Les données sont un catalyseur clé pour votre entreprise. De nombreux clients AWS ont intégré leurs données dans plusieurs sources de données à l'aide Colle AWS, un service d'intégration de données sans serveur, afin de prendre des décisions commerciales basées sur les données. Pour développer la puissance des données à grande échelle sur le long terme, il est fortement recommandé de concevoir un cycle de vie de développement de bout en bout pour vos pipelines d'intégration de données. Voici les demandes courantes de nos clients :
- Est-il possible de développer et de tester des tâches d'intégration de données AWS Glue sur mon ordinateur portable local ?
- Existe-t-il des approches recommandées pour le provisionnement des composants pour l'intégration des données ?
- Comment pouvons-nous construire un intégration continue ainsi que livraison continue pipeline (CI/CD) pour notre pipeline d'intégration de données ?
- Quelle est la meilleure pratique pour passer d'un environnement de pré-production à la production ?
Pour répondre à ces demandes, cet article définit le cycle de vie de développement pour l'intégration de données et montre comment les ingénieurs logiciels et les ingénieurs de données peuvent concevoir un cycle de vie de développement de bout en bout à l'aide d'AWS Glue, y compris le développement, les tests et la CI/CD, à l'aide d'un exemple de référence. modèle.
Cycle de vie de développement de bout en bout pour un pipeline d'intégration de données
Aujourd'hui, il est courant de définir non seulement les tâches d'intégration de données, mais également tous les composants de données dans le code. Cela signifie que vous pouvez vous fier aux meilleures pratiques logicielles standard pour créer votre pipeline d'intégration de données. Le cycle de vie du développement logiciel sur AWS définit les six phases suivantes : Planifier, Concevoir, Implémenter, Tester, Déployer et Maintenir.

Dans cette section, nous abordons chaque phase dans le contexte du pipeline d'intégration de données.
Plan
Dans la phase de planification, les développeurs collectent les exigences des parties prenantes telles que les utilisateurs finaux pour définir une exigence de données. Il peut s'agir des cas d'utilisation (par exemple, requêtes ad hoc, tableau de bord ou dépannage), de la quantité de données à traiter (par exemple, 1 To par jour), des types de données, du nombre de sources de données différentes à extraire , la latence des données à accepter pour les rendre interrogeables (par exemple, 15 minutes), etc.
Conception
Dans la phase de conception, vous analysez les exigences et identifiez la meilleure solution pour créer le pipeline d'intégration de données. Dans AWS, vous devez choisir les bons services pour atteindre l'objectif et proposer l'architecture en intégrant ces services et en définissant les dépendances entre les composants. Par exemple, vous pouvez choisir les tâches AWS Glue comme composant principal pour charger des données à partir de différentes sources, y compris Service de stockage simple Amazon (Amazon S3), puis les intégrer et prétraiter et enrichir les données. Ensuite, vous souhaiterez peut-être enchaîner plusieurs tâches AWS Glue et les orchestrer. Enfin, vous pouvez utiliser Amazone Athéna ainsi que Amazon QuickSight pour présenter les données enrichies aux utilisateurs finaux.
Mettre en œuvre le
Dans la phase de mise en œuvre, les ingénieurs de données codent le pipeline d'intégration de données. Ils analysent les exigences pour identifier les tâches de codage afin d'obtenir le résultat final. Le code comprend les éléments suivants :
- Définition de ressource AWS
- Logique d'intégration des données
Lorsque vous utilisez AWS Glue, vous pouvez définir la logique d'intégration des données dans un script de travail, qui peut être écrit en Python ou Scala. Vous pouvez utiliser votre IDE préféré pour implémenter la définition de ressource AWS à l'aide de la Kit de développement AWS Cloud (AWS CDK) ou AWS CloudFormation, ainsi que la logique métier des scripts de travail AWS Glue pour l'intégration des données. Pour en savoir plus sur la façon d'implémenter vos scripts de travail AWS Glue localement, consultez Développer et tester localement les tâches AWS Glue versions 3.0 et 4.0 à l'aide d'un conteneur Docker.
Teste
Dans la phase de test, vous vérifiez l'implémentation pour les bogues. L'analyse de la qualité comprend le test du code pour les erreurs et la vérification s'il répond aux exigences. Étant donné que de nombreuses équipes testent immédiatement le code que vous écrivez, la phase de test se déroule souvent parallèlement à la phase de développement. Il existe différents types de tests :
- Tests unitaires
- Test d'intégration
- Test de performance
Pour les tests unitaires, même pour l'intégration de données, vous pouvez compter sur un cadre de test standard tel que question ainsi que Test Scala. Pour en savoir plus sur la façon de réaliser des tests unitaires localement, reportez-vous à Développer et tester localement les tâches AWS Glue versions 3.0 et 4.0 à l'aide d'un conteneur Docker.
Déployer
Lorsque les ingénieurs de données développent un pipeline d'intégration de données, vous codez et testez sur une copie du produit différente de celle à laquelle les utilisateurs finaux ont accès. L'environnement utilisé par les utilisateurs finaux s'appelle production, alors que d'autres copies seraient dans le développant au sein de l’ pré-production environnement.
Le fait d'avoir des environnements de construction et de production séparés garantit que vous pouvez continuer à utiliser le pipeline d'intégration de données même lorsqu'il est modifié ou mis à niveau. La phase de déploiement comprend plusieurs tâches pour déplacer la dernière copie de build vers l'environnement de production, telles que l'empaquetage, la configuration de l'environnement et l'installation.
Les composants suivants sont déployés via AWS CDK ou AWS CloudFormation :
- Ressources AWS
- Scripts de tâche d'intégration de données pour AWS Glue
AWS CodePipeline vous aide à créer un mécanisme pour automatiser les déploiements dans différents environnements, y compris le développement, la pré-production et la production. Lorsque vous validez votre code Code AWSCommit, CodePipeline provisionne automatiquement les ressources AWS en fonction des modèles CloudFormation inclus dans la validation et télécharge les fichiers de script inclus dans la validation vers Amazon S3.
Maintenir
Même après avoir déployé votre solution dans un environnement de production, ce n'est pas la fin de votre projet. Vous devez surveiller en permanence le pipeline d'intégration de données et continuer à le maintenir et à l'améliorer. Plus précisément, vous devez également corriger les bogues, résoudre les problèmes des clients et gérer les modifications logicielles. En outre, vous devez surveiller les performances globales du système, la sécurité et l'expérience utilisateur pour identifier de nouvelles façons d'améliorer le pipeline d'intégration de données existant.
Vue d'ensemble de la solution
En règle générale, vous disposez de plusieurs comptes pour gérer et provisionner les ressources de votre pipeline de données. Dans cet article, nous supposons les trois comptes suivants :
- Compte en cours – Cela héberge le pipeline de bout en bout
- Compte de développement – Il héberge le pipeline d'intégration dans l'environnement de développement
- Compte de production – Il héberge le pipeline d'intégration de données dans l'environnement de production
Si vous le souhaitez, vous pouvez utiliser le même compte et la même région pour les trois.
Pour commencer à appliquer facilement et rapidement ce modèle de cycle de vie de développement de bout en bout à votre plateforme de données, nous avons préparé le modèle de base aws-glue-cdk-baseline à l'aide du CDK AWS. Le modèle est construit sur AWSCDK v2 ainsi que Conduites CDK. Il fournit deux types de piles :
- Pile d'applications AWS Glue – Cela provisionne le pipeline d'intégration de données : un dans le compte dev et un dans le compte prod
- Pile de pipeline – Cela provisionne le référentiel Git et le pipeline CI/CD dans le compte de pipeline
La pile d'applications AWS Glue provisionne le pipeline d'intégration de données, y compris les ressources suivantes :
- Emplois AWS Glue
- Scripts de travail AWS Glue
Le diagramme suivant illustre cette architecture.
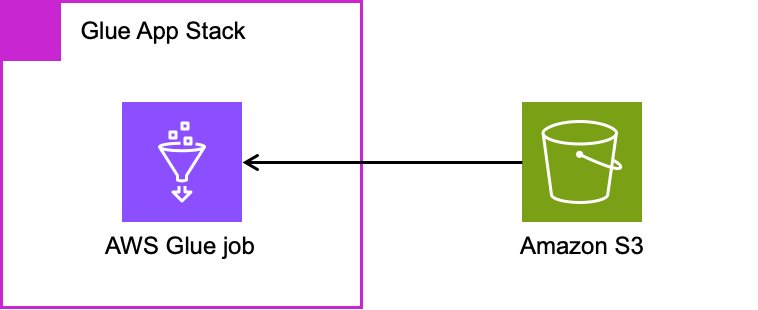
Au moment de la publication de cet article, l'AWS CDK a deux versions du module AWS Glue : @aws-cdk/aws-glue ainsi que @aws-cdk/aws-glue-alphacontenant Constructions L1 ainsi que Constructions L2, respectivement. L'exemple de pile d'applications AWS Glue est défini à l'aide de aws-glue-alpha, la construction L2 pour AWS Glue, car il est simple de définir et de gérer les ressources AWS Glue. Si vous souhaitez utiliser la construction L1, reportez-vous à Créer, tester et déployer des solutions ETL à l'aide des pipelines CI/CD basés sur AWS Glue et AWS CDK.
La pile de pipeline provisionne l'intégralité du pipeline CI/CD, y compris les ressources suivantes :
Le diagramme suivant illustre le workflow du pipeline.
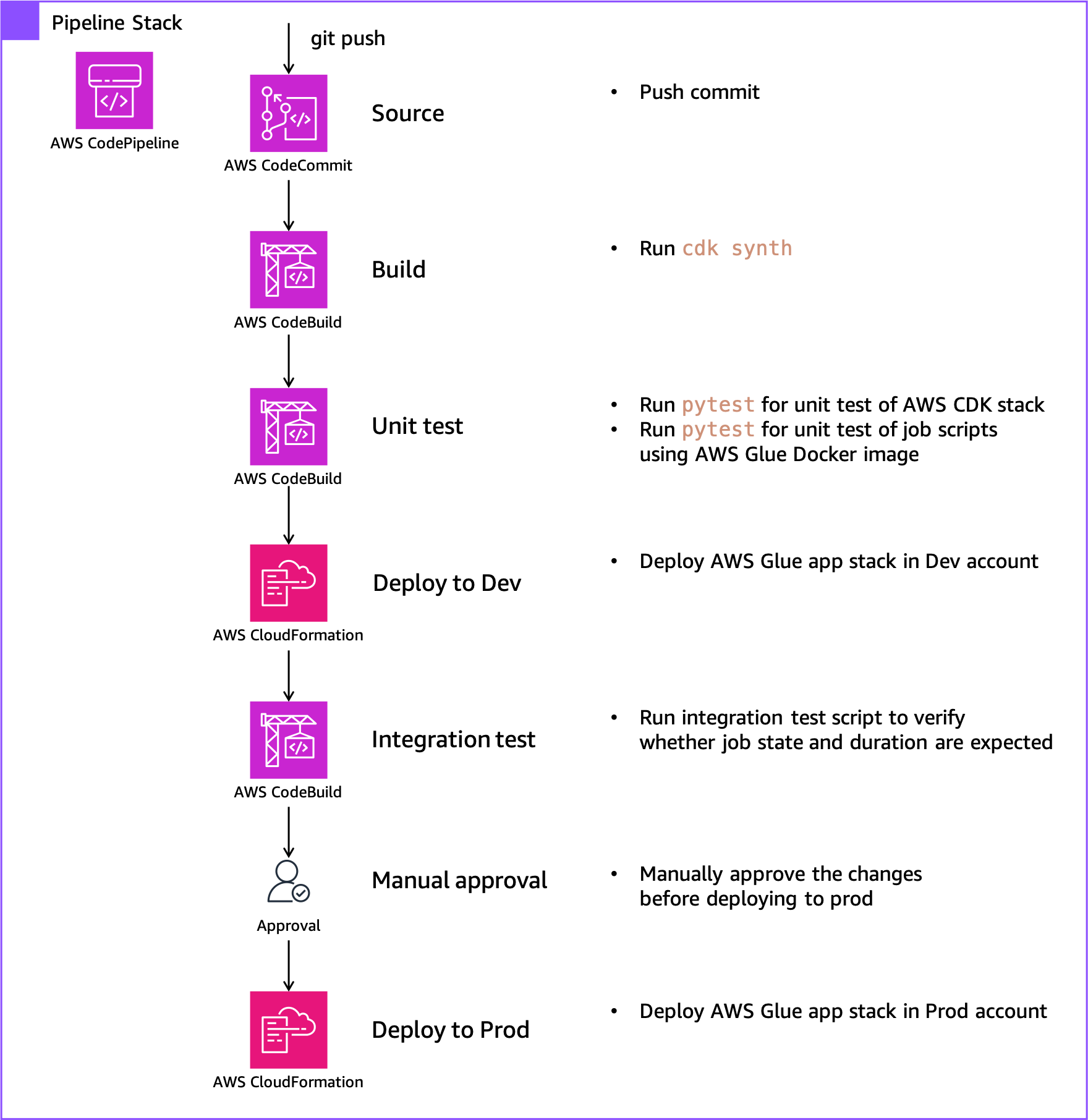
Chaque fois que les besoins de l'entreprise changent (comme l'ajout de sources de données ou la modification de la logique de transformation des données), vous apportez des modifications à la pile d'applications AWS Glue et réapprovisionnez la pile pour refléter vos modifications. Pour ce faire, validez vos modifications dans le modèle AWS CDK dans le référentiel CodeCommit, puis CodePipeline reflète les modifications sur les ressources AWS à l'aide Ensembles de modifications CloudFormation.
Dans les sections suivantes, nous présentons les étapes de configuration de l'environnement requis et démontrons le cycle de développement de bout en bout.
Pré-requis
Vous avez besoin des ressources suivantes :
Initialiser le projet
Pour initialiser le projet, procédez comme suit :
- Cloner le modèle de référence à votre lieu de travail :
- Créer un Python environnement virtuel spécifique au projet sur le poste client :
Nous utilisons un environnement virtuel afin d'isoler l'environnement Python pour ce projet et de ne pas installer le logiciel globalement.
- Activez l'environnement virtuel selon votre OS :
- Sur MacOS et Linux, utilisez la commande suivante :
- Sur une plate-forme Windows, utilisez la commande suivante :
Après cette étape, les étapes suivantes s'exécutent dans les limites de l'environnement virtuel sur la machine cliente et interagissent avec le compte AWS selon les besoins.
- Installez les dépendances requises décrites dans conditions.txt à l'environnement virtuel :
- Modifier le fichier de configuration
default-config.yamlen fonction de vos environnements (remplacez chaque identifiant de compte par le vôtre) : - Courir
pytestpour initialiser les fichiers de test d'instantané en exécutant la commande suivante :
Amorcez vos environnements AWS
Exécutez les commandes suivantes pour amorcer vos environnements AWS :
- Dans le compte de pipeline, remplacez NUMÉRO DE COMPTE-PIPELINE, RÉGIONet PROFIL DE PIPELINE avec vos propres valeurs :
- Dans le compte de développement, remplacez NUMÉRO DE COMPTE-PIPELINE, NUMÉRO DE COMPTE DEV, RÉGIONet DEV-PROFIL avec vos propres valeurs :
- Dans le compte prod, remplacez NUMÉRO DE COMPTE-PIPELINE, NUMÉRO DE COMPTE PROD, RÉGIONet PROD-PROFIL avec vos propres valeurs :
Lorsque vous utilisez un seul compte pour tous les environnements, vous pouvez simplement exécuter le cdk bootstrap commande une fois.
Déployez vos ressources AWS
Exécutez la commande à l'aide du compte de pipeline pour déployer les ressources définies dans le modèle de référence AWS CDK :
Cela crée la pile de pipeline dans le compte de pipeline et la pile d'applications AWS Glue dans le compte de développement.
When the cdk deploy commande est terminée, vérifions le pipeline à l'aide du compte de pipeline.
Dans la console CodePipeline, accédez à GluePipeline. Vérifiez ensuite que GluePipeline comporte les étapes suivantes : Source, Build, UpdatePipeline, Assets, DeployDevet DeployProd. Vérifiez également que les étapes Source, Build, UpdatePipeline, Assets, DeployDev ont réussi, et DeployProd est en attente. Cela peut prendre environ 15 minutes.

Maintenant que le pipeline a été créé avec succès, vous pouvez également vérifier la ressource de pile d'applications AWS Glue sur la console AWS CloudFormation dans le dev compte.
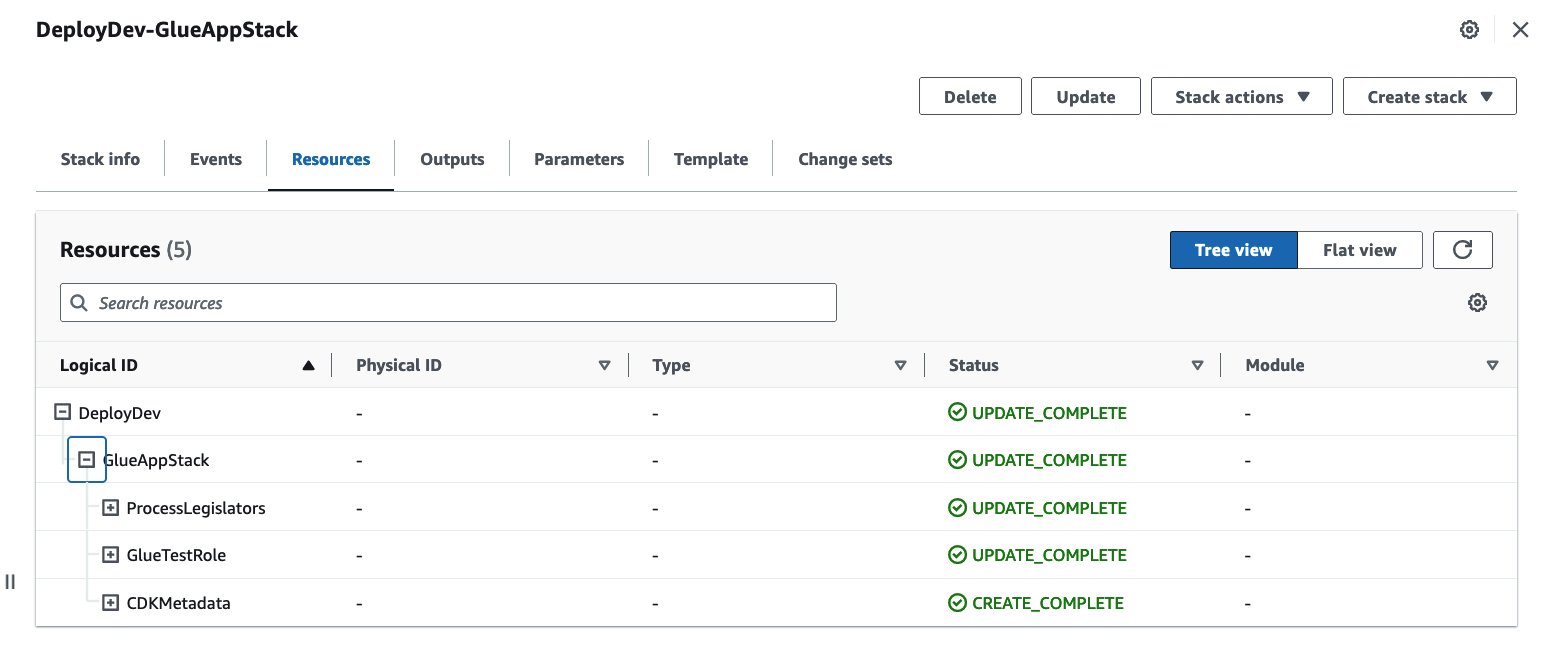
À cette étape, la pile d'applications AWS Glue est déployée uniquement dans le dev compte. Vous pouvez essayer d'exécuter le travail AWS Glue ProcessLegislators pour voir comment ça marche.
Configurez votre référentiel Git avec CodeCommit
Dans une étape précédente, vous avez cloné le référentiel Git à partir de GitHub. Bien qu'il soit possible de configurer le modèle AWS CDK pour qu'il fonctionne avec GitHub, GitHub Enterprise ou Bitbucket, pour cet article, nous utilisons CodeCommit. Si vous préférez ces fournisseurs Git tiers, configurer les connexions et éditer pipeline_stack.py pour définir la variable source pour utiliser le fournisseur Git cible en utilisant CodePipelineSource.
Étant donné que vous avez déjà exécuté la commande cdk deploy, le référentiel CodeCommit a déjà été créé avec tout le code requis et les fichiers associés. La première étape consiste à configurer l'accès à CodeCommit. L'étape suivante consiste à cloner le référentiel du référentiel CodeCommit vers votre local. Exécutez les commandes suivantes :
Dans l'étape suivante, nous apportons des modifications à cette copie locale du référentiel CodeCommit.
Cycle de développement de bout en bout
Maintenant que l'environnement a été créé avec succès, vous êtes prêt à commencer à développer un pipeline d'intégration de données à l'aide de ce modèle de référence. Passons en revue le cycle de développement de bout en bout.
Lorsque vous souhaitez définir votre propre pipeline d'intégration de données, vous devez ajouter d'autres tâches AWS Glue et implémenter des scripts de tâche. Pour cet article, supposons que le cas d'utilisation consiste à ajouter une nouvelle tâche AWS Glue avec un nouveau script de tâche pour lire plusieurs emplacements S3 et les joindre.
Implémenter et tester dans votre environnement local
Tout d'abord, implémentez et testez la tâche AWS Glue et son script de tâche dans votre environnement local à l'aide de Visual Studio Code.
Configurez votre environnement de développement en suivant les étapes de Développer et tester localement les tâches AWS Glue versions 3.0 et 4.0 à l'aide d'un conteneur Docker. Les étapes suivantes sont requises dans le cadre de cet article :
- Démarrez Docker.
- Extrayez l'image Docker qui contient l'environnement de développement local à l'aide de la bibliothèque ETL AWS Glue :
- Exécutez la commande suivante pour définir le nom du profil nommé AWS :
- Exécutez la commande suivante pour la rendre disponible avec le modèle de ligne de base :
- Exécutez le conteneur Docker :
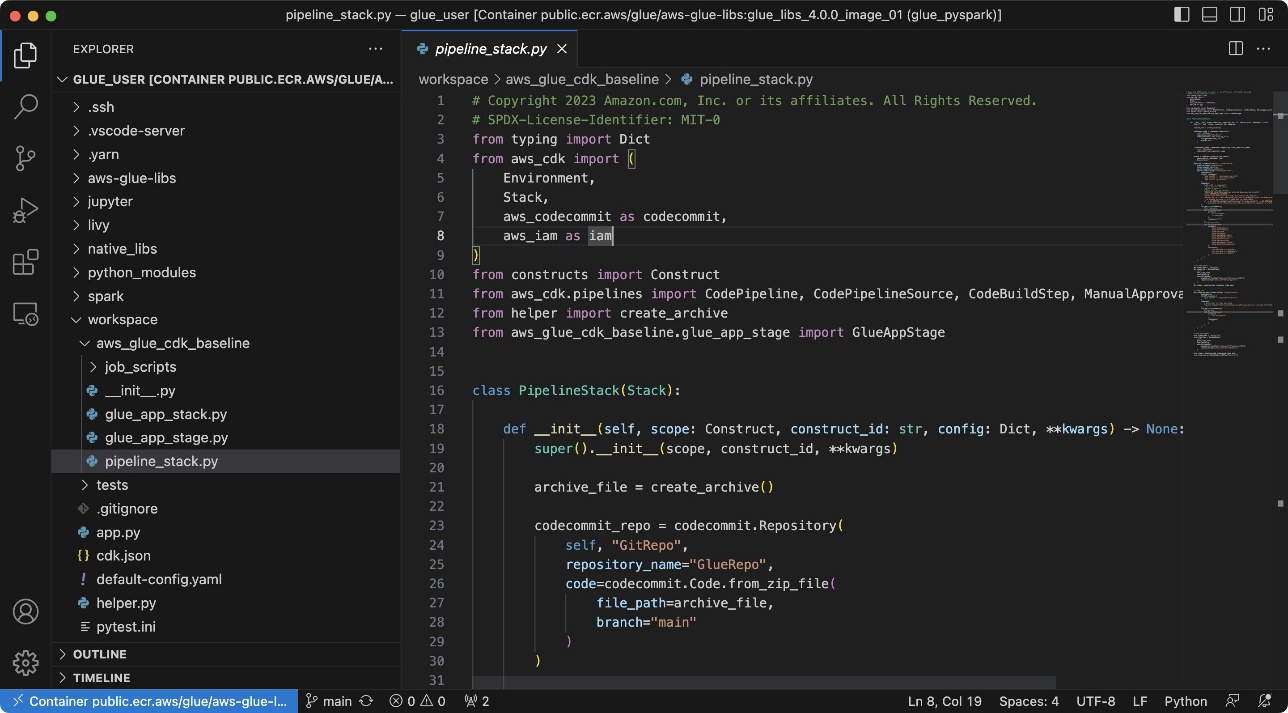
- Démarrez Visual Studio Code.
- Selectionnez Explorateur distant dans le volet de navigation, puis choisissez l'icône de flèche du dossier de l'espace de travail dans le conteneur
public.ecr.aws/glue/aws-glue-libs:glue_libs_4.0.0_image_01.
Si le dossier de l'espace de travail n'est pas affiché, choisissez Dossier ouvert et sélectionnez /home/glue_user/workspace.
Ensuite, vous verrez une vue similaire à la capture d'écran suivante.
En option, vous pouvez installer Kit d'outils AWS pour Visual Studio Codeet commence Chuchoteur de code Amazon pour activer les recommandations de code alimentées par le modèle d'apprentissage automatique. Par exemple, dans aws_glue_cdk_baseline/job_scripts/process_legislators.py, vous pouvez mettre des commentaires comme "# Écrivez un DataFrame au format Parquet sur S3", appuyez sur la touche Entrée, puis CodeWhisperer recommandera un extrait de code similaire à ce qui suit :

Maintenant, vous installez les dépendances requises décrites dans conditions.txt à l'environnement du conteneur.
- Exécutez les commandes suivantes dans le terminal dans Visual Studio Code:
- Implémentez le code.
Apportons maintenant les modifications requises pour une nouvelle tâche AWS Glue ici.
- Modifier le fichier aws_glue_cdk_baseline/glue_app_stack.py. Ajoutons le nouveau bloc de code suivant après la définition de tâche existante de
ProcessLegislatorsafin d'ajouter la nouvelle tâche AWS GlueJoinLegislators:
Ici, vous avez ajouté trois paramètres de travail pour différents emplacements S3 à l'aide de la variable config. C'est le dictionnaire généré à partir de par défaut-config.yaml. Dans ce modèle de ligne de base, nous utilisons ce fichier de configuration central pour gérer les paramètres de tous les travaux Glue dans la structure <stage name>/jobs/<job name>/<parameter name>. Dans les étapes suivantes, vous fournissez ces emplacements via les paramètres de tâche AWS Glue.
- Créez un nouveau script de travail appelé
aws_glue_cdk_baseline/job_scripts/join_legislators.py: - Créez un nouveau script de test unitaire pour la nouvelle tâche AWS Glue appelée
aws_glue_cdk_baseline/job_scripts/tests/test_join_legislators.py: - In par défaut-config.yaml, ajoutez ce qui suit sous
prodainsi quedev: - Ajoutez ce qui suit sous
"jobs"dans la variableconfigin tests/unité/test_glue_app_stack.py, tests/unité/test_pipeline_stack.pyet tests/instantané/test_snapshot_glue_app_stack.py (pas besoin de remplacer les emplacements S3): - Selectionnez Courir en haut à droite pour exécuter les scripts de travail individuels.

Si la Courir bouton n'est pas affiché, installez Python dans le conteneur via Extensions dans le volet de navigation.
- Pour les tests unitaires locaux, exécutez la commande suivante dans le terminal dans Visual Studio Code:
Ensuite, vous pouvez vérifier que le test unitaire nouvellement ajouté a réussi.
- Courir
pytestpour initialiser les fichiers de test d'instantané en exécutant la commande suivante :
Déployer dans l'environnement de développement
Effectuez les étapes suivantes pour déployer la pile d'applications AWS Glue dans l'environnement de développement et y exécuter des tests d'intégration :
- Configurer l'accès à CodeCommit.
- Validez et envoyez vos modifications au référentiel CodeCommit :
Vous pouvez voir que le pipeline est déclenché avec succès.
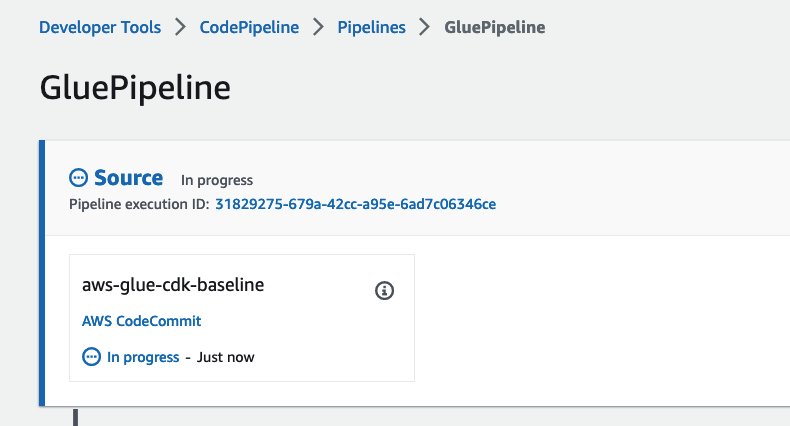
Test d'intégration
Rien n'est requis pour exécuter le test d'intégration pour la tâche AWS Glue nouvellement ajoutée. Le script de test d'intégration integ_test_glue_app_stack.py exécute tous les travaux incluant une balise spécifique, puis vérifie l'état et sa durée. Si vous souhaitez modifier la condition ou le seuil, vous pouvez modifier les assertions à la fin de la méthode integ_test_glue_job.
Déployer dans l'environnement de production
Effectuez les étapes suivantes pour déployer la pile d'applications AWS Glue dans l'environnement de production :
- Dans la console CodePipeline, accédez à
GluePipeline. - Selectionnez Avis sous le
DeployProdétape. - Selectionnez Approuver.
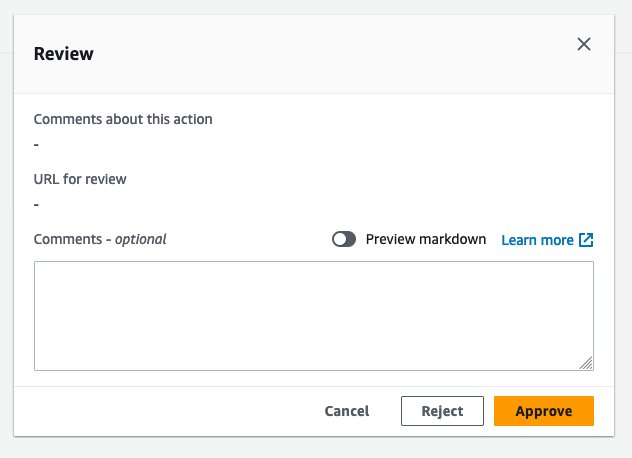
Attends le DeployProd à terminer, vous pouvez vérifier la ressource de pile d'applications AWS Glue dans le compte dev.
Nettoyer
Pour nettoyer vos ressources, procédez comme suit :
- Exécutez la commande suivante à l'aide du compte de pipeline :
- Supprimez la pile d'applications AWS Glue dans le compte de développement et le compte de production.
Conclusion
Dans cet article, vous avez appris à définir le cycle de vie de développement pour l'intégration de données et comment les ingénieurs logiciels et les ingénieurs de données peuvent concevoir un cycle de vie de développement de bout en bout à l'aide d'AWS Glue, y compris le développement, les tests et la CI/CD, via un exemple AWS Modèle CDK. Vous pouvez commencer à créer votre propre cycle de vie de développement de bout en bout pour votre charge de travail à l'aide d'AWS Glue.
A propos de l'auteure
 Noritaka Sekiyama est architecte Big Data principal au sein de l'équipe AWS Glue. Il travaille à Tokyo, au Japon. Il est responsable de la création d'artefacts logiciels pour aider les clients. Dans ses temps libres, il aime faire du vélo avec son vélo de route.
Noritaka Sekiyama est architecte Big Data principal au sein de l'équipe AWS Glue. Il travaille à Tokyo, au Japon. Il est responsable de la création d'artefacts logiciels pour aider les clients. Dans ses temps libres, il aime faire du vélo avec son vélo de route.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/end-to-end-development-lifecycle-for-data-engineers-to-build-a-data-integration-pipeline-using-aws-glue/

