Aujourd'hui, nous sommes ravis d'annoncer que les modèles de base Code Llama, développés par Meta, sont disponibles pour les clients via Amazon SageMaker JumpStart à déployer en un clic pour exécuter l'inférence. Code Llama est un modèle de langage étendu (LLM) de pointe capable de générer du code et du langage naturel sur le code à partir d'invites de code et de langage naturel. Vous pouvez essayer ce modèle avec SageMaker JumpStart, un hub d'apprentissage automatique (ML) qui donne accès à des algorithmes, des modèles et des solutions ML afin que vous puissiez rapidement démarrer avec le ML. Dans cet article, nous expliquons comment découvrir et déployer le modèle Code Llama via SageMaker JumpStart.
Code Lama
Code Llama est un modèle édité par Meta qui est construit sur Llama 2. Ce modèle de pointe est conçu pour améliorer la productivité des tâches de programmation des développeurs en les aidant à créer du code de haute qualité et bien documenté. Les modèles excellent en Python, C++, Java, PHP, C#, TypeScript et Bash, et ont le potentiel de faire gagner du temps aux développeurs et de rendre les flux de travail logiciels plus efficaces.
Il se décline en trois variantes, conçues pour couvrir une grande variété d'applications : le modèle fondamental (Code Llama), un modèle spécialisé Python (Code Llama Python) et un modèle de suivi d'instructions pour comprendre les instructions en langage naturel (Code Llama Instruct). Toutes les variantes de Code Llama sont disponibles en quatre tailles : paramètres 7B, 13B, 34B et 70B. Les variantes de base et d'instruction 7B et 13B prennent en charge le remplissage en fonction du contenu environnant, ce qui les rend idéales pour les applications d'assistant de code. Les modèles ont été conçus en utilisant Llama 2 comme base, puis entraînés sur 500 milliards de jetons de données de code, la version spécialisée Python étant entraînée sur 100 milliards de jetons supplémentaires. Les modèles Code Llama fournissent des générations stables avec jusqu'à 100,000 16,000 jetons de contexte. Tous les modèles sont entraînés sur des séquences de 100,000 XNUMX jetons et présentent des améliorations sur les entrées jusqu'à XNUMX XNUMX jetons.
Le modèle est mis à disposition sous le même licence communautaire en tant que Llama 2.
Modèles de fondation dans SageMaker
SageMaker JumpStart donne accès à une gamme de modèles provenant de hubs de modèles populaires, notamment Hugging Face, PyTorch Hub et TensorFlow Hub, que vous pouvez utiliser dans votre flux de travail de développement ML dans SageMaker. Les progrès récents du ML ont donné naissance à une nouvelle classe de modèles connus sous le nom de modèles de fondation, qui sont généralement formés sur des milliards de paramètres et sont adaptables à une large catégorie de cas d'utilisation, tels que le résumé de texte, la génération d'art numérique et la traduction linguistique. La formation de ces modèles étant coûteuse, les clients souhaitent utiliser des modèles de base pré-entraînés existants et les affiner si nécessaire, plutôt que de former ces modèles eux-mêmes. SageMaker fournit une liste organisée de modèles parmi lesquels vous pouvez choisir sur la console SageMaker.
Vous pouvez trouver des modèles de base auprès de différents fournisseurs de modèles dans SageMaker JumpStart, ce qui vous permet de démarrer rapidement avec les modèles de base. Vous pouvez trouver des modèles de base basés sur différentes tâches ou fournisseurs de modèles, et consulter facilement les caractéristiques des modèles et les conditions d'utilisation. Vous pouvez également essayer ces modèles à l’aide d’un widget d’interface utilisateur de test. Lorsque vous souhaitez utiliser un modèle de base à grande échelle, vous pouvez le faire sans quitter SageMaker en utilisant des blocs-notes prédéfinis provenant de fournisseurs de modèles. Étant donné que les modèles sont hébergés et déployés sur AWS, vous pouvez être assuré que vos données, qu'elles soient utilisées pour évaluer ou utiliser le modèle à grande échelle, ne sont jamais partagées avec des tiers.
Découvrez le modèle Code Llama dans SageMaker JumpStart
Pour déployer le modèle Code Llama 70B, procédez comme suit dans Amazon SageMakerStudio:
- Sur la page d'accueil de SageMaker Studio, choisissez Début de saut dans le volet de navigation.
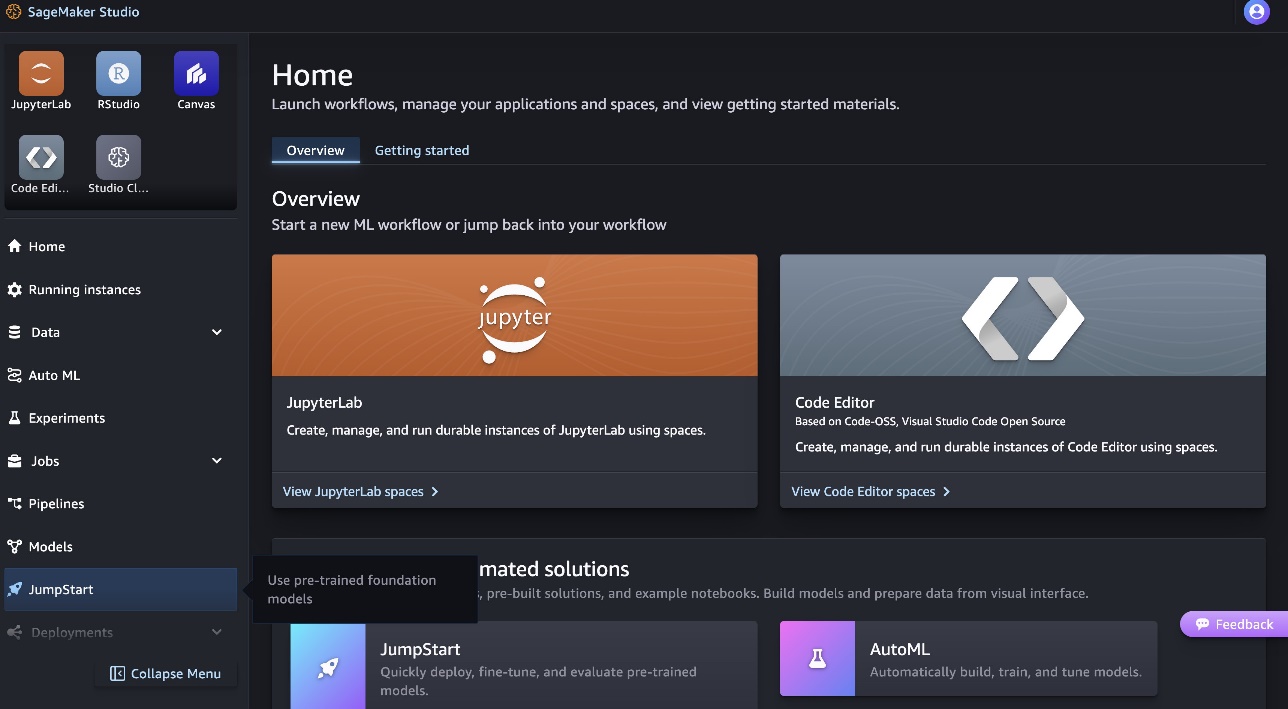
- Recherchez les modèles Code Llama et choisissez le modèle Code Llama 70B dans la liste des modèles affichés.
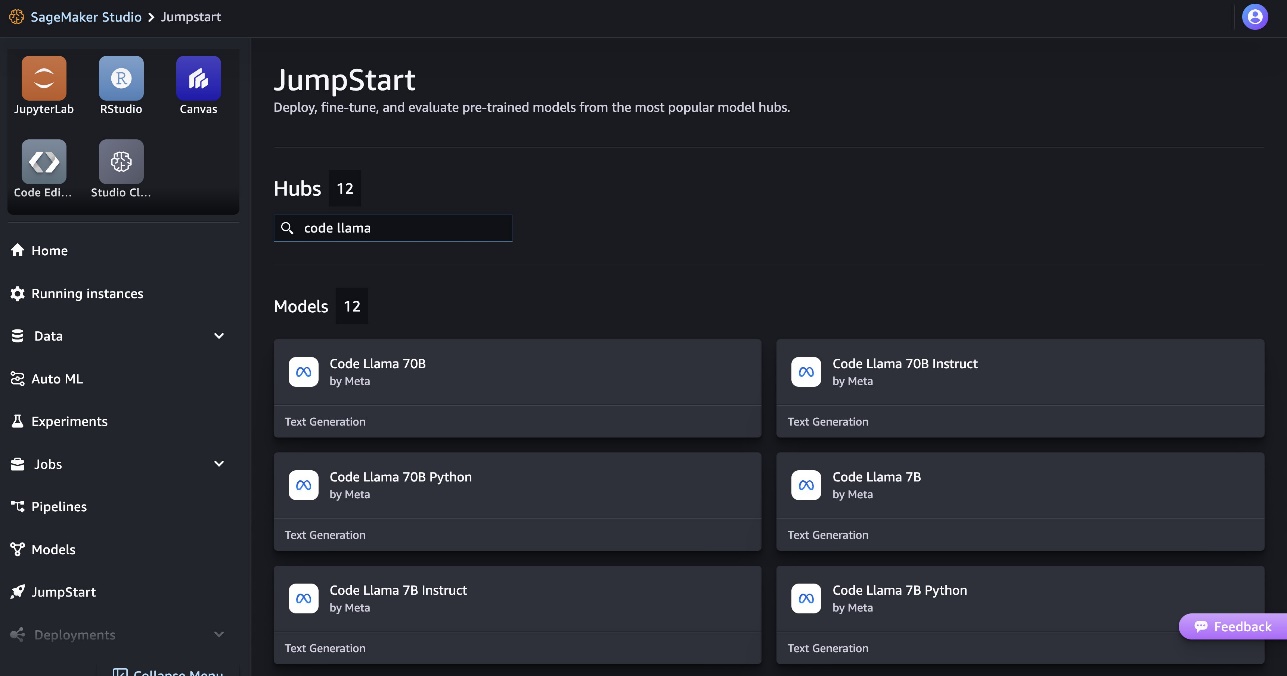
Vous pouvez trouver plus d'informations sur le modèle sur la fiche modèle Code Llama 70B.
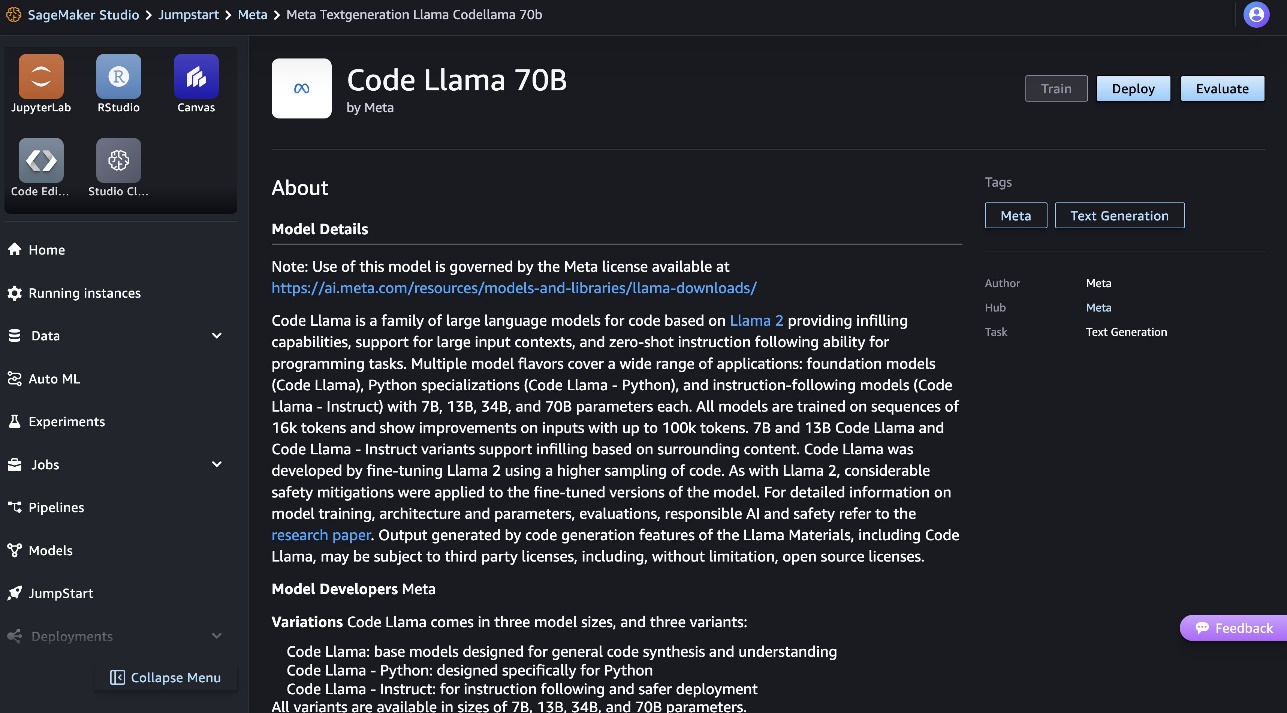
La capture d'écran suivante montre les paramètres du point de terminaison. Vous pouvez modifier les options ou utiliser celles par défaut.
- Acceptez le contrat de licence utilisateur final (CLUF) et choisissez Déployer.
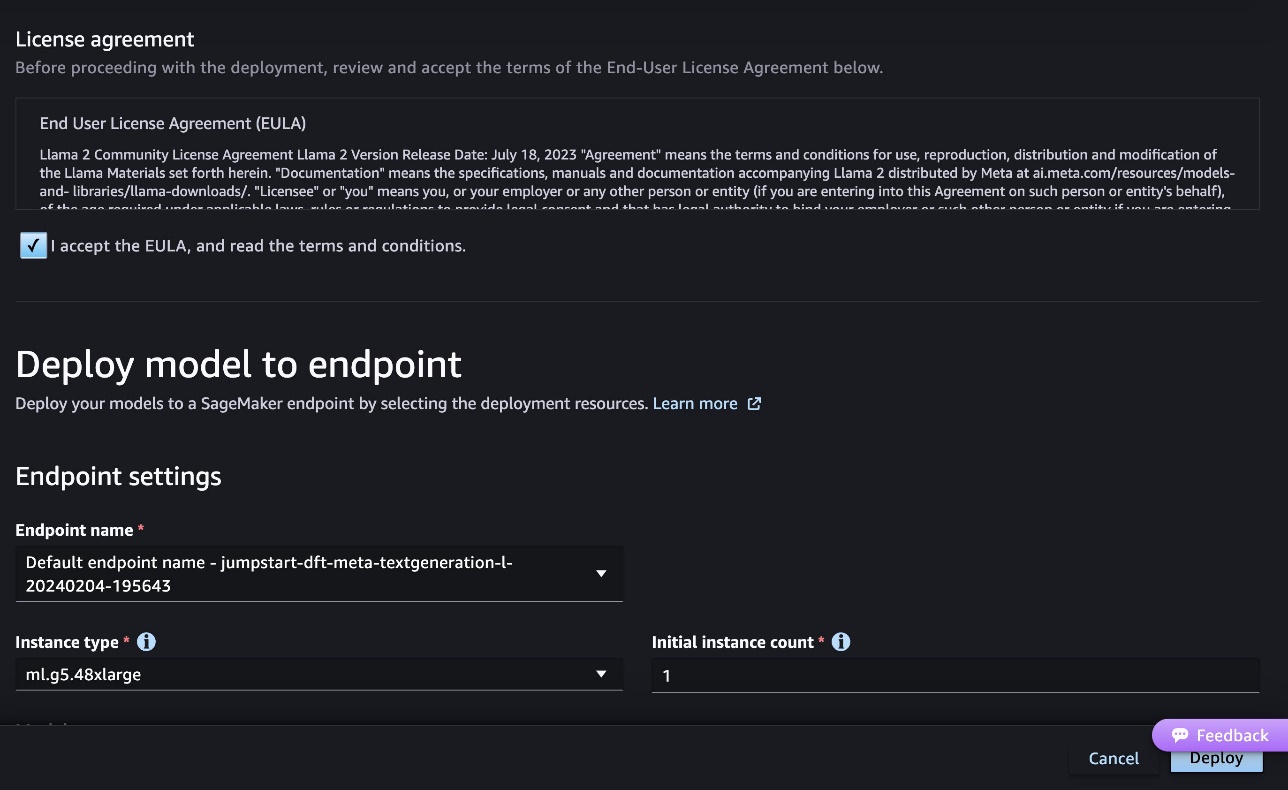
Cela lancera le processus de déploiement du point de terminaison, comme indiqué dans la capture d'écran suivante.
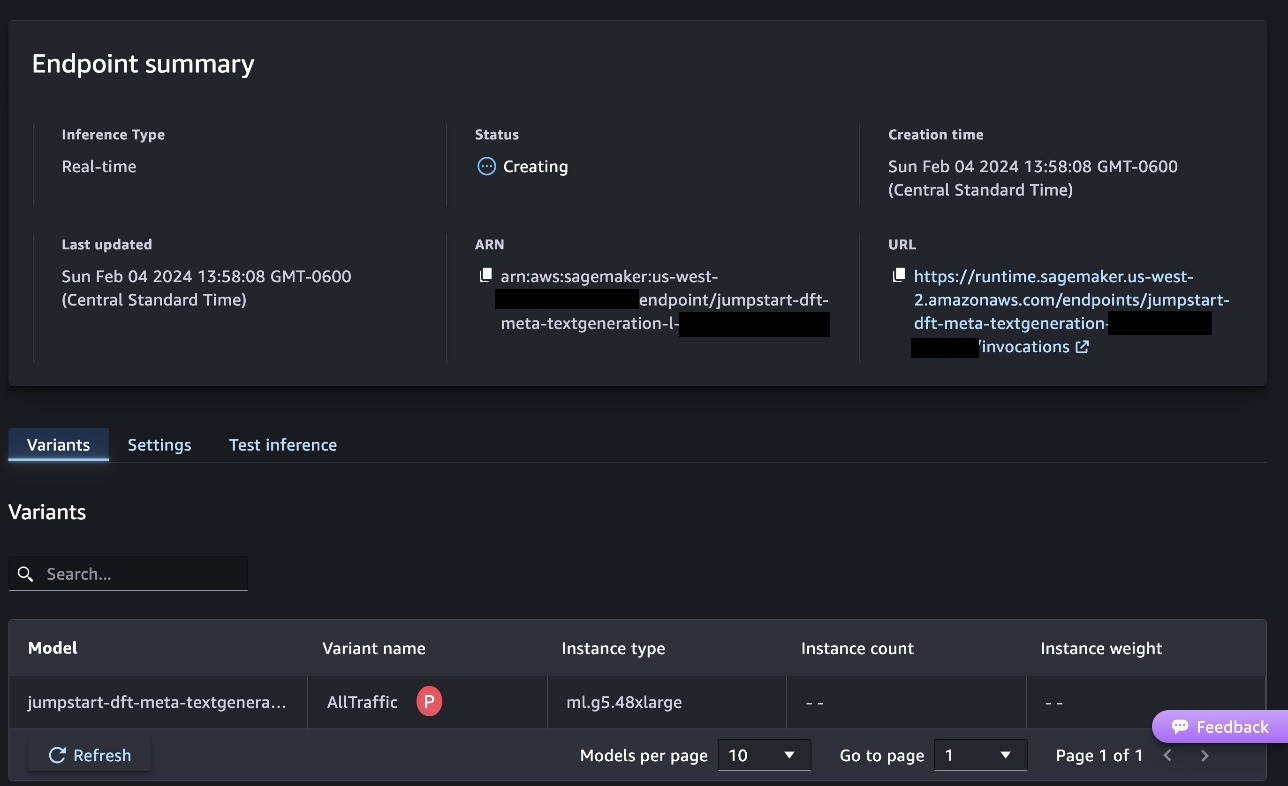
Déployer le modèle avec le SDK SageMaker Python
Vous pouvez également déployer via l'exemple de bloc-notes en choisissant Cahier ouvert dans la page de détails du modèle de Classic Studio. L'exemple de bloc-notes fournit des conseils de bout en bout sur la manière de déployer le modèle pour l'inférence et de nettoyer les ressources.
Pour déployer à l'aide d'un notebook, nous commençons par sélectionner un modèle approprié, spécifié par le model_id. Vous pouvez déployer n'importe lequel des modèles sélectionnés sur SageMaker avec le code suivant :
Cela déploie le modèle sur SageMaker avec les configurations par défaut, y compris le type d'instance par défaut et les configurations VPC par défaut. Vous pouvez modifier ces configurations en spécifiant des valeurs autres que celles par défaut dans Modèle JumpStart. Notez que par défaut, accept_eula est fixé à False. Vous devez définir accept_eula=True pour déployer le point de terminaison avec succès. Ce faisant, vous acceptez le contrat de licence utilisateur et la politique d'utilisation acceptable mentionnés précédemment. Vous pouvez aussi download le contrat de licence.
Appeler un point de terminaison SageMaker
Une fois le point de terminaison déployé, vous pouvez effectuer une inférence à l'aide de Boto3 ou du SDK SageMaker Python. Dans le code suivant, nous utilisons le SDK SageMaker Python pour appeler le modèle à des fins d'inférence et imprimer la réponse :
La fonction print_response prend une charge utile composée de la charge utile et de la réponse du modèle et imprime la sortie. Code Llama prend en charge de nombreux paramètres lors de l'inférence :
- longueur maximale – Le modèle génère du texte jusqu'à ce que la longueur de sortie (qui inclut la longueur du contexte d'entrée) atteigne
max_length. S'il est spécifié, il doit s'agir d'un entier positif. - max_new_tokens – Le modèle génère du texte jusqu'à ce que la longueur de sortie (à l'exclusion de la longueur du contexte d'entrée) atteigne
max_new_tokens. S'il est spécifié, il doit s'agir d'un entier positif. - nombre_faisceaux – Ceci spécifie le nombre de faisceaux utilisés dans la recherche gourmande. S'il est spécifié, il doit s'agir d'un nombre entier supérieur ou égal à
num_return_sequences. - no_repeat_ngram_size – Le modèle assure qu'une suite de mots de
no_repeat_ngram_sizen'est pas répété dans la séquence de sortie. S'il est spécifié, il doit s'agir d'un entier positif supérieur à 1. - la réactivité – Ceci contrôle le caractère aléatoire de la sortie. Plus haut
temperaturedonne une séquence de sortie avec des mots à faible probabilité, et une séquence de sortie inférieuretemperatureaboutit à une séquence de sortie avec des mots à haute probabilité. Sitemperatureest 0, cela entraîne un décodage gourmand. S’il est spécifié, il doit s’agir d’un flottant positif. - arrêt_précoce - Si
True, la génération du texte est terminée lorsque toutes les hypothèses du faisceau atteignent le jeton de fin de phrase. S'il est spécifié, il doit être booléen. - faire_sample - Si
True, le modèle échantillonne le mot suivant selon la vraisemblance. S'il est spécifié, il doit être booléen. - top_k – À chaque étape de génération de texte, le modèle échantillonne uniquement le
top_kmots les plus probables. S'il est spécifié, il doit s'agir d'un entier positif. - top_p – À chaque étape de génération de texte, le modèle échantillonne à partir du plus petit ensemble de mots possible avec une probabilité cumulative
top_p. S'il est spécifié, il doit s'agir d'un nombre flottant compris entre 0 et 1. - return_full_text - Si
True, le texte d'entrée fera partie du texte généré en sortie. S'il est spécifié, il doit être booléen. La valeur par défaut estFalse. - Arrêtez – Si spécifié, il doit s'agir d'une liste de chaînes. La génération de texte s'arrête si l'une des chaînes spécifiées est générée.
Vous pouvez spécifier n'importe quel sous-ensemble de ces paramètres lors de l'appel d'un point de terminaison. Ensuite, nous montrons un exemple de la façon d'invoquer un point de terminaison avec ces arguments.
Compléter le code
Les exemples suivants montrent comment effectuer la complétion du code lorsque la réponse attendue du point de terminaison est la suite naturelle de l'invite.
Nous exécutons d'abord le code suivant :
Nous obtenons la sortie suivante :
Pour notre prochain exemple, nous exécutons le code suivant :
Nous obtenons la sortie suivante :
Génération de code
Les exemples suivants montrent la génération de code Python à l'aide de Code Llama.
Nous exécutons d'abord le code suivant :
Nous obtenons la sortie suivante :
Pour notre prochain exemple, nous exécutons le code suivant :
Nous obtenons la sortie suivante :
Voici quelques exemples de tâches liées au code utilisant Code Llama 70B. Vous pouvez utiliser le modèle pour générer du code encore plus compliqué. Nous vous encourageons à l’essayer en utilisant vos propres cas d’utilisation et exemples liés au code !
Nettoyer
Après avoir testé les points de terminaison, assurez-vous de supprimer les points de terminaison d'inférence SageMaker et le modèle pour éviter d'encourir des frais. Utilisez le code suivant :
Conclusion
Dans cet article, nous avons présenté Code Llama 70B sur SageMaker JumpStart. Code Llama 70B est un modèle de pointe pour générer du code à partir d'invites en langage naturel ainsi que du code. Vous pouvez déployer le modèle en quelques étapes simples dans SageMaker JumpStart, puis l'utiliser pour effectuer des tâches liées au code telles que la génération de code et le remplissage de code. Dans une prochaine étape, essayez d'utiliser le modèle avec vos propres cas d'utilisation et données liés au code.
À propos des auteurs
 Dr Kyle Ulrich est un scientifique appliqué au sein de l'équipe Amazon SageMaker JumpStart. Ses intérêts de recherche comprennent les algorithmes d'apprentissage automatique évolutifs, la vision par ordinateur, les séries chronologiques, les processus bayésiens non paramétriques et gaussiens. Son doctorat est de l'Université Duke et il a publié des articles dans NeurIPS, Cell et Neuron.
Dr Kyle Ulrich est un scientifique appliqué au sein de l'équipe Amazon SageMaker JumpStart. Ses intérêts de recherche comprennent les algorithmes d'apprentissage automatique évolutifs, la vision par ordinateur, les séries chronologiques, les processus bayésiens non paramétriques et gaussiens. Son doctorat est de l'Université Duke et il a publié des articles dans NeurIPS, Cell et Neuron.
 Dr Farooq Sabir est architecte principal de solutions spécialisées en intelligence artificielle et en apprentissage automatique chez AWS. Il est titulaire d'un doctorat et d'une maîtrise en génie électrique de l'Université du Texas à Austin et d'une maîtrise en informatique du Georgia Institute of Technology. Il a plus de 15 ans d'expérience de travail et aime aussi enseigner et encadrer des étudiants. Chez AWS, il aide les clients à formuler et à résoudre leurs problèmes commerciaux dans les domaines de la science des données, de l'apprentissage automatique, de la vision par ordinateur, de l'intelligence artificielle, de l'optimisation numérique et des domaines connexes. Basé à Dallas, au Texas, lui et sa famille adorent voyager et faire de longs trajets en voiture.
Dr Farooq Sabir est architecte principal de solutions spécialisées en intelligence artificielle et en apprentissage automatique chez AWS. Il est titulaire d'un doctorat et d'une maîtrise en génie électrique de l'Université du Texas à Austin et d'une maîtrise en informatique du Georgia Institute of Technology. Il a plus de 15 ans d'expérience de travail et aime aussi enseigner et encadrer des étudiants. Chez AWS, il aide les clients à formuler et à résoudre leurs problèmes commerciaux dans les domaines de la science des données, de l'apprentissage automatique, de la vision par ordinateur, de l'intelligence artificielle, de l'optimisation numérique et des domaines connexes. Basé à Dallas, au Texas, lui et sa famille adorent voyager et faire de longs trajets en voiture.
 Juin gagné est chef de produit chez SageMaker JumpStart. Il se concentre sur la création de modèles de base facilement détectables et utilisables pour aider les clients à créer des applications d'IA génératives. Son expérience chez Amazon comprend également l'application d'achat mobile et la livraison du dernier kilomètre.
Juin gagné est chef de produit chez SageMaker JumpStart. Il se concentre sur la création de modèles de base facilement détectables et utilisables pour aider les clients à créer des applications d'IA génératives. Son expérience chez Amazon comprend également l'application d'achat mobile et la livraison du dernier kilomètre.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/code-llama-70b-is-now-available-in-amazon-sagemaker-jumpstart/

