- Crea il segreto.
Seguendo questi passaggi, ti assicuri che le tue credenziali di connessione siano gestite in modo sicuro, utilizzando le robuste funzionalità di sicurezza di AWS per gestire i dati sensibili in modo efficace.
Crea una connessione AWS Glue per Amazon Redshift
Per configurare una connessione con Amazon Redshift utilizzando una definizione JSON, compila i campi necessari e salva la seguente configurazione JSON su disco:
Per creare un oggetto di connessione AWS Glue per l'origine dati Redshift, utilizza il seguente comando AWS CLI:
Questo comando crea una connessione in AWS Glue collegata all'origine dati Redshift. Se il comando viene eseguito correttamente, sarai in grado di vedere la tua origine dati Redshift all'interno del notebook JupyterLab di SageMaker Studio, pronta per l'esecuzione di query SQL e l'esecuzione dell'analisi dei dati.

Crea una connessione Atena
Athena è un servizio di query SQL completamente gestito di AWS che consente l'analisi dei dati archiviati in Amazon S3 utilizzando SQL standard. Per configurare una connessione Athena come origine dati nel browser SQL del notebook JupyterLab, è necessario creare una definizione di connessione di esempio Athena JSON. La seguente struttura JSON configura i dettagli necessari per connettersi ad Athena, specificando il catalogo dati, la directory di staging S3 e la regione:
Per creare un oggetto di connessione AWS Glue per l'origine dati Athena, utilizzare il seguente comando AWS CLI:
Se il comando ha esito positivo, sarai in grado di accedere al catalogo dati e alle tabelle di Athena direttamente dal browser SQL all'interno del tuo notebook SageMaker Studio JupyterLab.
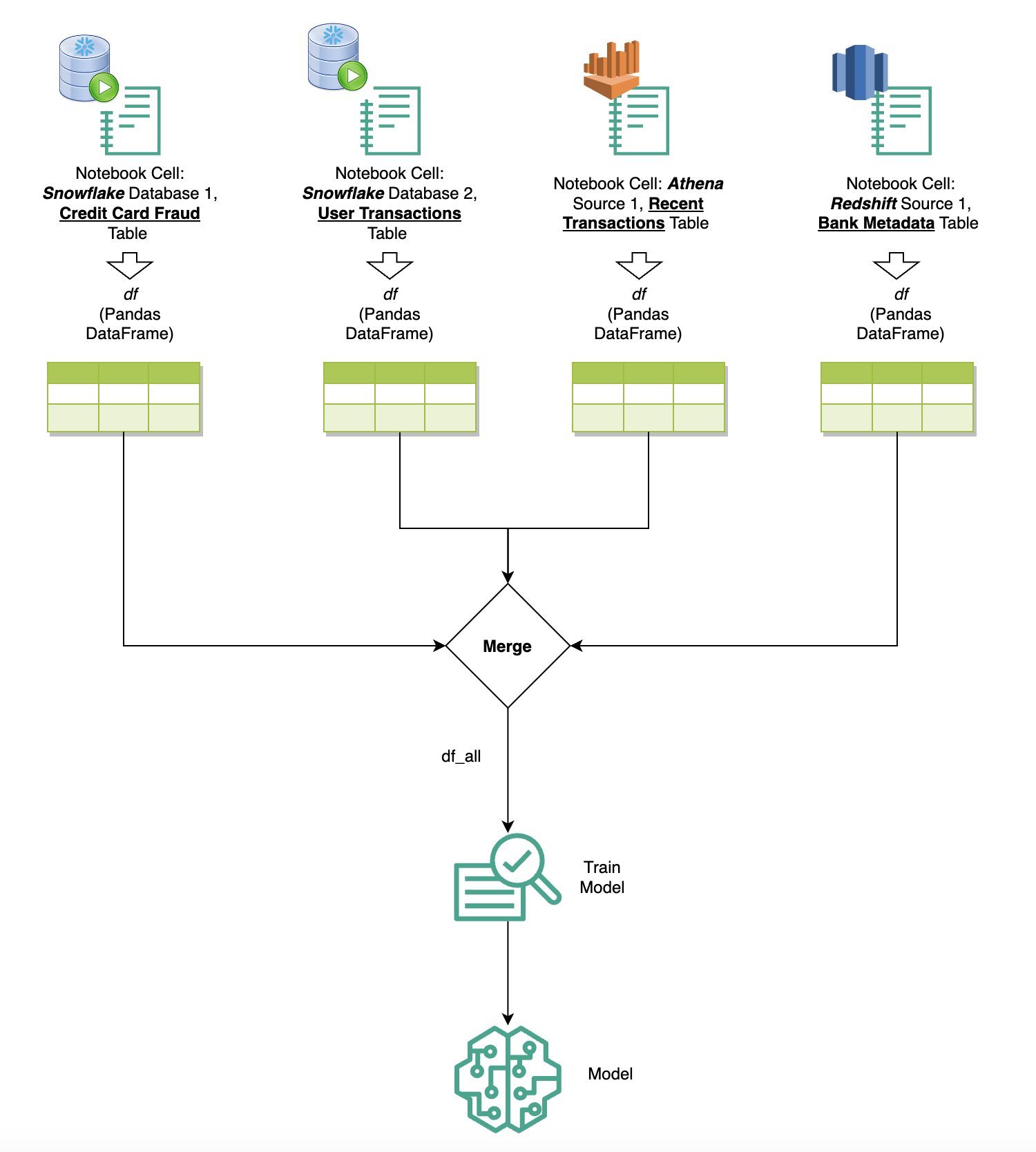
Interrogare dati da più fonti
Se disponi di più origini dati integrate in SageMaker Studio tramite il browser SQL integrato e la funzionalità SQL del notebook, puoi eseguire rapidamente query e passare facilmente da un backend all'altro dell'origine dati nelle celle successive all'interno di un notebook. Questa funzionalità consente transizioni fluide tra diversi database o origini dati durante il flusso di lavoro di analisi.
Puoi eseguire query su una raccolta diversificata di backend di origini dati e portare i risultati direttamente nello spazio Python per ulteriori analisi o visualizzazioni. Ciò è facilitato dal %%sm_sql comando magico disponibile nei notebook SageMaker Studio. Per generare i risultati della tua query SQL in un DataFrame panda, ci sono due opzioni:
- Dalla barra degli strumenti della cella del notebook, scegli il tipo di output dataframe e dai un nome alla variabile DataFrame
- Aggiungi il seguente parametro al tuo
%%sm_sqlcomando:
Il diagramma seguente illustra questo flusso di lavoro e mostra come eseguire facilmente query su varie origini nelle celle successive del notebook, nonché addestrare un modello SageMaker utilizzando processi di training o direttamente all'interno del notebook utilizzando il calcolo locale. Inoltre, il diagramma evidenzia come l'integrazione SQL integrata di SageMaker Studio semplifica i processi di estrazione e creazione direttamente nell'ambiente familiare di una cella notebook JupyterLab.
Testo in SQL: utilizzo del linguaggio naturale per migliorare la creazione di query
SQL è un linguaggio complesso che richiede la comprensione di database, tabelle, sintassi e metadati. Oggi, l'intelligenza artificiale generativa (AI) può consentirti di scrivere query SQL complesse senza richiedere un'esperienza SQL approfondita. Il progresso degli LLM ha avuto un impatto significativo sulla generazione SQL basata sull'elaborazione del linguaggio naturale (NLP), consentendo la creazione di query SQL precise da descrizioni in linguaggio naturale, una tecnica denominata Text-to-SQL. Tuttavia, è essenziale riconoscere le differenze intrinseche tra il linguaggio umano e SQL. Il linguaggio umano a volte può essere ambiguo o impreciso, mentre SQL è strutturato, esplicito e non ambiguo. Colmare questo divario e convertire accuratamente il linguaggio naturale in query SQL può rappresentare una sfida formidabile. Se forniti con istruzioni appropriate, gli LLM possono aiutare a colmare questa lacuna comprendendo l'intento dietro il linguaggio umano e generando query SQL accurate di conseguenza.
Con il rilascio della funzionalità di query SQL in-notebook di SageMaker Studio, SageMaker Studio semplifica l'ispezione di database e schemi, nonché la creazione, l'esecuzione e il debug di query SQL senza mai lasciare l'IDE del notebook Jupyter. Questa sezione esplora il modo in cui le funzionalità Text-to-SQL di LLM avanzati possono facilitare la generazione di query SQL utilizzando il linguaggio naturale all'interno dei notebook Jupyter. Utilizziamo il modello all'avanguardia Text-to-SQL defog/sqlcoder-7b-2 in collaborazione con Jupyter AI, un assistente AI generativo progettato specificamente per i notebook Jupyter, per creare query SQL complesse dal linguaggio naturale. Utilizzando questo modello avanzato, possiamo creare query SQL complesse in modo semplice ed efficiente utilizzando il linguaggio naturale, migliorando così la nostra esperienza SQL all'interno dei notebook.
Prototipazione di notebook utilizzando Hugging Face Hub
Per iniziare la prototipazione, è necessario quanto segue:
- codice GitHub – Il codice presentato in questa sezione è disponibile di seguito Repository GitHub e facendo riferimento a quaderno di esempio.
- Spazio JupyterLab – L’accesso a uno spazio JupyterLab di SageMaker Studio supportato da istanze basate su GPU è essenziale. Per il
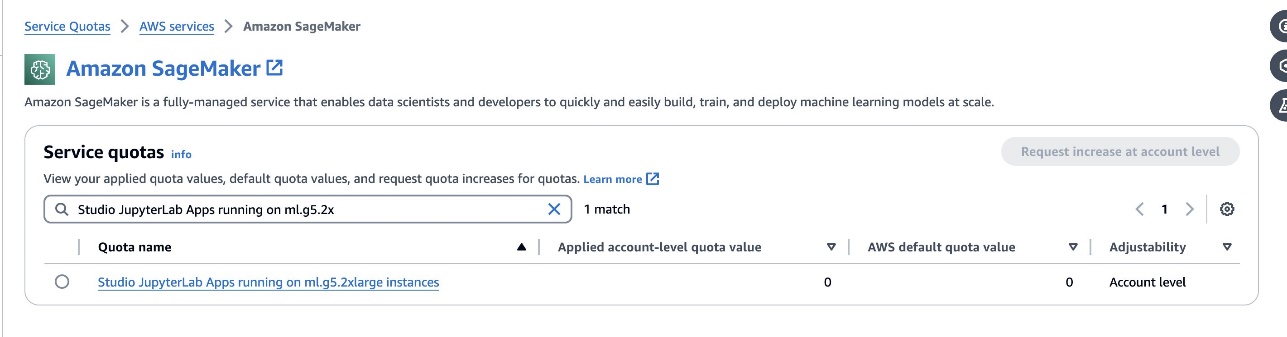
defog/sqlcoder-7b-2model, si consiglia un modello con parametri 7B che utilizza un'istanza ml.g5.2xlarge. Alternative comedefog/sqlcoder-70b-alpha odefog/sqlcoder-34b-alphasono utilizzabili anche per la conversione dal linguaggio naturale a SQL, ma per la prototipazione potrebbero essere necessari tipi di istanza più grandi. Assicurati di disporre della quota per avviare un'istanza supportata da GPU accedendo alla console Service Quotas, cercando SageMaker e cercandoStudio JupyterLab Apps running on <instance type>.
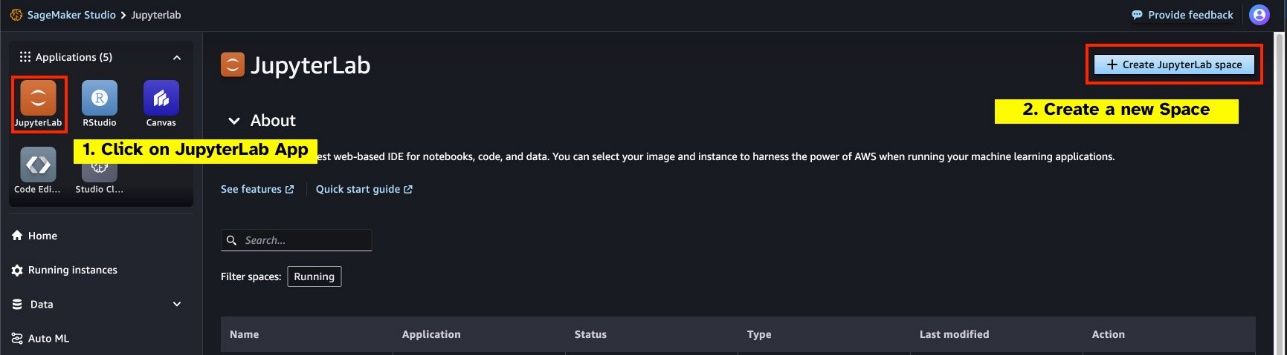
Avvia un nuovo JupyterLab Space supportato da GPU dal tuo SageMaker Studio. Si consiglia di creare un nuovo spazio JupyterLab con almeno 75 GB di spazio Negozio di blocchi elastici di Amazon (Amazon EBS) per un modello di parametri 7B.

- Hub per il viso che abbraccia – Se il tuo dominio SageMaker Studio ha accesso al download di modelli da Hub per il viso che abbraccia, è possibile utilizzare il comando
AutoModelForCausalLMclasse da faccia abbracciata/trasformatori per scaricare automaticamente i modelli e aggiungerli alle GPU locali. I pesi del modello verranno archiviati nella cache del computer locale. Vedere il seguente codice:
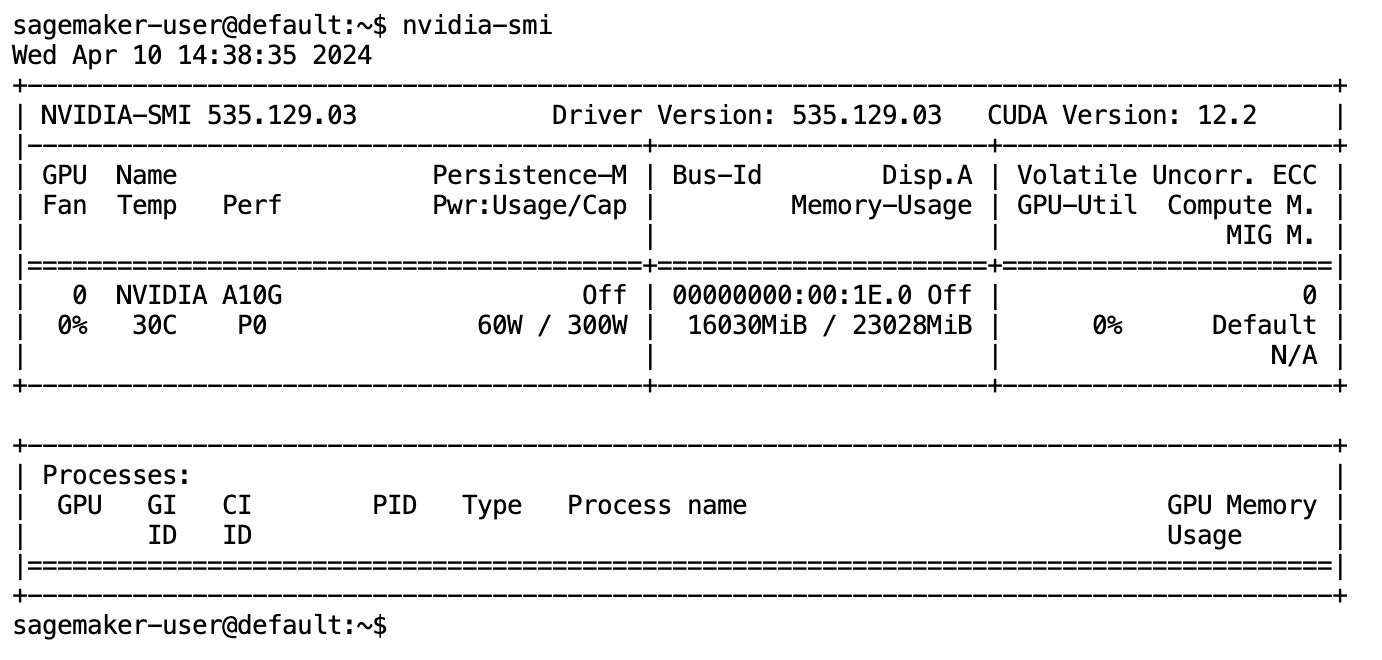
Dopo che il modello è stato completamente scaricato e caricato in memoria, dovresti osservare un aumento nell'utilizzo della GPU sul tuo computer locale. Ciò indica che il modello utilizza attivamente le risorse GPU per attività di calcolo. Puoi verificarlo nel tuo spazio JupyterLab eseguendo nvidia-smi (per una visualizzazione singola) o nvidia-smi —loop=1 (da ripetere ogni secondo) dal tuo terminale JupyterLab.
I modelli text-to-SQL eccellono nel comprendere l'intento e il contesto della richiesta di un utente, anche quando il linguaggio utilizzato è colloquiale o ambiguo. Il processo prevede la traduzione degli input in linguaggio naturale negli elementi corretti dello schema del database, come nomi di tabelle, nomi di colonne e condizioni. Tuttavia, un modello Text-to-SQL standardizzato non conoscerà intrinsecamente la struttura del data warehouse, gli schemi di database specifici o non sarà in grado di interpretare accuratamente il contenuto di una tabella basandosi esclusivamente sui nomi delle colonne. Per utilizzare in modo efficace questi modelli per generare query SQL pratiche ed efficienti dal linguaggio naturale, è necessario adattare il modello di generazione del testo SQL allo schema specifico del database di magazzino. Questo adattamento è facilitato dall'uso di LLM richiede. Quello che segue è un modello di prompt consigliato per il modello testo-SQL defog/sqlcoder-7b-2, diviso in quattro parti:
- Task – Questa sezione dovrebbe specificare un compito di alto livello che deve essere svolto dal modello. Dovrebbe includere il tipo di backend del database (come Amazon RDS, PostgreSQL o Amazon Redshift) per rendere il modello consapevole di eventuali differenze sintattiche sfumate che potrebbero influenzare la generazione della query SQL finale.
- Istruzioni – Questa sezione dovrebbe definire i limiti delle attività e la consapevolezza del dominio per il modello e può includere alcuni esempi per guidare il modello nella generazione di query SQL ottimizzate.
- Schema del database – Questa sezione dovrebbe dettagliare gli schemi del database del magazzino, delineando le relazioni tra tabelle e colonne per aiutare il modello a comprendere la struttura del database.
- Risposta – Questa sezione è riservata al modello per l'output della risposta alla query SQL all'input in linguaggio naturale.
Un esempio dello schema del database e del prompt utilizzati in questa sezione è disponibile nel file Archivio GitHub.
L'ingegneria tempestiva non consiste solo nel formulare domande o affermazioni; è un'arte e una scienza ricca di sfumature che ha un impatto significativo sulla qualità delle interazioni con un modello di intelligenza artificiale. Il modo in cui crei un prompt può influenzare profondamente la natura e l'utilità della risposta dell'IA. Questa abilità è fondamentale per massimizzare il potenziale delle interazioni dell’intelligenza artificiale, soprattutto in compiti complessi che richiedono comprensione specializzata e risposte dettagliate.
È importante avere la possibilità di creare e testare rapidamente la risposta di un modello per un determinato prompt e ottimizzare il prompt in base alla risposta. I notebook JupyterLab offrono la possibilità di ricevere feedback istantaneo sul modello da un modello in esecuzione sul calcolo locale e di ottimizzare il prompt e ottimizzare ulteriormente la risposta di un modello o modificare completamente un modello. In questo post, utilizziamo un notebook SageMaker Studio JupyterLab supportato dalla GPU NVIDIA A5.2G da 10 GB di ml.g24xlarge per eseguire l'inferenza del modello Text-to-SQL sul notebook e creare in modo interattivo il prompt del modello fino a quando la risposta del modello non è sufficientemente ottimizzata per fornire risposte che sono direttamente eseguibili nelle celle SQL di JupyterLab. Per eseguire l'inferenza del modello e trasmettere simultaneamente le risposte del modello, utilizziamo una combinazione di model.generate ed TextIteratorStreamer come definito nel seguente codice:
L'output del modello può essere decorato con la magia SQL di SageMaker %%sm_sql ..., che consente al notebook JupyterLab di identificare la cella come cella SQL.
Ospita modelli Text-to-SQL come endpoint SageMaker
Alla fine della fase di prototipazione, abbiamo selezionato il nostro LLM Text-to-SQL preferito, un formato di prompt efficace e un tipo di istanza appropriato per ospitare il modello (GPU singola o multi-GPU). SageMaker facilita l'hosting scalabile di modelli personalizzati attraverso l'uso di endpoint SageMaker. Questi endpoint possono essere definiti in base a criteri specifici, consentendo la distribuzione di LLM come endpoint. Questa funzionalità consente di adattare la soluzione a un pubblico più ampio, consentendo agli utenti di generare query SQL da input in linguaggio naturale utilizzando LLM ospitati personalizzati. Il diagramma seguente illustra questa architettura.

Per ospitare il tuo LLM come endpoint SageMaker, generi diversi artefatti.
Il primo artefatto sono i pesi del modello. Servizio SageMaker Deep Java Library (DJL). i contenitori ti consentono di impostare configurazioni tramite un meta servire.proprietà file, che ti consente di determinare la modalità di approvvigionamento dei modelli, direttamente da Hugging Face Hub o scaricando gli artefatti del modello da Amazon S3. Se specifichi model_id=defog/sqlcoder-7b-2, DJL Serving tenterà di scaricare direttamente questo modello da Hugging Face Hub. Tuttavia, potresti incorrere in costi di ingresso/uscita dalla rete ogni volta che l'endpoint viene distribuito o ridimensionato in modo elastico. Per evitare questi addebiti e velocizzare potenzialmente il download degli artefatti del modello, si consiglia di saltare l'utilizzo model_id in serving.properties e salva i pesi del modello come artefatti S3 e specificali solo con s3url=s3://path/to/model/bin.
Il salvataggio di un modello (con il relativo tokenizzatore) su disco e il caricamento su Amazon S3 possono essere eseguiti con poche righe di codice:
Si utilizza anche un file di prompt del database. In questa configurazione, il prompt del database è composto da Task, Instructions, Database Schemae Answer sections. Per l'architettura attuale, allochiamo un file di prompt separato per ogni schema di database. Tuttavia, esiste la flessibilità per espandere questa configurazione per includere più database per file di prompt, consentendo al modello di eseguire join compositi tra database sullo stesso server. Durante la fase di prototipazione, salviamo il prompt del database come file di testo denominato <Database-Glue-Connection-Name>.prompt, Dove Database-Glue-Connection-Name corrisponde al nome della connessione visibile nel tuo ambiente JupyterLab. Ad esempio, questo post si riferisce a una connessione Snowflake denominata Airlines_Dataset, quindi viene denominato il file di prompt del database Airlines_Dataset.prompt. Questo file viene quindi archiviato su Amazon S3 e successivamente letto e memorizzato nella cache dalla nostra logica di servizio del modello.
Inoltre, questa architettura consente a tutti gli utenti autorizzati di questo endpoint di definire, archiviare e generare linguaggio naturale per query SQL senza la necessità di ridistribuzioni multiple del modello. Usiamo quanto segue esempio di prompt del database per dimostrare la funzionalità Text-to-SQL.
Successivamente, genererai la logica del servizio modello personalizzato. In questa sezione viene delineata una logica di inferenza personalizzata denominata modello.py. Questo script è progettato per ottimizzare le prestazioni e l'integrazione dei nostri servizi Text-to-SQL:
- Definire la logica di memorizzazione nella cache dei file di prompt del database – Per ridurre al minimo la latenza, implementiamo una logica personalizzata per il download e la memorizzazione nella cache dei file di prompt del database. Questo meccanismo garantisce che i prompt siano prontamente disponibili, riducendo il sovraccarico associato ai download frequenti.
- Definire la logica di inferenza del modello personalizzato – Per migliorare la velocità di inferenza, il nostro modello text-to-SQL viene caricato nel formato di precisione float16 e quindi convertito in un modello DeepSpeed. Questo passaggio consente un calcolo più efficiente. Inoltre, all'interno di questa logica, specifichi quali parametri gli utenti possono regolare durante le chiamate di inferenza per personalizzare la funzionalità in base alle loro esigenze.
- Definire la logica di input e output personalizzata – Stabilire formati di input/output chiari e personalizzati è essenziale per un’integrazione fluida con le applicazioni a valle. Una di queste applicazioni è JupyterAI, di cui parleremo nella sezione successiva.
Inoltre, includiamo a serving.properties file, che funge da file di configurazione globale per i modelli ospitati utilizzando il servizio DJL. Per ulteriori informazioni, fare riferimento a Configurazioni e impostazioni.
Infine, puoi anche includere a requirements.txt file per definire moduli aggiuntivi richiesti per l'inferenza e impacchettare tutto in un file tar per la distribuzione.
Vedi il seguente codice:
Integra il tuo endpoint con l'assistente AI Jupyter di SageMaker Studio
IA di Giove è uno strumento open source che porta l'intelligenza artificiale generativa sui notebook Jupyter, offrendo una piattaforma solida e intuitiva per esplorare modelli di intelligenza artificiale generativa. Migliora la produttività in JupyterLab e nei notebook Jupyter fornendo funzionalità come %%ai magic per creare un parco giochi IA generativo all'interno dei notebook, un'interfaccia utente di chat nativa in JupyterLab per interagire con l'intelligenza artificiale come assistente conversazionale e supporto per un'ampia gamma di LLM da ai fornitori piace Titano Amazzonico, AI21, Anthropic, Cohere e Hugging Face o servizi gestiti come Roccia Amazzonica ed endpoint SageMaker. Per questo post, utilizziamo l'integrazione pronta all'uso di Jupyter AI con gli endpoint SageMaker per portare la funzionalità Text-to-SQL nei notebook JupyterLab. Lo strumento Jupyter AI è preinstallato in tutti gli spazi JupyterLab di SageMaker Studio supportati da Immagini di distribuzione SageMaker; agli utenti finali non è richiesto di effettuare alcuna configurazione aggiuntiva per iniziare a utilizzare l'estensione Jupyter AI per l'integrazione con un endpoint ospitato da SageMaker. In questa sezione, discutiamo i due modi per utilizzare lo strumento AI Jupyter integrato.
Jupyter AI all'interno di un notebook utilizzando la magia
L'intelligenza artificiale di Jupyter %%ai Il comando magico ti consente di trasformare i tuoi notebook SageMaker Studio JupyterLab in un ambiente AI generativo riproducibile. Per iniziare a utilizzare AI Magics, assicurati di aver caricato l'estensione jupyter_ai_magics da utilizzare %%ai magia e inoltre caricare amazon_sagemaker_sql_magic usare %%sm_sql Magia:
Per eseguire una chiamata al tuo endpoint SageMaker dal tuo notebook utilizzando il file %%ai comando magico, fornire i seguenti parametri e strutturare il comando come segue:
- –nome-regione – Specificare la regione in cui viene distribuito l'endpoint. Ciò garantisce che la richiesta venga instradata alla posizione geografica corretta.
- –schema-richiesta – Includere lo schema dei dati di input. Questo schema delinea il formato e i tipi previsti dei dati di input necessari al modello per elaborare la richiesta.
- –percorso-di-risposta – Definisci il percorso all'interno dell'oggetto risposta in cui si trova l'output del tuo modello. Questo percorso viene utilizzato per estrarre i dati rilevanti dalla risposta restituita dal modello.
- -f (facoltativo) - Questo è un formattatore di output flag che indica il tipo di output restituito dal modello. Nel contesto di un notebook Jupyter, se l'output è codice, questo flag deve essere impostato di conseguenza per formattare l'output come codice eseguibile nella parte superiore della cella di un notebook Jupyter, seguito da un'area di input di testo libero per l'interazione dell'utente.
Ad esempio, il comando in una cella del notebook Jupyter potrebbe assomigliare al codice seguente:
Finestra di chat dell'intelligenza artificiale di Jupyter
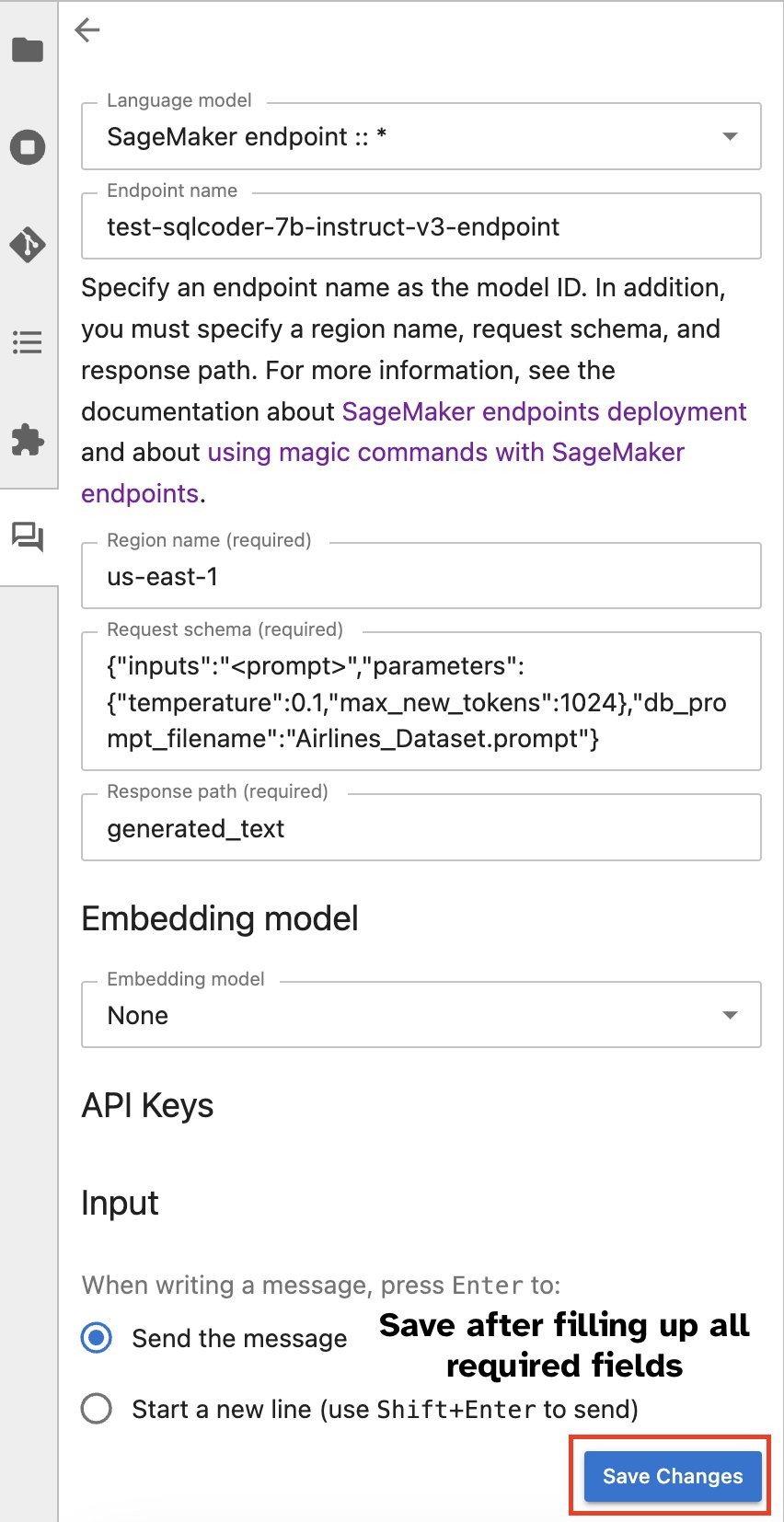
In alternativa, puoi interagire con gli endpoint SageMaker tramite un'interfaccia utente integrata, semplificando il processo di generazione di query o di dialogo. Prima di iniziare a chattare con il tuo endpoint SageMaker, configura le impostazioni pertinenti in Jupyter AI per l'endpoint SageMaker, come mostrato nello screenshot seguente.
 |
 |
Conclusione
SageMaker Studio ora semplifica e ottimizza il flusso di lavoro dei data scientist integrando il supporto SQL nei notebook JupyterLab. Ciò consente ai data scientist di concentrarsi sulle proprie attività senza la necessità di gestire più strumenti. Inoltre, la nuova integrazione SQL integrata in SageMaker Studio consente ai data personas di generare facilmente query SQL utilizzando testo in linguaggio naturale come input, accelerando così il flusso di lavoro.
Ti invitiamo a esplorare queste funzionalità in SageMaker Studio. Per ulteriori informazioni, fare riferimento a Preparare i dati con SQL in Studio.
Appendice
Abilitare il browser SQL e la cella SQL del notebook in ambienti personalizzati
Se non utilizzi un'immagine di distribuzione SageMaker o immagini di distribuzione 1.5 o precedenti, esegui i seguenti comandi per abilitare la funzionalità di navigazione SQL all'interno del tuo ambiente JupyterLab:
Riposizionare il widget del browser SQL
I widget JupyterLab consentono il riposizionamento. A seconda delle tue preferenze, puoi spostare i widget su entrambi i lati del riquadro dei widget di JupyterLab. Se preferisci, puoi spostare la direzione del widget SQL sul lato opposto (da destra a sinistra) della barra laterale con un semplice clic destro sull'icona del widget e scegliendo Cambia il lato della barra laterale.
 |
 |
Circa gli autori
 Pranav Murthy è un AI/ML Specialist Solutions Architect presso AWS. Il suo obiettivo è aiutare i clienti a creare, addestrare, distribuire e migrare carichi di lavoro di machine learning (ML) su SageMaker. In precedenza ha lavorato nel settore dei semiconduttori sviluppando modelli di visione artificiale (CV) di grandi dimensioni e di elaborazione del linguaggio naturale (NLP) per migliorare i processi dei semiconduttori utilizzando tecniche ML all'avanguardia. Nel tempo libero gli piace giocare a scacchi e viaggiare. Puoi trovare Pranav su LinkedIn.
Pranav Murthy è un AI/ML Specialist Solutions Architect presso AWS. Il suo obiettivo è aiutare i clienti a creare, addestrare, distribuire e migrare carichi di lavoro di machine learning (ML) su SageMaker. In precedenza ha lavorato nel settore dei semiconduttori sviluppando modelli di visione artificiale (CV) di grandi dimensioni e di elaborazione del linguaggio naturale (NLP) per migliorare i processi dei semiconduttori utilizzando tecniche ML all'avanguardia. Nel tempo libero gli piace giocare a scacchi e viaggiare. Puoi trovare Pranav su LinkedIn.
 Varun Shah è un ingegnere del software che lavora su Amazon SageMaker Studio presso Amazon Web Services. Si concentra sulla creazione di soluzioni ML interattive che semplificano i percorsi di elaborazione e preparazione dei dati. Nel suo tempo libero, Varun ama le attività all'aria aperta, tra cui l'escursionismo e lo sci, ed è sempre pronto a scoprire posti nuovi ed entusiasmanti.
Varun Shah è un ingegnere del software che lavora su Amazon SageMaker Studio presso Amazon Web Services. Si concentra sulla creazione di soluzioni ML interattive che semplificano i percorsi di elaborazione e preparazione dei dati. Nel suo tempo libero, Varun ama le attività all'aria aperta, tra cui l'escursionismo e lo sci, ed è sempre pronto a scoprire posti nuovi ed entusiasmanti.
 Sumedha Swami è Principal Product Manager presso Amazon Web Services, dove guida il team di SageMaker Studio nella sua missione di sviluppare l'IDE preferito per la scienza dei dati e l'apprendimento automatico. Ha dedicato gli ultimi 15 anni alla creazione di prodotti consumer e aziendali basati sul machine learning.
Sumedha Swami è Principal Product Manager presso Amazon Web Services, dove guida il team di SageMaker Studio nella sua missione di sviluppare l'IDE preferito per la scienza dei dati e l'apprendimento automatico. Ha dedicato gli ultimi 15 anni alla creazione di prodotti consumer e aziendali basati sul machine learning.
 BoscoAlbuquerque è Sr. Partner Solutions Architect presso AWS e ha oltre 20 anni di esperienza nella collaborazione con prodotti di database e analisi di fornitori di database aziendali e fornitori di cloud. Ha aiutato aziende tecnologiche a progettare e implementare soluzioni e prodotti di analisi dei dati.
BoscoAlbuquerque è Sr. Partner Solutions Architect presso AWS e ha oltre 20 anni di esperienza nella collaborazione con prodotti di database e analisi di fornitori di database aziendali e fornitori di cloud. Ha aiutato aziende tecnologiche a progettare e implementare soluzioni e prodotti di analisi dei dati.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

