
Immagine di Freepik
L’intelligenza artificiale conversazionale si riferisce ad agenti virtuali e chatbot che imitano le interazioni umane e possono coinvolgere gli esseri umani in conversazioni. L'uso dell'intelligenza artificiale conversazionale sta rapidamente diventando uno stile di vita, dal chiedere ad Alexa di "trova il ristorante più vicino” per chiedere a Siri di "creare un promemoria", assistenti virtuali e chatbot vengono spesso utilizzati per rispondere alle domande dei consumatori, risolvere reclami, effettuare prenotazioni e molto altro ancora.
Lo sviluppo di questi assistenti virtuali richiede uno sforzo notevole. Tuttavia, comprendere e affrontare le sfide principali può semplificare il processo di sviluppo. Ho utilizzato la mia esperienza diretta nella creazione di un chatbot maturo per una piattaforma di reclutamento come punto di riferimento per spiegare le sfide chiave e le relative soluzioni.
Per creare un chatbot AI conversazionale, gli sviluppatori possono utilizzare framework come RASA, Lex di Amazon o Dialogflow di Google per creare chatbot. La maggior parte preferisce RASA quando pianificano modifiche personalizzate o il bot è nella fase matura poiché si tratta di un framework open source. Anche altri framework sono adatti come punto di partenza.
Le sfide possono essere classificate come tre componenti principali di un chatbot.
Comprensione del linguaggio naturale (NLU) è la capacità di un bot di comprendere il dialogo umano. Esegue la classificazione degli intenti, l'estrazione delle entità e il recupero delle risposte.
Responsabile del dialogo è responsabile di una serie di azioni da eseguire in base all'insieme attuale e precedente di input dell'utente. Prende l'intento e le entità come input (come parte della conversazione precedente) e identifica la risposta successiva.
Generazione del linguaggio naturale (NLG) è il processo di generazione di frasi scritte o parlate da dati dati. Inquadra la risposta, che viene poi presentata all'utente.
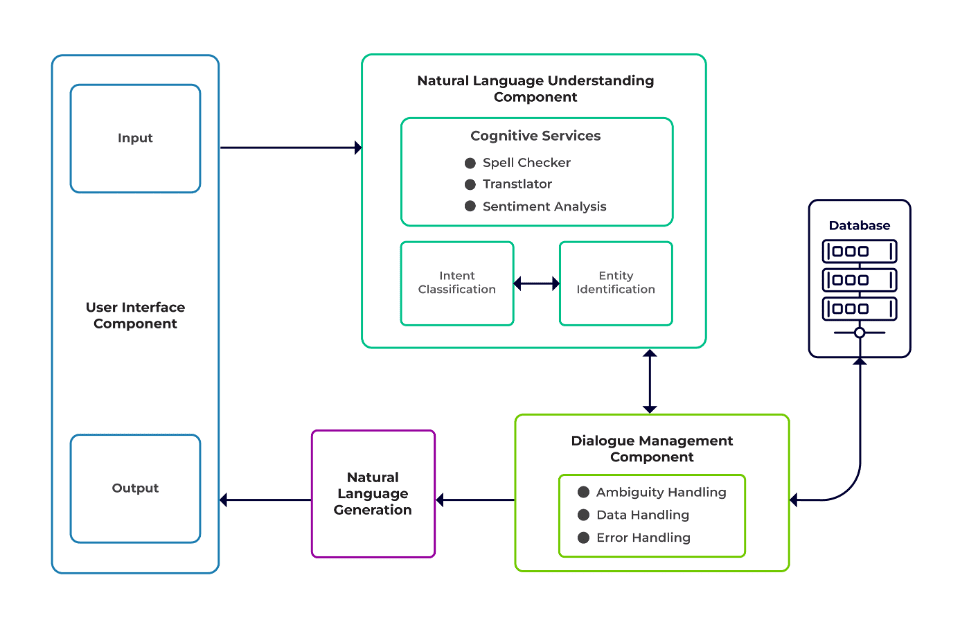
Immagine da Talentica Software
Dati insufficienti
Quando gli sviluppatori sostituiscono le FAQ o altri sistemi di supporto con un chatbot, ottengono una discreta quantità di dati di formazione. Ma lo stesso non accade quando creano il bot da zero. In questi casi, gli sviluppatori generano sinteticamente i dati di addestramento.
Cosa fare?
Un generatore di dati basato su modelli può generare una discreta quantità di query utente per la formazione. Una volta che il chatbot è pronto, i proprietari del progetto possono esporlo a un numero limitato di utenti per migliorare i dati di formazione e aggiornarli in un periodo.
Selezione del modello inadatto
La selezione del modello e i dati di addestramento appropriati sono cruciali per ottenere i migliori risultati di intento ed estrazione di entità. Gli sviluppatori solitamente addestrano i chatbot in una lingua e in un dominio specifici e la maggior parte dei modelli pre-addestrati disponibili sono spesso specifici del dominio e formati in un'unica lingua.
Possono esserci anche casi di lingue miste in cui le persone sono poliglotte. Potrebbero inserire query in una lingua mista. Ad esempio, in una regione a predominanza francese, le persone possono utilizzare un tipo di inglese che è un mix di francese e inglese.
Cosa fare?
L'utilizzo di modelli addestrati in più lingue potrebbe ridurre il problema. In questi casi può essere utile un modello pre-addestrato come LaBSE (incorporamento delle frasi Bert agnostico del linguaggio). LaBSE è formato in più di 109 lingue su un compito di somiglianza delle frasi. Il modello conosce già parole simili in una lingua diversa. Nel nostro progetto ha funzionato davvero bene.
Estrazione di entità impropria
I chatbot richiedono che le entità identifichino il tipo di dati che l'utente sta cercando. Queste entità includono ora, luogo, persona, oggetto, data, ecc. Tuttavia, i bot possono non riuscire a identificare un'entità dal linguaggio naturale:
Stesso contesto ma entità diverse. Ad esempio, i bot possono confondere un luogo come entità quando un utente digita “Nome degli studenti dell’IIT Delhi” e poi “Nome degli studenti di Bangalore”.
Scenari in cui le entità vengono previste erroneamente con scarsa confidenza. Ad esempio, un bot può identificare l'IIT Delhi come una città con scarsa sicurezza.
Estrazione parziale delle entità tramite modello di machine learning. Se un utente digita "studenti dell'IIT Delhi", il modello può identificare solo "IIT" come entità anziché "IIT Delhi".
Gli input di una sola parola senza contesto possono confondere i modelli di machine learning. Ad esempio, una parola come “Rishikesh” può significare sia il nome di una persona che quello di una città.
Cosa fare?
Aggiungere ulteriori esempi di formazione potrebbe essere una soluzione. Ma c’è un limite oltre il quale aggiungerne altro non aiuterebbe. Inoltre, è un processo infinito. Un'altra soluzione potrebbe essere quella di definire modelli regex utilizzando parole predefinite per aiutare a estrarre entità con un insieme noto di possibili valori, come città, paese, ecc.
I modelli condividono una minore confidenza ogni volta che non sono sicuri della previsione dell'entità. Gli sviluppatori possono utilizzarlo come trigger per chiamare un componente personalizzato in grado di correggere l'entità con scarsa sicurezza. Consideriamo l’esempio sopra. Se IIT Delhi viene prevista come città con bassa confidenza, l'utente può sempre cercarla nel database. Dopo aver fallito nel trovare l'entità prevista nel file Città table, il modello procederebbe ad altre tabelle e, infine, lo troverebbe in Istituto tabella, con conseguente correzione dell'entità.
Classificazione delle intenzioni errata
A ogni messaggio utente è associato un intento. Poiché gli intenti derivano la successiva serie di azioni di un bot, è fondamentale classificare correttamente le query degli utenti con l'intento. Tuttavia, gli sviluppatori devono identificare gli intenti riducendo al minimo la confusione tra gli intenti. Altrimenti ci possono essere casi in cui si crea confusione. Per esempio, "Mostrami le posizioni aperte” contro “Mostrami i candidati per le posizioni aperte”.
Cosa fare?
Esistono due modi per differenziare le query confuse. In primo luogo, uno sviluppatore può introdurre un sottointento. In secondo luogo, i modelli possono gestire query in base alle entità identificate.
Un chatbot specifico per un dominio dovrebbe essere un sistema chiuso in cui dovrebbe identificare chiaramente di cosa è capace e cosa no. Gli sviluppatori devono eseguire lo sviluppo in fasi durante la pianificazione di chatbot specifici del dominio. In ogni fase, possono identificare le funzionalità non supportate del chatbot (tramite intenti non supportati).
Possono anche identificare ciò che il chatbot non può gestire con intenti "fuori ambito". Ma potrebbero esserci casi in cui il bot viene confuso con intenti non supportati e fuori ambito. Per tali scenari, dovrebbe essere predisposto un meccanismo di fallback in cui, se la confidenza dell’intento è inferiore a una soglia, il modello può funzionare correttamente con un intento di fallback per gestire i casi di confusione.
Una volta che il bot identifica l’intento del messaggio di un utente, deve inviare una risposta. Il bot decide la risposta in base a un determinato insieme di regole e storie definite. Ad esempio, una regola può essere semplice quanto assoluta "Buongiorno" quando l'utente saluta "CIAO". Tuttavia, molto spesso, le conversazioni con i chatbot comprendono interazioni successive e le loro risposte dipendono dal contesto generale della conversazione.
Cosa fare?
Per gestire ciò, i chatbot vengono alimentati con esempi di conversazioni reali chiamate Storie. Tuttavia, gli utenti non sempre interagiscono come previsto. Un chatbot maturo dovrebbe gestire con garbo tutte queste deviazioni. Designer e sviluppatori possono garantirlo se non si concentrano solo su un percorso felice mentre scrivono storie, ma lavorano anche su percorsi infelici.
Il coinvolgimento degli utenti con i chatbot dipende in larga misura dalle risposte dei chatbot. Gli utenti potrebbero perdere interesse se le risposte sono troppo robotiche o troppo familiari. Ad esempio, a un utente potrebbe non piacere una risposta come "Hai digitato una query sbagliata" per un input sbagliato anche se la risposta è corretta. La risposta qui non corrisponde alla persona di un assistente.
Cosa fare?
Il chatbot funge da assistente e dovrebbe possedere una personalità e un tono di voce specifici. Dovrebbero essere accoglienti e umili e gli sviluppatori dovrebbero progettare conversazioni ed espressioni di conseguenza. Le risposte non dovrebbero sembrare robotiche o meccaniche. Ad esempio, il bot potrebbe dire: "Mi dispiace, sembra che non abbia dettagli. Potresti per favore riscrivere la tua query?" per affrontare un input sbagliato.
I chatbot basati su LLM (Large Language Model) come ChatGPT e Bard rappresentano innovazioni rivoluzionarie e hanno migliorato le capacità delle IA conversazionali. Non solo sono bravi a realizzare conversazioni aperte simili a quelle umane, ma possono svolgere diversi compiti come il riepilogo del testo, la scrittura di paragrafi, ecc., che in precedenza potevano essere raggiunti solo da modelli specifici.
Una delle sfide con i tradizionali sistemi di chatbot è classificare ogni frase in intenti e decidere la risposta di conseguenza. Questo approccio non è pratico. Risposte come "Mi dispiace, non sono riuscito a capirti" sono spesso irritanti. I sistemi di chatbot senza intenti sono la via da seguire e gli LLM possono renderlo realtà.
I LLM possono facilmente ottenere risultati all'avanguardia nel riconoscimento generale delle entità denominate, escludendo determinati riconoscimenti di entità specifiche del dominio. Un approccio misto all'utilizzo dei LLM con qualsiasi framework di chatbot può ispirare un sistema di chatbot più maturo e robusto.
Con gli ultimi progressi e la continua ricerca nell'intelligenza artificiale conversazionale, i chatbot migliorano ogni giorno. Aree come la gestione di compiti complessi con molteplici intenti, come “Prenotare un volo per Mumbai e organizzare un taxi per Dadar”, stanno ricevendo molta attenzione.
Presto avverranno conversazioni personalizzate in base alle caratteristiche dell'utente per mantenere l'utente coinvolto. Ad esempio, se un bot scopre che l'utente è infelice, reindirizza la conversazione a un agente reale. Inoltre, con il costante aumento dei dati dei chatbot, le tecniche di deep learning come ChatGPT possono generare automaticamente risposte alle query utilizzando una knowledge base.
Suman Saurav è un Data Scientist presso Talentica Software, una società di sviluppo di prodotti software. È un alunno di NIT Agartala con oltre 8 anni di esperienza nella progettazione e implementazione di soluzioni AI rivoluzionarie utilizzando PNL, AI conversazionale e AI generativa.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them

