
Image par l'éditeur
Les entreprises du monde entier s'attendent de plus en plus à ce que leurs processus décisionnels soient éclairés par des systèmes d'analyse prédictive basés sur les données, ou du moins ils devraient l'être. De l'investissement en temps opportun à la logistique d'exécution en passant par la prévention de la fraude, les données sont exploitées dans un nombre croissant de flux de travail, avec un nombre croissant d'yeux rivés sur elles. En d'autres termes, les flux d'informations qui étaient souvent relégués aux scientifiques des données sont désormais vus - et manipulés - par des personnes moins averties dans les arts sombres des données.
Aujourd'hui, les profanes des données relatives peuvent soudainement se retrouver avec la responsabilité à la fois de contribuer aux pools de données et d'interpréter leur analyse ML de celles-ci. Cela pourrait conduire à des situations qui font cracher et siffler vos données, au lieu de ronronner de manière coopérative. Pour atténuer le potentiel de rayures dues à une mauvaise hygiène des données due à un ajustement excessif, ou pire, CatBoost saute sur la table de la cuisine, se présentant clairement comme la meilleure option pour de nombreux secteurs verticaux.
ChatBoost est un système ML boostant le gradient qui se distingue des autres GBDT en offrant des solutions uniques pour interpréter les sources de données hautement catégorielles ou contenant des points de données manquants. En effet, c'est là que l'API tire son nom, de Boosting Categories, plutôt que d'une origine féline. Comparaisons côte à côte montrent que CatBoost surpasse également XGBoost et LightBGM de façon significative en termes de délai de livraison des prédictions et de temps de réglage des paramètres, tout en restant comparable dans d'autres métriques.
Sous le capot, CatBoost y parvient en utilisant la méthode de division par popularité pour créer des arbres de décision symétriques. En regroupant les fonctionnalités en une seule division avec seulement un enfant gauche et droit, la puissance et le temps de traitement nécessaires sont considérablement réduits par rapport aux arbres avec des enfants pour chaque fonctionnalité individuelle dans un ensemble. Ces caractéristiques peuvent être catégorielles ou numériques. Ils peuvent ensuite être analysés à différents niveaux de l'arbre jusqu'à ce que la variable cible soit atteinte. Cela régularise efficacement les données, décourageant les points de données de développer des corrélations explicites en offrant plusieurs points de vue sur les mêmes sous-ensembles. Cela donne aux prédictions de CatBoost plus de résilience face aux erreurs de surajustement et de généralisation dans le processus de formation.
Bien que ces points soient évidemment avantageux du point de vue de la science des données et du calcul, leurs avantages pour l'ensemble d'une organisation peuvent être moins apparents.
Ainsi, il ne vous accueille pas avec vos pantoufles lorsque vous arrivez à la maison, il ne vous rend pas les soins et l'attention que vous lui accordez de manière affectueuse, alors comment exactement CatBoost améliore-t-il vos opérations ? Comment l'efficacité de calcul de CatBoost aide-t-elle réellement les fonctions commerciales essentielles, et pour qui ? Certains éléments de l'algorithme de CatBoost semblent être de petites différences par rapport à des systèmes ML similaires, mais se traduisent par d'énormes dividendes logistiques pour de nombreuses entreprises.
Nous allons zoomer sur plusieurs de ces composants, puis revenir en arrière pour voir comment leurs implémentations dans le monde réel aident à rationaliser les processus et, en fin de compte, à économiser de l'argent - économiser de l'argent est un langage que tout le monde parle dans l'entreprise. Les entreprises pourraient reconnaître que certains de leurs points douloureux granulaires sont traités au cours de notre exploration, en particulier s'ils ont été égratignés ou même cicatrisés.
Pour chacune de ces nuances au sein de l'API open source, il existe des avantages pratiques qui sont immédiatement évidents pour les scientifiques des données. Pour le nombre croissant d'équipes non techniques à qui l'on demande de participer à la chaîne d'analyse des données de leur entreprise, ainsi que pour les personnes dont le travail consiste à approuver les flux de travail ML, c'est décidément moins évident.
1 : Pas besoin d'encodage à chaud
CatBoost gère les caractéristiques catégorielles en texte clair, évitant ainsi le besoin d'un prétraitement approfondi, comme avec d'autres GBDT qui insistent sur les entrées numériques. La méthode de prétraitement la plus courante pour les données catégorielles consiste à les étiqueter via un codage à chaud, qui divise les données en binaire, bien que dans certains cas, l'utilisation d'une méthode de codage cible fictive, ordinale, LOO ou bayésienne soit plus applicable, selon la nature de les données. Les caractéristiques catégorielles prétraitées via un codage à chaud peuvent souvent être volumineuses et devenir rapidement trop dimensionnelles. Grâce au système de codage ordinal intégré de CatBoost, les caractéristiques catégorielles se voient attribuer une valeur numérique, mais les longs temps de traitement et les caractéristiques de surajustement des données hautement dimensionnelles sont évités.
Bien que ces calculs puissent se produire dans le cloud, les avantages sur le terrain incluent :
- Comme l'API gère les données catégorielles textuelles de manière native, il y a moins de calculs et moins de transformations des données requises, ce qui entraîne moins d'erreurs.
- Par rapport à l'encodage à chaud, CatBoost décompose les données en moins de fonctionnalités, ce qui augmente la simplicité et finalement l'interprétabilité pour les équipes d'analystes.
- Les données textuelles qui sont introduites dans la bibliothèque sont renvoyées avec la même étiquette de texte, ce qui rationalise également l'interpétabilité.
- CatBoost facilite l'analyse approfondie en permettant de se concentrer facilement sur la contribution d'une seule fonctionnalité au modèle, plutôt que sur une valeur spécifique d'une fonctionnalité spécifique, comme c'est le cas avec les colonnes encodées à chaud. En utilisant la méthode get_feature_importance(), CatBoost mesure les caractéristiques à l'aide des valeurs SHAP, qui peuvent également être facilement visualisées pour l'interprétation et l'analyse (voir ci-dessous).
- De même, cette utilisation de données catégorielles permet au personnel de tous les départements de saisir et d'interpréter les données beaucoup plus facilement.
- Ce niveau d'accessibilité permet aux entreprises d'avoir des flux de données unifiés, de sorte que toutes les branches de l'entreprise se réfèrent à un seul pool d'informations. Les entreprises qui ont été mordues par confusion interministérielle d'avoir plusieurs profils d'une seule entité savent combien de contraintes et de ressources cela peut économiser.
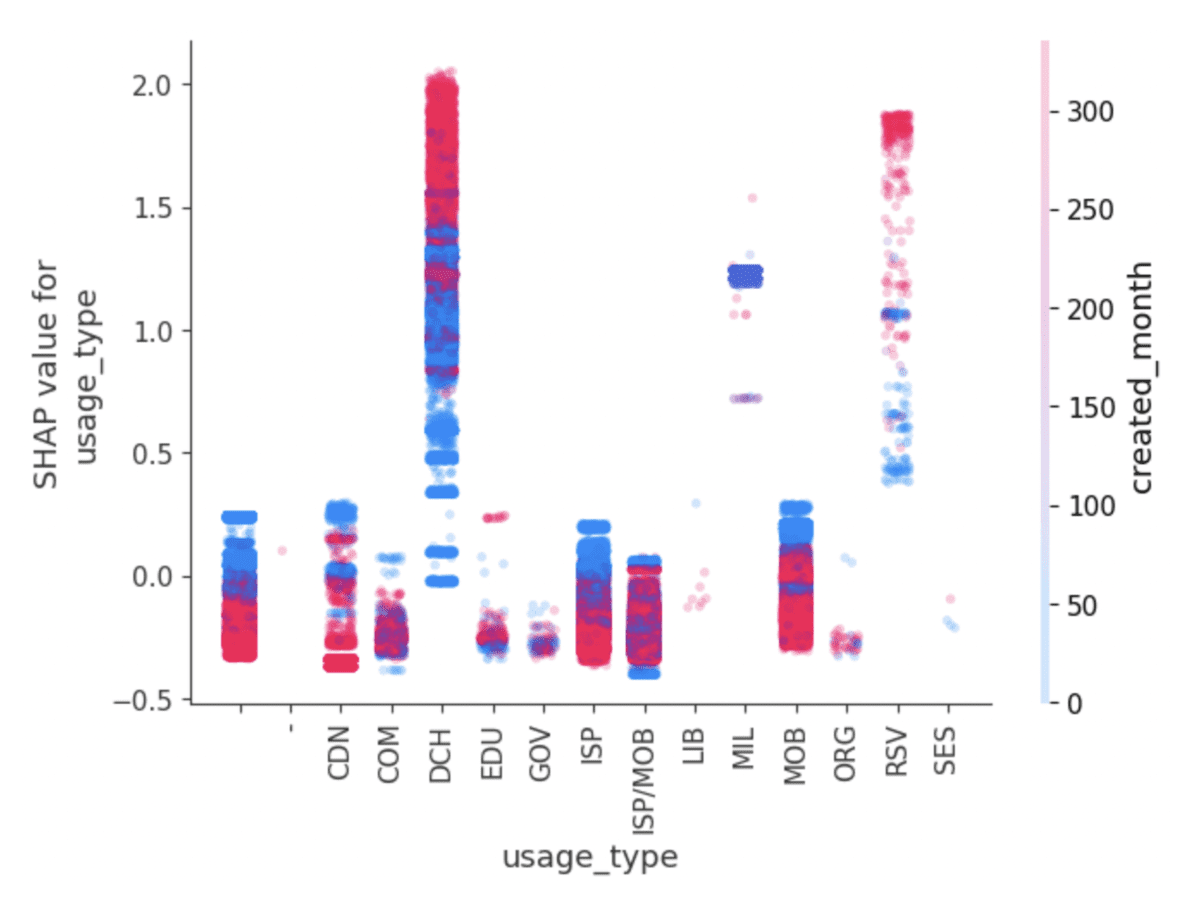
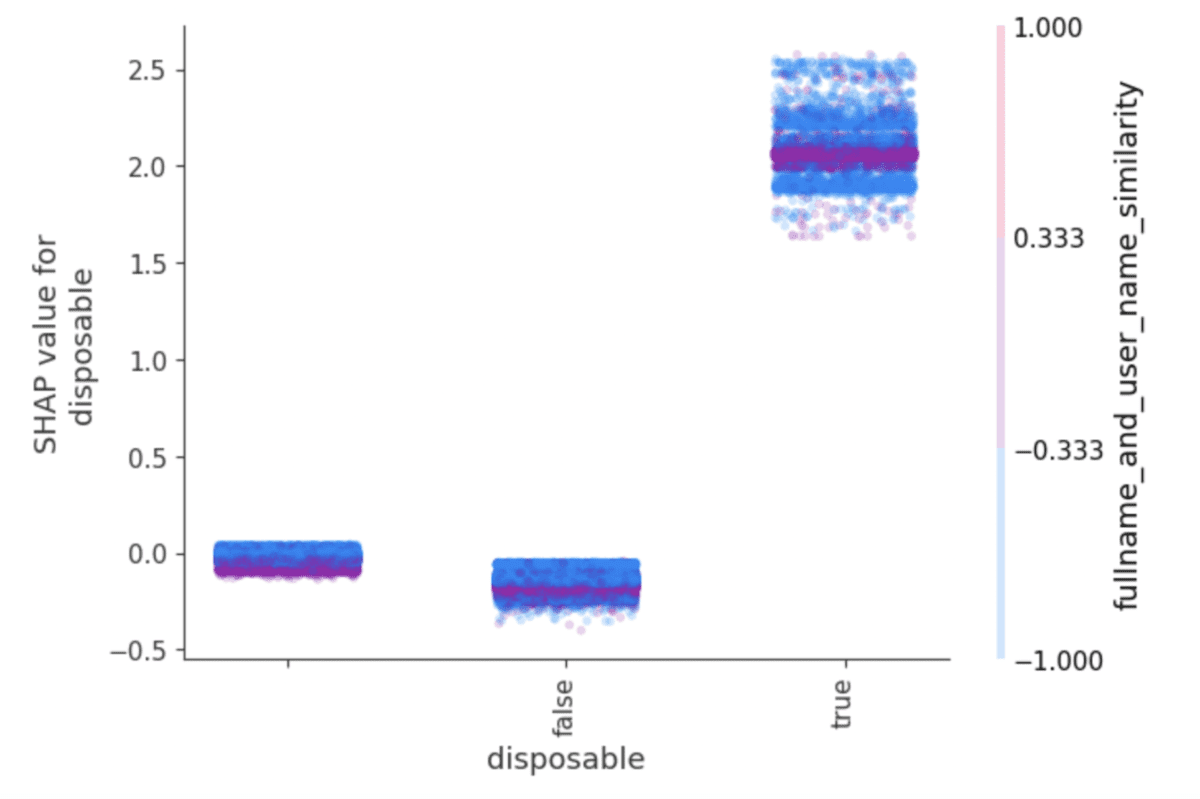
CatBoost héberge nativement la bibliothèque SHAP, facilitant les visualisations de sortie comme celles-ci, qui ont été formées sur les données de prévention de la fraude.
Cet aspect de l'API de CatBoost est un avantage évident pour les marchés verticaux travaillant avec des données intrinsèquement moins numériques que, par exemple, les prévisions financières. Des domaines tels que le diagnostic médical, la prévention de la fraude, la segmentation du marché et la publicité sont tous des domaines qui traitent de grandes quantités de données catégorielles et qui bénéficieraient des griffes habiles de CatBoost pour les traiter.
2 : Arbres inconscients
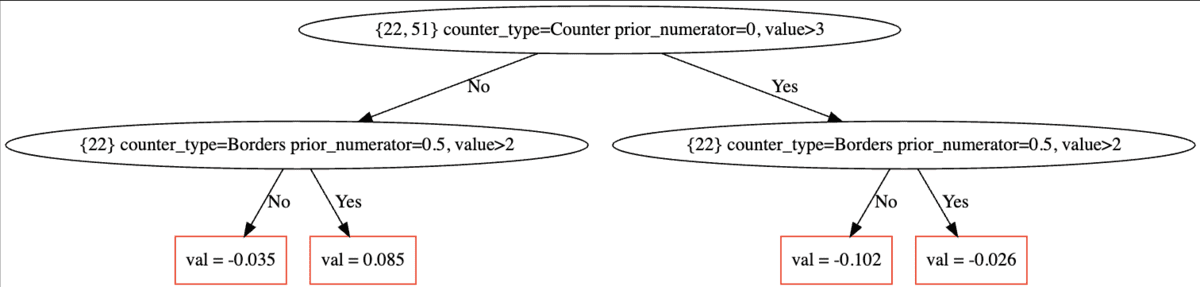
CatBoost exploite des arbres de décision inconscients en tant qu'apprenant de base dans son processus d'amplification du gradient. Cela signifie que chaque arbre est limité à une seule division symétrique, chaque côté étant équilibré par la mesure intégrée de l'importance des caractéristiques de l'algorithme.
Plutôt que d'avoir des nœuds divisés plusieurs fois pour une fonctionnalité hautement dimensionnelle, comme avec XGBoost, CatBoost crée à la place plusieurs niveaux pour analyser une seule fonctionnalité. Cela lui donne la capacité de briller lorsqu'il s'agit de :
- Optimisation du temps et de la puissance de traitement. Les données non numériques hautement dimensionnelles nécessiteront inévitablement plus de temps de traitement et de puissance lorsqu'elles seront transmises via XGBoost par rapport à CatBoost. Une division unique dans chaque nœud signifie une vitesse de traitement nettement plus rapide pour chaque décision, réduisant la consommation d'énergie et optimisant les temps d'attente, en interne ou en externe.
- Régularisation et robustesse contre le surajustement. Les algorithmes qui prennent des fonctionnalités et divisent les arbres en tous les résultats possibles de cette fonctionnalité remarqueront souvent que leurs données sont surajustées. En limitant la complexité de chaque niveau de l'arbre, cela crée essentiellement une ligne de régression plus rigide à travers vos données, une sorte de régularisation de facto. Cela se traduit par moins de faux négatifs et de faux positifs, ce qui pourrait se traduire par la manière dont votre organisation utilise ses données de différentes manières.
- Facilité d'interprétabilité. Encore une fois, en fonction de l'industrie et du processus automatisé, il peut y avoir de bonnes raisons de pouvoir expliquer comment une détermination ML donnée a été effectuée. Cela peut être pour satisfaire un client, mais cela peut également faire partie de la conformité légale lorsqu'il s'agit d'avoir des pratiques loyales de manière transparente ou d'effectuer une diligence raisonnable en matière de sécurité.
Le modèle d'arbre inconscient de CatBoost est ce qui lui donne la plus grande légèreté de traitement et en fait également une option hautement évolutive pour les grands ensembles de données. Lors du traitement de données catégorielles, CatBoost est beaucoup plus efficace pour tirer rapidement des conclusions tout en ignorant le bruit des données. Dans les domaines de la segmentation du marché, de l'optimisation automatisée de la chaîne d'approvisionnement, de la publicité PPC, par exemple, les données bruyantes sont parfois la raison pour laquelle une publicité apparemment aléatoire est ciblée sur votre appareil, ou une chaîne de magasins a trop ou trop peu de quelque chose.
3 : Données « Nan Manipulation »
Les ensembles de données avec des valeurs manquantes sont, bien sûr, moins utiles pour l'analyse en général. Lorsque vous approchez des ensembles de données numériques, plutôt que de laisser ces valeurs manquantes affecter la stabilité du modèle, CatBoost remplace automatiquement les valeurs manquantes. Selon la taille du sous-ensemble, la valeur est soit remplacée par des calculs simples, soit par des relations dérivées de l'apprentissage automatique entre les caractéristiques. Ces relations peuvent être à peine explicables, mais les avantages explicables dans les processus de travail réels incluent :
- De meilleures performances en termes de précision et de taux de faux positifs, se transformant en processus plus fluides partout où les données sont analysées par CatBoost.
- Dans le cas de la prévention de la fraude, les valeurs nulles peuvent elles-mêmes être utiles comme indicateurs de risque potentiel.
- Facilite les modèles sur mesure pour les clients individuels, car chacun aura des processus différents et aura des données et des ratios nan différents (taux d'entrées Not a Number dans les ensembles de données).
- D'autres secteurs verticaux comme la santé, la banque, l'analyse des clients et la gestion de la chaîne d'approvisionnement font bon usage de la gestion des nan - considérez n'importe où quelqu'un sur la chaîne de saisie des données, des nouveaux clients aux agents d'exécution, pourrait être enclin à ne sauraient remplir une partie d'un formulaire. Parfois, cela pourrait être de la paresse, d'autres fois, cela pourrait indiquer tentative de fraude à la candidature.
Notamment, CatBoost ne gère que les données numériques en mode natif. Pour les données catégorielles, une catégorie individuelle du type « chaîne vide » ou « valeur manquante » doit être créée afin que ces valeurs NaN soient prises en compte dans la répartition symétrique.
Voici un exemple de la manière de gérer facilement les valeurs nan dans les données catégorielles :
for col in df.columns: if df[col].dtype.name in ("bool", "object", "category"): if (df[col].dtype.name == "category" and ("" not in df[col].cat.categories)): df[col] = df[col].cat.add_categories([""]) df[col] = df[col].fillna("")4 : Traitement parallèle (Zooms)
Comme mentionné ci-dessus, la division symétrique unique de CatBoost est très bénéfique pour la puissance de traitement et la vitesse de prédiction.
Il y a deux raisons principales pour cela. Le premier est la capacité de la structure arborescente symétrique à parvenir à une prédiction à travers multiplication vectorielle. Là où d'autres bibliothèques d'amplification de gradient effectueraient ces calculs à chaque niveau de l'arbre, CatBoost peut l'appliquer à l'ensemble de l'arbre, accélérant considérablement la génération de prédictions.
La deuxième explication de la vitesse de CatBoost est sa fonctionnalité de tri par popularité, qui prend des données dimensionnelles et les regroupe en deux branches égales, au lieu de créer une branche possible pour chaque fonctionnalité. Naturellement, une seule division prend moins d'énergie pour naviguer que 5, mais avoir ce type d'organisation se prête facilement à traitement parallèle – fractionner les données en sous-ensembles pour répartir la tâche sur plusieurs processeurs. En fonction des ressources matérielles disponibles, CatBoost peut également trouver la méthode de traitement parallèle la plus optimale.
Outre les avantages évidents d'une consommation d'énergie réduite et de processus globaux plus rapides, réfléchissez à certaines façons dont les expériences des clients et des partenaires pourraient être affectées par une gestion inefficace des données :
- Les flux de travail internes sont souvent chargés de petits temps d'attente qui peuvent gonfler en plus longs. Nous le savons tous.
- De petits temps d'attente pour l'analyse des risques, la prévention de la fraude, la vérification de l'âge et d'autres mesures de sécurité peuvent faire ou défaire une expérience en ligne. Le taux de désabonnement augmente évidemment en même temps que les temps d'attente à friction élevée.
5 : Facteur de gentillesse
CatBoost est assez attachant par rapport à des algorithmes ML similaires. Quel que soit le niveau d'apprentissage automatique ou d'expertise des données, l'API peut être apprise grâce à sa documentation claire et compréhensible. Considérez ces fonctionnalités ensemble :
- Explique les paramètres d'hyperréglage pour comprendre quel problème spécifique est résolu
- Gère automatiquement les données catégorielles, y compris le prétraitement
- A un modèle robuste qui est généralement déployable prêt à l'emploi
- Visualisations avancées
from catboost import CatBoostRegressor
from sklearn.datasets import load_boston
boston_data = load_boston()
model = CatBoostRegressor( depth=2, verbose=False, iterations=1).fit( boston_data['data'], boston_data['target'])
Le bloc de code ci-dessus montre à quel point un modèle CatBoost peut être propre et facile à former sur un jeu de données boston. Ceci est un bon exemple de la façon dont CatBoost crée un environnement plus accessible que certains, en particulier compte tenu de la communauté importante et active autour du produit.
Les avantages de cette accessibilité devraient être clairs, en particulier pour les personnes expérimentées qui s'intègrent à de nouveaux logiciels d'entreprise avancés. En général, être capable d'inclure un plus large éventail de membres de l'équipe dans processus de données sans les effrayer est précieux pour répartir les responsabilités et optimiser la répartition des ressources.
Bien qu'il ait été conçu avec rapidité et efficacité pour les données catégorielles en particulier, CatBoost gère les données numériques avec la même habileté. Cela dit, certains domaines pourraient certainement être tout aussi bien adaptés à XGBoost ou LightGBM. Ces deux algorithmes ont été conçus dans un souci de rapidité et d'évolutivité, y compris des données purement numériques hautement dimensionnelles et en constante évolution. Ainsi, les secteurs verticaux qui traitent de très grands ensembles de données intrinsèquement complets et en flux peuvent mieux fonctionner avec l'une de ces deux API, comme :
- prévisions financières
- distribution d'énergie
- gestion de la chaîne logistique
LightGBM en particulier prospère dans les endroits où la vitesse de traitement est essentielle, comme le traitement du langage naturel et la reconnaissance d'images.
Alors que les données deviennent de plus en plus omniprésentes dans les fonctions commerciales d'un espace d'entreprise de plus en plus numérisé, les solutions de données doivent être plus accessibles. Des secteurs verticaux comme la publicité, l'analyse de marché, la segmentation de la clientèle, la prévention de la fraude et le traitement médical, CatBoost est probablement un bon match. De nombreux types de financement aussi. Bien qu'il ne soit jamais aussi accessible qu'un chat domestique, dans de nombreux cas, CatBoost peut être plus convivial et certainement plus utile.
Gellért Nacsa est le responsable de la science des données chez SEON. Il a étudié les mathématiques appliquées à l'université et a travaillé comme analyste de données, concepteur d'algorithmes et scientifique de données. Il aime jouer avec les données, l'apprentissage automatique et apprendre de nouvelles choses tout le temps.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.kdnuggets.com/2023/02/top-5-advantages-catboost-ml-brings-data-make-purr.html?utm_source=rss&utm_medium=rss&utm_campaign=top-5-advantages-that-catboost-ml-brings-to-your-data-to-make-it-purr

