Le volume de données générées à l’échelle mondiale continue d’augmenter, depuis les jeux, la vente au détail et la finance jusqu’à l’industrie manufacturière, la santé et les voyages. Les organisations recherchent davantage de moyens d'utiliser rapidement l'afflux constant de données pour innover pour leurs activités et leurs clients. Ils doivent capturer, traiter, analyser et charger les données de manière fiable dans une myriade de magasins de données, le tout en temps réel.
Apache Kafka est un choix populaire pour ces besoins de streaming en temps réel. Cependant, il peut être difficile de configurer un cluster Kafka avec d'autres composants de traitement de données qui évoluent automatiquement en fonction des besoins de votre application. Vous risquez un sous-provisionnement pour les pics de trafic, ce qui peut entraîner des temps d'arrêt, ou un surprovisionnement pour la charge de base, entraînant un gaspillage. AWS propose plusieurs services sans serveur comme Amazon Managed Streaming pour Apache Kafka (AmazonMSK), Amazon Data Firehose, Amazon DynamoDBet AWS Lambda qui évolue automatiquement en fonction de vos besoins.
Dans cet article, nous expliquons comment vous pouvez utiliser certains de ces services, notamment MSK sans serveur, pour créer une plateforme de données sans serveur pour répondre à vos besoins en temps réel.
Vue d'ensemble de la solution
Imaginons un scénario. Vous êtes responsable de la gestion de milliers de modems pour un fournisseur de services Internet déployé dans plusieurs zones géographiques. Vous souhaitez surveiller la qualité de la connectivité du modem qui a un impact significatif sur la productivité et la satisfaction des clients. Votre déploiement comprend différents modems qui doivent être surveillés et entretenus pour garantir un temps d'arrêt minimal. Chaque appareil transmet des milliers d'enregistrements de 1 Ko chaque seconde, tels que l'utilisation du processeur, l'utilisation de la mémoire, l'alarme et l'état de la connexion. Vous souhaitez accéder en temps réel à ces données afin de pouvoir surveiller les performances en temps réel et détecter et atténuer rapidement les problèmes. Vous avez également besoin d'un accès à plus long terme à ces données pour les modèles d'apprentissage automatique (ML) afin d'exécuter des évaluations de maintenance prédictive, de trouver des opportunités d'optimisation et de prévoir la demande.
Vos clients qui collectent les données sur site sont écrits en Python et peuvent envoyer toutes les données sous forme de sujets Apache Kafka à Amazon MSK. Pour la faible latence et l'accès aux données en temps réel de votre application, vous pouvez utiliser Lambda et DynamoDB. Pour un stockage de données à plus long terme, vous pouvez utiliser le service de connecteur sans serveur géré Amazon Data Firehose pour envoyer des données à votre lac de données.
Le diagramme suivant montre comment créer cette application sans serveur de bout en bout.
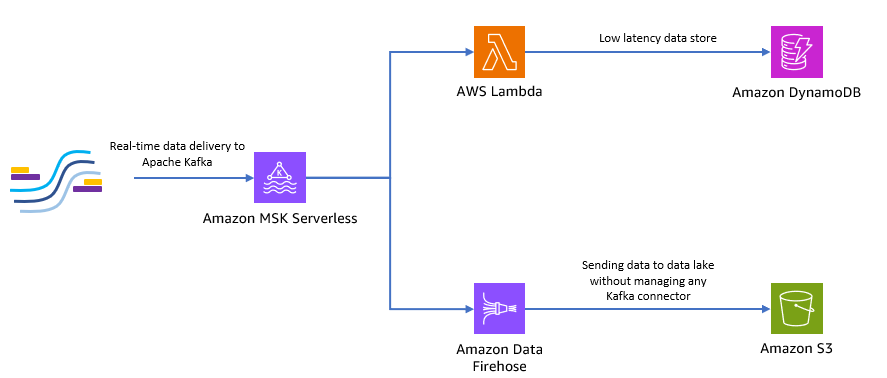
Suivons les étapes des sections suivantes pour implémenter cette architecture.
Créer un cluster Kafka sans serveur sur Amazon MSK
Nous utilisons Amazon MSK pour ingérer les données de télémétrie en temps réel des modems. La création d'un cluster Kafka sans serveur est simple sur Amazon MSK. Cela ne prend que quelques minutes en utilisant le Console de gestion AWS ou le SDK AWS. Pour utiliser la console, reportez-vous à Premiers pas avec les clusters MSK Serverless. Vous créez un cluster sans serveur, Gestion des identités et des accès AWS (IAM) et la machine client.
Créer un sujet Kafka en utilisant Python
Lorsque votre cluster et votre machine client sont prêts, connectez-vous en SSH à votre machine client et installez Kafka Python et la bibliothèque MSK IAM pour Python.
- Exécutez les commandes suivantes pour installer Kafka Python et le Bibliothèque MSK IAM:
- Créez un nouveau fichier appelé
createTopic.py. - Copiez le code suivant dans ce fichier, en remplaçant le
bootstrap_serversainsi queregioninformations avec les détails de votre cluster. Pour obtenir des instructions sur la récupération dubootstrap_serversinformations sur votre cluster MSK, voir Obtenir les courtiers d'amorçage pour un cluster Amazon MSK.
- Exécutez le
createTopic.pyscript pour créer un nouveau sujet Kafka appelémytopicsur votre cluster sans serveur :
Produire des enregistrements en utilisant Python
Générons quelques exemples de données de télémétrie du modem.
- Créez un nouveau fichier appelé
kafkaDataGen.py. - Copiez le code suivant dans ce fichier, en mettant à jour le
BROKERSainsi queregioninformations avec les détails de votre cluster :
- Exécutez le
kafkaDataGen.pypour générer en continu des données aléatoires et les publier dans le sujet Kafka spécifié :
Stocker les événements dans Amazon S3
Maintenant, vous stockez toutes les données brutes des événements dans un Service de stockage simple Amazon (Amazon S3) lac de données pour l'analyse. Vous pouvez utiliser les mêmes données pour entraîner des modèles ML. Le intégration avec Amazon Data Firehose permet à Amazon MSK de charger de manière transparente les données de vos clusters Apache Kafka dans un lac de données S3. Effectuez les étapes suivantes pour diffuser en continu des données de Kafka vers Amazon S3, éliminant ainsi le besoin de créer ou de gérer vos propres applications de connecteur :
- Sur la console Amazon S3, créez un nouveau compartiment. Vous pouvez également utiliser un bucket existant.
- Créez un nouveau dossier dans votre compartiment S3 appelé
streamingDataLake. - Sur la console Amazon MSK, choisissez votre cluster MSK Serverless.
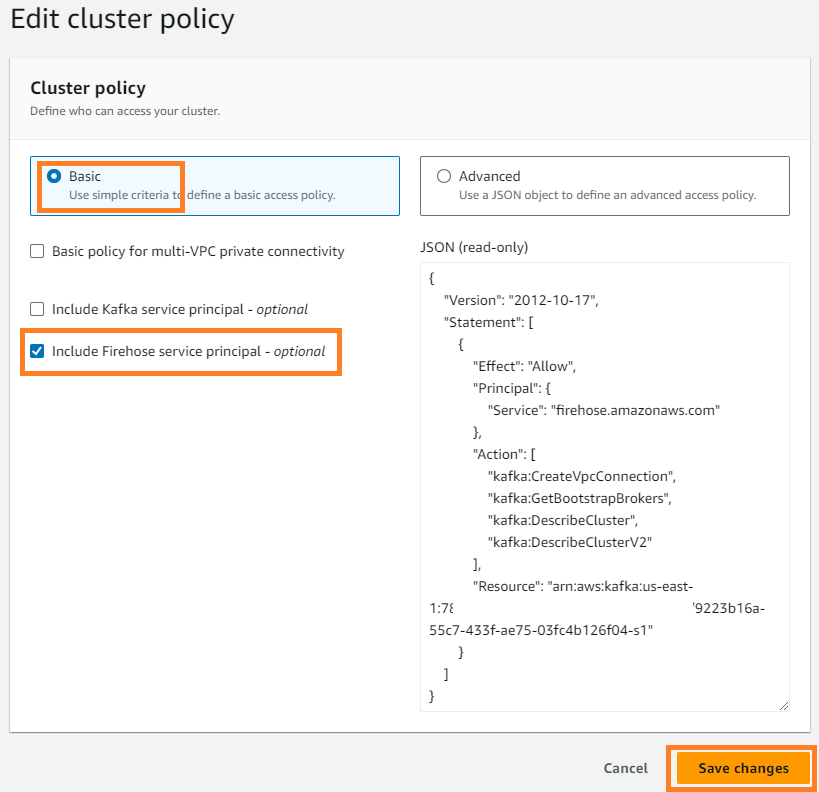
- Sur le Actions menu, choisissez Modifier la stratégie de cluster.

- Sélectionnez Inclure le principal du service Firehose et choisissez Enregistrer les modifications.
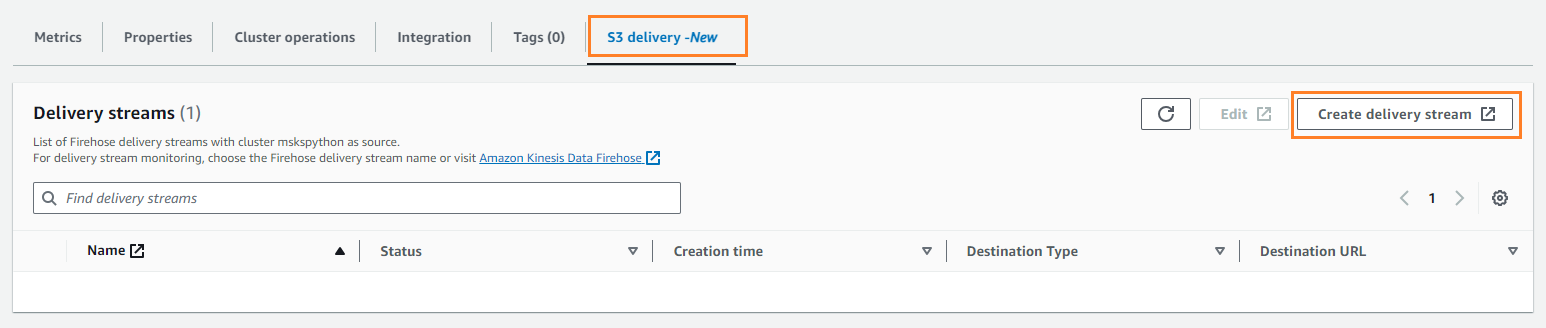
- Sur le Livraison S3 onglet, choisissez Créer un flux de diffusion.
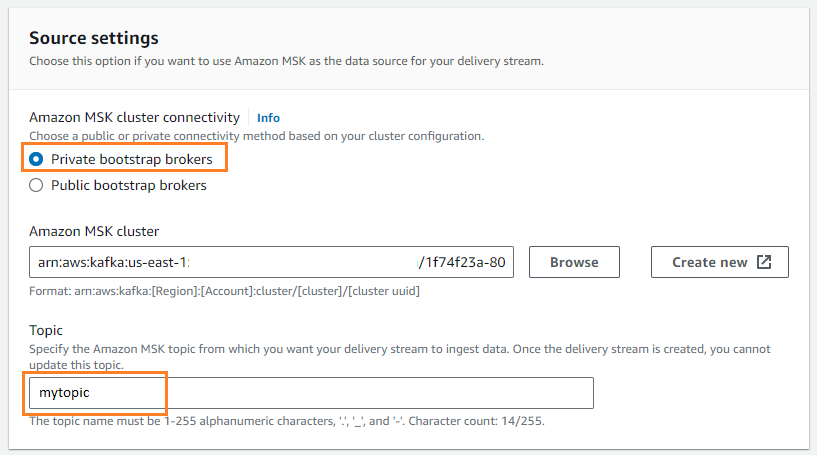
- Pour Identifier, choisissez AmazonMSK.
- Pour dentaire, choisissez Amazon S3.

- Pour Connectivité du cluster Amazon MSK, sélectionnez Courtiers bootstrap privés.
- Pour Sujet, saisissez un nom de sujet (pour ce message,
mytopic).
- Pour Seau S3, choisissez Explorer et choisissez votre compartiment S3.
- Entrer
streamingDataLakecomme préfixe de compartiment S3. - Entrer
streamingDataLakeErrcomme préfixe de sortie d'erreur de compartiment S3.

- Selectionnez Créer un flux de diffusion.
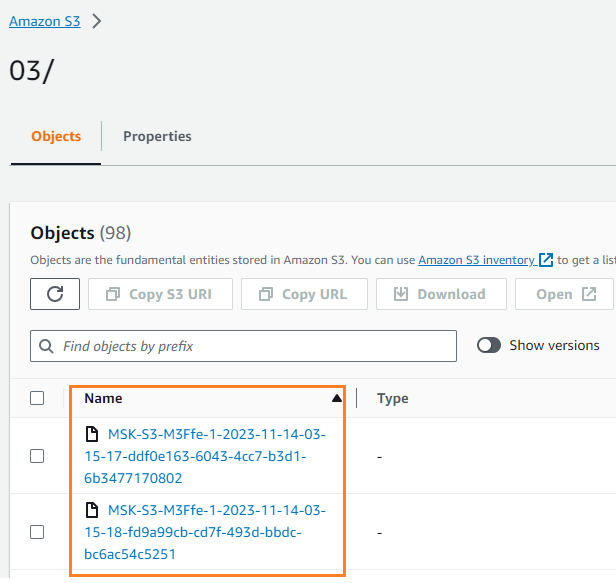
Vous pouvez vérifier que les données ont été écrites dans votre compartiment S3. Vous devriez voir que le streamingDataLake Le répertoire a été créé et les fichiers sont stockés dans des partitions.
Stocker les événements dans DynamoDB
Pour la dernière étape, vous stockez les données du modem les plus récentes dans DynamoDB. Cela permet à l'application client d'accéder à l'état du modem et d'interagir avec le modem à distance depuis n'importe où, avec une faible latence et une haute disponibilité. Lambda fonctionne de manière transparente avec Amazon MSK. Lambda recherche en interne les nouveaux messages de la source d'événements, puis appelle de manière synchrone la fonction Lambda cible. Lambda lit les messages par lots et les fournit à votre fonction en tant que charge utile d'événement.
Créons d'abord une table dans DynamoDB. Faire référence à Autorisations de l'API DynamoDB : référence sur les actions, les ressources et les conditions pour vérifier que votre ordinateur client dispose des autorisations nécessaires.
- Créez un nouveau fichier appelé
createTable.py. - Copiez le code suivant dans le fichier, en mettant à jour le
regioninformations:
- Exécutez le
createTable.pyscript pour créer une table appeléedevice_statusdans DynamoDB :
Configurons maintenant la fonction Lambda.
- Sur la console Lambda, choisissez Les fonctions dans le volet de navigation.
- Selectionnez Créer une fonction.
- Sélectionnez Auteur à partir de zéro.
- Pour Nom de la fonction¸ entrez un nom (par exemple,
my-notification-kafka). - Pour Runtime, choisissez Python 3.11.
- Pour Permissions, sélectionnez Utiliser un rôle existant et choisissez un rôle avec autorisations de lecture à partir de votre cluster.
- Créez la fonction.
Sur la page de configuration de la fonction Lambda, vous pouvez désormais configurer les sources, les destinations et le code de votre application.
- Selectionnez Ajouter un déclencheur.
- Pour Configuration du déclencheur, Entrer
MSKpour configurer Amazon MSK comme déclencheur pour la fonction source Lambda. - Pour Pôle MSK, Entrer
myCluster. - Désélectionner Activer le déclencheur, car vous n'avez pas encore configuré votre fonction Lambda.
- Pour Taille du lot, Entrer
100. - Pour Position de départ, choisissez Actualités.
- Pour Nom du sujet¸ entrez un nom (par exemple,
mytopic). - Selectionnez Ajouter.
- Sur la page de détails de la fonction Lambda, sur la page Code onglet, entrez le code suivant:
- Déployez la fonction Lambda.
- Sur le configuration onglet, choisissez Modifier pour modifier le déclencheur.
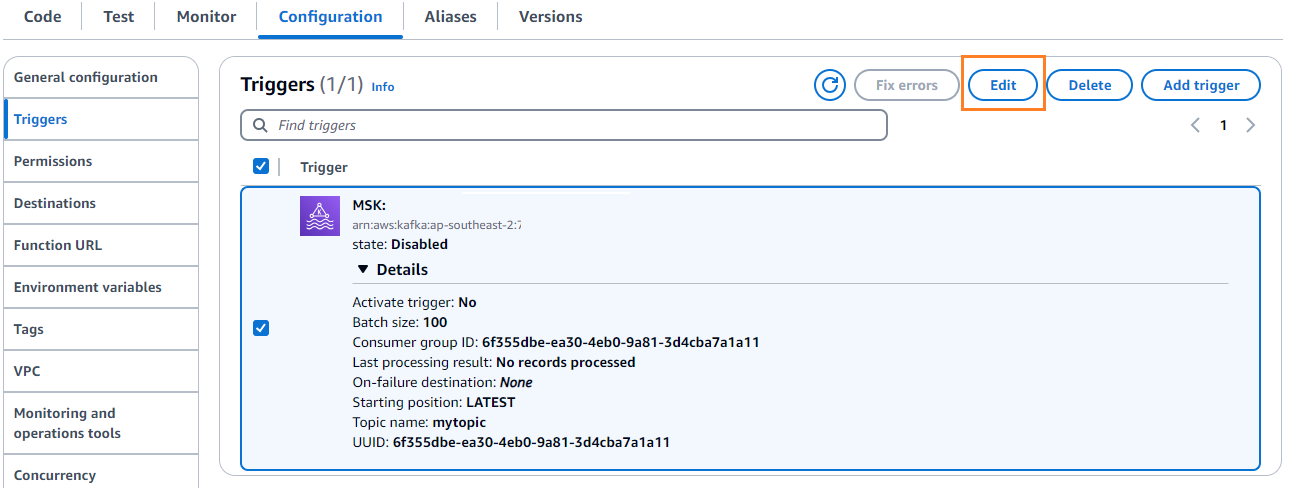
- Sélectionnez le déclencheur, puis choisissez Épargnez.
- Sur la console DynamoDB, choisissez Explorer les articles dans le volet de navigation.
- Sélectionnez la table
device_status.
Vous verrez que Lambda écrit les événements générés dans la rubrique Kafka dans DynamoDB.

Résumé
Les pipelines de données en streaming sont essentiels pour créer des applications en temps réel. Cependant, la mise en place et la gestion de l’infrastructure peuvent s’avérer intimidantes. Dans cet article, nous avons expliqué comment créer un pipeline de streaming sans serveur sur AWS à l'aide d'Amazon MSK, Lambda, DynamoDB, Amazon Data Firehose et d'autres services. Les principaux avantages sont l'absence de serveurs à gérer, l'évolutivité automatique de l'infrastructure et un modèle de paiement à l'utilisation utilisant des services entièrement gérés.
Prêt à créer votre propre pipeline en temps réel ? Commencez dès aujourd'hui avec un compte AWS gratuit. Grâce à la puissance du sans serveur, vous pouvez vous concentrer sur la logique de votre application pendant qu'AWS s'occupe du gros travail indifférencié. Créons quelque chose de génial sur AWS !
À propos des auteurs
 Masudur Rahaman Sayem est architecte de données en continu chez AWS. Il travaille avec des clients AWS dans le monde entier pour concevoir et créer des architectures de streaming de données afin de résoudre des problèmes commerciaux réels. Il est spécialisé dans l'optimisation des solutions qui utilisent les services de données en continu et NoSQL. Sayem est passionné par l'informatique distribuée.
Masudur Rahaman Sayem est architecte de données en continu chez AWS. Il travaille avec des clients AWS dans le monde entier pour concevoir et créer des architectures de streaming de données afin de résoudre des problèmes commerciaux réels. Il est spécialisé dans l'optimisation des solutions qui utilisent les services de données en continu et NoSQL. Sayem est passionné par l'informatique distribuée.
 Michael Oguike est chef de produit pour Amazon MSK. Il est passionné par l’utilisation des données pour découvrir des informations qui conduisent à l’action. Il aime aider les clients d'un large éventail de secteurs à améliorer leurs activités grâce au streaming de données. Michael aime également en apprendre davantage sur les sciences du comportement et la psychologie à partir de livres et de podcasts.
Michael Oguike est chef de produit pour Amazon MSK. Il est passionné par l’utilisation des données pour découvrir des informations qui conduisent à l’action. Il aime aider les clients d'un large éventail de secteurs à améliorer leurs activités grâce au streaming de données. Michael aime également en apprendre davantage sur les sciences du comportement et la psychologie à partir de livres et de podcasts.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

