Aujourd'hui, les clients de tous les secteurs, qu'il s'agisse des services financiers, de la santé et des sciences de la vie, des voyages et de l'hôtellerie, des médias et du divertissement, des télécommunications, des logiciels en tant que service (SaaS) et même des fournisseurs de modèles propriétaires, utilisent des modèles de langage étendus (LLM) pour créez des applications telles que des chatbots de questions et réponses (QnA), des moteurs de recherche et des bases de connaissances. Ces IA générative les applications ne sont pas seulement utilisées pour automatiser les processus métier existants, mais ont également la capacité de transformer l'expérience des clients utilisant ces applications. Avec les progrès réalisés avec les LLM comme le Instruction Mixtral-8x7B, dérivé d'architectures telles que la mélange d'experts (MoE), les clients recherchent continuellement des moyens d'améliorer les performances et la précision des applications d'IA générative tout en leur permettant d'utiliser efficacement une gamme plus large de modèles fermés et open source.
Un certain nombre de techniques sont généralement utilisées pour améliorer la précision et les performances des résultats d'un LLM, telles que l'ajustement avec réglage fin efficace des paramètres (PEFT), apprentissage par renforcement à partir de la rétroaction humaine (RLHF), et effectuer distillation des connaissances. Cependant, lors de la création d'applications d'IA générative, vous pouvez utiliser une solution alternative qui permet l'incorporation dynamique de connaissances externes et vous permet de contrôler les informations utilisées pour la génération sans avoir besoin d'affiner votre modèle de base existant. C'est là qu'intervient la génération augmentée de récupération (RAG), en particulier pour les applications d'IA générative, par opposition aux alternatives de réglage fin plus coûteuses et plus robustes dont nous avons discuté. Si vous implémentez des applications RAG complexes dans vos tâches quotidiennes, vous pouvez rencontrer des problèmes courants avec vos systèmes RAG, tels qu'une récupération inexacte, une taille et une complexité croissantes des documents et un débordement de contexte, ce qui peut avoir un impact significatif sur la qualité et la fiabilité des réponses générées. .
Cet article traite des modèles RAG pour améliorer la précision des réponses à l'aide de LangChain et d'outils tels que le récupérateur de documents parent, en plus de techniques telles que la compression contextuelle afin de permettre aux développeurs d'améliorer les applications d'IA générative existantes.
Vue d'ensemble de la solution
Dans cet article, nous démontrons l'utilisation de la génération de texte Mixtral-8x7B Instruct combinée au modèle d'intégration BGE Large En pour construire efficacement un système RAG QnA sur un bloc-notes Amazon SageMaker à l'aide de l'outil de récupération de documents parent et de la technique de compression contextuelle. Le schéma suivant illustre l'architecture de cette solution.
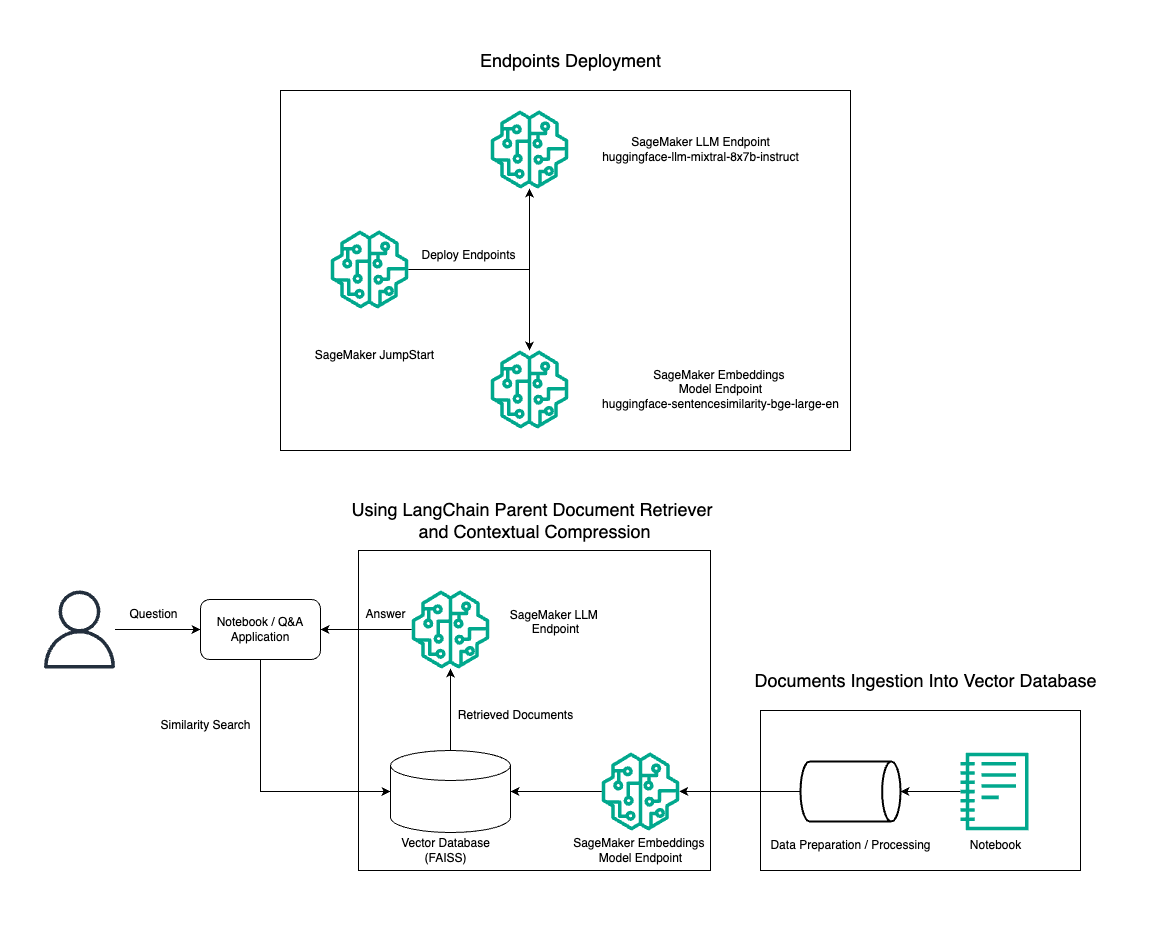
Vous pouvez déployer cette solution en quelques clics en utilisant Amazon SageMaker JumpStart, une plateforme entièrement gérée qui propose des modèles de base de pointe pour divers cas d'utilisation tels que la rédaction de contenu, la génération de code, la réponse aux questions, la rédaction, le résumé, la classification et la récupération d'informations. Il fournit une collection de modèles pré-entraînés que vous pouvez déployer rapidement et facilement, accélérant ainsi le développement et le déploiement d'applications d'apprentissage automatique (ML). L'un des composants clés de SageMaker JumpStart est le Model Hub, qui propose un vaste catalogue de modèles pré-entraînés, tels que le Mixtral-8x7B, pour une variété de tâches.
Mixtral-8x7B utilise une architecture MoE. Cette architecture permet à différentes parties d'un réseau neuronal de se spécialiser dans différentes tâches, répartissant ainsi efficacement la charge de travail entre plusieurs experts. Cette approche permet la formation et le déploiement efficaces de modèles plus grands par rapport aux architectures traditionnelles.
L’un des principaux avantages de l’architecture MoE est son évolutivité. En répartissant la charge de travail entre plusieurs experts, les modèles MoE peuvent être formés sur des ensembles de données plus volumineux et atteindre de meilleures performances que les modèles traditionnels de même taille. De plus, les modèles MoE peuvent être plus efficaces lors de l'inférence car seul un sous-ensemble d'experts doit être activé pour une entrée donnée.
Pour plus d'informations sur Mixtral-8x7B Instruct sur AWS, reportez-vous à Mixtral-8x7B est désormais disponible dans Amazon SageMaker JumpStart. Le modèle Mixtral-8x7B est mis à disposition sous la licence permissive Apache 2.0, pour une utilisation sans restrictions.
Dans cet article, nous expliquons comment vous pouvez utiliser LangChaîne pour créer des applications RAG efficaces et plus efficientes. LangChain est une bibliothèque Python open source conçue pour créer des applications avec des LLM. Il fournit un cadre modulaire et flexible permettant de combiner les LLM avec d'autres composants, tels que des bases de connaissances, des systèmes de récupération et d'autres outils d'IA, afin de créer des applications puissantes et personnalisables.
Nous passons en revue la construction d'un pipeline RAG sur SageMaker avec Mixtral-8x7B. Nous utilisons le modèle de génération de texte Mixtral-8x7B Instruct avec le modèle d'intégration BGE Large En pour créer un système QnA efficace à l'aide de RAG sur un notebook SageMaker. Nous utilisons une instance ml.t3.medium pour démontrer le déploiement de LLM via SageMaker JumpStart, accessible via un point de terminaison d'API généré par SageMaker. Cette configuration permet l'exploration, l'expérimentation et l'optimisation de techniques RAG avancées avec LangChain. Nous illustrons également l'intégration du magasin FAISS Embedding dans le flux de travail RAG, en soulignant son rôle dans le stockage et la récupération des intégrations pour améliorer les performances du système.
Nous effectuons une brève présentation du notebook SageMaker. Pour des instructions plus détaillées et étape par étape, reportez-vous au Modèles RAG avancés avec Mixtral sur le dépôt GitHub SageMaker Jumpstart.
Le besoin de modèles RAG avancés
Les modèles RAG avancés sont essentiels pour améliorer les capacités actuelles des LLM en matière de traitement, de compréhension et de génération de texte de type humain. À mesure que la taille et la complexité des documents augmentent, la représentation de plusieurs facettes du document dans une seule intégration peut entraîner une perte de spécificité. Bien qu'il soit essentiel de capturer l'essence générale d'un document, il est tout aussi crucial de reconnaître et de représenter les divers sous-contextes qu'il contient. C'est un défi auquel vous êtes souvent confronté lorsque vous travaillez avec des documents plus volumineux. Un autre défi avec RAG est qu'avec la récupération, vous n'êtes pas au courant des requêtes spécifiques que votre système de stockage de documents traitera lors de l'ingestion. Cela pourrait conduire à ce que les informations les plus pertinentes pour une requête soient enfouies sous le texte (débordement de contexte). Pour atténuer les échecs et améliorer l'architecture RAG existante, vous pouvez utiliser des modèles RAG avancés (récupérateur de documents parents et compression contextuelle) pour réduire les erreurs de récupération, améliorer la qualité des réponses et permettre la gestion de questions complexes.
Grâce aux techniques abordées dans cet article, vous pouvez relever les principaux défis associés à la récupération et à l'intégration de connaissances externes, permettant ainsi à votre application de fournir des réponses plus précises et contextuelles.
Dans les sections suivantes, nous explorons comment récupérateurs de documents parents ainsi que compression contextuelle peut vous aider à résoudre certains des problèmes dont nous avons discuté.
Récupérateur de documents parents
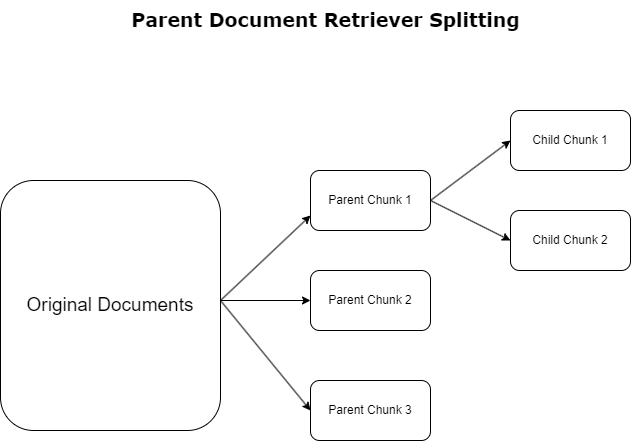
Dans la section précédente, nous avons mis en évidence les défis auxquels les applications RAG sont confrontées lorsqu'elles traitent des documents volumineux. Pour relever ces défis, récupérateurs de documents parents catégoriser et désigner les documents entrants comme documents parents. Ces documents sont reconnus pour leur caractère exhaustif mais ne sont pas directement utilisés sous leur forme originale pour des intégrations. Plutôt que de compresser un document entier en une seule intégration, les récupérateurs de documents parents disséquent ces documents parents en documents pour enfants. Chaque document enfant capture des aspects ou des sujets distincts du document parent plus large. Suite à l'identification de ces segments enfants, des intégrations individuelles sont attribuées à chacun, capturant leur essence thématique spécifique (voir le diagramme suivant). Lors de la récupération, le document parent est invoqué. Cette technique offre des capacités de recherche ciblées mais étendues, offrant au LLM une perspective plus large. Les récupérateurs de documents parents offrent aux LLM un double avantage : la spécificité des intégrations de documents enfants pour une récupération d'informations précises et pertinentes, couplée à l'invocation de documents parents pour la génération de réponses, qui enrichit les sorties du LLM avec un contexte en couches et approfondi.
Compression contextuelle
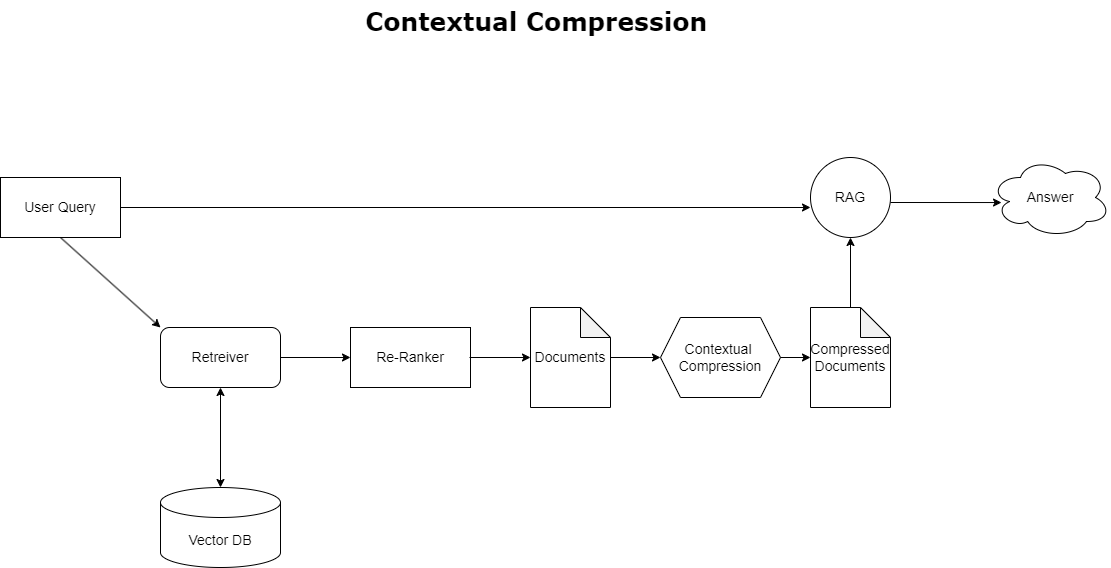
Pour résoudre le problème de débordement de contexte évoqué précédemment, vous pouvez utiliser compression contextuelle pour compresser et filtrer les documents récupérés en fonction du contexte de la requête, afin que seules les informations pertinentes soient conservées et traitées. Ceci est réalisé grâce à la combinaison d'un outil de récupération de base pour la récupération initiale des documents et d'un compresseur de documents pour affiner ces documents en réduisant leur contenu ou en les excluant entièrement en fonction de leur pertinence, comme illustré dans le diagramme suivant. Cette approche rationalisée, facilitée par le récupérateur de compression contextuelle, améliore considérablement l'efficacité des applications RAG en fournissant une méthode permettant d'extraire et d'utiliser uniquement l'essentiel d'une masse d'informations. Il s'attaque de front au problème de la surcharge d'informations et du traitement des données non pertinentes, conduisant à une qualité de réponse améliorée, à des opérations LLM plus rentables et à un processus de récupération global plus fluide. Il s'agit essentiellement d'un filtre qui adapte les informations à la requête en question, ce qui en fait un outil indispensable pour les développeurs souhaitant optimiser leurs applications RAG pour de meilleures performances et la satisfaction des utilisateurs.
Pré-requis
Si vous êtes nouveau sur SageMaker, reportez-vous au Guide de développement Amazon SageMaker.
Avant de commencer avec la solution, créer un compte AWS. Lorsque vous créez un compte AWS, vous obtenez une identité d'authentification unique (SSO) qui dispose d'un accès complet à tous les services et ressources AWS du compte. Cette identité est appelée le compte AWS utilisateur root.
Se connecter au Console de gestion AWS l'utilisation de l'adresse e-mail et du mot de passe que vous avez utilisés pour créer le compte vous donne un accès complet à toutes les ressources AWS de votre compte. Nous vous déconseillons fortement d'utiliser l'utilisateur root pour les tâches quotidiennes, même administratives.
Respectez plutôt les bonnes pratiques de sécurité in Gestion des identités et des accès AWS (Je suis et créer un utilisateur et un groupe administratif. Verrouillez ensuite en toute sécurité les informations d'identification de l'utilisateur root et utilisez-les pour effectuer uniquement quelques tâches de gestion de comptes et de services.
Le modèle Mixtral-8x7b nécessite une instance ml.g5.48xlarge. SageMaker JumpStart offre un moyen simplifié d'accéder et de déployer plus de 100 modèles de fondations open source et tiers différents. Pour lancer un point de terminaison pour héberger Mixtral-8x7B à partir de SageMaker JumpStart, vous devrez peut-être demander une augmentation du quota de service pour accéder à une instance ml.g5.48xlarge pour l'utilisation du point de terminaison. Tu peux demander une augmentation du quota de service via la console, Interface de ligne de commande AWS (AWS CLI) ou API pour autoriser l'accès à ces ressources supplémentaires.
Configurer une instance de notebook SageMaker et installer les dépendances
Pour commencer, créez une instance de notebook SageMaker et installez les dépendances requises. Se référer au GitHub repo pour garantir une installation réussie. Après avoir configuré l'instance de notebook, vous pouvez déployer le modèle.
Vous pouvez également exécuter le bloc-notes localement sur votre environnement de développement intégré (IDE) préféré. Assurez-vous que le laboratoire de notebook Jupyter est installé.
Déployer le modèle
Déployez le modèle Mixtral-8X7B Instruct LLM sur SageMaker JumpStart :
Déployez le modèle d'intégration BGE Large En sur SageMaker JumpStart :
Configurer LangChain
Après avoir importé toutes les bibliothèques nécessaires et déployé le modèle Mixtral-8x7B et le modèle d'intégration BGE Large En, vous pouvez maintenant configurer LangChain. Pour obtenir des instructions étape par étape, reportez-vous au GitHub repo.
Préparation des données
Dans cet article, nous utilisons plusieurs années de lettres aux actionnaires d'Amazon comme corpus de textes sur lequel effectuer des QnA. Pour des étapes plus détaillées de préparation des données, reportez-vous au GitHub repo.
Question répondant
Une fois les données préparées, vous pouvez utiliser le wrapper fourni par LangChain, qui entoure le magasin de vecteurs et prend les entrées pour le LLM. Ce wrapper effectue les étapes suivantes :
- Prenez la question d'entrée.
- Créez une intégration de questions.
- Récupérez les documents pertinents.
- Incorporez les documents et la question dans une invite.
- Invoquez le modèle avec l'invite et générez la réponse de manière lisible.
Maintenant que le magasin de vecteurs est en place, vous pouvez commencer à poser des questions :
Chaîne de récupération régulière
Dans le scénario précédent, nous avons exploré le moyen simple et rapide d'obtenir une réponse contextuelle à votre question. Examinons maintenant une option plus personnalisable avec l'aide de RetrievalQA, où vous pouvez personnaliser la façon dont les documents récupérés doivent être ajoutés à l'invite à l'aide du paramètre chain_type. De plus, afin de contrôler le nombre de documents pertinents à récupérer, vous pouvez modifier le paramètre k dans le code suivant pour voir différentes sorties. Dans de nombreux scénarios, vous souhaiterez peut-être savoir quels documents sources le LLM a utilisés pour générer la réponse. Vous pouvez obtenir ces documents dans la sortie en utilisant return_source_documents, qui renvoie les documents ajoutés au contexte de l'invite LLM. RetrievalQA vous permet également de fournir un modèle d'invite personnalisé qui peut être spécifique au modèle.
Posons une question :
Chaîne de récupération de documents parent
Examinons une option RAG plus avancée à l'aide de ParentDocumentRetriever. Lorsque vous travaillez avec la récupération de documents, vous pouvez être confronté à un compromis entre le stockage de petits morceaux d'un document pour des intégrations précises et des documents plus volumineux pour préserver davantage de contexte. Le récupérateur de documents parent atteint cet équilibre en divisant et en stockant de petits morceaux de données.
Nous faisons appel à une parent_splitter pour diviser les documents originaux en morceaux plus grands appelés documents parents et un child_splitter pour créer des documents enfants plus petits à partir des documents originaux :
Les documents enfants sont ensuite indexés dans un magasin vectoriel à l'aide d'intégrations. Cela permet une récupération efficace des documents enfants pertinents sur la base de la similarité. Pour récupérer les informations pertinentes, le récupérateur de documents parent récupère d'abord les documents enfants du magasin vectoriel. Il recherche ensuite les ID parent de ces documents enfants et renvoie les documents parents plus volumineux correspondants.
Posons une question :
Chaîne de compression contextuelle
Examinons une autre option RAG avancée appelée compression contextuelle. L'un des défis liés à la récupération est que nous ne connaissons généralement pas les requêtes spécifiques auxquelles votre système de stockage de documents sera confronté lorsque vous ingérez des données dans le système. Cela signifie que les informations les plus pertinentes pour une requête peuvent être enfouies dans un document contenant beaucoup de texte non pertinent. La transmission de ce document complet via votre candidature peut entraîner des appels LLM plus coûteux et de moins bonnes réponses.
Le récupérateur de compression contextuelle relève le défi de la récupération d'informations pertinentes à partir d'un système de stockage de documents, où les données pertinentes peuvent être enfouies dans des documents contenant beaucoup de texte. En compressant et en filtrant les documents récupérés en fonction du contexte de requête donné, seules les informations les plus pertinentes sont renvoyées.
Pour utiliser le récupérateur de compression contextuelle, vous aurez besoin de :
- Un récupérateur de base – Il s’agit du récupérateur initial qui récupère les documents du système de stockage en fonction de la requête
- Un compresseur de documents – Ce composant prend les documents initialement récupérés et les raccourcit en réduisant le contenu de documents individuels ou en supprimant complètement les documents non pertinents, en utilisant le contexte de requête pour déterminer la pertinence.
Ajout d'une compression contextuelle avec un extracteur de chaîne LLM
Tout d'abord, enveloppez votre base retriever avec un ContextualCompressionRetriever. Vous ajouterez un LLMChainExtracteur, qui parcourra les documents initialement renvoyés et extraira de chacun uniquement le contenu pertinent pour la requête.
Initialisez la chaîne à l'aide du ContextualCompressionRetriever peut comprendre un atténuateur. LLMChainExtractor et transmettez l'invite via le chain_type_kwargs argument.
Posons une question :
Filtrer les documents avec un filtre de chaîne LLM
La LLMChainFilter est un compresseur légèrement plus simple mais plus robuste qui utilise une chaîne LLM pour décider lesquels des documents initialement récupérés filtrer et lesquels renvoyer, sans manipuler le contenu du document :
Initialisez la chaîne à l'aide du ContextualCompressionRetriever peut comprendre un atténuateur. LLMChainFilter et transmettez l'invite via le chain_type_kwargs argument.
Posons une question :
Comparer les résultats
Le tableau suivant compare les résultats de différentes requêtes basées sur la technique.
| Technique | Requête 1 | Requête 2 | Comparaison |
| Comment AWS a-t-il évolué ? | Pourquoi Amazon a-t-il du succès ? | ||
| Sortie de chaîne de récupération régulière | AWS (Amazon Web Services) est passé d'un investissement initialement non rentable à une activité au chiffre d'affaires annuel de 85 milliards de dollars avec une forte rentabilité, offrant une large gamme de services et de fonctionnalités et devenant une partie importante du portefeuille d'Amazon. Malgré le scepticisme et les vents contraires à court terme, AWS a continué à innover, à attirer de nouveaux clients et à migrer les clients actifs, offrant des avantages tels que l'agilité, l'innovation, la rentabilité et la sécurité. AWS a également étendu ses investissements à long terme, notamment le développement de puces, pour offrir de nouvelles fonctionnalités et changer ce qui est possible pour ses clients. | Amazon réussit grâce à son innovation continue et à son expansion dans de nouveaux domaines tels que les services d'infrastructure technologique, les appareils de lecture numérique, les assistants personnels à commande vocale et de nouveaux modèles commerciaux comme le marché tiers. Sa capacité à faire évoluer rapidement ses opérations, comme en témoigne l'expansion rapide de ses réseaux de distribution et de transport, contribue également à son succès. De plus, l'accent mis par Amazon sur l'optimisation et les gains d'efficacité de ses processus a abouti à des améliorations de productivité et à des réductions de coûts. L'exemple d'Amazon Business met en évidence la capacité de l'entreprise à tirer parti de ses atouts en matière de commerce électronique et de logistique dans différents secteurs. | Sur la base des réponses de la chaîne de récupération régulière, nous remarquons que bien qu'elle fournisse de longues réponses, elle souffre d'un débordement de contexte et ne mentionne aucun détail significatif du corpus concernant la réponse à la requête fournie. La chaîne de récupération habituelle n'est pas en mesure de capturer les nuances avec une profondeur ou une vision contextuelle, ce qui risque de manquer des aspects critiques du document. |
| Sortie de l'outil de récupération de documents parents | AWS (Amazon Web Services) a démarré avec un lancement initial pauvre en fonctionnalités du service Elastic Compute Cloud (EC2) en 2006, fournissant une seule taille d'instance, dans un centre de données, dans une région du monde, avec des instances de système d'exploitation Linux uniquement. , et sans de nombreuses fonctionnalités clés telles que la surveillance, l'équilibrage de charge, la mise à l'échelle automatique ou le stockage persistant. Cependant, le succès d'AWS leur a permis d'itérer et d'ajouter rapidement les fonctionnalités manquantes, pour finalement s'étendre pour offrir différentes versions, tailles et optimisations de calcul, de stockage et de mise en réseau, ainsi que de développer leurs propres puces (Graviton) pour pousser encore plus loin les prix et les performances. . Le processus d'innovation itératif d'AWS a nécessité d'importants investissements en ressources financières et humaines sur 20 ans, souvent bien avant la date de paiement, pour répondre aux besoins des clients et améliorer l'expérience client à long terme, la fidélité et les rendements pour les actionnaires. | Amazon réussit grâce à sa capacité à innover constamment, à s'adapter aux conditions changeantes du marché et à répondre aux besoins des clients dans divers segments de marché. Cela est évident dans le succès d'Amazon Business, qui s'est développé pour générer environ 35 milliards de dollars de ventes brutes annualisées en offrant sélection, valeur et commodité aux clients professionnels. Les investissements d'Amazon dans les capacités de commerce électronique et de logistique ont également permis la création de services tels que Buy with Prime, qui aide les commerçants disposant de sites Web de vente directe aux consommateurs à générer des conversions de vues en achats. | L'outil de récupération de documents parent approfondit les spécificités de la stratégie de croissance d'AWS, y compris le processus itératif d'ajout de nouvelles fonctionnalités basé sur les commentaires des clients et le parcours détaillé depuis un lancement initial pauvre en fonctionnalités jusqu'à une position dominante sur le marché, tout en fournissant une réponse riche en contexte. . Les réponses couvrent un large éventail d'aspects, depuis les innovations techniques et la stratégie de marché jusqu'à l'efficacité organisationnelle et l'orientation client, offrant une vision globale des facteurs contribuant au succès ainsi que des exemples. Cela peut être attribué aux capacités de recherche ciblées mais étendues du récupérateur de documents parent. |
| Extracteur de chaîne LLM : sortie de compression contextuelle | AWS a évolué en commençant comme un petit projet au sein d'Amazon, nécessitant un investissement en capital important et confronté au scepticisme de l'intérieur et de l'extérieur de l'entreprise. Cependant, AWS avait une longueur d'avance sur ses concurrents potentiels et croyait en la valeur qu'elle pouvait apporter aux clients et à Amazon. AWS s'est engagé à long terme à poursuivre ses investissements, ce qui a abouti au lancement de plus de 3,300 2022 nouvelles fonctionnalités et services en 85. AWS a transformé la façon dont les clients gèrent leur infrastructure technologique et est devenue une entreprise au chiffre d'affaires annuel de 2 milliards de dollars avec une forte rentabilité. AWS a également continuellement amélioré ses offres, notamment en améliorant ECXNUMX avec des fonctionnalités et des services supplémentaires après son lancement initial. | Sur la base du contexte fourni, le succès d'Amazon peut être attribué à son expansion stratégique d'une plate-forme de vente de livres à un marché mondial doté d'un écosystème de vendeurs tiers dynamique, à un investissement précoce dans AWS, à l'innovation dans l'introduction du Kindle et d'Alexa et à une croissance substantielle. de chiffre d'affaires annuel de 2019 à 2022. Cette croissance a conduit à l'expansion de l'empreinte du centre de distribution, à la création d'un réseau de transport du dernier kilomètre et à la construction d'un nouveau réseau de centres de tri, optimisés pour la productivité et la réduction des coûts. | L'extracteur de chaîne LLM maintient un équilibre entre couvrir les points clés de manière exhaustive et éviter une profondeur inutile. Il s'adapte dynamiquement au contexte de la requête, de sorte que le résultat est directement pertinent et complet. |
| Filtre de chaîne LLM : sortie de compression contextuelle | AWS (Amazon Web Services) a évolué en lançant initialement peu de fonctionnalités, mais en itérant rapidement en fonction des commentaires des clients pour ajouter les fonctionnalités nécessaires. Cette approche a permis à AWS de lancer EC2 en 2006 avec des fonctionnalités limitées, puis d'ajouter continuellement de nouvelles fonctionnalités, telles que des tailles d'instance supplémentaires, des centres de données, des régions, des options de système d'exploitation, des outils de surveillance, l'équilibrage de charge, la mise à l'échelle automatique et le stockage persistant. Au fil du temps, AWS est passé d'un service pauvre en fonctionnalités à une entreprise multimilliardaire en se concentrant sur les besoins des clients, l'agilité, l'innovation, la rentabilité et la sécurité. AWS affiche désormais un chiffre d'affaires annuel de 85 milliards de dollars et propose plus de 3,300 XNUMX nouvelles fonctionnalités et services chaque année, s'adressant à un large éventail de clients, des start-ups aux entreprises multinationales et aux organisations du secteur public. | Amazon réussit grâce à ses modèles commerciaux innovants, ses progrès technologiques continus et ses changements organisationnels stratégiques. L'entreprise a constamment bouleversé les secteurs traditionnels en introduisant de nouvelles idées, telles qu'une plate-forme de commerce électronique pour divers produits et services, un marché tiers, des services d'infrastructure cloud (AWS), la liseuse Kindle et l'assistant personnel vocal Alexa. . De plus, Amazon a apporté des changements structurels pour améliorer son efficacité, comme la réorganisation de son réseau de distribution aux États-Unis afin de réduire les coûts et les délais de livraison, contribuant ainsi davantage à son succès. | Semblable à l'extracteur de chaîne LLM, le filtre de chaîne LLM garantit que même si les points clés sont couverts, le résultat est efficace pour les clients à la recherche de réponses concises et contextuelles. |
En comparant ces différentes techniques, nous pouvons voir que dans des contextes tels que détailler la transition d'AWS d'un simple service à une entité complexe valant plusieurs milliards de dollars, ou expliquer les succès stratégiques d'Amazon, la chaîne de récupération habituelle n'a pas la précision qu'offrent les techniques plus sophistiquées. conduisant à des informations moins ciblées. Bien que très peu de différences soient visibles entre les techniques avancées évoquées, elles sont de loin plus informatives que les chaînes de récupération classiques.
Pour les clients de secteurs tels que la santé, les télécommunications et les services financiers qui cherchent à implémenter RAG dans leurs applications, les limites de la chaîne de récupération standard pour fournir une précision, éviter la redondance et compresser efficacement les informations la rendent moins adaptée à la satisfaction de ces besoins. aux techniques de récupération de documents parents et de compression contextuelle plus avancées. Ces techniques sont capables de distiller de grandes quantités d’informations en informations concentrées et percutantes dont vous avez besoin, tout en contribuant à améliorer le rapport prix-performance.
Nettoyer
Lorsque vous avez terminé d'exécuter le notebook, supprimez les ressources que vous avez créées afin d'éviter l'accumulation de frais pour les ressources utilisées :
Conclusion
Dans cet article, nous avons présenté une solution qui vous permet d'implémenter des techniques de récupération de documents parents et de chaîne de compression contextuelle pour améliorer la capacité des LLM à traiter et générer des informations. Nous avons testé ces techniques RAG avancées avec les modèles Mixtral-8x7B Instruct et BGE Large En disponibles avec SageMaker JumpStart. Nous avons également exploré l'utilisation du stockage persistant pour les intégrations et les morceaux de documents ainsi que l'intégration avec les magasins de données d'entreprise.
Les techniques que nous avons appliquées affinent non seulement la manière dont les modèles LLM accèdent et intègrent des connaissances externes, mais améliorent également considérablement la qualité, la pertinence et l'efficacité de leurs résultats. En combinant la récupération de grands corpus de textes avec des capacités de génération de langage, ces techniques RAG avancées permettent aux LLM de produire des réponses plus factuelles, cohérentes et adaptées au contexte, améliorant ainsi leurs performances dans diverses tâches de traitement du langage naturel.
SageMaker JumpStart est au centre de cette solution. Avec SageMaker JumpStart, vous avez accès à un vaste assortiment de modèles open source et fermés, rationalisant le processus de démarrage avec le ML et permettant une expérimentation et un déploiement rapides. Pour commencer à déployer cette solution, accédez au bloc-notes dans le GitHub repo.
À propos des auteurs
 Niithiyn Vijeaswaran est architecte de solutions chez AWS. Son domaine d'intervention est l'IA générative et les accélérateurs AWS AI. Il est titulaire d'un baccalauréat en informatique et bioinformatique. Niithiyn travaille en étroite collaboration avec l'équipe Generative AI GTM pour aider les clients AWS sur plusieurs fronts et accélérer leur adoption de l'IA générative. Il est un grand fan des Dallas Mavericks et aime collectionner des baskets.
Niithiyn Vijeaswaran est architecte de solutions chez AWS. Son domaine d'intervention est l'IA générative et les accélérateurs AWS AI. Il est titulaire d'un baccalauréat en informatique et bioinformatique. Niithiyn travaille en étroite collaboration avec l'équipe Generative AI GTM pour aider les clients AWS sur plusieurs fronts et accélérer leur adoption de l'IA générative. Il est un grand fan des Dallas Mavericks et aime collectionner des baskets.
 Sébastien Bustillo est architecte de solutions chez AWS. Il se concentre sur les technologies IA/ML avec une profonde passion pour l’IA générative et les accélérateurs de calcul. Chez AWS, il aide les clients à libérer de la valeur commerciale grâce à l'IA générative. Lorsqu'il n'est pas au travail, il aime préparer une parfaite tasse de café de spécialité et explorer le monde avec sa femme.
Sébastien Bustillo est architecte de solutions chez AWS. Il se concentre sur les technologies IA/ML avec une profonde passion pour l’IA générative et les accélérateurs de calcul. Chez AWS, il aide les clients à libérer de la valeur commerciale grâce à l'IA générative. Lorsqu'il n'est pas au travail, il aime préparer une parfaite tasse de café de spécialité et explorer le monde avec sa femme.
 Armando Diaz est architecte de solutions chez AWS. Il se concentre sur l'IA générative, l'IA/ML et l'analyse de données. Chez AWS, Armando aide les clients à intégrer des capacités d'IA générative de pointe dans leurs systèmes, favorisant ainsi l'innovation et l'avantage concurrentiel. Lorsqu'il n'est pas au travail, il aime passer du temps avec sa femme et sa famille, faire de la randonnée et parcourir le monde.
Armando Diaz est architecte de solutions chez AWS. Il se concentre sur l'IA générative, l'IA/ML et l'analyse de données. Chez AWS, Armando aide les clients à intégrer des capacités d'IA générative de pointe dans leurs systèmes, favorisant ainsi l'innovation et l'avantage concurrentiel. Lorsqu'il n'est pas au travail, il aime passer du temps avec sa femme et sa famille, faire de la randonnée et parcourir le monde.
 Dr Farooq Sabir est architecte principal de solutions spécialisées en intelligence artificielle et en apprentissage automatique chez AWS. Il est titulaire d'un doctorat et d'une maîtrise en génie électrique de l'Université du Texas à Austin et d'une maîtrise en informatique du Georgia Institute of Technology. Il a plus de 15 ans d'expérience de travail et aime aussi enseigner et encadrer des étudiants. Chez AWS, il aide les clients à formuler et à résoudre leurs problèmes commerciaux dans les domaines de la science des données, de l'apprentissage automatique, de la vision par ordinateur, de l'intelligence artificielle, de l'optimisation numérique et des domaines connexes. Basé à Dallas, au Texas, lui et sa famille adorent voyager et faire de longs trajets en voiture.
Dr Farooq Sabir est architecte principal de solutions spécialisées en intelligence artificielle et en apprentissage automatique chez AWS. Il est titulaire d'un doctorat et d'une maîtrise en génie électrique de l'Université du Texas à Austin et d'une maîtrise en informatique du Georgia Institute of Technology. Il a plus de 15 ans d'expérience de travail et aime aussi enseigner et encadrer des étudiants. Chez AWS, il aide les clients à formuler et à résoudre leurs problèmes commerciaux dans les domaines de la science des données, de l'apprentissage automatique, de la vision par ordinateur, de l'intelligence artificielle, de l'optimisation numérique et des domaines connexes. Basé à Dallas, au Texas, lui et sa famille adorent voyager et faire de longs trajets en voiture.
 Marco Punio est un architecte de solutions axé sur la stratégie d'IA générative, les solutions d'IA appliquées et la conduite de recherches pour aider les clients à évoluer à grande échelle sur AWS. Marco est un conseiller cloud natif numérique avec une expérience dans les secteurs de la FinTech, de la santé et des sciences de la vie, du logiciel en tant que service et, plus récemment, dans les secteurs des télécommunications. C'est un technologue qualifié passionné par l'apprentissage automatique, l'intelligence artificielle et les fusions et acquisitions. Marco est basé à Seattle, Washington et aime écrire, lire, faire de l'exercice et créer des applications pendant son temps libre.
Marco Punio est un architecte de solutions axé sur la stratégie d'IA générative, les solutions d'IA appliquées et la conduite de recherches pour aider les clients à évoluer à grande échelle sur AWS. Marco est un conseiller cloud natif numérique avec une expérience dans les secteurs de la FinTech, de la santé et des sciences de la vie, du logiciel en tant que service et, plus récemment, dans les secteurs des télécommunications. C'est un technologue qualifié passionné par l'apprentissage automatique, l'intelligence artificielle et les fusions et acquisitions. Marco est basé à Seattle, Washington et aime écrire, lire, faire de l'exercice et créer des applications pendant son temps libre.
 AJ Dhimine est architecte de solutions chez AWS. Il se spécialise dans l’IA générative, l’informatique sans serveur et l’analyse de données. Il est un membre/mentor actif de la communauté technique d’apprentissage automatique et a publié plusieurs articles scientifiques sur divers sujets liés à l’IA/ML. Il travaille avec des clients, allant des start-ups aux entreprises, pour développer des solutions d'IA générative. Il est particulièrement passionné par l’exploitation des grands modèles linguistiques pour l’analyse avancée des données et par l’exploration d’applications pratiques qui répondent aux défis du monde réel. En dehors du travail, AJ aime voyager et se trouve actuellement dans 53 pays dans le but de visiter tous les pays du monde.
AJ Dhimine est architecte de solutions chez AWS. Il se spécialise dans l’IA générative, l’informatique sans serveur et l’analyse de données. Il est un membre/mentor actif de la communauté technique d’apprentissage automatique et a publié plusieurs articles scientifiques sur divers sujets liés à l’IA/ML. Il travaille avec des clients, allant des start-ups aux entreprises, pour développer des solutions d'IA générative. Il est particulièrement passionné par l’exploitation des grands modèles linguistiques pour l’analyse avancée des données et par l’exploration d’applications pratiques qui répondent aux défis du monde réel. En dehors du travail, AJ aime voyager et se trouve actuellement dans 53 pays dans le but de visiter tous les pays du monde.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

