À l’ère numérique d’aujourd’hui, les données sont au cœur du succès de toute organisation. L'un des formats les plus couramment utilisés pour échanger des données est XML. L'analyse des fichiers XML est cruciale pour plusieurs raisons. Premièrement, les fichiers XML sont utilisés dans de nombreux secteurs, notamment la finance, la santé et le gouvernement. L'analyse des fichiers XML peut aider les organisations à mieux comprendre leurs données, leur permettant ainsi de prendre de meilleures décisions et d'améliorer leurs opérations. L'analyse des fichiers XML peut également faciliter l'intégration des données, car de nombreuses applications et systèmes utilisent XML comme format de données standard. En analysant les fichiers XML, les organisations peuvent facilement intégrer des données provenant de différentes sources et garantir la cohérence entre leurs systèmes. Cependant, les fichiers XML contiennent des données semi-structurées et hautement imbriquées, ce qui rend difficile l'accès et l'analyse des informations, surtout si le fichier est volumineux et a schéma complexe et hautement imbriqué.
Les fichiers XML conviennent bien aux applications, mais ils ne sont peut-être pas optimaux pour les moteurs d'analyse. Afin d'améliorer les performances des requêtes et de permettre un accès facile aux moteurs d'analyse en aval tels que Amazone Athéna, il est crucial de prétraiter les fichiers XML dans un format en colonnes comme Parquet. Cette transformation permet d'améliorer l'efficacité et la convivialité des flux de travail d'analyse. Dans cet article, nous montrons comment traiter les données XML à l'aide Colle AWS et Athéna.
Vue d'ensemble de la solution
Nous explorons deux techniques distinctes qui peuvent rationaliser votre flux de travail de traitement de fichiers XML :
- Technique 1 : utiliser un robot d'exploration AWS Glue et l'éditeur visuel AWS Glue – Vous pouvez utiliser l'interface utilisateur d'AWS Glue conjointement avec un robot d'exploration pour définir la structure des tables de vos fichiers XML. Cette approche offre une interface conviviale et convient particulièrement aux personnes qui préfèrent une approche graphique pour gérer leurs données.
- Technique 2 : utiliser AWS Glue DynamicFrames avec des schémas déduits et fixes – Le robot d'exploration a une limitation lorsqu'il s'agit de traiter une seule ligne dans des fichiers XML de taille supérieure à 1 MB. Pour surmonter cette restriction, nous utilisons un bloc-notes AWS Glue pour construire AWS Glue
DynamicFrames, en utilisant à la fois des schémas déduits et fixes. Cette méthode garantit une gestion efficace des fichiers XML dont la taille des lignes dépasse 1 Mo.
Dans les deux approches, notre objectif ultime est de convertir les fichiers XML au format Apache Parquet, les rendant ainsi facilement disponibles pour les interrogations à l'aide d'Athena. Grâce à ces techniques, vous pouvez améliorer la vitesse de traitement et l'accessibilité de vos données XML, vous permettant ainsi d'obtenir facilement des informations précieuses.
Pré-requis
Avant de commencer ce didacticiel, remplissez les conditions préalables suivantes (elles s'appliquent aux deux techniques) :
- Téléchargez les fichiers XML technique1.xml ainsi que technique2.xml.
- Téléchargez les fichiers sur un Service de stockage simple Amazon (Amazon S3). Vous pouvez les télécharger dans le même compartiment S3 dans différents dossiers ou dans différents compartiments S3.
- Créer un Gestion des identités et des accès AWS (IAM) pour votre travail ou notebook ETL, comme indiqué dans Configurer les autorisations IAM pour AWS Glue Studio.
- Ajoutez une stratégie en ligne à votre rôle avec le iam:PassRole action:
- Ajoutez une stratégie d'autorisations au rôle ayant accès à votre compartiment S3.
Maintenant que nous en avons fini avec les prérequis, passons à la mise en œuvre de la première technique.
Technique 1 : utiliser un robot d'exploration AWS Glue et l'éditeur visuel
Le diagramme suivant illustre l'architecture simple que vous pouvez utiliser pour implémenter la solution.
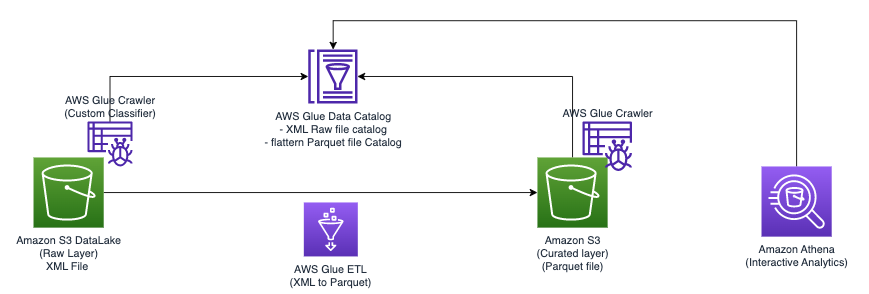
Pour analyser les fichiers XML stockés dans Amazon S3 à l'aide d'AWS Glue et Athena, nous effectuons les étapes générales suivantes :
- Créez un robot d'exploration AWS Glue pour extraire les métadonnées XML et créer une table dans le catalogue de données AWS Glue.
- Traitez et transformez les données XML dans un format (comme Parquet) adapté à Athena à l'aide d'une tâche d'extraction, de transformation et de chargement (ETL) AWS Glue.
- Configurez et exécutez une tâche AWS Glue via la console AWS Glue ou le Interface de ligne de commande AWS (AWS CLI).
- Utilisez les données traitées (au format Parquet) avec les tables Athena, permettant les requêtes SQL.
- Utilisez l'interface conviviale d'Athena pour analyser les données XML avec des requêtes SQL sur vos données stockées dans Amazon S3.
Cette architecture est une solution évolutive et rentable pour analyser les données XML sur Amazon S3 à l'aide d'AWS Glue et d'Athena. Vous pouvez analyser de grands ensembles de données sans gestion complexe de l'infrastructure.
Nous utilisons le robot d'exploration AWS Glue pour extraire les métadonnées des fichiers XML. Vous pouvez choisir le classificateur AWS Glue par défaut pour la classification XML à usage général. Il détecte automatiquement la structure et le schéma des données XML, ce qui est utile pour les formats courants.
Nous utilisons également un classificateur XML personnalisé dans cette solution. Il est conçu pour des schémas ou formats XML spécifiques, permettant une extraction précise des métadonnées. C'est idéal pour les formats XML non standard ou lorsque vous avez besoin d'un contrôle détaillé sur la classification. Un classificateur personnalisé garantit que seules les métadonnées nécessaires sont extraites, simplifiant ainsi les tâches de traitement et d'analyse en aval. Cette approche optimise l'utilisation de vos fichiers XML.
La capture d'écran suivante montre un exemple de fichier XML avec des balises.

Créer un classificateur personnalisé
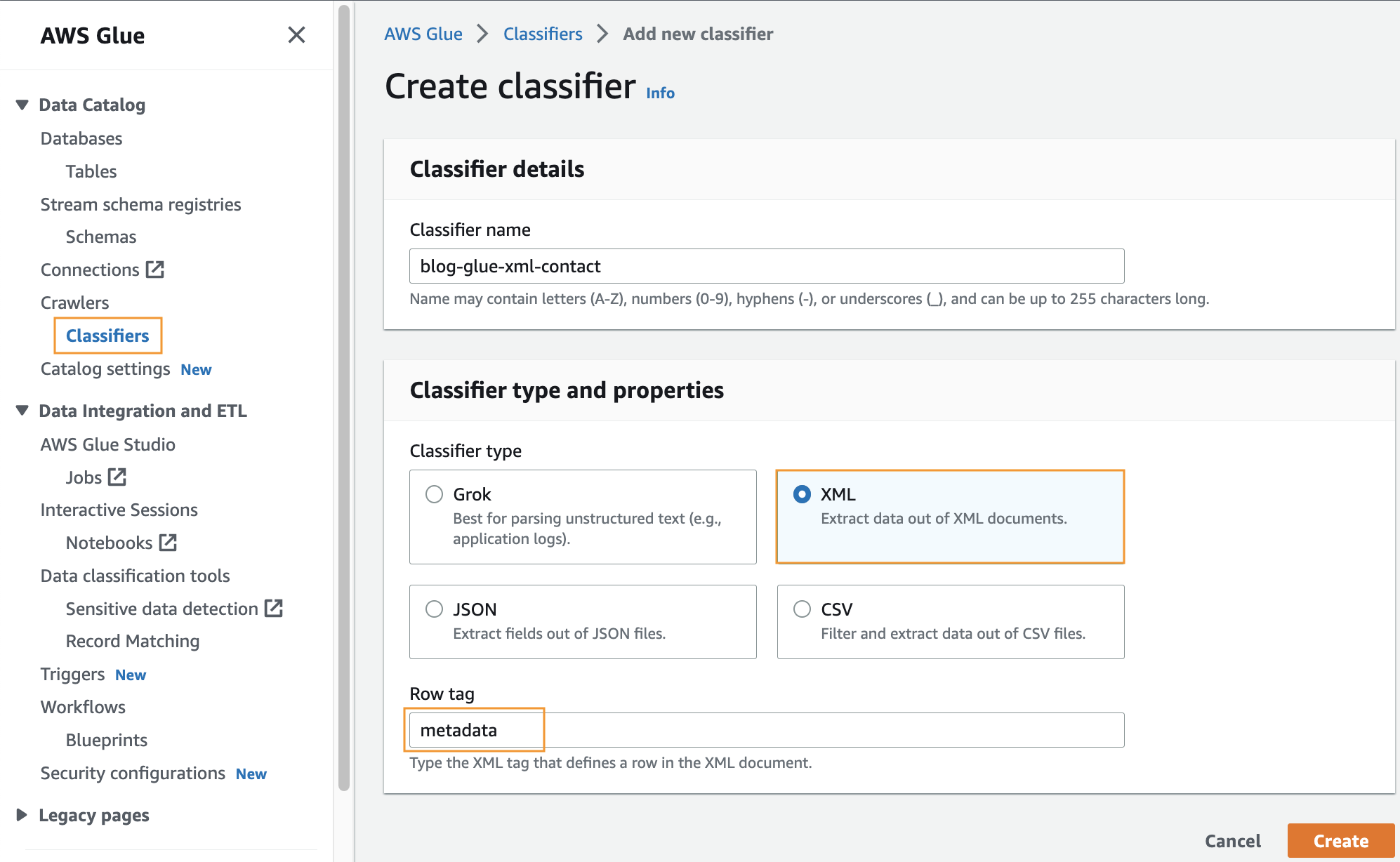
Au cours de cette étape, vous créez un classificateur AWS Glue personnalisé pour extraire les métadonnées d'un fichier XML. Effectuez les étapes suivantes :
- Sur la console AWS Glue, sous Rampeurs dans le volet de navigation, choisissez Classificateurs.
- Selectionnez Ajouter un classificateur.
- Sélectionnez XML comme type de classificateur.
- Entrez un nom pour le classificateur, tel que
blog-glue-xml-contact. - Pour Balise de ligne, saisissez le nom de la balise racine qui contient les métadonnées (par exemple,
metadata). - Selectionnez Création.
Créer un AWS Glue Crawler pour analyser le fichier XML
Dans cette section, nous créons un Glue Crawler pour extraire les métadonnées du fichier XML à l'aide du classificateur client créé à l'étape précédente.
Créer une base de données
- Allez à Console AWS Glue, choisissez Bases de données dans le volet de navigation.
- Cliquez sur Ajouter une base de données.
- Fournissez un nom tel que
blog_glue_xml - Selectionnez Création Base de données
Créer un robot
Suivez les étapes suivantes pour créer votre premier robot :
- Sur la console AWS Glue, choisissez Rampeurs dans le volet de navigation.
- Selectionnez Créer un robot.
- Sur le Définir les propriétés du robot page, fournissez un nom pour le nouveau robot d'exploration (tel que
blog-glue-parquet), Alors choisi Suivant. - Sur le Choisissez des sources de données et des classificateurs page, sélectionnez Pas encore sous Configuration de la source de données.
- Selectionnez Ajouter un magasin de données.
- Pour Chemin S3, accédez à
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Assurez-vous de choisir le dossier XML plutôt que le fichier à l'intérieur du dossier.
- Laissez le reste des options par défaut et choisissez Ajouter une source de données S3.
- Développer vous Classificateurs personnalisés – facultatif, choisissez blog-glue-xml-contact, puis choisissez Suivant et conservez le reste des options par défaut.
- Choisissez votre rôle IAM ou choisissez Créer un nouveau rôle IAM, ajoutez le suffixe
glue-xml-contact(par exemple,AWSGlueServiceNotebookRoleBlog), et choisissez Suivant. - Sur le Définir la sortie et la planification page, sous Configuration de sortie, choisissez
blog_glue_xmlen Base de données cible. - Entrer
console_comme préfixe ajouté aux tableaux (facultatif) et sous Horaire du robot d'exploration, laissez la fréquence réglée sur Sur demande. - Selectionnez Suivant.
- Passez en revue tous les paramètres et choisissez Créer un robot.
Exécutez le robot d'exploration
Après avoir créé le robot d'exploration, procédez comme suit pour l'exécuter :
- Sur la console AWS Glue, choisissez Rampeurs dans le volet de navigation.
- Ouvrez le robot que vous avez créé et choisissez Courir.
Le robot d'exploration prendra 1 à 2 minutes.

- Une fois le robot d'exploration terminé, choisissez Bases de données dans le volet de navigation.
- Choisissez la base de données que vous avez créée et choisissez le nom de la table pour voir le schéma extrait par le robot.

Créez une tâche AWS Glue pour convertir le XML au format Parquet
Au cours de cette étape, vous créez une tâche AWS Glue Studio pour convertir le fichier XML en fichier Parquet. Effectuez les étapes suivantes :
- Sur la console AWS Glue, choisissez Emplois dans le volet de navigation.
- Sous Créer un emploi, sélectionnez Visuel avec une toile vierge.
- Selectionnez Création.
- Renommez le travail en
blog_glue_xml_job.
Vous disposez désormais d'un éditeur de tâches visuel AWS Glue Studio vierge. En haut de l'éditeur se trouvent les onglets pour différentes vues.
- Choisissez le scénario pour voir un shell vide du script AWS Glue ETL.
Au fur et à mesure que nous ajoutons de nouvelles étapes dans l'éditeur visuel, le script sera mis à jour automatiquement.
- Choisissez le Détails du poste pour voir toutes les configurations de tâches.
- Pour Rôle IAM, choisissez
AWSGlueServiceNotebookRoleBlog. - Pour Version colle, choisissez Colle 4.0 – Prise en charge de Spark 3.3, Scala 2, Python 3.
- Ensemble Nombre de travailleurs demandé à 2.
- Ensemble Nombre de tentatives à 0.
- Choisissez le Visuel pour revenir à l'éditeur visuel.
- Sur le Identifier menu déroulant, choisissez Catalogue de données AWS Glue.
- Sur le Propriétés de la source de données – Catalogue de données onglet, fournissez les informations suivantes :
- Pour Base de données, choisissez
blog_glue_xml. - Pour lampe de table, choisissez la table qui commence par le nom console_ créé par le robot d'exploration (par exemple,
console_geologicalsurvey).
- Pour Base de données, choisissez
- Sur le Propriétés du nœud onglet, fournissez les informations suivantes :
- Modifier Nom à
geologicalsurveyjeu de données. - Selectionnez Action et la métamorphose Modifier le schéma (appliquer le mappage).
- Selectionnez Propriétés du nœud et changez le nom de la transformation de Change Schema (Apply Mapping) en
ApplyMapping. - Sur le Target menu, choisissez S3.
- Modifier Nom à
- Sur le Propriétés de la source de données - S3 onglet, fournissez les informations suivantes :
- Pour Format, sélectionnez Parquet.
- Pour Type de compression, sélectionnez Non compressé.
- Pour Type de source S3, sélectionnez Emplacement S3.
- Pour URL S3, Entrer
s3://${BUCKET_NAME}/output/parquet/. - Selectionnez Propriétés du nœud et changez le nom en
Output.
- Selectionnez Épargnez pour sauver le travail.
- Selectionnez Courir pour exécuter le travail.
La capture d'écran suivante montre le travail dans l'éditeur visuel.

Créez un AWS Gue Crawler pour explorer le fichier Parquet
Au cours de cette étape, vous créez un robot d'exploration AWS Glue pour extraire les métadonnées du fichier Parquet que vous avez créé à l'aide d'une tâche AWS Glue Studio. Cette fois, vous utilisez le classificateur par défaut. Effectuez les étapes suivantes :
- Sur la console AWS Glue, choisissez Rampeurs dans le volet de navigation.
- Selectionnez Créer un robot.
- Sur le Définir les propriétés du robot page, indiquez un nom pour le nouveau robot, tel que blog-glue-parquet-contact, puis choisissez Suivant.
- Sur le Choisissez des sources de données et des classificateurs page, sélectionnez Pas encore en Configuration de la source de données.
- Selectionnez Ajouter un magasin de données.
- Pour Chemin S3, accédez à
s3://${BUCKET_NAME}/output/parquet/.
Assurez-vous de choisir le parquet dossier plutôt que le fichier à l’intérieur du dossier.
- Choisissez votre rôle IAM créé lors de la section prérequis ou choisissez Créer un nouveau rôle IAM (par exemple,
AWSGlueServiceNotebookRoleBlog), et choisissez Suivant. - Sur le Définir la sortie et la planification page, sous Configuration de sortie, choisissez
blog_glue_xmlen Base de données. - Entrer
parquet_comme préfixe ajouté aux tableaux (facultatif) et sous Horaire du robot d'exploration, laissez la fréquence réglée sur Sur demande. - Selectionnez Suivant.
- Passez en revue tous les paramètres et choisissez Créer un robot.
Vous pouvez maintenant exécuter le robot d’exploration, ce qui prend 1 à 2 minutes.

Vous pouvez prévisualiser le schéma nouvellement créé pour le fichier Parquet dans le catalogue de données AWS Glue, qui est similaire au schéma du fichier XML.

Nous possédons désormais des données pouvant être utilisées avec Athena. Dans la section suivante, nous effectuons des requêtes de données à l'aide d'Athena.
Interroger le fichier Parquet à l'aide d'Athena
Athena ne prend pas en charge l'interrogation du Format de fichier XML, c'est pourquoi vous avez converti le fichier XML en Parquet pour une interrogation et une utilisation plus efficaces des données. notation par points pour interroger des types complexes et des structures imbriquées.
L'exemple de code suivant utilise la notation par points pour interroger les données imbriquées :

Maintenant que nous avons terminé la technique 1, passons à la technique 2.
Technique 2 : utiliser AWS Glue DynamicFrames avec des schémas déduits et fixes
Dans la section précédente, nous avons abordé le processus de gestion d'un petit fichier XML à l'aide d'un robot d'exploration AWS Glue pour générer une table, d'une tâche AWS Glue pour convertir le fichier au format Parquet et d'Athena pour accéder aux données Parquet. Cependant, le robot rencontre des limitations lorsqu'il s'agit de traiter des fichiers XML dépassant 1 Mo. Dans cette section, nous abordons le sujet du traitement par lots de fichiers XML plus volumineux, nécessitant une analyse supplémentaire pour extraire des événements individuels et effectuer une analyse à l'aide d'Athena.
Notre approche consiste à lire les fichiers XML via AWS Glue Cadres dynamiques, utilisant à la fois des schémas déduits et fixes. Ensuite, nous extrayons les événements individuels au format Parquet en utilisant le relationnaliser transformation, nous permettant de les interroger et de les analyser de manière transparente à l’aide d’Athena.
Pour mettre en œuvre cette solution, vous devez effectuer les étapes de haut niveau suivantes :
- Créez un bloc-notes AWS Glue pour lire et analyser le fichier XML.
- Utilisez
DynamicFramesavecInferSchemapour lire le fichier XML. - Utilisez la fonction relationnalize pour désimbriquer les tableaux.
- Convertissez les données au format Parquet.
- Interrogez les données Parquet à l’aide d’Athena.
- Répétez les étapes précédentes, mais cette fois-ci, transmettez un schéma à
DynamicFramesà la place d'utiliserInferSchema.
Le fichier XML de données sur la population de véhicules électriques a un response balise à son niveau racine. Cette balise contient un tableau de row balises, qui sont imbriquées à l’intérieur. La balise de ligne est un tableau qui contient un ensemble d'autres balises de ligne, qui fournissent des informations sur un véhicule, notamment sa marque, son modèle et d'autres détails pertinents. La capture d'écran suivante montre un exemple.

Créer un bloc-notes AWS Glue
Pour créer un bloc-notes AWS Glue, procédez comme suit :
- Ouvrez le Studio de colle AWS console, choisissez Emplois dans le volet de navigation.
- Sélectionnez Jupyter Notebook et choisissez Création.

- Entrez un nom pour votre tâche AWS Glue, tel que
blog_glue_xml_job_Jupyter. - Choisissez le rôle que vous avez créé dans les prérequis (
AWSGlueServiceNotebookRoleBlog).

Le bloc-notes AWS Glue est livré avec un exemple préexistant qui montre comment interroger une base de données et écrire la sortie sur Amazon S3.
- Ajustez le délai d'expiration (en minutes) comme indiqué dans la capture d'écran suivante et exécutez la cellule pour créer la session interactive AWS Glue.

Créer des variables de base
Après avoir créé la session interactive, à la fin du bloc-notes, créez une nouvelle cellule avec les variables suivantes (indiquez votre propre nom de compartiment) :
Lire le fichier XML déduisant le schéma
Si vous ne transmettez pas de schéma au DynamicFrame, il déduira le schéma des fichiers. Pour lire les données à l'aide d'un frame dynamique, vous pouvez utiliser la commande suivante :
Imprimer le schéma DynamicFrame
Imprimez le schéma avec le code suivant :

Le schéma montre une structure imbriquée avec un row tableau contenant plusieurs éléments. Pour désimbriquer cette structure en lignes, vous pouvez utiliser AWS Glue relationnaliser transformation:
Nous ne nous intéressons qu'aux informations contenues dans le tableau de lignes et nous pouvons afficher le schéma en utilisant la commande suivante :

Les noms de colonnes contiennent row.row, qui correspondent à la structure du tableau et à la colonne du tableau dans l'ensemble de données. Nous ne renommeons pas les colonnes de cet article ; pour obtenir des instructions à cet effet, reportez-vous à Automatisez le mappage dynamique et le renommage des noms de colonnes dans les fichiers de données à l'aide d'AWS Glue : partie 1. Vous pouvez ensuite convertir les données au format Parquet et créer la table AWS Glue à l'aide de la commande suivante :
Colle AWS DynamicFrame fournit des fonctionnalités que vous pouvez utiliser dans votre script ETL pour créer et mettre à jour un schéma dans le catalogue de données. Nous utilisons le updateBehavior paramètre pour créer la table directement dans le Data Catalog. Avec cette approche, nous n'avons pas besoin d'exécuter un robot d'exploration AWS Glue une fois la tâche AWS Glue terminée.

Lire le fichier XML en définissant un schéma
Une autre façon de lire le fichier consiste à prédéfinir un schéma. Pour ce faire, procédez comme suit :
- Importez les types de données AWS Glue :
- Créez un schéma pour le fichier XML :
- Passez le schéma lors de la lecture du fichier XML :
- Désimbriquez l'ensemble de données comme avant :
- Convertissez l'ensemble de données en Parquet et créez la table AWS Glue :
Interrogez les tables à l'aide d'Athena
Maintenant que nous avons créé les deux tables, nous pouvons interroger les tables à l'aide d'Athena. Par exemple, nous pouvons utiliser la requête suivante :

Clean Up
Dans cet article, nous avons créé un rôle IAM, un bloc-notes AWS Glue Jupyter et deux tables dans le catalogue de données AWS Glue. Nous avons également téléchargé certains fichiers dans un compartiment S3. Pour nettoyer ces objets, procédez comme suit :
- Sur la console IAM, supprimez le rôle que vous avez créé.
- Sur la console AWS Glue Studio, supprimez le classificateur personnalisé, le robot d'exploration, les tâches ETL et le bloc-notes Jupyter.
- Accédez au catalogue de données AWS Glue et supprimez les tables que vous avez créées.
- Sur la console Amazon S3, accédez au compartiment que vous avez créé et supprimez les dossiers nommés
temp,infer_schemaetno_infer_schema.
Faits marquants
Dans AWS Glue, il existe une fonctionnalité appelée InferSchema dans AWS Glue DynamicFrames. Il détermine automatiquement la structure d'un bloc de données en fonction des données qu'il contient. En revanche, définir un schéma signifie indiquer explicitement quelle doit être la structure du bloc de données avant de charger les données.
XML, étant un format basé sur du texte, ne restreint pas les types de données de ses colonnes. Cela peut entraîner des problèmes avec la fonction InferSchema. Par exemple, lors de la première exécution, un fichier avec une colonne A ayant une valeur de 2 donne lieu à un fichier Parquet avec une colonne A sous forme d'entier. Lors de la deuxième exécution, un nouveau fichier a la colonne A avec la valeur C, conduisant à un fichier Parquet avec la colonne A comme chaîne. Il existe désormais deux fichiers sur S3, chacun avec une colonne A de types de données différents, ce qui peut créer des problèmes en aval.
La même chose se produit avec les types de données complexes comme les structures ou les tableaux imbriqués. Par exemple, si un fichier comporte une entrée de balise appelée transaction, c'est déduit comme une structure. Mais si un autre fichier a la même balise, il est déduit comme un tableau
Malgré ces problèmes de type de données, InferSchema est utile lorsque vous ne connaissez pas le schéma ou qu'il n'est pas pratique d'en définir un manuellement. Cependant, ce n’est pas idéal pour les ensembles de données volumineux ou en constante évolution. La définition d'un schéma est plus précise, en particulier avec des types de données complexes, mais présente ses propres problèmes, comme nécessiter un effort manuel et être inflexible face aux modifications des données.
InferSchema a des limites, comme une inférence de type de données incorrecte et des problèmes de gestion des valeurs nulles. La définition d'un schéma présente également des limites, telles que l'effort manuel et les erreurs potentielles.
Le choix entre déduire et définir un schéma dépend des besoins du projet. InferSchema est idéal pour l'exploration rapide de petits ensembles de données, tandis que la définition d'un schéma est préférable pour les ensembles de données plus volumineux et complexes nécessitant précision et cohérence. Tenez compte des compromis et des contraintes de chaque méthode pour choisir celle qui convient le mieux à votre projet.
Conclusion
Dans cet article, nous avons exploré deux techniques de gestion des données XML à l'aide d'AWS Glue, chacune étant adaptée pour répondre aux besoins et défis spécifiques que vous pourriez rencontrer.
La Technique 1 offre un parcours convivial pour ceux qui préfèrent une interface graphique. Vous pouvez utiliser un robot d'exploration AWS Glue et l'éditeur visuel pour définir sans effort la structure des tables de vos fichiers XML. Cette approche simplifie le processus de gestion des données et est particulièrement attrayante pour ceux qui recherchent un moyen simple de gérer leurs données.
Cependant, nous reconnaissons que le robot d'exploration a ses limites, en particulier lorsqu'il s'agit de fichiers XML comportant des lignes de plus de 1 Mo. C'est là que la technique 2 vient à la rescousse. En exploitant AWS Glue DynamicFrames avec des schémas déduits et fixes, et en utilisant un bloc-notes AWS Glue, vous pouvez gérer efficacement des fichiers XML de n'importe quelle taille. Cette méthode fournit une solution robuste qui garantit un traitement transparent même pour les fichiers XML dont les lignes dépassent la contrainte de 1 Mo.
Lorsque vous naviguez dans le monde de la gestion des données, disposer de ces techniques dans votre boîte à outils vous permet de prendre des décisions éclairées en fonction des exigences spécifiques de votre projet. Que vous préfériez la simplicité de la technique 1 ou l'évolutivité de la technique 2, AWS Glue offre la flexibilité dont vous avez besoin pour gérer efficacement les données XML.
À propos des auteurs
 Navnit Shuklasert d'architecte de solutions spécialisé AWS avec un accent sur l'analyse. Il possède un grand enthousiasme pour aider les clients à découvrir des informations précieuses à partir de leurs données. Grâce à son expertise, il construit des solutions innovantes qui permettent aux entreprises de prendre des décisions éclairées et fondées sur les données. Notamment, Navnit Shukla est l'auteur accompli du livre intitulé « Data Wrangling on AWS ».
Navnit Shuklasert d'architecte de solutions spécialisé AWS avec un accent sur l'analyse. Il possède un grand enthousiasme pour aider les clients à découvrir des informations précieuses à partir de leurs données. Grâce à son expertise, il construit des solutions innovantes qui permettent aux entreprises de prendre des décisions éclairées et fondées sur les données. Notamment, Navnit Shukla est l'auteur accompli du livre intitulé « Data Wrangling on AWS ».
 Patrick Müller travaille en tant qu'architecte senior de laboratoire de données chez AWS. Sa principale responsabilité est d'aider les clients à transformer leurs idées en un produit de données prêt pour la production. Pendant son temps libre, Patrick aime jouer au football, regarder des films et voyager.
Patrick Müller travaille en tant qu'architecte senior de laboratoire de données chez AWS. Sa principale responsabilité est d'aider les clients à transformer leurs idées en un produit de données prêt pour la production. Pendant son temps libre, Patrick aime jouer au football, regarder des films et voyager.
 Amogh Gaikwad est développeur de solutions senior chez Amazon Web Services. Il aide les clients mondiaux à créer et à déployer des solutions IA/ML sur AWS. Son travail se concentre principalement sur la vision par ordinateur et le traitement du langage naturel et aide les clients à optimiser leurs charges de travail IA/ML dans un souci de durabilité. Amogh a obtenu sa maîtrise en informatique spécialisée en apprentissage automatique.
Amogh Gaikwad est développeur de solutions senior chez Amazon Web Services. Il aide les clients mondiaux à créer et à déployer des solutions IA/ML sur AWS. Son travail se concentre principalement sur la vision par ordinateur et le traitement du langage naturel et aide les clients à optimiser leurs charges de travail IA/ML dans un souci de durabilité. Amogh a obtenu sa maîtrise en informatique spécialisée en apprentissage automatique.
 Sheela Sonone est architecte résident senior chez AWS. Elle aide les clients AWS à faire des choix et des compromis éclairés pour accélérer leurs charges de travail et implémentations de données, d'analyses et d'IA/ML. Dans ses temps libres, elle aime passer du temps avec sa famille, généralement sur les courts de tennis.
Sheela Sonone est architecte résident senior chez AWS. Elle aide les clients AWS à faire des choix et des compromis éclairés pour accélérer leurs charges de travail et implémentations de données, d'analyses et d'IA/ML. Dans ses temps libres, elle aime passer du temps avec sa famille, généralement sur les courts de tennis.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/

