Questo post è stato scritto in collaborazione con Chaoyang He, Al Nevarez e Salman Avestimehr di FedML.
Molte organizzazioni stanno implementando il machine learning (ML) per migliorare il processo decisionale aziendale attraverso l'automazione e l'uso di grandi set di dati distribuiti. Con un maggiore accesso ai dati, il machine learning ha il potenziale per fornire approfondimenti e opportunità di business senza precedenti. Tuttavia, la condivisione di informazioni sensibili grezze e non disinfettate in luoghi diversi comporta rischi significativi per la sicurezza e la privacy, soprattutto nei settori regolamentati come quello sanitario.
Per affrontare questo problema, il federated learning (FL) è una tecnica di formazione ML decentralizzata e collaborativa che offre privacy dei dati mantenendo accuratezza e fedeltà. A differenza della formazione ML tradizionale, la formazione FL avviene all'interno di una sede client isolata utilizzando una sessione sicura indipendente. Il client condivide solo i parametri del modello di output con un server centralizzato, noto come coordinatore del training o server di aggregazione, e non i dati effettivi utilizzati per il training del modello. Questo approccio allevia molti problemi di privacy dei dati consentendo al tempo stesso una collaborazione efficace sulla formazione dei modelli.
Sebbene FL rappresenti un passo avanti verso il raggiungimento di una migliore privacy e sicurezza dei dati, non è una soluzione garantita. Le reti non sicure prive di controllo degli accessi e di crittografia possono comunque esporre informazioni sensibili agli aggressori. Inoltre, le informazioni addestrate localmente possono esporre dati privati se ricostruite tramite un attacco di inferenza. Per mitigare questi rischi, il modello FL utilizza algoritmi di formazione personalizzati e mascheramenti e parametrizzazioni efficaci prima di condividere le informazioni con il coordinatore della formazione. Forti controlli di rete in sedi locali e centralizzate possono ridurre ulteriormente i rischi di inferenza ed esfiltrazione.
In questo post condividiamo un approccio FL utilizzando FedML, Servizio Amazon Elastic Kubernetes (Amazon EKS) e Amazon Sage Maker per migliorare i risultati dei pazienti affrontando al tempo stesso i problemi di privacy e sicurezza dei dati.
La necessità di un apprendimento federato in ambito sanitario
Il settore sanitario fa molto affidamento su origini dati distribuite per effettuare previsioni e valutazioni accurate sulla cura dei pazienti. Limitare le fonti di dati disponibili per proteggere la privacy influisce negativamente sull’accuratezza dei risultati e, in ultima analisi, sulla qualità della cura del paziente. Pertanto, il machine learning crea sfide per i clienti AWS che devono garantire la privacy e la sicurezza tra le entità distribuite senza compromettere i risultati dei pazienti.
Le organizzazioni sanitarie devono rispettare rigide normative di conformità, come l'Health Insurance Portability and Accountability Act (HIPAA) negli Stati Uniti, mentre implementano le soluzioni FL. Garantire la privacy, la sicurezza e la conformità dei dati diventa ancora più critico nel settore sanitario, poiché richiede crittografia solida, controlli di accesso, meccanismi di audit e protocolli di comunicazione sicuri. Inoltre, i set di dati sanitari spesso contengono tipi di dati complessi ed eterogenei, rendendo la standardizzazione e l’interoperabilità dei dati una sfida nelle impostazioni FL.
Panoramica dei casi d'uso
Il caso d'uso delineato in questo post riguarda i dati sulle malattie cardiache in diverse organizzazioni, sui quali un modello ML eseguirà algoritmi di classificazione per prevedere le malattie cardiache nel paziente. Poiché questi dati riguardano più organizzazioni, utilizziamo l'apprendimento federato per raccogliere i risultati.
I Set di dati sulle malattie cardiache dal Machine Learning Repository dell'Università della California Irvine è un set di dati ampiamente utilizzato per la ricerca cardiovascolare e la modellazione predittiva. È composto da 303 campioni, ciascuno rappresentante un paziente, e contiene una combinazione di attributi clinici e demografici, nonché la presenza o l'assenza di malattie cardiache.
Questo set di dati multivariato presenta 76 attributi nelle informazioni del paziente, di cui 14 attributi sono più comunemente utilizzati per sviluppare e valutare algoritmi ML per prevedere la presenza di malattie cardiache in base agli attributi forniti.
quadro FedML
Esiste un'ampia selezione di framework FL, ma abbiamo deciso di utilizzare il file quadro FedML per questo caso d'uso perché è open source e supporta diversi paradigmi FL. FedML fornisce una popolare libreria open source, una piattaforma MLOps e un ecosistema di applicazioni per FL. Questi facilitano lo sviluppo e l'implementazione di soluzioni FL. Fornisce una suite completa di strumenti, librerie e algoritmi che consentono a ricercatori e professionisti di implementare e sperimentare algoritmi FL in un ambiente distribuito. FedML affronta le sfide della privacy dei dati, della comunicazione e dell'aggregazione dei modelli in FL, offrendo un'interfaccia intuitiva e componenti personalizzabili. Concentrandosi sulla collaborazione e sulla condivisione delle conoscenze, FedML mira ad accelerare l'adozione di FL e promuovere l'innovazione in questo campo emergente. Il framework FedML è indipendente dal modello, incluso il supporto recentemente aggiunto per i modelli linguistici di grandi dimensioni (LLM). Per ulteriori informazioni, fare riferimento a Rilascio di FedLLM: costruisci i tuoi modelli linguistici di grandi dimensioni su dati proprietari utilizzando la piattaforma FedML.
Polpo FedML
La gerarchia e l'eterogeneità del sistema rappresentano una sfida chiave nei casi d'uso FL reali, in cui diversi silos di dati possono avere infrastrutture diverse con CPU e GPU. In tali scenari, è possibile utilizzare Polpo FedML.
FedML Octopus è la piattaforma di livello industriale di FL cross-silo per la formazione tra organizzazioni e account. Insieme a FedML MLOps, consente agli sviluppatori o alle organizzazioni di condurre una collaborazione aperta da qualsiasi luogo e su qualsiasi scala in modo sicuro. FedML Octopus esegue un paradigma di formazione distribuito all'interno di ciascun silo di dati e utilizza formazioni sincrone o asincrone.
FedMLMLOps
FedML MLOps consente lo sviluppo locale di codice che può successivamente essere distribuito ovunque utilizzando i framework FedML. Prima di iniziare la formazione, devi creare un account FedML, nonché creare e caricare i pacchetti server e client in FedML Octopus. Per ulteriori dettagli, fare riferimento a passi ed Presentazione di FedML Octopus: scalabilità dell'apprendimento federato nella produzione con MLOps semplificati.
Panoramica della soluzione
Distribuiamo FedML in più cluster EKS integrati con SageMaker per il monitoraggio degli esperimenti. Noi usiamo Blueprint di Amazon EKS per Terraform per implementare l’infrastruttura necessaria. EKS Blueprints aiuta a comporre cluster EKS completi completamente bootstrap con il software operativo necessario per distribuire e gestire i carichi di lavoro. Con EKS Blueprints, la configurazione per lo stato desiderato dell'ambiente EKS, come il piano di controllo, i nodi di lavoro e i componenti aggiuntivi Kubernetes, viene descritta come un progetto IaC (infrastruttura come codice). Una volta configurato, un progetto può essere utilizzato per creare ambienti coerenti su più account e regioni AWS utilizzando l'automazione della distribuzione continua.
Il contenuto condiviso in questo post riflette situazioni ed esperienze di vita reale, ma è importante notare che la distribuzione di queste situazioni in luoghi diversi può variare. Sebbene utilizziamo un singolo account AWS con VPC separati, è fondamentale comprendere che le circostanze e le configurazioni individuali possono differire. Pertanto, le informazioni fornite devono essere utilizzate come guida generale e potrebbero richiedere adattamenti in base a requisiti specifici e condizioni locali.
Il diagramma seguente illustra l'architettura della nostra soluzione.
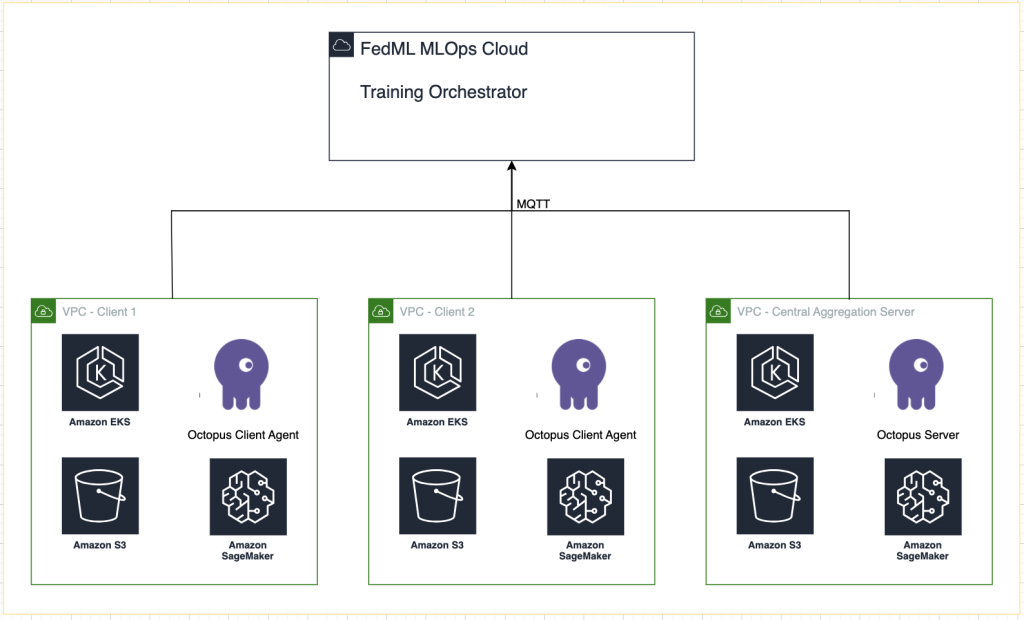
Oltre al tracciamento fornito da FedML MLOps per ogni esecuzione della formazione, utilizziamo Esperimenti Amazon SageMaker per monitorare le prestazioni di ciascun modello client e del modello centralizzato (aggregatore).
SageMaker Experiments è una funzionalità di SageMaker che ti consente di creare, gestire, analizzare e confrontare i tuoi esperimenti ML. Registrando i dettagli, i parametri e i risultati dell'esperimento, i ricercatori possono riprodurre e convalidare accuratamente il loro lavoro. Consente un confronto e un’analisi efficaci di diversi approcci, portando a un processo decisionale informato. Inoltre, il monitoraggio degli esperimenti facilita il miglioramento iterativo fornendo informazioni dettagliate sulla progressione dei modelli e consentendo ai ricercatori di imparare dalle iterazioni precedenti, accelerando in definitiva lo sviluppo di soluzioni più efficaci.
Inviamo quanto segue a SageMaker Experiments per ogni esecuzione:
- Metriche di valutazione del modello – Perdita di allenamento e Area sotto la curva (AUC)
- iperparametri – Epoca, velocità di apprendimento, dimensione del batch, ottimizzatore e decadimento del peso
Prerequisiti
Per seguire questo post, dovresti avere i seguenti prerequisiti:
Distribuisci la soluzione
Per iniziare, clona localmente il repository che ospita il codice di esempio:
Quindi distribuisci l'infrastruttura del caso d'uso utilizzando i seguenti comandi:
La distribuzione completa del modello Terraform potrebbe richiedere 20-30 minuti. Dopo la distribuzione, seguire i passaggi nelle sezioni successive per eseguire l'applicazione FL.
Crea un pacchetto di distribuzione MLOps
Come parte della documentazione FedML, dobbiamo creare i pacchetti client e server, che la piattaforma MLOps distribuirà al server e ai client per iniziare la formazione.
Per creare questi pacchetti, esegui il seguente script trovato nella directory root:
Ciò creerà i rispettivi pacchetti nella seguente directory nella directory principale del progetto:
Carica i pacchetti sulla piattaforma FedML MLOps
Completa i seguenti passaggi per caricare i pacchetti:
- Nell'interfaccia utente FedML, scegli Le mie applicazioni nel pannello di navigazione.
- Scegli Nuova applicazione.
- Carica i pacchetti client e server dalla tua workstation.
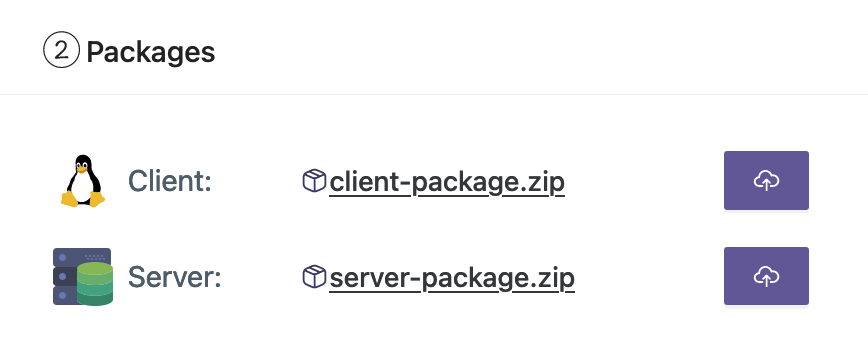
- Puoi anche modificare gli iperparametri o crearne di nuovi.

Attiva la formazione federata
Per eseguire la formazione federata, completare i seguenti passaggi:
- Nell'interfaccia utente FedML, scegli Elenco progetti nel pannello di navigazione.
- Scegli Creare un nuovo progetto.
- Inserisci un nome di gruppo e un nome di progetto, quindi scegli OK.

- Scegli il progetto appena creato e scegli Crea una nuova corsa per attivare una corsa di allenamento.
- Seleziona i dispositivi client edge e il server aggregatore centrale per questa esecuzione del training.
- Scegli l'applicazione che hai creato nei passaggi precedenti.

- Aggiorna uno qualsiasi degli iperparametri o utilizza le impostazioni predefinite.
- Scegli Inizio per iniziare la formazione.

- Scegliere il Stato di formazione scheda e attendere il completamento dell'esecuzione dell'addestramento. Puoi anche navigare tra le schede disponibili.
- Una volta completata la formazione, scegli il Sistema scheda per visualizzare le durate dei tempi di formazione sui server periferici e gli eventi di aggregazione.
Visualizza i risultati e i dettagli dell'esperimento
Una volta completata la formazione, puoi visualizzare i risultati utilizzando FedML e SageMaker.
Nell'interfaccia utente FedML, nel file Modelli scheda, puoi vedere l'aggregatore e il modello client. È inoltre possibile scaricare questi modelli dal sito Web.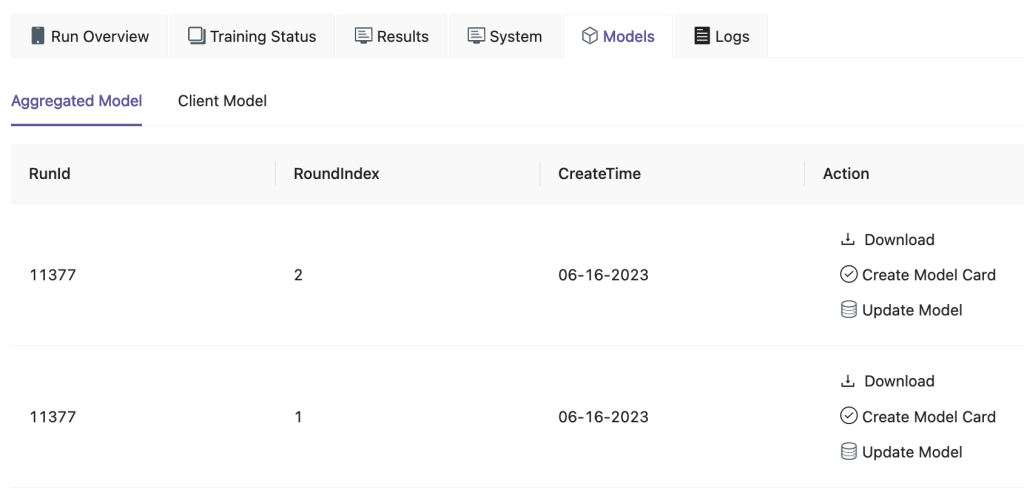
Puoi anche accedere a Amazon Sage Maker Studio e scegli Esperimenti nel pannello di navigazione.
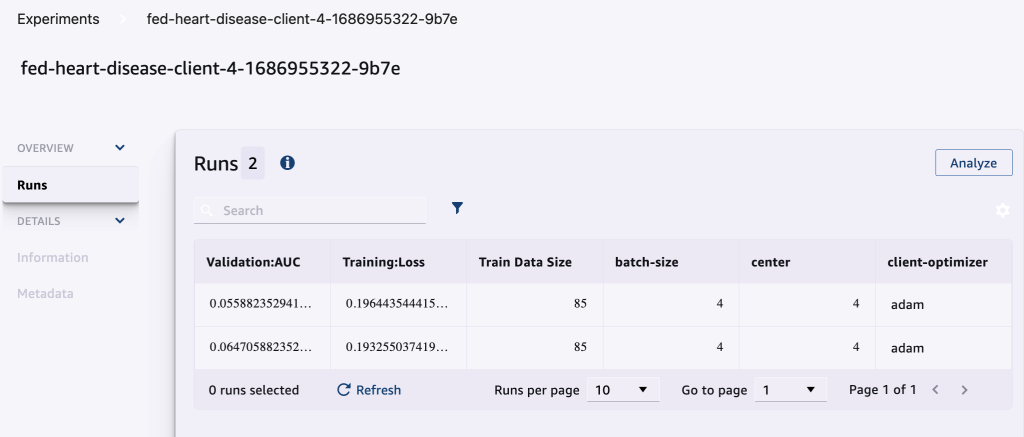
Lo screenshot seguente mostra gli esperimenti registrati.
Codice di monitoraggio dell'esperimento
In questa sezione esploriamo il codice che integra il monitoraggio degli esperimenti SageMaker con la formazione sul framework FL.
In un editor di tua scelta, apri la seguente cartella per visualizzare le modifiche al codice per inserire il codice di monitoraggio dell'esperimento SageMaker come parte della formazione:
Per monitorare la formazione, noi creare un esperimento SageMaker con parametri e metriche registrati utilizzando il file log_parameter ed log_metric comando come descritto nel seguente esempio di codice.
Una voce nel config/fedml_config.yaml file dichiara il prefisso dell'esperimento, a cui si fa riferimento nel codice per creare nomi di esperimenti univoci: sm_experiment_name: "fed-heart-disease". Puoi aggiornarlo con qualsiasi valore di tua scelta.
Ad esempio, vedere il codice seguente per il file heart_disease_trainer.py, che viene utilizzato da ciascun cliente per addestrare il modello sul proprio set di dati:
Per ogni esecuzione del cliente, i dettagli dell'esperimento vengono monitorati utilizzando il seguente codice in heart_disease_trainer.py:
Allo stesso modo, puoi utilizzare il codice in heart_disease_aggregator.py per eseguire un test sui dati locali dopo aver aggiornato i pesi del modello. I dettagli vengono registrati dopo ogni comunicazione eseguita con i client.
ripulire
Una volta completata la soluzione, assicurati di ripulire le risorse utilizzate per garantire un utilizzo efficiente delle risorse e una gestione dei costi ed evitare spese inutili e sprechi di risorse. Il riordino attivo dell'ambiente, come l'eliminazione delle istanze inutilizzate, l'arresto dei servizi non necessari e la rimozione dei dati temporanei, contribuisce a un'infrastruttura pulita e organizzata. Puoi utilizzare il seguente codice per ripulire le tue risorse:
Sommario
Utilizzando Amazon EKS come infrastruttura e FedML come framework per FL, siamo in grado di fornire un ambiente scalabile e gestito per la formazione e la distribuzione di modelli condivisi rispettando la privacy dei dati. Grazie alla natura decentralizzata di FL, le organizzazioni possono collaborare in modo sicuro, sbloccare il potenziale dei dati distribuiti e migliorare i modelli ML senza compromettere la privacy dei dati.
Come sempre, AWS accoglie con favore il tuo feedback. Per favore lascia i tuoi pensieri e domande nella sezione commenti.
Informazioni sugli autori
 Randy De Fauw è un Senior Principal Solutions Architect presso AWS. Ha conseguito un MSEE presso l'Università del Michigan, dove ha lavorato sulla visione artificiale per veicoli autonomi. Ha inoltre conseguito un MBA presso la Colorado State University. Randy ha ricoperto diversi incarichi nel settore tecnologico, dall'ingegneria del software alla gestione del prodotto. È entrato nello spazio dei big data nel 2013 e continua a esplorare quell'area. Sta lavorando attivamente a progetti nello spazio ML e ha presentato in numerose conferenze, tra cui Strata e GlueCon.
Randy De Fauw è un Senior Principal Solutions Architect presso AWS. Ha conseguito un MSEE presso l'Università del Michigan, dove ha lavorato sulla visione artificiale per veicoli autonomi. Ha inoltre conseguito un MBA presso la Colorado State University. Randy ha ricoperto diversi incarichi nel settore tecnologico, dall'ingegneria del software alla gestione del prodotto. È entrato nello spazio dei big data nel 2013 e continua a esplorare quell'area. Sta lavorando attivamente a progetti nello spazio ML e ha presentato in numerose conferenze, tra cui Strata e GlueCon.
 Arnab Sinha è un Senior Solutions Architect per AWS, che agisce come Field CTO per aiutare le organizzazioni a progettare e realizzare soluzioni scalabili che supportino i risultati aziendali attraverso le migrazioni dei data center, la trasformazione digitale e la modernizzazione delle applicazioni, i big data e l'apprendimento automatico. Ha supportato clienti in diversi settori, tra cui energia, vendita al dettaglio, produzione, sanità e scienze della vita. Arnab possiede tutte le certificazioni AWS, inclusa la certificazione di specialità ML. Prima di entrare in AWS, Arnab è stato un leader tecnologico e in precedenza ha ricoperto ruoli di leadership di architetto e ingegneria.
Arnab Sinha è un Senior Solutions Architect per AWS, che agisce come Field CTO per aiutare le organizzazioni a progettare e realizzare soluzioni scalabili che supportino i risultati aziendali attraverso le migrazioni dei data center, la trasformazione digitale e la modernizzazione delle applicazioni, i big data e l'apprendimento automatico. Ha supportato clienti in diversi settori, tra cui energia, vendita al dettaglio, produzione, sanità e scienze della vita. Arnab possiede tutte le certificazioni AWS, inclusa la certificazione di specialità ML. Prima di entrare in AWS, Arnab è stato un leader tecnologico e in precedenza ha ricoperto ruoli di leadership di architetto e ingegneria.
 Prachi Kulkarni è un Senior Solutions Architect presso AWS. La sua specializzazione è l'apprendimento automatico e sta lavorando attivamente alla progettazione di soluzioni utilizzando varie offerte di AWS ML, big data e analisi. Prachi ha esperienza in molteplici settori, tra cui sanità, benefit, vendita al dettaglio e istruzione, e ha lavorato in una serie di posizioni nell'ingegneria e architettura del prodotto, nella gestione e nel successo dei clienti.
Prachi Kulkarni è un Senior Solutions Architect presso AWS. La sua specializzazione è l'apprendimento automatico e sta lavorando attivamente alla progettazione di soluzioni utilizzando varie offerte di AWS ML, big data e analisi. Prachi ha esperienza in molteplici settori, tra cui sanità, benefit, vendita al dettaglio e istruzione, e ha lavorato in una serie di posizioni nell'ingegneria e architettura del prodotto, nella gestione e nel successo dei clienti.
 Sceriffo domatore è un Principal Solutions Architect presso AWS, con un background diversificato nel campo dei servizi di consulenza aziendale e tecnologica, che copre oltre 17 anni come Solutions Architect. Con particolare attenzione alle infrastrutture, l'esperienza di Tamer copre un ampio spettro di settori verticali, tra cui commerciale, sanitario, automobilistico, settore pubblico, produzione, petrolio e gas, servizi media e altro ancora. La sua competenza si estende a vari ambiti, come architettura cloud, edge computing, networking, storage, virtualizzazione, produttività aziendale e leadership tecnica.
Sceriffo domatore è un Principal Solutions Architect presso AWS, con un background diversificato nel campo dei servizi di consulenza aziendale e tecnologica, che copre oltre 17 anni come Solutions Architect. Con particolare attenzione alle infrastrutture, l'esperienza di Tamer copre un ampio spettro di settori verticali, tra cui commerciale, sanitario, automobilistico, settore pubblico, produzione, petrolio e gas, servizi media e altro ancora. La sua competenza si estende a vari ambiti, come architettura cloud, edge computing, networking, storage, virtualizzazione, produttività aziendale e leadership tecnica.
 Hans Nesbitt è un Senior Solutions Architect presso AWS con sede nel sud della California. Lavora con clienti negli Stati Uniti occidentali per creare architetture cloud altamente scalabili, flessibili e resilienti. Nel tempo libero gli piace passare il tempo con la famiglia, cucinare e suonare la chitarra.
Hans Nesbitt è un Senior Solutions Architect presso AWS con sede nel sud della California. Lavora con clienti negli Stati Uniti occidentali per creare architetture cloud altamente scalabili, flessibili e resilienti. Nel tempo libero gli piace passare il tempo con la famiglia, cucinare e suonare la chitarra.
 Chaoyang He è co-fondatore e CTO di FedML, Inc., una startup che opera per una comunità che crea un'intelligenza artificiale aperta e collaborativa da qualsiasi luogo e su qualsiasi scala. La sua ricerca si concentra su algoritmi, sistemi e applicazioni di machine learning distribuiti e federati. Ha conseguito il dottorato in Informatica presso la University of Southern California.
Chaoyang He è co-fondatore e CTO di FedML, Inc., una startup che opera per una comunità che crea un'intelligenza artificiale aperta e collaborativa da qualsiasi luogo e su qualsiasi scala. La sua ricerca si concentra su algoritmi, sistemi e applicazioni di machine learning distribuiti e federati. Ha conseguito il dottorato in Informatica presso la University of Southern California.
 Al Nevarez è Direttore della gestione del prodotto presso FedML. Prima di FedML, è stato group product manager presso Google e senior manager di data science presso LinkedIn. Possiede numerosi brevetti relativi ai prodotti dati e ha studiato ingegneria alla Stanford University.
Al Nevarez è Direttore della gestione del prodotto presso FedML. Prima di FedML, è stato group product manager presso Google e senior manager di data science presso LinkedIn. Possiede numerosi brevetti relativi ai prodotti dati e ha studiato ingegneria alla Stanford University.
 Salman Avestimehr è cofondatore e amministratore delegato di FedML. È stato professore preside presso la USC, direttore dell'USC-Amazon Center on Trustworthy AI e Amazon Scholar in Alexa AI. È un esperto di machine learning federato e decentralizzato, teoria dell'informazione, sicurezza e privacy. È membro dell'IEEE e ha conseguito il dottorato di ricerca in EECS presso l'UC Berkeley.
Salman Avestimehr è cofondatore e amministratore delegato di FedML. È stato professore preside presso la USC, direttore dell'USC-Amazon Center on Trustworthy AI e Amazon Scholar in Alexa AI. È un esperto di machine learning federato e decentralizzato, teoria dell'informazione, sicurezza e privacy. È membro dell'IEEE e ha conseguito il dottorato di ricerca in EECS presso l'UC Berkeley.
 Samir ragazzo è un esperto tecnologo aziendale di AWS che lavora a stretto contatto con i dirigenti di livello C dei clienti. In qualità di ex dirigente di alto livello che ha guidato trasformazioni in diverse aziende Fortune 100, Samir condivide le sue preziose esperienze per aiutare i suoi clienti ad avere successo nel loro percorso di trasformazione.
Samir ragazzo è un esperto tecnologo aziendale di AWS che lavora a stretto contatto con i dirigenti di livello C dei clienti. In qualità di ex dirigente di alto livello che ha guidato trasformazioni in diverse aziende Fortune 100, Samir condivide le sue preziose esperienze per aiutare i suoi clienti ad avere successo nel loro percorso di trasformazione.
 Stephen Kraemer è un consulente del consiglio di amministrazione e del CxO ed ex dirigente di AWS. Stephen sostiene la cultura e la leadership come basi del successo. Secondo lui, la sicurezza e l'innovazione sono i fattori trainanti della trasformazione del cloud che abilitano organizzazioni altamente competitive e basate sui dati.
Stephen Kraemer è un consulente del consiglio di amministrazione e del CxO ed ex dirigente di AWS. Stephen sostiene la cultura e la leadership come basi del successo. Secondo lui, la sicurezza e l'innovazione sono i fattori trainanti della trasformazione del cloud che abilitano organizzazioni altamente competitive e basate sui dati.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/federated-learning-on-aws-using-fedml-amazon-eks-and-amazon-sagemaker/

