
« Mieux vaut prévenir que guérir », dit le vieil adage, qui nous rappelle qu'il est plus facile d'empêcher quelque chose de se produire en premier lieu que de réparer les dégâts après qu'ils se soient produits.
À l’ère de l’intelligence artificielle (IA), ce proverbe souligne l’importance d’éviter les pièges potentiels, tels que le surajustement, grâce à des techniques comme la régularisation.
Dans cet article, nous découvrirons la régularisation en commençant par ses principes fondamentaux jusqu'à son application à l'aide de Sci-kit Learn (Machine Learning) et Tensorflow (Deep Learning) et serons témoins de son pouvoir de transformation avec des ensembles de données du monde réel en comparant ces résultats. Commençons!
La régularisation est un concept essentiel de l'apprentissage automatique et de l'apprentissage profond qui vise à empêcher le surajustement des modèles.
Le surajustement se produit lorsqu'un modèle apprend trop bien les données d'entraînement. La situation montre que votre modèle est trop beau pour être vrai.
Voyons à quoi ressemble le surapprentissage.
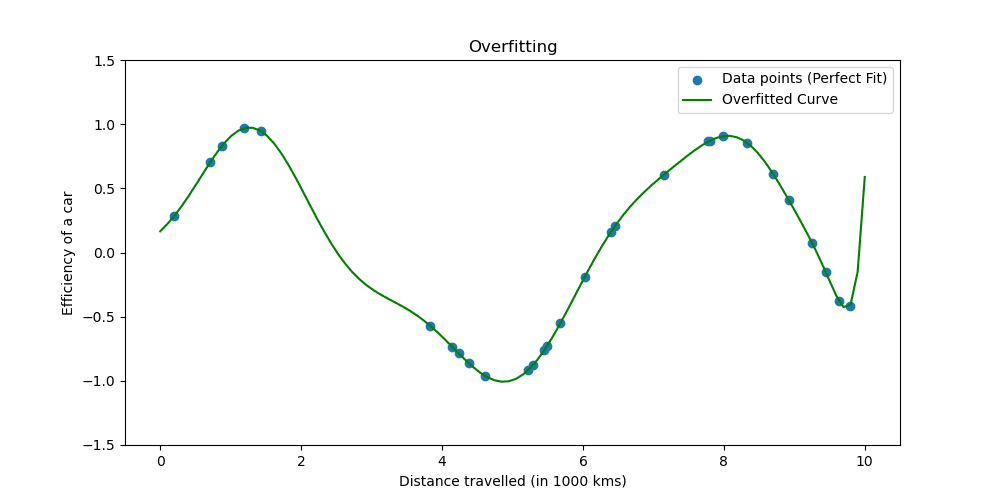
Les techniques de régularisation ajustent le processus d'apprentissage pour simplifier le modèle, garantissant qu'il fonctionne bien sur les données d'entraînement et qu'il se généralise bien aux nouvelles données. Nous allons explorer deux manières bien connues de procéder.
En apprentissage automatique, la régularisation est souvent appliquée aux modèles linéaires, tels que la régression linéaire et logistique. Dans ce contexte, les formes de régularisation les plus courantes sont :
- Régularisation L1 (régression Lasso)
- Régularisation L2 (régression Ridge)
Régularisation au lasso encourage le modèle à utiliser uniquement les fonctionnalités les plus essentielles en permettant à certaines valeurs de coefficient d'être exactement nulles, ce qui peut être particulièrement utile pour la sélection des fonctionnalités.


D'autre part, Régularisation des crêtes décourage les coefficients significatifs en pénalisant le carré de leurs valeurs.

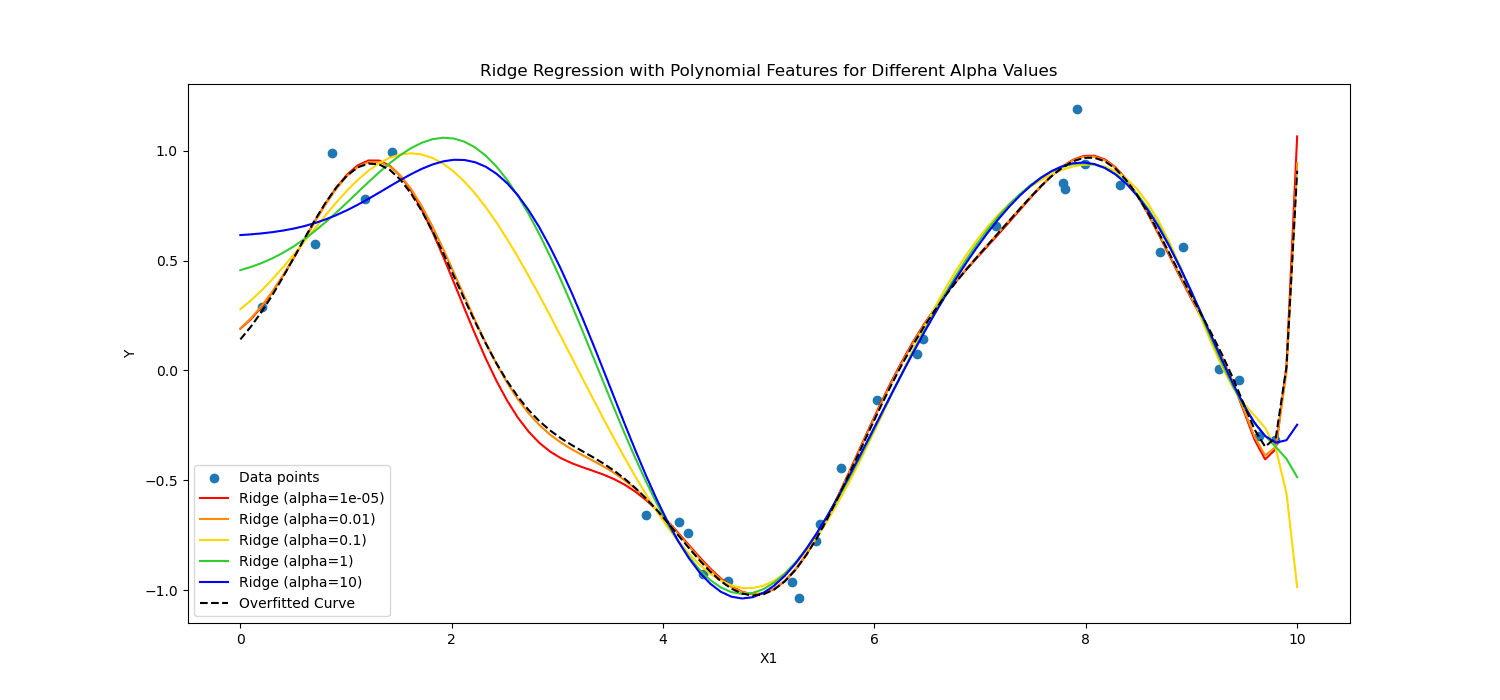
Bref, ils ont calculé différemment.
Appliquons-les aux données des patients cardiaques pour voir leur puissance en matière d'apprentissage profond et d'apprentissage automatique.
Nous allons maintenant appliquer la régularisation pour analyser les données des patients cardiaques afin de constater le pouvoir de la régularisation. Vous pouvez accéder à l'ensemble de données à partir de ici.
Pour appliquer l'apprentissage automatique, nous utiliserons Scikit-learn ; pour appliquer le deep learning, nous utiliserons TensorFlow. Commençons!
Régularisation en Machine Learning
Scikit-learn est l'un des plus populaires Bibliothèques Python pour l'apprentissage automatique qui fournit des outils d'analyse et de modélisation de données simples et efficaces.
Il comprend des implémentations de diverses techniques de régularisation, notamment pour les modèles linéaires.
Ici, nous allons explorer comment appliquer la régularisation L1 (Lasso) et L2 (Ridge).
Dans le code suivant, nous entraînerons la régression logistique à l'aide des techniques de régularisation Ridge (L2) et Lasso (L1). À la fin, nous verrons le rapport détaillé. Voyons le code.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
Voici la sortie.
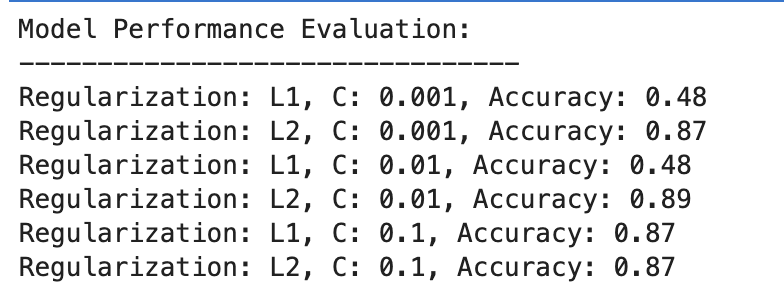
Évaluons le résultat.
Régularisation L1
- À C=0.001, la précision est particulièrement faible (48 %). Cela montre que le modèle est sous-ajusté. Cela montre trop de régularisation.
- À mesure que C augmente jusqu'à 0.01, la précision reste inchangée pour L1, ce qui suggère que le modèle souffre toujours d'un sous-ajustement ou que la régularisation est trop forte.
- À C = 0.1, la précision s'améliore considérablement jusqu'à 87 %, ce qui montre que la réduction de la force de régularisation permet au modèle de mieux apprendre des données.
Régularisation L2
Dans l’ensemble, la régularisation L2 fonctionne toujours bien, avec une précision à 87 % pour C=0.001 et légèrement plus élevée à 89 % pour C=0.01, puis se stabilise à 87 % pour C=0.1.
Cela suggère que la régularisation L2 est généralement plus indulgente et efficace pour cet ensemble de données dans les modèles de régression logistique, potentiellement en raison de sa nature.
Régularisation en Deep Learning
Plusieurs techniques de régularisation sont utilisées dans l'apprentissage profond, notamment la régularisation L1 (Lasso) et L2 (Ridge), l'abandon et l'arrêt anticipé.
Dans celui-ci, pour répéter ce que nous avons fait dans l’exemple de machine learning précédent, nous appliquerons la régularisation L1 et L2. Définissons cette fois une liste de valeurs de régularisation L1 et L2.
Ensuite, pour toutes ces valeurs, nous entraînerons et évaluerons notre modèle d'apprentissage profond, et à la fin, nous évaluerons les résultats.
Voyons le code.
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:8} | {metrics[1]:8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
Voici la sortie.
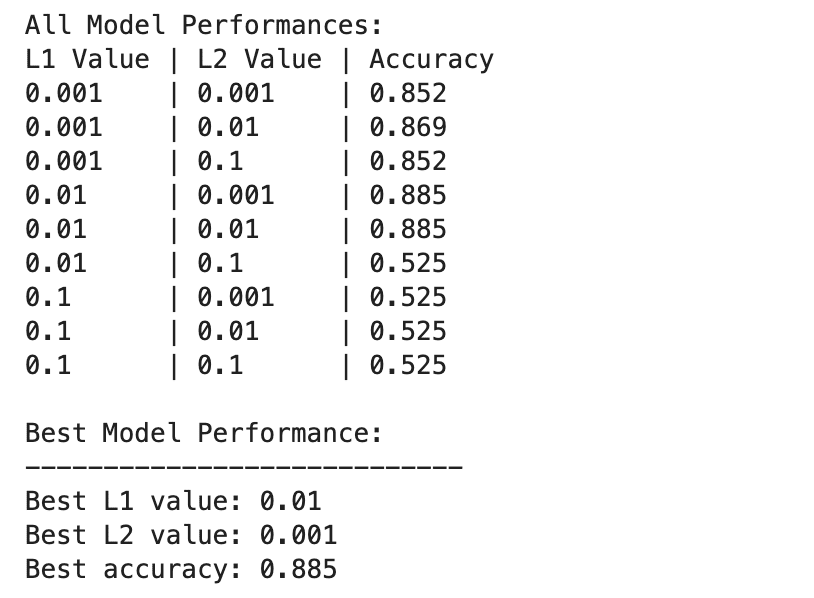
Les performances du modèle d'apprentissage profond varient plus considérablement selon différentes combinaisons de valeurs de régularisation L1 et L2.
Les meilleures performances sont observées à L1=0.01 et L2=0.001, avec une précision de 88.5 %, ce qui indique une régularisation équilibrée qui empêche le surajustement tout en permettant au modèle de capturer les modèles sous-jacents dans les données.
Des valeurs de régularisation plus élevées, en particulier à L1=0.1 ou L2=0.1, réduisent considérablement la précision du modèle à 52.5 %, ce qui suggère qu'une régularisation trop importante limite considérablement la capacité d'apprentissage du modèle.
Machine Learning et Deep Learning en régularisation
Comparons les résultats entre le Machine Learning et le Deep Learning.
Efficacité de la régularisation: Tant dans les contextes d'apprentissage automatique que d'apprentissage profond, une régularisation appropriée aide à atténuer le surapprentissage, mais une régularisation excessive conduit à un sous-apprentissage. La force de régularisation optimale varie, les modèles d’apprentissage profond nécessitant potentiellement un équilibre plus nuancé en raison de leur plus grande complexité.
Performance : Le modèle d'apprentissage automatique le plus performant (L2 avec C=0.01, précision de 89 %) et le modèle d'apprentissage profond le plus performant (L1=0.01, L2=0.001, précision de 88.5 %) atteignent des précisions comparables, démontrant que les deux approches peuvent être efficaces. régularisé pour atteindre des performances élevées sur cet ensemble de données.
Stratégie de régularisation : La régularisation L2 semble être plus efficace et moins sensible au choix de C dans les modèles de régression logistique, tandis qu'une combinaison de régularisation L1 et L2 fournit le meilleur résultat en apprentissage profond, offrant un équilibre entre sélection de caractéristiques et pénalisation de poids.
Le choix et la force de la régularisation doivent être soigneusement ajustés pour équilibrer la complexité de l’apprentissage avec le risque de surapprentissage ou de sous-apprentissage.
Tout au long de cette exploration, nous avons démystifié la régularisation, montrant son rôle dans la prévention du surajustement et garantissant que nos modèles se généralisent bien à des données invisibles.
L'application de techniques de régularisation vous rapprochera de la maîtrise de l'apprentissage automatique et de l'apprentissage profond, renforçant ainsi votre ensemble d'outils de data scientist.
Accédez aux projets de données et essayez de régulariser vos données dans différents scénarios, tels que Prévision de la durée de livraison. Nous avons utilisé à la fois des modèles de Machine Learning et de Deep Learning dans ce projet de données. Cependant, en fin de compte, nous avons également mentionné qu’il pourrait y avoir des améliorations à apporter. Alors pourquoi n'essayez-vous pas la régularisation là-bas et voyez si cela aide ?
Nate Rosidi est data scientist et en stratégie produit. Il est également professeur adjoint enseignant l'analytique et fondateur de StrataScratch, une plate-forme aidant les data scientists à préparer leurs entretiens avec de vraies questions d'entretien posées par les meilleures entreprises. Connectez-vous avec lui sur Twitter : StrataScratch or LinkedIn.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-regularization-and-what-is-it-for

