L'ingénierie des données joue un rôle central dans le vaste écosystème de données en collectant, transformant et fournissant des données essentielles à l'analyse, au reporting et à l'apprentissage automatique. Les futurs ingénieurs de données recherchent souvent des projets du monde réel pour acquérir une expérience pratique et mettre en valeur leur expertise. Cet article présente les 20 meilleures idées de projets d'ingénierie de données avec leur code source. Que vous soyez débutant, ingénieur de niveau intermédiaire ou praticien avancé, ces projets offrent une excellente opportunité d'affiner vos compétences en ingénierie de données.
Table des matières
Projets d'ingénierie de données pour les débutants
1. Infrastructure IoT intelligente
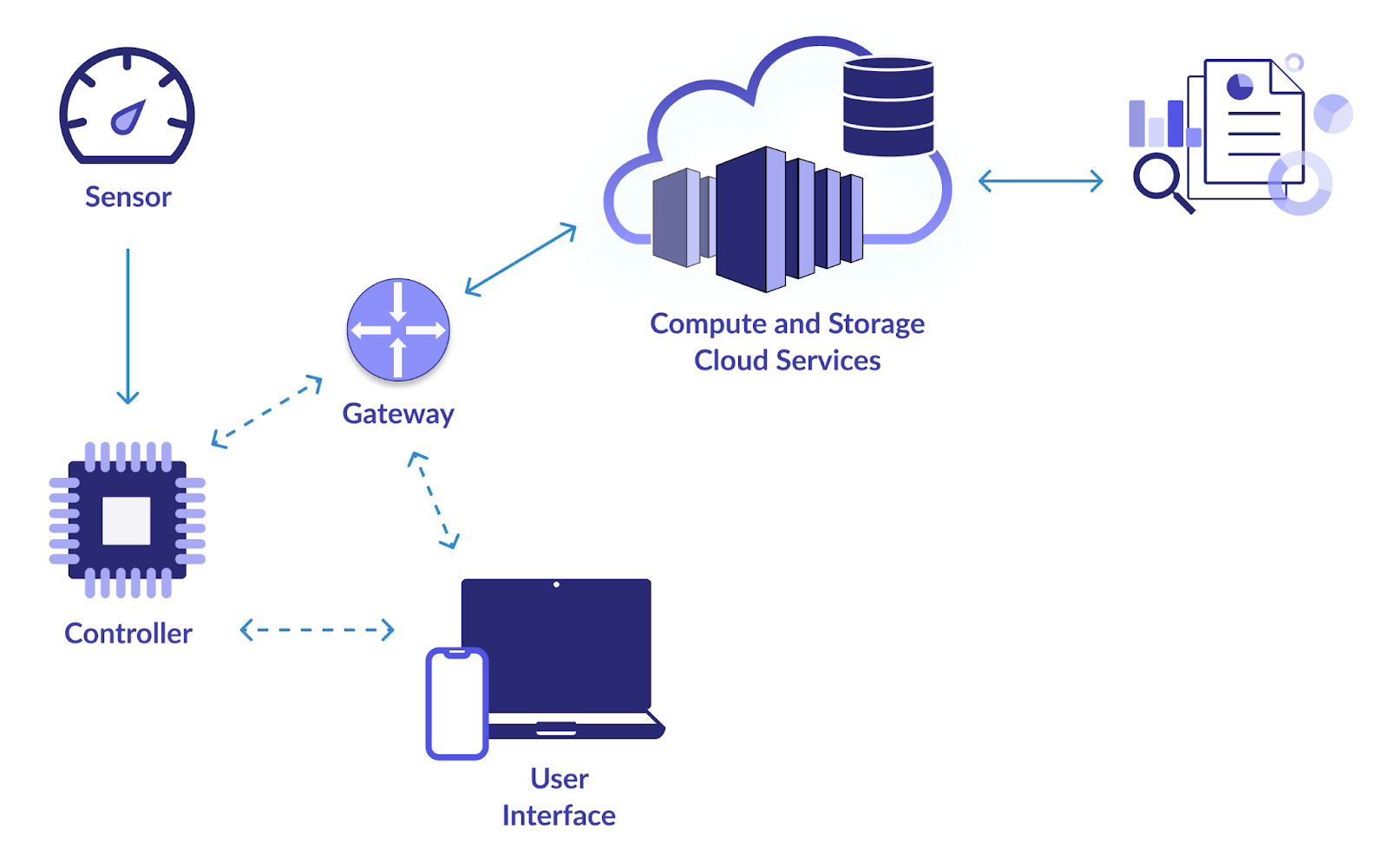
Objectif
L'objectif principal de ce projet est d'établir un pipeline de données fiable pour collecter et analyser les données des appareils IoT (Internet des objets). Les webcams, les capteurs de température, les détecteurs de mouvement et autres appareils IoT génèrent tous beaucoup de données. Vous souhaitez concevoir un système pour consommer, stocker, traiter et analyser efficacement ces données. Ce faisant, une surveillance en temps réel et une prise de décision basée sur les enseignements tirés des données IoT sont rendues possibles.
Comment résoudre?
- Utilisez des technologies telles qu'Apache Kafka ou MQTT pour une ingestion efficace des données à partir d'appareils IoT. Ces technologies prennent en charge des flux de données à haut débit.
- Utilisez des bases de données évolutives comme Apache Cassandra ou MongoDB pour stocker les données IoT entrantes. Ces bases de données NoSQL peuvent gérer le volume et la variété des données IoT.
- Implémentez le traitement des données en temps réel à l'aide d'Apache Spark Streaming ou d'Apache Flink. Ces frameworks vous permettent d'analyser et de transformer les données au fur et à mesure de leur arrivée, ce qui les rend adaptées à la surveillance en temps réel.
- Utilisez des outils de visualisation tels que Grafana ou Kibana pour créer des tableaux de bord qui fournissent des informations sur les données IoT. Les visualisations en temps réel peuvent aider les parties prenantes à prendre des décisions éclairées.
Cliquez ici pour vérifier le code source
2. Analyse des données aéronautiques

Objectif
Pour collecter, traiter et analyser des données aéronautiques provenant de nombreuses sources, notamment la Federal Aviation Administration (FAA), les compagnies aériennes et les aéroports, ce projet tente de développer un pipeline de données. Les données aéronautiques comprennent les vols, les aéroports, la météo et la démographie des passagers. Votre objectif est d'extraire des informations significatives de ces données pour améliorer la planification des vols, renforcer les mesures de sécurité et optimiser divers aspects de l'industrie aéronautique.
Comment résoudre?
- Apache Nifi ou AWS Kinesis peuvent être utilisés pour l'ingestion de données provenant de diverses sources.
- Stockez les données traitées dans des entrepôts de données comme Amazon Redshift ou Google BigQuery pour des requêtes et des analyses efficaces.
- Utilisez Python avec des bibliothèques comme Pandas et Matplotlib pour analyser des données aéronautiques approfondies. Cela peut impliquer d’identifier les tendances en matière de retards de vol, d’optimiser les itinéraires et d’évaluer les tendances des passagers.
- Des outils tels que Tableau ou Power BI peuvent être utilisés pour créer des visualisations informatives qui aident les parties prenantes à prendre des décisions basées sur les données dans le secteur de l'aviation.
Cliquez ici pour voir le code source
3. Prévision de la demande d’expédition et de distribution
Objectif
Dans ce projet, votre objectif est de créer un pipeline ETL (Extract, Transform, Load) robuste qui traite les données d'expédition et de distribution. En utilisant des données historiques, vous construirez un système de prévision de la demande qui prédit la demande future de produits dans le contexte de l'expédition et de la distribution. Ceci est crucial pour optimiser la gestion des stocks, réduire les coûts opérationnels et garantir des livraisons dans les délais.
Comment résoudre?
- Apache NiFi ou Talend peuvent être utilisés pour créer le pipeline ETL, qui extraira les données de diverses sources, les transformera et les chargera dans une solution de stockage de données appropriée.
- Utilisez des outils comme Python ou Apache Spark pour les tâches de transformation de données. Vous devrez peut-être nettoyer, regrouper et prétraiter les données pour les rendre adaptées aux modèles de prévision.
- Mettez en œuvre des modèles de prévision tels que ARIMA (AutoRegressive Integrated Moving Average) ou Prophet pour prédire la demande avec précision.
- Stockez les données nettoyées et transformées dans des bases de données comme PostgreSQL ou MySQL.
Cliquez ici pour voir le code source de ce projet d'ingénierie de données,
4. Analyse des données d'événement

Objectif
Créez un pipeline de données qui collecte des informations sur divers événements, notamment des conférences, des événements sportifs, des concerts et des rassemblements sociaux. Le traitement des données en temps réel, l'analyse des sentiments des publications sur les réseaux sociaux sur ces événements et la création de visualisations pour montrer les tendances et les informations en temps réel font tous partie du projet.
Comment résoudre?
- En fonction des sources de données d'événement, vous pouvez utiliser l'API Twitter pour collecter des tweets, du web scraping pour des sites Web liés à des événements ou d'autres méthodes d'ingestion de données.
- Utilisez des techniques de traitement du langage naturel (NLP) en Python pour effectuer une analyse des sentiments sur les publications sur les réseaux sociaux. Des outils comme NLTK ou spaCy peuvent être précieux.
- Utilisez des technologies de streaming comme Apache Kafka ou Apache Flink pour le traitement et l'analyse des données en temps réel.
- Créez des tableaux de bord et des visualisations interactifs à l'aide de frameworks tels que Dash ou Plotly pour présenter des informations liées aux événements dans un format convivial.
Cliquez ici pour vérifier le code source.
5. Projet d'analyse des journaux
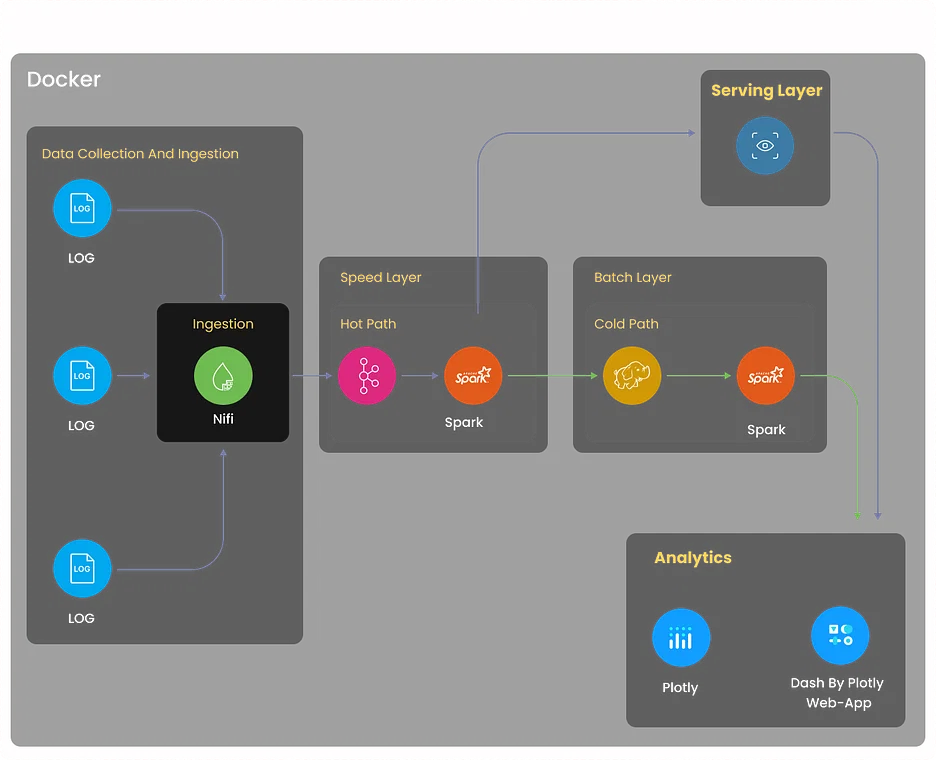
Objectif
Créez un système complet d'analyse des journaux qui collecte les journaux provenant de diverses sources, notamment des serveurs, des applications et des périphériques réseau. Le système doit centraliser les données des journaux, détecter les anomalies, faciliter le dépannage et optimiser les performances du système grâce à des informations basées sur les journaux.
Comment résoudre?
- Implémentez la collecte de journaux à l'aide d'outils tels que Logstash ou Fluentd. Ces outils peuvent regrouper les journaux provenant de diverses sources et les normaliser pour un traitement ultérieur.
- Utilisez Elasticsearch, un puissant moteur de recherche et d'analyse distribué, pour stocker et indexer efficacement les données des journaux.
- Utilisez Kibana pour créer des tableaux de bord et des visualisations permettant aux utilisateurs de surveiller les données des journaux en temps réel.
- Configurez des mécanismes d'alerte à l'aide d'Elasticsearch Watcher ou de Grafana Alerts pour informer les parties prenantes concernées lorsque des modèles de journaux ou des anomalies spécifiques sont détectés.
Cliquez ici pour explorer ce projet d'ingénierie de données
6. Analyse des données Movielens pour les recommandations

Objectif
- Concevoir et développer un moteur de recommandation à l'aide de l'ensemble de données Movielens.
- Créez un pipeline ETL robuste pour prétraiter et nettoyer les données.
- Implémentez des algorithmes de filtrage collaboratifs pour fournir des recommandations de films personnalisées aux utilisateurs.
Comment résoudre?
- Tirez parti d'Apache Spark ou d'AWS Glue pour créer un pipeline ETL qui extrait les données des films et des utilisateurs, les transforme dans un format approprié et les charge dans une solution de stockage de données.
- Implémentez des techniques de filtrage collaboratif, telles que le filtrage collaboratif basé sur l'utilisateur ou sur l'élément, à l'aide de bibliothèques telles que Scikit-learn ou TensorFlow.
- Stockez les données nettoyées et transformées dans des solutions de stockage de données telles qu'Amazon S3 ou Hadoop HDFS.
- Développez une application Web (par exemple, en utilisant Flask ou Django) dans laquelle les utilisateurs peuvent saisir leurs préférences, et le moteur de recommandation fournit des recommandations de films personnalisées.
Cliquez ici pour explorer ce projet d'ingénierie de données.
7. Projet d'analyse de vente au détail
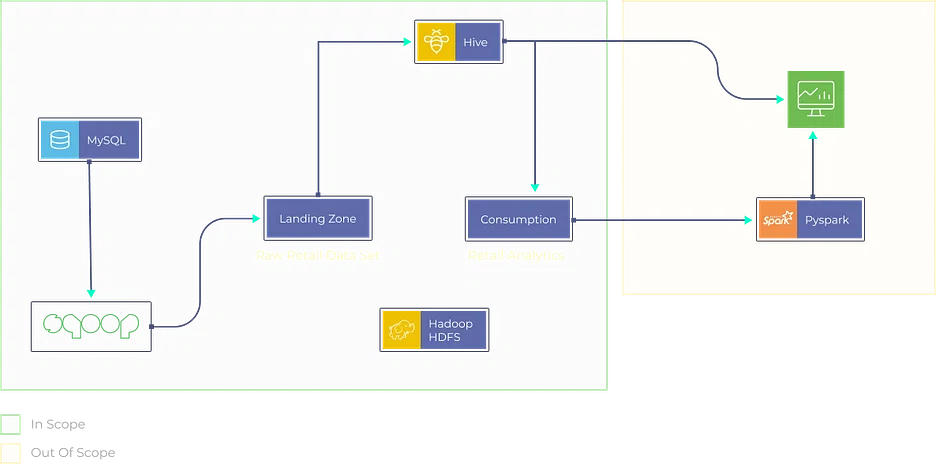
Objectif
Créez une plateforme d'analyse de vente au détail qui ingère des données provenant de diverses sources, notamment des systèmes de point de vente, des bases de données d'inventaire et des interactions avec les clients. Analysez les tendances des ventes, optimisez la gestion des stocks et générez des recommandations de produits personnalisées pour les clients.
Comment résoudre?
- Mettez en œuvre des processus ETL à l'aide d'outils tels qu'Apache Beam ou AWS Data Pipeline pour extraire, transformer et charger des données à partir de sources de vente au détail.
- Utilisez des algorithmes d'apprentissage automatique tels que XGBoost ou Random Forest pour la prévision des ventes et l'optimisation des stocks.
- Stockez et gérez les données dans des solutions d'entreposage de données telles que Snowflake ou Azure Synapse Analytics pour des requêtes efficaces.
- Créez des tableaux de bord interactifs à l'aide d'outils tels que Tableau ou Looker pour présenter des informations analytiques sur la vente au détail dans un format visuellement attrayant et compréhensible.
Cliquez ici pour explorer le code source.
Projets d'ingénierie de données sur GitHub
8. Analyse de données en temps réel
Objectif
Contribuez à un projet open source axé sur l'analyse de données en temps réel. Ce projet offre l'opportunité d'améliorer la vitesse de traitement des données, l'évolutivité et les capacités de visualisation en temps réel du projet. Vous pourriez être chargé d'améliorer les performances des composants de streaming de données, d'optimiser l'utilisation des ressources ou d'ajouter de nouvelles fonctionnalités pour prendre en charge les cas d'utilisation de l'analyse en temps réel.
Comment résoudre?
La méthode de résolution dépendra du projet auquel vous contribuez, mais elle implique souvent des technologies comme Apache Flink, Spark Streaming ou Apache Storm.
Cliquez ici pour explorer le code source de ce projet d'ingénierie de données.
9. Analyse de données en temps réel avec Azure Stream Services

Objectif
Explorez Azure Stream Analytics en contribuant ou en créant un projet de traitement de données en temps réel sur Azure. Cela peut impliquer l'intégration de services Azure comme Azure Functions et Power BI pour obtenir des informations et visualiser des données en temps réel. Vous pouvez vous concentrer sur l’amélioration des capacités d’analyse en temps réel et rendre le projet plus convivial.
Comment résoudre?
- Décrivez clairement les objectifs et les exigences du projet, y compris les sources de données et les informations souhaitées.
- Créez un environnement Azure Stream Analytics, configurez les entrées/sorties et intégrez Azure Functions et Power BI.
- Ingérez des données en temps réel, appliquez les transformations nécessaires à l'aide de requêtes de type SQL.
- Implémentez une logique personnalisée pour le traitement des données en temps réel à l’aide d’Azure Functions.
- Configurez Power BI pour la visualisation des données en temps réel et assurez une expérience conviviale.
Cliquez ici pour explorer le code source de ce projet d'ingénierie de données.
10. Pipeline de données sur les marchés financiers en temps réel avec l'API Finnhub et Kafka
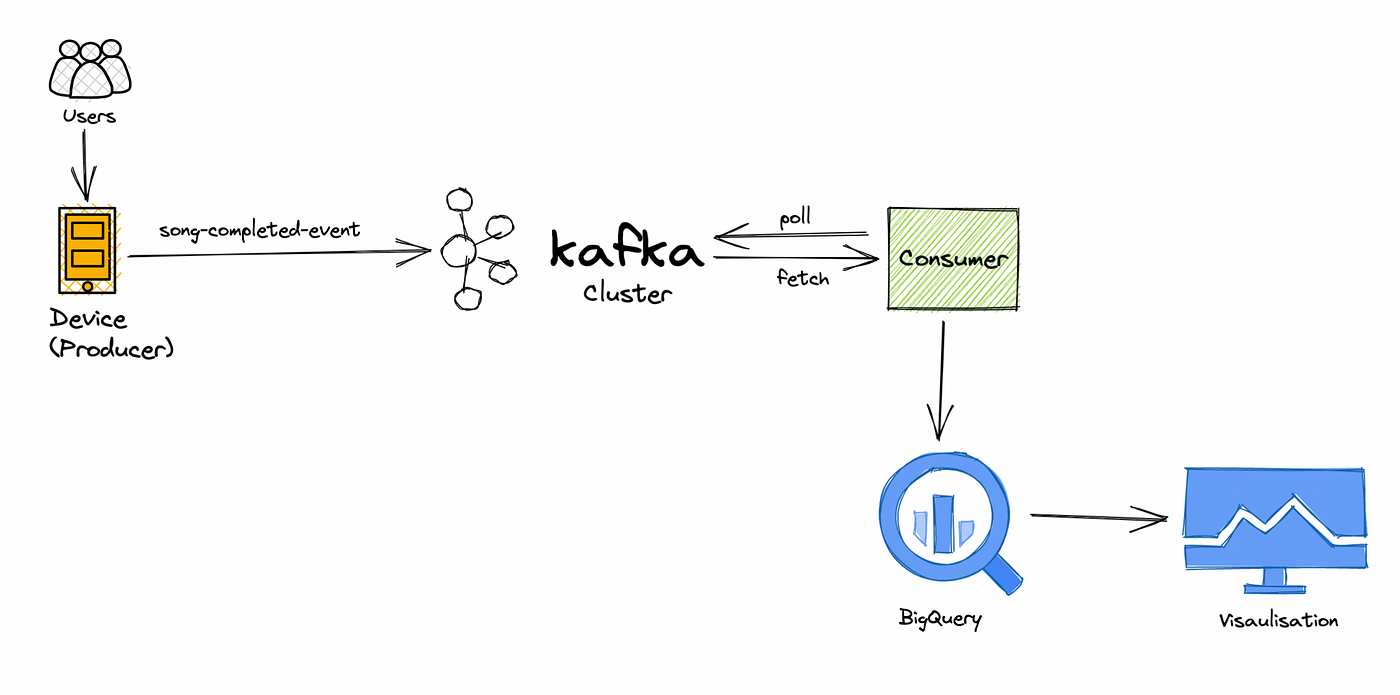
Objectif
Créez un pipeline de données qui collecte et traite les données des marchés financiers en temps réel à l'aide de l'API Finnhub et d'Apache Kafka. Ce projet consiste à analyser les cours des actions, à effectuer une analyse des sentiments sur les données d'actualité et à visualiser les tendances du marché en temps réel. Les contributions peuvent inclure l’optimisation de l’ingestion de données, l’amélioration de l’analyse des données ou l’amélioration des composants de visualisation.
Comment résoudre?
- Décrivez clairement les objectifs du projet, qui incluent la collecte et le traitement des données des marchés financiers en temps réel et la réalisation d'analyses boursières et d'analyses des sentiments.
- Créez un pipeline de données à l'aide d'Apache Kafka et de l'API Finnhub pour collecter et traiter des données de marché en temps réel.
- Analysez les cours des actions et effectuez une analyse des sentiments sur les données d'actualité en cours.
- Visualisez les tendances du marché en temps réel et envisagez des optimisations pour l'ingestion et l'analyse des données.
- Explorez les opportunités d’optimiser le traitement des données, d’améliorer l’analyse et d’améliorer les composants de visualisation tout au long du projet.
Cliquez ici pour explorer le code source de ce projet.
11. Pipeline de traitement des données des applications musicales en temps réel
Objectif
Collaborez sur un projet de données de streaming musical en temps réel axé sur le traitement et l'analyse des données de comportement des utilisateurs en temps réel. Vous explorerez les préférences des utilisateurs, suivrez la popularité et améliorerez le système de recommandation musicale. Les contributions peuvent inclure l'amélioration de l'efficacité du traitement des données, la mise en œuvre d'algorithmes de recommandation avancés ou le développement de tableaux de bord en temps réel.
Comment résoudre?
- Définissez clairement les objectifs du projet, en vous concentrant sur l'analyse du comportement des utilisateurs en temps réel et l'amélioration des recommandations musicales.
- Collaborez sur le traitement des données en temps réel pour explorer les préférences des utilisateurs, suivre la popularité et affiner le système de recommandation.
- Identifiez et mettez en œuvre des améliorations d’efficacité au sein du pipeline de traitement des données.
- Développer et intégrer des algorithmes de recommandation avancés pour améliorer le système.
- Créez des tableaux de bord en temps réel pour surveiller et visualiser les données sur le comportement des utilisateurs, et envisagez des améliorations continues.
Cliquez ici pour explorer le code source.
Projets d'ingénierie de données avancés pour CV
12. Surveillance de site Web

Objectif
Développez un système complet de surveillance de sites Web qui suit les performances, la disponibilité et l’expérience utilisateur. Ce projet implique l'utilisation d'outils tels que Selenium pour le web scraping afin de collecter des données à partir de sites Web et de créer des mécanismes d'alerte pour des notifications en temps réel lorsque des problèmes de performances sont détectés.
Comment résoudre?
- Définir les objectifs du projet, qui incluent la création d'un système de surveillance de site Web pour suivre les performances et la disponibilité, ainsi que l'amélioration de l'expérience utilisateur.
- Utilisez Selenium pour le web scraping afin de collecter des données sur les sites Web cibles.
- Implémentez des mécanismes d'alerte en temps réel pour avertir lorsque des problèmes de performances ou des temps d'arrêt sont détectés.
- Créez un système complet pour suivre les performances, la disponibilité et l'expérience utilisateur du site Web.
- Planifier une maintenance continue et une optimisation du système de surveillance pour assurer son efficacité dans le temps.
Cliquez ici pour explorer le code source de ce projet d'ingénierie de données.
13. Extraction de Bitcoin

Objectif
Plongez dans le monde des crypto-monnaies en créant un pipeline de données minières Bitcoin. Analysez les modèles de transaction, explorez le réseau blockchain et obtenez des informations sur l'écosystème Bitcoin. Ce projet nécessitera la collecte de données à partir des API blockchain, l'analyse et la visualisation.
Comment résoudre?
- Définir les objectifs du projet, en se concentrant sur la création d'un pipeline de données minières Bitcoin pour l'analyse des transactions et l'exploration de la blockchain.
- Implémentez des mécanismes de collecte de données à partir des API blockchain pour les données liées au minage.
- Plongez dans l'analyse de la blockchain pour explorer les modèles de transactions et obtenir des informations sur l'écosystème Bitcoin.
- Développez des composants de visualisation de données pour représenter efficacement les informations sur le réseau Bitcoin.
- Créez un pipeline de données complet qui englobe la collecte, l'analyse et la visualisation de données pour une vue globale des activités minières de Bitcoin.
Cliquez ici pour explorer le code source de ce projet d'ingénierie de données.
14. Projet GCP pour explorer les fonctions cloud

Objectif
Explorez Google Cloud Platform (GCP) en concevant et en mettant en œuvre un projet d'ingénierie de données qui exploite les services GCP tels que Cloud Functions, BigQuery et Dataflow. Ce projet peut inclure des tâches de traitement, de transformation et de visualisation des données, en se concentrant sur l'optimisation de l'utilisation des ressources et l'amélioration des flux de travail d'ingénierie des données.
Comment résoudre?
- Définissez clairement la portée du projet, en mettant l'accent sur l'utilisation des services GCP pour l'ingénierie des données, notamment Cloud Functions, BigQuery et Dataflow.
- Concevoir et mettre en œuvre l'intégration des services GCP, en garantissant une utilisation efficace de Cloud Functions, BigQuery et Dataflow.
- Exécuter des tâches de traitement et de transformation des données dans le cadre du projet, en ligne avec les objectifs généraux.
- Concentrez-vous sur l'optimisation de l'utilisation des ressources dans l'environnement GCP pour améliorer l'efficacité.
- Rechercher des opportunités pour améliorer les flux de travail d'ingénierie des données tout au long du cycle de vie du projet, en visant des processus rationalisés et efficaces.
Cliquez ici pour explorer le code source de ce projet.
15. Visualisation des données Reddit
Objectif
Collectez et analysez les données de Reddit, l'une des plateformes de médias sociaux les plus populaires. Créez des visualisations interactives et obtenez des informations sur le comportement des utilisateurs, les sujets d'actualité et l'analyse des sentiments sur la plateforme. Ce projet nécessitera des techniques de web scraping, d'analyse de données et de visualisation de données créatives.
Comment résoudre?
- Définissez les objectifs du projet, en mettant l'accent sur la collecte et l'analyse des données de Reddit pour obtenir des informations sur le comportement des utilisateurs, les sujets d'actualité et l'analyse des sentiments.
- Mettez en œuvre des techniques de web scraping pour collecter des données à partir de la plateforme Reddit.
- Plongez dans l'analyse des données pour explorer le comportement des utilisateurs, identifier les sujets d'actualité et effectuer une analyse des sentiments.
- Créez des visualisations interactives pour transmettre efficacement les informations tirées des données Reddit.
- Utiliser des techniques innovantes de visualisation de données pour améliorer la présentation des résultats tout au long du projet.
Cliquez ici pour explorer le code source de ce projet.
Projets d'ingénierie de données Azure
16. Analyse des données Yelp

Objectif
Dans ce projet, votre objectif est d'analyser de manière exhaustive les données Yelp. Vous construirez un pipeline de données pour extraire, transformer et charger les données Yelp dans une solution de stockage appropriée. L’analyse peut impliquer :
- Identifier les entreprises populaires.
- Analyser le sentiment des avis des utilisateurs.
- Fournir des informations aux entreprises locales pour améliorer leurs services.
Comment résoudre?
- Utilisez des techniques de web scraping ou l'API Yelp pour extraire des données.
- Nettoyez et prétraitez les données à l'aide de Python ou Azure Data Factory.
- Stockez les données dans Azure Blob Storage ou Azure SQL Data Warehouse.
- Effectuez une analyse de données à l'aide de bibliothèques Python telles que Pandas et Matplotlib.
Cliquez ici pour explorer le code source de ce projet.
17. Gouvernance des données
Objectif
La gouvernance des données est essentielle pour garantir la qualité, la conformité et la sécurité des données. Dans ce projet, vous concevrez et mettrez en œuvre un cadre de gouvernance des données à l'aide des services Azure. Cela peut impliquer de définir des politiques en matière de données, de créer des catalogues de données et de mettre en place des contrôles d'accès aux données pour garantir que les données sont utilisées de manière responsable et conformément aux réglementations.
Comment résoudre?
- Utilisez Azure Purview pour créer un catalogue qui documente et classe les actifs de données.
- Implémentez des politiques de données à l’aide d’Azure Policy et d’Azure Blueprints.
- Configurez le contrôle d'accès basé sur les rôles (RBAC) et l'intégration d'Azure Active Directory pour gérer l'accès aux données.
Cliquez ici pour explorer le code source de ce projet d'ingénierie de données.
18. Ingestion de données en temps réel

Objectif
Concevez un pipeline d'ingestion de données en temps réel sur Azure à l'aide de services tels qu'Azure Data Factory, Azure Stream Analytics et Azure Event Hubs. L’objectif est d’ingérer des données provenant de diverses sources et de les traiter en temps réel, fournissant ainsi des informations immédiates pour la prise de décision.
Comment résoudre?
- Utilisez Azure Event Hubs pour l’ingestion de données.
- Implémentez le traitement des données en temps réel avec Azure Stream Analytics.
- Stockez les données traitées dans Azure Data Lake Storage ou Azure SQL Database.
- Visualisez des informations en temps réel à l’aide de Power BI ou d’Azure Dashboards.
cliquez ici pour explorer le code source de ce projet.
Idées de projets d'ingénierie de données AWS
19. Pipeline ETL

Objectif
Créez un pipeline ETL (Extract, Transform, Load) de bout en bout sur AWS. Le pipeline doit extraire des données de diverses sources, effectuer des transformations et charger les données traitées dans un entrepôt ou un lac de données. Ce projet est idéal pour comprendre les principes fondamentaux de l'ingénierie des données.
Comment résoudre?
- Utilisez AWS Glue ou AWS Data Pipeline pour l'extraction de données.
- Implémentez des transformations à l'aide d'Apache Spark sur Amazon EMR ou AWS Glue.
- Stockez les données traitées dans Amazon S3 ou Amazon Redshift.
- Configurez l'automatisation à l'aide d'AWS Step Functions ou d'AWS Lambda pour l'orchestration.
Cliquez ici pour explorer le code source de ce projet.
20. Opérations ETL et ELT

Objectif
Explorez les approches d'intégration de données ETL (Extract, Transform, Load) et ELT (Extract, Load, Transform) sur AWS. Comparez leurs forces et leurs faiblesses dans différents scénarios. Ce projet fournira des informations sur le moment d'utiliser chaque approche en fonction des exigences spécifiques de l'ingénierie des données.
Comment résoudre?
- Implémentez des processus ETL à l'aide d'AWS Glue pour la transformation et le chargement des données. Utilisez AWS Data Pipeline ou AWS DMS (Database Migration Service) pour les opérations ELT.
- Stockez les données dans Amazon S3, Amazon Redshift ou Amazon Aurora, selon l'approche.
- Automatisez les flux de travail de données à l'aide des fonctions AWS Step Functions ou AWS Lambda.
Cliquez ici pour explorer le code source de ce projet.
Conclusion
Les projets d’ingénierie des données offrent une incroyable opportunité de plonger dans le monde des données, d’exploiter leur puissance et de générer des informations significatives. Que vous construisiez des pipelines pour le streaming de données en temps réel ou que vous élaboriez des solutions pour traiter de vastes ensembles de données, ces projets perfectionnent vos compétences et ouvrent les portes à des perspectives de carrière passionnantes.
Mais ne vous arrêtez pas là ; si vous êtes impatient de faire passer votre parcours d'ingénierie des données au niveau supérieur, pensez à vous inscrire à notre Programme BlackBelt Plus. Avec BB+, vous aurez accès à des conseils d'experts, à une expérience pratique et à une communauté de soutien, propulsant vos compétences en ingénierie de données vers de nouveaux sommets. Inscrivez-vous maintenant!
Foire aux Questions
A. L'ingénierie des données implique la conception, la construction et la maintenance de pipelines de données. Exemple : création d'un pipeline pour collecter, nettoyer et stocker les données client à des fins d'analyse.
R. Les meilleures pratiques en matière d'ingénierie des données incluent des contrôles robustes de la qualité des données, des processus ETL efficaces, de la documentation et une évolutivité pour la croissance future des données.
A. Les ingénieurs de données travaillent sur des tâches telles que le développement de pipelines de données, garantissant l'exactitude des données, collaborant avec des data scientists et résolvant les problèmes liés aux données.
A. Présenter les projets d'ingénierie des données sur un CV, mettre en évidence les projets clés, mentionner les technologies utilisées et quantifier l'impact sur les résultats du traitement des données ou de l'analyse.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/09/data-engineering-project/

