परिचय
तकनीकी क्रांति के दौर से गुजर रही दुनिया में, कृत्रिम बुद्धिमत्ता और स्वास्थ्य देखभाल का संलयन चिकित्सा निदान और उपचार के परिदृश्य को नया आकार दे रहा है। इस परिवर्तन के पीछे के मूक नायकों में से एक चिकित्सा, स्वास्थ्य क्षेत्र और मुख्य रूप से पाठ विश्लेषण के क्षेत्र में बड़े भाषा मॉडल (एलएलएम) का अनुप्रयोग है। यह लेख पाठ-आधारित चिकित्सा अनुप्रयोगों के संदर्भ में एलएलएम के दायरे पर प्रकाश डालता है और पता लगाता है कि कैसे ये शक्तिशाली एआई मॉडल स्वास्थ्य सेवा उद्योग में क्रांति ला रहे हैं।

सीखने के मकसद
- चिकित्सा पाठ विश्लेषण में बड़े भाषा मॉडल (एलएलएम) की भूमिका को समझें।
- आधुनिक स्वास्थ्य देखभाल में मेडिकल इमेजिंग के महत्व को पहचानें।
- स्वास्थ्य देखभाल में चिकित्सा छवियों की मात्रा से उत्पन्न चुनौतियों की पहचान करें।
- समझें कि एलएलएम चिकित्सा पाठ विश्लेषण और निदान को स्वचालित करने में कैसे सहायता करते हैं।
- गंभीर चिकित्सा मामलों की सुनवाई में एलएलएम की दक्षता की सराहना करें।
- पता लगाएं कि एलएलएम रोगी के इतिहास के आधार पर वैयक्तिकृत उपचार योजनाओं में कैसे योगदान करते हैं।
- रेडियोलॉजिस्ट की सहायता में एलएलएम की सहयोगी भूमिका को समझें।
- जानें कि एलएलएम मेडिकल छात्रों और चिकित्सकों के लिए शिक्षा में कैसे मदद कर सकता है।
इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन।
विषय - सूची
मेडिकल इमेजिंग और हेल्थकेयर की अनदेखी दुनिया
इससे पहले कि हम एलएलएम की दुनिया में उतरें, आइए मेडिकल इमेजिंग की उपस्थिति की सराहना करने के लिए कुछ समय निकालें। यह वर्तमान तकनीकी जीवन में आधुनिक चिकित्सा की रीढ़ है जो बीमारियों की कल्पना करने और उनका पता लगाने में मदद करता है और कई उपचार प्रगति की निगरानी करने में मदद करता है। रेडियोलॉजी, विशेष रूप से, एक्स-रे, एमआरआई, सीटी स्कैन और अन्य से प्राप्त चिकित्सा छवियों पर बहुत अधिक निर्भर करती है।
हालाँकि, चिकित्सा छवियों का यह खजाना एक चुनौती के साथ आता है: विशाल मात्रा। अस्पताल और स्वास्थ्य सेवा संस्थान प्रतिदिन बड़ी मात्रा में चिकित्सा छवियों का उपयोग करते हैं। इस बाढ़ का मैन्युअल रूप से विश्लेषण और व्याख्या करना कठिन, समय लेने वाला और मानवीय त्रुटि की संभावना है।

चिकित्सा छवियों का विश्लेषण करने में उनकी महत्वपूर्ण भूमिका के अलावा, बड़े भाषा मॉडल पाठ-आधारित चिकित्सा जानकारी को समझने और संसाधित करने में उत्कृष्टता प्राप्त करते हैं। वे जटिल चिकित्सा शब्दजाल को समझने में स्पष्टता प्रदान करते हैं, यहां तक कि नोट्स और रिपोर्ट की व्याख्या करने में भी सहायता करते हैं। एलएलएम अधिक कुशल और सटीक चिकित्सा पाठ विश्लेषण में योगदान करते हैं, स्वास्थ्य देखभाल पेशेवरों और चिकित्सा विश्लेषण की समग्र क्षमताओं में सुधार करते हैं।
इस समझ के साथ, आइए आगे देखें कि कैसे एलएलएम मेडिकल इमेजिंग और टेक्स्ट विश्लेषण में स्वास्थ्य सेवा उद्योग में क्रांति ला रहे हैं।
मेडिकल टेक्स्ट विश्लेषण में एलएलएम के अनुप्रयोग
स्वास्थ्य सेवा में बड़े भाषा मॉडल की बहुआयामी भूमिकाओं को समझने से पहले, आइए चिकित्सा पाठ विश्लेषण के क्षेत्र में उनके प्रमुख अनुप्रयोगों पर एक संक्षिप्त नज़र डालें:
- रोग निदान और पूर्वानुमान: एलएलएम विभिन्न बीमारियों के निदान में स्वास्थ्य सेवा प्रदाताओं की सहायता के लिए चिकित्सा ग्रंथों के बड़े डेटाबेस को खंगाल सकते हैं। वे न केवल प्रारंभिक निदान में मदद कर सकते हैं, बल्कि पर्याप्त प्रासंगिक जानकारी दिए जाने पर वे रोग की प्रगति और पूर्वानुमान के बारे में शिक्षित अनुमान भी लगा सकते हैं।
- नैदानिक दस्तावेज़ीकरण और इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड: चिकित्सा पेशेवरों के लिए व्यापक नैदानिक दस्तावेज़ीकरण को संभालना समय लेने वाला हो सकता है। एलएलएम इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड (ईएचआर) को लिखने, सारांशित करने और विश्लेषण करने के लिए अधिक कुशल साधन प्रदान करते हैं, जिससे स्वास्थ्य सेवा प्रदाताओं को रोगी देखभाल पर अधिक ध्यान केंद्रित करने की अनुमति मिलती है।
- औषधि की खोज और पुनर्प्रयोजन: ढेर सारे बायोमेडिकल साहित्य के माध्यम से खनन करके, एलएलएम संभावित दवा उम्मीदवारों की पहचान कर सकते हैं और यहां तक कि मौजूदा दवाओं के लिए वैकल्पिक उपयोग का सुझाव भी दे सकते हैं, जिससे फार्माकोलॉजी में खोज और पुन: उपयोग की प्रक्रिया में तेजी आएगी।
- बायोमेडिकल साहित्य विश्लेषण: चिकित्सा साहित्य का निरंतर बढ़ता हुआ समूह अभिभूत करने वाला हो सकता है। एलएलएम कई वैज्ञानिक पत्रों की जांच कर सकते हैं, प्रमुख निष्कर्षों की पहचान कर सकते हैं और संक्षिप्त सारांश प्रदान कर सकते हैं, जिससे नए ज्ञान को तेजी से आत्मसात करने में सहायता मिलती है।
- रोगी सहायता और स्वास्थ्य चैटबॉट: एलएलएम बुद्धिमान चैटबॉट्स को शक्ति प्रदान करते हैं जो सामान्य स्वास्थ्य प्रश्नों का उत्तर देने से लेकर आपात स्थिति में प्रारंभिक परीक्षण की पेशकश करने तक, रोगियों और स्वास्थ्य सेवा प्रदाताओं दोनों को अमूल्य सहायता प्रदान करने तक कई प्रकार के कार्यों को संभाल सकते हैं।
हेल्थकेयर उद्योग में एलएलएम कैसे काम करते हैं?

- बड़े भाषा मॉडल क्या हैं? बड़े भाषा मॉडल मशीन लर्निंग मॉडल का एक सबसेट हैं जो मानव-जैसे पाठ को समझने, व्याख्या करने और उत्पन्न करने के लिए डिज़ाइन किए गए हैं। इन मॉडलों को पुस्तकों, लेखों, वेबसाइटों और अन्य पाठ-आधारित स्रोतों वाले विशाल डेटासेट पर प्रशिक्षित किया जाता है। वे अत्यधिक उन्नत पाठ विश्लेषक और जनरेटर के रूप में कार्य करते हैं जो संदर्भ और शब्दार्थ को समझ सकते हैं।
- चिकित्सा क्षेत्र में एलएलएम का विकास: पिछले दशक में, एलएलएम ने स्वास्थ्य देखभाल में प्रमुखता हासिल की है, जो सरल चैटबॉट से लेकर जटिल चिकित्सा साहित्य को पार्स करने में सक्षम परिष्कृत उपकरणों तक विकसित हुआ है। अधिक शक्तिशाली हार्डवेयर और अधिक कुशल एल्गोरिदम के आगमन ने इन मॉडलों को वास्तविक समय की अंतर्दृष्टि और विश्लेषण की पेशकश करते हुए सेकंड के भीतर गीगाबाइट डेटा को छानने में सक्षम बनाया है। उनकी अनुकूलनशीलता उन्हें लगातार नई जानकारी से सीखने की अनुमति देती है, जिससे वे अधिक सटीक और विश्वसनीय बन जाती हैं।
- एलएलएम पारंपरिक एनएलपी विधियों से कैसे भिन्न हैं? पारंपरिक प्राकृतिक भाषा प्रसंस्करण (एनएलपी) विधियां जैसे नियम-आधारित सिस्टम या सरल मशीन लर्निंग मॉडल संदर्भ को समझने के सीमित दायरे के साथ निश्चित एल्गोरिदम पर काम करते हैं। हालाँकि, एलएलएम मुहावरों, चिकित्सा शब्दजाल और जटिल वाक्य संरचनाओं सहित मानव भाषा की जटिलताओं को समझने के लिए गहन शिक्षा का लाभ उठाते हैं। यह एलएलएम को ऐसी अंतर्दृष्टि उत्पन्न करने में सक्षम बनाता है जो पारंपरिक एनएलपी तरीकों की तुलना में कहीं अधिक सूक्ष्म और प्रासंगिक रूप से सटीक है।
मेडिकल टेक्स्ट विश्लेषण में एलएलएम के लाभ और क्षमताएं
- प्रासंगिक समझ: कीवर्ड मिलान पर निर्भर पारंपरिक खोज एल्गोरिदम के विपरीत, एलएलएम पाठ के संदर्भ को समझते हैं, जिससे अधिक सूक्ष्म और सटीक अंतर्दृष्टि प्राप्त होती है।
- गति: एलएलएम त्वरित रूप से विश्लेषण और रिपोर्ट तैयार कर सकते हैं, जिससे महत्वपूर्ण स्वास्थ्य देखभाल सेटिंग्स में बहुमूल्य समय की बचत होती है।
- multifunctionality: सरल पाठ विश्लेषण से परे, वे निदान में सहायता कर सकते हैं, व्यक्तिगत उपचार सिफारिशें प्रदान कर सकते हैं और शैक्षिक उपकरण के रूप में काम कर सकते हैं।
- अनुकूलन क्षमता: इन मॉडलों को विशिष्ट चिकित्सा डोमेन या कार्यों के लिए ठीक से ट्यून किया जा सकता है, जिससे वे अविश्वसनीय रूप से बहुमुखी बन जाते हैं।
मेडिकल पाठ विश्लेषण में एलएलएम की भूमिका
- स्वचालित विश्लेषण और निदान: बड़े भाषा मॉडलों को चिकित्सा साहित्य और वास्तविक समय के मामले के अध्ययन सहित कई डेटासेट का उपयोग करके प्रशिक्षित किया जाता है। वे संदर्भ को समझने में उत्कृष्ट हैं और जटिल चिकित्सा शब्दजाल को पार्स कर सकते हैं। चिकित्सा ग्रंथों पर लागू होने पर एलएलएम स्वचालित विश्लेषण प्रदान कर सकते हैं और यहां तक कि बीमारियों का निदान भी कर सकते हैं।
- कुशल ट्राइएज: आपातकालीन कक्ष में, हर मिनट मायने रखता है। बड़े भाषा मॉडल मेडिकल रिपोर्ट या क्लिनिक टेक्स्ट नोट्स का विश्लेषण करके, रक्तस्राव या असामान्यताओं जैसी गंभीर स्थितियों को चिह्नित करके मामलों का त्वरित निदान कर सकते हैं। इससे रोगी की देखभाल में तेजी आती है और संसाधन आवंटन का अनुकूलन होता है।
- वैयक्तिकृत उपचार योजनाएँ: मेडिकल इमेजिंग एलएलएम आनुवंशिकी, एलर्जी और पिछले उपचार प्रतिक्रियाओं सहित रोगी के इतिहास का विश्लेषण करके व्यक्तिगत चिकित्सा में योगदान करते हैं। वे इस जानकारी के आधार पर अनुरूप उपचार योजनाओं की सिफारिश कर सकते हैं।
- सहायक रेडियोलॉजिस्ट: बड़े भाषा मॉडल रेडियोलॉजिस्ट के सहायक के रूप में मदद करते हैं। वे मेडिकल रिपोर्ट की पूर्व-स्क्रीनिंग कर सकते हैं, विसंगतियों को उजागर कर सकते हैं और संभावित निदान का सुझाव दे सकते हैं। यह सहयोगात्मक दृष्टिकोण निदान की सटीकता को बढ़ाता है और रेडियोलॉजिस्ट की थकान को कम करता है।
- शैक्षिक उपकरण: बड़े भाषा मॉडल मेडिकल छात्रों और चिकित्सकों के लिए शिक्षा उद्देश्यों के लिए उपकरण के रूप में सहायक हो सकते हैं। वे पाठ्य विवरणों से 3डी पुनर्निर्माण उत्पन्न कर सकते हैं, चिकित्सा परिदृश्यों का अनुकरण कर सकते हैं और शैक्षिक उद्देश्यों के लिए विस्तृत स्पष्टीकरण प्रदान कर सकते हैं।
निदान के लिए एलएलएम को कैसे स्वचालित किया जा सकता है?
यहां एक भाषा मॉडल (जैसे GPT-3) का उपयोग करके एक सरलीकृत कोड स्निपेट दिया गया है, यह देखने के लिए कि चिकित्सा पाठ के आधार पर स्वचालित विश्लेषण और निदान के लिए बड़े भाषा मॉडल का उपयोग कैसे किया जा सकता है:
import openai
import time # Your OpenAI API key
api_key = "YOUR_API_KEY" # Patient's medical report medical_report = """
Patient: John Doe
Age: 45
Symptoms: Persistent cough, shortness of breath, fever. Medical History:
- Allergies: None
- Medications: None
- Past Illnesses: None Diagnosis:
Based on the patient's symptoms and medical history, John Doe is suffering from a respiratory infection, possibly pneumonia. Further tests and evaluation are recommended for confirmation. """ # Initialize OpenAI's GPT-3 model
openai.api_key = api_key # Define a language model
prompt = f"Diagnose the condition by seeing the following report:n{medical_report}nDiagnosis:" while True: try: # Generate a diagnosis using the language model response = openai.Completion.create( engine="davinci", prompt=prompt, max_tokens=50 # Adjust the number of tokens based on your requirements ) # Extract and print the generated diagnosis diagnosis = response.choices[0].text.strip() print("Generated Diagnosis:") print(diagnosis) # Break out of the loop once the response is successfully obtained break except openai.error.RateLimitError as e: # If you hit the rate limit, wait for a moment and retry print("Rate limit exceeded. Waiting for rate limit reset...") time.sleep(60) # Wait for 1 minute (adjust as needed) except Exception as e: # Handle other exceptions print(f"An error occurred: {e}") break # Break out of the loop on other errors
आउटपुट:

- ओपनएआई लाइब्रेरी आयात करें और ओपनएआई कुंजी सेट करें
- रोगी की जानकारी, लक्षण और चिकित्सा इतिहास वाली एक मेडिकल रिपोर्ट बनाएं।
- OpenAI के GPT-3 मॉडल को आरंभ करें और एक संकेत परिभाषित करें जो मॉडल को प्रदान की गई रिपोर्ट के आधार पर चिकित्सा स्थिति का निदान करने के लिए कहता है।
- निदान उत्पन्न करने के लिए openai.Completion का उपयोग करें। और जेनरेट किए गए टेक्स्ट की लंबाई को नियंत्रित करने के लिए max_tokens पैरामीटर को समायोजित करें।
- उत्पन्न निदान को निकालें और प्रिंट करें।
नमूना आउटपुट
Generated Diagnosis: "Based on the patient's symptoms and medical history, it is likely that John Doe is suffering from a respiratory infection, possibly pneumonia.
Further tests and evaluation are recommended for confirmation."यह कोड दिखाता है कि कैसे एक बड़ा भाषा मॉडल पाठ्य चिकित्सा रिपोर्टों के आधार पर स्वचालित चिकित्सा निदान उत्पन्न करने में सहायता कर सकता है। याद रखें कि वास्तविक दुनिया के चिकित्सा निदान में हमेशा स्वास्थ्य देखभाल पेशेवरों के साथ परामर्श शामिल होना चाहिए और एआई-जनित निदान पर भरोसा नहीं करना चाहिए।
व्यापक चिकित्सा छवि विश्लेषण के लिए वीआईटी और एलएलएम का संयोजन
आइए कुछ कोड स्निपेट देखें जो मेडिकल इमेजिंग में एलएलएम के अनुप्रयोग को प्रदर्शित करते हैं।
import torch
from transformers import ViTFeatureExtractor, ViTForImageClassification # Load a pre-trained Vision Transformer (ViT) model
model_name = "google/vit-base-patch16-224-in21k"
feature_extractor = ViTFeatureExtractor(model_name)
model = ViTForImageClassification.from_pretrained(model_name) # Load and preprocess a medical image
from PIL import Image image = Image.open("chest_xray.jpg")
inputs = feature_extractor(images=image, return_tensors="pt") # Get predictions from the model
outputs = model(**inputs)
logits_per_image = outputs.logitsइस कोड में, हम मेडिकल छवि को वर्गीकृत करने के लिए विज़न ट्रांसफॉर्मर (वीआईटी) मॉडल का उपयोग करते हैं। एलएलएम, वीआईटी की तरह, मेडिकल इमेजिंग में विभिन्न छवि-संबंधी कार्यों के लिए अनुकूल हैं।
विसंगतियों का स्वचालित पता लगाना
import torch
import torchvision.transforms as transforms
from PIL import Image
from transformers import ViTFeatureExtractor, ViTForImageClassification # Load a pre-trained Vision Transformer (ViT) model
model_name = "google/vit-base-patch16-224-in21k"
feature_extractor = ViTFeatureExtractor(model_name)
model = ViTForImageClassification.from_pretrained(model_name) # Load and preprocess a medical image
image = Image.open("chest_xray.jpg")
transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(),
])
input_image = transform(image).unsqueeze(0) # Extract features from the image
inputs = feature_extractor(images=input_image)
outputs = model(**inputs)
logits_per_image = outputs.logitsइस कोड में, हम मेडिकल छवि में विसंगतियों का स्वचालित रूप से पता लगाने के लिए विज़न ट्रांसफार्मर (वीआईटी) मॉडल का उपयोग करते हैं। मॉडल छवि से विशेषताएं निकालता है, और logits_per_image वैरिएबल में मॉडल की भविष्यवाणियां शामिल होती हैं।
मेडिकल इमेज कैप्शनिंग
import torch
from transformers import ViTFeatureExtractor, ViTForImageToText # Load a pre-trained ViT model for image captioning
model_name = "google/vit-base-patch16-224-in21k-cmlm"
feature_extractor = ViTFeatureExtractor.from_pretrained(model_name)
model = ViTForImageToText.from_pretrained(model_name) # Load and preprocess a medical image
image = Image.open("MRI_scan.jpg")
inputs = feature_extractor(images=image, return_tensors="pt")
output = model.generate(input_ids=inputs["pixel_values"]) caption = feature_extractor.decode(output[0], skip_special_tokens=True)
print("Image Caption:", caption)यह कोड दर्शाता है कि कैसे एक एलएलएम चिकित्सा छवियों के लिए वर्णनात्मक कैप्शन उत्पन्न कर सकता है। यह एक पूर्व-प्रशिक्षित विज़न ट्रांसफार्मर (ViT) मॉडल का उपयोग करता है।
मेडिकल टेक्स्ट विश्लेषण में एलएलएम का तकनीकी वर्कफ़्लो
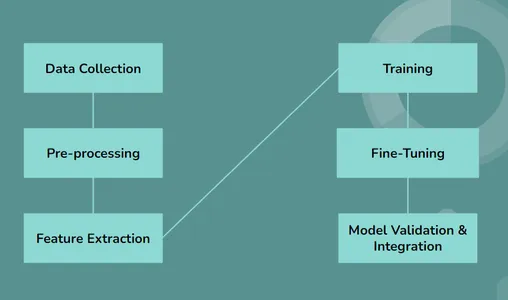
- डेटा संग्रहण: एलएलएम विभिन्न डेटासेट का उपयोग और संग्रह करके प्रक्रिया शुरू करते हैं, जिसमें चिकित्सा रिपोर्ट, शोध लेख और नैदानिक नोट शामिल हैं।
- पूर्व प्रसंस्करण: एकत्रित डेटा पूर्व-प्रसंस्करण से गुजरता है, जहां पाठ को विश्लेषण के लिए मानकीकृत, साफ और व्यवस्थित किया जाता है।
- सुविधा निकालना: बड़े भाषा मॉडल पाठ्य डेटा से महत्वपूर्ण और उपयोगी जानकारी प्राप्त करने या ढूंढने के लिए उन्नत तरीकों का उपयोग करते हैं, प्रमुख विवरणों और चिकित्सा मुद्दों की पहचान करते हैं।
- प्रशिक्षण: बड़े भाषा मॉडलों को गहन शिक्षण का उपयोग करके प्रशिक्षित किया जाता है जो पाठ्य रूप में मौजूद जानकारी के भीतर पैटर्न और चिकित्सा स्थितियों को खोजने और निरीक्षण करने में मदद करता है।
- फ़ाइन ट्यूनिंग: प्रशिक्षण प्रक्रिया के बाद विशिष्ट चिकित्सा कार्यों के लिए मॉडल को ठीक किया गया है। उदाहरण के लिए, यह मेडिकल रिपोर्ट से विशिष्ट बीमारियों या स्थितियों की पहचान करना सीख सकता है।
- मॉडल सत्यापन: चिकित्सा पाठ विश्लेषण में सटीकता और विश्वसनीयता सुनिश्चित करने के लिए अलग-अलग डेटासेट का उपयोग करके एलएलएम के प्रदर्शन को सख्ती से मान्य किया जाता है।
- एकता: एक बार मान्य होने के बाद, मॉडल को हेल्थकेयर सिस्टम और वर्कफ़्लो में एकीकृत किया जाता है, जहां यह मेडिकल टेक्स्ट डेटा का विश्लेषण और व्याख्या करने में हेल्थकेयर पेशेवरों की सहायता कर सकता है।
निश्चित रूप से! नीचे एक सरलीकृत कोड स्निपेट है जो यह समझने में मदद करता है कि मेडिकल में मेडिकल टेक्स्ट-आधारित कार्यों के लिए GPT-3 (एक प्रकार का एलएलएम - बड़ा भाषा मॉडल) जैसे भाषा मॉडल का उपयोग कैसे किया जा सकता है। इस कोड स्निपेट में, हम एक पायथन स्क्रिप्ट बनाएंगे जो रोगी के लक्षणों और चिकित्सा इतिहास के आधार पर एक चिकित्सा निदान रिपोर्ट तैयार करने के लिए ओपनएआई जीपीटी-3 एपीआई का उपयोग करती है।
इससे पहले, सुनिश्चित करें कि आपके पास OpenAI Python पैकेज स्थापित है (openai)। आपको OpenAI से एक एपीआई कुंजी की आवश्यकता है।
import openai # Set your OpenAI API key here
api_key = "YOUR_API_KEY" # Function to generate a medical diagnosis report
def generate_medical_diagnosis_report(symptoms, medical_history): prompt = f"Patient presents with the following symptoms: {symptoms}. Medical history: {medical_history}. Please provide a diagnosis and recommended treatment." # Call the OpenAI GPT-3 API response = openai.Completion.create( engine="text-davinci-002", # You can choose the appropriate engine prompt=prompt, max_tokens=150, # Adjust max_tokens based on the desired response length api_key=api_key ) # Extract and return the model's response diagnosis_report = response.choices[0].text.strip() return diagnosis_report # Example usage
if __name__ == "__main__": symptoms = "Persistent cough, fever, and chest pain" medical_history = "Patient has a history of asthma and allergies." diagnosis_report = generate_medical_diagnosis_report(symptoms, medical_history) print("Medical Diagnosis Report:") print(diagnosis_report)
याद रखें कि यह एक सरलीकृत उदाहरण है, और वास्तविक दुनिया के चिकित्सा अनुप्रयोग डेटा गोपनीयता, नियामक अनुपालन और चिकित्सा पेशेवरों के साथ परामर्श पर विचार करते हैं। ऐसे मॉडलों का हमेशा जिम्मेदारी से उपयोग करें और वास्तविक चिकित्सा निदान और उपचार के लिए स्वास्थ्य देखभाल विशेषज्ञों से परामर्श लें।
बड़े भाषा मॉडल: भविष्यवाणी से परे की शक्ति
बड़े भाषा मॉडल भी स्वास्थ्य सेवा के विभिन्न हिस्सों में आगे बढ़ रहे हैं:
- दवाओं की खोज: एलएलएम रसायनों के बड़े डेटासेट का अध्ययन करके, उनके काम करने के तरीके की भविष्यवाणी करके और दवा के विकास को तेज़ बनाकर दवा की खोज में मदद करते हैं।
- इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड (ईएचआर): एलएलएम, जब ईएचआर के साथ उपयोग किया जाता है, तो जोखिमों की भविष्यवाणी करने, उपचार का सुझाव देने और अध्ययन करने के लिए रोगी के रिकॉर्ड का त्वरित विश्लेषण कर सकता है कि उपचार मरीजों के स्वास्थ्य को कैसे प्रभावित करते हैं।
- चिकित्सा साहित्य सारांश: एलएलएम व्यापक चिकित्सा साहित्य को छान-बीन कर सकते हैं, मुख्य अंतर्दृष्टि निकाल सकते हैं, और संक्षिप्त सारांश तैयार कर सकते हैं, शोधकर्ताओं और स्वास्थ्य देखभाल चिकित्सकों की सहायता कर सकते हैं।
- टेलीमेडिसिन और आभासी स्वास्थ्य सहायक: एलएलएम आभासी स्वास्थ्य सहायकों को शक्ति प्रदान कर सकते हैं जो रोगी के प्रश्नों को समझते हैं, स्वास्थ्य संबंधी जानकारी प्रदान करते हैं, और लक्षणों और उपचार विकल्पों पर मार्गदर्शन प्रदान करते हैं।

नैतिक प्रतिपूर्ति
- रोगी की गोपनीयता: गोपनीयता बनाए रखने के लिए रोगी डेटा को कठोरता से सुरक्षित रखें।
- डेटा पूर्वाग्रह: न्यायसंगत निदान सुनिश्चित करने के लिए एलएलएम के भीतर पूर्वाग्रहों का लगातार आकलन और सुधार करें।
- सूचित सहमति: एआई-सहायता प्राप्त निदान और उपचार के लिए रोगी की सहमति सुरक्षित करें।
- पारदर्शिता: स्वास्थ्य सेवा प्रदाताओं के लिए एआई-जनित अनुशंसाओं में पारदर्शिता सुनिश्चित करें।
- आँकड़े की गुणवत्ता: भरोसेमंद परिणामों के लिए डेटा गुणवत्ता और सटीकता बनाए रखें।
- पूर्वाग्रह शमन: नैतिक स्वास्थ्य देखभाल अनुप्रयोगों के लिए एलएलएम में चल रहे पूर्वाग्रह शमन को प्राथमिकता दें।
निष्कर्ष
स्वास्थ्य देखभाल और एआई की लगातार बदलती दुनिया में, बड़े भाषा मॉडल (एलएलएम) और मेडिकल इमेजिंग की टीमवर्क एक बड़ी बात है और बहुत महत्वपूर्ण है। यह मानवीय जानकारी को प्रतिस्थापित करने के बारे में नहीं है, बल्कि इसमें सुधार करने और उसकी भागीदारी के बिना मनुष्यों की तरह परिणाम प्राप्त करने के बारे में है। एलएलएम त्वरित निदान और वैयक्तिकृत उपचार में सहायता करते हैं, जिससे चिकित्सा विशेषज्ञों के लिए रोगियों की शीघ्र सहायता करना आसान हो जाता है।
लेकिन जैसे ही हम इस तकनीक में जाते हैं, हमें नैतिक होना नहीं भूलना चाहिए और रोगी की जानकारी को सुरक्षित हाथों में सुरक्षित रखना चाहिए। संभावनाएं ऊंची और विशाल हैं, लेकिन हमारी जिम्मेदारियां भी बड़ी हैं। यह सब प्रगति और लोगों की सुरक्षा के बीच सही संतुलन खोजने के बारे में है।
यात्रा अभी शुरू हुई है. एलएलएम के साथ, हम एक ऐसे रास्ते पर चल रहे हैं जो अधिक सटीक निदान, बेहतर रोगी परिणाम और एक स्वास्थ्य देखभाल प्रणाली की ओर ले जाता है जो कुशल और दयालु दोनों है। एलएलएम द्वारा निर्देशित स्वास्थ्य सेवा का भविष्य, सभी के लिए एक स्वस्थ दुनिया का वादा करता है।
चाबी छीन लेना
- बड़े भाषा मॉडल (एलएलएम) चिकित्सा ग्रंथों के विश्लेषण में क्रांति ला रहे हैं, निदान और उपचार योजना में प्रगति कर रहे हैं।
- वे मेडिकल रिपोर्ट और क्लिनिकल नोट्स में मुद्दों की तेजी से पहचान करके आपातकालीन देखभाल में तेजी लाते हैं।
- एलएलएम रेडियोलॉजिस्ट की क्षमताओं को प्रतिस्थापित करने के बजाय पाठ-आधारित छवि व्याख्या में सहायता करके बढ़ाते हैं, इस प्रकार व्यापक डेटा समझ में सहायता मिलती है।
- ये मॉडल शिक्षा में उपयोगिता पाते हैं और स्वास्थ्य सेवा क्षेत्र में विविध अनुप्रयोग पेश करते हैं।
- चिकित्सा क्षेत्र में एलएलएम का लाभ उठाने के लिए रोगी की गोपनीयता, डेटा निष्पक्षता और मॉडल पारदर्शिता पर सावधानीपूर्वक विचार करने की आवश्यकता है।
- एलएलएम और चिकित्सा विशेषज्ञों के सहयोगात्मक प्रयास स्वास्थ्य सेवाओं की गुणवत्ता और करुणा को बढ़ा सकते हैं।
आम सवाल-जवाब
उ. नहीं, एलएलएम मेडिकल इमेजिंग में रेडियोलॉजिस्ट की जगह नहीं ले रहे हैं। इसके बजाय, वे एक साथ काम कर रहे हैं। एलएलएम रेडियोलॉजिस्ट को समस्याओं का तुरंत पता लगाने और प्रक्रिया को तेज़ बनाने में मदद करते हैं। वे शिक्षण के लिए उपयोग करते हैं और अन्य चिकित्सीय उपयोग भी करते हैं। चिकित्सा में एलएलएम का उपयोग करते समय रोगी की गोपनीयता और डेटा में निष्पक्षता आवश्यक है।
ए. एलएलएम प्रत्येक इमेजिंग पद्धति के लिए विशिष्ट विविध डेटासेट को ठीक करके विभिन्न चिकित्सा छवियों को अनुकूलित करते हैं। वे इस प्रक्रिया के दौरान टेक्स्ट-आधारित एक्स-रे, एमआरआई और सीटी स्कैन से अनूठी विशेषताएं और पैटर्न सीखते हैं। क्रॉस-मोडल प्रशिक्षण तकनीकें उन्हें तौर-तरीकों में ज्ञान स्थानांतरित करने, तौर-तरीके-विशिष्ट बारीकियों को समझते हुए सटीकता बनाए रखने के लिए उपलब्ध कराती हैं।
ए. मेडिकल इमेजिंग में एलएलएम के साथ चुनौतियों में डेटा पूर्वाग्रह को संबोधित करना और कम करना, एआई-सहायक निदान के लिए मरीजों से सूचित सहमति प्राप्त करना और नैतिकता बनाए रखते हुए एआई-जनित सिफारिशों को तैयार और प्रस्तुत करने के तरीके में पारदर्शिता सुनिश्चित करना शामिल है।
उ. हां, एलएलएम स्वास्थ्य देखभाल में शैक्षिक उपकरण के रूप में काम कर सकते हैं। वे चिकित्सा अवधारणाओं को पढ़ाने में मदद करते हैं और समझने में आसान तरीके से बहुमूल्य जानकारी साझा करते हैं। इससे विभिन्न प्रकार के छात्रों, स्वास्थ्य देखभाल पेशेवरों और यहां तक कि उन रोगियों को भी लाभ हो सकता है जो अपनी स्थितियों के बारे में अधिक जानना चाहते हैं।
इस लेख में दिखाया गया मीडिया एनालिटिक्स विद्या के स्वामित्व में नहीं है और इसका उपयोग लेखक के विवेक पर किया जाता है।
सम्बंधित
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2023/10/the-impact-of-large-language-models-on-medical-text-analysis/

