Con Amazon EMR 6.15, abbiamo lanciato Formazione AWS Lake controlli di accesso a grana fine (FGAC) basati su formati Open Table Formats (OTF), tra cui Apache Hudi, Apache Iceberg e Delta Lake. Ciò consente di semplificare la sicurezza e la governance data lake transazionali fornendo controlli di accesso a autorizzazioni a livello di tabella, colonna e riga con i processi Apache Spark. Molte grandi aziende cercano di utilizzare il proprio data Lake transazionale per ottenere informazioni approfondite e migliorare il processo decisionale. Puoi creare l'architettura di una casa sul lago utilizzando Amazon EMR integrato con Lake Formation per FGAC. Questa combinazione di servizi ti consente di condurre analisi dei dati sul tuo data Lake transazionale garantendo al tempo stesso un accesso sicuro e controllato.
Il componente del server di record Amazon EMR supporta funzionalità di filtraggio dei dati a livello di tabella, colonna, riga, cella e attributo nidificato. Estende il supporto ai formati Hive, Apache Hudi, Apache Iceberg e Delta Lake sia per operazioni di lettura (inclusi viaggi nel tempo e query incrementali) che per operazioni di scrittura (su istruzioni DML come INSERT). Inoltre, con la versione 6.15, Amazon EMR introduce la protezione del controllo degli accessi per l'interfaccia web della sua applicazione come Spark History Server su cluster, Yarn Timeline Server e Yarn Resource Manager UI.
In questo post, mostriamo come implementare FGAC su Apache Hudi tabelle che utilizzano Amazon EMR integrato con Lake Formation.
Caso d'uso del Data Lake sulle transazioni
I clienti Amazon EMR utilizzano spesso i formati Open Table per supportare le transazioni ACID e le esigenze di viaggio nel tempo in un data Lake. Preservando le versioni storiche, il viaggio nel tempo del data Lake offre vantaggi quali controllo e conformità, ripristino e rollback dei dati, analisi riproducibile ed esplorazione dei dati in diversi momenti nel tempo.
Un altro caso d'uso popolare del data Lake sulle transazioni è la query incrementale. La query incrementale si riferisce a una strategia di query incentrata sull'elaborazione e sull'analisi solo dei dati nuovi o aggiornati all'interno di un data Lake dall'ultima query. L'idea chiave alla base delle query incrementali è utilizzare metadati o meccanismi di rilevamento delle modifiche per identificare i dati nuovi o modificati dall'ultima query. Identificando queste modifiche, il motore di query può ottimizzare la query per elaborare solo i dati rilevanti, riducendo significativamente i tempi di elaborazione e i requisiti di risorse.
Panoramica della soluzione
In questo post, dimostriamo come implementare FGAC su tabelle Apache Hudi utilizzando Amazon EMR Cloud di calcolo elastico di Amazon (Amazon EC2) integrato con Lake Formation. Apache Hudi è un framework data Lake transazionale open source che semplifica notevolmente l'elaborazione incrementale dei dati e lo sviluppo di pipeline di dati. Questa nuova funzionalità FGAC supporta tutti gli OTF. Oltre alla dimostrazione con Hudi qui, seguiremo altri tavoli OTF con altri blog. Noi usiamo computer portatili in Amazon Sage Maker Studio per leggere e scrivere dati Hudi tramite diverse autorizzazioni di accesso utente attraverso un cluster EMR. Ciò riflette scenari di accesso ai dati reali, ad esempio se un utente tecnico necessita dell'accesso completo ai dati per risolvere i problemi su una piattaforma dati, mentre gli analisti di dati potrebbero dover accedere solo a un sottoinsieme di tali dati che non contiene informazioni di identificazione personale (PII) ). Integrazione con Lake Formation tramite il Ruolo runtime Amazon EMR consente inoltre di migliorare il livello di sicurezza dei dati e semplifica la gestione del controllo dei dati per i carichi di lavoro Amazon EMR. Questa soluzione garantisce un ambiente sicuro e controllato per l'accesso ai dati, soddisfacendo le diverse esigenze e requisiti di sicurezza dei diversi utenti e ruoli in un'organizzazione.
Il diagramma seguente illustra l'architettura della soluzione.
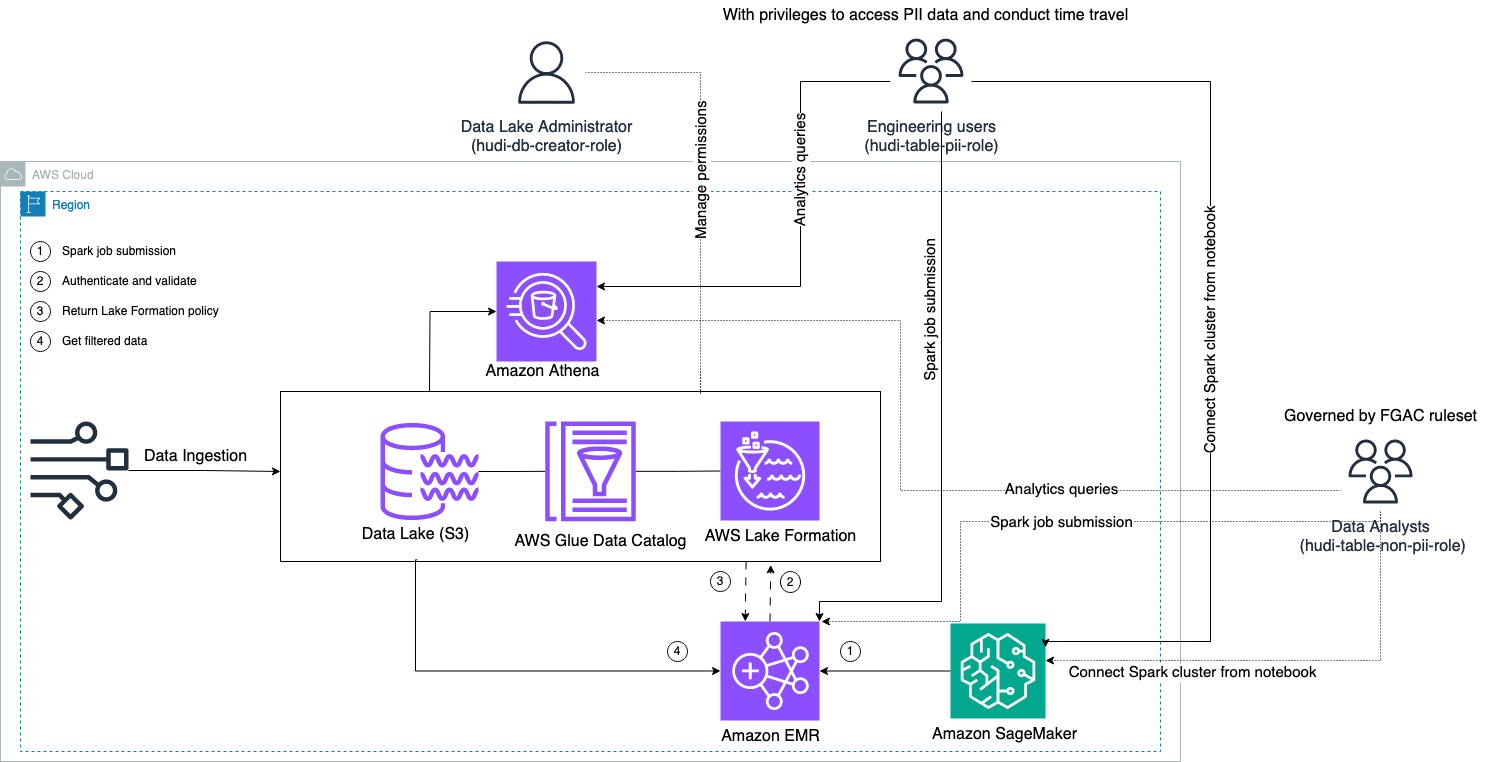
Conduciamo un processo di inserimento dei dati per aggiornare (aggiornare e inserire) un set di dati Hudi in un file Servizio di archiviazione semplice Amazon (Amazon S3) e rendere persistente o aggiornare lo schema della tabella nel file Colla AWS Catalogo dati. Con zero spostamenti di dati, possiamo interrogare la tabella Hudi governata da Lake Formation tramite vari servizi AWS, come Amazzone Atena, Amazon EMR e Amazon Sage Maker.
Quando gli utenti inviano un lavoro Spark tramite qualsiasi endpoint del cluster EMR (EMR Steps, Livy, EMR Studio e SageMaker), Lake Formation convalida i loro privilegi e indica al cluster EMR di filtrare i dati sensibili come i dati PII.
Questa soluzione ha tre diverse tipologie di utenti con diversi livelli di autorizzazione per accedere ai dati Hudi:
- ruolo-creatore-hudi-db – Viene utilizzato dall'amministratore del Data Lake che dispone dei privilegi per eseguire operazioni DDL come la creazione, la modifica e l'eliminazione di oggetti del database. Possono definire regole di filtraggio dei dati su Lake Formation per il controllo dell'accesso ai dati a livello di riga e di colonna. Queste regole FGAC garantiscono che il data Lake sia protetto e soddisfi le norme sulla privacy dei dati richieste.
- hudi-table-pii-ruolo – Viene utilizzato dagli utenti tecnici. Gli utenti ingegneristici sono in grado di eseguire viaggi nel tempo e query incrementali sia su Copy-on-Write (CoW) che su Merge-on-Read (MoR). Hanno inoltre il privilegio di accedere ai dati PII in base a eventuali timestamp.
- hudi-table-non-pii-ruolo – Viene utilizzato dagli analisti di dati. I diritti di accesso ai dati degli analisti di dati sono regolati dalle regole autorizzate dalla FGAC controllate dagli amministratori del data Lake. Non hanno visibilità sulle colonne contenenti dati PII come nomi e indirizzi. Inoltre, non possono accedere a righe di dati che non soddisfano determinate condizioni. Ad esempio, gli utenti possono accedere solo alle righe di dati che appartengono al loro Paese.
Prerequisiti
Puoi scaricare i tre taccuini utilizzati in questo post dal Repository GitHub.
Prima di distribuire la soluzione, assicurati di disporre di quanto segue:
Completa i seguenti passaggi per impostare le tue autorizzazioni:
- Accedi al tuo account AWS con l'utente IAM amministratore.
Assicurati di essere nel fileus-east-1Regione.
- Crea un bucket S3 nel file
us-east-1Regione (ad esempio,emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Successivamente, abilitiamo Lake Formation tramite modifica del modello di autorizzazione predefinito.
- Accedi alla console Lake Formation come utente amministratore.
- Scegli Impostazioni del catalogo dati per Amministrazione nel pannello di navigazione.
- Sotto Autorizzazioni predefinite per database e tabelle appena creati, deseleziona Utilizza solo il controllo degli accessi IAM per i nuovi database ed Utilizza solo il controllo degli accessi IAM per le nuove tabelle nei nuovi database.
- Scegli Risparmi.

In alternativa, devi revocare IAMAllowedPrincipals sulle risorse (database e tabelle) create se hai avviato Lake Formation con l'opzione predefinita.
Infine, creiamo una coppia di chiavi per Amazon EMR.
- Sulla console Amazon EC2, scegli Coppie di chiavi nel pannello di navigazione.
- Scegli Crea coppia di chiavi.
- Nel Nome, inserisci un nome (ad es
emr-fgac-hudi-keypair). - Scegli Crea coppia di chiavi.
La coppia di chiavi generata (per questo post, emr-fgac-hudi-keypair.pem) salverà sul tuo computer locale.
Successivamente, creiamo un AWS Cloud9 ambiente di sviluppo interattivo (IDE).
- Nella console AWS Cloud9, scegli Ambienti nel pannello di navigazione.
- Scegli Crea ambiente.
- Nel Nomeinserire un nome (ad esempio,
emr-fgac-hudi-env). - Mantieni le altre impostazioni come predefinite.
- Scegli Creare.
- Quando l'IDE è pronto, scegli Apri per aprirlo.
- Nell'IDE AWS Cloud9, su Compila il menù, scegliere Carica file locali.

- Carica il file della coppia di chiavi (
emr-fgac-hudi-keypair.pem). - Scegli il segno più e scegli Nuovo terminale.
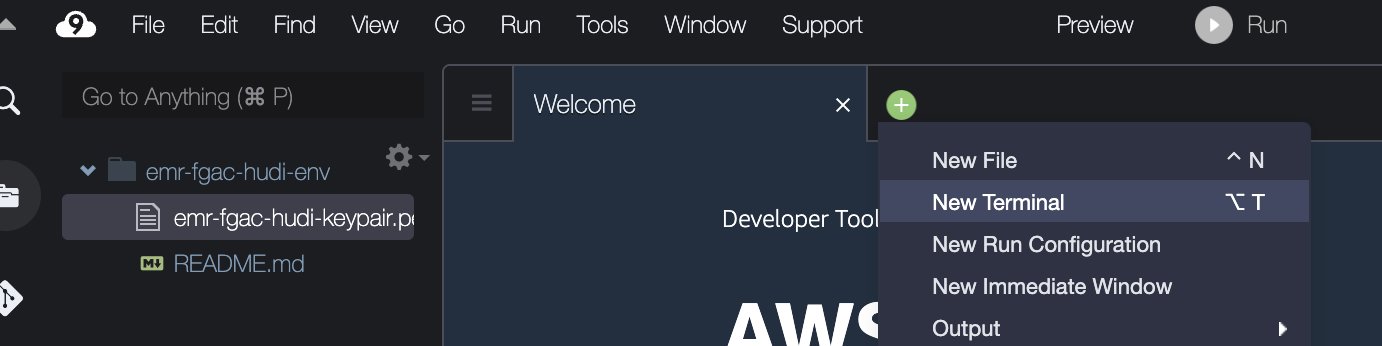
- Nel terminale, inserisci le seguenti righe di comando:
Tieni presente che il codice di esempio è una prova di concetto solo a scopo dimostrativo. Per i sistemi di produzione, utilizzare un'autorità di certificazione (CA) attendibile per emettere certificati. Fare riferimento a Fornitura di certificati per la crittografia dei dati in transito con la crittografia Amazon EMR per i dettagli.
Distribuisci la soluzione tramite AWS CloudFormation
Forniamo un file AWS CloudFormazione modello che imposta automaticamente i seguenti servizi e componenti:
- Un bucket S3 per il data Lake. Contiene il set di dati TPC-DS di esempio.
- Un cluster EMR con configurazione di sicurezza e DNS pubblico abilitato.
- Ruoli IAM runtime EMR con autorizzazioni granulari di Lake Formation:
- -hudi-db-creator-role – Questo ruolo viene utilizzato per creare database e tabelle Apache Hudi.
- -hudi-table-pii-role – Questo ruolo fornisce l'autorizzazione per interrogare tutte le colonne delle tabelle Hudi, incluse le colonne con PII.
- -hudi-table-non-pii-role – Questo ruolo fornisce l'autorizzazione per eseguire query sulle tabelle Hudi che hanno filtrato le colonne PII in base a Lake Formation.
- Ruoli di esecuzione di SageMaker Studio che consentono agli utenti di assumere i ruoli runtime EMR corrispondenti.
- Risorse di rete come VPC, sottoreti e gruppi di sicurezza.
Completare i seguenti passaggi per distribuire le risorse:
- Scegli Stack di creazione rapida per avviare lo stack CloudFormation.
- Nel Nome dello stack, inserisci un nome di stack (ad esempio,
rsv2-emr-hudi-blog). - Nel Ec2KeyPair, inserisci il nome della tua coppia di chiavi.
- Nel IdleTimeout, inserisci un timeout di inattività per il cluster EMR per evitare di pagare per il cluster quando non viene utilizzato.
- Nel InitS3Bucket, inserisci il nome del bucket S3 creato per salvare il file .zip del certificato di crittografia Amazon EMR.
- Nel S3CertsZip, inserisci l'URI S3 del file .zip del certificato di crittografia Amazon EMR.
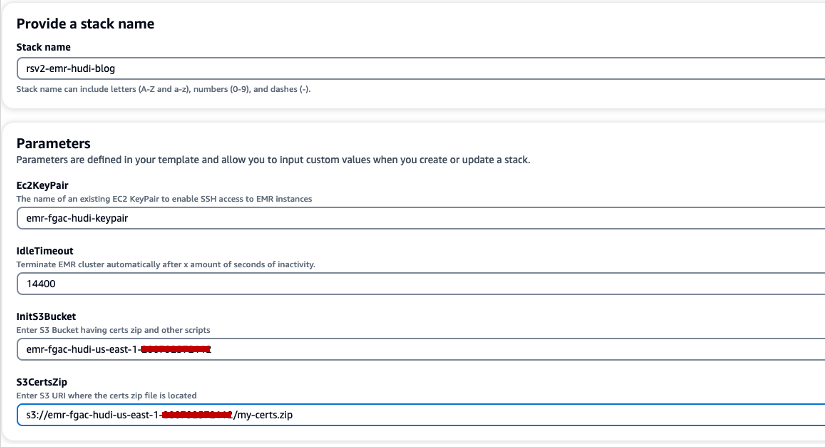
- Seleziona Riconosco che AWS CloudFormation potrebbe creare risorse IAM con nomi personalizzati.
- Scegli Crea stack.
La distribuzione dello stack CloudFormation richiede circa 10 minuti.
Configura Lake Formation per l'integrazione di Amazon EMR
Completa i seguenti passaggi per impostare Lake Formation:
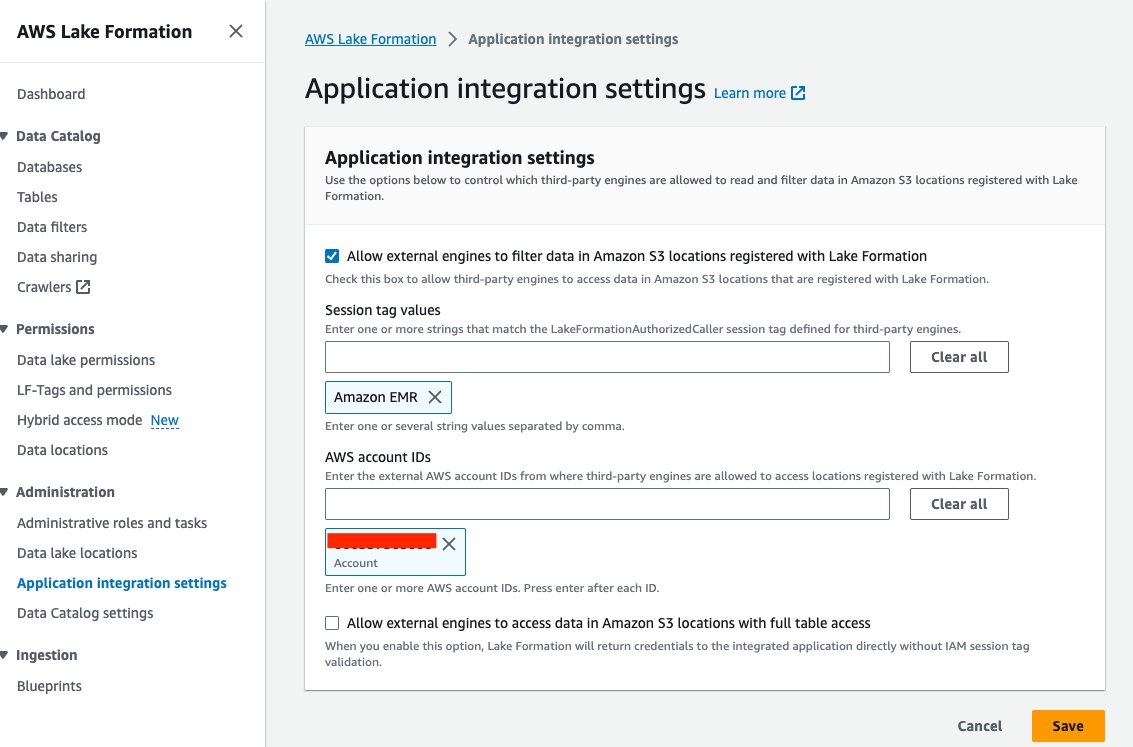
- Sulla console Lake Formation, scegli Impostazioni di integrazione dell'applicazione per Amministrazione nel pannello di navigazione.
- Seleziona Consenti ai motori esterni di filtrare i dati nelle posizioni Amazon S3 registrate con Lake Formation.
- Scegli Amazon EMR per Valori dei tag di sessione.
- Inserisci l'ID del tuo account AWS per ID account AWS.
- Scegli Risparmi.
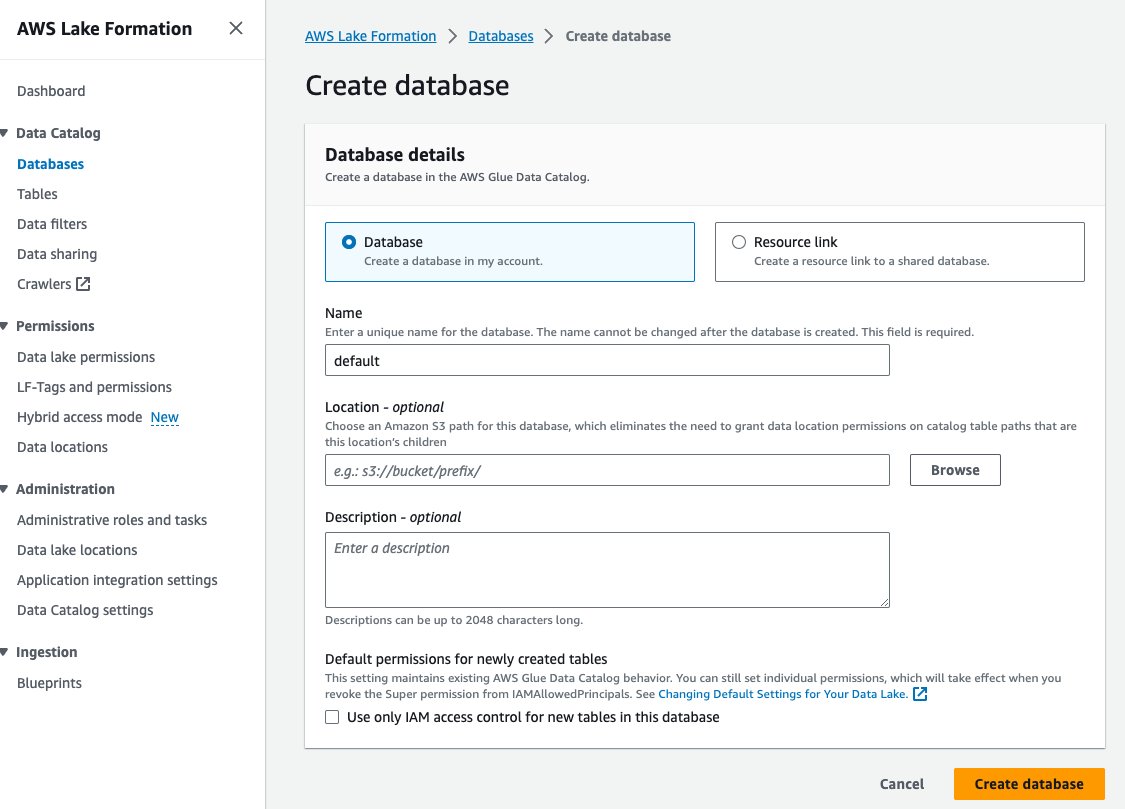
- Scegli Database per Catalogo dati nel pannello di navigazione.
- Scegli Crea database.
- Nel Nome, inserisci predefinito.
- Scegli Crea database.
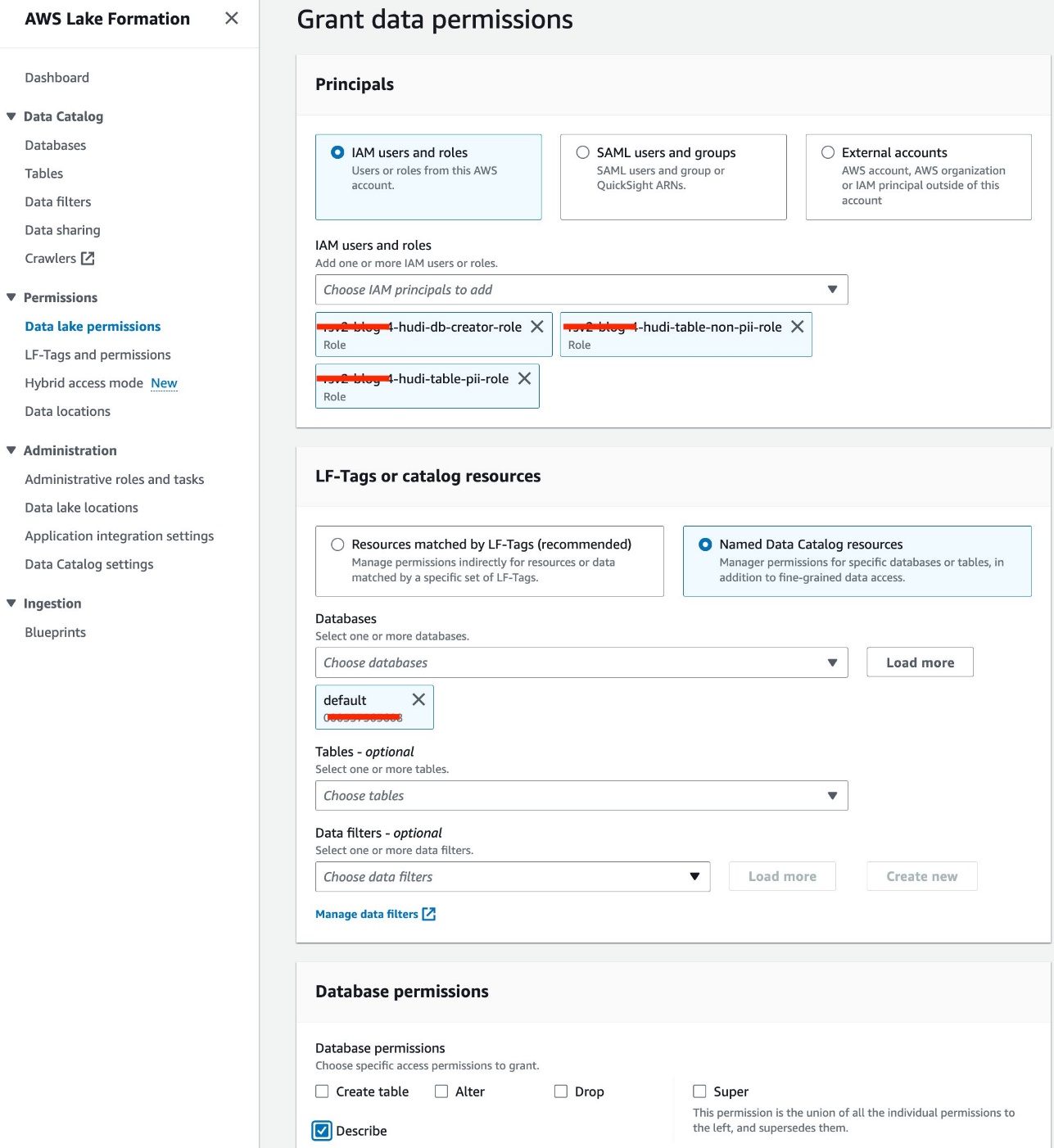
- Scegli Autorizzazioni del data lake per Permessi nel pannello di navigazione.
- Scegli Grant.
- Seleziona Utenti e ruoli IAM.
- Scegli i tuoi ruoli IAM.
- Nel Database, scegli predefinito.
- Nel Permessi del database, selezionare Descrivere.
- Scegli Grant.
Copia il file JAR Hudi su Amazon EMR HDFS
A usa Hudi con i notebook Jupyter, è necessario completare i passaggi seguenti per il cluster EMR, che includono la copia di un file JAR Hudi dalla directory locale Amazon EMR al relativo storage HDFS, in modo da poter configurare una sessione Spark per utilizzare Hudi:
- Autorizzare il traffico SSH in entrata (porta 22).
- Copia il valore per DNS pubblico del nodo primario (ad esempio, ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) dal cluster EMR Sommario .
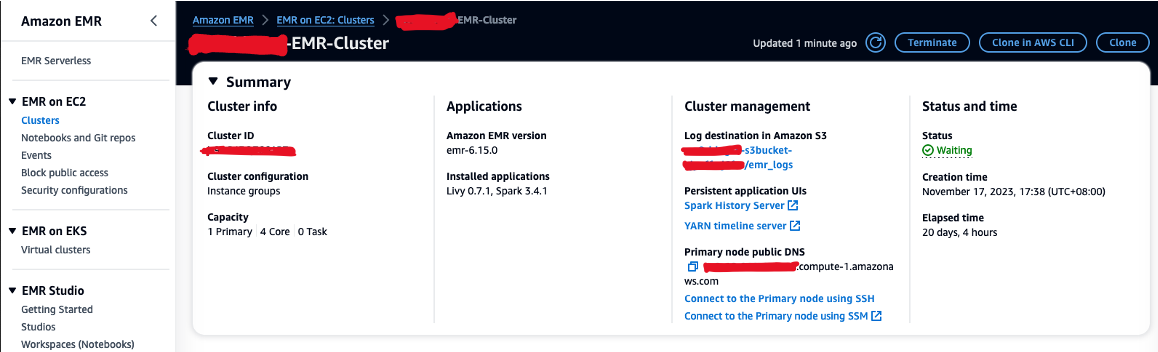
- Torna al terminale AWS Cloud9 precedente utilizzato per creare la coppia di chiavi EC2.
- Esegui il comando seguente su SSH nel nodo primario EMR. Sostituisci il segnaposto con il nome host DNS EMR:
- Esegui il comando seguente per copiare il file JAR Hudi su HDFS:
Crea il database e le tabelle Hudi in Lake Formation
Ora siamo pronti per creare il database e le tabelle Hudi con FGAC abilitato dal ruolo runtime EMR. IL Ruolo runtime EMR è un ruolo IAM che puoi specificare quando invii un lavoro o una query a un cluster EMR.
Concedere l'autorizzazione al creatore del database
Innanzitutto, concediamo al creatore del database Lake Formation l'autorizzazione a<STACK-NAME>-hudi-db-creator-role:
- Accedi al tuo account AWS come amministratore.
- Sulla console Lake Formation, scegli Ruoli e compiti amministrativi per Amministrazione nel pannello di navigazione.
- Conferma che l'utente di accesso ad AWS sia stato aggiunto come amministratore del data Lake.
- Nel Creatore di banche dati sezione, scegliere Grant.
- Nel Utenti e ruoli IAMscegli
<STACK-NAME>-hudi-db-creator-role. - Nel Permessi catalogo Catalog, selezionare Crea database.
- Scegli Grant.
Registrare la posizione del data Lake
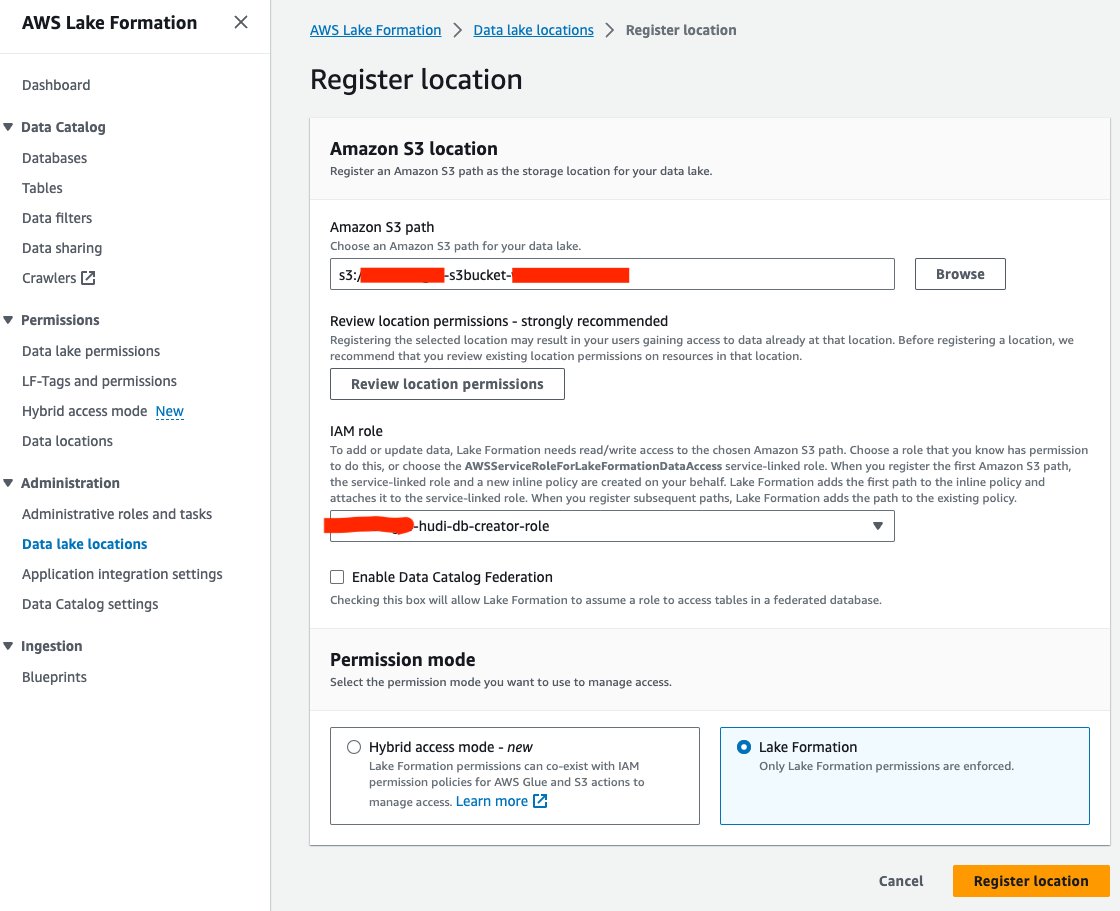
Successivamente, registriamo la posizione del data Lake S3 in Lake Formation:
- Sulla console Lake Formation, scegli Posizioni del data lake per Amministrazione nel pannello di navigazione.
- Scegli Registra posizione.
- Nel Percorso Amazon S3, Scegli Scopri la nostra gamma di prodotti e scegli il bucket Data Lake S3. (
<STACK_NAME>s3bucket-XXXXXXX) creato dallo stack CloudFormation. - Nel Ruolo IAMscegli
<STACK-NAME>-hudi-db-creator-role. - Nel Modalità di autorizzazione, selezionare Formazione del lago.
- Scegli Registra posizione.
Concedere l'autorizzazione alla localizzazione dei dati
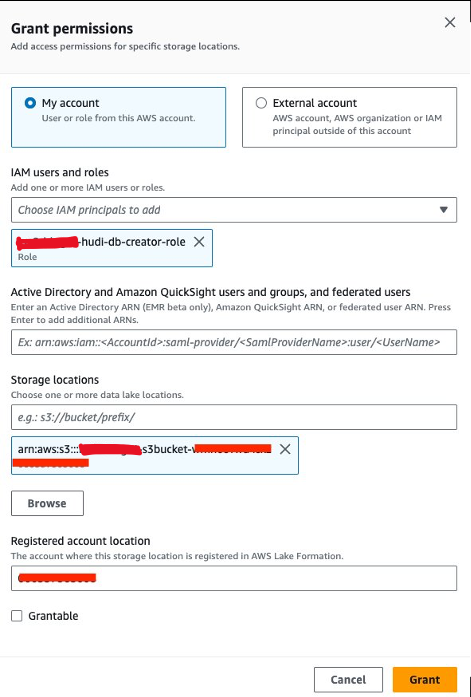
Successivamente, dobbiamo concedere<STACK-NAME>-hudi-db-creator-roleil permesso di localizzazione dei dati:
- Sulla console Lake Formation, scegli Posizioni dei dati per Permessi nel pannello di navigazione.
- Scegli Grant.
- Nel Utenti e ruoli IAMscegli
<STACK-NAME>-hudi-db-creator-role. - Nel Posizioni di stoccaggio, inserisci il bucket S3 (
<STACK_NAME>-s3bucket-XXXXXXX). - Scegli Grant.
Connettersi al cluster EMR
Ora utilizziamo un notebook Jupyter in SageMaker Studio per connetterci al cluster EMR con il ruolo runtime EMR creatore del database:
- Sulla console di SageMaker, scegli Domini nel pannello di navigazione.
- Scegli il dominio
<STACK-NAME>-Studio-EMR-LF-Hudi. - Sulla Lancio menu accanto al profilo utente
<STACK-NAME>-hudi-db-creatorscegli Studio.
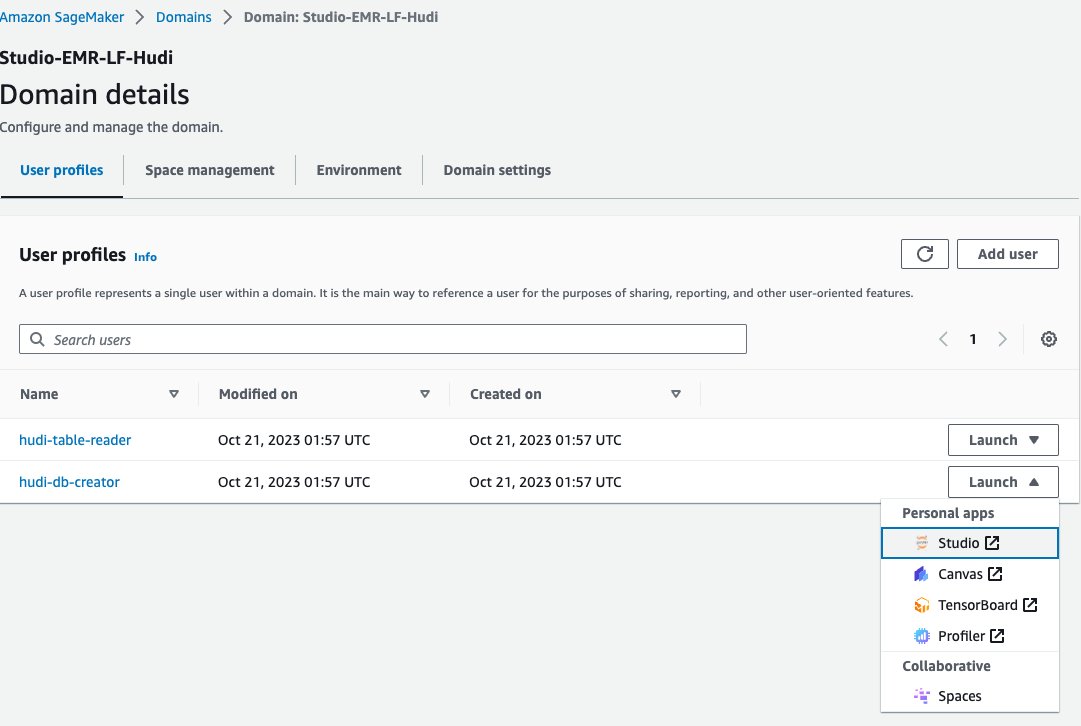
- Scarica il taccuino rsv2-hudi-db-creator-notebook.
- Scegli l'icona di caricamento.
- Scegli il taccuino Jupyter scaricato e scegli Apri.
- Apri il taccuino caricato.
- Nel Immaginescegli Spark Magic.
- Nel noccioloscegli PySpark.
- Lascia le altre configurazioni come predefinite e scegli Seleziona.

- Scegli Cluster per connettersi al cluster EMR.

- Scegli il cluster EMR sul cluster EC2 (
<STACK-NAME>-EMR-Cluster) creato con lo stack CloudFormation. - Scegli Connettiti.
- Nel Ruolo di esecuzione dell'EMRscegli
<STACK-NAME>-hudi-db-creator-role. - Scegli Connettiti.
Creare database e tabelle
Ora puoi seguire i passaggi nel notebook per creare il database e le tabelle Hudi. I passaggi principali sono i seguenti:
- Quando avvii il notebook, configura
“spark.sql.catalog.spark_catalog.lf.managed":"true"per informare Spark che spark_catalog è protetto da Lake Formation. - Crea tabelle Hudi utilizzando il seguente Spark SQL.
- Inserisci i dati dalla tabella di origine alle tabelle Hudi.
- Inserisci nuovamente i dati nelle tabelle Hudi.
Interroga le tabelle Hudi tramite Lake Formation con FGAC
Dopo aver creato il database e le tabelle Hudi, sei pronto per eseguire query sulle tabelle utilizzando il controllo degli accessi granulare con Lake Formation. Abbiamo creato due tipi di tabelle Hudi: Copy-On-Write (COW) e Merge-On-Read (MOR). La tabella COW memorizza i dati in un formato colonnare (Parquet) e ogni aggiornamento crea una nuova versione dei file durante una scrittura. Ciò significa che per ogni aggiornamento, Hudi riscrive l'intero file, il che può richiedere più risorse ma fornire prestazioni di lettura più veloci. MOR, d'altra parte, viene introdotto per i casi in cui COW potrebbe non essere ottimale, in particolare per carichi di lavoro pesanti di scrittura o modifica. In una tabella MOR, ogni volta che si verifica un aggiornamento, Hudi scrive solo la riga per il record modificato, riducendo i costi e consentendo scritture a bassa latenza. Tuttavia, le prestazioni di lettura potrebbero essere più lente rispetto alle tabelle COW.
Concedere l'autorizzazione di accesso alla tabella
Utilizziamo il ruolo IAM<STACK-NAME>-hudi-table-pii-roleper interrogare Hudi COW e MOR contenenti colonne PII. Per prima cosa concediamo l'autorizzazione di accesso alla tabella tramite Lake Formation:
- Sulla console Lake Formation, scegli Autorizzazioni del data lake per Permessi nel pannello di navigazione.
- Scegli Grant.
- Scegli
<STACK-NAME>-hudi-table-pii-roleper Utenti e ruoli IAM. - Scegliere il
rsv2_blog_hudi_db_1database per Database. - Nel tavoli, scegli le quattro tabelle Hudi che hai creato nel taccuino Jupyter.
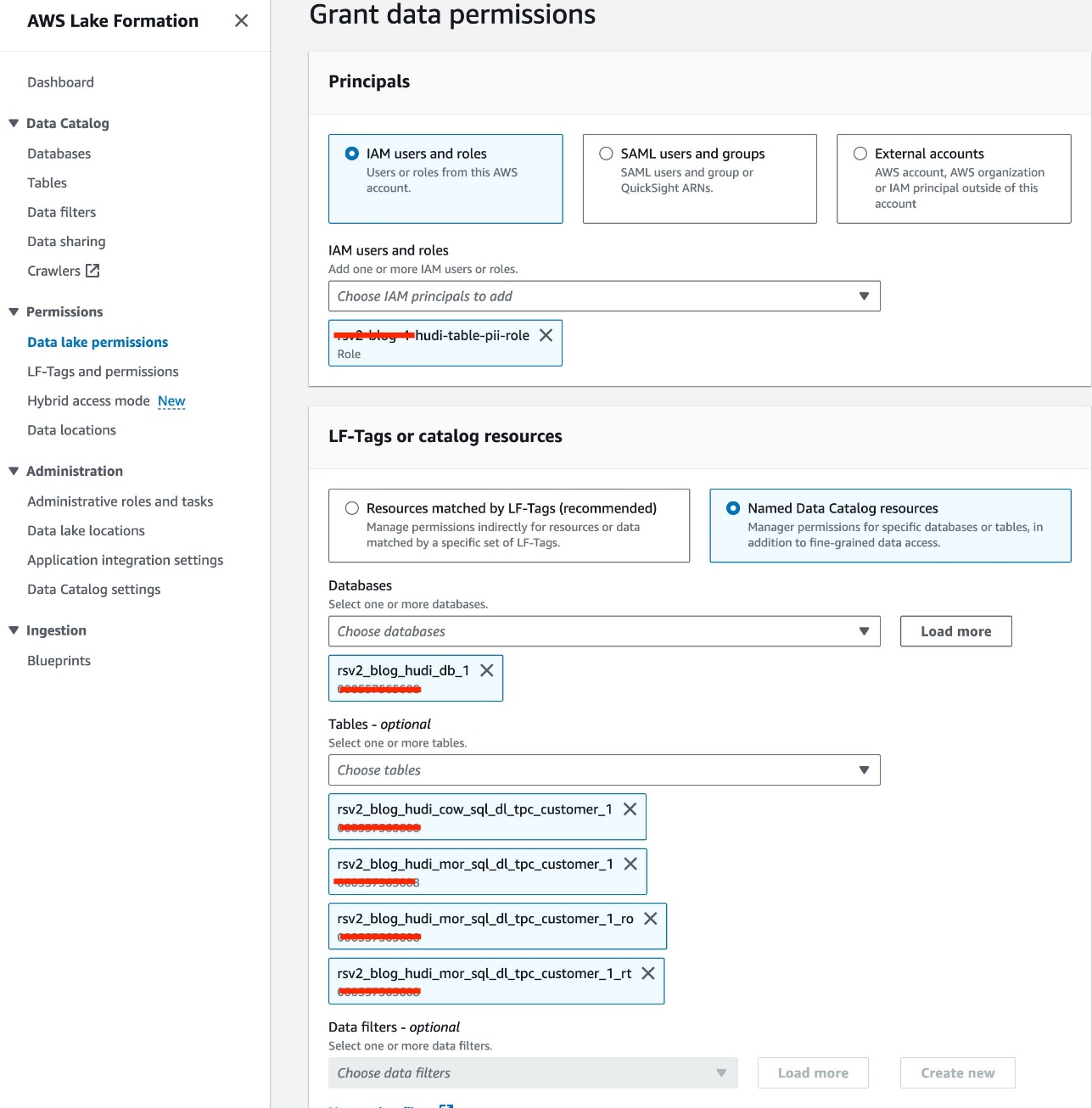
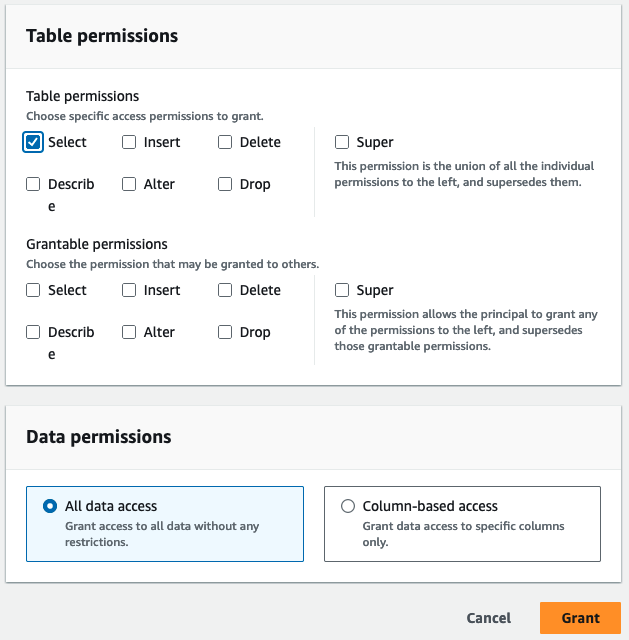
- Nel Autorizzazioni della tabella, selezionare Seleziona.
- Scegli Grant.
Interrogare le colonne PII
Ora sei pronto per eseguire il notebook per interrogare le tabelle Hudi. Seguiamo passaggi simili alla sezione precedente per eseguire il notebook in SageMaker Studio:
- Sulla console SageMaker, vai a
<STACK-NAME>-Studio-EMR-LF-Hudidominio. - Sulla Lancio menu accanto a
<STACK-NAME>-hudi-table-readerprofilo utente, scegli Studio. - Carica il taccuino scaricato rsv2-hudi-table-pii-reader-notebook.
- Apri il taccuino caricato.
- Ripeti i passaggi di configurazione del notebook e connettiti allo stesso cluster EMR, ma utilizza il ruolo
<STACK-NAME>-hudi-table-pii-role.
Nella fase attuale, il cluster EMR abilitato per FGAC deve interrogare la colonna del tempo di commit di Hudi per eseguire query incrementali e viaggi nel tempo. Non supporta la sintassi "timestamp as of" di Spark e Spark.read(). Stiamo lavorando attivamente per incorporare il supporto per entrambe le azioni nelle future versioni di Amazon EMR con FGAC abilitato.
Ora puoi seguire i passaggi nel taccuino. Di seguito sono riportati alcuni passaggi evidenziati:
- Esegui una query di istantanea.
- Esegui una query incrementale.
- Esegui una query di viaggio nel tempo.
- Esegui query sulle tabelle MOR ottimizzate per la lettura e in tempo reale.
Interroga le tabelle Hudi con filtri di dati a livello di colonna e di riga
Utilizziamo il ruolo IAM<STACK-NAME>-hudi-table-non-pii-roleper interrogare le tabelle Hudi. A questo ruolo non è consentito eseguire query su colonne contenenti PII. Utilizziamo i filtri di dati a livello di colonna e di riga di Lake Formation per implementare un controllo degli accessi granulare:
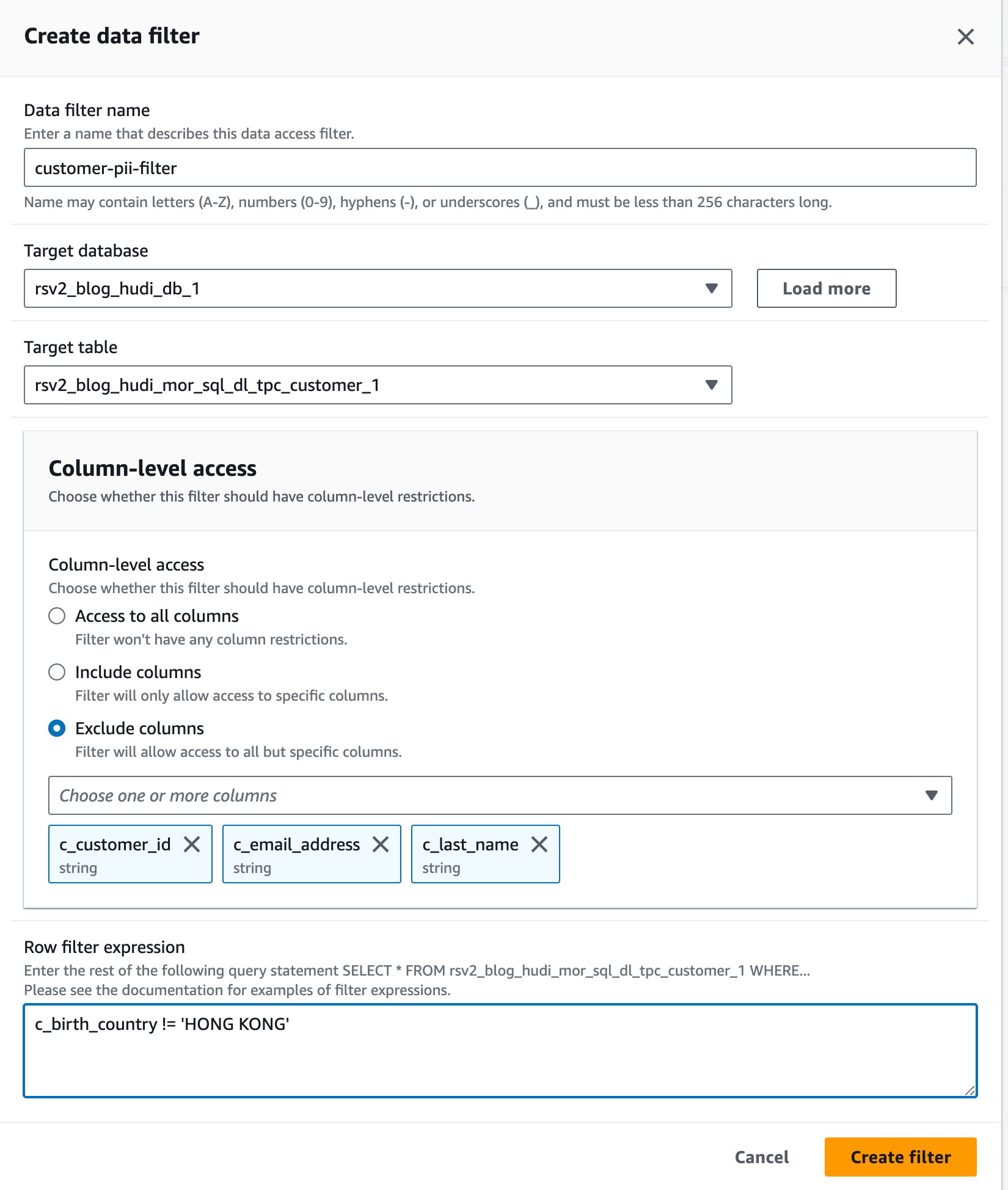
- Sulla console Lake Formation, scegli Filtri dati per Catalogo dati nel pannello di navigazione.
- Scegli Crea nuovo filtro.
- Nel Nome del filtro dati, accedere
customer-pii-filter. - Scegli
rsv2_blog_hudi_db_1per Database di destinazione. - Scegli
rsv2_blog_hudi_mor_sql_dl_customer_1per Tabella di destinazione. - Seleziona Escludi colonne e scegliere il
c_customer_id,c_email_addressec_last_namecolonne. - entrare
c_birth_country != 'HONG KONG'per Espressione del filtro di riga. - Scegli Crea un filtro.
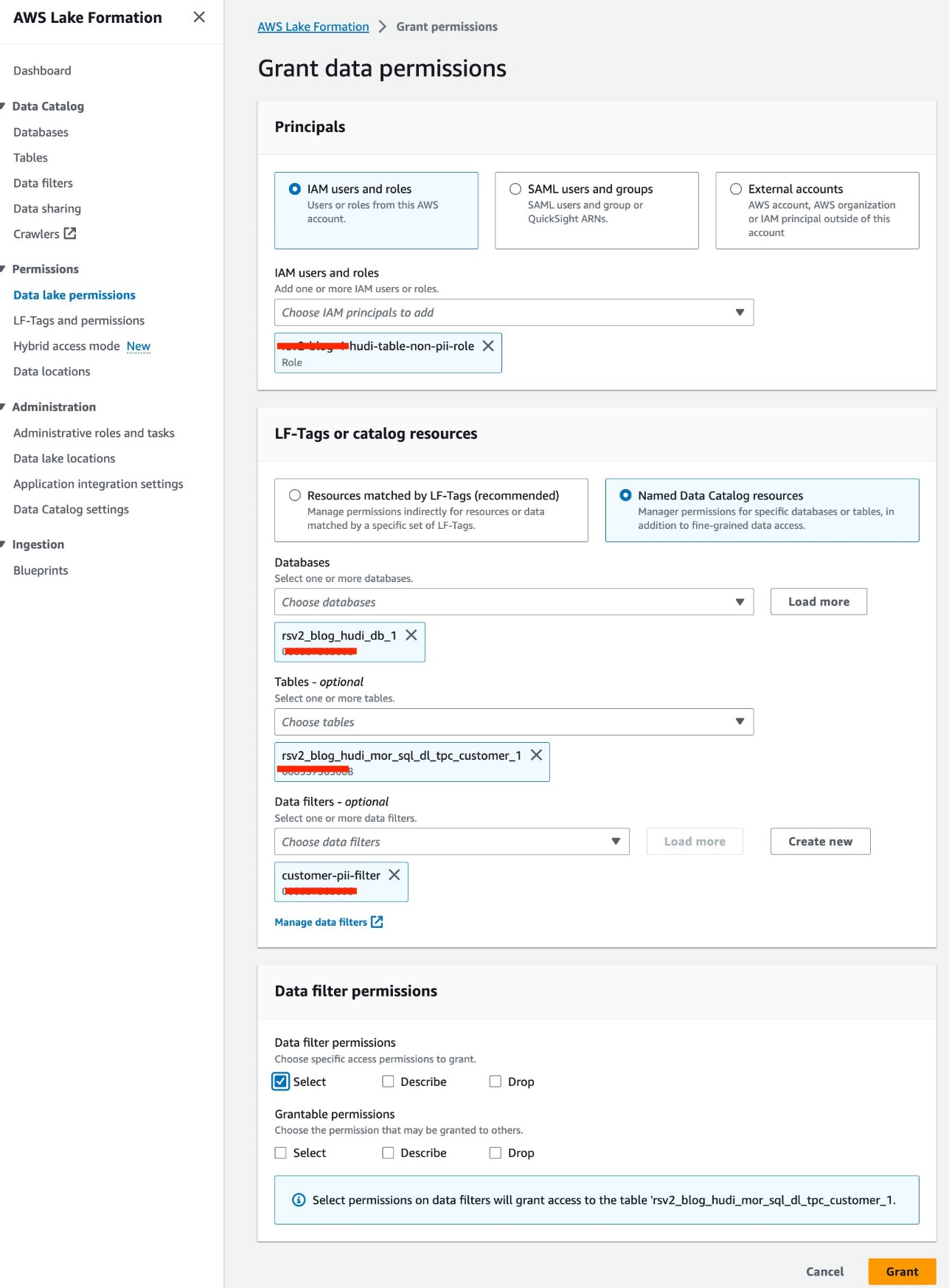
- Scegli Autorizzazioni del data lake per Permessi nel pannello di navigazione.
- Scegli Grant.
- Scegli
<STACK-NAME>-hudi-table-non-pii-roleper Utenti e ruoli IAM. - Scegli
rsv2_blog_hudi_db_1per Database. - Scegli
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1per tavoli. - Scegli
customer-pii-filterper Filtri dati. - Nel Autorizzazioni del filtro dati, selezionare Seleziona.
- Scegli Grant.
Seguiamo passaggi simili per eseguire il notebook in SageMaker Studio:
- Nella console SageMaker, vai al dominio
Studio-EMR-LF-Hudi. - Sulla Lancio menù per il
hudi-table-readerprofilo utente, scegli Studio. - Carica il taccuino scaricato rsv2-hudi-table-non-pii-reader-notebook e scegli Apri.
- Ripeti i passaggi di configurazione del notebook e connettiti allo stesso cluster EMR, ma seleziona il ruolo
<STACK-NAME>-hudi-table-non-pii-role.
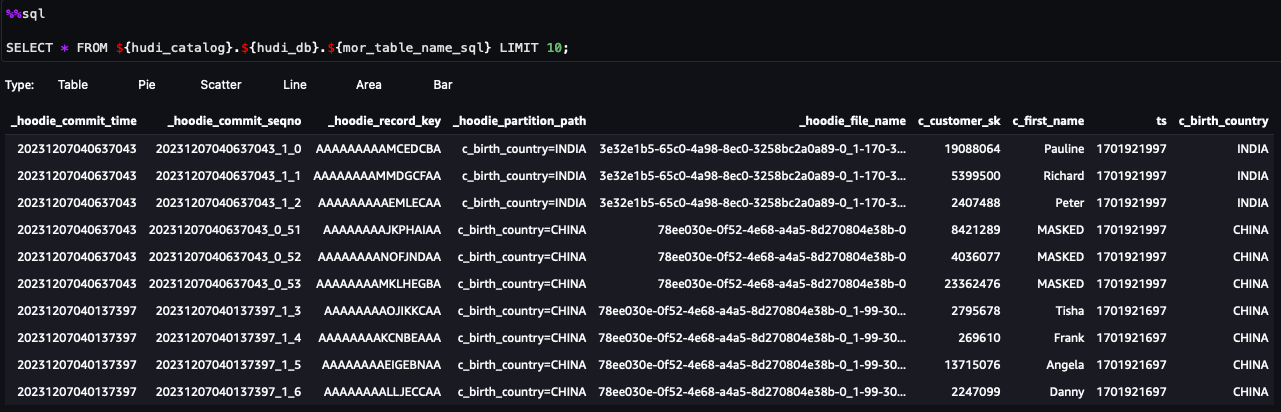
Ora puoi seguire i passaggi nel taccuino. Dai risultati della query, puoi vedere che è stato applicato FGAC tramite il filtro dati Lake Formation. Il ruolo non può vedere le colonne PIIc_customer_id,c_last_nameec_email_address. Inoltre, le righe daHONG KONGsono stati filtrati.
ripulire
Dopo aver finito di sperimentare la soluzione, ti consigliamo di ripulire le risorse con i seguenti passaggi per evitare costi imprevisti:
- Chiudi le app SageMaker Studio per i profili utente.
Il cluster EMR verrà eliminato automaticamente dopo il valore di timeout di inattività.
- Eliminare il File system elastico Amazon (Amazon EFS) creato per il dominio.
- Svuotare i secchi S3 creato dallo stack CloudFormation.
- Nella console AWS CloudFormation, elimina lo stack.
Conclusione
In questo post, abbiamo utilizzato Apachi Hudi, un tipo di tabelle OTF, per dimostrare questa nuova funzionalità per applicare un controllo degli accessi granulare su Amazon EMR. Puoi definire autorizzazioni granulari in Lake Formation per le tabelle OTF e applicarle tramite query Spark SQL sui cluster EMR. Puoi anche utilizzare funzionalità di data Lake transazionale come l'esecuzione di query snapshot, query incrementali, viaggi nel tempo e query DML. Tieni presente che questa nuova funzionalità copre tutte le tabelle OTF.
Questa funzionalità viene lanciata a partire dalla versione 6.15 di Amazon EMR Regioni dove è disponibile Amazon EMR. Con l'integrazione di Amazon EMR con Lake Formation, puoi gestire ed elaborare con sicurezza i big data, sbloccando insight e facilitando un processo decisionale informato mantenendo al contempo la sicurezza e la governance dei dati.
Per saperne di più, fare riferimento a Abilita la formazione di laghi con Amazon EMR e non esitare a contattare i tuoi AWS Solutions Architect, che possono esserti di aiuto durante il tuo percorso con i dati.
L'autore
 Raimondo Lai è un Senior Solutions Architect specializzato nel soddisfare le esigenze dei clienti di grandi imprese. La sua esperienza consiste nell'assistere i clienti nella migrazione di complessi sistemi e database aziendali su AWS, nella costruzione di piattaforme di data warehousing e data Lake aziendali. Raymond eccelle nell'identificazione e progettazione di soluzioni per casi d'uso AI/ML e si concentra in particolare sulle soluzioni AWS Serverless e sulla progettazione dell'architettura basata sugli eventi.
Raimondo Lai è un Senior Solutions Architect specializzato nel soddisfare le esigenze dei clienti di grandi imprese. La sua esperienza consiste nell'assistere i clienti nella migrazione di complessi sistemi e database aziendali su AWS, nella costruzione di piattaforme di data warehousing e data Lake aziendali. Raymond eccelle nell'identificazione e progettazione di soluzioni per casi d'uso AI/ML e si concentra in particolare sulle soluzioni AWS Serverless e sulla progettazione dell'architettura basata sugli eventi.
 Bin Wang, PhD, è un Senior Analytic Specialist Solutions Architect presso AWS, vanta oltre 12 anni di esperienza nel settore ML, con particolare attenzione alla pubblicità. Possiede esperienza nell'elaborazione del linguaggio naturale (NLP), nei sistemi di raccomandazione, in diversi algoritmi ML e nelle operazioni ML. È profondamente appassionato nell'applicazione delle tecniche ML/DL e dei big data per risolvere problemi del mondo reale.
Bin Wang, PhD, è un Senior Analytic Specialist Solutions Architect presso AWS, vanta oltre 12 anni di esperienza nel settore ML, con particolare attenzione alla pubblicità. Possiede esperienza nell'elaborazione del linguaggio naturale (NLP), nei sistemi di raccomandazione, in diversi algoritmi ML e nelle operazioni ML. È profondamente appassionato nell'applicazione delle tecniche ML/DL e dei big data per risolvere problemi del mondo reale.
 Aditya Shah è un ingegnere di sviluppo software presso AWS. È interessato ai motori di database e data warehouse e ha lavorato sull'ottimizzazione delle prestazioni, sulla conformità della sicurezza e sulla conformità ACID per motori come Apache Hive e Apache Spark.
Aditya Shah è un ingegnere di sviluppo software presso AWS. È interessato ai motori di database e data warehouse e ha lavorato sull'ottimizzazione delle prestazioni, sulla conformità della sicurezza e sulla conformità ACID per motori come Apache Hive e Apache Spark.
 Melodia Yang è Senior Big Data Solution Architect per Amazon EMR presso AWS. È una leader esperta nell'analisi dei dati che collabora con i clienti AWS per fornire indicazioni sulle best practice e consigli tecnici al fine di assisterli con successo nella trasformazione dei dati. Le sue aree di interesse sono i framework e l'automazione open source, l'ingegneria dei dati e i DataOps.
Melodia Yang è Senior Big Data Solution Architect per Amazon EMR presso AWS. È una leader esperta nell'analisi dei dati che collabora con i clienti AWS per fornire indicazioni sulle best practice e consigli tecnici al fine di assisterli con successo nella trasformazione dei dati. Le sue aree di interesse sono i framework e l'automazione open source, l'ingegneria dei dati e i DataOps.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/

