Veriff est un partenaire de plateforme de vérification d'identité pour les organisations innovantes axées sur la croissance, notamment des pionniers des services financiers, des FinTech, de la cryptographie, des jeux, de la mobilité et des marchés en ligne. Ils fournissent une technologie avancée qui combine l’automatisation basée sur l’IA avec des commentaires humains, des informations approfondies et une expertise.

Veriff fournit une infrastructure éprouvée qui permet à ses clients d'avoir confiance dans les identités et les attributs personnels de leurs utilisateurs à tous les moments pertinents de leur parcours client. Veriff bénéficie de la confiance de clients tels que Bolt, Deel, Monese, Starship, Super Awesome, Trustpilot et Wise.
En tant que solution basée sur l'IA, Veriff doit créer et exécuter des dizaines de modèles d'apprentissage automatique (ML) de manière rentable. Ces modèles vont des modèles arborescents légers aux modèles de vision par ordinateur d'apprentissage en profondeur, qui doivent fonctionner sur des GPU pour atteindre une faible latence et améliorer l'expérience utilisateur. Veriff ajoute également actuellement davantage de produits à son offre, ciblant une solution hyper-personnalisée pour ses clients. Servir différents modèles pour différents clients ajoute au besoin d'une solution de gestion de modèles évolutive.
Dans cet article, nous vous montrons comment Veriff a standardisé son workflow de déploiement de modèles en utilisant Amazon Sage Maker, réduisant ainsi les coûts et le temps de développement.
Défis d’infrastructure et de développement
L'architecture backend de Veriff est basée sur un modèle de microservices, avec des services exécutés sur différents clusters Kubernetes hébergés sur l'infrastructure AWS. Cette approche a été initialement utilisée pour tous les services de l’entreprise, y compris les microservices qui exécutent des modèles ML de vision par ordinateur coûteux.
Certains de ces modèles nécessitaient un déploiement sur des instances GPU. Conscient du coût comparativement plus élevé des types d'instances basés sur GPU, Veriff a développé un solution personnalisée sur Kubernetes pour partager les ressources d'un GPU donné entre différentes répliques de service. Un seul GPU dispose généralement de suffisamment de VRAM pour contenir en mémoire plusieurs modèles de vision par ordinateur de Veriff.
Bien que la solution ait effectivement réduit les coûts du GPU, elle s'accompagnait également de la contrainte selon laquelle les data scientists devaient indiquer à l'avance la quantité de mémoire GPU dont leur modèle aurait besoin. De plus, les DevOps devaient provisionner manuellement les instances GPU en réponse aux modèles de demande. Cela a entraîné une surcharge opérationnelle et un surprovisionnement des instances, ce qui a abouti à un profil de coûts sous-optimal.
Outre le provisionnement du GPU, cette configuration nécessitait également que les data scientists créent un wrapper d'API REST pour chaque modèle, ce qui était nécessaire pour fournir une interface générique à utiliser par d'autres services de l'entreprise et pour encapsuler le prétraitement et le post-traitement des données du modèle. Ces API nécessitaient du code de qualité production, ce qui rendait difficile la production de modèles pour les data scientists.
L'équipe de la plateforme de science des données de Veriff a recherché des solutions alternatives à cette approche. L'objectif principal était d'accompagner les data scientists de l'entreprise dans une meilleure transition de la recherche à la production en fournissant des pipelines de déploiement plus simples. L'objectif secondaire était de réduire les coûts opérationnels de provisionnement des instances GPU.
Vue d'ensemble de la solution
Veriff nécessitait une nouvelle solution qui résolvait deux problèmes :
- Permettre de créer facilement des wrappers d'API REST autour de modèles ML
- Autoriser la gestion de la capacité des instances GPU provisionnées de manière optimale et, si possible, automatiquement
En fin de compte, l'équipe de la plateforme ML a convergé vers la décision d'utiliser Points de terminaison multimodèles Sagemaker (MME). Cette décision a été motivée par le support de MME pour NVIDIA Serveur d'inférence Triton (un serveur axé sur le ML qui facilite l'encapsulation de modèles sous forme d'API REST ; Veriff expérimentait également déjà Triton), ainsi que sa capacité à gérer nativement la mise à l'échelle automatique des instances GPU via de simples politiques de mise à l'échelle automatique.
Deux MME ont été créés chez Veriff, un pour la mise en scène et un pour la production. Cette approche leur permet d'exécuter des étapes de test dans un environnement de test sans affecter les modèles de production.
MME SageMaker
SageMaker est un service entièrement géré qui offre aux développeurs et aux data scientists la possibilité de créer, former et déployer rapidement des modèles ML. Les MME SageMaker fournissent une solution évolutive et rentable pour déployer un grand nombre de modèles pour l'inférence en temps réel. Les MME utilisent un conteneur de service partagé et une flotte de ressources qui peuvent utiliser des instances accélérées telles que des GPU pour héberger tous vos modèles. Cela réduit les coûts d'hébergement en maximisant l'utilisation des points de terminaison par rapport à l'utilisation de points de terminaison à modèle unique. Cela réduit également les frais généraux de déploiement, car SageMaker gère le chargement et le déchargement des modèles en mémoire et les met à l'échelle en fonction des modèles de trafic du terminal. De plus, tous les points de terminaison en temps réel SageMaker bénéficient de fonctionnalités intégrées pour gérer et surveiller les modèles, telles que l'inclusion variantes d'ombre, mise à l'échelle automatique, et intégration native avec Amazon Cloud Watch (pour plus d'informations, reportez-vous à Métriques CloudWatch pour les déploiements de points de terminaison multimodèles).
Modèles d'ensembles Triton personnalisés
Il y a plusieurs raisons pour lesquelles Veriff a décidé d'utiliser Triton Inference Server, les principales étant :
- Il permet aux data scientists de créer des API REST à partir de modèles en organisant les fichiers d'artefacts de modèle dans un format de répertoire standard (solution sans code)
- Il est compatible avec tous les principaux frameworks d'IA (PyTorch, Tensorflow, XGBoost, etc.)
- Il fournit des optimisations de bas niveau et de serveur spécifiques au ML telles que traitement par lots dynamique de demandes
L'utilisation de Triton permet aux data scientists de déployer facilement des modèles, car ils n'ont besoin que de créer des référentiels de modèles formatés au lieu d'écrire du code pour créer des API REST (Triton prend également en charge Modèles Python si une logique d'inférence personnalisée est requise). Cela réduit le temps de déploiement des modèles et donne aux data scientists plus de temps pour se concentrer sur la création de modèles plutôt que sur leur déploiement.
Une autre caractéristique importante de Triton est qu'il vous permet de créer ensembles de modèles, qui sont des groupes de modèles enchaînés. Ces ensembles peuvent fonctionner comme s’il s’agissait d’un seul modèle Triton. Veriff utilise actuellement cette fonctionnalité pour déployer une logique de prétraitement et de post-traitement avec chaque modèle ML à l'aide de modèles Python (comme mentionné précédemment), garantissant ainsi l'absence de divergences dans les données d'entrée ou la sortie du modèle lorsque les modèles sont utilisés en production.
Voici à quoi ressemble un référentiel de modèles Triton typique pour cette charge de travail :
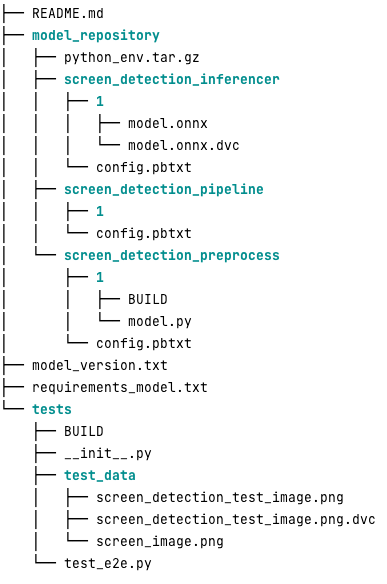
La model.py Le fichier contient du code de prétraitement et de post-traitement. Les poids du modèle entraîné sont dans le screen_detection_inferencer répertoire, sous version modèle 1 (le modèle est au format ONNX dans cet exemple, mais peut également être au format TensorFlow, PyTorch ou autre). La définition du modèle d'ensemble se trouve dans le screen_detection_pipeline répertoire, où les entrées et sorties entre les étapes sont mappées dans un fichier de configuration.
Les dépendances supplémentaires nécessaires à l'exécution des modèles Python sont détaillées dans un requirements.txt et doivent être compressés par conda pour créer un environnement Conda (python_env.tar.gz). Pour plus d'informations, reportez-vous à Gestion du runtime et des bibliothèques Python. De plus, les fichiers de configuration pour les étapes Python doivent pointer vers python_env.tar.gz utilisant l' EXECUTION_ENV_PATH Directive.
Le dossier modèle doit ensuite être compressé en TAR et renommé en utilisant model_version.txt. Finalement, le résultat <model_name>_<model_version>.tar.gz le fichier est copié dans le Service de stockage simple Amazon (Amazon S3) connecté au MME, permettant à SageMaker de détecter et de servir le modèle.
Versionnement du modèle et déploiement continu
Comme la section précédente l’a montré, la création d’un référentiel de modèles Triton est simple. Cependant, l’exécution de toutes les étapes nécessaires à son déploiement est fastidieuse et sujette aux erreurs si elle est exécutée manuellement. Pour surmonter ce problème, Veriff a construit un monorepo contenant tous les modèles à déployer sur les MME, où les data scientists collaborent selon une approche de type Gitflow. Ce monorepo présente les caractéristiques suivantes :
- Il est géré en utilisant Pantalons.
- Des outils de qualité de code tels que Black et MyPy sont appliqués à l'aide de Pants.
- Des tests unitaires sont définis pour chaque modèle, qui vérifient que la sortie du modèle est la sortie attendue pour une entrée de modèle donnée.
- Les poids des modèles sont stockés à côté des référentiels de modèles. Ces poids peuvent être de gros fichiers binaires, donc DVC est utilisé pour les synchroniser avec Git de manière versionnée.
Ce monorepo est intégré à un outil d'intégration continue (CI). Pour chaque nouveau push vers le dépôt ou nouveau modèle, les étapes suivantes sont exécutées :
- Passez le contrôle de qualité du code.
- Téléchargez les poids des modèles.
- Créez l'environnement Conda.
- Lancez un serveur Triton à l'aide de l'environnement Conda et utilisez-le pour traiter les requêtes définies dans les tests unitaires.
- Construisez le fichier TAR du modèle final (
<model_name>_<model_version>.tar.gz).
Ces étapes garantissent que les modèles ont la qualité requise pour le déploiement, donc pour chaque poussée vers une branche de dépôt, le fichier TAR résultant est copié (dans une autre étape CI) dans le compartiment intermédiaire S3. Lorsque les push sont effectués dans la branche principale, le fichier de modèle est copié dans le compartiment S3 de production. Le diagramme suivant représente ce système CI/CD.
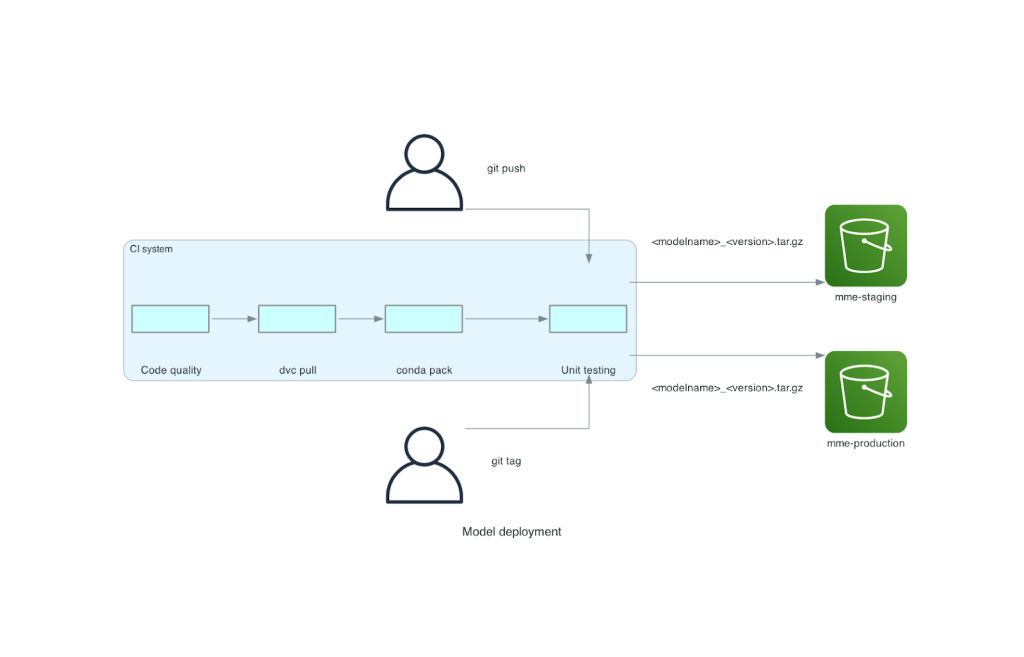
Avantages en termes de coût et de vitesse de déploiement
L'utilisation de MME permet à Veriff d'utiliser une approche monorepo pour déployer des modèles en production. En résumé, le nouveau workflow de déploiement de modèles de Veriff comprend les étapes suivantes :
- Créez une branche dans le monorepo avec le nouveau modèle ou la nouvelle version du modèle.
- Définir et exécuter des tests unitaires sur une machine de développement.
- Poussez la branche lorsque le modèle est prêt à être testé dans l’environnement de test.
- Fusionnez la branche dans main lorsque le modèle est prêt à être utilisé en production.
Avec cette nouvelle solution en place, le déploiement d'un modèle chez Veriff est une partie simple du processus de développement. Le temps de développement d’un nouveau modèle est passé de 10 jours à 2 jours en moyenne.
Les fonctionnalités de provisionnement de l'infrastructure gérée et de mise à l'échelle automatique de SageMaker ont apporté des avantages supplémentaires à Veriff. Ils ont utilisé le AppelsParInstance Métrique CloudWatch évolutive en fonction des modèles de trafic, permettant ainsi de réaliser des économies sans sacrifier la fiabilité. Pour définir la valeur seuil de la métrique, ils ont effectué des tests de charge sur le point de terminaison intermédiaire afin de trouver le meilleur compromis entre latence et coût.
Après avoir déployé sept modèles de production sur les MME et analysé les dépenses, Veriff a signalé une réduction de 75 % des coûts du modèle GPU par rapport à la solution originale basée sur Kubernetes. Les coûts opérationnels ont également été réduits, car le fardeau du provisionnement manuel des instances a été allégé pour les ingénieurs DevOps de l'entreprise.
Conclusion
Dans cet article, nous avons expliqué pourquoi Veriff a choisi les MME Sagemaker plutôt que le déploiement de modèles autogérés sur Kubernetes. SageMaker assume le gros du travail indifférencié, permettant à Veriff de réduire le temps de développement des modèles, d'augmenter l'efficacité de l'ingénierie et de réduire considérablement le coût de l'inférence en temps réel tout en maintenant les performances nécessaires à ses opérations critiques. Enfin, nous avons présenté le pipeline CI/CD de déploiement de modèles simple mais efficace et le mécanisme de gestion des versions de modèles de Veriff, qui peuvent être utilisés comme implémentation de référence pour combiner les meilleures pratiques de développement logiciel et les MME SageMaker. Vous pouvez trouver des exemples de code sur l'hébergement de plusieurs modèles à l'aide de SageMaker MME sur GitHub.
À propos des auteurs
 Ricard Borras est senior machine learning chez Veriff, où il dirige les efforts MLOps au sein de l'entreprise. Il aide les data scientists à créer des produits IA/ML plus rapides et meilleurs en créant une plate-forme de science des données au sein de l'entreprise et en combinant plusieurs solutions open source avec les services AWS.
Ricard Borras est senior machine learning chez Veriff, où il dirige les efforts MLOps au sein de l'entreprise. Il aide les data scientists à créer des produits IA/ML plus rapides et meilleurs en créant une plate-forme de science des données au sein de l'entreprise et en combinant plusieurs solutions open source avec les services AWS.
 Joao Moura est un architecte de solutions spécialisé en IA/ML chez AWS, basé en Espagne. Il aide les clients avec la formation à grande échelle et l'optimisation des inférences de modèles d'apprentissage profond, et plus largement dans la création de plates-formes de ML à grande échelle sur AWS.
Joao Moura est un architecte de solutions spécialisé en IA/ML chez AWS, basé en Espagne. Il aide les clients avec la formation à grande échelle et l'optimisation des inférences de modèles d'apprentissage profond, et plus largement dans la création de plates-formes de ML à grande échelle sur AWS.
 Michel Ferreira travaille en tant qu'architecte de solutions senior chez AWS basé à Helsinki, en Finlande. L'IA/ML a toujours été un intérêt et il a aidé plusieurs clients à intégrer Amazon SageMaker dans leurs flux de travail ML.
Michel Ferreira travaille en tant qu'architecte de solutions senior chez AWS basé à Helsinki, en Finlande. L'IA/ML a toujours été un intérêt et il a aidé plusieurs clients à intégrer Amazon SageMaker dans leurs flux de travail ML.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/how-veriff-decreased-deployment-time-by-80-using-amazon-sagemaker-multi-model-endpoints/

