Amazon Sage Maker points de terminaison multimodèles (MME) sont une fonctionnalité entièrement gérée d'inférence SageMaker qui vous permet de déployer des milliers de modèles sur un seul point de terminaison. Auparavant, les MME allouaient de manière prédéterminée la puissance de calcul du processeur aux modèles de manière statique, quelle que soit la charge de trafic du modèle, en utilisant Serveur multimodèle (MMS) comme serveur modèle. Dans cet article, nous discutons d'une solution dans laquelle une MME peut ajuster dynamiquement la puissance de calcul attribuée à chaque modèle en fonction du modèle de trafic du modèle. Cette solution vous permet d'utiliser le calcul sous-jacent des MME plus efficacement et de réduire les coûts.
Les MME chargent et déchargent dynamiquement des modèles en fonction du trafic entrant vers le point de terminaison. Lorsqu'elles utilisent MMS comme serveur de modèles, les MME allouent un nombre fixe de travailleurs modèles pour chaque modèle. Pour plus d'informations, reportez-vous à Modèles d'hébergement de modèles dans Amazon SageMaker, partie 3 : exécuter et optimiser l'inférence multimodèle avec les points de terminaison multimodèle Amazon SageMaker.
Cependant, cela peut entraîner quelques problèmes lorsque votre modèle de trafic est variable. Disons que vous disposez d'un ou de quelques modèles recevant une grande quantité de trafic. Vous pouvez configurer MMS pour allouer un nombre élevé de travailleurs à ces modèles, mais cela est attribué à tous les modèles derrière MME car il s'agit d'une configuration statique. Cela conduit un grand nombre de travailleurs à utiliser le calcul matériel, même les modèles inactifs. Le problème inverse peut se produire si vous définissez une petite valeur pour le nombre de travailleurs. Les modèles populaires n'auront pas suffisamment de nœuds de calcul au niveau du serveur de modèles pour allouer correctement suffisamment de matériel derrière le point de terminaison de ces modèles. Le principal problème est qu'il est difficile de rester indépendant du modèle de trafic si vous ne pouvez pas faire évoluer dynamiquement vos nœuds de calcul au niveau du serveur de modèles pour allouer la quantité de calcul nécessaire.
La solution dont nous discutons dans cet article utilise DJLserveur en tant que serveur de modèles, ce qui peut aider à atténuer certains des problèmes dont nous avons discuté, permettre une mise à l'échelle par modèle et permettre aux MME d'être indépendants des modèles de trafic.
Architecture MME
Les MME SageMaker vous permettent de déployer plusieurs modèles derrière un seul point de terminaison d'inférence pouvant contenir une ou plusieurs instances. Chaque instance est conçue pour charger et servir plusieurs modèles dans la limite de sa mémoire et de sa capacité CPU/GPU. Grâce à cette architecture, une entreprise de logiciels en tant que service (SaaS) peut réduire le coût linéairement croissant de l'hébergement de plusieurs modèles et parvenir à une réutilisation de l'infrastructure cohérente avec le modèle multi-tenant appliqué ailleurs dans la pile d'applications. Le diagramme suivant illustre cette architecture.
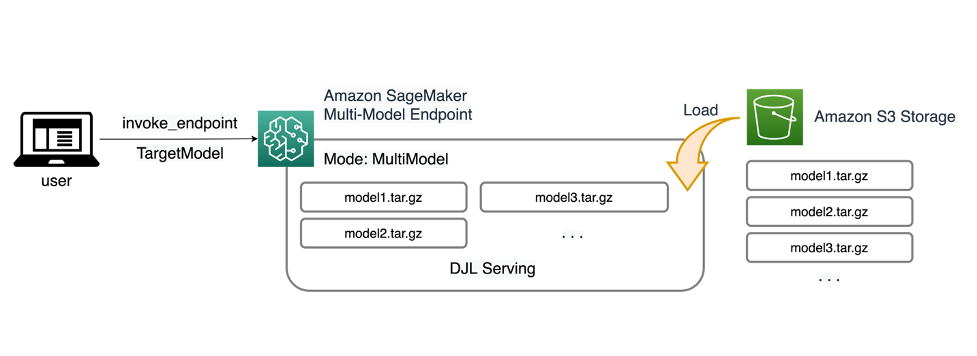
Un SageMaker MME charge dynamiquement des modèles à partir de Service de stockage simple Amazon (Amazon S3) lorsqu'il est invoqué, au lieu de télécharger tous les modèles lors de la première création du point de terminaison. Par conséquent, un appel initial à un modèle peut entraîner une latence d'inférence plus élevée que les inférences suivantes, qui sont effectuées avec une faible latence. Si le modèle est déjà chargé sur le conteneur lorsqu'il est invoqué, l'étape de téléchargement est ignorée et le modèle renvoie les inférences avec une faible latence. Par exemple, supposons que vous disposiez d’un modèle qui n’est utilisé que quelques fois par jour. Il est automatiquement chargé à la demande, tandis que les modèles fréquemment consultés sont conservés en mémoire et invoqués avec une latence constamment faible.
Derrière chaque MME se trouvent des instances d'hébergement de modèles, comme illustré dans le diagramme suivant. Ces instances chargent et expulsent plusieurs modèles vers et depuis la mémoire en fonction des modèles de trafic vers les modèles.
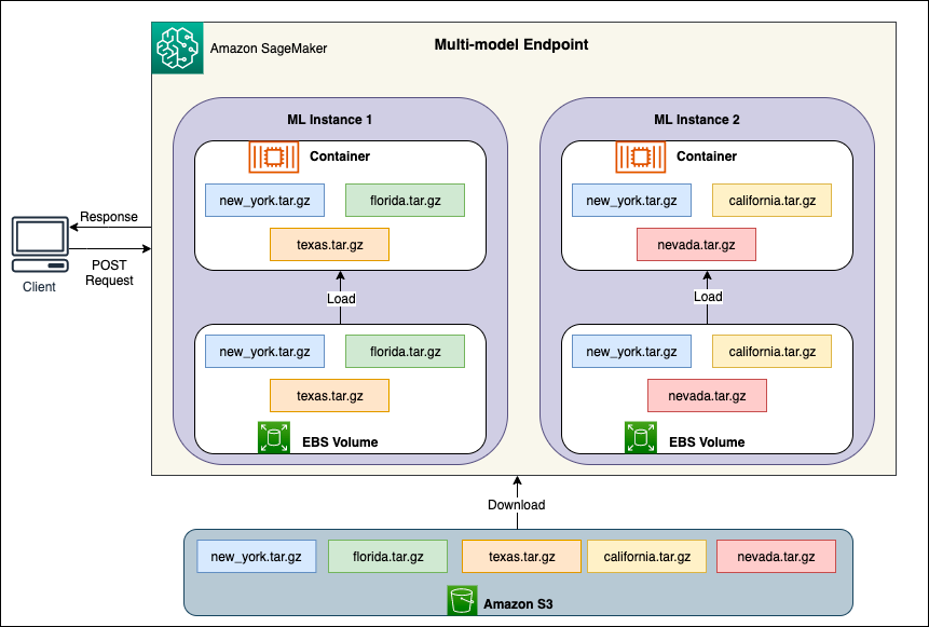
SageMaker continue d'acheminer les demandes d'inférence pour un modèle vers l'instance où le modèle est déjà chargé, de sorte que les demandes soient servies à partir d'une copie de modèle mise en cache (voir le diagramme suivant, qui montre le chemin de la demande pour la première demande de prédiction par rapport à la prédiction mise en cache. chemin de la demande). Toutefois, si le modèle reçoit de nombreuses demandes d'appel et qu'il existe des instances supplémentaires pour le MME, SageMaker achemine certaines demandes vers une autre instance pour répondre à cette augmentation. Pour profiter de la mise à l'échelle automatisée du modèle dans SageMaker, assurez-vous d'avoir configuration de la mise à l'échelle automatique de l'instance pour provisionner une capacité d'instance supplémentaire. Configurez votre stratégie de mise à l'échelle au niveau du point de terminaison avec des paramètres personnalisés ou des appels par minute (recommandé) pour ajouter plus d'instances au parc de points de terminaison.

Présentation du serveur de modèles
Un serveur de modèles est un composant logiciel qui fournit un environnement d'exécution pour déployer et servir des modèles d'apprentissage automatique (ML). Il agit comme une interface entre les modèles formés et les applications clientes qui souhaitent effectuer des prédictions à l'aide de ces modèles.
L'objectif principal d'un serveur de modèles est de permettre une intégration sans effort et un déploiement efficace de modèles ML dans les systèmes de production. Au lieu d'intégrer le modèle directement dans une application ou un framework spécifique, le serveur de modèles fournit une plate-forme centralisée sur laquelle plusieurs modèles peuvent être déployés, gérés et servis.
Les serveurs de modèles offrent généralement les fonctionnalités suivantes :
- Chargement du modèle – Le serveur charge les modèles ML formés en mémoire, les rendant prêts à servir des prédictions.
- API d'inférence – Le serveur expose une API qui permet aux applications clientes d'envoyer des données d'entrée et de recevoir des prédictions des modèles déployés.
- écaillage – Les serveurs modèles sont conçus pour gérer les demandes simultanées de plusieurs clients. Ils fournissent des mécanismes de traitement parallèle et de gestion efficace des ressources afin de garantir un débit élevé et une faible latence.
- Intégration avec les moteurs backend – Les serveurs de modèles sont intégrés à des frameworks backend tels que DeepSpeed et FasterTransformer pour partitionner de grands modèles et exécuter une inférence hautement optimisée.
Architecture DJL
Service DJL est un serveur modèle universel open source, hautes performances. DJL Serving est construit sur Djl, une bibliothèque d'apprentissage profond écrite dans le langage de programmation Java. Il peut prendre un modèle d'apprentissage profond, plusieurs modèles ou flux de travail et les rendre disponibles via un point de terminaison HTTP. DJL Serving prend en charge le déploiement de modèles à partir de plusieurs frameworks tels que PyTorch, TensorFlow, Apache MXNet, ONNX, TensorRT, Hugging Face Transformers, DeepSpeed, FasterTransformer, etc.
DJL Serving propose de nombreuses fonctionnalités qui vous permettent de déployer vos modèles avec de hautes performances :
- Facilité d’utilisation – DJL Serving peut servir la plupart des modèles prêts à l’emploi. Apportez simplement les artefacts du modèle et DJL Serving peut les héberger.
- Prise en charge de plusieurs appareils et accélérateurs – DJL Serving prend en charge le déploiement de modèles sur CPU, GPU et Inférence AWS.
- Performance – DJL Serving exécute une inférence multithread dans une seule JVM pour augmenter le débit.
- Mise en lots dynamique – DJL Serving prend en charge le traitement par lots dynamique pour augmenter le débit.
- Mise à l'échelle automatique – DJL Serving augmentera et diminuera automatiquement les travailleurs en fonction de la charge de trafic.
- Prise en charge multimoteur – DJL Serving peut héberger simultanément des modèles utilisant différents frameworks (tels que PyTorch et TensorFlow).
- Modèles d'ensemble et de workflow – DJL Serving prend en charge le déploiement de flux de travail complexes composés de plusieurs modèles et exécute des parties du flux de travail sur CPU et des parties sur GPU. Les modèles au sein d'un flux de travail peuvent utiliser différents frameworks.
En particulier, la fonction de mise à l'échelle automatique de DJL Serving permet de garantir facilement que les modèles sont mis à l'échelle de manière appropriée pour le trafic entrant. Par défaut, DJL Serving détermine le nombre maximum de Workers pour un modèle pouvant être pris en charge en fonction du matériel disponible (cœurs CPU, périphériques GPU). Vous pouvez définir des limites inférieures et supérieures pour chaque modèle afin de vous assurer qu'un niveau de trafic minimum peut toujours être servi et qu'un seul modèle ne consomme pas toutes les ressources disponibles.
DJL Serving utilise un Netty frontend au-dessus des pools de threads de travail backend. Le frontend utilise une seule configuration Netty avec plusieurs HttpRequestHandlers. Différents gestionnaires de requêtes fourniront un support pour le API d'inférence, API de gestion, ou d'autres API disponibles à partir de divers plugins.
Le backend est basé autour du Gestionnaire de charge de travail (WLM). Le WLM prend en charge plusieurs threads de travail pour chaque modèle ainsi que le traitement par lots et le routage des demandes vers ceux-ci. Lorsque plusieurs modèles sont servis, WLM vérifie d'abord la taille de la file d'attente des demandes d'inférence de chaque modèle. Si la taille de la file d'attente est supérieure à deux fois la taille du lot d'un modèle, WLM augmente le nombre de travailleurs affectés à ce modèle.
Vue d'ensemble de la solution
L'implémentation de DJL avec un MME diffère de la configuration MMS par défaut. Pour DJL Serving avec un MME, nous compressons les fichiers suivants au format model.tar.gz attendu par SageMaker Inference :
- modèle.joblib – Pour cette implémentation, nous poussons directement les métadonnées du modèle dans l’archive tar. Dans ce cas, nous travaillons avec un
.joblibfichier, nous fournissons donc ce fichier dans notre archive tar pour que notre script d'inférence puisse le lire. Si l'artefact est trop volumineux, vous pouvez également le transférer vers Amazon S3 et pointer vers celui-ci dans la configuration de diffusion que vous définissez pour DJL. - servant.propriétés – Ici, vous pouvez configurer n’importe quel modèle lié au serveur Variables d'environnement. La puissance de DJL ici est que vous pouvez configurer
minWorkersainsi quemaxWorkerspour chaque archive tar modèle. Cela permet à chaque modèle d'évoluer vers le haut et vers le bas au niveau du serveur de modèles. Par exemple, si un modèle unique reçoit la majorité du trafic pour une MME, le serveur de modèles augmentera dynamiquement les nœuds de calcul. Dans cet exemple, nous ne configurons pas ces variables et laissons DJL déterminer le nombre de travailleurs nécessaire en fonction de notre modèle de trafic. - modèle.py – Il s’agit du script d’inférence pour tout prétraitement ou post-traitement personnalisé que vous souhaitez implémenter. Le model.py s'attend à ce que votre logique soit encapsulée dans une méthode handle par défaut.
- exigences.txt (facultatif) – Par défaut, DJL est installé avec PyTorch, mais toutes les dépendances supplémentaires dont vous avez besoin peuvent être poussées ici.
Pour cet exemple, nous montrons la puissance de DJL avec un MME en prenant un exemple de modèle SKLearn. Nous exécutons une tâche de formation avec ce modèle, puis créons 1,000 XNUMX copies de cet artefact de modèle pour soutenir notre MME. Nous montrons ensuite comment DJL peut évoluer de manière dynamique pour gérer tout type de modèle de trafic que votre MME peut recevoir. Cela peut inclure une répartition uniforme du trafic sur tous les modèles ou même sur quelques modèles populaires recevant la majorité du trafic. Vous pouvez trouver tout le code dans ce qui suit GitHub repo.
Pré-requis
Pour cet exemple, nous utilisons une instance de notebook SageMaker avec un noyau conda_python3 et une instance ml.c5.xlarge. Pour effectuer les tests de charge, vous pouvez utiliser un Cloud de calcul élastique Amazon (Amazon EC2) ou une instance de bloc-notes SageMaker plus grande. Dans cet exemple, nous évoluons jusqu'à plus d'un millier de transactions par seconde (TPS), nous vous suggérons donc de tester sur une instance EC2 plus lourde telle qu'un ml.c5.18xlarge afin que vous disposiez de plus de calcul avec lequel travailler.
Créer un artefact de modèle
Nous devons d’abord créer notre artefact de modèle et les données que nous utilisons dans cet exemple. Pour ce cas, nous générons des données artificielles avec NumPy et nous entraînons à l'aide d'un modèle de régression linéaire SKLearn avec l'extrait de code suivant :
Après avoir exécuté le code précédent, vous devriez avoir un model.joblib fichier créé dans votre environnement local.
Extraire l'image DJL Docker
L'image Docker djl-inference:0.23.0-cpu-full-v1.0 est notre conteneur de service DJL utilisé dans cet exemple. Vous pouvez ajuster l'URL suivante en fonction de votre région :
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
En option, vous pouvez également utiliser cette image comme image de base et l'étendre pour créer votre propre image Docker sur Registre des conteneurs élastiques Amazon (Amazon ECR) avec toutes les autres dépendances dont vous avez besoin.
Créer le fichier modèle
Tout d'abord, nous créons un fichier appelé serving.properties. Cela demande à DJLServing d'utiliser le moteur Python. Nous définissons également le max_idle_time d'un travailleur à 600 secondes. Cela garantit que nous prendrons plus de temps pour réduire le nombre de travailleurs dont nous disposons par modèle. Nous ne nous ajustons pas minWorkers ainsi que maxWorkers que nous pouvons définir et nous laissons DJL calculer dynamiquement le nombre de travailleurs nécessaires en fonction du trafic que chaque modèle reçoit. Les propriétés de service sont affichées comme suit. Pour voir la liste complète des options de configuration, reportez-vous à Configuration du moteur.
Ensuite, nous créons notre fichier model.py, qui définit la logique de chargement et d'inférence du modèle. Pour les MME, chaque fichier model.py est spécifique à un modèle. Les modèles sont stockés dans leurs propres chemins sous le magasin de modèles (généralement /opt/ml/model/). Lors du chargement des modèles, ils seront chargés sous le chemin du magasin de modèles dans leur propre répertoire. L'exemple complet de model.py dans cette démo peut être vu dans le GitHub repo.
Nous créons un model.tar.gz fichier qui inclut notre modèle (model.joblib), model.pyet serving.properties:
À des fins de démonstration, nous réalisons 1,000 XNUMX copies du même model.tar.gz fichier pour représenter le grand nombre de modèles à héberger. En production, vous devez créer un model.tar.gz fichier pour chacun de vos modèles.
Enfin, nous téléchargeons ces modèles sur Amazon S3.
Créer un modèle SageMaker
Nous créons maintenant un Modèle SageMaker. Nous utilisons l'image ECR définie précédemment et l'artefact de modèle de l'étape précédente pour créer le modèle SageMaker. Dans la configuration du modèle, nous configurons le mode comme MultiModel. Cela indique à DJLServing que nous créons un MME.
Créer un point de terminaison SageMaker
Dans cette démo, nous utilisons 20 instances ml.c5d.18xlarge pour évoluer vers un TPS de l'ordre des milliers. Assurez-vous d'augmenter la limite de votre type d'instance, si nécessaire, pour atteindre le TPS que vous ciblez.
Test de charge
Au moment de la rédaction, l'outil de test de charge interne SageMaker Outil de recommandation d'inférence Amazon SageMaker ne prend pas en charge nativement les tests pour les MME. Par conséquent, nous utilisons l'outil open source Python Criquet. Locust est simple à configurer et peut suivre des métriques telles que le TPS et la latence de bout en bout. Pour une compréhension complète de la façon de le configurer avec SageMaker, voir Meilleures pratiques pour les tests de charge des points de terminaison d'inférence en temps réel Amazon SageMaker.
Dans ce cas d'utilisation, nous souhaitons simuler trois modèles de trafic différents avec des MME. Nous disposons donc des trois scripts Python suivants qui s'alignent sur chaque modèle. Notre objectif ici est de prouver que, quel que soit notre modèle de trafic, nous pouvons atteindre le même TPS cible et évoluer de manière appropriée.
Nous pouvons spécifier un poids dans notre script Locust pour attribuer le trafic à différentes parties de nos modèles. Par exemple, avec notre modèle chaud unique, nous implémentons deux méthodes comme suit :
Nous pouvons alors attribuer un certain poids à chaque méthode, c'est-à-dire lorsqu'une certaine méthode reçoit un pourcentage spécifique du trafic :
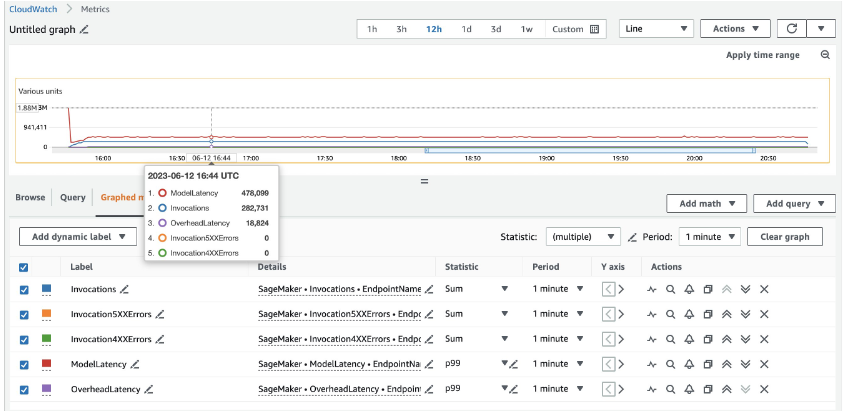
Pour 20 instances ml.c5d.18xlarge, nous voyons les métriques d'appel suivantes sur le Amazon Cloud Watch console. Ces valeurs restent assez cohérentes dans les trois modèles de trafic. Pour mieux comprendre les métriques CloudWatch pour l'inférence en temps réel SageMaker et les MME, reportez-vous à Métriques d'appel de point de terminaison SageMaker.
Vous pouvez trouver le reste des scripts Locust dans le répertoire locust-utils dans le dépôt GitHub.
Résumé
Dans cet article, nous avons expliqué comment un MME peut ajuster dynamiquement la puissance de calcul attribuée à chaque modèle en fonction du modèle de trafic du modèle. Cette fonctionnalité nouvellement lancée est disponible dans toutes les régions AWS où SageMaker est disponible. Notez qu'au moment de l'annonce, seules les instances CPU sont prises en charge. Pour en savoir plus, reportez-vous à Algorithmes, cadres et instances pris en charge.
À propos des auteurs
 Ram Végiraju est un architecte ML au sein de l'équipe SageMaker Service. Il se concentre sur l'aide aux clients pour créer et optimiser leurs solutions d'IA/ML sur Amazon SageMaker. Dans ses temps libres, il aime voyager et écrire.
Ram Végiraju est un architecte ML au sein de l'équipe SageMaker Service. Il se concentre sur l'aide aux clients pour créer et optimiser leurs solutions d'IA/ML sur Amazon SageMaker. Dans ses temps libres, il aime voyager et écrire.
 Qingwei Li est un spécialiste de l'apprentissage automatique chez Amazon Web Services. Il a obtenu son doctorat. en recherche opérationnelle après avoir cassé le compte de subvention de recherche de son conseiller et échoué à décerner le prix Nobel qu'il avait promis. Actuellement, il aide les clients du secteur des services financiers et de l'assurance à créer des solutions d'apprentissage automatique sur AWS. Dans ses temps libres, il aime lire et enseigner.
Qingwei Li est un spécialiste de l'apprentissage automatique chez Amazon Web Services. Il a obtenu son doctorat. en recherche opérationnelle après avoir cassé le compte de subvention de recherche de son conseiller et échoué à décerner le prix Nobel qu'il avait promis. Actuellement, il aide les clients du secteur des services financiers et de l'assurance à créer des solutions d'apprentissage automatique sur AWS. Dans ses temps libres, il aime lire et enseigner.
 James Wu est un architecte de solution spécialiste senior AI/ML chez AWS. aider les clients à concevoir et à créer des solutions d'IA/ML. Le travail de James couvre un large éventail de cas d'utilisation du ML, avec un intérêt principal pour la vision par ordinateur, l'apprentissage en profondeur et la mise à l'échelle du ML dans l'entreprise. Avant de rejoindre AWS, James a été architecte, développeur et leader technologique pendant plus de 10 ans, dont 6 ans en ingénierie et 4 ans dans les secteurs du marketing et de la publicité.
James Wu est un architecte de solution spécialiste senior AI/ML chez AWS. aider les clients à concevoir et à créer des solutions d'IA/ML. Le travail de James couvre un large éventail de cas d'utilisation du ML, avec un intérêt principal pour la vision par ordinateur, l'apprentissage en profondeur et la mise à l'échelle du ML dans l'entreprise. Avant de rejoindre AWS, James a été architecte, développeur et leader technologique pendant plus de 10 ans, dont 6 ans en ingénierie et 4 ans dans les secteurs du marketing et de la publicité.
 Saurabh Trikandé est chef de produit senior pour Amazon SageMaker Inference. Il est passionné par le travail avec les clients et est motivé par l'objectif de démocratiser l'apprentissage automatique. Il se concentre sur les principaux défis liés au déploiement d'applications ML complexes, de modèles ML multi-locataires, d'optimisations de coûts et de rendre le déploiement de modèles d'apprentissage en profondeur plus accessible. Dans ses temps libres, Saurabh aime faire de la randonnée, découvrir des technologies innovantes, suivre TechCrunch et passer du temps avec sa famille.
Saurabh Trikandé est chef de produit senior pour Amazon SageMaker Inference. Il est passionné par le travail avec les clients et est motivé par l'objectif de démocratiser l'apprentissage automatique. Il se concentre sur les principaux défis liés au déploiement d'applications ML complexes, de modèles ML multi-locataires, d'optimisations de coûts et de rendre le déploiement de modèles d'apprentissage en profondeur plus accessible. Dans ses temps libres, Saurabh aime faire de la randonnée, découvrir des technologies innovantes, suivre TechCrunch et passer du temps avec sa famille.
 Xu Deng est un responsable d'ingénieur logiciel au sein de l'équipe SageMaker. Il s'efforce d'aider les clients à créer et à optimiser leur expérience d'inférence AI/ML sur Amazon SageMaker. Dans ses temps libres, il aime voyager et faire du snowboard.
Xu Deng est un responsable d'ingénieur logiciel au sein de l'équipe SageMaker. Il s'efforce d'aider les clients à créer et à optimiser leur expérience d'inférence AI/ML sur Amazon SageMaker. Dans ses temps libres, il aime voyager et faire du snowboard.
 Siddharth Venkatesan est ingénieur logiciel chez AWS Deep Learning. Il se concentre actuellement sur la création de solutions pour l'inférence de grands modèles. Avant AWS, il a travaillé au sein de l'organisation Amazon Grocery pour créer de nouvelles fonctionnalités de paiement pour les clients du monde entier. En dehors du travail, il aime le ski, le plein air et regarder des sports.
Siddharth Venkatesan est ingénieur logiciel chez AWS Deep Learning. Il se concentre actuellement sur la création de solutions pour l'inférence de grands modèles. Avant AWS, il a travaillé au sein de l'organisation Amazon Grocery pour créer de nouvelles fonctionnalités de paiement pour les clients du monde entier. En dehors du travail, il aime le ski, le plein air et regarder des sports.
 Rohith Nalamaddi est ingénieur en développement logiciel chez AWS. Il travaille sur l'optimisation des charges de travail d'apprentissage en profondeur sur les GPU, la création d'inférences ML hautes performances et les solutions de service. Avant cela, il a travaillé sur la création de microservices basés sur AWS pour l'activité Amazon F3. En dehors du travail, il aime jouer et regarder des sports.
Rohith Nalamaddi est ingénieur en développement logiciel chez AWS. Il travaille sur l'optimisation des charges de travail d'apprentissage en profondeur sur les GPU, la création d'inférences ML hautes performances et les solutions de service. Avant cela, il a travaillé sur la création de microservices basés sur AWS pour l'activité Amazon F3. En dehors du travail, il aime jouer et regarder des sports.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

