Introduction
Les données sont un carburant pour l'industrie informatique et le Projet de science des données dans le monde en ligne d'aujourd'hui. Les industries informatiques s'appuient largement sur des informations en temps réel dérivées de données en continu sources. La gestion et le traitement des données en streaming constituent le travail le plus difficile pour Analyse des données. Nous savons que les données en streaming sont des données qui sont émises en grand volume lors d'un traitement continu, ce qui signifie que les données changent chaque seconde. Pour gérer ces données, nous utilisons Plateforme Confluent – Une distribution autogérée et de niveau entreprise de Apache Kafka.
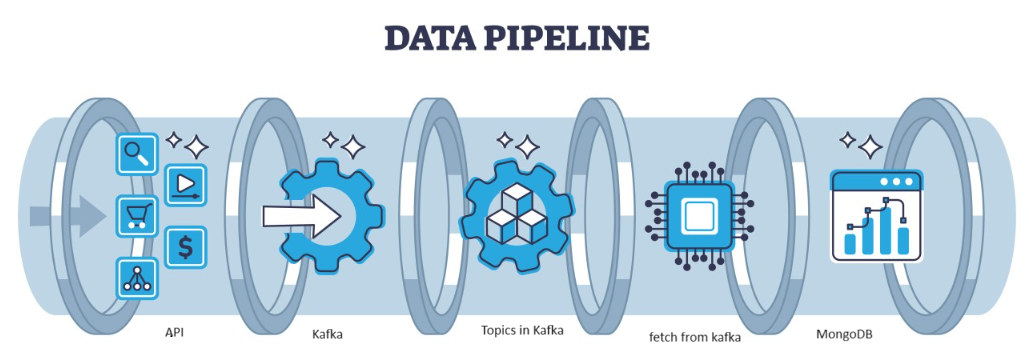
Kafka est une faille distribuée qui peut être gérée par l'architecture, qui constitue un choix populaire pour la gestion des flux de données à haut débit. Les données ensuite issues de Kafka sont collectées dans le MongoDB sous forme de collections. Dans cet article, nous allons créer le pipeline de bout en bout dans lequel les données sont récupérées à l'aide de l'API dans le Pipeline puis collectées dans Kafka sous forme de sujets puis stockées dans MongoDB à partir de là, nous pouvons l'utiliser dans le projet ou faire l'ingénierie des fonctionnalités.
Objectifs d'apprentissage
- Découvrez ce qu'est le streaming de données et comment gérer les données en streaming avec l'aide de Kafka.
- Comprendre la plateforme Confluent – Une distribution autogérée et de niveau entreprise d'Apache Kafka.
- Stockez les données collectées par Kafka dans MongoDB, une base de données NoSQL qui stocke les données non structurées.
- Créez un pipeline entièrement de bout en bout pour récupérer et stocker les données dans la base de données.
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
Identifiez le problème
Pour gérer les données en streaming provenant du capteur, les véhicules contenant des données de capteur sont produits par seconde et il est difficile de gérer et de prétraiter les données à utiliser dans le Projet de science des données. Ainsi, pour résoudre ce problème, nous créons le pipeline de bout en bout qui gère les données et les stocke.
Qu’est-ce que le streaming de données ?
Streaming de données Ce sont des données générées en continu par différentes sources et qui sont des données non structurées. Il fait référence à un flux continu de données générées à partir de différentes sources en temps réel ou quasi réel. Dans le traitement par lots traditionnel, les données sont collectées et ces données en streaming sont traitées au fur et à mesure de leur génération. Les données en streaming peuvent être des données IOT telles que des capteurs de température et des trackers GPS, ou des données de type machine, générées par des machines et des équipements industriels, comme les données de télémétrie des véhicules et des machines de fabrication. Il existe des plateformes de traitement de données en streaming comme Apache-Kafka.
Qu'est-ce que Kafka?
Apache Kafka est une plate-forme utilisée pour créer des pipelines de données en temps réel et des applications de streaming. L'API Kafka Streams est une bibliothèque puissante qui permet un traitement à la volée, vous permettant de collecter et de créer des paramètres de fenêtrage, d'effectuer des jointures de données au sein d'un flux, et bien plus encore. Apache Kafka se compose d'une couche de stockage et d'une couche de calcul qui combinent une ingestion de données efficace en temps réel, des pipelines de données en continu et un stockage entre les systèmes.
Quelle sera l’approche ?
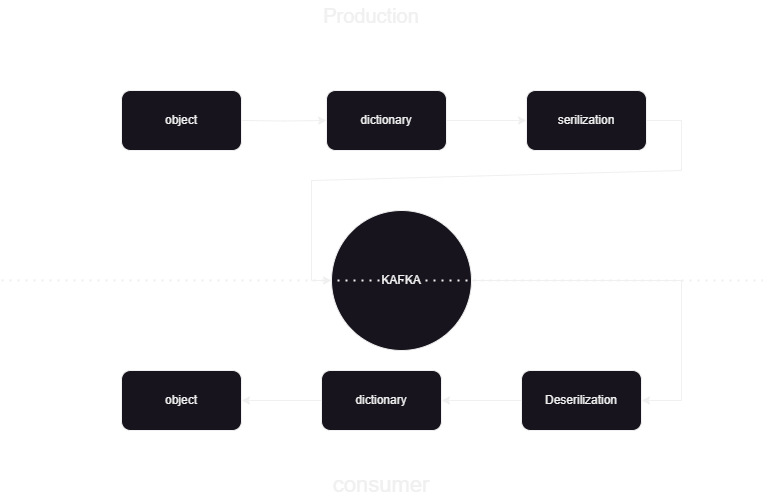
Il s'agit d'un pipeline d'apprentissage automatique pour nous aider à savoir comment publier et traiter les données vers et depuis Kafka confluent au format JSON. Il y a deux parties du consommateur et du producteur du traitement des données Kafka. Pour stocker les données en streaming des différents producteurs et les stocker dans confluent, puis la désérialisation des données est effectuée et ces données sont stockées dans la base de données.
Présentation de l'architecture du système
Nous traitons les données en streaming à l'aide de Kafka confluent et le Kafka est divisé en deux parties :
- Producteur Kafka : le producteur Kafka est responsable de la production et de l'envoi des données aux sujets Kafka.
- Kafka Consumer : Kafka Consumer doit lire et traiter les données des sujets Kafka.
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
Que sont les composants ?
- Sujets: Les sujets sont des chaînes ou des catégories logiques publiées par les producteurs. Chaque sujet est divisé en une ou plusieurs partitions et chaque sujet est répliqué sur plusieurs courtiers à des fins de tolérance aux pannes. Les producteurs publient des données sur des sujets spécifiques et les consommateurs s'abonnent à des sujets pour utiliser les données.
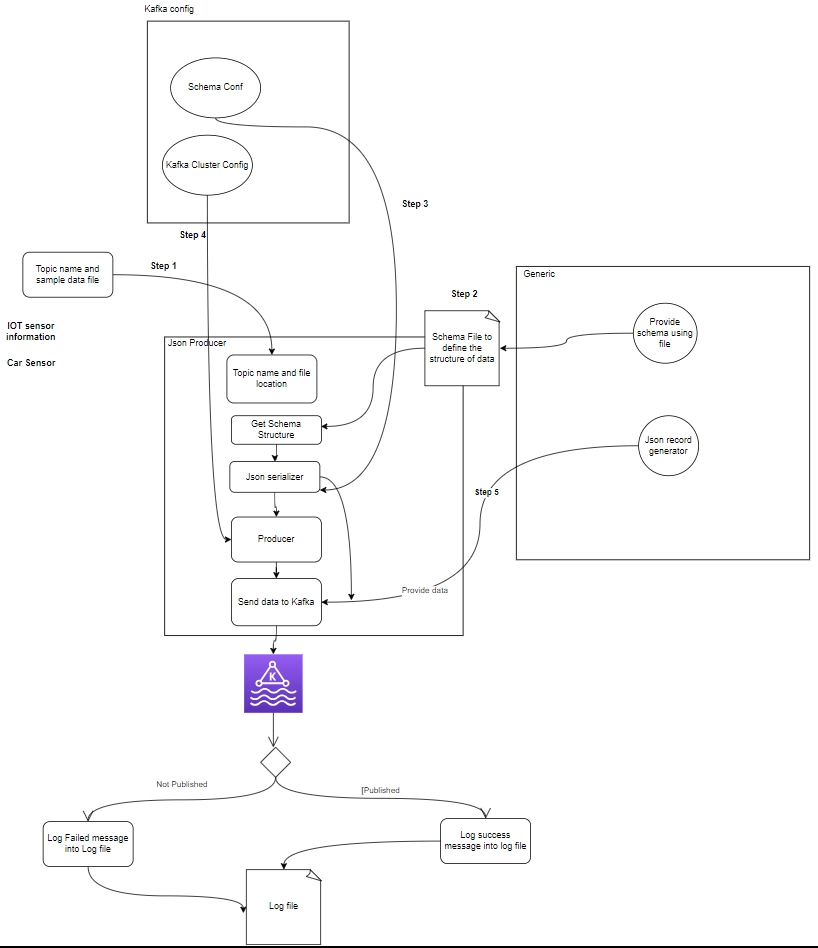
- Producteurs: Un Apache Kafka Producer est une application client qui publie (écrit) des événements sur un cluster Kafka. Les applications qui envoient des données dans des sujets sont appelées producteurs Kafka. Cette section donne un aperçu du producteur Kafka.
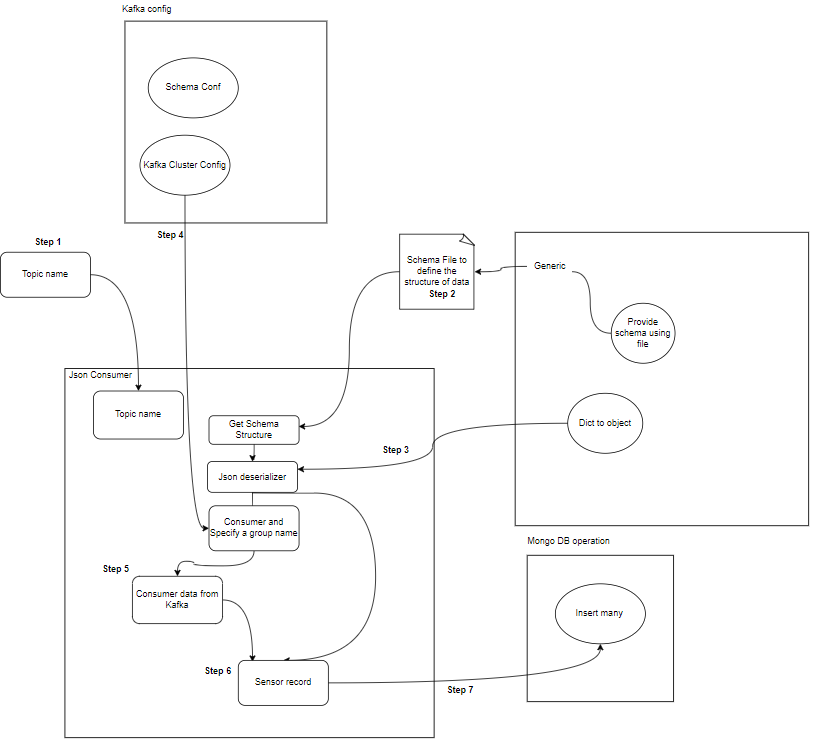
- Consommateur: Les consommateurs Kafka sont responsables de la lecture et du traitement des données des sujets Kafka et de leur traitement. Les consommateurs peuvent faire partie de n'importe quelle application qui doit utiliser et réagir aux données de Kafka. Ils s'abonnent à un ou plusieurs sujets et données des courtiers Kafka. Les consommateurs peuvent être organisés en groupes de consommateurs, chaque groupe de consommateurs comprenant un ou plusieurs consommateurs et chaque sujet d'un sujet étant consommé par un seul consommateur au sein du groupe. Cela permet un traitement parallèle et un équilibrage de charge de la consommation de données.
Quelle est la structure du projet ?
Ceci montre l'organigramme du projet comment le dossier et les fichiers sont divisés dans le projet :
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- Producteur Kafka : Le producteur est la partie principale qui génère les données des capteurs (par exemple, à partir de fichiers CSV dans sample_data/) et les publie dans un sujet Kafka. conditions d'erreur pouvant survenir lors de la génération ou de la publication de données.
- Courtier(s) Kafka : Les courtiers Kafka stockent et répliquent les données sur le cluster Kafka, gèrent le partitionnement des données et garantissent la tolérance aux pannes et la haute disponibilité.
- Consommateur(s) Kafka : Les consommateurs lisent les données des sujets Kafka, les traitent (par exemple, transformations, agrégations) et les stockent dans MongoDB. Ils surveillent également les conditions d'erreur pouvant survenir lors du traitement des données.
- MongoDB : MongoDB stocke les données des capteurs reçues des consommateurs Kafka. Il fournit une requête pour la récupération des données et garantit la durabilité des données grâce à des mécanismes de réplication et de tolérance aux pannes.
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
Conditions préalables au stockage des données
Kafka confluent
- Créer un compte : pour comprendre Kafka, vous avez besoin de Confluent. Vous aimez Apache Kafka®, mais vous ne le gérez pas. Le service cloud natif, complet et entièrement géré va au-delà de Kafka afin que vos meilleurs collaborateurs puissent se concentrer sur la création de valeur pour votre entreprise.
- Créer des sujets :
- Allez sur la page d'accueil et sur la barre latérale
- Allez dans Environnement puis cliquez sur Par défaut
- Aller aux sujets

- sélectionnez le Nouveau sujet donnez le nom du sujet

MongoDB
Créez une inscription, puis connectez-vous à MongoDB Atlas et enregistrez le lien de connexion de Mongodb Atlas pour une utilisation ultérieure.
Guide étape par étape pour la configuration du projet
- Installation de Python : assurez-vous que Python est installé sur votre ordinateur. Vous pouvez télécharger et installer Python du site officiel.
- Version Conda : vérifiez la version de Conda dans le terminal.
- Création d'un environnement virtuel : créez un environnement virtuel à l'aide de venv.
conda create -p venv python==3.10 -y- Activation de l'environnement virtuel : Activez l'environnement virtuel :
conda activate venv/- Installez les packages requis : Utilisez pip pour installer les dépendances nécessaires répertoriées dans le fichier Requirements.txt :
pip install -r requirements.txt- nous devons définir certaines des variables d'environnement dans le système local. Il s'agit de la variable d'environnement de cluster cloud confluent
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
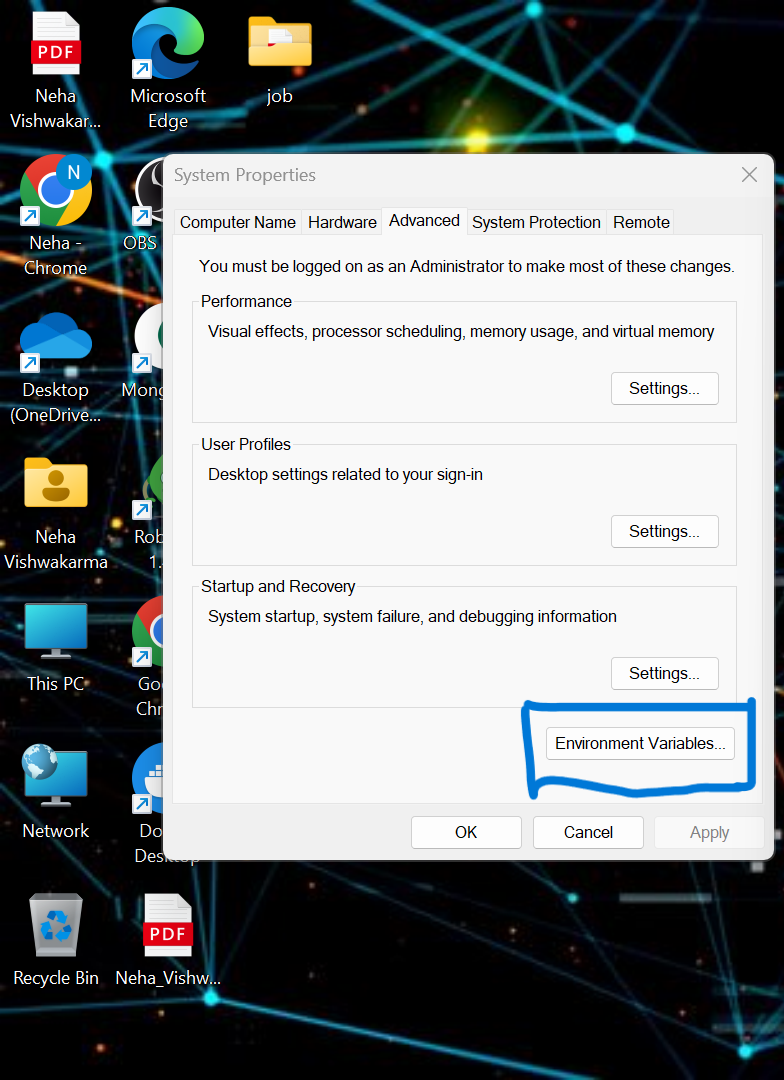
Mettez à jour les informations d'identification dans le fichier .env et exécutez la commande ci-dessous pour exécuter votre application dans le menu fixe..
- Créez un fichier .env dans le répertoire racine de votre projet s'il n'est pas disponible, collez le contenu ci-dessous et mettez à jour les informations d'identification
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- Exécution du fichier Producteur et Consommateur :
python producer_main.py
python consumer_main.pyComment implémenter le code ?
- src/ : Ce répertoire est le dossier principal de tous les fichiers de code source. Dans ce répertoire, nous avons les sous-répertoires suivants :
consumer/ : ce répertoire contient le code du Kafka_consumer, responsable de la lecture des données des sujets Kafka et de leur traitement.
producteur/ : ce répertoire contient le code du Kafka_producer, responsable de la génération et de l'envoi des données des capteurs aux sujets Kafka. - LISEZMOI.md : Ce fichier Markdown contient de la documentation et des instructions pour le projet, y compris un aperçu de son objectif, les instructions, les directives d'utilisation et toute information.
- exigences.txt : Ce fichier répertorie la bibliothèque Python requise pour le projet. Chaque dépendance est répertoriée avec son numéro de version. Des outils comme pip peuvent utiliser ce fichier pour installer automatiquement les dépendances nécessaires.
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: Pour connecter les MongoDB Altas via le lien, nous écrivons le script python
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
entrez votre URL qui est une copie de MongoDb Altas
Sortie :
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
Ce fichier s'exécute puis nous appelons le python producteur_main.py et cela va appeler le fichier ci-dessous :
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
Sortie :

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
Ce fichier s'exécute puis nous appelons le python consommateur_main.py et cela va appeler le fichier ci-dessous :
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()Sortie :

Lorsque nous gérons à la fois le consommateur et le producteur, le système fonctionne sur le kafka et les informations/données sont collectées plus rapidement.

Sortie :
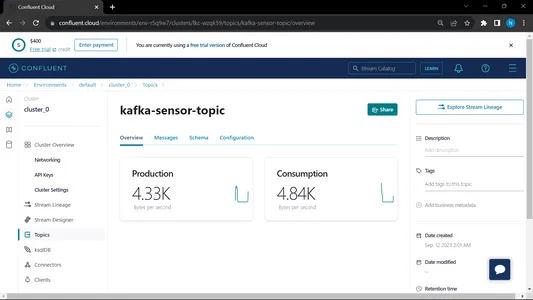
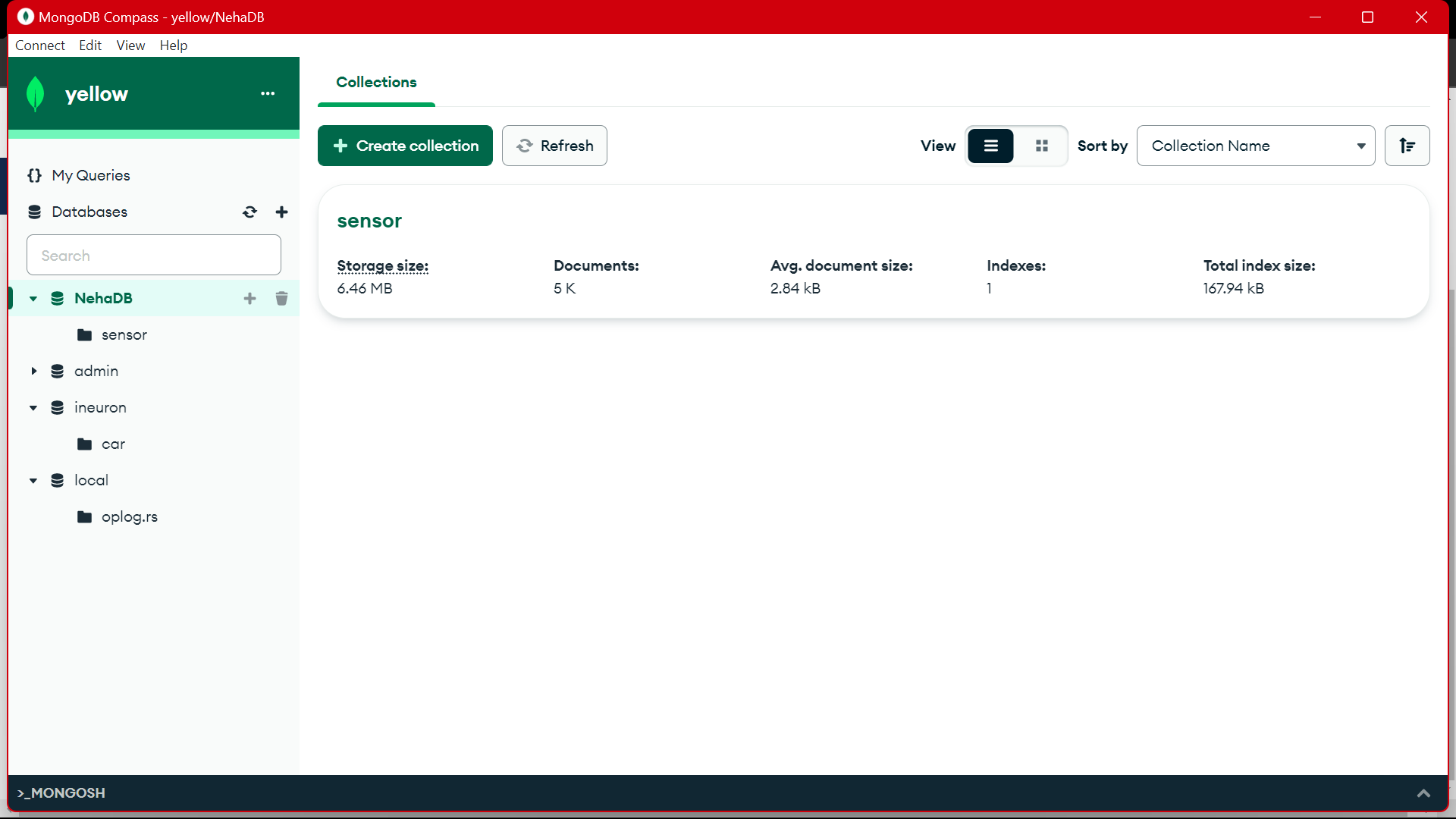
Depuis MongoDB, nous utilisons ces données pour prétraiter dans EDA, des travaux d'ingénierie de fonctionnalités et d'analyse de données sont effectués sur ces données.
[Contenu intégré]
Conclusion
Dans cet article, nous comprenons comment nous stockons et traitons les données en streaming du capteur vers Kafka sous forme de format JSON, puis nous stockons les données dans MongoDB. Nous savons que les données en streaming sont des données qui sont émises en grand volume lors d'un traitement continu, ce qui signifie que les données changent chaque seconde. Nous avons créé le pipeline de bout en bout dans lequel les données sont récupérées à l'aide de l'API dans le pipeline, puis collectées dans Kafka sous forme de sujets, puis stockées dans MongoDB à partir de là, nous pouvons les utiliser dans le projet ou faire le ingénierie des fonctionnalités.
Faits marquants
- Découvrez ce qu'est le streaming de données et comment gérer les données en streaming avec l'aide de Kafka.
- comprendre la plateforme Confluent – Une distribution autogérée et de niveau entreprise d'Apache Kafka.
- stockez les données collectées par Kafka dans MongoDB qui est une base de données NoSQL qui stocke les données non structurées.
- Créez un pipeline entièrement de bout en bout pour récupérer et stocker les données dans la base de données.
- comprendre la fonctionnalité de chaque composant du projet, l'implémenter sur le docker et l'implémenter sur un cloud pour l'utiliser à tout moment.
Ressources
Foire aux Questions
A. MongoDB stocke les données dans des données non structurées. les données de streaming sont des formes de données non structurées pour l'utilisation de la mémoire, nous utilisons MongoDB comme base de données.
R. L'objectif est de créer un pipeline de traitement de données en temps réel dans lequel les données ingérées dans les sujets Kafka peuvent être consommées, traitées et stockées dans MongoDB pour une analyse plus approfondie, des rapports ou une utilisation d'application.
A. Les cas d'utilisation incluent l'analyse en temps réel, le traitement des données IoT, l'agrégation de journaux, la surveillance des médias sociaux et les systèmes de recommandation, où les données en streaming doivent être traitées et stockées pour une analyse plus approfondie ou une utilisation des applications.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

