Questo post è stato scritto in collaborazione con Jayadeep Pabbistty, Sr. Specialist Data Engineering presso Merck, e Prabakaran Mathaiyan, Sr. ML Engineer presso Tiger Analytics.
L'ampio ciclo di vita dello sviluppo di modelli di machine learning (ML) richiede un processo di rilascio del modello scalabile simile a quello dello sviluppo del software. Gli sviluppatori di modelli spesso lavorano insieme nello sviluppo di modelli ML e necessitano di una solida piattaforma MLOps su cui lavorare. Una piattaforma MLOps scalabile deve includere un processo per gestire il flusso di lavoro del registro, dell'approvazione e della promozione del modello ML al livello di ambiente successivo (sviluppo, test , UAT o produzione).
Uno sviluppatore di modelli in genere inizia a lavorare in un ambiente di sviluppo ML individuale all'interno Amazon Sage Maker. Quando un modello è addestrato e pronto per essere utilizzato, deve essere approvato dopo essere stato registrato nel Registro dei modelli di Amazon SageMaker. In questo post, discutiamo di come il team AI/ML di AWS ha collaborato con il team IT MLOps di Merck Human Health per creare una soluzione che utilizza un flusso di lavoro automatizzato per l'approvazione e la promozione del modello ML con l'intervento umano nel mezzo.
Panoramica della soluzione
Questo post si concentra su una soluzione del flusso di lavoro che il ciclo di vita di sviluppo del modello ML può utilizzare tra la pipeline di training e la pipeline di inferenza. La soluzione fornisce un flusso di lavoro scalabile per MLOps nel supportare il processo di approvazione e promozione del modello ML con l'intervento umano. Un modello ML registrato da un data scientist necessita della revisione e dell'approvazione di un approvatore prima di essere utilizzato per una pipeline di inferenza e nel livello di ambiente successivo (test, UAT o produzione). La soluzione utilizza AWS Lambda, Gateway API Amazon, Amazon EventBridgee SageMaker per automatizzare il flusso di lavoro con l'intervento di approvazione umana nel mezzo. Il seguente diagramma dell'architettura mostra la progettazione complessiva del sistema, i servizi AWS utilizzati e il flusso di lavoro per l'approvazione e la promozione dei modelli ML con l'intervento umano dallo sviluppo alla produzione.
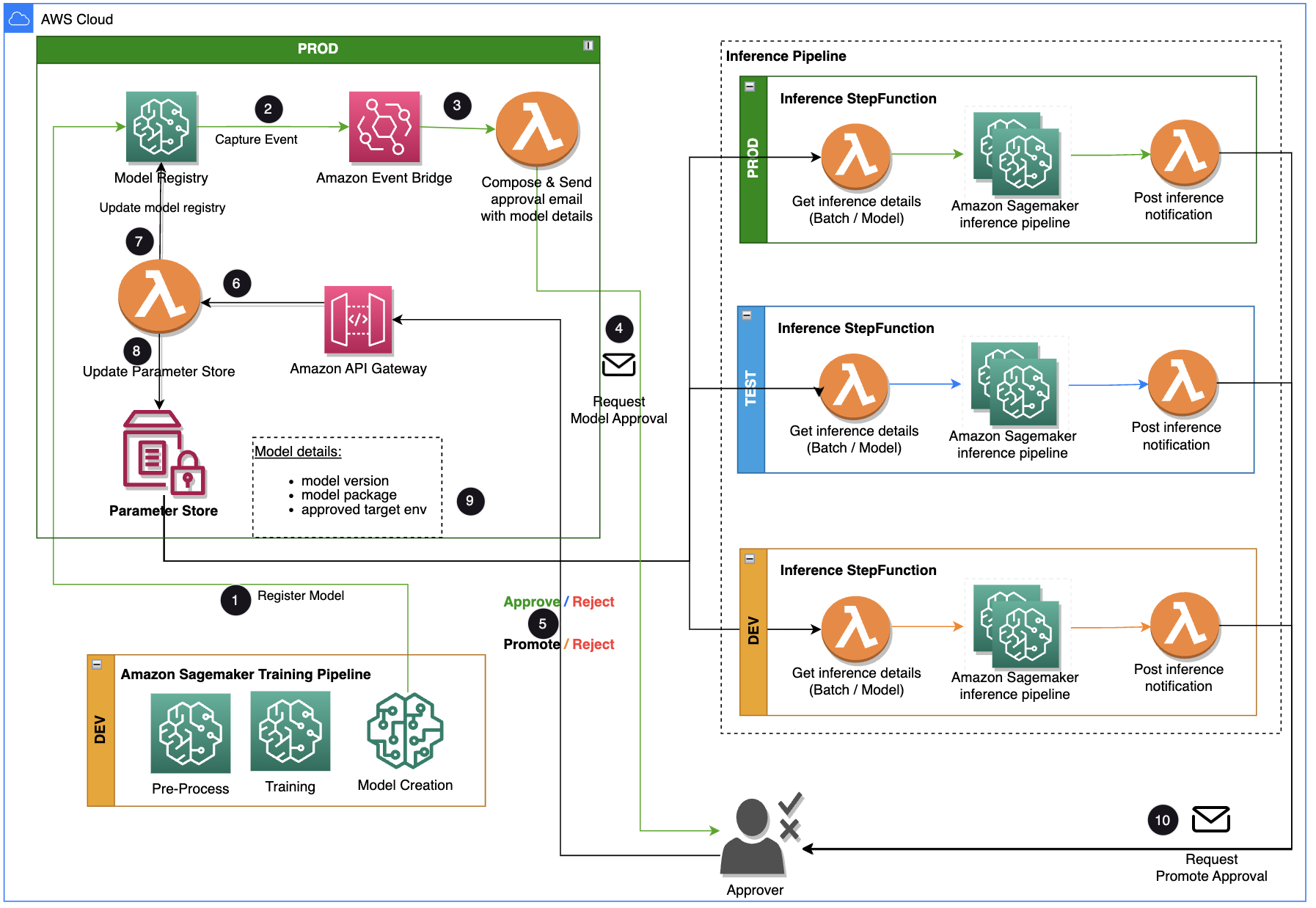
Il flusso di lavoro include i seguenti passaggi:
- La pipeline di training sviluppa e registra un modello nel registro dei modelli SageMaker. A questo punto lo status del modello è
PendingManualApproval. - EventBridge monitora gli eventi di modifica dello stato per intraprendere automaticamente azioni con regole semplici.
- La regola dell'evento di registrazione del modello EventBridge richiama una funzione Lambda che crea un'e-mail con un collegamento per approvare o rifiutare il modello registrato.
- L'approvatore riceve un'e-mail con il collegamento per rivedere e approvare o rifiutare il modello.
- L'approvatore approva il modello seguendo il collegamento nell'e-mail a un endpoint API Gateway.
- API Gateway richiama una funzione Lambda per avviare gli aggiornamenti del modello.
- Il registro del modello viene aggiornato per lo stato del modello (
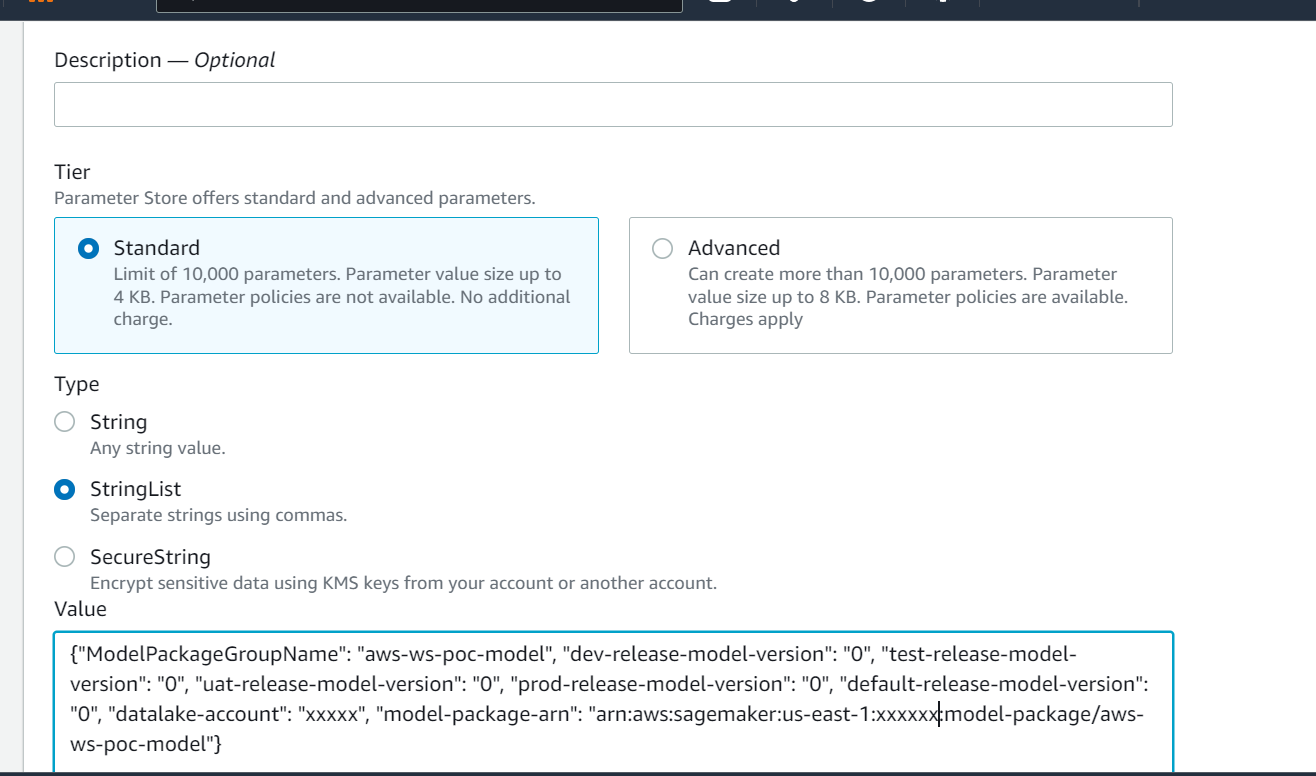
Approvedper l'ambiente di sviluppo, maPendingManualApprovalper test, UAT e produzione). - I dettagli del modello sono memorizzati in Archivio parametri AWS, una capacità di Gestore di sistemi AWS, inclusa la versione del modello, l'ambiente di destinazione approvato, il pacchetto del modello.
- La pipeline di inferenza recupera il modello approvato per l'ambiente di destinazione da Parameter Store.
- La funzione Lambda di notifica post-inferenza raccoglie i parametri di inferenza batch e invia un'e-mail all'approvatore per promuovere il modello nell'ambiente successivo.
Prerequisiti
Il flusso di lavoro in questo post presuppone che l'ambiente per la pipeline di formazione sia configurato in SageMaker, insieme ad altre risorse. L'input per la pipeline di training è il set di dati delle funzionalità. I dettagli sulla generazione delle funzionalità non sono inclusi in questo post, ma si concentra sul registro, sull'approvazione e sulla promozione dei modelli ML dopo che sono stati addestrati. Il modello è registrato nel registro dei modelli ed è regolato da un quadro di monitoraggio in Monitor modello Amazon SageMaker per rilevare eventuali derive e procedere alla riqualificazione in caso di deriva del modello.
Dettagli del flusso di lavoro
Il flusso di lavoro di approvazione inizia con un modello sviluppato da una pipeline di formazione. Quando i data scientist sviluppano un modello, lo registrano nel registro dei modelli SageMaker con lo stato del modello di PendingManualApproval. EventBridge monitora SageMaker per l'evento di registrazione del modello e attiva una regola evento che richiama una funzione Lambda. La funzione Lambda costruisce dinamicamente un'e-mail per l'approvazione del modello con un collegamento a un endpoint API Gateway a un'altra funzione Lambda. Quando l'approvatore segue il collegamento per approvare il modello, API Gateway inoltra l'azione di approvazione alla funzione Lambda, che aggiorna il registro dei modelli SageMaker e gli attributi del modello in Parameter Store. L'approvatore deve essere autenticato e far parte del gruppo di approvatori gestito da Active Directory. L'approvazione iniziale contrassegna il modello come Approved per sviluppatore ma PendingManualApproval per test, UAT e produzione. Gli attributi del modello salvati in Archivio parametri includono la versione del modello, il pacchetto del modello e l'ambiente di destinazione approvato.
Quando una pipeline di inferenza deve recuperare un modello, controlla l'archivio parametri per la versione più recente del modello approvata per l'ambiente di destinazione e ottiene i dettagli dell'inferenza. Una volta completata la pipeline di inferenza, viene inviata un'e-mail di notifica post-inferenza a una parte interessata che richiede l'approvazione per promuovere il modello al livello di ambiente successivo. L'e-mail contiene i dettagli sul modello e sui parametri, nonché un collegamento di approvazione a un endpoint API Gateway per una funzione Lambda che aggiorna gli attributi del modello.
Di seguito è riportata la sequenza di eventi e passaggi di implementazione per il flusso di lavoro di approvazione/promozione del modello ML dalla creazione del modello alla produzione. Il modello viene promosso dallo sviluppo agli ambienti di test, UAT e produzione con un'esplicita approvazione umana in ogni fase.
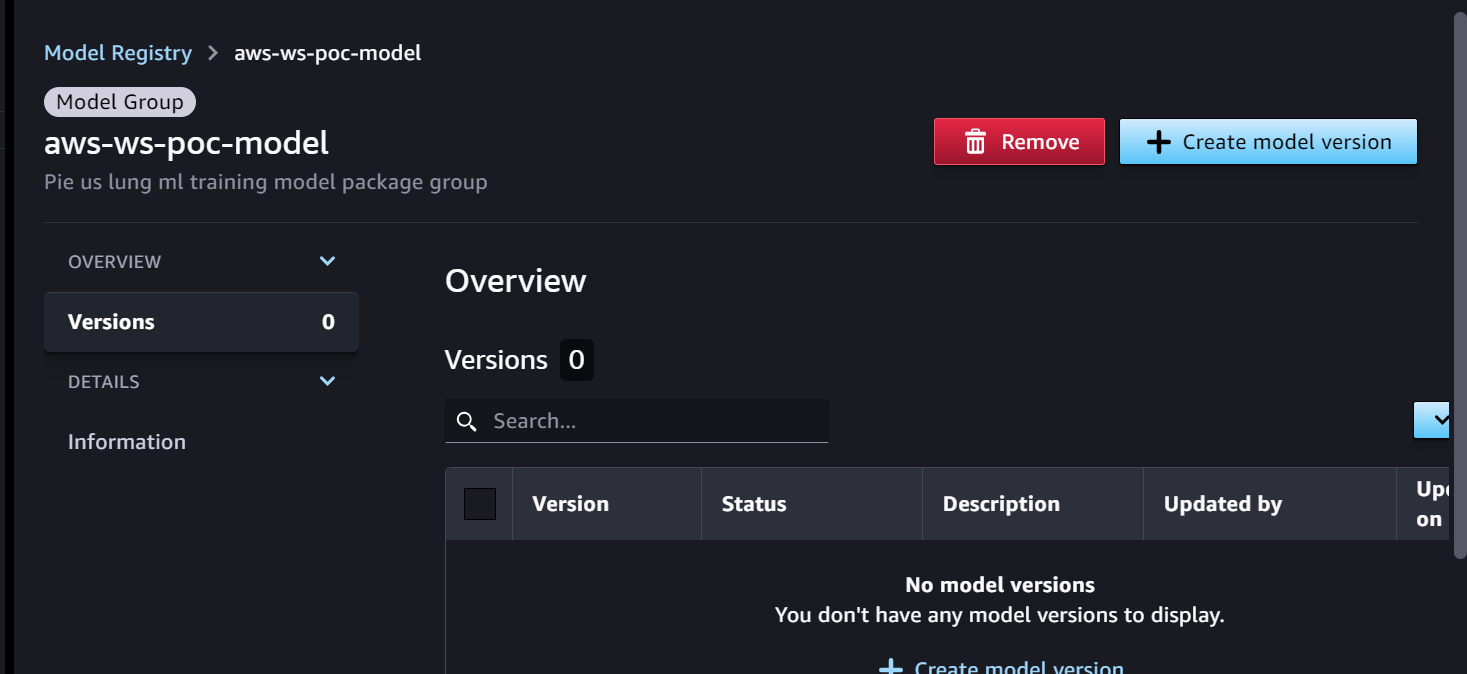
Iniziamo con la pipeline di formazione, pronta per lo sviluppo del modello. La versione del modello inizia come 0 nel registro dei modelli SageMaker.
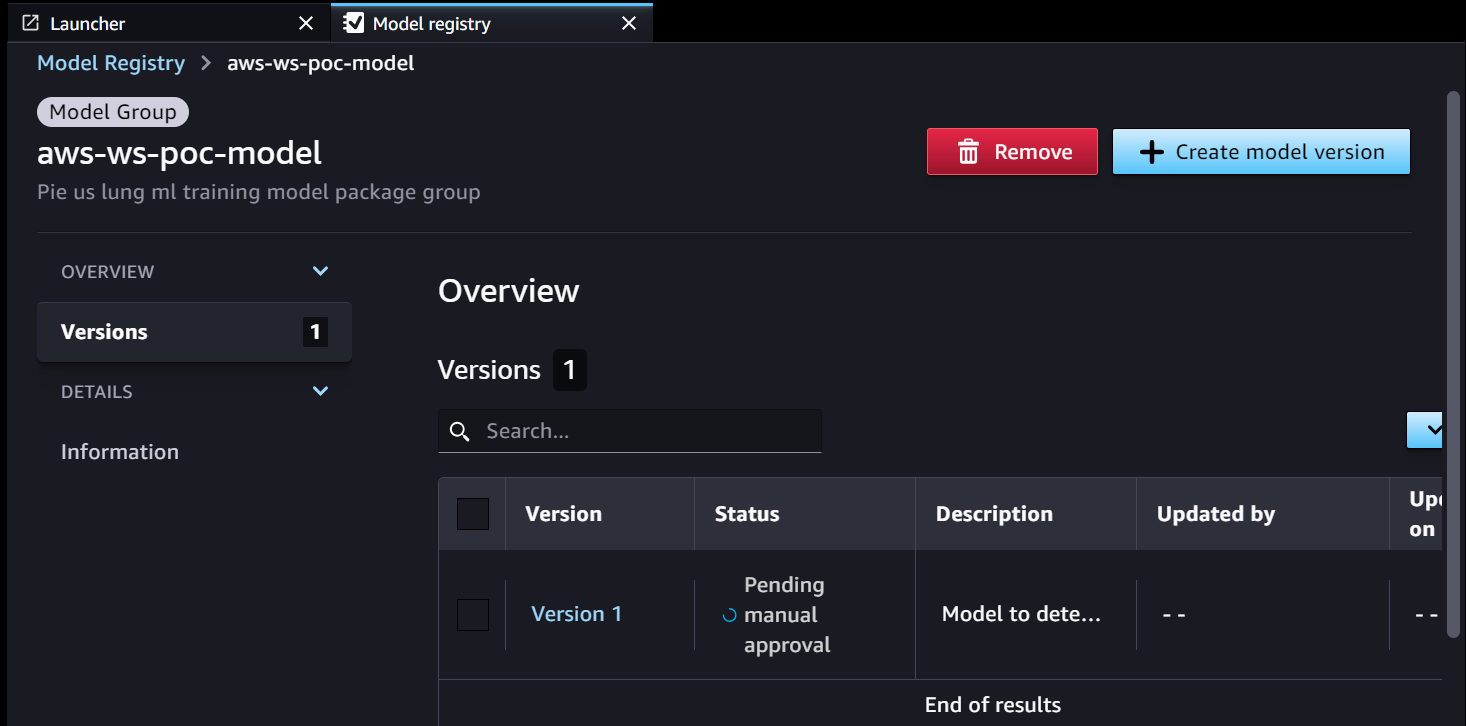
- La pipeline di formazione SageMaker sviluppa e registra un modello in SageMaker Model Registry. La versione 1 del modello è registrata e inizia con In attesa di approvazione manuale stato.
 I metadati del registro del modello hanno quattro campi personalizzati per gli ambienti:
I metadati del registro del modello hanno quattro campi personalizzati per gli ambienti: dev, test, uateprod.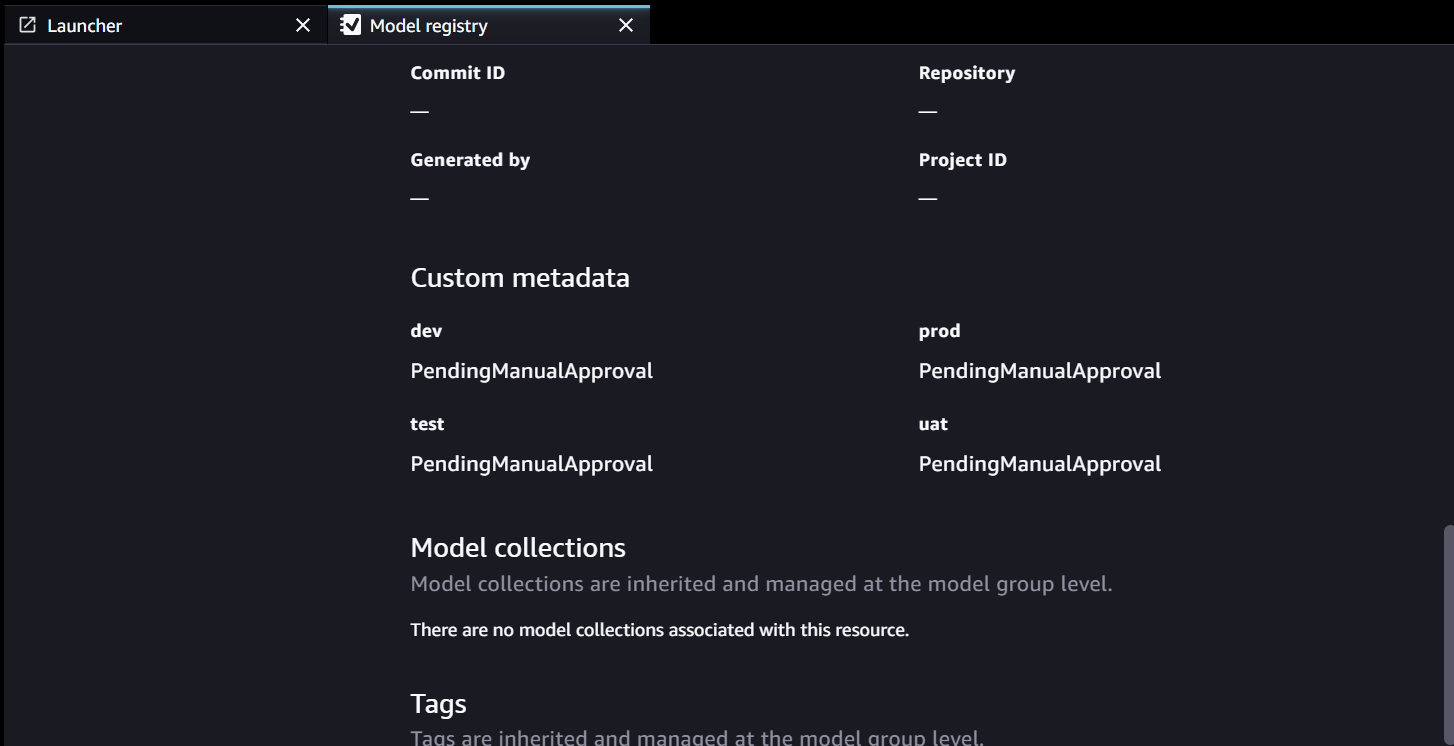
- EventBridge monitora il registro dei modelli SageMaker per la modifica dello stato per agire automaticamente con regole semplici.
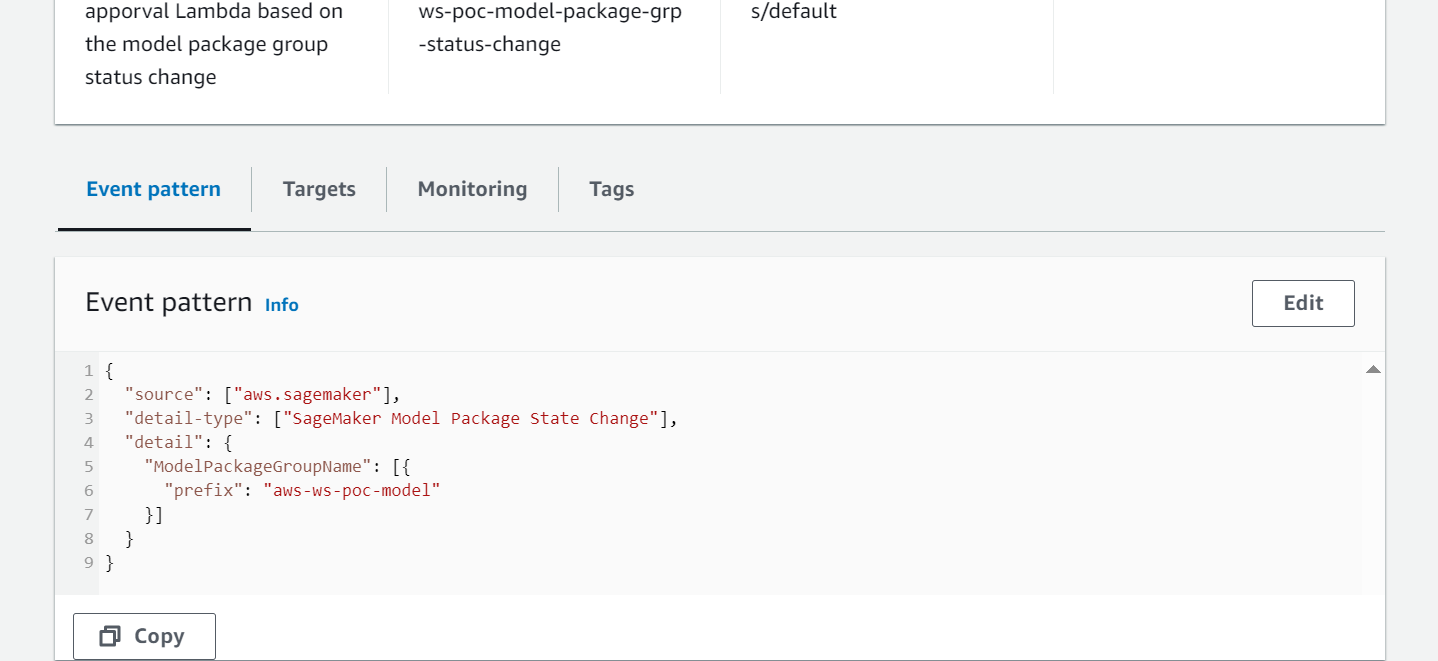
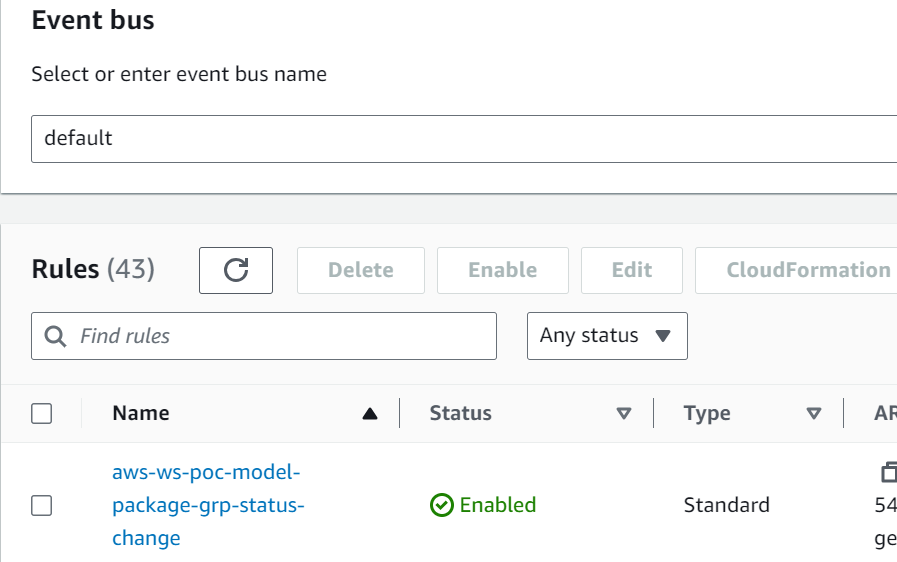
- La regola dell'evento di registrazione del modello richiama una funzione Lambda che costruisce un'e-mail con il collegamento per approvare o rifiutare il modello registrato.
- L'approvatore riceve un'e-mail con il collegamento per rivedere e approvare (o rifiutare) il modello.

- L'approvatore approva il modello seguendo il collegamento all'endpoint API Gateway nell'e-mail.
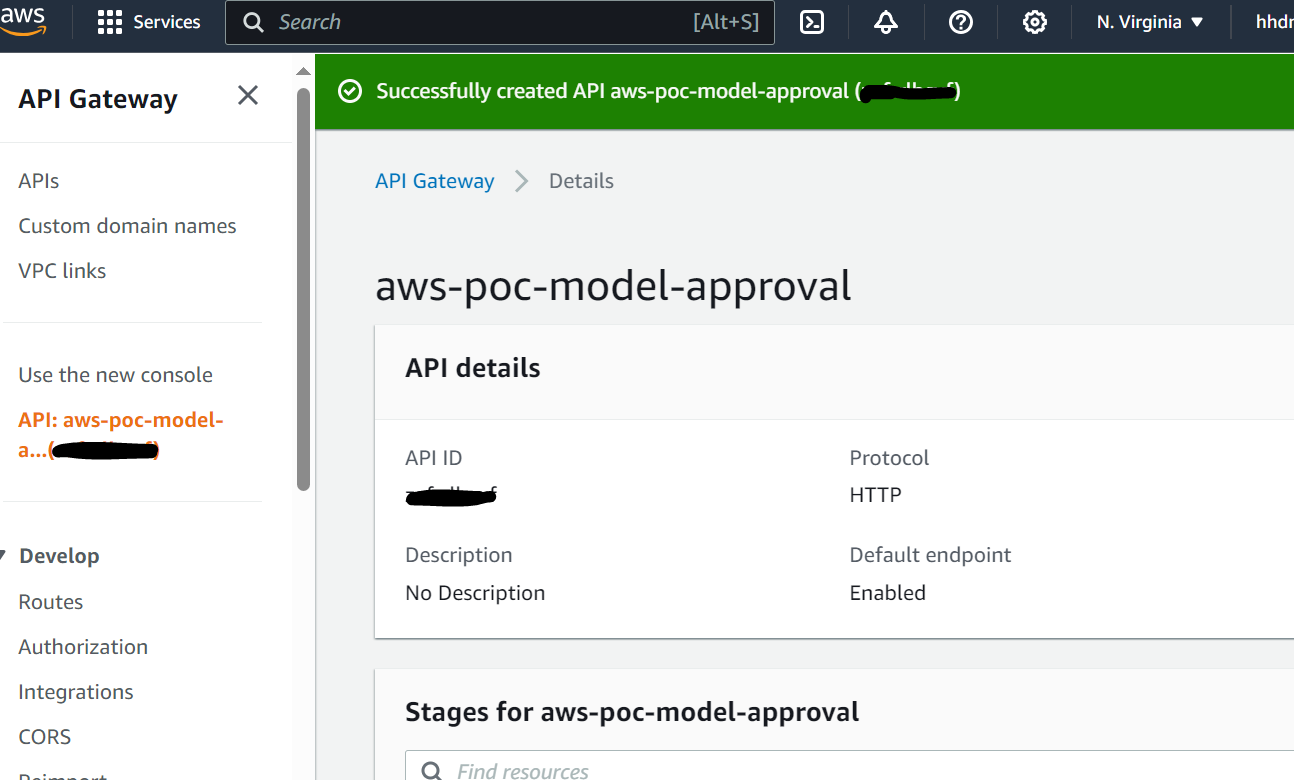
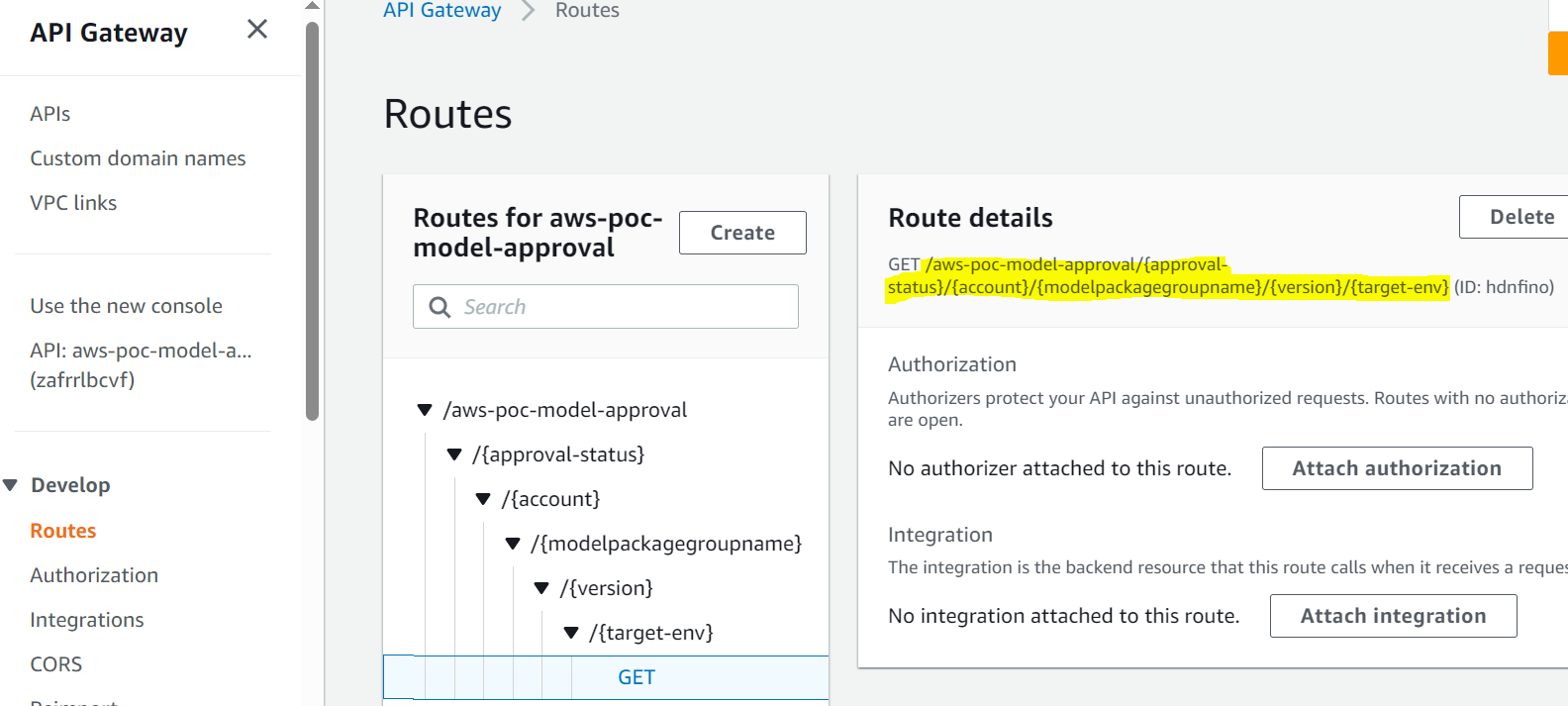
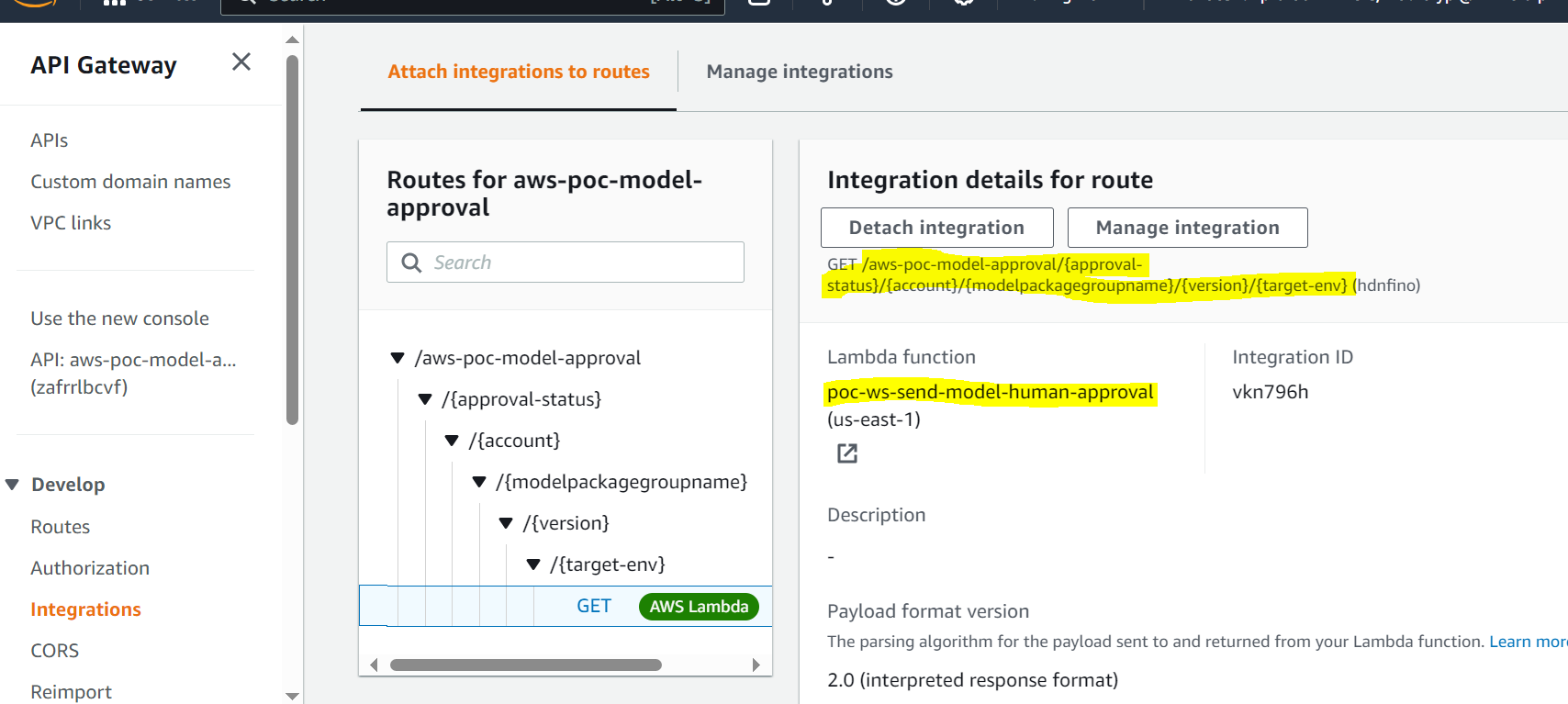
- API Gateway richiama la funzione Lambda per avviare gli aggiornamenti del modello.
- Il registro dei modelli SageMaker viene aggiornato con lo stato del modello.

- Le informazioni dettagliate sul modello vengono archiviate in Archivio parametri, inclusa la versione del modello, l'ambiente di destinazione approvato e il pacchetto del modello.
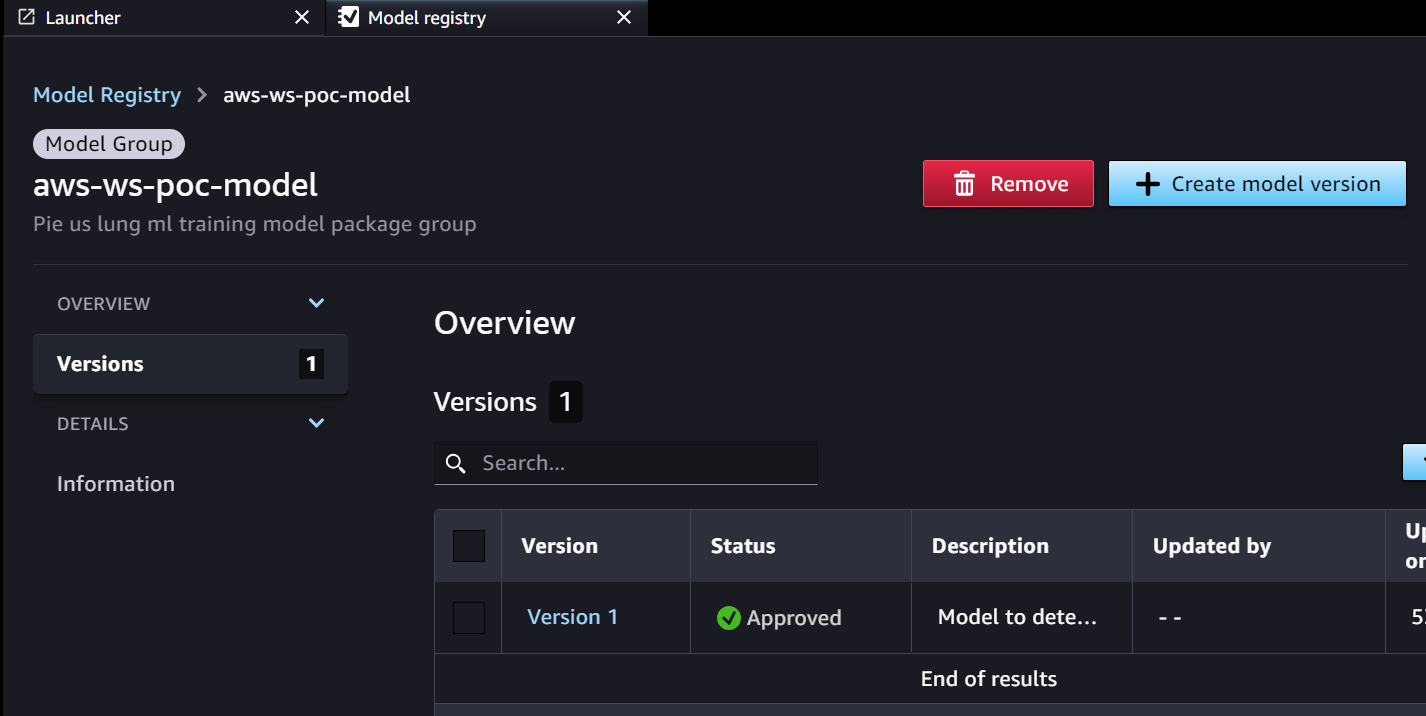

- La pipeline di inferenza recupera il modello approvato per l'ambiente di destinazione da Parameter Store.
- La funzione Lambda di notifica post-inferenza raccoglie i parametri di inferenza batch e invia un'e-mail all'approvatore per promuovere il modello nell'ambiente successivo.
- L'approvatore approva la promozione del modello al livello successivo seguendo il collegamento all'endpoint API Gateway, che attiva la funzione Lambda per aggiornare il registro dei modelli SageMaker e l'archivio parametri.
La cronologia completa del controllo delle versioni e dell'approvazione del modello viene salvata per la revisione nell'archivio parametri.

Conclusione
L'ampio ciclo di vita dello sviluppo di modelli ML richiede un processo di approvazione del modello ML scalabile. In questo post, abbiamo condiviso un'implementazione di un flusso di lavoro di registrazione, approvazione e promozione di modelli ML con intervento umano utilizzando SageMaker Model Registry, EventBridge, API Gateway e Lambda. Se stai considerando un processo di sviluppo di modelli ML scalabile per la tua piattaforma MLOps, puoi seguire i passaggi riportati in questo post per implementare un flusso di lavoro simile.
Circa gli autori
 TomKim è Senior Solution Architect presso AWS, dove aiuta i suoi clienti a raggiungere i loro obiettivi aziendali sviluppando soluzioni su AWS. Ha una vasta esperienza nell'architettura e nelle operazioni dei sistemi aziendali in diversi settori, in particolare nel settore sanitario e delle scienze della vita. Tom apprende sempre nuove tecnologie che portano ai risultati aziendali desiderati per i clienti, ad es. AI/ML, GenAI e analisi dei dati. Gli piace anche viaggiare in posti nuovi e giocare a nuovi campi da golf ogni volta che trova il tempo.
TomKim è Senior Solution Architect presso AWS, dove aiuta i suoi clienti a raggiungere i loro obiettivi aziendali sviluppando soluzioni su AWS. Ha una vasta esperienza nell'architettura e nelle operazioni dei sistemi aziendali in diversi settori, in particolare nel settore sanitario e delle scienze della vita. Tom apprende sempre nuove tecnologie che portano ai risultati aziendali desiderati per i clienti, ad es. AI/ML, GenAI e analisi dei dati. Gli piace anche viaggiare in posti nuovi e giocare a nuovi campi da golf ogni volta che trova il tempo.
 Shamika Ariyawansa, in qualità di Senior AI/ML Solutions Architect nella divisione Healthcare and Life Sciences presso Amazon Web Services (AWS), è specializzato in IA generativa, con particolare attenzione alla formazione LLM (Large Language Model), all'ottimizzazione dell'inferenza e al MLOps (Machine Learning). Operazioni). Guida i clienti nell'integrazione dell'intelligenza artificiale generativa avanzata nei loro progetti, garantendo solidi processi di formazione, meccanismi di inferenza efficienti e pratiche MLOps semplificate per soluzioni di intelligenza artificiale efficaci e scalabili. Al di là dei suoi impegni professionali, Shamika persegue con passione le avventure sugli sci e fuoristrada.
Shamika Ariyawansa, in qualità di Senior AI/ML Solutions Architect nella divisione Healthcare and Life Sciences presso Amazon Web Services (AWS), è specializzato in IA generativa, con particolare attenzione alla formazione LLM (Large Language Model), all'ottimizzazione dell'inferenza e al MLOps (Machine Learning). Operazioni). Guida i clienti nell'integrazione dell'intelligenza artificiale generativa avanzata nei loro progetti, garantendo solidi processi di formazione, meccanismi di inferenza efficienti e pratiche MLOps semplificate per soluzioni di intelligenza artificiale efficaci e scalabili. Al di là dei suoi impegni professionali, Shamika persegue con passione le avventure sugli sci e fuoristrada.
 Jayadeep Pabbistty è un Senior ML/Data Engineer presso Merck, dove progetta e sviluppa soluzioni ETL e MLOps per sbloccare la scienza e l'analisi dei dati per l'azienda. È sempre entusiasta di apprendere nuove tecnologie, esplorare nuove strade e acquisire le competenze necessarie per evolversi con il settore IT in continua evoluzione. Nel tempo libero coltiva la sua passione per lo sport e gli piace viaggiare ed esplorare posti nuovi.
Jayadeep Pabbistty è un Senior ML/Data Engineer presso Merck, dove progetta e sviluppa soluzioni ETL e MLOps per sbloccare la scienza e l'analisi dei dati per l'azienda. È sempre entusiasta di apprendere nuove tecnologie, esplorare nuove strade e acquisire le competenze necessarie per evolversi con il settore IT in continua evoluzione. Nel tempo libero coltiva la sua passione per lo sport e gli piace viaggiare ed esplorare posti nuovi.
 Prabakaran Mathaiyan è un Senior Machine Learning Engineer presso Tiger Analytics LLC, dove aiuta i suoi clienti a raggiungere i loro obiettivi aziendali fornendo soluzioni per la creazione di modelli, la formazione, la convalida, il monitoraggio, CICD e il miglioramento delle soluzioni di machine learning su AWS. Prabakaran apprende sempre nuove tecnologie che portano ai risultati aziendali desiderati per i clienti, ad es. AI/ML, GenAI, GPT e LLM. Gli piace anche giocare a cricket ogni volta che riesce a trovare il tempo.
Prabakaran Mathaiyan è un Senior Machine Learning Engineer presso Tiger Analytics LLC, dove aiuta i suoi clienti a raggiungere i loro obiettivi aziendali fornendo soluzioni per la creazione di modelli, la formazione, la convalida, il monitoraggio, CICD e il miglioramento delle soluzioni di machine learning su AWS. Prabakaran apprende sempre nuove tecnologie che portano ai risultati aziendali desiderati per i clienti, ad es. AI/ML, GenAI, GPT e LLM. Gli piace anche giocare a cricket ogni volta che riesce a trovare il tempo.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/build-an-amazon-sagemaker-model-registry-approval-and-promotion-workflow-with-human-intervention/

