Image par auteur
L'utilisation des pipelines Scikit-learn peut simplifier vos étapes de prétraitement et de modélisation, réduire la complexité du code, garantir la cohérence du prétraitement des données, faciliter le réglage des hyperparamètres et rendre votre flux de travail plus organisé et plus facile à maintenir. En intégrant plusieurs transformations et le modèle final dans une seule entité, Pipelines améliore la reproductibilité et rend tout plus efficace.
Dans ce tutoriel, nous travaillerons avec le Taux de désabonnement bancaire ensemble de données de Kaggle pour former un classificateur de forêt aléatoire. Nous comparerons l'approche conventionnelle de prétraitement des données et de formation de modèles avec une méthode plus efficace utilisant les pipelines Scikit-learn et les ColumnTransformers.
Dans le pipeline de traitement des données, nous apprendrons comment transformer individuellement les colonnes catégorielles et numériques. Nous commencerons par un style de code traditionnel, puis montrerons une meilleure façon d'effectuer un traitement similaire.
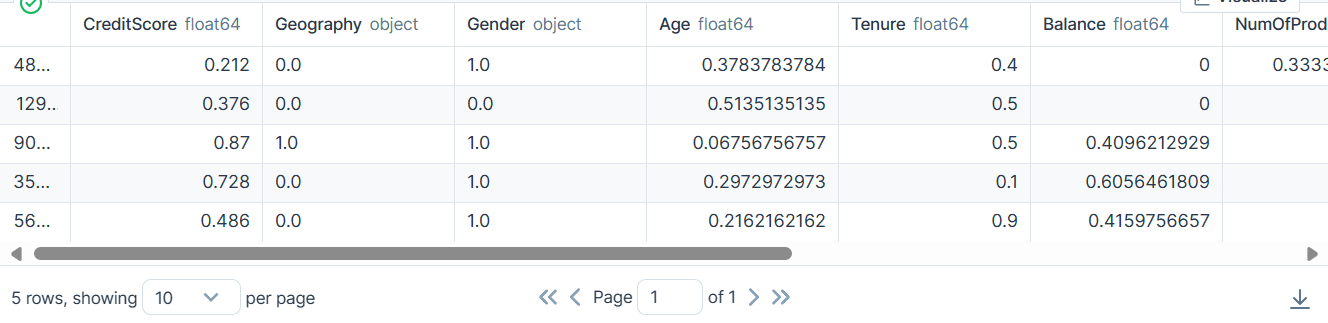
Après avoir extrait les données du fichier zip, chargez le fichier « train.csv » avec « id » comme colonne d'index. Supprimez les colonnes inutiles et mélangez l'ensemble de données.
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
bank_df.head()
Nous avons des colonnes catégorielles, entières et flottantes. L'ensemble de données semble assez propre.

Code simple d'apprentissage de Scikit
En tant que data scientist, j'ai écrit ce code plusieurs fois. Notre objectif est de combler les valeurs manquantes pour les caractéristiques catégorielles et numériques. Pour y parvenir, nous utiliserons un `SimpleImputer` avec différentes stratégies pour chaque type de fonctionnalité.
Une fois les valeurs manquantes renseignées, nous convertirons les caractéristiques catégorielles en nombres entiers et appliquerons une mise à l'échelle min-max aux caractéristiques numériques.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Filling missing categorical values
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Filling missing numerical values
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Encode categorical features as an integer array.
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Scaling numerical values.
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
bank_df.head()
En conséquence, nous avons obtenu un ensemble de données propre et transformé avec uniquement des valeurs entières ou flottantes.
Code des pipelines Scikit-learn
Convertissons le code ci-dessus en utilisant `Pipeline` et `ColumnTransformer`. Au lieu d'appliquer la technique de prétraitement, nous allons créer deux pipelines. L’un est destiné aux colonnes numériques et l’autre aux colonnes catégorielles.
- Dans le pipeline numérique, nous avons utilisé une imputation simple avec une stratégie « moyenne » et appliqué un échelonneur min-max pour la normalisation.
- Dans le pipeline catégoriel, nous avons utilisé le simple imputer avec la stratégie « most_frequent » et l'encodeur d'origine pour convertir les catégories en valeurs numériques.
Nous avons combiné les deux pipelines à l'aide de ColumnTransformer et fourni à chacun l'index des colonnes. Cela vous aidera à appliquer ces pipelines sur certaines colonnes. Par exemple, un pipeline de transformateur catégoriel sera appliqué uniquement aux colonnes 1 et 2.
Remarque: le reste = « passthrough » signifie que les colonnes qui n'ont pas été traitées seront finalement ajoutées. Dans notre cas, il s'agit de la colonne cible.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine transformers into a ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Apply the preprocessing pipeline
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df[0]
Après la transformation, le tableau résultant contient une valeur de transformation numérique au début et une valeur de transformation catégorielle à la fin, en fonction de l'ordre des pipelines dans le transformateur de colonne.
array([0.712 , 0.24324324, 0.6 , 0. , 0.33333333,
1. , 1. , 0.76443485, 2. , 0. ,
0. ])
Vous pouvez exécuter l'objet pipeline dans le notebook Jupyter pour visualiser le pipeline. Assurez-vous de disposer de la dernière version de Scikit-learn.
preproc_pipe

Pour entraîner et évaluer notre modèle, nous devons diviser notre ensemble de données en deux sous-ensembles : la formation et les tests.
Pour ce faire, nous allons d'abord créer des variables dépendantes et indépendantes et les convertir en tableaux NumPy. Ensuite, nous utiliserons la fonction `train_test_split` pour diviser l'ensemble de données en deux sous-ensembles.
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)Code simple d'apprentissage de Scikit
La manière conventionnelle d'écrire du code de formation consiste à effectuer d'abord la sélection de fonctionnalités à l'aide de « SelectKBest », puis à fournir la nouvelle fonctionnalité à notre modèle Random Forest Classifier.
Nous allons d’abord entraîner le modèle à l’aide de l’ensemble d’entraînement et évaluer les résultats à l’aide de l’ensemble de données de test.
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)
Nous avons obtenu un score de précision raisonnablement bon.
0.8613035487063481Code des pipelines Scikit-learn
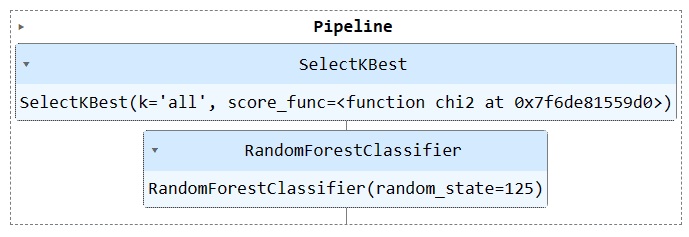
Utilisons la fonction « Pipeline » pour combiner les deux étapes de formation dans un pipeline. Nous pouvons ensuite ajuster le modèle sur l'ensemble d'entraînement et l'évaluer sur l'ensemble de test.
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)
Nous avons obtenu des résultats similaires, mais le code semble plus efficace et plus simple. Il est assez simple d'ajouter ou de supprimer de nouvelles étapes du pipeline de formation.
0.8613035487063481
Exécutez l'objet pipeline pour visualiser le pipeline.
train_pipe
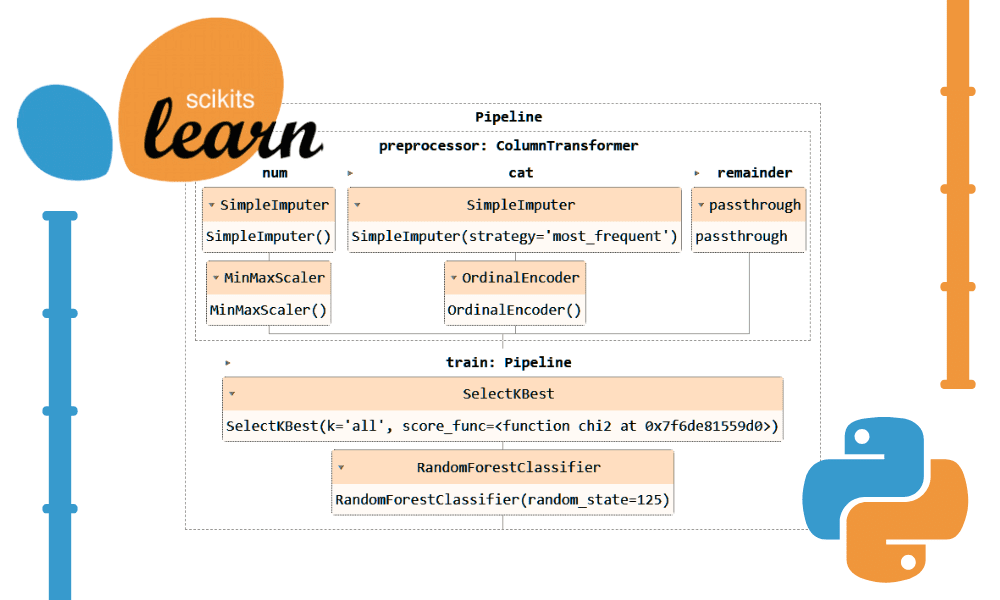
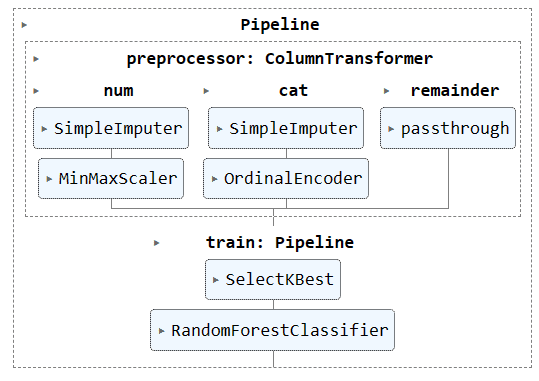
Nous allons maintenant combiner le pipeline de prétraitement et de formation en créant un autre pipeline et en ajoutant les deux pipelines.
Voici le code complet:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"],axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)
Sortie :
0.8592837955201874
Visualisation du pipeline complet.
complete_pipe

L'un des principaux avantages de l'utilisation de pipelines est que vous pouvez enregistrer le pipeline avec le modèle. Lors de l'inférence, il vous suffit de charger l'objet pipeline, qui sera prêt à traiter les données brutes et à vous fournir des prédictions précises. Vous n'avez pas besoin de réécrire les fonctions de traitement et de transformation dans le fichier d'application, car cela fonctionnera immédiatement. Cela rend le flux de travail d’apprentissage automatique plus efficace et permet de gagner du temps.
Sauvons d'abord le pipeline en utilisant le skops-dev/skops bibliothèque.
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")
Ensuite, chargez le pipeline enregistré et affichez-le.
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipe
Comme nous pouvons le voir, nous avons chargé le pipeline avec succès.
Pour évaluer notre pipeline chargé, nous ferons des prédictions sur l'ensemble de tests, puis calculerons la précision et les scores F1.
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
Il s’avère que nous devons nous concentrer sur les classes minoritaires pour améliorer notre score en F1.
Accuracy: 86.0% F1: 0.76
Les fichiers et le code du projet sont disponibles sur Espace de travail Deepnote. L'espace de travail comporte deux blocs-notes : un avec le pipeline Scikit-learn et un sans celui-ci.
Dans ce didacticiel, nous avons appris comment les pipelines Scikit-learn peuvent aider à rationaliser les flux de travail d'apprentissage automatique en enchaînant des séquences de transformations et de modèles de données. En combinant le prétraitement et la formation du modèle dans un seul objet Pipeline, nous pouvons simplifier le code, garantir des transformations de données cohérentes et rendre nos flux de travail plus organisés et reproductibles.
Abid Ali Awan (@1abidaliawan) est un spécialiste des données certifié qui aime créer des modèles d'apprentissage automatique. Actuellement, il se concentre sur la création de contenu et la rédaction de blogs techniques sur les technologies d'apprentissage automatique et de science des données. Abid est titulaire d'une maîtrise en gestion de la technologie et d'un baccalauréat en génie des télécommunications. Sa vision est de créer un produit d'IA utilisant un réseau de neurones graphiques pour les étudiants aux prises avec une maladie mentale.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/streamline-your-machine-learning-workflow-with-scikit-learn-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=streamline-your-machine-learning-workflow-with-scikit-learn-pipelines

