Il s'agit d'un article invité co-écrit par Shravan Kumar et Avirat S de Gramener.
Gramenerun S'efforcer entreprise, contribue au développement durable en se concentrant sur l'agriculture, la foresterie, la gestion de l'eau et les énergies renouvelables. En fournissant aux autorités les outils et les informations dont elles ont besoin pour prendre des décisions éclairées concernant l'impact environnemental et social, Gramener joue un rôle essentiel dans la construction d'un avenir plus durable.
Les îlots de chaleur urbains (ICU) sont des zones situées au sein des villes qui connaissent des températures nettement plus élevées que les zones rurales environnantes. Les UHI constituent une préoccupation croissante car ils peuvent entraîner divers problèmes environnementaux et sanitaires. Pour relever ce défi, Gramener a développé une solution qui utilise des données spatiales et des techniques de modélisation avancées pour comprendre et atténuer les effets UHI suivants :
- Écart de température – Les UHI peuvent rendre les zones urbaines plus chaudes que les régions rurales environnantes.
- Effets sanitaires – Des températures plus élevées dans les UHI contribuent à une augmentation de 10 à 20 % des maladies et des décès liés à la chaleur.
- Consommation d'énergie - Les UHI amplifient les demandes de climatisation, entraînant une augmentation jusqu'à 20 % de la consommation d'énergie.
- Qualité de l'air - Les UHI détériorent la qualité de l’air, entraînant des niveaux élevés de smog et de particules, susceptibles d’aggraver les problèmes respiratoires.
- Impact économique – Les UHI peuvent entraîner des milliards de dollars en coûts énergétiques supplémentaires, en dommages aux infrastructures et en dépenses de santé.
La solution GeoBox de Gramener permet aux utilisateurs d'exploiter et d'analyser sans effort les données géospatiales publiques grâce à sa puissante API, permettant une intégration transparente dans les flux de travail existants. Cela rationalise l’exploration et permet d’économiser du temps et des ressources précieuses, permettant aux communautés d’identifier rapidement les points chauds UHI. GeoBox transforme ensuite les données brutes en informations exploitables présentées dans des formats conviviaux tels que raster, GeoJSON et Excel, garantissant une compréhension claire et une mise en œuvre immédiate des stratégies d'atténuation de l'UHI. Cela permet aux communautés de prendre des décisions éclairées et de mettre en œuvre des initiatives de développement urbain durable, aidant ainsi les citoyens grâce à une meilleure qualité de l'air, une consommation d'énergie réduite et un environnement plus frais et plus sain.
Cet article montre comment la solution GeoBox de Gramener utilise les capacités géospatiales d'Amazon SageMaker pour effectuer une analyse d'observation de la Terre et débloquer des informations UHI à partir de l'imagerie satellite. Les capacités géospatiales de SageMaker permettent aux scientifiques des données et aux ingénieurs en apprentissage automatique (ML) de créer, former et déployer facilement des modèles à l'aide de données géospatiales. Les capacités géospatiales de SageMaker vous permettent de transformer et d'enrichir efficacement des ensembles de données géospatiales à grande échelle, et d'accélérer le développement de produits et le temps d'obtention d'informations grâce à des modèles ML pré-entraînés.
Vue d'ensemble de la solution
Geobox vise à analyser et prédire l’effet UHI en exploitant les caractéristiques spatiales. Il aide à comprendre comment les changements proposés en matière d’infrastructures et d’utilisation des sols peuvent avoir un impact sur les modèles d’UHI et identifie les facteurs clés qui influencent l’UHI. Ce modèle analytique fournit des estimations précises de la température de surface des terres (LST) à un niveau granulaire, permettant à Gramener de quantifier les changements dans l'effet UHI en fonction de paramètres (noms des indices et données utilisées).
Geobox permet aux services de la ville de :
- Adaptation climatique améliorée et la planification de votre patrimoine – Des décisions éclairées réduisent l’impact des épisodes de chaleur accablante.
- Soutien à l’agrandissement des espaces verts – Plus d’espaces verts améliorent la qualité de l’air et la qualité de vie.
- Collaboration interministérielle améliorée – Des efforts coordonnés améliorent la sécurité publique.
- Préparation stratégique aux situations d’urgence – Une planification ciblée réduit le risque d’urgence.
- Collaboration avec les services de santé – La coopération conduit à des interventions sanitaires plus efficaces.
Flux de travail des solutions
Dans cette section, nous discutons de la manière dont les différents composants fonctionnent ensemble, de l'acquisition de données à la modélisation et à la prévision spatiales, qui constituent le cœur de la solution UHI. La solution suit un flux de travail structuré, avec un accent principal sur la gestion des UHI dans une ville du Canada.
Phase 1 : Pipeline de données
Le satellite Landsat 8 capture des images détaillées de la zone d'intérêt tous les 15 jours à 11h30, offrant une vue complète du paysage et de l'environnement de la ville. Un système de grille est établi avec une taille de grille de 48 mètres à l'aide de la bibliothèque Supermercado Python de Mapbox au niveau de zoom 19, permettant une analyse spatiale précise.

Phase 2 : Analyse exploratoire
Intégrant des couches de données sur les infrastructures et la population, Geobox permet aux utilisateurs de visualiser la répartition variable de la ville et d'en tirer des informations morphologiques urbaines, permettant une analyse complète de la structure et du développement de la ville.
En outre, les images Landsat de la phase 1 sont utilisées pour obtenir des informations telles que l'indice de végétation par différence normalisée (NDVI) et l'indice d'accumulation de différence normalisée (NDBI), avec des données méticuleusement mises à l'échelle sur la grille de 48 mètres pour plus de cohérence et de précision.
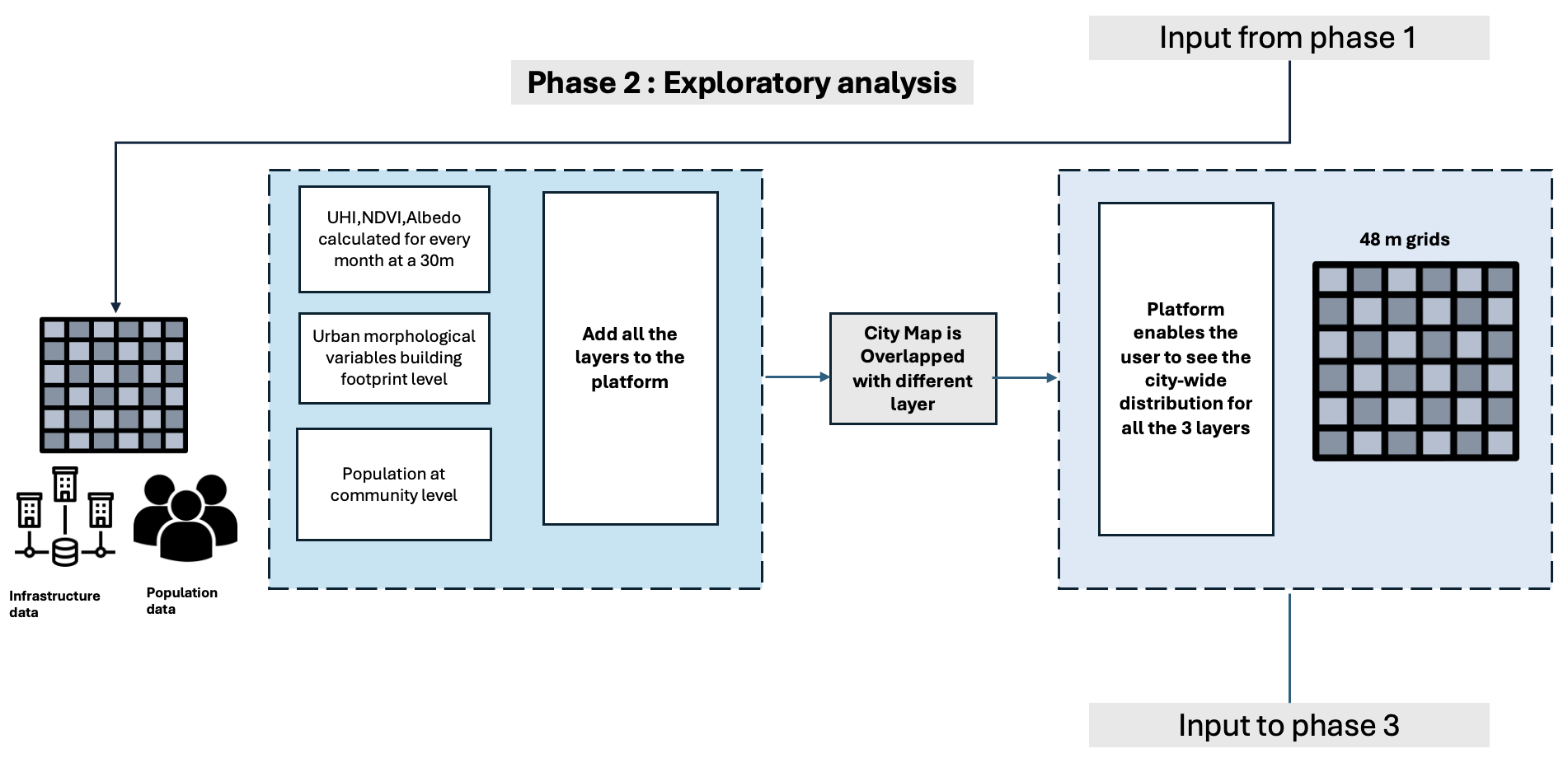
Les variables suivantes sont utilisées :
- Température à la surface du sol
- Couverture des chantiers
- NDVI
- Couverture des éléments de base
- NDBI
- Zone de construction
- Albédo
- Nombre de bâtiments
- Indice de différence d'eau normalisé modifié (MNDWI)
- Hauteur du bâtiment
- Nombre d'étages et superficie au sol
- Rapport de surface du plancher
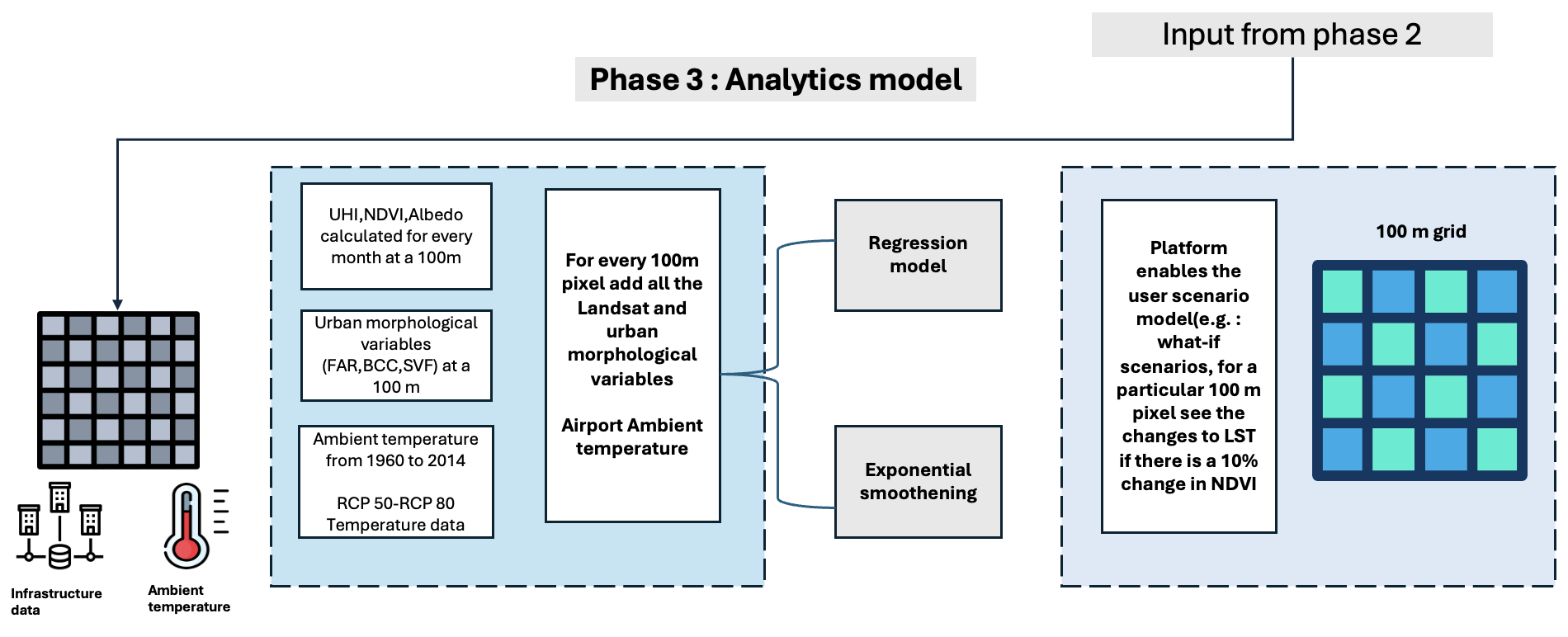
Phase 3 : modèle d'analyse
Cette phase comprend trois modules, utilisant des modèles ML sur les données pour mieux comprendre le LST et ses relations avec d'autres facteurs influents :
- Module 1 : Statistiques zonales et agrégation – Les statistiques zonales jouent un rôle essentiel dans le calcul des statistiques à l'aide des valeurs du raster de valeurs. Il s'agit d'extraire des données statistiques pour chaque zone en fonction du raster de zone. L'agrégation est effectuée à une résolution de 100 mètres, permettant une analyse complète des données.
- Module 2 : Modélisation spatiale – Gramener a évalué trois modèles de régression (effets linéaires, spatiaux et spatiaux fixes) pour démêler la corrélation entre la température de surface des terres (LST) et d'autres variables. Parmi ces modèles, le modèle spatial à effets fixes a donné la valeur R carré moyenne la plus élevée, en particulier pour la période allant de 2014 à 2020.
- Module 3 : Prévision des variables – Pour prévoir les variables à court terme, Gramener a utilisé des techniques de lissage exponentiel. Ces prévisions ont aidé à comprendre les futures valeurs du LST et leurs tendances. De plus, ils ont approfondi l’analyse à long terme en utilisant les données de la voie de concentration représentative (RCP8.5) pour prédire les valeurs LST sur des périodes prolongées.
Acquisition de données et prétraitement
Pour implémenter les modules, Gramener a utilisé le carnet géospatial SageMaker dans Amazon SageMakerStudio. Le noyau du bloc-notes géospatial est préinstallé avec des bibliothèques géospatiales couramment utilisées, permettant la visualisation et le traitement directs des données géospatiales dans l'environnement du bloc-notes Python.
Gramener a utilisé divers ensembles de données pour prédire les tendances du LST, notamment des données d'évaluation des bâtiments et de température, ainsi que des images satellite. La clé de la solution UHI résidait dans l’utilisation des données du satellite Landsat 8. Ce satellite d'imagerie de la Terre, une coentreprise de l'USGS et de la NASA, a constitué un élément fondamental du projet.
Avec la RechercheRasterDataCollection API, SageMaker fournit une fonctionnalité spécialement conçue pour faciliter la récupération d'images satellite. Gramener a utilisé cette API pour récupérer les données satellite Landsat 8 pour la solution UHI.
La SearchRasterDataCollection L'API utilise les paramètres d'entrée suivants :
- arn – L'Amazon Resource Name (ARN) de la collection de données raster utilisée dans la requête
- Lieu d'intérêt – Un polygone GeoJSON représentant la zone d’intérêt
- Filtre de plage de temps – La plage horaire d’intérêt, notée
{StartTime: <string>, EndTime: <string>} - Filtres de propriétés – Des filtres de propriétés supplémentaires, tels que des spécifications pour la couverture nuageuse maximale acceptable, peuvent également être incorporés
L'exemple suivant montre comment les données Landsat 8 peuvent être interrogées via l'API :
Pour traiter des données satellitaires à grande échelle, Gramener a utilisé Traitement d'Amazon SageMaker avec le conteneur géospatial. SageMaker Processing permet une mise à l'échelle flexible des clusters de calcul pour s'adapter à des tâches de différentes tailles, du traitement d'un seul pâté de maisons à la gestion de charges de travail à l'échelle planétaire. Traditionnellement, la création et la gestion manuelles d'un cluster de calcul pour de telles tâches étaient à la fois coûteuses et chronophages, notamment en raison des complexités liées à la standardisation d'un environnement adapté à la gestion des données géospatiales.
Désormais, grâce au conteneur géospatial spécialisé de SageMaker, la gestion et l'exécution de clusters pour le traitement géospatial sont devenues plus simples. Ce processus nécessite un effort de codage minimal : il vous suffit de définir la charge de travail, de spécifier l'emplacement des données géospatiales dans Service de stockage simple Amazon (Amazon S3) et sélectionnez le conteneur géospatial approprié. SageMaker Processing provisionne ensuite automatiquement les ressources de cluster nécessaires, facilitant ainsi l'exécution efficace des tâches géospatiales à des échelles allant du niveau de la ville au niveau du continent.
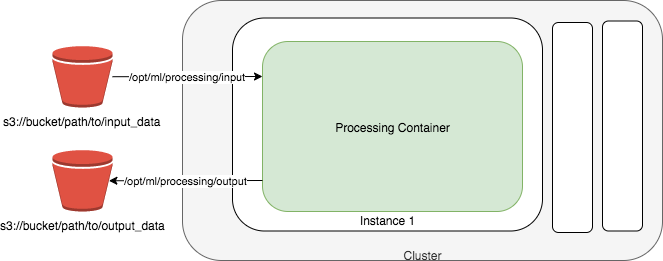
SageMaker gère entièrement l'infrastructure sous-jacente requise pour le travail de traitement. Il alloue des ressources de cluster pour la durée de la tâche et les supprime une fois la tâche terminée. Enfin, les résultats de la tâche de traitement sont enregistrés dans le compartiment S3 désigné.
Une tâche de traitement SageMaker utilisant l'image géospatiale peut être configurée comme suit à partir du bloc-notes géospatial :
Le paramètre instance_count définit le nombre d'instances que la tâche de traitement doit utiliser, et instance_type définit le type d'instance à utiliser.
L'exemple suivant montre comment un script Python est exécuté sur le cluster de tâches de traitement. Lorsque la commande run est appelée, le cluster démarre et provisionne automatiquement les ressources de cluster nécessaires :
Modélisation spatiale et prédictions LST
Dans le travail de traitement, une série de variables, notamment le rayonnement spectral au sommet de l'atmosphère, la température de luminosité et la réflectance de Landsat 8, sont calculées. De plus, des variables morphologiques telles que le rapport de surface au sol (FAR), la couverture du chantier, la couverture des blocs de construction et la valeur d'entropie de Shannon sont calculées.
Le code suivant montre comment cette arithmétique de bande peut être effectuée :
Une fois les variables calculées, des statistiques zonales sont effectuées pour agréger les données par grille. Cela implique de calculer des statistiques basées sur les valeurs d'intérêt au sein de chaque zone. Pour ces calculs, une grille d'environ 100 mètres a été utilisée.
Après avoir agrégé les données, une modélisation spatiale est réalisée. Gramener a utilisé des méthodes de régression spatiale, telles que la régression linéaire et les effets fixes spatiaux, pour tenir compte de la dépendance spatiale des observations. Cette approche facilite la modélisation de la relation entre les variables et le LST au niveau micro.
Le code suivant illustre comment une telle modélisation spatiale peut être exécutée :
Gramener a utilisé le lissage exponentiel pour prédire les valeurs LST. Le lissage exponentiel est une méthode efficace de prévision de séries chronologiques qui applique des moyennes pondérées aux données passées, les pondérations diminuant de façon exponentielle au fil du temps. Cette méthode est particulièrement efficace pour lisser les données afin d’identifier les tendances et les modèles. En utilisant le lissage exponentiel, il devient possible de visualiser et de prédire les tendances LST avec une plus grande précision, permettant ainsi des prédictions plus précises des valeurs futures basées sur des modèles historiques.
Pour visualiser les prédictions, Gramener a utilisé le bloc-notes géospatial SageMaker avec des bibliothèques géospatiales open source pour superposer les prédictions du modèle sur une carte de base et fournit des ensembles de données géospatiales de visualisation en couches directement dans le bloc-notes.
Conclusion
Cet article a démontré comment Gramener permet à ses clients de prendre des décisions fondées sur des données pour des environnements urbains durables. Avec SageMaker, Gramener a réalisé des gains de temps substantiels dans l'analyse UHI, réduisant le temps de traitement de plusieurs semaines à quelques heures. Cette génération rapide d'informations permet aux clients de Gramener d'identifier les zones nécessitant des stratégies d'atténuation de l'UHI, de planifier de manière proactive des projets de développement urbain et d'infrastructure pour minimiser l'UHI et d'acquérir une compréhension globale des facteurs environnementaux pour une évaluation complète des risques.
Découvrez le potentiel de l'intégration des données d'observation de la Terre dans vos projets de développement durable avec SageMaker. Pour plus d'informations, reportez-vous à Démarrez avec les fonctionnalités géospatiales d'Amazon SageMaker.
À propos des auteurs
 Abishek Mittal est architecte de solutions pour l'équipe mondiale du secteur public chez Amazon Web Services (AWS), où il travaille principalement avec des partenaires ISV de tous les secteurs en leur fournissant des conseils architecturaux pour créer une architecture évolutive et mettre en œuvre des stratégies pour favoriser l'adoption des services AWS. Il est passionné par la modernisation des plateformes traditionnelles et de la sécurité dans le cloud. En dehors du travail, il est passionné de voyages.
Abishek Mittal est architecte de solutions pour l'équipe mondiale du secteur public chez Amazon Web Services (AWS), où il travaille principalement avec des partenaires ISV de tous les secteurs en leur fournissant des conseils architecturaux pour créer une architecture évolutive et mettre en œuvre des stratégies pour favoriser l'adoption des services AWS. Il est passionné par la modernisation des plateformes traditionnelles et de la sécurité dans le cloud. En dehors du travail, il est passionné de voyages.
 Janosch Woschitz est architecte de solutions senior chez AWS, spécialisé dans l'IA/ML. Avec plus de 15 ans d'expérience, il aide ses clients du monde entier à tirer parti de l'IA et du ML pour des solutions innovantes et à créer des plateformes de ML sur AWS. Son expertise couvre l'apprentissage automatique, l'ingénierie des données et les systèmes distribués évolutifs, complétée par une solide expérience en ingénierie logicielle et une expertise industrielle dans des domaines tels que la conduite autonome.
Janosch Woschitz est architecte de solutions senior chez AWS, spécialisé dans l'IA/ML. Avec plus de 15 ans d'expérience, il aide ses clients du monde entier à tirer parti de l'IA et du ML pour des solutions innovantes et à créer des plateformes de ML sur AWS. Son expertise couvre l'apprentissage automatique, l'ingénierie des données et les systèmes distribués évolutifs, complétée par une solide expérience en ingénierie logicielle et une expertise industrielle dans des domaines tels que la conduite autonome.
 Shravan Kumar est directeur principal de la réussite client chez Gramener, avec une décennie d'expérience dans l'analyse commerciale, l'évangélisation des données et l'établissement de relations clients approfondies. Il possède une base solide en gestion de clients et en gestion de comptes dans le domaine de l'analyse de données, de l'IA et du ML.
Shravan Kumar est directeur principal de la réussite client chez Gramener, avec une décennie d'expérience dans l'analyse commerciale, l'évangélisation des données et l'établissement de relations clients approfondies. Il possède une base solide en gestion de clients et en gestion de comptes dans le domaine de l'analyse de données, de l'IA et du ML.
 Avirat S est un scientifique en données géospatiales chez Gramener, qui exploite l'IA/ML pour débloquer des informations à partir de données géographiques. Son expertise réside dans la gestion des catastrophes, l'agriculture et la planification urbaine, où son analyse éclaire les processus décisionnels.
Avirat S est un scientifique en données géospatiales chez Gramener, qui exploite l'IA/ML pour débloquer des informations à partir de données géographiques. Son expertise réside dans la gestion des catastrophes, l'agriculture et la planification urbaine, où son analyse éclaire les processus décisionnels.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/understanding-and-predicting-urban-heat-islands-at-gramener-using-amazon-sagemaker-geospatial-capabilities/

