Ottenere risposte accurate e approfondite da grandi quantità di testo è una capacità entusiasmante consentita dai modelli linguistici di grandi dimensioni (LLM). Quando si creano applicazioni LLM, è spesso necessario connettere ed eseguire query su origini dati esterne per fornire un contesto pertinente al modello. Un approccio diffuso è l’utilizzo del Retrieval Augmented Generation (RAG) per creare sistemi di domande e risposte che comprendano informazioni complesse e forniscano risposte naturali alle domande. RAG consente ai modelli di attingere a vaste basi di conoscenza e fornire un dialogo simile a quello umano per applicazioni come chatbot e assistenti di ricerca aziendali.
In questo post esploriamo come sfruttare il potere di CallIndex, Lama 2-70B-Chate LangChain per creare potenti applicazioni di domande e risposte. Con queste tecnologie all'avanguardia, puoi acquisire corpora di testo, indicizzare conoscenze critiche e generare testo che risponda alle domande degli utenti in modo preciso e chiaro.
Lama 2-70B-Chat
Llama 2-70B-Chat è un potente LLM che compete con i modelli principali. È pre-addestrato su due trilioni di token di testo e previsto da Meta per essere utilizzato per l'assistenza via chat agli utenti. I dati di pre-addestramento provengono da dati disponibili al pubblico e si concluderanno a settembre 2022, mentre i dati di perfezionamento si concluderanno a luglio 2023. Per ulteriori dettagli sul processo di addestramento del modello, considerazioni sulla sicurezza, apprendimenti e usi previsti, fare riferimento al documento Llama 2: Fondazione aperta e modelli di chat ottimizzati. I modelli Llama 2 sono disponibili su JumpStart di Amazon SageMaker per una distribuzione rapida e semplice.
CallIndex
CallIndex è un framework di dati che consente di creare applicazioni LLM. Fornisce strumenti che offrono connettori dati per acquisire i dati esistenti con varie origini e formati (PDF, documenti, API, SQL e altro). Sia che tu abbia dati archiviati in database o in PDF, LlamaIndex semplifica l'utilizzo di tali dati per i LLM. Come dimostriamo in questo post, le API LlamaIndex semplificano l'accesso ai dati e ti consentono di creare potenti applicazioni e flussi di lavoro LLM personalizzati.
Se stai sperimentando e sviluppando con LLM, probabilmente hai familiarità con LangChain, che offre un framework solido, semplificando lo sviluppo e l'implementazione di applicazioni basate su LLM. Similmente a LangChain, LlamaIndex offre una serie di strumenti, inclusi connettori di dati, indici di dati, motori e agenti dati, nonché integrazioni di applicazioni come strumenti e osservabilità, tracciamento e valutazione. LlamaIndex si concentra sul colmare il divario tra i dati e i potenti LLM, semplificando le attività relative ai dati con funzionalità intuitive. LlamaIndex è specificamente progettato e ottimizzato per la creazione di applicazioni di ricerca e recupero, come RAG, poiché fornisce un'interfaccia semplice per interrogare LLM e recuperare documenti rilevanti.
Panoramica della soluzione
In questo post, mostriamo come creare un'applicazione basata su RAG utilizzando LlamaIndex e un LLM. Il diagramma seguente mostra l'architettura passo passo di questa soluzione delineata nelle sezioni seguenti.
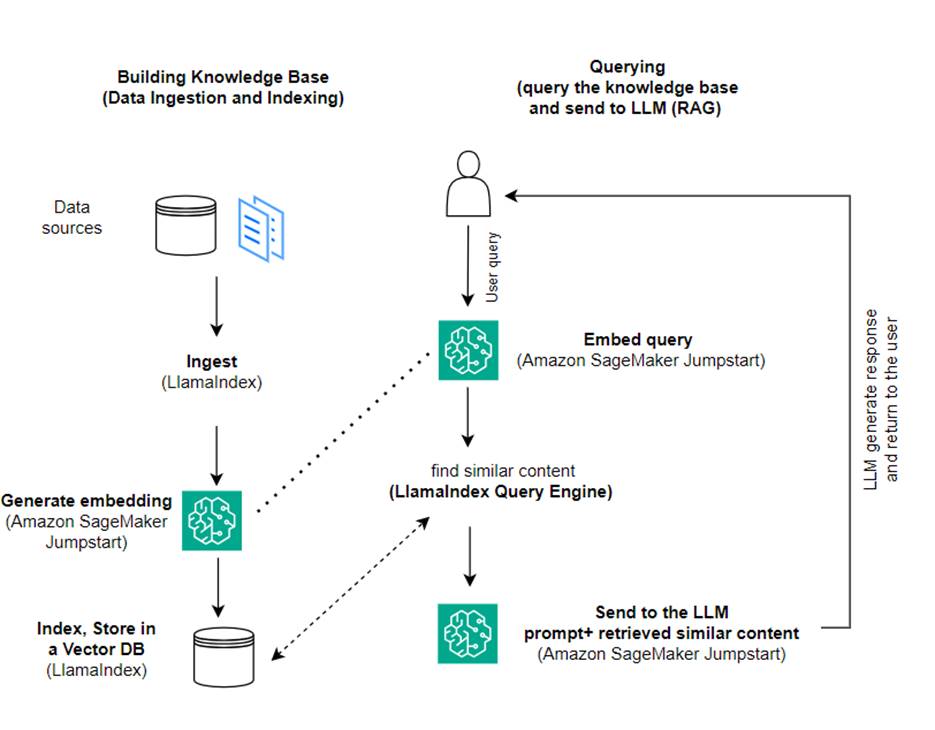
RAG combina il recupero delle informazioni con la generazione del linguaggio naturale per produrre risposte più approfondite. Quando richiesto, RAG ricerca prima i corpora di testo per recuperare gli esempi più rilevanti per l'input. Durante la generazione della risposta, il modello considera questi esempi per aumentare le sue capacità. Incorporando passaggi recuperati rilevanti, le risposte RAG tendono ad essere più fattuali, coerenti e coerenti con il contesto rispetto ai modelli generativi di base. Questa struttura di recupero-generazione sfrutta i punti di forza sia del recupero che della generazione, aiutando ad affrontare problemi come la ripetizione e la mancanza di contesto che possono derivare da modelli conversazionali puri autoregressivi. RAG introduce un approccio efficace per creare agenti conversazionali e assistenti IA con risposte contestualizzate e di alta qualità.
La creazione della soluzione prevede i seguenti passaggi:
- Impostare Amazon Sage Maker Studio come ambiente di sviluppo e installare le dipendenze richieste.
- Distribuisci un modello di incorporamento dall'hub JumpStart di Amazon SageMaker.
- Scarica i comunicati stampa da utilizzare come base di conoscenza esterna.
- Costruisci un indice dei comunicati stampa per poter eseguire query e aggiungere ulteriore contesto al prompt.
- Interroga la base di conoscenza.
- Crea un'applicazione di domande e risposte utilizzando gli agenti LlamaIndex e LangChain.
Tutto il codice in questo post è disponibile nel file Repository GitHub.
Prerequisiti
Per questo esempio, è necessario un account AWS con un dominio SageMaker e appropriato Gestione dell'identità e dell'accesso di AWS (IAM) autorizzazioni. Per le istruzioni sulla configurazione dell'account, vedere Crea un account AWS. Se non disponi già di un dominio SageMaker, fai riferimento a Dominio Amazon SageMaker panoramica per crearne uno. In questo post utilizziamo il file AmazonSageMakerFullAccess ruolo. Non è consigliabile utilizzare questa credenziale in un ambiente di produzione. Dovresti invece creare e utilizzare un ruolo con autorizzazioni con privilegi minimi. Puoi anche esplorare come puoi utilizzare Gestore ruoli di Amazon SageMaker per creare e gestire ruoli IAM basati su persona per le esigenze comuni di machine learning direttamente tramite la console SageMaker.
Inoltre, è necessario accedere ad almeno le seguenti dimensioni di istanza:
- ml.g5.2xgrande per l'utilizzo dell'endpoint durante la distribuzione di Volto abbracciato GPT-J modello di incorporamento del testo
- ml.g5.48xgrande per l'utilizzo dell'endpoint durante la distribuzione dell'endpoint del modello Llama 2-Chat
Per aumentare la quota, fare riferimento a Richiesta di un aumento della quota.
Distribuisci un modello di incorporamento GPT-J utilizzando SageMaker JumpStart
Questa sezione offre due opzioni durante la distribuzione dei modelli SageMaker JumpStart. È possibile utilizzare una distribuzione basata su codice utilizzando il codice fornito oppure utilizzare l'interfaccia utente (UI) SageMaker JumpStart.
Distribuisci con SageMaker Python SDK
È possibile utilizzare SageMaker Python SDK per distribuire i LLM, come mostrato nel file codice disponibile nel repository. Completa i seguenti passaggi:
- Imposta la dimensione dell'istanza da utilizzare per la distribuzione del modello di incorporamento utilizzando
instance_type = "ml.g5.2xlarge" - Individuare l'ID del modello da utilizzare per gli incorporamenti. In SageMaker JumpStart, è identificato come
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - Recupera il contenitore del modello pre-addestrato e distribuiscilo per l'inferenza.
SageMaker restituirà il nome dell'endpoint del modello e il seguente messaggio quando il modello di incorporamento sarà stato distribuito correttamente:
Distribuisci con SageMaker JumpStart in SageMaker Studio
Per distribuire il modello utilizzando SageMaker JumpStart in Studio, completare i seguenti passaggi:
- Nella console SageMaker Studio, scegli JumpStart nel riquadro di navigazione.

- Cerca e scegli il modello GPT-J 6B Embedding FP16.
- Scegli Distribuisci e personalizza la configurazione di distribuzione.

- Per questo esempio, abbiamo bisogno di un'istanza ml.g5.2xlarge, che è l'istanza predefinita suggerita da SageMaker JumpStart.
- Scegli di nuovo Distribuisci per creare l'endpoint.
L'endpoint impiegherà circa 5-10 minuti per essere in servizio.

Dopo aver distribuito il modello di incorporamento, per utilizzare l'integrazione LangChain con le API SageMaker, è necessario creare una funzione per gestire gli input (testo non elaborato) e trasformarli in incorporamenti utilizzando il modello. Puoi farlo creando una classe chiamata ContentHandler, che accetta un JSON di dati di input e restituisce un JSON di incorporamenti di testo: class ContentHandler(EmbeddingsContentHandler).
Passa il nome dell'endpoint del modello al file ContentHandler funzione per convertire il testo e restituire gli incorporamenti:
È possibile individuare il nome dell'endpoint nell'output dell'SDK o nei dettagli di distribuzione nell'interfaccia utente JumpStart di SageMaker.
Puoi testare che il ContentHandler la funzione e l'endpoint funzionano come previsto inserendo del testo non elaborato ed eseguendo il file embeddings.embed_query(text) funzione. È possibile utilizzare l'esempio fornito text = "Hi! It's time for the beach" oppure prova il tuo testo.
Distribuisci e testa Llama 2-Chat utilizzando SageMaker JumpStart
Ora puoi distribuire il modello in grado di avere conversazioni interattive con i tuoi utenti. In questo caso scegliamo uno dei modelli Llama 2-chat, identificato tramite
Il modello deve essere distribuito su un endpoint in tempo reale utilizzando predictor = my_model.deploy(). SageMaker restituirà il nome dell'endpoint del modello, che puoi utilizzare per il file endpoint_name variabile a cui fare riferimento in seguito.
Tu definisci a print_dialogue funzione per inviare input al modello di chat e ricevere la risposta in output. Il payload include gli iperparametri per il modello, inclusi i seguenti:
- max_new_tokens – Si riferisce al numero massimo di token che il modello può generare nei suoi output.
- in alto_p – Si riferisce alla probabilità cumulativa dei token che possono essere trattenuti dal modello durante la generazione dei suoi output
- temperatura – Si riferisce alla casualità degli output generati dal modello. Una temperatura maggiore di 0 o uguale a 1 aumenta il livello di casualità, mentre una temperatura pari a 0 genererà i token più probabili.
Dovresti selezionare gli iperparametri in base al tuo caso d'uso e testarli in modo appropriato. Modelli come la famiglia Llama richiedono che tu includa un parametro aggiuntivo che indichi che hai letto e accettato il Contratto di licenza con l'utente finale (EULA):
Per testare il modello, sostituire la sezione del contenuto del payload di input: "content": "what is the recipe of mayonnaise?". Puoi utilizzare i tuoi valori di testo e aggiornare gli iperparametri per comprenderli meglio.
Analogamente alla distribuzione del modello di incorporamento, puoi distribuire Llama-70B-Chat utilizzando l'interfaccia utente JumpStart di SageMaker:
- Nella console di SageMaker Studio, scegli inizio di salto nel riquadro di navigazione
- Cerca e scegli il
Llama-2-70b-Chat model - Accetta l'EULA e scegli Schierare, utilizzando nuovamente l'istanza predefinita
Similmente al modello di incorporamento, puoi utilizzare l'integrazione LangChain creando un modello di gestore del contenuto per gli input e gli output del tuo modello di chat. In questo caso, definisci gli input come quelli provenienti da un utente e indichi che sono governati dal system prompt. system prompt informa il modello del suo ruolo nell'assistere l'utente per un particolare caso d'uso.
Questo gestore di contenuto viene quindi passato quando si richiama il modello, oltre agli iperparametri e agli attributi personalizzati sopra menzionati (accettazione EULA). Analizzi tutti questi attributi utilizzando il seguente codice:
Quando l'endpoint è disponibile, puoi verificare che funzioni come previsto. Puoi aggiornare llm("what is amazon sagemaker?") con il tuo testo. È inoltre necessario definire lo specifico ContentHandler per richiamare LLM utilizzando LangChain, come mostrato nel file codice e il seguente frammento di codice:
Usa LlamaIndex per costruire il RAG
Per continuare, installa LlamaIndex per creare l'applicazione RAG. Puoi installare LlamaIndex usando il pip: pip install llama_index
Devi prima caricare i tuoi dati (base di conoscenza) su LlamaIndex per l'indicizzazione. Ciò comporta alcuni passaggi:
- Scegli un caricatore dati:
LlamaIndex fornisce una serie di connettori dati disponibili su LlamaHub per tipi di dati comuni come JSON, CSV e file di testo, nonché altre origini dati, consentendo di acquisire una varietà di set di dati. In questo post utilizziamo SimpleDirectoryReader per importare alcuni file PDF come mostrato nel codice. Il nostro campione di dati è costituito da due comunicati stampa di Amazon in versione PDF nel file comunicati stampa cartella nel nostro repository di codice. Dopo aver caricato i PDF, puoi vedere che sono stati convertiti in un elenco di 11 elementi.
Invece di caricare direttamente i documenti, puoi anche convertirli Document oggetto in Node oggetti prima di inviarli all'indice. La scelta tra l'invio dell'intero Document oggetto all'indice o conversione del documento in Node oggetti prima dell'indicizzazione dipende dal caso d'uso specifico e dalla struttura dei dati. L'approccio dei nodi è generalmente una buona scelta per documenti lunghi, in cui si desidera suddividere e recuperare parti specifiche di un documento anziché l'intero documento. Per ulteriori informazioni, fare riferimento a Documenti/Nodi.
- Istanziare il caricatore e caricare i documenti:
Questo passaggio inizializza la classe del caricatore e qualsiasi configurazione necessaria, ad esempio se ignorare i file nascosti. Per ulteriori dettagli, fare riferimento a SimpleDirectoryReader.
- Chiama il caricatore
load_dataper analizzare i file e i dati di origine e convertirli in oggetti LlamaIndex Document, pronti per l'indicizzazione e l'esecuzione di query. Puoi utilizzare il codice seguente per completare l'inserimento dei dati e la preparazione per la ricerca full-text utilizzando le funzionalità di indicizzazione e recupero di LlamaIndex:
- Costruisci l'indice:
La caratteristica chiave di LlamaIndex è la sua capacità di costruire indici organizzati sui dati, che sono rappresentati come documenti o nodi. L'indicizzazione facilita l'esecuzione di query efficienti sui dati. Creiamo il nostro indice con l'archivio vettoriale in memoria predefinito e con la nostra configurazione di impostazioni definita. L'indice dei lama Impostazioni profilo è un oggetto di configurazione che fornisce risorse e impostazioni di uso comune per le operazioni di indicizzazione e di query in un'applicazione LlamaIndex. Funziona come un oggetto singleton, in modo da consentire di impostare configurazioni globali, consentendo anche di sovrascrivere componenti specifici localmente passandoli direttamente nelle interfacce (come LLM, modelli di incorporamento) che li utilizzano. Quando un particolare componente non viene fornito esplicitamente, il framework LlamaIndex ricorre alle impostazioni definite nel file Settings oggetto come predefinito globale. Per utilizzare i nostri modelli di incorporamento e LLM con LangChain e configurare il file Settings dobbiamo installare llama_index.embeddings.langchain ed llama_index.llms.langchain. Possiamo configurare il Settings oggetto come nel seguente codice:
Per impostazione predefinita, VectorStoreIndex utilizza un in-memory SimpleVectorStore che viene inizializzato come parte del contesto di archiviazione predefinito. Nei casi d'uso reali, spesso è necessario connettersi ad archivi vettoriali esterni come Servizio Amazon OpenSearch. Per maggiori dettagli, fare riferimento a Motore vettoriale per Amazon OpenSearch Serverless.
Ora puoi eseguire domande e risposte sui tuoi documenti utilizzando il file query_engine da LlamaIndex. Per fare ciò, passa l'indice creato in precedenza per le query e fai la tua domanda. Il motore di query è un'interfaccia generica per eseguire query sui dati. Richiede una query in linguaggio naturale come input e restituisce una risposta ricca. Il motore di query è in genere basato su uno o più indici utilizzando cane da riporto.
Puoi vedere che la soluzione RAG è in grado di recuperare la risposta corretta dai documenti forniti:
Utilizza gli strumenti e gli agenti LangChain
Loader classe. Il caricatore è progettato per caricare dati in LlamaIndex o successivamente come strumento in a Agente LangChain. Ciò ti offre più potenza e flessibilità per utilizzarlo come parte della tua applicazione. Inizi definendo il tuo dalla classe agente LangChain. La funzione che trasmetti al tuo strumento interroga l'indice che hai creato sui tuoi documenti utilizzando LlamaIndex.
Quindi seleziona il tipo corretto di agente che desideri utilizzare per l'implementazione RAG. In questo caso, usi il file chat-zero-shot-react-description agente. Con questo agente, LLM utilizzerà lo strumento disponibile (in questo scenario, il RAG sulla knowledge base) per fornire la risposta. Quindi inizializzi l'agente passando lo strumento, il LLM e il tipo di agente:
Puoi vedere l'agente che passa thoughts, actionse observation , utilizzare lo strumento (in questo scenario, interrogando i documenti indicizzati); e restituire un risultato:
È possibile trovare il codice di implementazione end-to-end nel file allegato Repository GitHub.
ripulire
Per evitare costi inutili, puoi ripulire le tue risorse tramite i seguenti snippet di codice o l'interfaccia utente di Amazon JumpStart.
Per utilizzare l'SDK Boto3, utilizzare il codice seguente per eliminare l'endpoint del modello di incorporamento del testo e l'endpoint del modello di generazione del testo, nonché le configurazioni dell'endpoint:
Per utilizzare la console SageMaker, completare i seguenti passaggi:
- Nella console SageMaker, sotto Inferenza nel riquadro di navigazione, scegli Endpoint
- Cerca gli endpoint di incorporamento e di generazione del testo.
- Nella pagina dei dettagli dell'endpoint, scegli Elimina.
- Scegli di nuovo Elimina per confermare.
Conclusione
Per i casi d'uso incentrati sulla ricerca e sul recupero, LlamaIndex offre funzionalità flessibili. Eccelle nell'indicizzazione e nel recupero per i LLM, rendendolo un potente strumento per l'esplorazione approfondita dei dati. LlamaIndex ti consente di creare indici di dati organizzati, utilizzare diversi LLM, aumentare i dati per migliori prestazioni LLM ed eseguire query sui dati con linguaggio naturale.
Questo post ha dimostrato alcuni concetti e funzionalità chiave di LlamaIndex. Abbiamo utilizzato GPT-J per l'incorporamento e Llama 2-Chat come LLM per creare un'applicazione RAG, ma potresti invece utilizzare qualsiasi modello adatto. Puoi esplorare la gamma completa di modelli disponibili su SageMaker JumpStart.
Abbiamo anche mostrato come LlamaIndex può fornire strumenti potenti e flessibili per connettere, indicizzare, recuperare e integrare dati con altri framework come LangChain. Con le integrazioni LlamaIndex e LangChain, puoi creare applicazioni LLM più potenti, versatili e approfondite.
Informazioni sugli autori
 Dott.ssa Romina Sharifpour è un architetto senior di soluzioni di machine learning e intelligenza artificiale presso Amazon Web Services (AWS). Ha trascorso oltre 10 anni alla guida della progettazione e dell'implementazione di soluzioni end-to-end innovative rese possibili dai progressi nel machine learning e nell'intelligenza artificiale. Le aree di interesse di Romina sono l'elaborazione del linguaggio naturale, i modelli linguistici di grandi dimensioni e MLOps.
Dott.ssa Romina Sharifpour è un architetto senior di soluzioni di machine learning e intelligenza artificiale presso Amazon Web Services (AWS). Ha trascorso oltre 10 anni alla guida della progettazione e dell'implementazione di soluzioni end-to-end innovative rese possibili dai progressi nel machine learning e nell'intelligenza artificiale. Le aree di interesse di Romina sono l'elaborazione del linguaggio naturale, i modelli linguistici di grandi dimensioni e MLOps.
 Nicola Pinto è un AI/ML Specialist Solutions Architect con sede a Sydney, Australia. Il suo background nel settore sanitario e dei servizi finanziari le offre una prospettiva unica nella risoluzione dei problemi dei clienti. La sua passione è supportare i clienti attraverso l'apprendimento automatico e dare potere alla prossima generazione di donne nel campo STEM.
Nicola Pinto è un AI/ML Specialist Solutions Architect con sede a Sydney, Australia. Il suo background nel settore sanitario e dei servizi finanziari le offre una prospettiva unica nella risoluzione dei problemi dei clienti. La sua passione è supportare i clienti attraverso l'apprendimento automatico e dare potere alla prossima generazione di donne nel campo STEM.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

