ऑटो एम.एम.एल. आपको मशीन लर्निंग (एमएल) प्रोजेक्ट जीवनचक्र की शुरुआत में ही अपने डेटा से तीव्र, सामान्य अंतर्दृष्टि प्राप्त करने की अनुमति देता है। पहले से यह समझने से कि कौन सी प्रीप्रोसेसिंग तकनीक और एल्गोरिदम प्रकार सर्वोत्तम परिणाम प्रदान करते हैं, सही मॉडल को विकसित करने, प्रशिक्षित करने और तैनात करने में लगने वाले समय को कम कर देते हैं। यह प्रत्येक मॉडल की विकास प्रक्रिया में एक महत्वपूर्ण भूमिका निभाता है और डेटा वैज्ञानिकों को सबसे आशाजनक एमएल तकनीकों पर ध्यान केंद्रित करने की अनुमति देता है। इसके अतिरिक्त, ऑटोएमएल एक बेसलाइन मॉडल प्रदर्शन प्रदान करता है जो डेटा विज्ञान टीम के लिए एक संदर्भ बिंदु के रूप में काम कर सकता है।
एक ऑटोएमएल टूल आपके डेटा पर विभिन्न एल्गोरिदम और विभिन्न प्रीप्रोसेसिंग तकनीकों का संयोजन लागू करता है। उदाहरण के लिए, यह डेटा को स्केल कर सकता है, यूनीवेरिएट फीचर चयन कर सकता है, विभिन्न भिन्नता सीमा स्तरों पर पीसीए का संचालन कर सकता है और क्लस्टरिंग लागू कर सकता है। ऐसी प्रीप्रोसेसिंग तकनीकों को व्यक्तिगत रूप से लागू किया जा सकता है या पाइपलाइन में जोड़ा जा सकता है। इसके बाद, एक ऑटोएमएल टूल आपके प्रीप्रोसेस्ड डेटासेट के विभिन्न संस्करणों पर विभिन्न मॉडल प्रकारों, जैसे लीनियर रिग्रेशन, इलास्टिक-नेट, या रैंडम फ़ॉरेस्ट को प्रशिक्षित करेगा और हाइपरपैरामीटर ऑप्टिमाइज़ेशन (एचपीओ) करेगा। अमेज़ॅन सैजमेकर ऑटोपायलट एमएल मॉडलों के निर्माण में भारी भार उठाना समाप्त हो जाता है। डेटासेट प्रदान करने के बाद, सेजमेकर ऑटोपायलट सर्वोत्तम मॉडल खोजने के लिए स्वचालित रूप से विभिन्न समाधानों की खोज करता है। लेकिन क्या होगा यदि आप ऑटोएमएल वर्कफ़्लो के अपने अनुकूलित संस्करण को तैनात करना चाहते हैं?
यह पोस्ट दिखाती है कि कस्टम-निर्मित ऑटोएमएल वर्कफ़्लो कैसे बनाया जाए अमेज़न SageMaker का उपयोग अमेज़ॅन सेजमेकर स्वचालित मॉडल ट्यूनिंग नमूना कोड के साथ a में उपलब्ध है गिटहब रेपो।
समाधान अवलोकन
इस उपयोग के मामले में, मान लें कि आप एक डेटा विज्ञान टीम का हिस्सा हैं जो एक विशेष डोमेन में मॉडल विकसित करती है। आपने कस्टम प्रीप्रोसेसिंग तकनीकों का एक सेट विकसित किया है और कई एल्गोरिदम का चयन किया है जिनसे आप आमतौर पर अपनी एमएल समस्या के साथ अच्छा काम करने की उम्मीद करते हैं। नए एमएल उपयोग मामलों पर काम करते समय, आप संभावित समाधानों के दायरे को कम करने के लिए सबसे पहले अपनी प्रीप्रोसेसिंग तकनीकों और एल्गोरिदम का उपयोग करके एक ऑटोएमएल रन करना चाहेंगे।
इस उदाहरण के लिए, आप किसी विशेष डेटासेट का उपयोग नहीं करते हैं; इसके बजाय, आप कैलिफ़ोर्निया हाउसिंग डेटासेट के साथ काम करते हैं जिसे आप आयात करेंगे अमेज़न सरल भंडारण सेवा (अमेज़ॅन एस3)। सेजमेकर एचपीओ का उपयोग करके समाधान के तकनीकी कार्यान्वयन को प्रदर्शित करने पर ध्यान केंद्रित किया गया है, जिसे बाद में किसी भी डेटासेट और डोमेन पर लागू किया जा सकता है।
निम्नलिखित आरेख समग्र समाधान वर्कफ़्लो प्रस्तुत करता है।

.. पूर्वापेक्षाएँ
इस पोस्ट में वॉकथ्रू पूरा करने के लिए निम्नलिखित आवश्यक शर्तें हैं:
समाधान लागू करें
पूरा कोड इसमें उपलब्ध है गीथहब रेपो.
समाधान को लागू करने के चरण (जैसा कि वर्कफ़्लो आरेख में बताया गया है) इस प्रकार हैं:
- एक नोटबुक उदाहरण बनाएँ और निम्नलिखित निर्दिष्ट करें:
- के लिए नोटबुक उदाहरण प्रकार, चुनें एमएल.टी२.मध्यम.
- के लिए लोचदार अनुमान, चुनें कोई नहीं.
- के लिए प्लेटफ़ॉर्म पहचानकर्ता, चुनें अमेज़ॅन लिनक्स 2, ज्यूपिटर लैब 3.
- के लिए IAM भूमिका, डिफ़ॉल्ट चुनें
AmazonSageMaker-ExecutionRole. यदि यह अस्तित्व में नहीं है, तो एक नया बनाएँ AWS पहचान और अभिगम प्रबंधन (आईएएम) भूमिका और संलग्न करें AmazonSageMakerFullAccess IAM नीति.
ध्यान दें कि आपको उत्पादन में न्यूनतम दायरे वाली निष्पादन भूमिका और नीति बनानी चाहिए।
- अपने नोटबुक इंस्टेंस के लिए JupyterLab इंटरफ़ेस खोलें और GitHub रेपो को क्लोन करें।
आप एक नया टर्मिनल सत्र शुरू करके और इसे चलाकर ऐसा कर सकते हैं git clone <REPO> कमांड या यूआई कार्यक्षमता का उपयोग करके, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।

- ओपन
automl.ipynbनोटबुक फ़ाइल, का चयन करेंconda_python3कर्नेल, और ट्रिगर करने के लिए निर्देशों का पालन करें एचपीओ नौकरियों का सेट.
कोड को बिना किसी बदलाव के चलाने के लिए, आपको सेवा कोटा बढ़ाने की आवश्यकता है प्रशिक्षण कार्य उपयोग के लिए ml.m5.बड़ा और सभी प्रशिक्षण नौकरियों में उदाहरणों की संख्या. AWS डिफ़ॉल्ट रूप से दोनों कोटा के लिए केवल 20 समानांतर सेजमेकर प्रशिक्षण नौकरियों की अनुमति देता है। आपको दोनों के लिए कोटा बढ़ाकर 30 करने का अनुरोध करना होगा। दोनों कोटा परिवर्तन आम तौर पर कुछ मिनटों के भीतर स्वीकृत हो जाने चाहिए। को देखें कोटा बढ़ाने की मांग देखें।

यदि आप कोटा बदलना नहीं चाहते हैं, तो आप बस इसके मूल्य को संशोधित कर सकते हैं MAX_PARALLEL_JOBS स्क्रिप्ट में परिवर्तनशील (उदाहरण के लिए, 5 तक)।
- प्रत्येक एचपीओ कार्य का एक सेट पूरा होगा प्रशिक्षण नौकरी परीक्षण करें और इष्टतम हाइपरपैरामीटर के साथ मॉडल को इंगित करें।
- परिणामों का विश्लेषण करें और सबसे अच्छा प्रदर्शन करने वाला मॉडल तैनात करें.
इस समाधान पर आपके AWS खाते में लागत आएगी। इस समाधान की लागत एचपीओ प्रशिक्षण नौकरियों की संख्या और अवधि पर निर्भर करेगी। जैसे-जैसे ये बढ़ेंगे, लागत भी बढ़ेगी। आप प्रशिक्षण समय सीमित करके और कॉन्फ़िगर करके लागत कम कर सकते हैं TuningJobCompletionCriteriaConfig इस पोस्ट में बाद में चर्चा किए गए निर्देशों के अनुसार। मूल्य निर्धारण की जानकारी के लिए, देखें अमेज़न SageMaker मूल्य निर्धारण.
निम्नलिखित अनुभागों में, हम कोड उदाहरणों और परिणामों का विश्लेषण करने और सर्वोत्तम मॉडल का चयन करने के चरणों के साथ नोटबुक पर अधिक विस्तार से चर्चा करते हैं।
प्रारंभिक व्यवस्था
आइए इसे चलाने से शुरुआत करें आयात एवं सेटअप में अनुभाग custom-automl.ipynb स्मरण पुस्तक। यह सभी आवश्यक निर्भरताएँ स्थापित और आयात करता है, एक सेजमेकर सत्र और क्लाइंट को इंस्टेंट करता है, और डेटा संग्रहीत करने के लिए डिफ़ॉल्ट क्षेत्र और S3 बकेट सेट करता है।
डेटा तैयारी
कैलिफ़ोर्निया हाउसिंग डेटासेट डाउनलोड करें और इसे चलाकर तैयार करें डेटा डाउनलोड करें नोटबुक का अनुभाग. डेटासेट को प्रशिक्षण और परीक्षण डेटा फ़्रेम में विभाजित किया गया है और सेजमेकर सत्र डिफ़ॉल्ट S3 बकेट पर अपलोड किया गया है।
संपूर्ण डेटासेट में लक्ष्य सहित कुल मिलाकर 20,640 रिकॉर्ड और 9 कॉलम हैं। लक्ष्य एक घर के औसत मूल्य की भविष्यवाणी करना है (medianHouseValue स्तंभ)। निम्नलिखित स्क्रीनशॉट डेटासेट की शीर्ष पंक्तियाँ दिखाता है।

प्रशिक्षण स्क्रिप्ट टेम्पलेट
इस पोस्ट में ऑटोएमएल वर्कफ़्लो पर आधारित है scikit सीखने प्रीप्रोसेसिंग पाइपलाइन और एल्गोरिदम। इसका उद्देश्य सबसे अच्छा प्रदर्शन करने वाला सेटअप खोजने के लिए विभिन्न प्रीप्रोसेसिंग पाइपलाइनों और एल्गोरिदम का एक बड़ा संयोजन उत्पन्न करना है। आइए एक सामान्य प्रशिक्षण स्क्रिप्ट बनाने से शुरुआत करें, जो नोटबुक इंस्टेंस पर स्थानीय रूप से बनी रहती है। इस स्क्रिप्ट में, दो खाली टिप्पणी ब्लॉक हैं: एक हाइपरपैरामीटर इंजेक्ट करने के लिए और दूसरा प्रीप्रोसेसिंग-मॉडल पाइपलाइन ऑब्जेक्ट के लिए। उन्हें प्रत्येक प्रीप्रोसेसिंग मॉडल उम्मीदवार के लिए गतिशील रूप से इंजेक्ट किया जाएगा। एक सामान्य स्क्रिप्ट रखने का उद्देश्य कार्यान्वयन को सूखा रखना है (खुद को दोहराना नहीं है)।
प्रीप्रोसेसिंग और मॉडल संयोजन बनाएं
RSI preprocessors शब्दकोश में मॉडल की सभी इनपुट सुविधाओं पर लागू प्रीप्रोसेसिंग तकनीकों का एक विवरण शामिल है। प्रत्येक रेसिपी को a का उपयोग करके परिभाषित किया गया है Pipeline या एक FeatureUnion स्किकिट-लर्न से ऑब्जेक्ट, जो व्यक्तिगत डेटा परिवर्तनों को एक साथ जोड़ता है और उन्हें एक साथ रखता है। उदाहरण के लिए, mean-imp-scale एक सरल नुस्खा है जो यह सुनिश्चित करता है कि लापता मानों को संबंधित कॉलम के औसत मानों का उपयोग करके लगाया जाता है और सभी विशेषताओं को इसका उपयोग करके स्केल किया जाता है स्टैंडर्डस्केलर। इसके विपरीत, mean-imp-scale-pca रेसिपी श्रृंखलाएँ कुछ और ऑपरेशनों को एक साथ जोड़ती हैं:
- स्तंभों में लुप्त मानों को उसके माध्य सहित अंकित करें।
- माध्य और मानक विचलन का उपयोग करके फ़ीचर स्केलिंग लागू करें।
- एक निर्दिष्ट विचरण सीमा मान पर इनपुट डेटा के शीर्ष पर पीसीए की गणना करें और इसे आरोपित और स्केल किए गए इनपुट सुविधाओं के साथ मर्ज करें।
इस पोस्ट में, सभी इनपुट सुविधाएँ संख्यात्मक हैं। यदि आपके इनपुट डेटासेट में अधिक डेटा प्रकार हैं, तो आपको एक अधिक जटिल पाइपलाइन निर्दिष्ट करनी चाहिए जहां विभिन्न प्रीप्रोसेसिंग शाखाएं विभिन्न फीचर प्रकार सेटों पर लागू होती हैं।
RSI models शब्दकोश में विभिन्न एल्गोरिदम के विनिर्देश शामिल हैं जिन्हें आप डेटासेट में फिट करते हैं। प्रत्येक मॉडल प्रकार शब्दकोश में निम्नलिखित विशिष्टता के साथ आता है:
- स्क्रिप्ट_आउटपुट - अनुमानक द्वारा उपयोग की जाने वाली प्रशिक्षण स्क्रिप्ट के स्थान को इंगित करता है। यह फ़ील्ड गतिशील रूप से भरी जाती है जब
modelsशब्दकोष के साथ संयुक्त हैpreprocessorsशब्दकोश। - सम्मिलन - उस कोड को परिभाषित करता है जिसे इसमें डाला जाएगा
script_draft.pyऔर बाद में नीचे सहेजा गयाscript_output। चाबी“preprocessor”जानबूझकर खाली छोड़ दिया गया है क्योंकि एकाधिक मॉडल-प्रीप्रोसेसर संयोजन बनाने के लिए यह स्थान प्रीप्रोसेसरों में से एक से भरा हुआ है। - हाइपरपैरामीटर - हाइपरपैरामीटर का एक सेट जो एचपीओ जॉब द्वारा अनुकूलित है।
- include_cls_metadata - सेजमेकर द्वारा अधिक कॉन्फ़िगरेशन विवरण की आवश्यकता है
Tunerवर्ग.
का एक पूरा उदाहरण models शब्दकोश GitHub रिपॉजिटरी में उपलब्ध है।
इसके बाद, आइए इसके माध्यम से पुनरावृति करें preprocessors और models शब्दकोश और सभी संभव संयोजन बनाएँ। उदाहरण के लिए, यदि आपका preprocessors शब्दकोश में 10 व्यंजन हैं और आपके पास 5 मॉडल परिभाषाएँ हैं models शब्दकोश, नव निर्मित पाइपलाइन शब्दकोश में 50 प्रीप्रोसेसर-मॉडल पाइपलाइन शामिल हैं जिनका मूल्यांकन एचपीओ के दौरान किया जाता है। ध्यान दें कि इस बिंदु पर अभी तक व्यक्तिगत पाइपलाइन स्क्रिप्ट नहीं बनाई गई हैं। ज्यूपिटर नोटबुक का अगला कोड ब्लॉक (सेल 9) सभी प्रीप्रोसेसर-मॉडल ऑब्जेक्ट के माध्यम से पुनरावृत्त होता है pipelines शब्दकोश, सभी प्रासंगिक कोड टुकड़े सम्मिलित करता है, और नोटबुक में स्थानीय रूप से स्क्रिप्ट का एक पाइपलाइन-विशिष्ट संस्करण बनाए रखता है। उन स्क्रिप्टों का उपयोग अगले चरणों में व्यक्तिगत अनुमानक बनाते समय किया जाता है जिन्हें आप एचपीओ कार्य में प्लग करते हैं।
अनुमानकों को परिभाषित करें
अब आप सेजमेकर एस्टिमेटर्स को परिभाषित करने पर काम कर सकते हैं जिनका उपयोग एचपीओ कार्य स्क्रिप्ट तैयार होने के बाद करता है। आइए एक रैपर क्लास बनाने से शुरुआत करें जो सभी अनुमानकों के लिए कुछ सामान्य गुणों को परिभाषित करता है। यह से विरासत में मिला है SKLearn वर्ग और भूमिका, उदाहरण संख्या और प्रकार को निर्दिष्ट करता है, साथ ही स्क्रिप्ट द्वारा सुविधाओं और लक्ष्य के रूप में कौन से कॉलम का उपयोग किया जाता है।
आइए निर्माण करें estimators पहले उत्पन्न और स्थित सभी लिपियों के माध्यम से पुनरावृत्ति करके शब्दकोश scripts निर्देशिका। आप इसका उपयोग करके एक नया अनुमानक तैयार करते हैं SKLearnBase क्लास, एक अद्वितीय अनुमानक नाम और स्क्रिप्ट में से एक के साथ। ध्यान दें कि estimators शब्दकोश के दो स्तर हैं: शीर्ष स्तर a को परिभाषित करता है pipeline_family. यह मूल्यांकन किए जाने वाले मॉडल के प्रकार के आधार पर एक तार्किक समूह है और इसकी लंबाई के बराबर है models शब्दकोष। दूसरे स्तर में दिए गए के साथ संयुक्त व्यक्तिगत प्रीप्रोसेसर प्रकार शामिल हैं pipeline_family. एचपीओ कार्य बनाते समय इस तार्किक समूह की आवश्यकता होती है।
एचपीओ ट्यूनर तर्कों को परिभाषित करें
एचपीओ में पासिंग तर्कों को अनुकूलित करने के लिए Tuner कक्षा, द HyperparameterTunerArgs डेटा क्लास को एचपीओ क्लास के लिए आवश्यक तर्कों के साथ आरंभ किया गया है। यह फ़ंक्शंस के एक सेट के साथ आता है, जो यह सुनिश्चित करता है कि एक साथ कई मॉडल परिभाषाओं को तैनात करते समय एचपीओ तर्क अपेक्षित प्रारूप में लौटाए जाएं।
अगला कोड ब्लॉक पहले प्रस्तुत किए गए का उपयोग करता है HyperparameterTunerArgs डेटा वर्ग. आप नाम से एक और शब्दकोष बनाते हैं hp_args और प्रत्येक के लिए विशिष्ट इनपुट पैरामीटर का एक सेट तैयार करें estimator_family से estimators शब्दकोष। प्रत्येक मॉडल परिवार के लिए एचपीओ नौकरियों को आरंभ करते समय इन तर्कों का उपयोग अगले चरण में किया जाता है।
एचपीओ ट्यूनर ऑब्जेक्ट बनाएं
इस चरण में, आप प्रत्येक के लिए अलग-अलग ट्यूनर बनाते हैं estimator_family. आप सभी अनुमानकों में केवल एक लॉन्च करने के बजाय तीन अलग-अलग एचपीओ नौकरियां क्यों बनाते हैं? HyperparameterTuner क्लास इससे जुड़ी 10 मॉडल परिभाषाओं तक ही सीमित है। इसलिए, प्रत्येक एचपीओ किसी दिए गए मॉडल परिवार के लिए सबसे अच्छा प्रदर्शन करने वाला प्रीप्रोसेसर खोजने और उस मॉडल परिवार के हाइपरपैरामीटर को ट्यून करने के लिए जिम्मेदार है।
सेटअप के संबंध में कुछ और बिंदु निम्नलिखित हैं:
- अनुकूलन रणनीति बायेसियन है, जिसका अर्थ है कि एचपीओ सक्रिय रूप से सभी परीक्षणों के प्रदर्शन की निगरानी करता है और अनुकूलन को अधिक आशाजनक हाइपरपैरामीटर संयोजनों की ओर ले जाता है। शीघ्र रुकने की व्यवस्था की जानी चाहिए बंद or ऑटो बायेसियन रणनीति के साथ काम करते समय, जो उस तर्क को स्वयं संभालती है।
- प्रत्येक एचपीओ कार्य अधिकतम 100 कार्यों के लिए चलता है और समानांतर में 10 कार्य चलाता है। यदि आप बड़े डेटासेट के साथ काम कर रहे हैं, तो आप नौकरियों की कुल संख्या बढ़ाना चाहेंगे।
- इसके अतिरिक्त, आप उन सेटिंग्स का उपयोग करना चाह सकते हैं जो नियंत्रित करती हैं कि कोई कार्य कितने समय तक चलता है और आपका एचपीओ कितनी नौकरियों को ट्रिगर कर रहा है। ऐसा करने का एक तरीका अधिकतम रनटाइम को सेकंड में सेट करना है (इस पोस्ट के लिए, हमने इसे 1 घंटे पर सेट किया है)। दूसरा हाल ही में जारी किए गए का उपयोग करना है
TuningJobCompletionCriteriaConfig. यह सेटिंग्स का एक सेट प्रदान करता है जो आपकी नौकरियों की प्रगति की निगरानी करता है और तय करता है कि क्या यह संभावना है कि अधिक नौकरियों से परिणाम में सुधार होगा। इस पोस्ट में, हमने प्रशिक्षण नौकरियों में सुधार न होने की अधिकतम संख्या 20 निर्धारित की है। इस तरह, यदि स्कोर में सुधार नहीं हो रहा है (उदाहरण के लिए, चालीसवें परीक्षण से), तो आपको शेष परीक्षणों के लिए भुगतान नहीं करना होगा।max_jobsपहुंच गया।
आइए अब इसके माध्यम से पुनरावृति करें tuners और hp_args शब्दकोश और सेजमेकर में सभी एचपीओ नौकरियों को ट्रिगर करें। प्रतीक्षा तर्क के उपयोग पर ध्यान दें False, जिसका अर्थ है कि कर्नेल परिणाम पूरा होने तक प्रतीक्षा नहीं करेगा और आप एक ही बार में सभी नौकरियों को ट्रिगर कर सकते हैं।
यह संभावना है कि सभी प्रशिक्षण कार्य पूरे नहीं होंगे और उनमें से कुछ को एचपीओ कार्य द्वारा रोका जा सकता है। इसका कारण यह है TuningJobCompletionCriteriaConfig-यदि निर्दिष्ट मानदंडों में से कोई भी पूरा हो जाता है तो अनुकूलन समाप्त हो जाता है। इस मामले में, जब लगातार 20 नौकरियों के लिए अनुकूलन मानदंड में सुधार नहीं हो रहा है।
परिणाम का विश्लेषण करें
नोटबुक का सेल 15 जाँचता है कि क्या सभी एचपीओ कार्य पूरे हो गए हैं और आगे के विश्लेषण के लिए सभी परिणामों को पांडा डेटा फ्रेम के रूप में संयोजित करता है। परिणामों का विस्तार से विश्लेषण करने से पहले, आइए सेजमेकर कंसोल पर एक उच्च-स्तरीय नज़र डालें।
के शीर्ष पर हाइपरपैरामीटर ट्यूनिंग कार्य पेज पर, आप अपनी तीन लॉन्च की गई एचपीओ नौकरियां देख सकते हैं। वे सभी जल्दी समाप्त हो गए और सभी 100 प्रशिक्षण कार्य नहीं किए। निम्नलिखित स्क्रीनशॉट में, आप देख सकते हैं कि इलास्टिक-नेट मॉडल परिवार ने सबसे अधिक संख्या में परीक्षण पूरे किए, जबकि अन्य को सर्वोत्तम परिणाम प्राप्त करने के लिए इतनी अधिक प्रशिक्षण नौकरियों की आवश्यकता नहीं थी।
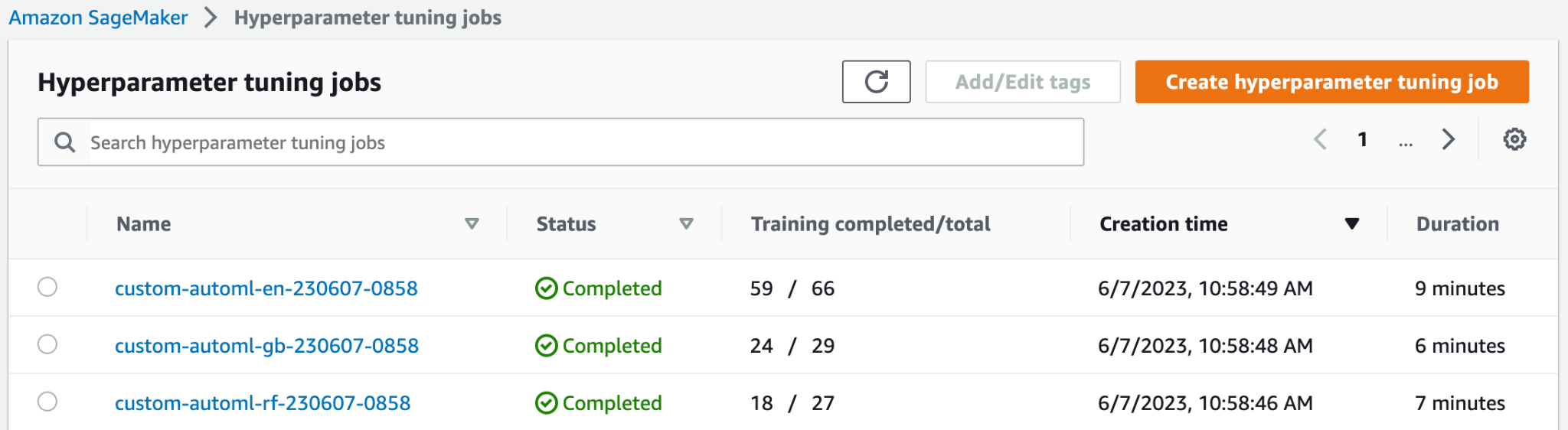
आप व्यक्तिगत प्रशिक्षण नौकरियों, नौकरी कॉन्फ़िगरेशन और सर्वोत्तम प्रशिक्षण नौकरी की जानकारी और प्रदर्शन जैसे अधिक विवरणों तक पहुंचने के लिए एचपीओ नौकरी खोल सकते हैं।

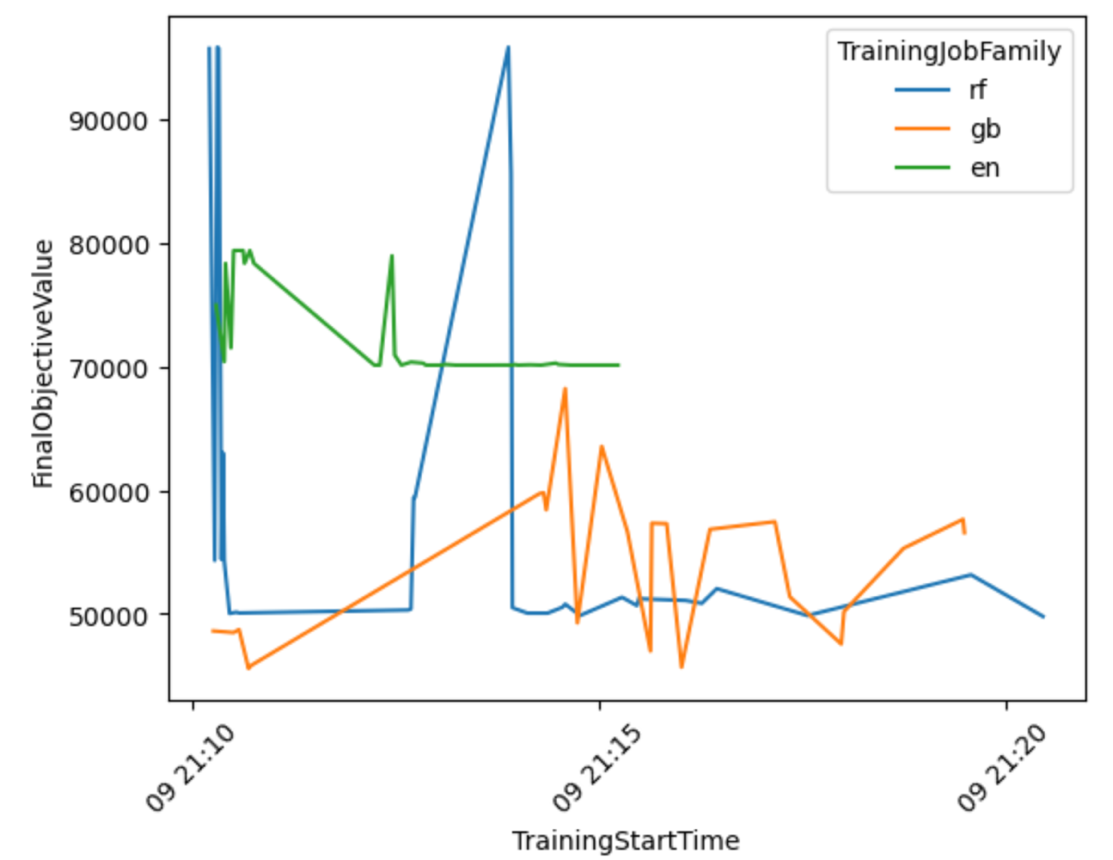
आइए सभी मॉडल परिवारों में ऑटोएमएल वर्कफ़्लो प्रदर्शन की अधिक जानकारी प्राप्त करने के लिए परिणामों के आधार पर एक विज़ुअलाइज़ेशन तैयार करें।
निम्नलिखित ग्राफ़ से, आप यह निष्कर्ष निकाल सकते हैं कि Elastic-Net मॉडल का प्रदर्शन 70,000 और 80,000 RMSE के बीच झूल रहा था और अंततः रुक गया, क्योंकि विभिन्न प्रीप्रोसेसिंग तकनीकों और हाइपरपैरामीटर मानों को आज़माने के बावजूद एल्गोरिदम अपने प्रदर्शन में सुधार करने में सक्षम नहीं था। ऐसा भी लगता है RandomForest एचपीओ द्वारा खोजे गए हाइपरपैरामीटर सेट के आधार पर प्रदर्शन में बहुत भिन्नता थी, लेकिन कई परीक्षणों के बावजूद यह 50,000 आरएमएसई त्रुटि से नीचे नहीं जा सका। GradientBoosting 50,000 आरएमएसई से नीचे जाकर शुरुआत से ही सर्वश्रेष्ठ प्रदर्शन हासिल किया। एचपीओ ने उस परिणाम को और बेहतर बनाने की कोशिश की लेकिन अन्य हाइपरपैरामीटर संयोजनों में बेहतर प्रदर्शन हासिल करने में सक्षम नहीं हो सका। सभी एचपीओ नौकरियों के लिए एक सामान्य निष्कर्ष यह है कि प्रत्येक एल्गोरिदम के लिए हाइपरपैरामीटर का सबसे अच्छा प्रदर्शन करने वाला सेट खोजने के लिए इतनी अधिक नौकरियों की आवश्यकता नहीं थी। परिणाम को और बेहतर बनाने के लिए, आपको अधिक सुविधाएँ बनाने और अतिरिक्त फ़ीचर इंजीनियरिंग निष्पादित करने के लिए प्रयोग करने की आवश्यकता होगी।
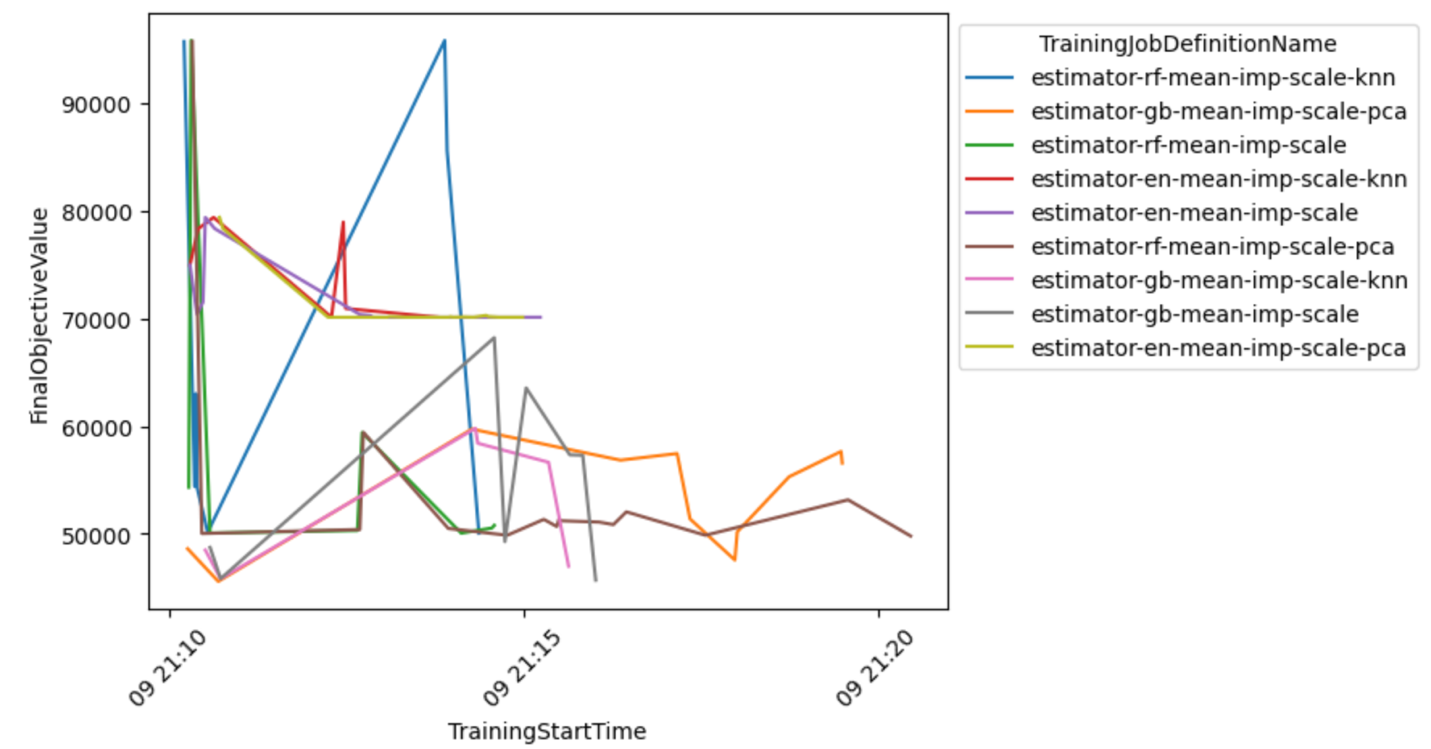
आप सबसे आशाजनक संयोजनों के बारे में निष्कर्ष निकालने के लिए मॉडल-प्रीप्रोसेसर संयोजन के अधिक विस्तृत दृश्य की भी जांच कर सकते हैं।
सर्वोत्तम मॉडल का चयन करें और उसे तैनात करें
निम्नलिखित कोड स्निपेट न्यूनतम प्राप्त उद्देश्य मान के आधार पर सर्वश्रेष्ठ मॉडल का चयन करता है। फिर आप मॉडल को सेजमेकर एंडपॉइंट के रूप में तैनात कर सकते हैं।
क्लीन अप
आपके AWS खाते पर अवांछित शुल्कों को रोकने के लिए, हम इस पोस्ट में आपके द्वारा उपयोग किए गए AWS संसाधनों को हटाने की अनुशंसा करते हैं:
- अमेज़ॅन S3 कंसोल पर, S3 बकेट से डेटा खाली करें जहां प्रशिक्षण डेटा संग्रहीत किया गया था।

- सेजमेकर कंसोल पर, नोटबुक इंस्टेंस को रोकें।

- यदि आपने मॉडल एंडपॉइंट को तैनात किया है तो उसे हटा दें। जब उपयोग में न रह जाएं तो एंडपॉइंट को हटा देना चाहिए, क्योंकि उनका बिल समय के अनुसार लगाया जाता है।
निष्कर्ष
इस पोस्ट में, हमने दिखाया कि एल्गोरिदम और प्रीप्रोसेसिंग तकनीकों के कस्टम चयन का उपयोग करके सेजमेकर में एक कस्टम एचपीओ जॉब कैसे बनाया जाए। विशेष रूप से, यह उदाहरण दर्शाता है कि कई प्रशिक्षण स्क्रिप्ट बनाने की प्रक्रिया को कैसे स्वचालित किया जाए और कई समानांतर अनुकूलन नौकरियों की कुशल तैनाती के लिए पायथन प्रोग्रामिंग संरचनाओं का उपयोग कैसे किया जाए। हमें उम्मीद है कि यह समाधान आपके एमएल वर्कफ़्लो के उच्च प्रदर्शन और गति को प्राप्त करने के लिए सेजमेकर का उपयोग करके आपके द्वारा तैनात किए जाने वाले किसी भी कस्टम मॉडल ट्यूनिंग जॉब के लिए आधार बनेगा।
सेजमेकर एचपीओ का उपयोग करने के तरीके के बारे में अपने ज्ञान को और गहरा करने के लिए निम्नलिखित संसाधनों की जाँच करें:
लेखक के बारे में
 कोनराड सेम्श अमेज़ॅन वेब सर्विसेज डेटा लैब टीम में एक वरिष्ठ एमएल सॉल्यूशंस आर्किटेक्ट हैं। वह ग्राहकों को AWS के साथ उनकी व्यावसायिक चुनौतियों को हल करने के लिए मशीन लर्निंग का उपयोग करने में मदद करता है। उन्हें ग्राहकों को उनकी एआई/एमएल परियोजनाओं के लिए सरल और व्यावहारिक समाधान प्रदान करने के लिए आविष्कार और सरलीकरण करने में आनंद आता है। वह MlOps और पारंपरिक डेटा विज्ञान के बारे में सबसे अधिक भावुक हैं। काम के अलावा, वह विंडसर्फिंग और काइटसर्फिंग का बहुत बड़ा प्रशंसक है।
कोनराड सेम्श अमेज़ॅन वेब सर्विसेज डेटा लैब टीम में एक वरिष्ठ एमएल सॉल्यूशंस आर्किटेक्ट हैं। वह ग्राहकों को AWS के साथ उनकी व्यावसायिक चुनौतियों को हल करने के लिए मशीन लर्निंग का उपयोग करने में मदद करता है। उन्हें ग्राहकों को उनकी एआई/एमएल परियोजनाओं के लिए सरल और व्यावहारिक समाधान प्रदान करने के लिए आविष्कार और सरलीकरण करने में आनंद आता है। वह MlOps और पारंपरिक डेटा विज्ञान के बारे में सबसे अधिक भावुक हैं। काम के अलावा, वह विंडसर्फिंग और काइटसर्फिंग का बहुत बड़ा प्रशंसक है।
 टूना एर्सॉय AWS में एक वरिष्ठ समाधान वास्तुकार हैं। उनका प्राथमिक ध्यान सार्वजनिक क्षेत्र के ग्राहकों को उनके कार्यभार के लिए क्लाउड प्रौद्योगिकियों को अपनाने में मदद करना है। उसके पास एप्लिकेशन डेवलपमेंट, एंटरप्राइज़ आर्किटेक्चर और संपर्क केंद्र प्रौद्योगिकियों की पृष्ठभूमि है। उनकी रुचियों में सर्वर रहित आर्किटेक्चर और एआई/एमएल शामिल हैं।
टूना एर्सॉय AWS में एक वरिष्ठ समाधान वास्तुकार हैं। उनका प्राथमिक ध्यान सार्वजनिक क्षेत्र के ग्राहकों को उनके कार्यभार के लिए क्लाउड प्रौद्योगिकियों को अपनाने में मदद करना है। उसके पास एप्लिकेशन डेवलपमेंट, एंटरप्राइज़ आर्किटेक्चर और संपर्क केंद्र प्रौद्योगिकियों की पृष्ठभूमि है। उनकी रुचियों में सर्वर रहित आर्किटेक्चर और एआई/एमएल शामिल हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/implement-a-custom-automl-job-using-pre-selected-algorithms-in-amazon-sagemaker-automatic-model-tuning/

