Client 360 (C360) fournit une vue complète et unifiée des interactions et du comportement d'un client sur tous les points de contact et canaux. Cette vue est utilisée pour identifier des modèles et des tendances dans le comportement des clients, qui peuvent éclairer les décisions basées sur les données afin d'améliorer les résultats commerciaux. Par exemple, vous pouvez utiliser C360 pour segmenter et créer des campagnes marketing plus susceptibles de toucher des groupes spécifiques de clients.
En 2022, AWS a commandé une étude menée par l'American Productivity and Quality Center (APQC) pour quantifier les Valeur commerciale de Customer 360. La figure suivante montre certaines des mesures dérivées de l’étude. Les organisations utilisant C360 ont obtenu une réduction de 43.9 % de la durée du cycle de vente, une augmentation de 22.8 % de la valeur à vie du client, une mise sur le marché 25.3 % plus rapide et une amélioration de 19.1 % du score net du promoteur (NPS).

Sans C360, les entreprises sont confrontées à des opportunités manquées, à des rapports inexacts et à des expériences client décousues, ce qui entraîne une perte de clientèle. Cependant, créer une solution C360 peut s’avérer compliqué. UN Enquête marketing Gartner ont constaté que seulement 14 % des organisations ont mis en œuvre avec succès une solution C360, en raison du manque de consensus sur ce que signifie une vue à 360 degrés, des défis liés à la qualité des données et du manque de structure de gouvernance interfonctionnelle pour les données clients.
Dans cet article, nous expliquons comment vous pouvez utiliser des services AWS spécialement conçus pour créer une stratégie de données de bout en bout pour C360 afin d'unifier et de gouverner les données client qui répondent à ces défis. Nous le structurons autour de cinq piliers qui alimentent C360 : collecte de données, unification, analyse, activation et gouvernance des données, ainsi qu'une architecture de solution que vous pouvez utiliser pour votre mise en œuvre.
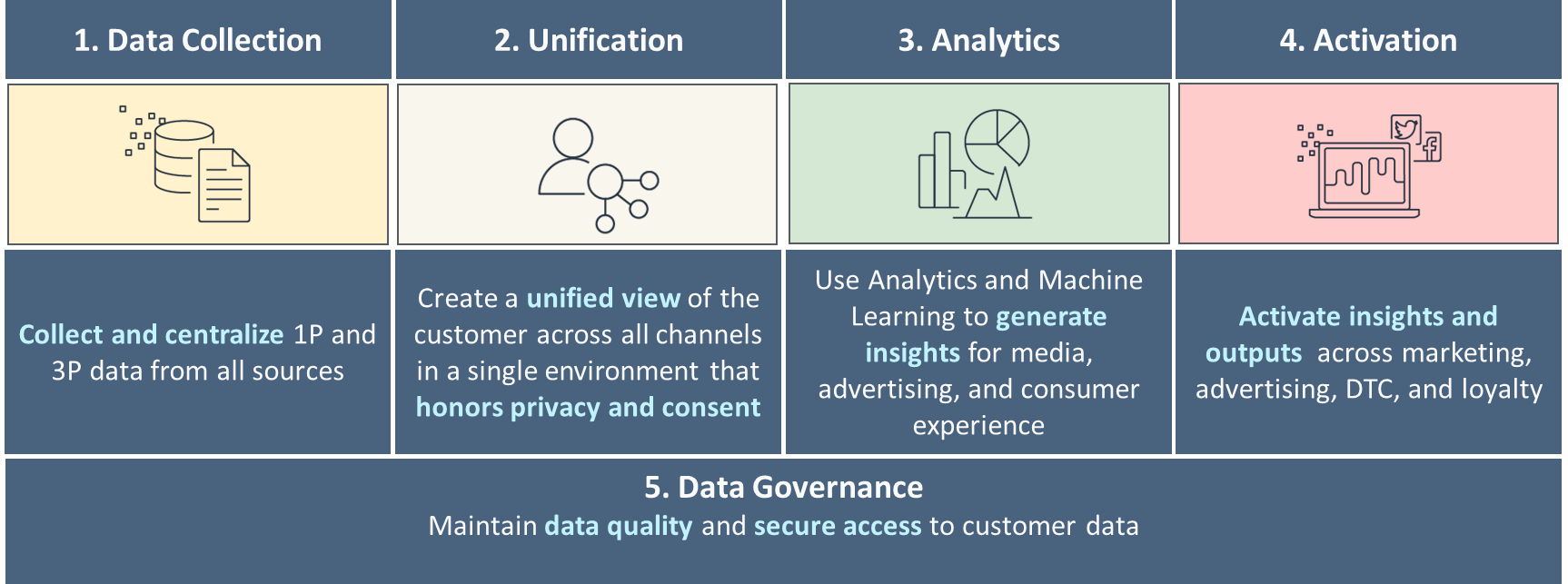
Les cinq piliers d'un C360 mature
Lorsque vous vous lancez dans la création d'un C360, vous travaillez avec plusieurs cas d'utilisation, types de données client, ainsi que des utilisateurs et applications qui nécessitent différents outils. Construire un C360 sur les bons ensembles de données, ajouter de nouveaux ensembles de données au fil du temps tout en maintenant la qualité des données et en les gardant sécurisées nécessite une stratégie de données de bout en bout pour vos données clients. Vous devez également fournir des outils qui permettent à vos équipes de créer facilement des produits qui font évoluer votre C360.
Nous vous recommandons de construire votre stratégie de données autour de cinq piliers de C360, comme le montre la figure suivante. Cela commence par la collecte de données de base, unifiant et reliant les données provenant de divers canaux liés à des clients uniques, et progresse vers des analyses de base à avancées pour la prise de décision et un engagement personnalisé via divers canaux. Au fur et à mesure que vous mûrissez dans chacun de ces piliers, vous progressez vers la réponse aux signaux clients en temps réel.
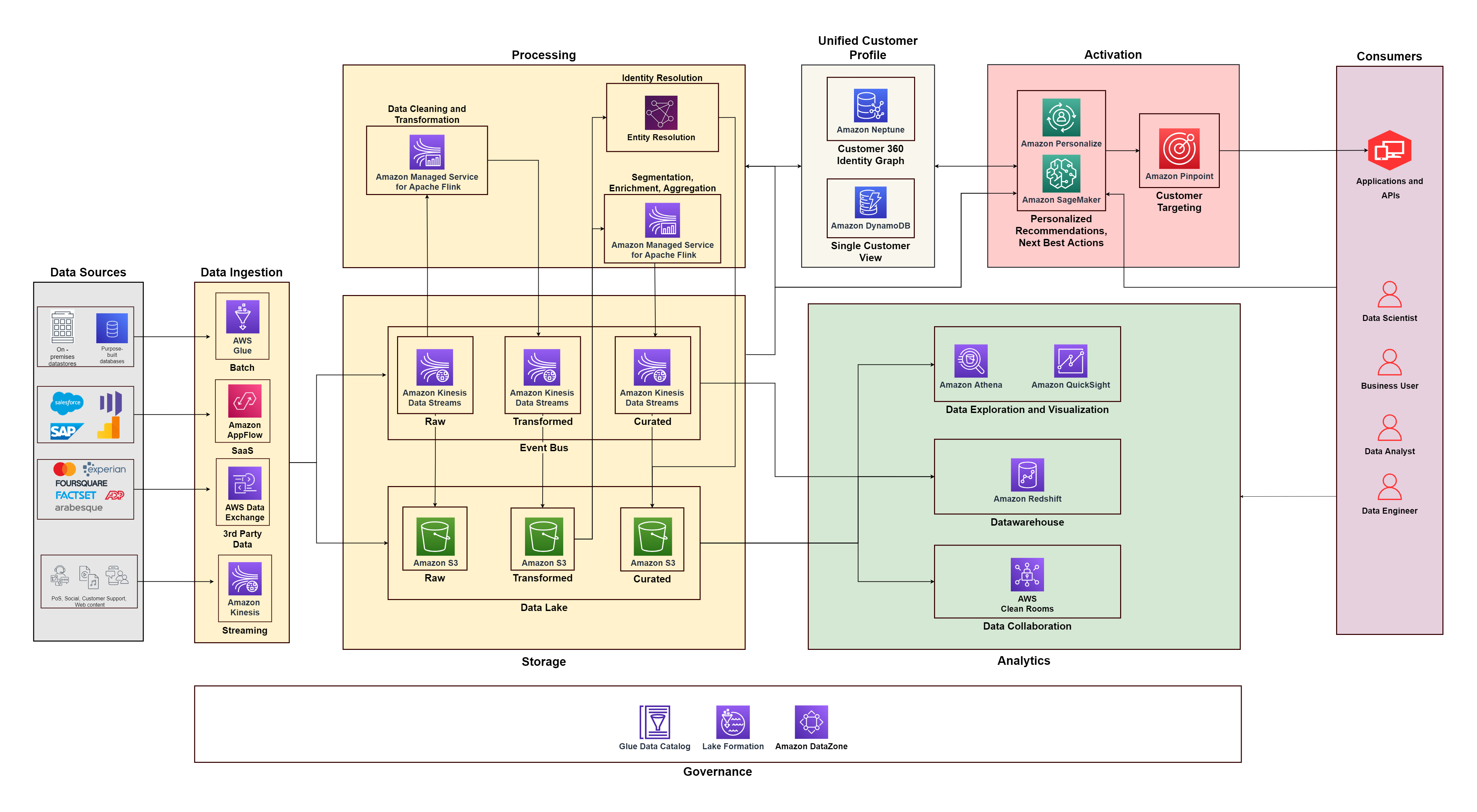
Le diagramme suivant illustre l'architecture fonctionnelle qui combine les éléments constitutifs d'un Plateforme de données client sur AWS avec des composants supplémentaires utilisés pour concevoir une solution C360 de bout en bout. Ceci est aligné sur les cinq piliers dont nous discutons dans cet article.
Pilier 1 : Collecte de données
Lorsque vous commencez à créer votre plate-forme de données clients, vous devez collecter des données à partir de divers systèmes et points de contact, tels que vos systèmes de vente, votre support client, le Web et les réseaux sociaux, ainsi que les marchés de données. Considérez le pilier de la collecte de données comme une combinaison de capacités d'ingestion, de stockage et de traitement.
Ingestion de données
Vous devez créer des pipelines d'ingestion en fonction de facteurs tels que les types de sources de données (magasins de données sur site, fichiers, applications SaaS, données tierces) et le flux de données (flux illimités ou données par lots). AWS fournit différents services pour créer des pipelines d'ingestion de données :
- Colle AWS est un service d'intégration de données sans serveur qui ingère des données par lots à partir de bases de données sur site et de magasins de données dans le cloud. Il se connecte à plus de 70 sources de données et vous aide à créer des pipelines d'extraction, de transformation et de chargement (ETL) sans avoir à gérer l'infrastructure des pipelines. Qualité des données AWS Glue vérifie et alerte sur les données médiocres, ce qui facilite la détection et la résolution des problèmes avant qu'ils ne nuisent à votre entreprise.
- Flux d'application Amazon ingère des données provenant d'applications SaaS (Software as a Service) telles que Google Analytics, Salesforce, SAP et Marketo, vous offrant ainsi la flexibilité d'ingérer des données de plus de 50 applications SaaS.
- Échange de données AWS facilite la recherche, l'abonnement et l'utilisation de données tierces à des fins d'analyse. Vous pouvez vous abonner à des produits de données qui contribuent à enrichir les profils clients, par exemple des données démographiques, des données publicitaires et des données sur les marchés financiers.
- Amazon Kinésis ingère les événements en streaming en temps réel à partir des systèmes de point de vente, les données de parcours des applications mobiles et des sites Web, ainsi que les données des réseaux sociaux. Vous pouvez également envisager d'utiliser Amazon Managed Streaming pour Apache Kafka (Amazon MSK) pour diffuser des événements en temps réel.
Le diagramme suivant illustre les différents pipelines permettant d'ingérer des données provenant de divers systèmes sources à l'aide des services AWS.
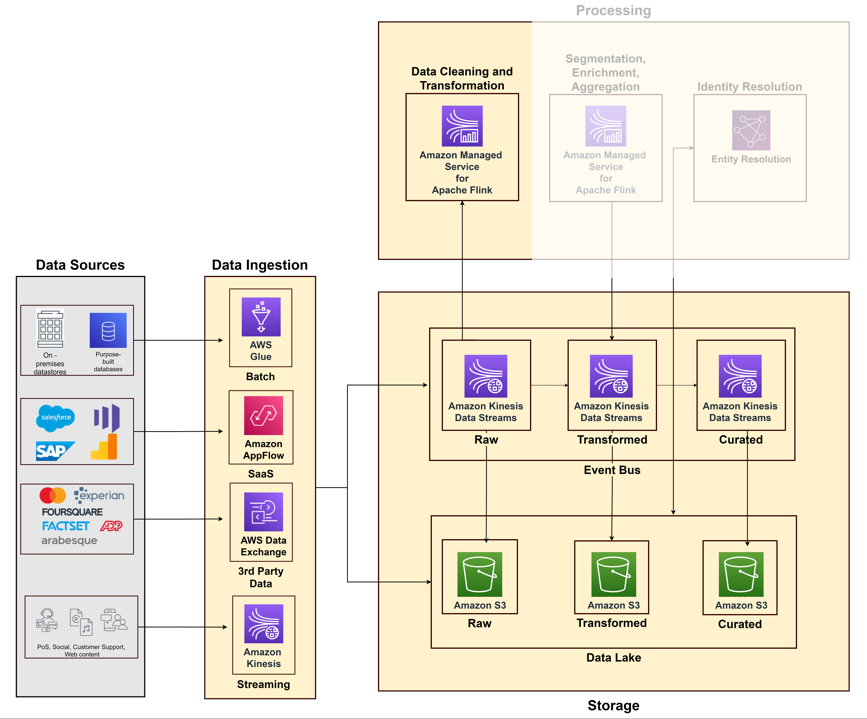
Stockage de données
Les données par lots structurées, semi-structurées ou non structurées sont stockées dans un stockage objet car elles sont rentables et durables. Service de stockage simple Amazon (Amazon S3) est un service de stockage géré doté de fonctionnalités d'archivage permettant de stocker des pétaoctets de données avec onze 9 de durabilité. Les données en streaming avec de faibles besoins de latence sont stockées dans Flux de données Amazon Kinesis pour une consommation en temps réel. Cela permet des analyses et des actions immédiates pour divers consommateurs en aval, comme le montre la plateforme centrale de Riot Games. Bus d'événement anti-émeute.
Traitement de l'information
Les données brutes sont souvent encombrées de doublons et de formats irréguliers. Vous devez traiter cela pour le préparer à l'analyse. Si vous consommez des données par lots et des données en streaming, envisagez d'utiliser un framework capable de gérer les deux. Un modèle tel que le Architecture Kappa considère tout comme un flux, simplifiant ainsi les pipelines de traitement. Pensez à utiliser Service géré Amazon pour Apache Flink pour gérer le travail de traitement. Avec Managed Service pour Apache Flink, vous pouvez nettoyer et transformer les données en streaming et les diriger vers la destination appropriée en fonction des exigences de latence. Vous pouvez également implémenter le traitement des données par lots en utilisant Amazon DME sur des frameworks open source tels qu'Apache Spark avec des performances 3.5 fois supérieures que la version autogérée. La décision d'architecture d'utiliser un système de traitement par lots ou en streaming dépendra de divers facteurs ; cependant, si vous souhaitez activer l'analyse en temps réel de vos données clients, nous vous recommandons d'utiliser un modèle d'architecture Kappa.
Pilier 2 : Unification
Pour relier les diverses données provenant de différents points de contact à un client unique, vous devez créer une solution de traitement d'identité qui identifie les connexions anonymes, stocke les informations utiles sur les clients, les relie à des données externes pour de meilleures informations et regroupe les clients dans des domaines d'intérêt. Bien que la solution de traitement des identités aide à créer un profil client unifié, nous vous recommandons de considérer cela comme faisant partie de vos capacités de traitement des données. Le diagramme suivant illustre les composants d’une telle solution.
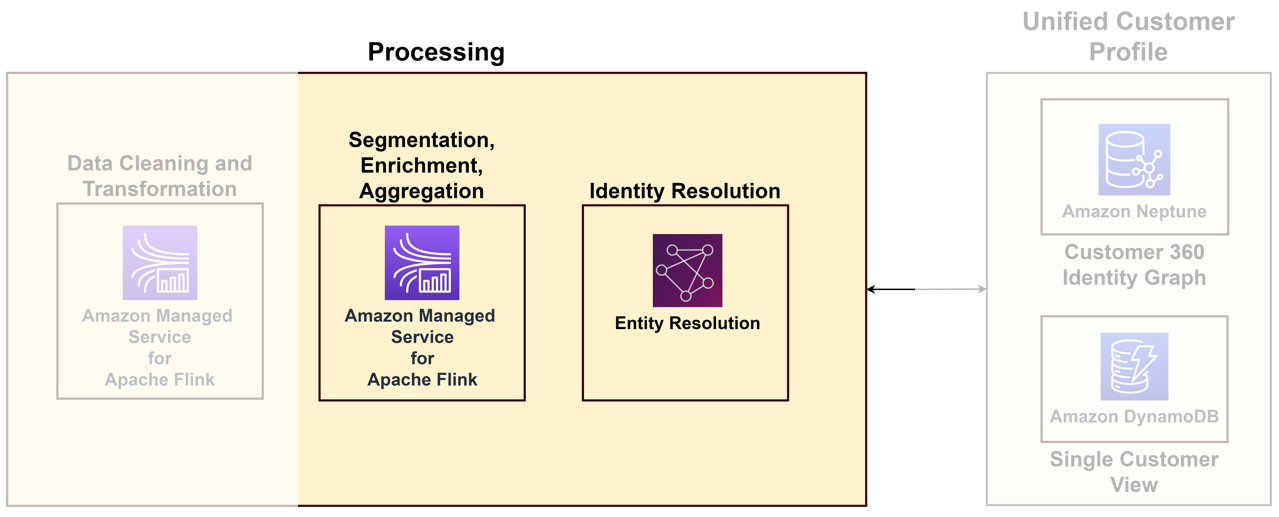
Les composants clés sont les suivants :
- Résolution d'identité – La résolution d'identité est une solution de déduplication, dans laquelle les enregistrements sont mis en correspondance pour identifier un client et des prospects uniques en reliant plusieurs identifiants tels que les cookies, les identifiants d'appareil, les adresses IP, les identifiants de messagerie et les identifiants internes de l'entreprise à une personne connue ou à un profil anonyme en utilisant la confidentialité. méthodes conformes. Ceci peut être réalisé en utilisant Résolution d'entité AWS, qui permet d'utiliser des règles et des techniques d'apprentissage automatique (ML) pour faire correspondre les enregistrements et résoudre les identités. Alternativement, vous pouvez construire des graphiques d'identité en utilisant Amazone Neptune pour une vue unique et unifiée de vos clients.
- Agrégation de profils – Lorsque vous avez identifié un client de manière unique, vous pouvez créer des applications dans Managed Service pour Apache Flink pour consolider toutes leurs métadonnées, du nom à l’historique des interactions. Ensuite, vous transformez ces données dans un format concis. Au lieu d'afficher chaque détail de transaction, vous pouvez proposer une valeur de dépense agrégée et un lien vers leur enregistrement de gestion de la relation client (CRM). Pour les interactions avec le service client, fournissez un score CSAT moyen et un lien vers le système du centre d'appels pour une analyse plus approfondie de leur historique de communication.
- Enrichissement du profil – Après avoir attribué à un client une identité unique, améliorez son profil à l’aide de diverses sources de données. L'enrichissement implique généralement l'ajout de données démographiques, comportementales et de géolocalisation. Vous pouvez utiliser produits de données tiers d'AWS Marketplace fournis via AWS Data Exchange pour obtenir des informations sur les revenus, les habitudes de consommation, les scores de risque de crédit et bien d’autres dimensions pour affiner davantage l’expérience client.
- Segmentation des clients – Après avoir identifié et enrichi de manière unique le profil d'un client, vous pouvez le segmenter en fonction de données démographiques telles que l'âge, les dépenses, les revenus et l'emplacement à l'aide des applications du service géré pour Apache Flink. Au fur et à mesure que vous avancez, vous pouvez intégrer Services d'IA pour des techniques de ciblage plus précises.
Après avoir effectué le traitement de l'identité et la segmentation, vous avez besoin d'une capacité de stockage pour stocker le profil client unique et fournir des fonctionnalités de recherche et d'interrogation en plus pour que les consommateurs en aval puissent utiliser les données client enrichies.
Le diagramme suivant illustre le pilier d'unification pour un profil client unifié et une vue unique du client pour les applications en aval.
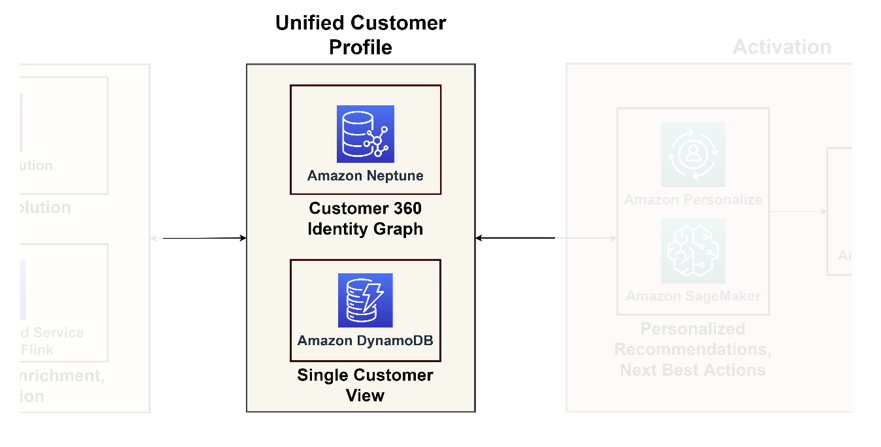
Profil client unifié
Les bases de données graphiques excellent dans la modélisation des interactions et des relations clients, offrant une vue complète du parcours client. Si vous traitez des milliards de profils et d'interactions, vous pouvez envisager d'utiliser Neptune, un service de base de données graphique gérée sur AWS. Des organisations telles que Zeta ainsi que Activision ont utilisé avec succès Neptune pour stocker et interroger des milliards d'identifiants uniques par mois et des millions de requêtes par seconde avec un temps de réponse d'une milliseconde.
Vue client unique
Bien que les bases de données graphiques fournissent des informations approfondies, elles peuvent néanmoins s’avérer complexes pour les applications classiques. Il est prudent de consolider ces données dans une vue client unique, servant de référence principale pour les applications en aval, allant des plateformes de commerce électronique aux systèmes CRM. Cette vue consolidée fait office de liaison entre la plateforme de données et les applications centrées sur le client. À ces fins, nous vous recommandons d'utiliser Amazon DynamoDB pour son adaptabilité, son évolutivité et ses performances, résultant en une base de données clients à jour et efficace. Cette base de données acceptera de nombreuses requêtes d'écriture provenant des systèmes d'activation qui apprendront de nouvelles informations sur les clients et les renverront.
Pilier 3 : Analyse
Le pilier analytique définit les fonctionnalités qui vous aident à générer des informations en plus de vos données clients. Votre stratégie d'analyse s'applique aux besoins organisationnels plus larges, et pas seulement à C360. Vous pouvez utiliser les mêmes fonctionnalités pour diffuser des rapports financiers, mesurer les performances opérationnelles ou même monétiser les actifs de données. Élaborez des stratégies en fonction de la manière dont vos équipes explorent les données, exécutent des analyses, traitent les données pour répondre aux exigences en aval et visualisent les données à différents niveaux. Planifiez comment vous pouvez permettre à vos équipes d'utiliser le ML pour passer de l'analyse descriptive à l'analyse prescriptive.
La Architecture de données moderne AWS montre un moyen de créer une plate-forme de données spécialement conçue, sécurisée et évolutive dans le cloud. Apprenez-en pour développer des capacités d'interrogation dans votre lac de données et votre entrepôt de données.
Le diagramme suivant décompose la capacité d'analyse en exploration de données, visualisation, entreposage de données et collaboration de données. Découvrons quel rôle joue chacun de ces composants dans le contexte de C360.

Exploration de données
L'exploration des données permet de découvrir des incohérences, des valeurs aberrantes ou des erreurs. En les repérant dès le début, vos équipes peuvent bénéficier d'une intégration plus claire des données pour C360, ce qui conduit à des analyses et des prédictions plus précises. Tenez compte des personnages qui explorent les données, de leurs compétences techniques et du temps nécessaire pour obtenir un aperçu. Par exemple, les analystes de données qui savent écrire du SQL peuvent directement interroger les données résidant dans Amazon S3 à l'aide de Amazone Athéna. Les utilisateurs intéressés par l'exploration visuelle peuvent le faire en utilisant Brassage de données AWS Glue. Les data scientists ou les ingénieurs peuvent utiliser Amazon EMRStudio or Amazon SageMakerStudio pour explorer les données du notebook et pour une expérience low-code, vous pouvez utiliser Gestionnaire de données Amazon SageMaker. Étant donné que ces services interrogent directement les compartiments S3, vous pouvez explorer les données au fur et à mesure qu'elles atterrissent dans le lac de données, réduisant ainsi le temps d'obtention d'informations.
Visualisation
La transformation d'ensembles de données complexes en visuels intuitifs révèle les modèles cachés dans les données et est cruciale pour les cas d'utilisation de C360. Grâce à cette fonctionnalité, vous pouvez concevoir des rapports pour différents niveaux répondant à différents besoins : des rapports exécutifs offrant des aperçus stratégiques, des rapports de gestion mettant en évidence les mesures opérationnelles et des rapports détaillés plongeant dans les détails. Une telle clarté visuelle aide votre organisation à prendre des décisions éclairées à tous les niveaux, en centralisant le point de vue du client.
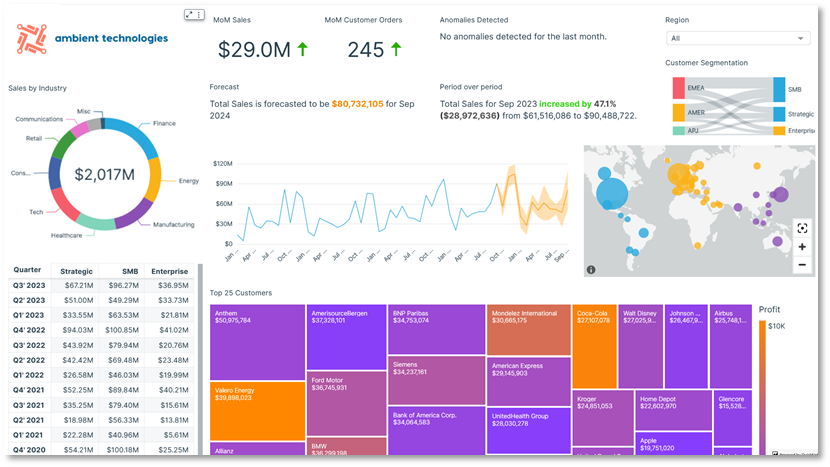
Le diagramme suivant montre un exemple de tableau de bord C360 construit sur Amazon QuickSight. QuickSight offre des fonctionnalités de visualisation évolutives et sans serveur. Vous pouvez bénéficier de ses intégrations ML pour des informations automatisées telles que les prévisions et la détection d'anomalies ou les requêtes en langage naturel avec Amazon Q dans QuickSight, connectivité directe des données provenant de diverses sources, et tarification à la séance. Avec QuickSight, vous pouvez intégrer des tableaux de bord à des sites Web et à des applications externes, et le SPICE Le moteur permet une visualisation rapide et interactive des données à grande échelle. La capture d'écran suivante montre un exemple de tableau de bord C360 construit sur QuickSight.
Entrepôt de données
Les entrepôts de données sont efficaces pour consolider les données structurées provenant de sources multiples et répondre aux requêtes analytiques d'un grand nombre d'utilisateurs simultanés. Les entrepôts de données peuvent fournir une vue unifiée et cohérente d'une grande quantité de données client pour les cas d'utilisation de C360. Redshift d'Amazon répond à ce besoin en gérant efficacement de gros volumes de données et des charges de travail diverses. Il offre une forte cohérence entre les ensembles de données, permettant aux organisations d'obtenir des informations fiables et complètes sur leurs clients, ce qui est essentiel pour une prise de décision éclairée. Amazon Redshift offre des informations en temps réel et des capacités d'analyse prédictive pour analyser des données allant de téraoctets à pétaoctets. Avec Amazon Redshift ML, vous pouvez intégrer du ML au-dessus des données stockées dans l'entrepôt de données avec une surcharge de développement minimale. Amazon Redshift sans serveur simplifie la création d'applications et permet aux entreprises d'intégrer facilement de riches capacités d'analyse de données.
Collaboration de données
Vous pouvez en toute sécurité collaborer et analyser des ensembles de données collectifs de vos partenaires sans partager ni copier les données sous-jacentes les uns des autres en utilisant Salles blanches AWS. Vous pouvez rassembler des données disparates provenant de différents canaux d'engagement et ensembles de données de partenaires pour former une vue à 360 degrés de vos clients. AWS Clean Rooms peut améliorer C360 en permettant des cas d'utilisation tels que l'optimisation du marketing multicanal, la segmentation avancée des clients et la personnalisation respectueuse de la confidentialité. En fusionnant en toute sécurité des ensembles de données, il offre des informations plus riches et une confidentialité des données robuste, répondant aux besoins commerciaux et aux normes réglementaires.
Pilier 4 : Activation
La valeur des données diminue à mesure qu’elles vieillissent, ce qui entraîne des coûts d’opportunité plus élevés au fil du temps. Dans une enquête réalisé par Intersystems, 75 % des organisations interrogées estiment que les données intempestives nuisent aux opportunités commerciales. Dans une autre enquête, 58% d'organisations (sur 560 répondants du conseil consultatif et des lecteurs de HBR) ont déclaré avoir constaté une augmentation de la fidélisation et de la fidélisation des clients grâce à l'analyse client en temps réel.
Vous pouvez atteindre une maturité dans C360 lorsque vous développez la capacité d’agir en temps réel sur toutes les informations acquises à partir des piliers précédents dont nous avons discuté. Par exemple, à ce niveau de maturité, vous pouvez agir sur le sentiment des clients en fonction du contexte que vous avez automatiquement dérivé avec un profil client enrichi et des canaux intégrés. Pour cela, vous devez mettre en œuvre une prise de décision normative sur la manière de répondre au sentiment du client. Pour ce faire à grande échelle, vous devez utiliser les services AI/ML pour la prise de décision. Le diagramme suivant illustre l'architecture permettant d'activer les informations à l'aide du ML pour l'analyse prescriptive et des services d'IA pour le ciblage et la segmentation.
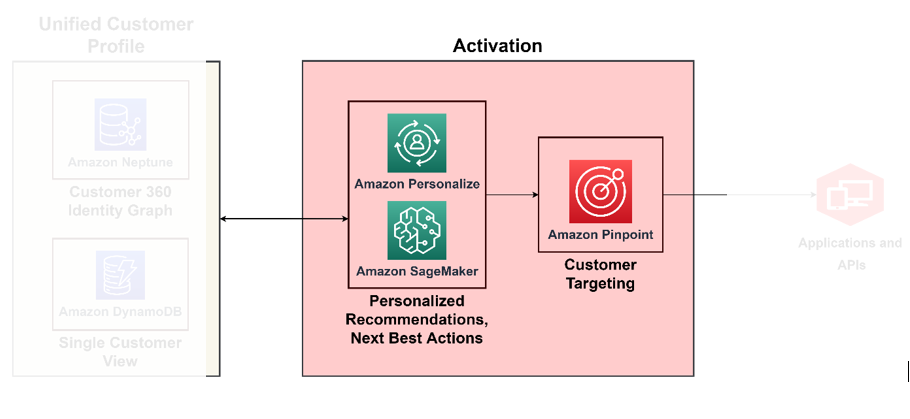
Utiliser le ML pour le moteur de prise de décision
Avec le ML, vous pouvez améliorer l'expérience client globale : vous pouvez créer des modèles de comportement client prédictifs, concevoir des offres hyper-personnalisées et cibler le bon client avec la bonne incitation. Vous pouvez les construire en utilisant Amazon Sage Maker, qui propose une suite de services gérés adaptés au cycle de vie de la science des données, notamment la gestion des données, la formation de modèles, l'hébergement de modèles, l'inférence de modèle, la détection de dérive de modèle et le stockage de fonctionnalités. SageMaker vous permet de construire et opérationnaliser vos modèles ML, en les réinjectant dans vos applications pour produire les bonnes informations à la bonne personne, au bon moment.
Amazon Personnaliser prend en charge les recommandations contextuelles, grâce auxquelles vous pouvez améliorer la pertinence des recommandations en les générant dans un contexte (par exemple, le type d'appareil, l'emplacement ou l'heure de la journée). Votre équipe peut démarrer sans aucune expérience préalable en ML en utilisant des API pour créer des capacités de personnalisation sophistiquées en quelques clics. Pour plus d'informations, voir Personnalisez vos recommandations en faisant la promotion d'articles spécifiques à l'aide de règles commerciales avec Amazon Personalize.
Activez les canaux de marketing, de publicité, de vente directe au consommateur et de fidélisation
Maintenant que vous savez qui sont vos clients et à qui vous adresser, vous pouvez créer des solutions pour mener des campagnes de ciblage à grande échelle. Avec Amazon Pinpoint, vous pouvez personnaliser et segmenter les communications pour engager les clients sur plusieurs canaux. Par exemple, vous pouvez utiliser Amazon Pinpoint pour créer des expériences client engageantes via divers canaux de communication tels que les e-mails, les SMS, les notifications push et les notifications intégrées à l'application.
Pilier 5 : Gouvernance des données
L’établissement d’une bonne gouvernance qui équilibre le contrôle et l’accès donne aux utilisateurs confiance dans les données. Imaginez proposer des promotions sur des produits dont un client n'a pas besoin, ou bombarder les mauvais clients de notifications. Une mauvaise qualité des données peut conduire à de telles situations et finalement entraîner une perte de clientèle. Vous devez créer des processus qui valident la qualité des données et prendre des mesures correctives. Qualité des données AWS Glue peut vous aider à créer des solutions qui valident la qualité des données au repos et en transit, sur la base de règles prédéfinies.
Pour mettre en place une structure de gouvernance interfonctionnelle pour les données clients, vous avez besoin d'une capacité de gouvernance et de partage des données au sein de votre organisation. Avec Zone de données Amazon, les administrateurs et les gestionnaires de données peuvent gérer et gouverner l'accès aux données, et les consommateurs tels que les ingénieurs de données, les scientifiques de données, les chefs de produit, les analystes et d'autres utilisateurs professionnels peuvent découvrir, utiliser et collaborer avec ces données pour générer des informations. Il rationalise l'accès aux données, vous permettant de rechercher et d'utiliser les données client, favorise la collaboration en équipe avec des ressources de données partagées et fournit des analyses personnalisées via une application Web ou une API sur un portail. Formation AWS Lake veille à ce que l'accès aux données soit sécurisé, garantissant que les bonnes personnes voient les bonnes données pour les bonnes raisons, ce qui est crucial pour une gouvernance interfonctionnelle efficace dans toute organisation. Les métadonnées commerciales sont stockées et gérées par Amazon DataZone, qui s'appuie sur des métadonnées techniques et des informations de schéma, enregistrées dans le Catalogue de données AWS Glue. Ces métadonnées techniques sont également utilisées à la fois par d'autres services de gouvernance tels que Lake Formation et Amazon DataZone, ainsi que par des services d'analyse tels qu'Amazon Redshift, Athena et AWS Glue.

Tout mettre ensemble
En utilisant le diagramme suivant comme référence, vous pouvez créer des projets et des équipes pour créer et exploiter différentes fonctionnalités. Par exemple, vous pouvez demander à une équipe d'intégration de données de se concentrer sur le pilier de la collecte de données. Vous pouvez ensuite aligner les rôles fonctionnels, tels que les architectes de données et les ingénieurs de données. Vous pouvez développer vos pratiques d’analyse et de science des données pour vous concentrer respectivement sur les piliers de l’analyse et de l’activation. Vous pouvez ensuite créer une équipe spécialisée pour le traitement de l’identité des clients et pour créer une vue unifiée du client. Vous pouvez créer une équipe de gouvernance des données avec des gestionnaires de données issus de différentes fonctions, des administrateurs de sécurité et des décideurs politiques en matière de gouvernance des données pour concevoir et automatiser des politiques.
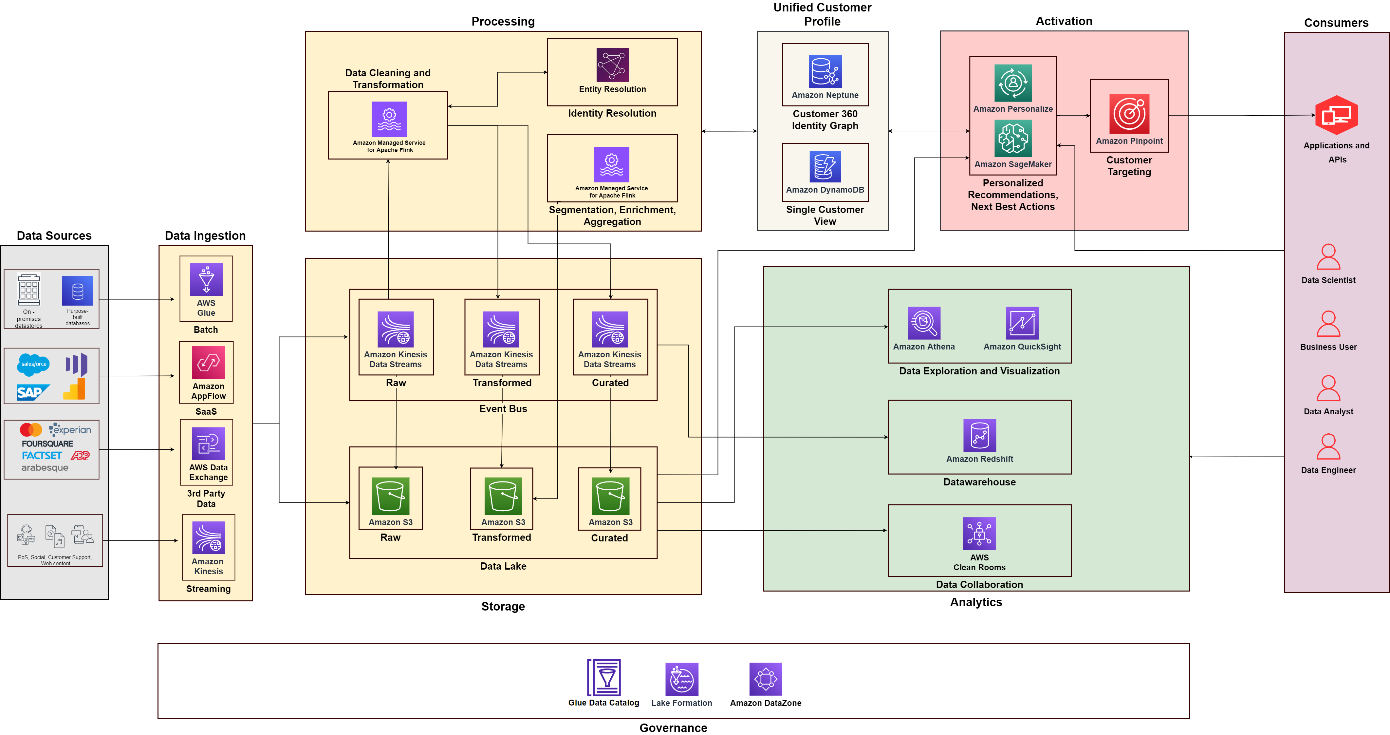
Conclusion
La création d'une capacité C360 robuste est fondamentale pour que votre organisation puisse mieux comprendre votre clientèle. Les services AWS Databases, Analytics et AI/ML peuvent aider à rationaliser ce processus, en offrant évolutivité et efficacité. En suivant les cinq piliers pour guider votre réflexion, vous pouvez élaborer une stratégie de données de bout en bout qui définit la vue C360 à travers l'organisation, garantit l'exactitude des données et établit une gouvernance interfonctionnelle pour les données clients. Vous pouvez catégoriser et hiérarchiser les produits et fonctionnalités que vous devez créer au sein de chaque pilier, sélectionner le bon outil pour le travail et développer les compétences dont vous avez besoin dans vos équipes.
Visiter Témoignages clients AWS pour les données pour découvrir comment AWS transforme les parcours clients, des plus grandes entreprises du monde aux startups en pleine croissance.
À propos des auteurs
 Ismaïl Makhlouf est architecte de solutions spécialisé senior pour l'analyse de données chez AWS. Ismail se concentre sur l'architecture de solutions pour les organisations dans l'ensemble de leur parc d'analyse de données de bout en bout, y compris le streaming par lots et en temps réel, le Big Data, l'entreposage de données et les charges de travail des lacs de données. Il travaille principalement avec des organisations du commerce de détail, du commerce électronique, des FinTech, des HealthTech et des voyages pour atteindre leurs objectifs commerciaux avec des plateformes de données bien architecturées.
Ismaïl Makhlouf est architecte de solutions spécialisé senior pour l'analyse de données chez AWS. Ismail se concentre sur l'architecture de solutions pour les organisations dans l'ensemble de leur parc d'analyse de données de bout en bout, y compris le streaming par lots et en temps réel, le Big Data, l'entreposage de données et les charges de travail des lacs de données. Il travaille principalement avec des organisations du commerce de détail, du commerce électronique, des FinTech, des HealthTech et des voyages pour atteindre leurs objectifs commerciaux avec des plateformes de données bien architecturées.
 Sandipan Bhaumik (Sandy) est architecte de solutions spécialiste senior de l'analyse chez AWS. Il aide les clients à moderniser leurs plateformes de données dans le cloud pour effectuer des analyses sécurisées à grande échelle, réduire les frais opérationnels et optimiser leur utilisation dans un souci de rentabilité et de durabilité.
Sandipan Bhaumik (Sandy) est architecte de solutions spécialiste senior de l'analyse chez AWS. Il aide les clients à moderniser leurs plateformes de données dans le cloud pour effectuer des analyses sécurisées à grande échelle, réduire les frais opérationnels et optimiser leur utilisation dans un souci de rentabilité et de durabilité.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/create-an-end-to-end-data-strategy-for-customer-360-on-aws/

