Az alapmodellek (FM-ek) nagyméretű gépi tanulási (ML) modellek, amelyeket a címkézetlen és általánosított adatkészletek széles spektrumára képeznek. Az FM-ek, ahogy a neve is sugallja, alapot adnak speciálisabb downstream alkalmazások készítéséhez, és egyediek az alkalmazkodóképességükben. Különféle feladatok széles skáláját tudják ellátni, például természetes nyelvi feldolgozást, képek osztályozását, trendek előrejelzését, hangulatelemzést és kérdések megválaszolását. Ez a lépték és az általános célú alkalmazkodóképesség különbözteti meg az FM-eket a hagyományos ML-modellektől. Az FM-ek multimodálisak; különböző adattípusokkal dolgoznak, például szöveggel, videóval, hanggal és képekkel. A nagy nyelvi modellek (LLM-ek) az FM egy fajtája, és hatalmas mennyiségű szöveges adatra vannak előképzettek, és jellemzően olyan alkalmazási területeket használnak, mint a szöveggenerálás, az intelligens chatbotok vagy az összegzés.
Az adatok streamelése elősegíti a változatos és naprakész információk folyamatos áramlását, javítva a modellek azon képességét, hogy alkalmazkodjanak és pontosabb, kontextuálisan releváns kimeneteket generáljanak. A streaming adatok dinamikus integrációja lehetővé teszi generatív AI alkalmazások, hogy azonnal reagáljanak a változó körülményekre, javítva alkalmazkodóképességüket és általános teljesítményüket a különböző feladatokban.
Ennek jobb megértéséhez képzeljünk el egy chatbotot, amely segít az utazóknak lefoglalni az utazást. Ebben a forgatókönyvben a chatbotnak valós idejű hozzáférésre van szüksége a légitársaság készletéhez, a járatok állapotához, a szállodai készlethez, a legutóbbi árváltozásokhoz és még sok máshoz. Ezek az adatok általában harmadik felektől származnak, és a fejlesztőknek meg kell találniuk a módját, hogy feldolgozzák ezeket az adatokat, és feldolgozzák az adatok változásait.
A kötegelt feldolgozás nem a legmegfelelőbb ebben a forgatókönyvben. Amikor az adatok gyorsan változnak, a kötegelt feldolgozás azt eredményezheti, hogy a chatbot elavult adatokat használ fel, pontatlan információkat szolgáltatva az ügyfélnek, ami kihat az általános ügyfélélményre. Az adatfolyam-feldolgozás azonban lehetővé teheti a chatbot számára, hogy valós idejű adatokhoz férhessen hozzá, és alkalmazkodjon a rendelkezésre állás és az ár változásaihoz, így a legjobb útmutatást nyújtja az ügyfélnek, és javítja az ügyfélélményt.
Egy másik példa egy mesterséges intelligencia által vezérelt megfigyelési és megfigyelési megoldás, ahol az FM-ek valós idejű belső mérőszámokat figyelnek a rendszerben, és riasztásokat állítanak elő. Ha a modell anomáliát vagy rendellenes metrikaértéket talál, azonnal riasztást kell küldenie, és értesítenie kell a kezelőt. Az ilyen fontos adatok értéke azonban idővel jelentősen csökken. Ezeket az értesítéseket ideális esetben másodperceken belül meg kell kapni, vagy akár közben is. Ha az üzemeltetők percekkel vagy órákkal azután kapják meg ezeket az értesítéseket, hogy megtörténtek, az ilyen betekintés nem használható fel, és potenciálisan elvesztette értékét. Hasonló felhasználási eseteket találhat más iparágakban is, például a kiskereskedelemben, az autógyártásban, az energetikában és a pénzügyi ágazatban.
Ebben a bejegyzésben megvitatjuk, hogy valós idejű jellege miatt miért az adatfolyamok kulcsfontosságú összetevője a generatív AI-alkalmazásoknak. Megbeszéljük az AWS adatfolyam-szolgáltatások értékét, mint pl Amazon által kezelt adatfolyam az Apache Kafka számára (Amazon MSK), Amazon Kinesis adatfolyamok, Amazon által felügyelt szolgáltatás az Apache Flink számáraés Amazon Kinesis Data Firehose generatív AI alkalmazások építésében.
Kontextusban tanulás
Az LLM-ek pont-időbeli adatokkal vannak kiképezve, és nem képesek hozzáférni a friss adatokhoz a következtetés időpontjában. Amint új adatok jelennek meg, folyamatosan finomhangolni vagy tovább kell tanítani a modellt. Ez nem csak költséges művelet, de a gyakorlatban nagyon korlátozó is, mert az új adatgenerálás sebessége messze felülmúlja a finomhangolás sebességét. Ezenkívül az LLM-ek nem ismerik a kontextust, és kizárólag a képzési adataikra hagyatkoznak, ezért hajlamosak a hallucinációkra. Ez azt jelenti, hogy gördülékeny, koherens és szintaktikailag megbízható, de tényszerűen helytelen választ generálhatnak. Emellett hiányzik a relevancia, a személyre szabottság és a kontextus.
Az LLM-ek azonban képesek tanulni a kontextusból kapott adatokból, hogy pontosabban válaszoljanak a modell súlyainak módosítása nélkül. Ezt nevezik kontextusban tanulás, és személyre szabott válaszok készítésére vagy pontos válaszadásra használható a szervezeti szabályzatokkal összefüggésben.
Például egy chatbotban az adatesemények vonatkozhatnak a járatok és szállodák leltárára vagy az árváltozásokra, amelyeket folyamatosan egy adatfolyam-tároló motorba töltenek be. Ezenkívül az adatesemények szűrése, gazdagítása és fogyasztási formátumba történő átalakítása adatfolyam-processzor segítségével történik. Az eredmény az alkalmazás számára elérhetővé válik a legfrissebb pillanatkép lekérdezésével. A pillanatkép folyamatosan frissül az adatfolyam-feldolgozás révén; ezért a naprakész adatokat a modellhez küldött felhasználói prompt keretében biztosítjuk. Ez lehetővé teszi a modell számára, hogy alkalmazkodjon a legújabb ár- és elérhetőségi változásokhoz. A következő diagram egy alapvető kontextuson belüli tanulási munkafolyamatot mutat be.
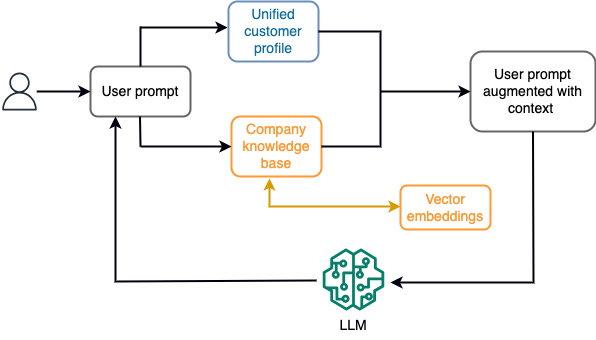
Egy általánosan használt kontextuson belüli tanulási megközelítés a Retrieval Augmented Generation (RAG) nevű technika alkalmazása. A RAG-ban megadja a releváns információkat, például a legfontosabb irányelveket és az ügyfélrekordokat, a felhasználói kérdéssel együtt. Ily módon az LLM választ generál a felhasználói kérdésre a kontextusként megadott további információk felhasználásával. Ha többet szeretne megtudni a RAG-ról, lásd: Kérdések megválaszolása a Retrieval Augmented Generation segítségével alapmodellekkel az Amazon SageMaker JumpStartban.
Egy RAG-alapú generatív AI-alkalmazás csak a képzési adatai és a tudásbázisban lévő releváns dokumentumok alapján tud általános válaszokat adni. Ez a megoldás elmarad, ha közel valós idejű, személyre szabott választ várnak az alkalmazástól. Például egy utazási csevegőbotnak figyelembe kell vennie a felhasználó aktuális foglalásait, a rendelkezésre álló szálloda- és repülőjegy-készletet stb. Ezen túlmenően az érintett ügyfél személyes adatai (közismert nevén a egységes ügyfélprofil) rendszerint változhat. Ha kötegelt folyamatot alkalmaznak a generatív mesterséges intelligencia felhasználói profiladatbázisának frissítésére, az ügyfél nem kielégítő válaszokat kaphat a régi adatok alapján.
Ebben a bejegyzésben az adatfolyam-feldolgozás alkalmazását tárgyaljuk egy olyan RAG-megoldás fejlesztésére, amelyet a kérdések megválaszoló ügynökeinek kontextussal való felépítésére használnak a valós idejű hozzáféréstől az egységes ügyfélprofilokig és a szervezeti tudásbázisig.
Közel valós idejű ügyfélprofil frissítések
Az ügyfélrekordokat általában a szervezeten belüli adattárak között osztják el. Ahhoz, hogy az Ön generatív AI-alkalmazása releváns, pontos és naprakész ügyfélprofilt biztosítson, létfontosságú olyan streaming adatfolyamokat építeni, amelyek identitásfeloldást és profil-összesítést végezhetnek az elosztott adattárak között. A streamelési feladatok folyamatosan új adatokat vesznek fel a rendszerek közötti szinkronizáláshoz, és hatékonyabban hajthatnak végre dúsítást, átalakításokat, összekapcsolásokat és aggregációkat az időablakok között. A módosítási adatrögzítés (CDC) események információkat tartalmaznak a forrásrekordról, a frissítésekről és a metaadatokról, például az időről, a forrásról, a besorolásról (beszúrás, frissítés vagy törlés), valamint a módosítás kezdeményezőjéről.
A következő diagram egy példa munkafolyamatot mutat be a CDC adatfolyamok feldolgozásához és feldolgozásához az egyesített ügyfélprofilokhoz.

Ebben a részben a RAG-alapú generatív mesterségesintelligencia-alkalmazások támogatásához szükséges CDC streaming minta fő összetevőit tárgyaljuk.
CDC adatfolyam feldolgozás
A CDC-replikátor egy olyan folyamat, amely összegyűjti az adatváltozásokat a forrásrendszerből (általában tranzakciós naplók vagy binlogok olvasásával), és pontosan ugyanabban a sorrendben írja ki a CDC-eseményeket, mint a streaming adatfolyamban vagy témakörben. Ez magában foglalja a napló alapú rögzítést olyan eszközökkel, mint pl AWS adatbázis-migrációs szolgáltatás (AWS DMS) vagy nyílt forráskódú csatlakozók, például Debezium for Apache Kafka csatlakoznak. Az Apache Kafka Connect az Apache Kafka környezet része, amely lehetővé teszi az adatok különböző forrásokból történő feldolgozását és különféle célállomásokra való eljuttatását. Futtathatja az Apache Kafka csatlakozóját Amazon MSK Connect percek alatt, anélkül, hogy aggódnia kellene az Apache Kafka-fürt konfigurációja, beállítása és működtetése miatt. Csak a csatlakozási szoftver összeállított kódját kell feltöltenie ide Amazon egyszerű tárolási szolgáltatás (Amazon S3), és állítsa be a csatlakozót a munkaterhelés-specifikus konfigurációval.
Vannak más módszerek is az adatváltozások rögzítésére. Például, Amazon DynamoDB szolgáltatást biztosít a CDC adatok streameléséhez Amazon DynamoDB Streams vagy Kinesis Data Streams. Az Amazon S3 triggert biztosít az an AWS Lambda funkció új dokumentum tárolásakor.
Streaming tárhely
A streaming tárolás közbenső pufferként működik a CDC események tárolására, mielőtt azok feldolgozásra kerülnének. A streaming tárolás megbízható tárolást biztosít a streaming adatok számára. Tervezésénél fogva rendkívül elérhető és ellenálló a hardver- vagy csomóponti hibákkal szemben, és fenntartja az események sorrendjét a leírtak szerint. A streaming tárhely folyamatosan vagy meghatározott ideig tárolhatja az adateseményeket. Ez lehetővé teszi az adatfolyam-processzorok számára, hogy az adatfolyam egy részéből olvassanak, ha meghibásodás vagy újrafeldolgozásra van szükség. A Kinesis Data Streams egy szerver nélküli streaming adatszolgáltatás, amely egyszerűvé teszi az adatfolyamok nagyarányú rögzítését, feldolgozását és tárolását. Az Amazon MSK egy teljesen felügyelt, magasan elérhető és biztonságos szolgáltatás, amelyet az AWS biztosít az Apache Kafka futtatásához.
Stream feldolgozás
Az adatfolyam-feldolgozó rendszereket párhuzamosságra kell tervezni, hogy nagy adatátviteli sebességet tudjanak kezelni. Fel kell osztaniuk a bemeneti adatfolyamot több, több számítási csomóponton futó feladat között. A feladatoknak képesnek kell lenniük arra, hogy az egyik művelet eredményét elküldjék a következőre a hálózaton keresztül, lehetővé téve az adatok párhuzamos feldolgozását olyan műveletek végrehajtása közben, mint az összekapcsolás, szűrés, gazdagítás és aggregálás. Az adatfolyam-feldolgozó alkalmazásoknak képesnek kell lenniük az események feldolgozására az eseményidő tekintetében olyan használati esetekben, amikor az események későn érkezhetnek meg, vagy a helyes számítás az események bekövetkezésének idejére, nem pedig a rendszeridőre támaszkodik. További információkért lásd: Időfogalmak: eseményidő és feldolgozási idő.
Az adatfolyam-folyamatok folyamatosan hoznak eredményt adatesemények formájában, amelyeket ki kell adni a célrendszernek. Célrendszer lehet bármely olyan rendszer, amely közvetlenül integrálható a folyamatba, vagy streaming tárolón keresztül, mint közvetítőként. Az adatfolyam-feldolgozáshoz választott keretrendszertől függően a rendelkezésre álló nyelőcsatlakozóktól függően különböző lehetőségek állnak rendelkezésre a célrendszerekhez. Ha úgy dönt, hogy az eredményeket egy közvetítő adatfolyam-tárolóra írja, létrehozhat egy külön folyamatot, amely beolvassa az eseményeket és alkalmazza a módosításokat a célrendszeren, például egy Apache Kafka fogadó-összekötőt futtat. Függetlenül attól, hogy melyik opciót választja, a CDC-adatok természetüknél fogva extra kezelést igényelnek. Mivel a CDC események információkat hordoznak a frissítésekről vagy törlésekről, fontos, hogy a megfelelő sorrendben egyesüljenek a célrendszerben. Ha a módosításokat rossz sorrendben alkalmazza, a célrendszer nem lesz szinkronban a forrásával.
Apache Flash egy hatékony adatfolyam-feldolgozó keretrendszer, amely alacsony késleltetéséről és nagy áteresztőképességéről ismert. Támogatja az eseményidő-feldolgozást, a pontosan egyszeri feldolgozás szemantikáját és a magas hibatűrést. Ezenkívül natív támogatást biztosít a CDC adatokhoz egy speciális struktúrán keresztül dinamikus táblázatok. A dinamikus táblák utánozzák a forrásadatbázis-táblázatokat, és oszlopos megjelenítést biztosítanak a streaming adatokról. A dinamikus táblákban lévő adatok minden feldolgozott eseménnyel változnak. Az új rekordok bármikor hozzáfűzhetők, frissíthetők vagy törölhetők. A dinamikus táblák elvonják azt az extra logikát, amelyet minden rekordművelethez (beszúrás, frissítés, törlés) külön-külön kell megvalósítani. További információkért lásd: Dinamikus táblázatok.
A Amazon által felügyelt szolgáltatás az Apache Flink számára, futtathat Apache Flink-feladatokat, és integrálhatja más AWS-szolgáltatásokkal. Nincsenek kezelhető kiszolgálók és fürtök, és nincs beállítandó számítási és tárolási infrastruktúra sem.
AWS ragasztó egy teljesen felügyelt kivonat, átalakítás és betöltés (ETL) szolgáltatás, ami azt jelenti, hogy az AWS kezeli az infrastruktúra kiépítését, méretezését és karbantartását. Bár elsősorban az ETL képességeiről ismert, az AWS Glue Spark streaming alkalmazásokhoz is használható. Az AWS Glue kölcsönhatásba léphet a streaming adatszolgáltatásokkal, például a Kinesis Data Streams-szel és az Amazon MSK-val a CDC adatok feldolgozásához és átalakításához. Az AWS Glue zökkenőmentesen integrálható más AWS-szolgáltatásokkal is, mint például a Lambda, AWS lépésfunkciókés a DynamoDB, amely átfogó ökoszisztémát biztosít az adatfeldolgozási folyamatok felépítéséhez és kezeléséhez.
Egységes ügyfélprofil
Az ügyfélprofil különböző forrásrendszerek közötti egységesítésének leküzdése robusztus adatfolyamok kifejlesztését igényli. Olyan adatfolyamokra van szüksége, amelyek az összes rekordot egyetlen adattárba hozhatják és szinkronizálhatják. Ez az adattár biztosítja a szervezete számára a holisztikus ügyfélrekord-nézetet, amely a RAG-alapú generatív AI-alkalmazások működési hatékonyságához szükséges. Egy ilyen adattár felépítéséhez egy strukturálatlan adattár lenne a legjobb.
Az identitásgráf hasznos struktúra az egységes ügyfélprofil létrehozásához, mert egyesíti és integrálja a különböző forrásokból származó ügyféladatokat, biztosítja az adatok pontosságát és deduplikációjának megszüntetését, valós idejű frissítéseket kínál, összekapcsolja a rendszerek közötti betekintést, lehetővé teszi a személyre szabást, javítja az ügyfélélményt és támogatja a szabályozási megfelelést. Ez az egységes ügyfélprofil lehetővé teszi a generatív AI-alkalmazás számára, hogy megértse az ügyfeleket, és hatékonyan kapcsolatba lépjen velük, és betartsa az adatvédelmi előírásokat, végső soron javítva az ügyfelek élményét és ösztönözve az üzleti növekedést. A segítségével elkészítheti identitásgráf-megoldását Amazon Neptun, egy gyors, megbízható, teljes körűen felügyelt grafikon adatbázis-szolgáltatás.
Az AWS néhány egyéb felügyelt és kiszolgáló nélküli NoSQL-tárolási szolgáltatást kínál strukturálatlan kulcsérték-objektumokhoz. Amazon DocumentDB (MongoDB kompatibilitással) egy gyors, méretezhető, magasan elérhető és teljes körűen felügyelt vállalat dokumentum adatbázis szolgáltatás, amely támogatja a natív JSON-munkaterheléseket. A DynamoDB egy teljesen felügyelt NoSQL adatbázis-szolgáltatás, amely gyors és kiszámítható teljesítményt biztosít zökkenőmentes méretezhetőség mellett.
Közel valós idejű szervezeti tudásbázis frissítések
Az ügyfélnyilvántartásokhoz hasonlóan a belső tudástárak, például a vállalati szabályzatok és a szervezeti dokumentumok is össze vannak zárva a tárolási rendszerek között. Ezek általában strukturálatlan adatok, és nem növekményes módon frissülnek. A strukturálatlan adatok mesterséges intelligencia-alkalmazásokhoz való felhasználása hatékony a vektoros beágyazással, amely a nagy dimenziós adatok, például szövegfájlok, képek és hangfájlok többdimenziós numerikus ábrázolásának technikája.
Az AWS számos lehetőséget kínál vektormotor-szolgáltatások, Mint például a Amazon OpenSearch kiszolgáló nélküli, Amazon Kendraés Amazon Aurora PostgreSQL-kompatibilis kiadás a pgvector kiterjesztéssel a vektorbeágyazások tárolására. A generatív AI-alkalmazások javíthatják a felhasználói élményt azáltal, hogy a felhasználói promptot vektorokká alakítják, és a vektormotor lekérdezésére használják a kontextus szempontjából releváns információk lekéréséhez. Ezután mind a prompt, mind a lekért vektoradatok átadásra kerül az LLM-nek, hogy pontosabb és személyre szabottabb választ kapjon.
A következő diagram egy példa adatfolyam-feldolgozási munkafolyamatot mutat be vektorbeágyazásokhoz.
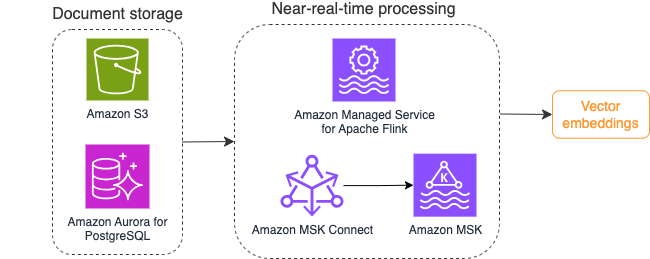
A tudásbázis tartalmát vektoros beágyazásokká kell konvertálni, mielőtt a vektoradattárba írnák őket. Amazon alapkőzet or Amazon SageMaker segítségével hozzáférhet a választott modellhez, és felfedhet egy privát végpontot ehhez a konverzióhoz. Ezenkívül használhat olyan könyvtárakat, mint például a LangChain, hogy integrálja ezeket a végpontokat. A kötegelt folyamat felépítése segíthet a tudásbázis tartalmának vektoradatokká konvertálásában, és kezdetben vektoradatbázisban való tárolásában. A dokumentumok újrafeldolgozásához azonban egy intervallumra kell támaszkodnia, hogy szinkronizálja a vektoradatbázist a tudásbázis tartalmának változásaival. Nagy számú dokumentum esetén ez a folyamat nem lehet hatékony. Ezen időszakok között a generatív AI alkalmazás felhasználói a régi tartalom szerint kapnak választ, vagy pontatlan választ kapnak, mert az új tartalom még nincs vektorizálva.
Az adatfolyam-feldolgozás ideális megoldás ezekre a kihívásokra. Kezdetben a meglévő dokumentumok szerint állítja elő az eseményeket, és tovább figyeli a forrásrendszert, és létrehoz egy dokumentummódosítási eseményt, amint azok bekövetkeznek. Ezek az események a streaming tárolóban tárolhatók, és megvárják, amíg egy adatfolyam-feladat feldolgozza őket. Egy adatfolyam-feladat beolvassa ezeket az eseményeket, betölti a dokumentum tartalmát, és a tartalmat kapcsolódó szavak tömbjévé alakítja. Minden token tovább alakul vektoradatokká egy beágyazó FM-hez intézett API-híváson keresztül. Az eredményeket elküldik tárolásra a vektortárolóba egy nyelő kezelőn keresztül.
Ha az Amazon S3-at használja a dokumentumok tárolására, létrehozhat egy eseményforrás-architektúrát a Lambda S3 objektummódosítási triggerei alapján. A Lambda függvény létrehozhat egy eseményt a kívánt formátumban, és beírhatja azt a streaming tárolójába.
Az Apache Flink segítségével streaming feladatként is futhat. Az Apache Flink biztosítja a natív fájlrendszer-forrás-összekötőt, amely képes felfedezni a meglévő fájlokat, és kezdetben elolvasni a tartalmukat. Ezt követően folyamatosan figyelni tudja a fájlrendszert az új fájlok után, és rögzíteni tudja azok tartalmát. A csatlakozó támogatja az elosztott fájlrendszerekből, például az Amazon S3-ból vagy a HDFS-ből származó fájlok beolvasását egyszerű szöveg, Avro, CSV, Parquet stb. formátumban, és streaming rekordot állít elő. Teljesen felügyelt szolgáltatásként az Apache Flink felügyelt szolgáltatása eltávolítja a Flink-feladatok üzembe helyezésének és karbantartásának többletköltségét, így Ön a streaming alkalmazások létrehozására és méretezésére összpontosíthat. Az AWS streaming szolgáltatásokba, mint például az Amazon MSK vagy a Kinesis Data Streams zökkenőmentes integrációjával olyan funkciókat biztosít, mint az automatikus skálázás, a biztonság és a rugalmasság, megbízható és hatékony Flink alkalmazásokat biztosítva a valós idejű adatfolyamok kezelésére.
A DevOps preferenciái alapján választhat a Kinesis Data Streams vagy az Amazon MSK között a streamelési rekordok tárolására. A Kinesis Data Streams leegyszerűsíti az egyéni streaming adatalkalmazások felépítésének és kezelésének bonyolultságát, lehetővé téve, hogy az infrastruktúra karbantartása helyett az adatokból való betekintésre összpontosítson. Az Apache Kafka-t használó ügyfelek gyakran választják az Amazon MSK-t annak egyszerűsége, méretezhetősége és megbízhatósága miatt az Apache Kafka-fürtök felügyelete során az AWS-környezetben. Teljesen felügyelt szolgáltatásként az Amazon MSK átveszi az Apache Kafka-fürtök telepítésével és karbantartásával kapcsolatos műveleti bonyolultságokat, lehetővé téve, hogy Ön a streaming alkalmazások felépítésére és bővítésére összpontosítson.
Mivel a RESTful API-integráció megfelel a folyamat természetének, olyan keretrendszerre van szüksége, amely támogatja az állapotalapú gazdagítási mintát RESTful API-hívásokon keresztül a hibák nyomon követéséhez és a sikertelen kérés újrapróbálásához. Az Apache Flink ismét egy olyan keretrendszer, amely memóriasebességgel képes állapottartó műveleteket végezni. Az Apache Flink segítségével történő API-hívások legjobb módjainak megértéséhez lásd: Gyakori adatfolyam-dúsítási minták az Amazon Kinesis Data Analytics for Apache Flink szolgáltatásban.
Az Apache Flink natív nyelő csatlakozókat biztosít az adatok vektoros adattárakba, például Amazon Aurora for PostgreSQL-be írásához pgvector vagy Amazon OpenSearch szolgáltatás a VectorDB-vel. Alternatív megoldásként a Flink-feladat kimenetét (vektorizált adatok) egy MSK-témában vagy egy Kinesis-adatfolyamban állíthatja be. Az OpenSearch szolgáltatás támogatja a Kinesis adatfolyamokból vagy MSK-témákból származó natív feldolgozást. További információkért lásd: Az Amazon MSK bemutatása az Amazon OpenSearch adatfeldolgozás forrásaként és a Streaming adatok betöltése az Amazon Kinesis Data Streams szolgáltatásból.
Visszajelzéselemzés és finomhangolás
Az adatkezelési menedzserek és az AI/ML fejlesztők számára fontos, hogy betekintést kapjanak a generatív AI-alkalmazás és a használt FM-ek teljesítményébe. Ennek eléréséhez olyan adatfolyamokat kell felépítenie, amelyek a felhasználói visszajelzések, valamint az alkalmazásnaplók és metrikák sokfélesége alapján számítják ki a fontos kulcsteljesítmény-mutató (KPI) adatait. Ezek az információk hasznosak az érdekelt felek számára, hogy valós idejű betekintést nyerjenek az FM teljesítményéről, az alkalmazásról, és általános felhasználói elégedettségükről az Ön alkalmazásától kapott támogatás minőségével kapcsolatban. Ezenkívül össze kell gyűjtenie és tárolnia kell a beszélgetési előzményeket az FM-ek további finomhangolásához, hogy javítsa azok képességét a tartományspecifikus feladatok végrehajtásában.
Ez a használati eset nagyon jól illeszkedik az adatfolyam-elemzési tartományba. Az alkalmazásnak minden beszélgetést a streaming tárhelyen kell tárolnia. Az alkalmazás felkérheti a felhasználókat az egyes válaszok pontosságának értékelésére és általános elégedettségükre. Ezek az adatok lehetnek bináris formátumúak vagy szabad formátumú szövegek. Ezek az adatok egy Kinesis adatfolyamban vagy MSK-témában tárolhatók, és feldolgozhatók a KPI-k valós időben történő generálásához. Munkába állíthatja az FM-eket a felhasználók hangulatelemzésére. Az FM-ek minden választ elemezhetnek, és hozzárendelhetik a felhasználói elégedettség kategóriáját.
Az Apache Flink architektúrája lehetővé teszi az időablakok közötti összetett adatok összesítését. Támogatja az adatesemények folyamán keresztüli SQL lekérdezését is. Ezért az Apache Flink használatával gyorsan elemezheti a nyers felhasználói bemeneteket, és valós időben generálhat KPI-ket ismerős SQL-lekérdezések írásával. További információkért lásd: Táblázat API és SQL.
A Amazon által felügyelt szolgáltatás az Apache Flink Studio számára, létrehozhat és futtathat Apache Flink adatfolyam-feldolgozó alkalmazásokat szabványos SQL, Python és Scala használatával egy interaktív notebookban. A Studio notebookokat az Apache Zeppelin hajtja, és az Apache Flinket használják adatfolyam-feldolgozó motorként. A Studio notebookok zökkenőmentesen kombinálják ezeket a technológiákat, hogy az adatfolyamok fejlett elemzését minden készségkészlettel rendelkező fejlesztő számára elérhetővé tegyék. A felhasználó által definiált függvények (UDF-ek) támogatásával az Apache Flink egyedi operátorok létrehozását teszi lehetővé, hogy integrálódjanak külső erőforrásokkal, például FM-ekkel összetett feladatok, például hangulatelemzés végrehajtásához. Az UDF-ek segítségével különféle mutatókat számíthat ki, vagy a felhasználói visszajelzések nyers adatait további információkkal, például a felhasználói véleményekkel gazdagíthatja. Ha többet szeretne megtudni erről a mintáról, lásd: Az ügyfelek problémáinak proaktív kezelése valós időben a GenAI, a Flink, az Apache Kafka és a Kinesis segítségével.
Az Apache Flink Studio felügyelt szolgáltatásával egyetlen kattintással telepítheti Studio-jegyzetfüzetét streaming feladatként. Az Apache Flink által biztosított natív nyelőcsatlakozók segítségével elküldheti a kimenetet a választott tárhelyére, vagy elhelyezheti Kinesis adatfolyamban vagy MSK-témában. Amazon RedShift és az OpenSearch Service egyaránt ideális az analitikai adatok tárolására. Mindkét motor natív feldolgozási támogatást nyújt a Kinesis Data Streamstől és az Amazon MSK-tól egy külön adatfolyamon keresztül egy adattóhoz vagy adattárházhoz elemzés céljából.
Az Amazon Redshift az SQL-t használja a strukturált és félig strukturált adatok elemzésére az adattárházak és adatforrások között, az AWS által tervezett hardvert és gépi tanulást használva a legjobb ár-teljesítmény elérése érdekében. Az OpenSearch Service vizualizációs lehetőségeket kínál az OpenSearch Dashboards és a Kibana (1.5-7.10 verziók) által.
Az ilyen elemzések eredményét a felhasználói kérdőíves adatokkal kombinálva felhasználhatja az FM finomhangolására, amikor szükséges. A SageMaker a legegyszerűbb módja az FM-ek finomhangolásának. Az Amazon S3 és a SageMaker használata erőteljes és zökkenőmentes integrációt biztosít a modellek finomhangolásához. Az Amazon S3 méretezhető és tartós objektumtárolási megoldásként szolgál, amely lehetővé teszi a nagy adatkészletek, betanítási adatok és modelltermékek egyszerű tárolását és visszakeresését. A SageMaker egy teljesen felügyelt ML szolgáltatás, amely leegyszerűsíti az ML teljes életciklusát. Ha az Amazon S3-at használja a SageMaker háttértárként, kihasználhatja az Amazon S3 méretezhetőségét, megbízhatóságát és költséghatékonyságát, miközben zökkenőmentesen integrálja azt a SageMaker képzési és telepítési képességeivel. Ez a kombináció lehetővé teszi a hatékony adatkezelést, megkönnyíti az együttműködésen alapuló modellfejlesztést, és biztosítja, hogy az ML munkafolyamatok áramvonalasak és méretezhetők legyenek, végső soron javítva az ML folyamat általános agilitását és teljesítményét. További információkért lásd: Finomhangolja a Falcon 7B-t és más LLM-eket az Amazon SageMakeren a @remote dekorátorral.
A fájlrendszer-nyelő-csatlakozóval az Apache Flink jobok nyílt formátumban (például JSON, Avro, Parquet és egyebek) adatobjektumokként küldhetnek adatokat az Amazon S3-nak. Ha inkább tranzakciós adattó-keretrendszer (például Apache Hudi, Apache Iceberg vagy Delta Lake) használatával kívánja kezelni az adattót, akkor ezek a keretrendszerek mindegyike egyéni csatlakozót biztosít az Apache Flink számára. További részletekért lásd: Hozzon létre egy alacsony késleltetésű forrás-adat-tó csővezetéket az Amazon MSK Connect, az Apache Flink és az Apache Hudi segítségével.
Összegzésként
Egy RAG-modellre épülő generatív mesterségesintelligencia-alkalmazáshoz meg kell fontolnia két adattároló rendszer építését, és olyan adatműveleteket kell felépítenie, amelyek az összes forrásrendszerrel naprakészen tartják azokat. A hagyományos kötegelt munkák nem elegendőek a generatív AI-alkalmazásba való integráláshoz szükséges adatok méretének és sokféleségének feldolgozásához. A forrásrendszerek változásainak feldolgozásának késése pontatlan választ eredményez, és csökkenti a generatív AI-alkalmazás hatékonyságát. Az adatfolyam-szolgáltatás lehetővé teszi, hogy különféle adatbázisokból, különféle rendszereken keresztül töltsön be adatokat. Lehetővé teszi továbbá számos forrásból származó adatok hatékony, közel valós időben történő átalakítását, gazdagítását, összekapcsolását és összesítését. Az adatfolyam egyszerűsített adatarchitektúrát biztosít a felhasználók valós idejű reakcióinak vagy megjegyzéseinek összegyűjtéséhez és átalakításához az alkalmazások válaszaira vonatkozóan, így segíti az eredmények továbbítását és tárolását egy adattóban a modell finomhangolásához. Az adatfolyam az adatfolyamok optimalizálását is segíti, mivel csak a változási eseményeket dolgozza fel, így gyorsabban és hatékonyabban reagálhat az adatváltozásokra.
Tudjon meg többet AWS adatfolyam-szolgáltatások és kezdje el saját adatfolyam-megoldása kiépítését.
A szerzőkről
 Ali Alemi az AWS Streaming Specialist Solutions Építésze. Ali tanácsot ad az AWS ügyfeleinek a legjobb építészeti gyakorlatokkal kapcsolatban, és segít nekik megbízható, biztonságos, hatékony és költséghatékony valós idejű analitikai adatrendszerek tervezésében. Az ügyfelek használati eseteitől visszafelé dolgozik, és adatmegoldásokat tervez üzleti problémáik megoldására. Mielőtt csatlakozott volna az AWS-hez, Ali számos közszférabeli ügyfelet és AWS tanácsadó partnert támogatott az alkalmazások modernizálásában és a felhőre való átállásban.
Ali Alemi az AWS Streaming Specialist Solutions Építésze. Ali tanácsot ad az AWS ügyfeleinek a legjobb építészeti gyakorlatokkal kapcsolatban, és segít nekik megbízható, biztonságos, hatékony és költséghatékony valós idejű analitikai adatrendszerek tervezésében. Az ügyfelek használati eseteitől visszafelé dolgozik, és adatmegoldásokat tervez üzleti problémáik megoldására. Mielőtt csatlakozott volna az AWS-hez, Ali számos közszférabeli ügyfelet és AWS tanácsadó partnert támogatott az alkalmazások modernizálásában és a felhőre való átállásban.
 Imtiaz (Taz) Sayed az AWS analitika világszintű műszaki vezetője. Szereti a közösséggel való kapcsolatteremtést minden adattal és elemzéssel kapcsolatban. keresztül lehet elérni LinkedIn.
Imtiaz (Taz) Sayed az AWS analitika világszintű műszaki vezetője. Szereti a közösséggel való kapcsolatteremtést minden adattal és elemzéssel kapcsolatban. keresztül lehet elérni LinkedIn.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

