Cliente 360 (C360) fornisce una visione completa e unificata delle interazioni e del comportamento del cliente attraverso tutti i punti di contatto e i canali. Questa visualizzazione viene utilizzata per identificare modelli e tendenze nel comportamento dei clienti, che possono orientare le decisioni basate sui dati per migliorare i risultati aziendali. Ad esempio, puoi utilizzare C360 per segmentare e creare campagne di marketing che hanno maggiori probabilità di avere risonanza con gruppi specifici di clienti.
Nel 2022, AWS ha commissionato uno studio condotto dall'American Productivity and Quality Center (APQC) per quantificare il Valore aziendale del cliente 360. La figura seguente mostra alcuni dei parametri derivati dallo studio. Le organizzazioni che utilizzano C360 hanno ottenuto una riduzione del 43.9% della durata del ciclo di vendita, un aumento del 22.8% del valore della vita del cliente, un time-to-market più veloce del 25.3% e un miglioramento del 19.1% nella valutazione del punteggio netto del promotore (NPS).

Senza C360, le aziende si trovano ad affrontare opportunità mancate, report imprecisi ed esperienze cliente sconnesse, con conseguente abbandono dei clienti. Tuttavia, costruire una soluzione C360 può essere complicato. UN Sondaggio di marketing Gartner ha rilevato che solo il 14% delle organizzazioni ha implementato con successo una soluzione C360, a causa della mancanza di consenso su cosa significhi una visione a 360 gradi, delle sfide legate alla qualità dei dati e della mancanza di una struttura di governance interfunzionale per i dati dei clienti.
In questo post, discutiamo di come utilizzare servizi AWS appositamente creati per creare una strategia dati end-to-end per C360 per unificare e governare i dati dei clienti che affrontano queste sfide. Lo struttureamo in cinque pilastri che alimentano C360: raccolta dati, unificazione, analisi, attivazione e governance dei dati, insieme a un'architettura della soluzione che puoi utilizzare per la tua implementazione.
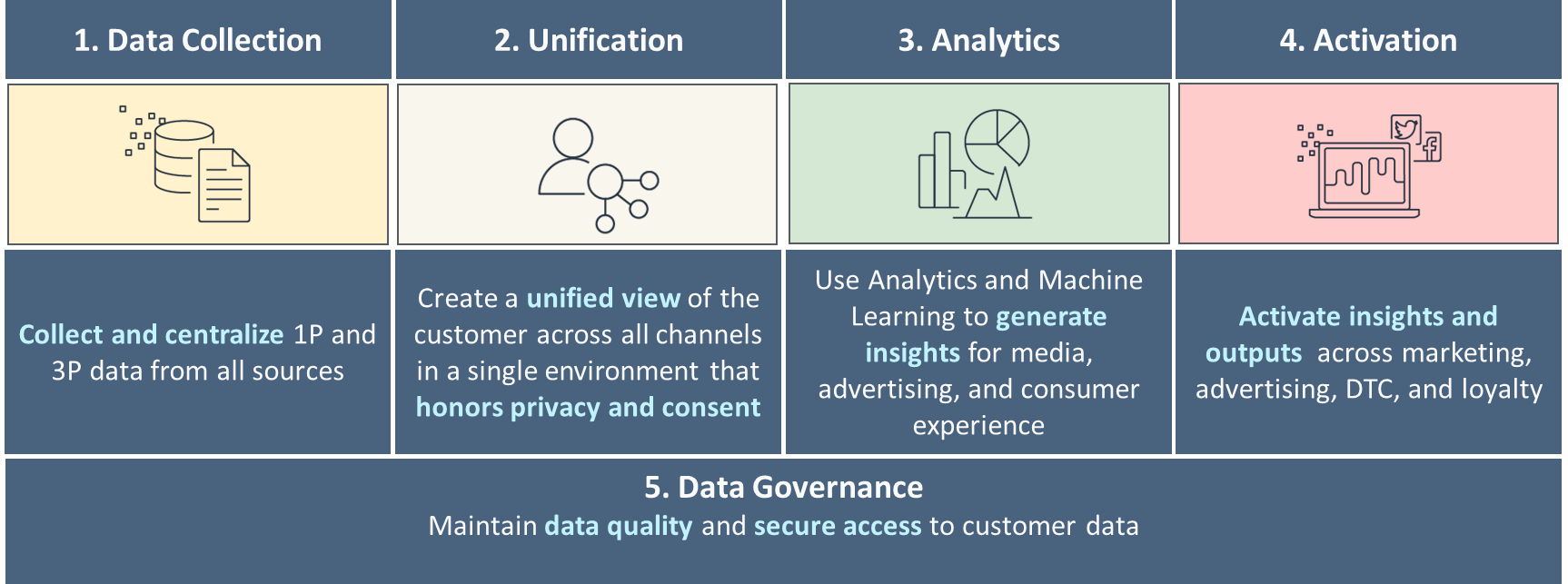
I cinque pilastri di una C360 matura
Quando inizi a creare un C360, lavori con più casi d'uso, tipi di dati dei clienti e utenti e applicazioni che richiedono strumenti diversi. Costruire un C360 sui set di dati giusti, aggiungere nuovi set di dati nel tempo mantenendo la qualità dei dati e mantenerli sicuri richiede una strategia dati end-to-end per i dati dei clienti. È inoltre necessario fornire strumenti che rendano semplice per i tuoi team creare prodotti che maturino il tuo C360.
Ti consigliamo di costruire la tua strategia dati attorno ai cinque pilastri di C360, come mostrato nella figura seguente. Si inizia con la raccolta di dati di base, unificando e collegando i dati provenienti da vari canali relativi a clienti unici, e si procede verso analisi di base e avanzate per il processo decisionale e un coinvolgimento personalizzato attraverso vari canali. Man mano che maturi in ciascuno di questi pilastri, progredisci verso la risposta ai segnali dei clienti in tempo reale.
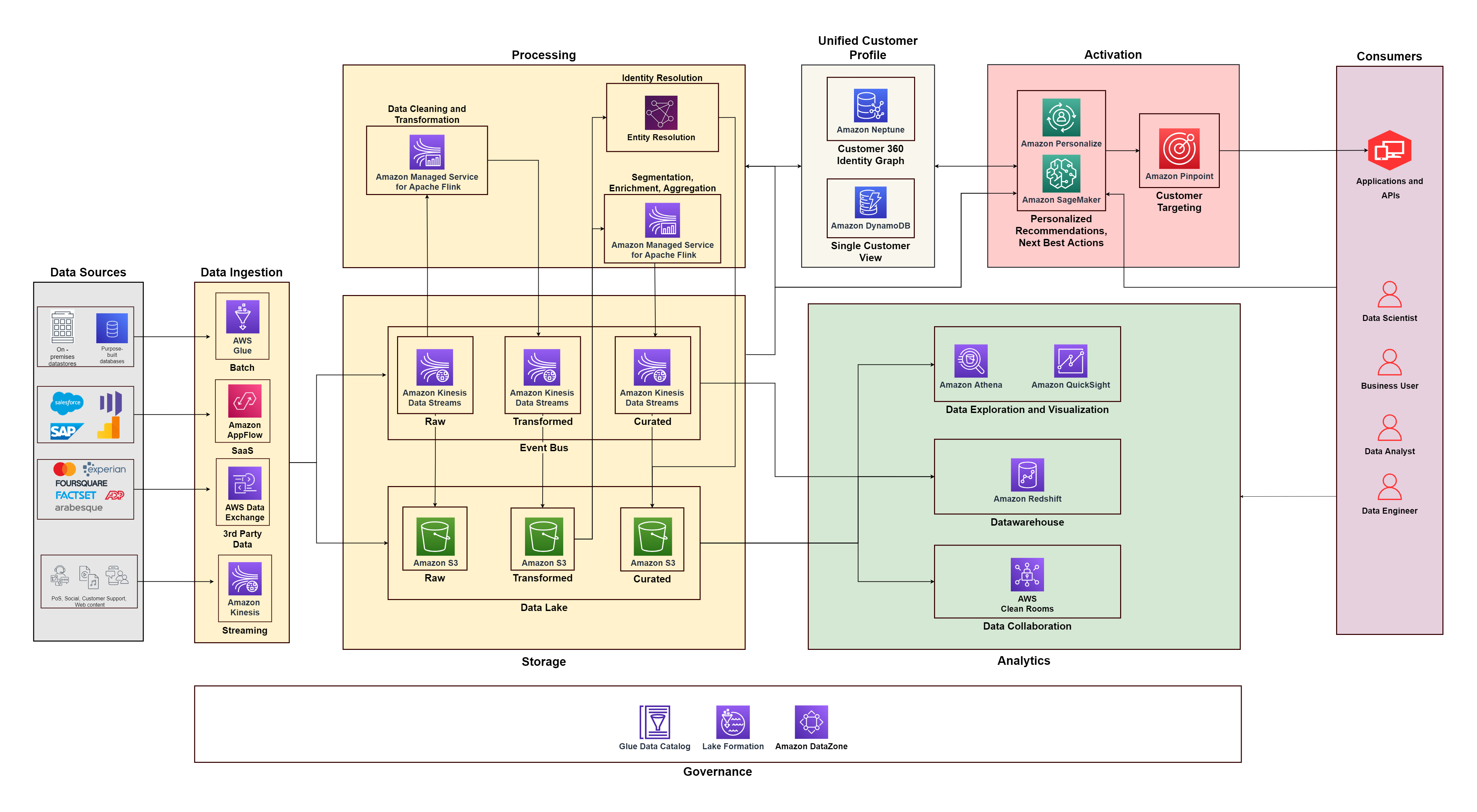
Il diagramma seguente illustra l'architettura funzionale che combina gli elementi costitutivi di a Piattaforma dati cliente su AWS con componenti aggiuntivi utilizzati per progettare una soluzione C360 end-to-end. Questo è in linea con i cinque pilastri di cui discutiamo in questo post.
Pilastro 1: raccolta dati
Quando inizi a costruire la tua piattaforma dati cliente, devi raccogliere dati da vari sistemi e punti di contatto, come i sistemi di vendita, l'assistenza clienti, il web e i social media e i mercati dei dati. Pensa al pilastro della raccolta dati come a una combinazione di capacità di acquisizione, archiviazione ed elaborazione.
Importazione dei dati
È necessario creare pipeline di acquisizione in base a fattori quali tipi di origini dati (archivi dati locali, file, applicazioni SaaS, dati di terze parti) e flusso di dati (flussi illimitati o dati batch). AWS fornisce diversi servizi per la creazione di pipeline di acquisizione dati:
- Colla AWS è un servizio di integrazione dei dati serverless che inserisce dati in batch da database locali e archivi dati nel cloud. Si connette a più di 70 origini dati e ti aiuta a creare pipeline di estrazione, trasformazione e caricamento (ETL) senza dover gestire l'infrastruttura della pipeline. Qualità dei dati di AWS Glue controlla e avvisa in caso di dati inadeguati, semplificando l'individuazione e la risoluzione dei problemi prima che danneggino la tua attività.
- Flusso di app Amazon acquisisce dati da applicazioni SaaS (Software as a Service) come Google Analytics, Salesforce, SAP e Marketo, offrendoti la flessibilità di acquisire dati da oltre 50 applicazioni SaaS.
- Scambio di dati AWS semplifica la ricerca, la sottoscrizione e l'utilizzo di dati di terze parti per l'analisi. Puoi abbonarti a prodotti di dati che aiutano ad arricchire i profili dei clienti, ad esempio dati demografici, dati pubblicitari e dati sui mercati finanziari.
- Cinesi amazzonica acquisisce eventi in streaming in tempo reale da sistemi di punti vendita, dati clickstream da app mobili e siti Web e dati di social media. Potresti anche considerare l'utilizzo Streaming gestito da Amazon per Apache Kafka (Amazon MSK) per lo streaming di eventi in tempo reale.
Il diagramma seguente illustra le diverse pipeline per acquisire dati da vari sistemi di origine utilizzando i servizi AWS.
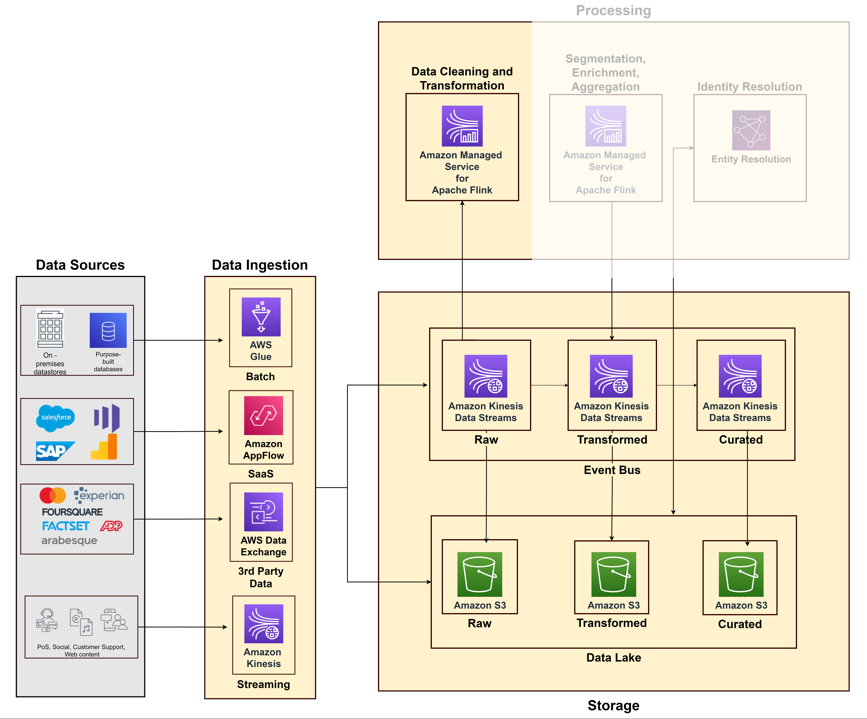
Archivio dati
I dati batch strutturati, semistrutturati o non strutturati vengono archiviati in uno storage di oggetti perché sono convenienti e durevoli. Servizio di archiviazione semplice Amazon (Amazon S3) è un servizio di archiviazione gestito con funzionalità di archiviazione con cui è possibile archiviare petabyte di dati undici 9 di durabilità. I dati in streaming con esigenze di bassa latenza vengono archiviati in Flussi di dati di Amazon Kinesis per il consumo in tempo reale. Ciò consente analisi e azioni immediate per vari consumatori a valle, come visto con il central di Riot Games Bus degli eventi antisommossa.
Elaborazione dei dati
I dati grezzi sono spesso ingombri di duplicati e formati irregolari. È necessario elaborarlo per renderlo pronto per l'analisi. Se stai consumando dati batch e dati in streaming, prendi in considerazione l'utilizzo di un framework in grado di gestirli entrambi. Un modello come il Architettura Kappa visualizza tutto come un flusso, semplificando le pipeline di elaborazione. Considera l'utilizzo Servizio gestito da Amazon per Apache Flink per gestire il lavoro di elaborazione. Con Managed Service per Apache Flink, puoi pulire e trasformare i dati di streaming e indirizzarli alla destinazione appropriata in base ai requisiti di latenza. È inoltre possibile implementare l'elaborazione dati batch utilizzando Amazon EMR su framework open source come Apache Spark con prestazioni 3.5 volte migliori rispetto alla versione autogestita. La decisione sull'architettura di utilizzare un sistema di elaborazione batch o streaming dipenderà da vari fattori; tuttavia, se desideri abilitare analisi in tempo reale sui dati dei tuoi clienti, ti consigliamo di utilizzare un modello di architettura Kappa.
Pilastro 2: Unificazione
Per collegare i diversi dati che arrivano da vari punti di contatto a un cliente unico, è necessario creare una soluzione di elaborazione delle identità che identifichi gli accessi anonimi, memorizzi informazioni utili sui clienti, li colleghi a dati esterni per informazioni migliori e raggruppi i clienti in domini di interesse. Sebbene la soluzione di elaborazione delle identità aiuti a creare il profilo cliente unificato, ti consigliamo di considerarlo come parte delle tue capacità di elaborazione dei dati. Il diagramma seguente illustra i componenti di tale soluzione.
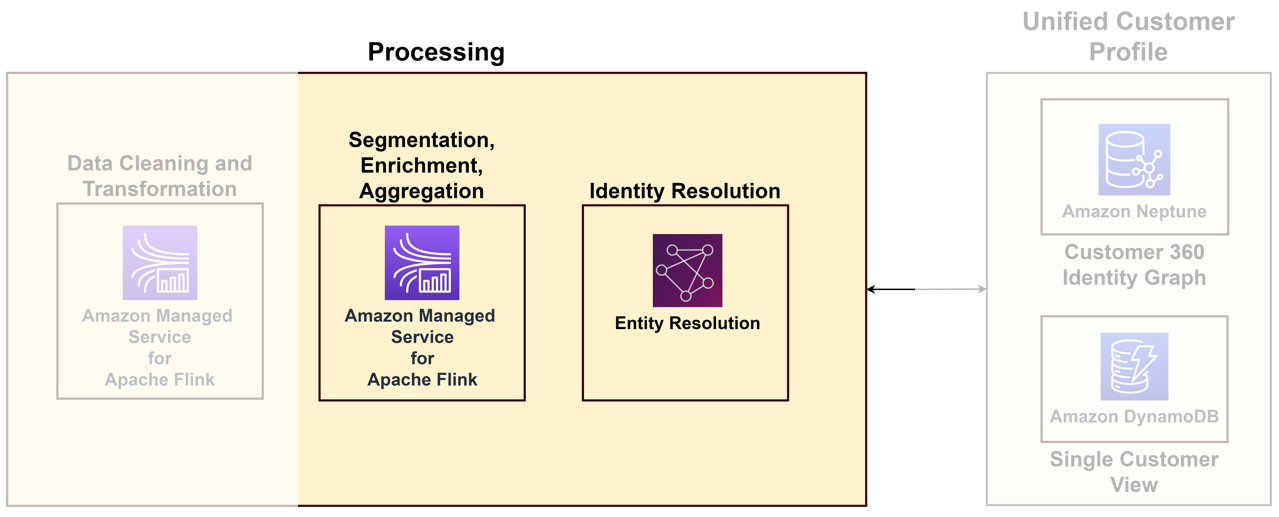
I componenti chiave sono i seguenti:
- Risoluzione dell'identità – La risoluzione dell'identità è una soluzione di deduplicazione, in cui i record vengono abbinati per identificare un cliente e potenziali clienti univoci collegando più identificatori come cookie, identificatori di dispositivo, indirizzi IP, ID e-mail e ID aziendali interni a una persona conosciuta o un profilo anonimo utilizzando la privacy- metodi conformi. Ciò può essere ottenuto utilizzando Risoluzione dell'entità AWS, che consente di utilizzare regole e tecniche di machine learning (ML). abbinare i record e risolvere le identità. In alternativa, puoi costruire grafici di identità utilizzando Amazon Nettuno per un'unica visione unificata dei tuoi clienti.
- Aggregazione dei profili – Quando hai identificato in modo univoco un cliente, puoi farlo creare applicazioni in Managed Service per Apache Flink per consolidare tutti i loro metadati, dal nome alla cronologia delle interazioni. Quindi, trasformi questi dati in un formato conciso. Invece di mostrare tutti i dettagli della transazione, puoi offrire un valore di spesa aggregato e un collegamento al record CRM (Customer Relationship Management). Per le interazioni con il servizio clienti, fornisci un punteggio CSAT medio e un collegamento al sistema del call center per un'analisi più approfondita della cronologia delle comunicazioni.
- Arricchimento del profilo – Dopo aver assegnato un cliente a una singola identità, migliora il suo profilo utilizzando varie origini dati. L'arricchimento in genere comporta l'aggiunta di dati demografici, comportamentali e di geolocalizzazione. Puoi usare prodotti dati di terze parti da AWS Marketplace forniti tramite AWS Data Exchange per ottenere informazioni dettagliate su reddito, modelli di consumo, punteggi di rischio di credito e molte altre dimensioni per perfezionare ulteriormente l'esperienza del cliente.
- Segmentazione del cliente – Dopo aver identificato e arricchito in modo univoco il profilo di un cliente, puoi segmentarlo in base a dati demografici quali età, spesa, reddito e posizione utilizzando le applicazioni in Managed Service per Apache Flink. Man mano che avanzi, puoi incorporare Servizi di intelligenza artificiale per tecniche di targeting più precise.
Dopo aver eseguito l'elaborazione e la segmentazione dell'identità, è necessaria una capacità di archiviazione per archiviare il profilo cliente univoco e fornire funzionalità di ricerca e query su di esso affinché i consumatori a valle possano utilizzare i dati arricchiti dei clienti.
Il diagramma seguente illustra il pilastro di unificazione per un profilo cliente unificato e una visione unica del cliente per le applicazioni a valle.
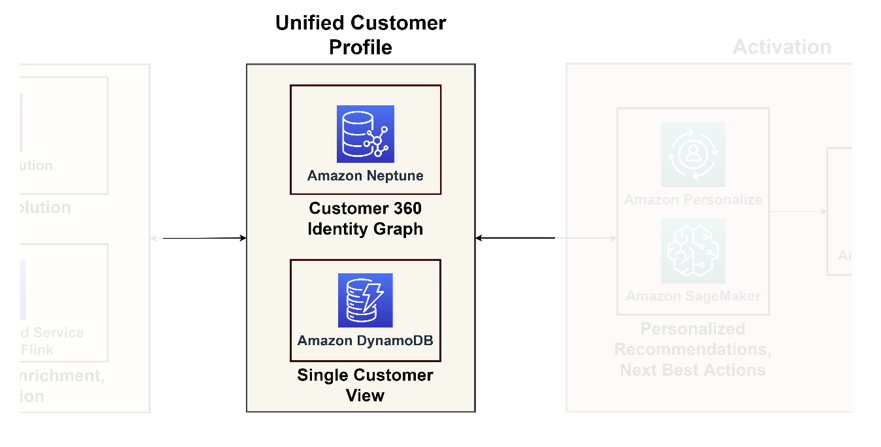
Profilo cliente unificato
I database grafici eccellono nella modellazione delle interazioni e delle relazioni con i clienti, offrendo una visione completa del percorso del cliente. Se hai a che fare con miliardi di profili e interazioni, puoi prendere in considerazione l'utilizzo di Neptune, un servizio di database a grafo gestito su AWS. Organizzazioni come Zeta ed Activision hanno utilizzato con successo Neptune per archiviare ed eseguire query su miliardi di identificatori univoci al mese e milioni di query al secondo con tempi di risposta millisecondi.
Vista cliente singolo
Sebbene i database a grafo forniscano approfondimenti approfonditi, possono tuttavia risultare complessi per le normali applicazioni. È prudente consolidare questi dati in un’unica visione del cliente, fungendo da riferimento primario per le applicazioni a valle, che vanno dalle piattaforme di e-commerce ai sistemi CRM. Questa visione consolidata funge da collegamento tra la piattaforma dati e le applicazioni incentrate sul cliente. Per tali scopi, si consiglia di utilizzare Amazon DynamoDB per la sua adattabilità, scalabilità e prestazioni, risultando in un database clienti aggiornato ed efficiente. Questo database accetterà molte richieste di scrittura dai sistemi di attivazione che apprendono nuove informazioni sui clienti e le restituiscono.
Pilastro 3: Analisi
Il pilastro dell'analisi definisce le funzionalità che ti aiutano a generare approfondimenti sui dati dei tuoi clienti. La tua strategia di analisi si applica alle esigenze organizzative più ampie, non solo a C360. Puoi utilizzare le stesse funzionalità per fornire report finanziari, misurare le prestazioni operative o persino monetizzare le risorse di dati. Stabilisci la strategia in base al modo in cui i tuoi team esplorano i dati, eseguono analisi, discutono i dati per i requisiti a valle e visualizzano i dati a diversi livelli. Pianifica come consentire ai tuoi team di utilizzare il machine learning per passare dall'analisi descrittiva a quella prescrittiva.
I Architettura moderna dei dati AWS mostra un modo per creare una piattaforma dati su misura, sicura e scalabile nel cloud. Impara da questo per creare funzionalità di query nel tuo data Lake e nel data warehouse.
Il diagramma seguente suddivide la funzionalità di analisi in esplorazione dei dati, visualizzazione, data warehousing e collaborazione dei dati. Scopriamo quale ruolo gioca ciascuno di questi componenti nel contesto di C360.

Esplorazione dei dati
L'esplorazione dei dati aiuta a scoprire incoerenze, valori anomali o errori. Individuandoli in anticipo, i tuoi team possono ottenere un'integrazione dei dati più pulita per C360, che a sua volta porta ad analisi e previsioni più accurate. Considera le persone che esplorano i dati, le loro competenze tecniche e il tempo dedicato all'analisi. Ad esempio, gli analisti di dati che sanno scrivere SQL possono eseguire query direttamente sui dati che risiedono in Amazon S3 utilizzando Amazzone Atena. Gli utenti interessati all'esplorazione visiva possono farlo utilizzando DataBrew di AWS Glue. I data scientist o gli ingegneri possono utilizzare Amazon EMR Studio or Amazon Sage Maker Studio per esplorare i dati dal notebook e per un'esperienza a basso codice, puoi utilizzare Gestore di dati di Amazon SageMaker. Poiché questi servizi interrogano direttamente i bucket S3, puoi esplorare i dati non appena arrivano nel data Lake, riducendo i tempi di acquisizione delle informazioni.
Visualizzazione
Trasformare set di dati complessi in elementi visivi intuitivi svela modelli nascosti nei dati ed è fondamentale per i casi d'uso di C360. Con questa funzionalità, puoi progettare report per diversi livelli in grado di soddisfare esigenze diverse: report esecutivi che offrono panoramiche strategiche, report gestionali che evidenziano metriche operative e report dettagliati che approfondiscono le specifiche. Tale chiarezza visiva aiuta la tua organizzazione a prendere decisioni informate a tutti i livelli, centralizzando la prospettiva del cliente.
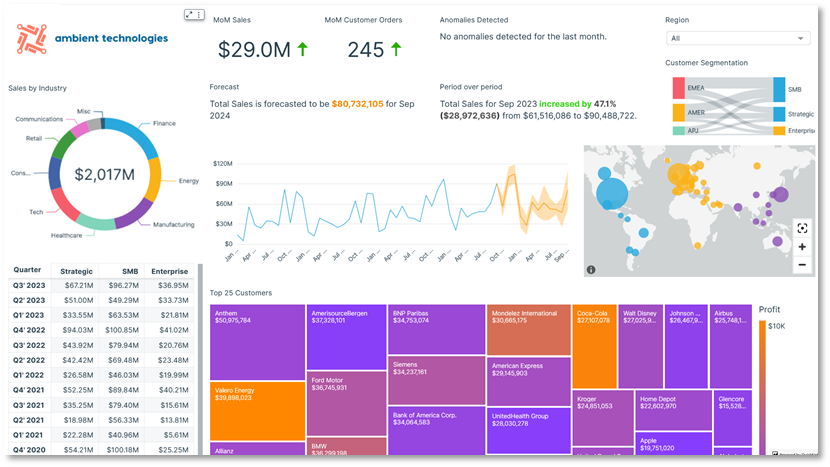
Il diagramma seguente mostra un dashboard C360 di esempio integrato Amazon QuickSight. QuickSight offre funzionalità di visualizzazione scalabili e senza server. Puoi trarre vantaggio dalle sue integrazioni ML per approfondimenti automatizzati come previsioni e rilevamento di anomalie o query in linguaggio naturale Amazon Q in QuickSight, connettività diretta dei dati da varie fonti e tariffazione a sessione. Con QuickSight puoi incorporare dashboard in siti Web e applicazioni esterne, e il SPEZIA Il motore consente una visualizzazione dei dati rapida e interattiva su larga scala. Lo screenshot seguente mostra un esempio di dashboard C360 basato su QuickSight.
Data warehouse
I data warehouse sono efficienti nel consolidare dati strutturati provenienti da molteplici fonti e nel servire query di analisi da un gran numero di utenti simultanei. I data warehouse possono fornire una visione unificata e coerente di una grande quantità di dati dei clienti per i casi d'uso di C360. Amazon RedShift risponde a questa esigenza gestendo abilmente grandi volumi di dati e carichi di lavoro diversificati. Fornisce una forte coerenza tra i set di dati, consentendo alle organizzazioni di ricavare informazioni affidabili e complete sui propri clienti, il che è essenziale per un processo decisionale informato. Amazon Redshift offre insight in tempo reale e funzionalità di analisi predittiva per analizzare dati da terabyte a petabyte. Con Amazon RedshiftML, puoi incorporare il machine learning sui dati archiviati nel data warehouse con un sovraccarico di sviluppo minimo. Amazon Redshift senza server semplifica la creazione di applicazioni e rende semplice per le aziende incorporare funzionalità di analisi dei dati avanzate.
Collaborazione sui dati
Puoi in tutta sicurezza collaborare e analizzare set di dati collettivi dai tuoi partner senza condividere o copiare i dati sottostanti degli altri utilizzando Camere bianche AWS. Puoi riunire dati disparati provenienti da diversi canali di coinvolgimento e set di dati dei partner per formare una visione a 360 gradi dei tuoi clienti. AWS Clean Rooms può migliorare C360 consentendo casi d'uso come l'ottimizzazione del marketing multicanale, la segmentazione avanzata dei clienti e la personalizzazione conforme alla privacy. Unendo in modo sicuro i set di dati, offre insight più ricchi e una solida privacy dei dati, soddisfacendo le esigenze aziendali e gli standard normativi.
Pilastro 4: Attivazione
Il valore dei dati diminuisce man mano che invecchiano, determinando nel tempo costi opportunità più elevati. In un sondaggio condotto da Intersystems, il 75% delle organizzazioni intervistate ritiene che i dati intempestivi abbiano inibito le opportunità di business. In un altro sondaggio, 58% di organizzazioni (su 560 intervistati del comitato consultivo e dei lettori di HBR) hanno dichiarato di aver notato un aumento nella fidelizzazione e nella fedeltà dei clienti utilizzando l'analisi dei clienti in tempo reale.
Puoi raggiungere la maturità in C360 quando sviluppi la capacità di agire in tempo reale su tutte le informazioni acquisite dai pilastri precedenti di cui abbiamo discusso. Ad esempio, a questo livello di maturità, puoi agire in base al sentiment del cliente in base al contesto derivato automaticamente con un profilo cliente arricchito e canali integrati. Per questo è necessario implementare un processo decisionale prescrittivo su come affrontare il sentiment del cliente. Per fare ciò su larga scala, è necessario utilizzare i servizi AI/ML per il processo decisionale. Il diagramma seguente illustra l'architettura per attivare gli insight utilizzando il machine learning per l'analisi prescrittiva e i servizi di intelligenza artificiale per il targeting e la segmentazione.
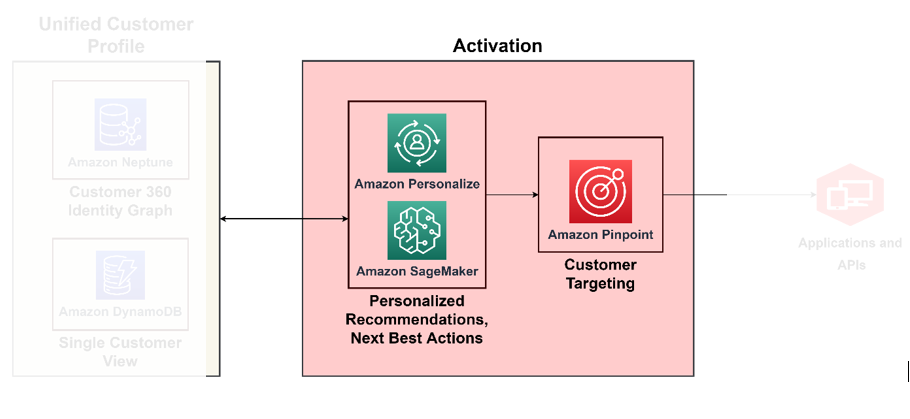
Utilizza il machine learning come motore decisionale
Con il machine learning puoi migliorare l'esperienza complessiva del cliente: puoi creare modelli predittivi di comportamento dei clienti, progettare offerte iper-personalizzate e indirizzare il cliente giusto con il giusto incentivo. Puoi costruirli usando Amazon Sage Maker, che presenta una suite di servizi gestiti mappati al ciclo di vita della scienza dei dati, tra cui wrangling dei dati, addestramento dei modelli, hosting dei modelli, inferenza dei modelli, rilevamento della deriva dei modelli e archiviazione delle funzionalità. SageMaker ti consente di farlo costruisci e rendi operativi i tuoi modelli ML, reintegrandoli nelle tue applicazioni per produrre le informazioni giuste per la persona giusta al momento giusto.
Amazon Personalizza supporta consigli contestuali, attraverso i quali è possibile migliorare la pertinenza dei consigli generandoli all'interno di un contesto, ad esempio tipo di dispositivo, posizione o ora del giorno. Il tuo team può iniziare senza alcuna esperienza precedente nel machine learning utilizzando le API per creare sofisticate funzionalità di personalizzazione in pochi clic. Per ulteriori informazioni, vedere Personalizza i tuoi consigli promuovendo articoli specifici utilizzando le regole aziendali con Amazon Personalize.
Attiva canali di marketing, pubblicità, direct-to-consumer e fidelizzazione
Ora che sai chi sono i tuoi clienti e a chi rivolgerti, puoi creare soluzioni per eseguire campagne di targeting su larga scala. Con Pinpoint Amazon, puoi personalizzare e segmentare le comunicazioni per coinvolgere i clienti su più canali. Ad esempio, puoi utilizzare Amazon Pinpoint per creare esperienze cliente coinvolgenti attraverso vari canali di comunicazione come e-mail, SMS, notifiche push e notifiche in-app.
Pilastro 5: governance dei dati
Stabilire la giusta governance che bilancia controllo e accesso offre agli utenti fiducia e sicurezza nei dati. Immagina di offrire promozioni su prodotti di cui un cliente non ha bisogno o di bombardare i clienti sbagliati con notifiche. Una scarsa qualità dei dati può portare a tali situazioni e, in definitiva, comportare l’abbandono dei clienti. È necessario creare processi che convalidino la qualità dei dati e intraprendano azioni correttive. Qualità dei dati di AWS Glue può aiutarti a creare soluzioni che convalidano la qualità dei dati inattivi e in transito, sulla base di regole predefinite.
Per impostare una struttura di governance interfunzionale per i dati dei clienti, è necessaria la capacità di governare e condividere i dati all'interno dell'organizzazione. Con Amazon DataZone, gli amministratori e gli steward dei dati possono gestire e governare l'accesso ai dati, mentre i consumatori come data engineer, data scientist, product manager, analisti e altri utenti aziendali possono scoprire, utilizzare e collaborare con tali dati per ottenere insight. Semplifica l'accesso ai dati, consentendoti di trovare e utilizzare i dati dei clienti, promuove la collaborazione del team con risorse di dati condivise e fornisce analisi personalizzate tramite un'app Web o un'API su un portale. Formazione AWS Lake garantisce che l'accesso ai dati sia sicuro, garantendo che le persone giuste vedano i dati giusti per le ragioni giuste, il che è fondamentale per un'efficace governance interfunzionale in qualsiasi organizzazione. I metadati aziendali vengono archiviati e gestiti da Amazon DataZone, che è supportato da metadati tecnici e informazioni sullo schema, registrati nel Catalogo dati di AWS Glue. Questi metadati tecnici vengono utilizzati anche da altri servizi di governance come Lake Formation e Amazon DataZone, e da servizi di analisi come Amazon Redshift, Athena e AWS Glue.

Mettere tutto insieme
Utilizzando il diagramma seguente come riferimento, puoi creare progetti e team per creare e gestire funzionalità diverse. Ad esempio, puoi fare in modo che un team di integrazione dei dati si concentri sul pilastro della raccolta dati, in modo da allineare i ruoli funzionali, come architetti e ingegneri dei dati. Puoi sviluppare le tue pratiche di analisi e scienza dei dati per concentrarti rispettivamente sui pilastri di analisi e attivazione. Quindi puoi creare un team specializzato per l'elaborazione dell'identità del cliente e per costruire una visione unificata del cliente. Puoi creare un team di governance dei dati con amministratori dei dati di diverse funzioni, amministratori della sicurezza e responsabili delle politiche di governance dei dati per progettare e automatizzare le policy.
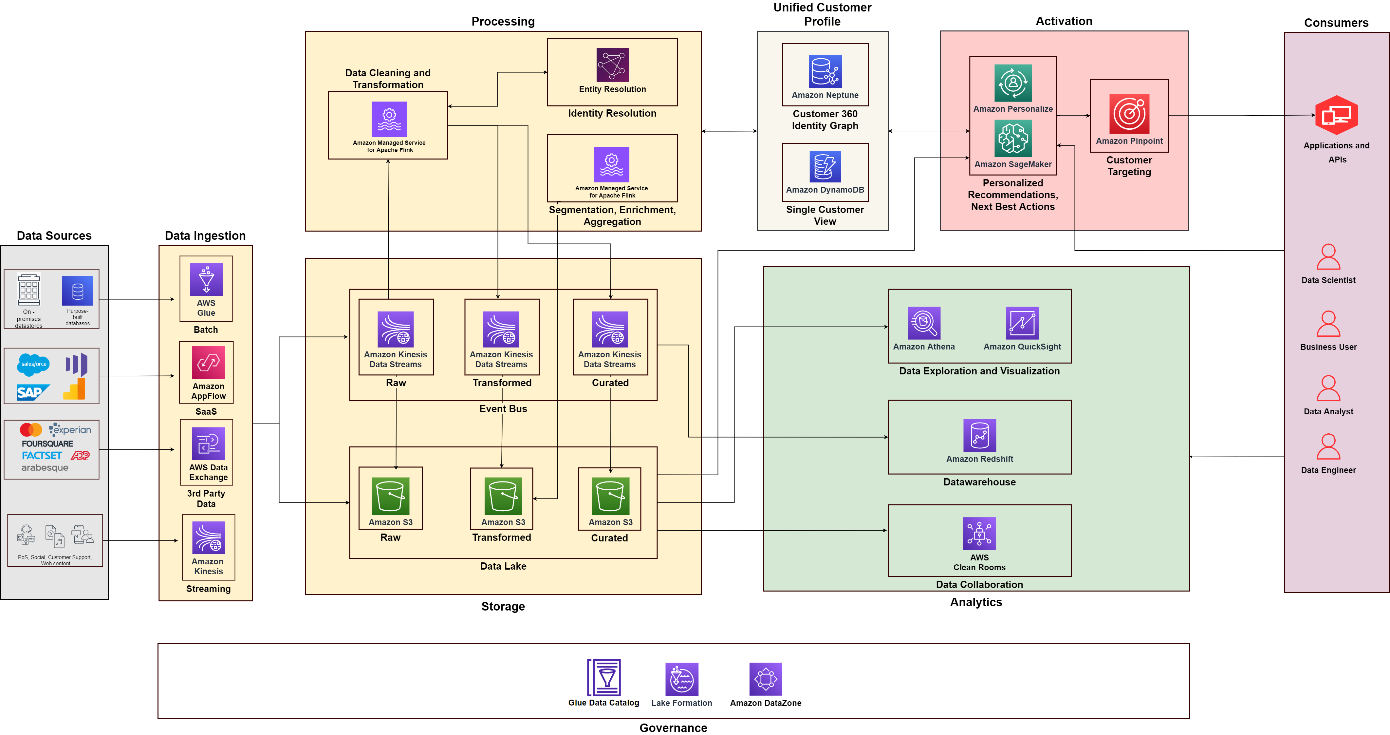
Conclusione
Costruire una solida funzionalità C360 è fondamentale per la tua organizzazione per ottenere informazioni approfondite sulla tua base di clienti. I servizi di database, analisi e AI/ML di AWS possono contribuire a semplificare questo processo, garantendo scalabilità ed efficienza. Seguendo i cinque pilastri che guidano il tuo pensiero, puoi costruire una strategia dei dati end-to-end che definisca la visione di C360 in tutta l'organizzazione, assicuri che i dati siano accurati e stabilisca una governance interfunzionale per i dati dei clienti. Puoi classificare e dare priorità ai prodotti e alle funzionalità che devi sviluppare all'interno di ciascun pilastro, selezionare lo strumento giusto per il lavoro e sviluppare le competenze di cui hai bisogno nei tuoi team.
Visita AWS per i dati Storie dei clienti per scoprire come AWS sta trasformando il percorso dei clienti, dalle più grandi imprese del mondo alle startup in crescita.
Informazioni sugli autori
 Ismail Makhlouf è un Senior Specialist Solutions Architect per l'analisi dei dati presso AWS. Ismail si concentra sull'architettura di soluzioni per le organizzazioni in tutto il loro patrimonio di analisi dei dati end-to-end, inclusi streaming batch e in tempo reale, big data, data warehousing e carichi di lavoro data lake. Lavora principalmente con organizzazioni nei settori della vendita al dettaglio, dell'e-commerce, della tecnologia finanziaria, della tecnologia sanitaria e dei viaggi per raggiungere i propri obiettivi aziendali con piattaforme dati ben architettate.
Ismail Makhlouf è un Senior Specialist Solutions Architect per l'analisi dei dati presso AWS. Ismail si concentra sull'architettura di soluzioni per le organizzazioni in tutto il loro patrimonio di analisi dei dati end-to-end, inclusi streaming batch e in tempo reale, big data, data warehousing e carichi di lavoro data lake. Lavora principalmente con organizzazioni nei settori della vendita al dettaglio, dell'e-commerce, della tecnologia finanziaria, della tecnologia sanitaria e dei viaggi per raggiungere i propri obiettivi aziendali con piattaforme dati ben architettate.
 Sandipan Bhaumik (Sandi) è un Senior Analytics Specialist Solutions Architect presso AWS. Aiuta i clienti a modernizzare le proprie piattaforme dati nel cloud per eseguire analisi in modo sicuro su larga scala, ridurre i costi operativi e ottimizzare l'utilizzo per efficienza in termini di costi e sostenibilità.
Sandipan Bhaumik (Sandi) è un Senior Analytics Specialist Solutions Architect presso AWS. Aiuta i clienti a modernizzare le proprie piattaforme dati nel cloud per eseguire analisi in modo sicuro su larga scala, ridurre i costi operativi e ottimizzare l'utilizzo per efficienza in termini di costi e sostenibilità.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/create-an-end-to-end-data-strategy-for-customer-360-on-aws/

