Lors du déploiement d'un grand modèle de langage (LLM), les praticiens de l'apprentissage automatique (ML) se soucient généralement de deux mesures des performances de diffusion du modèle : la latence, définie par le temps nécessaire pour générer un seul jeton, et le débit, défini par le nombre de jetons générés. par seconde. Même si une seule requête adressée au point de terminaison déployé présenterait un débit approximativement égal à l'inverse de la latence du modèle, ce n'est pas nécessairement le cas lorsque plusieurs requêtes simultanées sont envoyées simultanément au point de terminaison. En raison des techniques de diffusion de modèles, telles que le traitement par lots continu de requêtes simultanées côté client, la latence et le débit entretiennent une relation complexe qui varie considérablement en fonction de l'architecture du modèle, des configurations de diffusion, du type de matériel d'instance, du nombre de requêtes simultanées et des variations des charges utiles d'entrée telles que en nombre de jetons d'entrée et de jetons de sortie.
Cet article explore ces relations via une analyse comparative complète des LLM disponibles dans Amazon SageMaker JumpStart, y compris les variantes Llama 2, Falcon et Mistral. Avec SageMaker JumpStart, les praticiens du ML peuvent choisir parmi une large sélection de modèles de base accessibles au public à déployer sur des sites dédiés. Amazon Sage Maker instances dans un environnement isolé du réseau. Nous fournissons des principes théoriques sur l’impact des spécifications des accélérateurs sur l’analyse comparative LLM. Nous démontrons également l'impact du déploiement de plusieurs instances derrière un seul point de terminaison. Enfin, nous fournissons des recommandations pratiques pour adapter le processus de déploiement de SageMaker JumpStart à vos exigences en matière de latence, de débit, de coût et de contraintes sur les types d'instances disponibles. Tous les résultats de l'analyse comparative ainsi que les recommandations sont basés sur un outil polyvalent cahier que vous pouvez adapter à votre cas d’utilisation.
Analyse comparative des points de terminaison déployés
La figure suivante montre les valeurs de latences les plus faibles (à gauche) et de débit les plus élevées (à droite) pour les configurations de déploiement sur divers types de modèles et types d'instances. Il est important de noter que chacun de ces déploiements de modèles utilise les configurations par défaut fournies par SageMaker JumpStart, en fonction de l'ID de modèle et du type d'instance souhaités pour le déploiement.
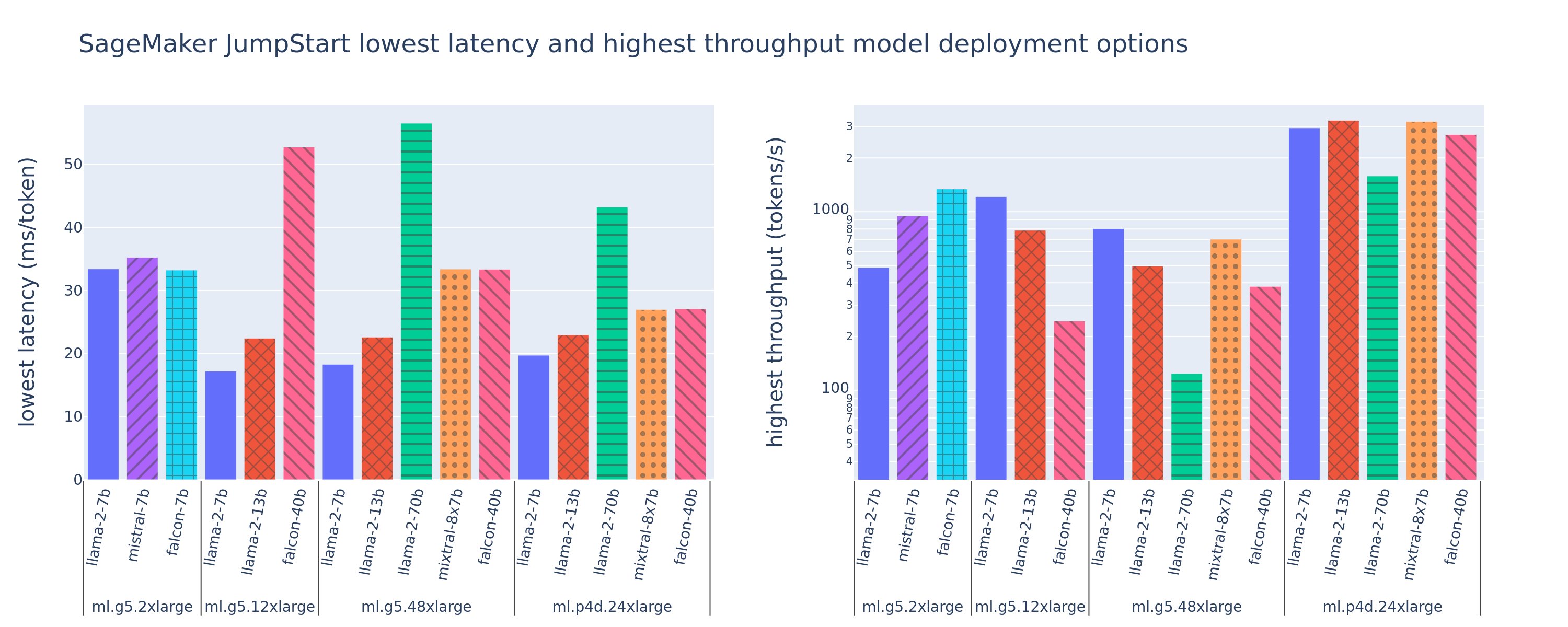
Ces valeurs de latence et de débit correspondent à des charges utiles avec 256 jetons d'entrée et 256 jetons de sortie. La configuration à latence la plus faible limite le modèle servant à une seule requête simultanée, et la configuration à débit le plus élevé maximise le nombre possible de requêtes simultanées. Comme nous pouvons le constater dans notre analyse comparative, l'augmentation des requêtes simultanées augmente de manière monotone le débit avec une amélioration décroissante pour les requêtes simultanées volumineuses. De plus, les modèles sont entièrement partagés sur l'instance prise en charge. Par exemple, étant donné que l'instance ml.g5.48xlarge dispose de 8 GPU, tous les modèles SageMaker JumpStart utilisant cette instance sont partitionnés à l'aide du parallélisme tensoriel sur les huit accélérateurs disponibles.
Nous pouvons retenir quelques points à retenir de ce chiffre. Premièrement, tous les modèles ne sont pas pris en charge sur toutes les instances ; certains modèles plus petits, tels que Falcon 7B, ne prennent pas en charge le partitionnement de modèle, tandis que les modèles plus grands ont des besoins en ressources de calcul plus élevés. Deuxièmement, à mesure que le partitionnement augmente, les performances s'améliorent généralement, mais pas nécessairement pour les petits modèles.. En effet, les petits modèles tels que 7B et 13B entraînent une surcharge de communication substantielle lorsqu'ils sont partagés sur trop d'accélérateurs. Nous en discuterons plus en profondeur plus tard. Enfin, les instances ml.p4d.24xlarge ont tendance à avoir un débit nettement meilleur en raison des améliorations de la bande passante mémoire des GPU A100 par rapport aux GPU A10G. Comme nous le verrons plus tard, la décision d'utiliser un type d'instance particulier dépend de vos exigences de déploiement, notamment des contraintes de latence, de débit et de coût.
Comment pouvez-vous obtenir ces valeurs de configuration de latence la plus faible et de débit le plus élevé ? Commençons par tracer la latence par rapport au débit pour un point de terminaison Llama 2 7B sur une instance ml.g5.12xlarge pour une charge utile avec 256 jetons d'entrée et 256 jetons de sortie, comme le montre la courbe suivante. Une courbe similaire existe pour chaque point de terminaison LLM déployé.

À mesure que la concurrence augmente, le débit et la latence augmentent également de manière monotone. Par conséquent, le point de latence le plus bas se produit à une valeur de demande simultanée de 1, et vous pouvez augmenter de manière rentable le débit du système en augmentant les demandes simultanées. Il existe un « genou » distinct dans cette courbe, où il est évident que les gains de débit associés à une concurrence supplémentaire ne compensent pas l'augmentation de la latence associée. L'emplacement exact de ce genou dépend du cas d'utilisation ; certains praticiens peuvent définir le genou au point où une exigence de latence prédéfinie est dépassée (par exemple, 100 ms/jeton), tandis que d'autres peuvent utiliser des tests de charge et des méthodes théoriques de file d'attente comme la règle de la demi-latence, et d'autres peuvent utiliser spécifications théoriques de l’accélérateur.
On note également que le nombre maximum de demandes simultanées est limité. Dans la figure précédente, la trace de ligne se termine par 192 requêtes simultanées. La source de cette limitation est la limite de délai d'expiration de l'appel SageMaker, où les points de terminaison SageMaker expirent une réponse d'appel après 60 secondes. Ce paramètre est spécifique au compte et n'est pas configurable pour un point de terminaison individuel. Pour les LLM, la génération d'un grand nombre de jetons de sortie peut prendre quelques secondes, voire quelques minutes. Par conséquent, des charges utiles d’entrée ou de sortie volumineuses peuvent entraîner l’échec des demandes d’appel. De plus, si le nombre de requêtes simultanées est très important, de nombreuses requêtes connaîtront des temps d'attente importants, ce qui entraînera cette limite de délai d'attente de 60 secondes. Pour les besoins de cette étude, nous utilisons la limite de délai d'attente pour définir le débit maximum possible pour un déploiement de modèle. Il est important de noter que même si un point de terminaison SageMaker peut gérer un grand nombre de requêtes simultanées sans observer de délai de réponse à l'appel, vous souhaiterez peut-être définir le nombre maximal de requêtes simultanées par rapport au genou dans la courbe latence-débit. C'est probablement à ce moment-là que vous commencerez à envisager une mise à l'échelle horizontale, où un seul point de terminaison provisionne plusieurs instances avec des réplicas de modèle et équilibre la charge des requêtes entrantes entre les réplicas, pour prendre en charge davantage de requêtes simultanées.
Pour aller plus loin, le tableau suivant contient les résultats d'analyse comparative pour différentes configurations du modèle Llama 2 7B, y compris différents nombres de jetons d'entrée et de sortie, types d'instances et nombre de requêtes simultanées. Notez que la figure précédente ne représente qu’une seule ligne de ce tableau.
| . | Débit (jetons/s) | Latence (ms/jeton) | ||||||||||||||||||
| Demandes simultanées | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Nombre total de jetons : 512, Nombre de jetons de sortie : 256 | ||||||||||||||||||||
| ml.g5.2xlarge | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xlarge | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xlarge | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xlarge | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Nombre total de jetons : 4096, Nombre de jetons de sortie : 256 | ||||||||||||||||||||
| ml.g5.2xlarge | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xlarge | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xlarge | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xlarge | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
Nous observons quelques modèles supplémentaires dans ces données. Lorsque la taille du contexte augmente, la latence augmente et le débit diminue. Par exemple, sur ml.g5.2xlarge avec une simultanéité de 1, le débit est de 30 jetons/s lorsque le nombre total de jetons est de 512, contre 20 jetons/s si le nombre total de jetons est de 4,096 2. En effet, le traitement d’une entrée plus importante prend plus de temps. Nous pouvons également constater que l’augmentation des capacités du GPU et le partitionnement ont un impact sur le débit maximal et le nombre maximal de requêtes simultanées prises en charge. Le tableau montre que Llama 7 5.12B a des valeurs de débit maximum sensiblement différentes pour différents types d'instances, et ces valeurs de débit maximum se produisent à différentes valeurs de requêtes simultanées. Ces caractéristiques inciteraient un praticien du ML à justifier le coût d’une instance par rapport à une autre. Par exemple, étant donné une faible latence requise, le praticien peut sélectionner une instance ml.g4xlarge (10 GPU A5.2G) plutôt qu'une instance ml.g1xlarge (10 GPU A4G). Si l’exigence de débit est élevée, l’utilisation d’une instance ml.p24d.8xlarge (100 GPU A7) avec partitionnement complet ne serait justifiée que dans des conditions de concurrence élevée. Notez cependant qu'il est souvent avantageux de charger plusieurs composants d'inférence d'un modèle 4B sur une seule instance ml.p24d.XNUMXxlarge ; une telle prise en charge multimodèle est abordée plus loin dans cet article.
Les observations précédentes ont été faites pour le modèle Llama 2 7B. Cependant, des tendances similaires restent également vraies pour d’autres modèles. L'un des principaux points à retenir est que les chiffres de latence et de performances de débit dépendent de la charge utile, du type d'instance et du nombre de requêtes simultanées. Vous devrez donc trouver la configuration idéale pour votre application spécifique. Pour générer les numéros précédents pour votre cas d'utilisation, vous pouvez exécuter le lien cahier, où vous pouvez configurer cette analyse de test de charge pour votre modèle, votre type d'instance et votre charge utile.
Donner du sens aux spécifications des accélérateurs
La sélection du matériel approprié pour l'inférence LLM dépend fortement de cas d'utilisation spécifiques, des objectifs d'expérience utilisateur et du LLM choisi. Cette section tente de comprendre le genou dans la courbe latence-débit par rapport aux principes de haut niveau basés sur les spécifications de l'accélérateur. Ces principes ne suffisent pas à eux seuls à prendre une décision : de véritables repères sont nécessaires. Le terme dispositif est utilisé ici pour englober tous les accélérateurs matériels ML. Nous affirmons que le coude dans la courbe latence-débit est déterminé par l'un des deux facteurs suivants :
- L'accélérateur a épuisé la mémoire pour mettre en cache les matrices KV, les requêtes suivantes sont donc mises en file d'attente
- L'accélérateur dispose toujours de mémoire disponible pour le cache KV, mais utilise une taille de lot suffisamment grande pour que le temps de traitement soit déterminé par la latence des opérations de calcul plutôt que par la bande passante mémoire.
Nous préférons généralement être limités par le deuxième facteur car cela implique que les ressources de l'accélérateur sont saturées. Fondamentalement, vous maximisez les ressources pour lesquelles vous avez payé. Explorons cette affirmation plus en détail.
Mise en cache KV et mémoire de l'appareil
Les mécanismes standard d'attention du transformateur calculent l'attention pour chaque nouveau jeton par rapport à tous les jetons précédents. La plupart des serveurs ML modernes mettent en cache les clés d'attention et les valeurs dans la mémoire de l'appareil (DRAM) pour éviter un nouveau calcul à chaque étape. C'est ce qu'on appelle le Cache KV, et il augmente avec la taille du lot et la longueur de la séquence. Il définit combien de requêtes d'utilisateurs peuvent être traitées en parallèle et déterminera le genou de la courbe latence-débit si le régime lié au calcul dans le deuxième scénario mentionné précédemment n'est pas encore respecté, compte tenu de la DRAM disponible. La formule suivante est une approximation approximative de la taille maximale du cache KV.

Dans cette formule, B est la taille du lot et N est le nombre d'accélérateurs. Par exemple, le modèle Llama 2 7B en FP16 (2 octets/paramètre) servi sur un GPU A10G (24 Go de DRAM) consomme environ 14 Go, laissant 10 Go pour le cache KV. En intégrant la longueur complète du contexte du modèle (N = 4096 32) et les paramètres restants (n_layers=32, n_kv_attention_heads=128 et d_attention_head=XNUMX), cette expression montre que nous sommes limités à servir une taille de lot de quatre utilisateurs en parallèle en raison des contraintes de DRAM. . Si vous observez les références correspondantes dans le tableau précédent, il s'agit d'une bonne approximation du genou observé dans cette courbe latence-débit. Des méthodes telles que attention aux requêtes groupées (GQA) peut réduire la taille du cache KV, dans le cas de GQA du même facteur, il réduit le nombre de têtes KV.
Intensité arithmétique et bande passante de la mémoire de l'appareil
La croissance de la puissance de calcul des accélérateurs ML a dépassé leur bande passante mémoire, ce qui signifie qu'ils peuvent effectuer beaucoup plus de calculs sur chaque octet de données dans le temps nécessaire pour accéder à cet octet.
La intensité arithmétique, ou le rapport entre les opérations de calcul et les accès à la mémoire, car une opération détermine si elle est limitée par la bande passante mémoire ou la capacité de calcul sur le matériel sélectionné. Par exemple, un GPU A10G (famille de types d'instances g5) avec 70 TFLOPS FP16 et 600 Go/s de bande passante peut calculer environ 116 opérations/octet. Un GPU A100 (famille de types d'instances p4d) peut calculer environ 208 opérations/octet. Si l'intensité arithmétique d'un modèle de transformateur est inférieure à cette valeur, elle est liée à la mémoire ; s'il est supérieur, il est lié au calcul. Le mécanisme d'attention pour Llama 2 7B nécessite 62 opérations/octet pour la taille de lot 1 (pour une explication, voir Un guide sur l'inférence et la performance LLM), ce qui signifie qu'il est lié à la mémoire. Lorsque le mécanisme d'attention est limité en mémoire, des FLOPS coûteux restent inutilisés.
Il existe deux manières de mieux utiliser l'accélérateur et d'augmenter l'intensité arithmétique : réduire les accès mémoire nécessaires à l'opération (c'est ce que FlashAttention se concentre sur) ou augmentez la taille du lot. Cependant, nous ne pourrons peut-être pas augmenter suffisamment la taille de notre lot pour atteindre un régime lié au calcul si notre DRAM est trop petite pour contenir le cache KV correspondant. Une approximation grossière de la taille critique du lot B* qui sépare les régimes liés au calcul des régimes liés à la mémoire pour l'inférence du décodeur GPT standard est décrite par l'expression suivante, où A_mb est la bande passante de la mémoire de l'accélérateur, A_f est le FLOPS de l'accélérateur et N est le nombre. d'accélérateurs. Cette taille critique de lot peut être dérivée en trouvant où le temps d'accès à la mémoire est égal au temps de calcul. Faire référence à ce blog pour comprendre l'équation 2 et ses hypothèses plus en détail.
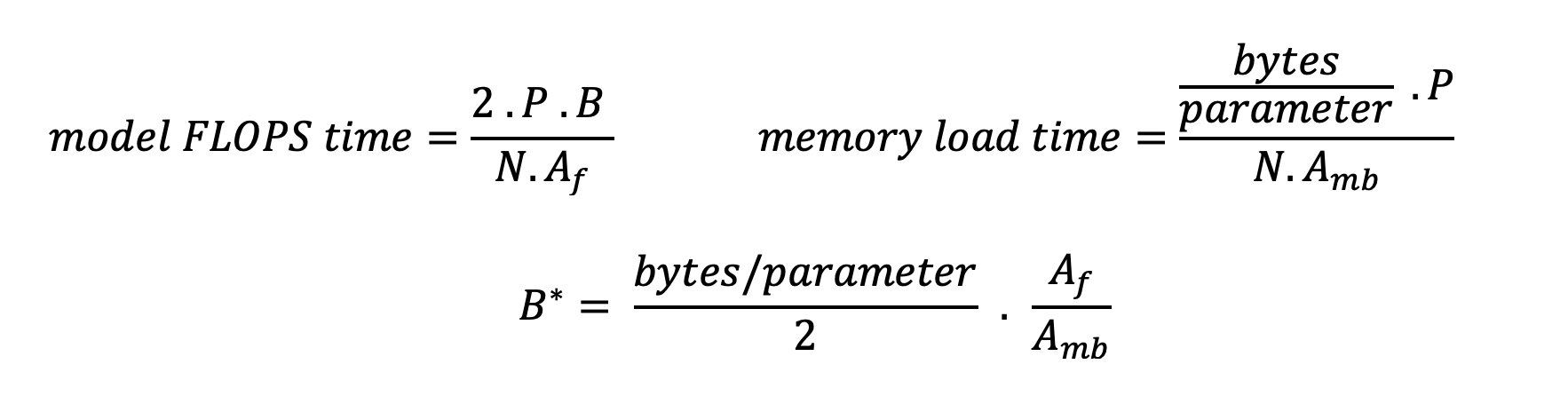
Il s'agit du même rapport opérations/octets que nous avons calculé précédemment pour l'A10G, donc la taille de lot critique sur ce GPU est de 116. Une façon d'aborder cette taille de lot théorique et critique consiste à augmenter le partitionnement du modèle et à diviser le cache entre plusieurs N accélérateurs. Cela augmente efficacement la capacité du cache KV ainsi que la taille des lots liés à la mémoire.
Un autre avantage du partitionnement de modèle est la répartition des paramètres de modèle et du travail de chargement des données sur N accélérateurs. Ce type de partitionnement est un type de parallélisme de modèles également appelé parallélisme tenseur. Naïvement, il y a N fois plus de bande passante mémoire et de puissance de calcul au total. En supposant qu'il n'y ait aucune surcharge d'aucune sorte (communication, logiciel, etc.), cela réduirait la latence de décodage par jeton de N si nous sommes limités en mémoire, car la latence de décodage des jetons dans ce régime est limitée par le temps nécessaire au chargement du modèle. poids et cache. Dans la vie réelle, cependant, l’augmentation du degré de partitionnement entraîne une communication accrue entre les appareils pour partager des activations intermédiaires à chaque couche du modèle. Cette vitesse de communication est limitée par la bande passante d'interconnexion du périphérique. Il est difficile d'estimer précisément son impact (pour plus de détails, voir Parallélisme du modèle), mais cela peut éventuellement cesser de produire des avantages ou détériorer les performances — cela est particulièrement vrai pour les modèles plus petits, car des transferts de données plus petits entraînent des taux de transfert plus faibles.
Pour comparer les accélérateurs ML en fonction de leurs spécifications, nous recommandons ce qui suit. Tout d’abord, calculez la taille critique approximative du lot pour chaque type d’accélérateur selon la deuxième équation et la taille du cache KV pour la taille critique du lot selon la première équation. Vous pouvez ensuite utiliser la DRAM disponible sur l'accélérateur pour calculer le nombre minimum d'accélérateurs requis pour s'adapter au cache KV et aux paramètres du modèle. Si vous décidez entre plusieurs accélérateurs, hiérarchisez les accélérateurs par ordre de coût par Go/s de bande passante mémoire le plus bas. Enfin, comparez ces configurations et vérifiez quel est le meilleur coût/jeton pour votre limite supérieure de latence souhaitée.
Sélectionnez une configuration de déploiement de point de terminaison
De nombreux LLM distribués par SageMaker JumpStart utilisent le inférence de génération de texte (TGI) Conteneur SageMaker pour le service de modèle. Le tableau suivant explique comment ajuster divers paramètres de diffusion de modèles pour affecter la diffusion de modèles, ce qui a un impact sur la courbe de latence-débit, ou pour protéger le point de terminaison contre les requêtes qui pourraient surcharger le point de terminaison. Il s'agit des principaux paramètres que vous pouvez utiliser pour configurer le déploiement de votre point de terminaison pour votre cas d'utilisation. Sauf indication contraire, nous utilisons la valeur par défaut paramètres de charge utile de génération de texte ainsi que Variables d'environnement TGI.
| Variable d'environnement | Description | Valeur par défaut de SageMaker JumpStart |
| Configurations de diffusion de modèles | . | . |
MAX_BATCH_PREFILL_TOKENS |
Limite le nombre de jetons dans l'opération de pré-remplissage. Cette opération génère le cache KV pour une nouvelle séquence d'invite d'entrée. Elle est gourmande en mémoire et liée au calcul, cette valeur limite donc le nombre de jetons autorisés dans une seule opération de pré-remplissage. Les étapes de décodage des autres requêtes s'interrompent pendant le pré-remplissage. | 4096 XNUMX (TGI par défaut) ou longueur de contexte maximale prise en charge spécifique au modèle (SageMaker JumpStart fourni), selon la valeur la plus élevée. |
MAX_BATCH_TOTAL_TOKENS |
Contrôle le nombre maximum de jetons à inclure dans un lot lors du décodage, ou un seul passage direct dans le modèle. Idéalement, cela vise à maximiser l’utilisation de tout le matériel disponible. | Non spécifié (TGI par défaut). TGI définira cette valeur par rapport à la mémoire CUDA restante pendant le préchauffage du modèle. |
SM_NUM_GPUS |
Le nombre de fragments à utiliser. C'est-à-dire le nombre de GPU utilisés pour exécuter le modèle en utilisant le parallélisme tensoriel. | Dépend de l’instance (SageMaker JumpStart fourni). Pour chaque instance prise en charge pour un modèle donné, SageMaker JumpStart fournit le meilleur paramètre pour le parallélisme tensoriel. |
| Configurations pour protéger votre point de terminaison (définissez-les pour votre cas d'utilisation) | . | . |
MAX_TOTAL_TOKENS |
Cela limite le budget mémoire d'une requête client unique en limitant le nombre de jetons dans la séquence d'entrée plus le nombre de jetons dans la séquence de sortie (le nombre de jetons dans la séquence de sortie). max_new_tokens paramètre de charge utile). |
Longueur de contexte maximale prise en charge spécifique au modèle. Par exemple, 4096 pour Lama 2. |
MAX_INPUT_LENGTH |
Identifie le nombre maximum autorisé de jetons dans la séquence d'entrée pour une seule demande client. Les éléments à prendre en compte lors de l'augmentation de cette valeur incluent : les séquences d'entrée plus longues nécessitent plus de mémoire, ce qui affecte le traitement par lots continu, et de nombreux modèles ont une longueur de contexte prise en charge qui ne doit pas être dépassée. | Longueur de contexte maximale prise en charge spécifique au modèle. Par exemple, 4095 pour Lama 2. |
MAX_CONCURRENT_REQUESTS |
Nombre maximum de requêtes simultanées autorisées par le point de terminaison déployé. Les nouvelles requêtes au-delà de cette limite généreront immédiatement une erreur de surcharge de modèle afin d'éviter une mauvaise latence pour les requêtes de traitement en cours. | 128 (TGI par défaut). Ce paramètre vous permet d'obtenir un débit élevé pour une variété de cas d'utilisation, mais vous devez épingler le cas échéant pour atténuer les erreurs de délai d'invocation de SageMaker. |
Le serveur TGI utilise le traitement par lots continu, qui regroupe dynamiquement les requêtes simultanées pour partager une seule passe avant d'inférence de modèle. Il existe deux types de passes avant : le pré-remplissage et le décodage. Chaque nouvelle requête doit exécuter une seule passe de pré-remplissage pour remplir le cache KV pour les jetons de séquence d'entrée. Une fois le cache KV rempli, une passe de décodage effectue une seule prédiction du jeton suivant pour toutes les requêtes par lots, qui est répétée de manière itérative pour produire la séquence de sortie. Au fur et à mesure que de nouvelles requêtes sont envoyées au serveur, l'étape de décodage suivante doit attendre afin que l'étape de pré-remplissage puisse s'exécuter pour les nouvelles requêtes. Cela doit se produire avant que ces nouvelles demandes ne soient incluses dans les étapes de décodage ultérieures en continu. En raison de contraintes matérielles, le traitement par lots continu utilisé pour le décodage peut ne pas inclure toutes les requêtes. À ce stade, les requêtes entrent dans une file d’attente de traitement et la latence d’inférence commence à augmenter considérablement avec un gain de débit mineur.
Il est possible de séparer les analyses comparatives de latence LLM en latence de pré-remplissage, latence de décodage et latence de file d'attente. Le temps consommé par chacun de ces composants est de nature fondamentalement différente : le pré-remplissage est un calcul unique, le décodage a lieu une fois pour chaque jeton de la séquence de sortie et la mise en file d'attente implique des processus de traitement par lots sur le serveur. Lorsque plusieurs requêtes simultanées sont en cours de traitement, il devient difficile de démêler les latences de chacun de ces composants, car la latence subie par une requête client donnée implique des latences de file d'attente entraînées par la nécessité de pré-remplir de nouvelles requêtes simultanées ainsi que des latences de file d'attente entraînées par l'inclusion. de la requête dans les processus de décodage par lots. Pour cette raison, cet article se concentre sur la latence de traitement de bout en bout. Le genou dans la courbe latence-débit se produit au point de saturation où les latences de file d’attente commencent à augmenter de manière significative. Ce phénomène se produit pour tout serveur d'inférence de modèle et est piloté par les spécifications de l'accélérateur.
Les exigences courantes lors du déploiement incluent la satisfaction d'un débit minimum requis, d'une latence maximale autorisée, d'un coût horaire maximum et d'un coût maximum pour générer 1 million de jetons. Vous devez conditionner ces exigences aux charges utiles qui représentent les demandes des utilisateurs finaux. Une conception répondant à ces exigences doit prendre en compte de nombreux facteurs, notamment l'architecture spécifique du modèle, la taille du modèle, les types d'instances et le nombre d'instances (mise à l'échelle horizontale). Dans les sections suivantes, nous nous concentrons sur le déploiement de points de terminaison pour minimiser la latence, maximiser le débit et minimiser les coûts. Cette analyse prend en compte 512 jetons au total et 256 jetons de sortie.
Minimiser la latence
La latence est une exigence importante dans de nombreux cas d’utilisation en temps réel. Dans le tableau suivant, nous examinons la latence minimale pour chaque modèle et chaque type d'instance. Vous pouvez obtenir une latence minimale en définissant MAX_CONCURRENT_REQUESTS = 1.
| Latence minimale (ms/jeton) | |||||
| ID du modèle | ml.g5.2xlarge | ml.g5.12xlarge | ml.g5.48xlarge | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Lama 2 7B | 33 | 17 | 18 | 20 | - |
| Bavarder | 33 | 17 | 18 | 20 | - |
| Lama 2 13B | - | 22 | 23 | 23 | - |
| Bavarder | - | 23 | 23 | 23 | - |
| Lama 2 70B | - | - | 57 | 43 | - |
| Bavarder | - | - | 57 | 45 | - |
| Mistral7B | 35 | - | - | - | - |
| Instruire Mistral 7B | 35 | - | - | - | - |
| Mixtral 8x7B | - | - | 33 | 27 | - |
| Falcon 7B | 33 | - | - | - | - |
| Instruire le Falcon 7B | 33 | - | - | - | - |
| Falcon 40B | - | 53 | 33 | 27 | - |
| Instruire le Falcon 40B | - | 53 | 33 | 28 | - |
| Falcon 180B | - | - | - | - | 42 |
| Bavarder | - | - | - | - | 42 |
Pour obtenir une latence minimale pour un modèle, vous pouvez utiliser le code suivant en remplaçant l'ID de modèle et le type d'instance souhaités :
Notez que les chiffres de latence changent en fonction du nombre de jetons d'entrée et de sortie. Cependant, le processus de déploiement reste le même à l'exception des variables d'environnement MAX_INPUT_TOKENS ainsi que MAX_TOTAL_TOKENS. Ici, ces variables d'environnement sont définies pour aider à garantir les exigences de latence des points de terminaison, car des séquences d'entrée plus grandes peuvent violer les exigences de latence. Notez que SageMaker JumpStart fournit déjà les autres variables d'environnement optimales lors de la sélection du type d'instance ; par exemple, utiliser ml.g5.12xlarge définira SM_NUM_GPUS à 4 dans l’environnement modèle.
Maximiser le débit
Dans cette section, nous maximisons le nombre de jetons générés par seconde. Ceci est généralement réalisé au maximum de requêtes simultanées valides pour le modèle et le type d'instance. Dans le tableau suivant, nous signalons le débit atteint à la valeur de requête simultanée la plus élevée atteinte avant de rencontrer un délai d'expiration d'appel SageMaker pour une requête.
| Débit maximum (jetons/s), requêtes simultanées | |||||
| ID du modèle | ml.g5.2xlarge | ml.g5.12xlarge | ml.g5.48xlarge | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Lama 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Bavarder | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Lama 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Bavarder | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Lama 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Bavarder | - | - | 114 (16) | 1546 (256) | - |
| Mistral7B | 947 (64) | - | - | - | - |
| Instruire Mistral 7B | 986 (128) | - | - | - | - |
| Mixtral 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Falcon 7B | 1340 (128) | - | - | - | - |
| Instruire le Falcon 7B | 1313 (128) | - | - | - | - |
| Falcon 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Instruire le Falcon 40B | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Falcon 180B | - | - | - | - | 1100 (128) |
| Bavarder | - | - | - | - | 1081 (128) |
Pour obtenir un débit maximal pour un modèle, vous pouvez utiliser le code suivant :
Notez que le nombre maximum de requêtes simultanées dépend du type de modèle, du type d'instance, du nombre maximum de jetons d'entrée et du nombre maximum de jetons de sortie. Par conséquent, vous devez définir ces paramètres avant de définir MAX_CONCURRENT_REQUESTS.
Notez également qu'un utilisateur souhaitant minimiser la latence est souvent en désaccord avec un utilisateur souhaitant maximiser le débit. Le premier s'intéresse aux réponses en temps réel, tandis que le second s'intéresse au traitement par lots de telle sorte que la file d'attente des points de terminaison soit toujours saturée, minimisant ainsi les temps d'arrêt du traitement. Les utilisateurs qui souhaitent maximiser le débit en fonction des exigences de latence sont souvent intéressés à opérer au genou dans la courbe latence-débit.
Minimiser les coûts
La première option pour minimiser les coûts consiste à minimiser le coût horaire. Avec cela, vous pouvez déployer un modèle sélectionné sur l'instance SageMaker avec le coût horaire le plus bas. Pour connaître la tarification en temps réel des instances SageMaker, reportez-vous à Tarification d'Amazon SageMaker. En général, le type d'instance par défaut pour les LLM SageMaker JumpStart est l'option de déploiement la moins coûteuse.
La deuxième option pour minimiser les coûts consiste à minimiser le coût de génération d'un million de jetons. Il s'agit d'une simple transformation du tableau dont nous avons discuté précédemment pour maximiser le débit, où vous pouvez d'abord calculer le temps nécessaire en heures pour générer 1 million de jetons (1e1 / débit / 6). Vous pouvez ensuite multiplier ce temps pour générer 3600 million de jetons avec le prix horaire de l'instance SageMaker spécifiée.
Notez que les instances avec le coût horaire le plus bas ne sont pas les mêmes que les instances avec le coût le plus bas pour générer 1 million de jetons. Par exemple, si les demandes d'appel sont sporadiques, une instance avec le coût horaire le plus bas pourrait être optimale, alors que dans les scénarios de limitation, le coût le plus bas pour générer un million de jetons pourrait être plus approprié.
Compromis tenseur parallèle et multimodèle
Dans toutes les analyses précédentes, nous avons envisagé de déployer une seule réplique de modèle avec un degré de parallèle tenseur égal au nombre de GPU sur le type d'instance de déploiement. Il s'agit du comportement par défaut de SageMaker JumpStart. Cependant, comme indiqué précédemment, le partitionnement d'un modèle ne peut améliorer la latence et le débit du modèle que jusqu'à une certaine limite, au-delà de laquelle les exigences de communication entre les appareils dominent le temps de calcul. Cela implique qu'il est souvent avantageux de déployer plusieurs modèles avec un degré parallèle de tenseur inférieur sur une seule instance plutôt qu'un seul modèle avec un degré parallèle de tenseur plus élevé.
Ici, nous déployons les points de terminaison Llama 2 7B et 13B sur des instances ml.p4d.24xlarge avec des degrés de tenseur parallèle (TP) de 1, 2, 4 et 8. Pour plus de clarté dans le comportement du modèle, chacun de ces points de terminaison ne charge qu'un seul modèle.
| . | Débit (jetons/s) | Latence (ms/jeton) | ||||||||||||||||||
| Demandes simultanées | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Diplôme TP | Lama 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Lama 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Nos analyses précédentes ont déjà montré des avantages significatifs en matière de débit sur les instances ml.p4d.24xlarge, ce qui se traduit souvent par de meilleures performances en termes de coût pour générer 1 million de jetons par rapport à la famille d'instances g5 dans des conditions de charge de requêtes simultanées élevées. Cette analyse démontre clairement que vous devez considérer le compromis entre le partitionnement du modèle et la réplication du modèle au sein d'une seule instance ; autrement dit, un modèle entièrement partitionné ne constitue généralement pas la meilleure utilisation des ressources de calcul ml.p4d.24xlarge pour les familles de modèles 7B et 13B. En fait, pour la famille de modèles 7B, vous obtenez le meilleur débit pour une réplique de modèle unique avec un degré parallèle de tenseur de 4 au lieu de 8.
À partir de là, vous pouvez extrapoler que la configuration de débit la plus élevée pour le modèle 7B implique un degré tensoriel parallèle de 1 avec huit répliques de modèle, et que la configuration de débit la plus élevée pour le modèle 13B est probablement un degré tensoriel parallèle de 2 avec quatre répliques de modèle. Pour en savoir plus sur la façon d'y parvenir, reportez-vous à Réduisez les coûts de déploiement de modèles de 50 % en moyenne grâce aux dernières fonctionnalités d'Amazon SageMaker, qui démontre l'utilisation de points de terminaison basés sur des composants d'inférence. En raison des techniques d'équilibrage de charge, du routage des serveurs et du partage des ressources du processeur, vous ne pourrez peut-être pas obtenir des améliorations de débit exactement égales au nombre de répliques multiplié par le débit d'une seule réplique.
Mise à l'échelle horizontale
Comme observé précédemment, chaque déploiement de point de terminaison a une limitation sur le nombre de requêtes simultanées en fonction du nombre de jetons d'entrée et de sortie ainsi que du type d'instance. Si cela ne répond pas à vos exigences en matière de débit ou de demandes simultanées, vous pouvez évoluer pour utiliser plusieurs instances derrière le point de terminaison déployé. SageMaker effectue automatiquement l'équilibrage de charge des requêtes entre les instances. Par exemple, le code suivant déploie un point de terminaison pris en charge par trois instances :
Le tableau suivant montre le gain de débit en tant que facteur du nombre d'instances pour le modèle Llama 2 7B.
| . | . | Débit (jetons/s) | Latence (ms/jeton) | ||||||||||||||
| . | Demandes simultanées | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Nombre d'instances | Type d'instance | Nombre total de jetons : 512, Nombre de jetons de sortie : 256 | |||||||||||||||
| 1 | ml.g5.2xlarge | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xlarge | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xlarge | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Notamment, le coude de la courbe latence-débit se déplace vers la droite, car un nombre d'instances plus élevé peut gérer un plus grand nombre de requêtes simultanées au sein du point de terminaison multi-instance. Pour ce tableau, la valeur des demandes simultanées concerne l'ensemble du point de terminaison, et non le nombre de demandes simultanées que chaque instance individuelle reçoit.
Vous pouvez également utiliser la mise à l'échelle automatique, une fonctionnalité permettant de surveiller vos charges de travail et d'ajuster dynamiquement la capacité afin de maintenir des performances stables et prévisibles au coût le plus bas possible. Cela dépasse la portée de cet article. Pour en savoir plus sur l'autoscaling, reportez-vous à Configuration des points de terminaison d'inférence d'autoscaling dans Amazon SageMaker.
Appeler un point de terminaison avec des requêtes simultanées
Supposons que vous disposiez d'un grand nombre de requêtes que vous souhaitez utiliser pour générer des réponses à partir d'un modèle déployé dans des conditions de débit élevé. Par exemple, dans le bloc de code suivant, nous compilons une liste de 1,000 100 charges utiles, chaque charge utile demandant la génération de 100,000 jetons. Au total, nous demandons la génération de XNUMX XNUMX tokens.
Lors de l'envoi d'un grand nombre de requêtes à l'API d'exécution SageMaker, vous pouvez rencontrer des erreurs de limitation. Pour atténuer ce problème, vous pouvez créer un client d'exécution SageMaker personnalisé qui augmente le nombre de nouvelles tentatives. Vous pouvez fournir l'objet de session SageMaker résultant au JumpStartModel constructeur ou sagemaker.predictor.retrieve_default si vous souhaitez attacher un nouveau prédicteur à un point de terminaison déjà déployé. Dans le code suivant, nous utilisons cet objet de session lors du déploiement d'un modèle Llama 2 avec les configurations SageMaker JumpStart par défaut :
Ce point de terminaison déployé a MAX_CONCURRENT_REQUESTS = 128 par défaut. Dans le bloc suivant, nous utilisons la bibliothèque concurrent futures pour itérer sur l'appel du point de terminaison pour toutes les charges utiles avec 128 threads de travail. Au maximum, le point final traitera 128 requêtes simultanées, et chaque fois qu'une requête renvoie une réponse, l'exécuteur enverra immédiatement une nouvelle requête au point final.
Cela aboutit à la génération de 100,000 1255 jetons au total avec un débit de 5.2 80 jetons/s sur une seule instance ml.gXNUMXxlarge. Le traitement prend environ XNUMX secondes.
Notez que cette valeur de débit est sensiblement différente du débit maximum pour Llama 2 7B sur ml.g5.2xlarge dans les tableaux précédents de cet article (486 jetons/s pour 64 requêtes simultanées). En effet, la charge utile d'entrée utilise 8 jetons au lieu de 256, le nombre de jetons de sortie est de 100 au lieu de 256 et le nombre de jetons plus petit permet 128 requêtes simultanées. Ceci est un dernier rappel que tous les chiffres de latence et de débit dépendent de la charge utile ! La modification du nombre de jetons de charge utile affectera les processus de traitement par lots pendant la diffusion du modèle, ce qui affectera à son tour les temps de préremplissage, de décodage et d'attente émergents pour votre application.
Conclusion
Dans cet article, nous avons présenté l'analyse comparative des LLM SageMaker JumpStart, notamment Llama 2, Mistral et Falcon. Nous avons également présenté un guide pour optimiser la latence, le débit et le coût de la configuration de déploiement de votre point de terminaison. Vous pouvez commencer en exécutant le cahier associé pour comparer votre cas d'utilisation.
À propos des auteurs
 Dr Kyle Ulrich est un scientifique appliqué au sein de l'équipe Amazon SageMaker JumpStart. Ses intérêts de recherche comprennent les algorithmes d'apprentissage automatique évolutifs, la vision par ordinateur, les séries chronologiques, les processus bayésiens non paramétriques et gaussiens. Son doctorat est de l'Université Duke et il a publié des articles dans NeurIPS, Cell et Neuron.
Dr Kyle Ulrich est un scientifique appliqué au sein de l'équipe Amazon SageMaker JumpStart. Ses intérêts de recherche comprennent les algorithmes d'apprentissage automatique évolutifs, la vision par ordinateur, les séries chronologiques, les processus bayésiens non paramétriques et gaussiens. Son doctorat est de l'Université Duke et il a publié des articles dans NeurIPS, Cell et Neuron.
 Dr. Vivek Madan est un scientifique appliqué au sein de l'équipe Amazon SageMaker JumpStart. Il a obtenu son doctorat à l'Université de l'Illinois à Urbana-Champaign et a été chercheur postdoctoral à Georgia Tech. Il est un chercheur actif en apprentissage automatique et en conception d'algorithmes et a publié des articles dans les conférences EMNLP, ICLR, COLT, FOCS et SODA.
Dr. Vivek Madan est un scientifique appliqué au sein de l'équipe Amazon SageMaker JumpStart. Il a obtenu son doctorat à l'Université de l'Illinois à Urbana-Champaign et a été chercheur postdoctoral à Georgia Tech. Il est un chercheur actif en apprentissage automatique et en conception d'algorithmes et a publié des articles dans les conférences EMNLP, ICLR, COLT, FOCS et SODA.
 Dr Ashish Khetan est un scientifique appliqué senior chez Amazon SageMaker JumpStart et aide à développer des algorithmes d'apprentissage automatique. Il a obtenu son doctorat à l'Université de l'Illinois à Urbana-Champaign. Il est un chercheur actif en apprentissage automatique et en inférence statistique, et a publié de nombreux articles dans les conférences NeurIPS, ICML, ICLR, JMLR, ACL et EMNLP.
Dr Ashish Khetan est un scientifique appliqué senior chez Amazon SageMaker JumpStart et aide à développer des algorithmes d'apprentissage automatique. Il a obtenu son doctorat à l'Université de l'Illinois à Urbana-Champaign. Il est un chercheur actif en apprentissage automatique et en inférence statistique, et a publié de nombreux articles dans les conférences NeurIPS, ICML, ICLR, JMLR, ACL et EMNLP.
 Joao Moura est architecte senior de solutions spécialisées en IA/ML chez AWS. João aide les clients AWS – des petites startups aux grandes entreprises – à former et déployer efficacement de grands modèles et, plus largement, à créer des plates-formes ML sur AWS.
Joao Moura est architecte senior de solutions spécialisées en IA/ML chez AWS. João aide les clients AWS – des petites startups aux grandes entreprises – à former et déployer efficacement de grands modèles et, plus largement, à créer des plates-formes ML sur AWS.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/

