Introduction
C’est au cœur de Lavaux, science des données Les statistiques de mensonges, qui existent depuis des siècles, restent fondamentalement essentielles à l'ère numérique d'aujourd'hui. Pourquoi? Parce que les concepts statistiques de base constituent l’épine dorsale de l'analyse des données, nous permettant de donner un sens aux grandes quantités de données générées quotidiennement. C'est comme converser avec des données, où les statistiques nous aident à poser les bonnes questions et à comprendre les histoires que les données tentent de raconter.
Qu'il s'agisse de prédire les tendances futures, de prendre des décisions basées sur des données, de tester des hypothèses et de mesurer les performances, les statistiques sont l'outil qui alimente les informations qui sous-tendent les décisions basées sur les données. C'est le pont entre les données brutes et les informations exploitables, ce qui en fait un élément indispensable de la science des données.
Dans cet article, j'ai compilé les 15 principaux concepts statistiques fondamentaux que tout débutant en science des données devrait connaître !

Table des matières
1. Échantillonnage statistique et collecte de données
Nous apprendrons quelques concepts de base en statistiques, mais comprendre d'où viennent nos données et comment nous les collectons est essentiel avant de plonger profondément dans l'océan des données. C’est là que les populations, les échantillons et diverses techniques d’échantillonnage entrent en jeu.
Imaginez que nous voulions connaître la taille moyenne des habitants d’une ville. Il est pratique de mesurer tout le monde, c'est pourquoi nous prenons un plus petit groupe (échantillon) représentant la population la plus large. L’astuce réside dans la manière dont nous sélectionnons cet échantillon. Des techniques telles que l'échantillonnage aléatoire, stratifié ou en grappes garantissent que notre échantillon est bien représenté, minimisant ainsi les biais et rendant nos résultats plus fiables.
En comprenant les populations et les échantillons, nous pouvons étendre en toute confiance nos connaissances de l’échantillon à l’ensemble de la population, prenant ainsi des décisions éclairées sans avoir besoin d’interroger tout le monde.
2. Types de données et échelles de mesure
Les données se présentent sous différentes formes, et connaître le type de données que vous traitez est crucial pour choisir les bons outils et techniques statistiques.
Données quantitatives et qualitatives
- Des données quantitatives: Ce type de données est avant tout une question de chiffres. Il est mesurable et peut être utilisé pour des calculs mathématiques. Les données quantitatives nous indiquent « combien » ou « combien », comme le nombre d’utilisateurs visitant un site Web ou la température dans une ville. C'est simple et objectif, fournissant une image claire grâce à des valeurs numériques.
- Données qualitatives: À l’inverse, les données qualitatives traitent des caractéristiques et des descriptions. Il s'agit de « quel type » ou « quelle catégorie ». Considérez-le comme des données qui décrivent des qualités ou des attributs, comme la couleur d'une voiture ou le genre d'un livre. Ces données sont subjectives, basées sur des observations plutôt que sur des mesures.
Quatre échelles de mesure
- Échelle nominale : Il s'agit de la forme de mesure la plus simple utilisée pour catégoriser les données sans ordre spécifique. Les exemples incluent les types de cuisine, les groupes sanguins ou la nationalité. Il s'agit d'un étiquetage sans aucune valeur quantitative.
- Échelle ordinaire: Les données peuvent être ordonnées ou classées ici, mais les intervalles entre les valeurs ne sont pas définis. Pensez à une enquête de satisfaction avec des options comme satisfait, neutre et insatisfait. Il nous indique l'ordre mais pas la distance entre les classements.
- Échelle d'intervalle: L'intervalle met à l'échelle les données de commande et quantifie la différence entre les entrées. Cependant, il n’y a pas de véritable point zéro. Un bon exemple est la température en Celsius ; la différence entre 10°C et 20°C est la même qu'entre 20°C et 30°C, mais 0°C ne signifie pas l'absence de température.
- Échelle de rapport: L'échelle la plus informative possède toutes les propriétés d'une échelle à intervalles plus un point zéro significatif, permettant une comparaison précise des grandeurs. Les exemples incluent le poids, la taille et le revenu. Ici, on peut dire qu’une chose vaut deux fois plus qu’une autre.
3. Statistiques descriptives
Imagine statistiques descriptives comme votre premier rendez-vous avec vos données. Il s'agit d'apprendre à connaître les bases, les grandes lignes qui décrivent ce qui se trouve devant vous. Les statistiques descriptives sont de deux types principaux : les mesures de tendance centrale et les mesures de variabilité.
Mesures de tendance centrale: Ce sont comme le centre de gravité des données. Ils nous donnent une valeur unique typique ou représentative de notre ensemble de données.
Signifier: La moyenne est calculée en additionnant toutes les valeurs et en divisant par le nombre de valeurs. C'est comme la note globale d'un restaurant basée sur tous les avis. La formule mathématique de la moyenne est donnée ci-dessous :

Médian: La valeur moyenne lorsque les données sont classées du plus petit au plus grand. Si le nombre d’observations est pair, c’est la moyenne des deux nombres du milieu. Il est utilisé pour trouver le point médian d'un pont.
Si n est pair, la médiane est la moyenne des deux nombres centraux.
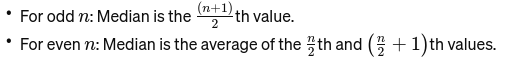
Mode: L'intelligence relationnelle c'est valeur la plus fréquente dans un ensemble de données. Considérez-le comme le plat le plus populaire dans un restaurant.
Mesures de variabilité : Alors que les mesures de tendance centrale nous amènent au centre, les mesures de variabilité nous renseignent sur la propagation ou la dispersion.
Plage : La différence entre les valeurs les plus élevées et les plus basses. Cela donne une idée de base de la propagation.
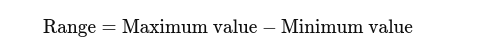
Variation: Mesure la distance entre chaque nombre de l'ensemble et la moyenne et donc de tous les autres nombres de l'ensemble. Pour un échantillon, c'est calculé comme suit :
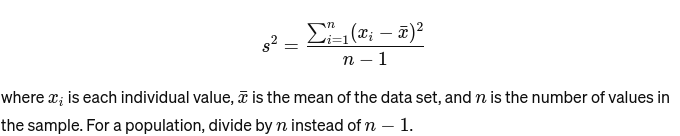
Écart-type: La racine carrée de la variance fournit une mesure de la distance moyenne par rapport à la moyenne. C'est comme évaluer la consistance des tailles de gâteaux d'un boulanger. Il est représenté ainsi :
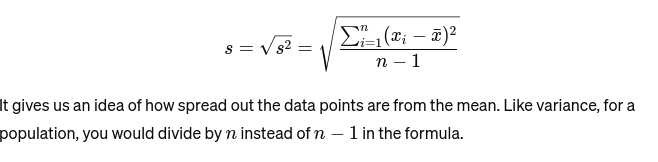
Avant de passer au prochain concept de base des statistiques, voici un Guide du débutant sur l'analyse statistique pour toi!
4. Visualisation des données
Visualisation de données est l'art et la science de raconter des histoires avec des données. Il transforme les résultats complexes de notre analyse en quelque chose de tangible et de compréhensible. C'est crucial pour l'analyse exploratoire des données, où l'objectif est de découvrir des modèles, des corrélations et des informations à partir des données sans encore tirer de conclusions formelles.
- Graphiques et graphiques : En commençant par les bases, les graphiques à barres, les graphiques linéaires et les diagrammes circulaires fournissent des informations fondamentales sur les données. Ce sont l’ABC de la visualisation de données, indispensables à tout conteur de données.
Nous avons un exemple de graphique à barres (à gauche) et de graphique linéaire (à droite) ci-dessous.
- Visualisations avancées : À mesure que nous approfondissons, les cartes thermiques, les nuages de points et les histogrammes permettent une analyse plus nuancée. Ces outils aident à identifier les tendances, les distributions et les valeurs aberrantes.
Vous trouverez ci-dessous un exemple de nuage de points et d'histogramme

Les visualisations relient les données brutes et la cognition humaine, nous permettant d'interpréter et de donner rapidement un sens à des ensembles de données complexes.
5. Bases des probabilités
Probabilité est la grammaire du langage des statistiques. Il s'agit de la chance ou de la probabilité que des événements se produisent. Comprendre les concepts de probabilité est essentiel pour interpréter les résultats statistiques et faire des prédictions.
- Événements indépendants et dépendants :
- Événements indépendants : Le résultat d’un événement n’affecte pas le résultat d’un autre. Comme lancer une pièce de monnaie, obtenir face sur un lancer ne change pas les chances du prochain lancer.
- Événements dépendants : Le résultat d’un événement affecte le résultat d’un autre. Par exemple, si vous piochez une carte d'un jeu et ne la remplacez pas, vos chances de piocher une autre carte spécifique changent.
La probabilité constitue la base pour faire des déductions sur les données et est essentielle à la compréhension de la signification statistique et aux tests d’hypothèses.
6. Distributions de probabilités communes
Distributions de probabilité sont comme différentes espèces dans l’écosystème statistique, chacune adaptée à sa niche d’applications.
- Distribution normale: Souvent appelée courbe en cloche en raison de sa forme, cette distribution se caractérise par sa moyenne et son écart type. Il s’agit d’une hypothèse courante dans de nombreux tests statistiques, car de nombreuses variables sont naturellement distribuées de cette façon dans le monde réel.
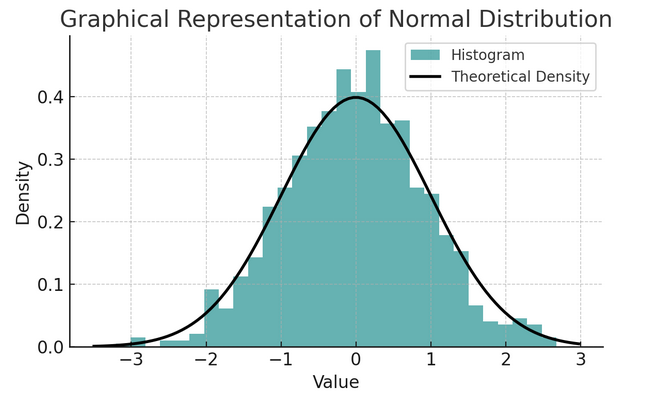
Un ensemble de règles connues sous le nom de règle empirique ou règle 68-95-99.7 résume les caractéristiques d'une distribution normale, qui décrit la manière dont les données sont réparties autour de la moyenne.
Règle 68-95-99.7 (règle empirique)
Cette règle s'applique à une distribution parfaitement normale et décrit ce qui suit :
- 68% des données se situe dans un écart type (σ) de la moyenne (μ).
- 95% des données se situe à moins de deux écarts types de la moyenne.
- Environ 99.7% des données se situe à moins de trois écarts types de la moyenne.
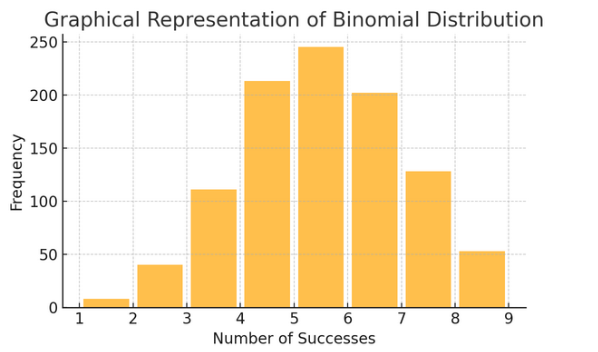
Distribution binomiale: Cette distribution s'applique aux situations avec deux résultats (comme le succès ou l'échec) répétés plusieurs fois. Il permet de modéliser des événements comme lancer une pièce de monnaie ou passer un test vrai/faux.
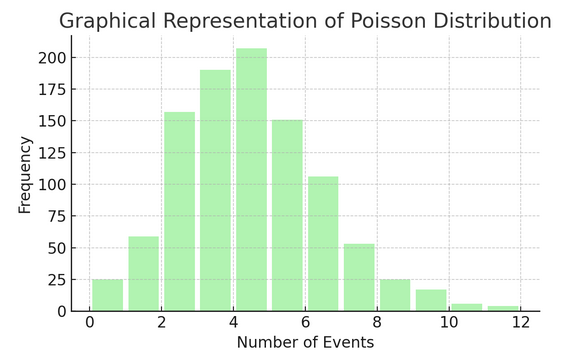
Distribution de Poisson compte le nombre de fois que quelque chose se produit sur un intervalle ou un espace spécifique. C'est idéal pour les situations où les événements se produisent de manière indépendante et constante, comme les e-mails quotidiens que vous recevez.
Chaque distribution possède son propre ensemble de formules et de caractéristiques, et le choix de la bonne dépend de la nature de vos données et de ce que vous essayez de découvrir. Comprendre ces distributions permet aux statisticiens et aux data scientists de modéliser des phénomènes du monde réel et de prédire avec précision les événements futurs.
7 . Tests d'hypothèses
Pensez à tests d'hypothèses comme travail de détective en statistiques. C'est une méthode pour tester si une théorie particulière concernant nos données pourrait être vraie. Ce processus part de deux hypothèses opposées :
- Hypothèse nulle (H0) : Il s'agit de l'hypothèse par défaut, suggérant qu'il existe un effet ou une différence. Cela veut dire : « Ce n'est pas » nouveau ici.
- Al’hypothèse alternative (H1 ou Ha) : Cela remet en question le statu quo, proposant un effet ou une différence. Il prétend : « Il se passe quelque chose d’intéressant. »
Exemple : tester si un nouveau programme de régime entraîne une perte de poids par rapport au fait de ne suivre aucun régime.
- Hypothèse nulle (H0) : Le nouveau programme de régime n’entraîne pas de perte de poids (pas de différence de perte de poids entre ceux qui suivent le nouveau programme de régime et ceux qui ne le suivent pas).
- Hypothèse alternative (H1) : Le nouveau programme de régime entraîne une perte de poids (une différence de perte de poids entre ceux qui le suivent et ceux qui ne le suivent pas).
Les tests d'hypothèses consistent à choisir entre ces deux éléments en fonction des preuves (nos données).
Niveaux d’erreur et de signification de types I et II :
- Erreur de type I : Cela se produit lorsque nous rejetons à tort l’hypothèse nulle. Il condamne un innocent.
- Erreur de type II : Cela se produit lorsque nous ne parvenons pas à rejeter une fausse hypothèse nulle. Cela permet de libérer un coupable.
- Niveau de signification (α) : Il s’agit le seuil pour décider combien de preuves sont suffisantes pour rejeter l’hypothèse nulle. Il est souvent fixé à 5 % (0.05), ce qui indique un risque de 5 % d'erreur de type I.
8. Intervalles de confiance
Intervalles de confiance donnez-nous une plage de valeurs dans laquelle nous nous attendons à ce que le paramètre de population valide (comme une moyenne ou une proportion) se situe avec un certain niveau de confiance (généralement 95 %). C'est comme prédire le score final d'une équipe sportive avec une marge d'erreur ; nous disons : « Nous sommes sûrs à 95 % que le véritable score se situera dans cette fourchette. »
La construction et l'interprétation d'intervalles de confiance nous aident à comprendre la précision de nos estimations. Plus l’intervalle est large, moins notre estimation est précise, et vice versa.
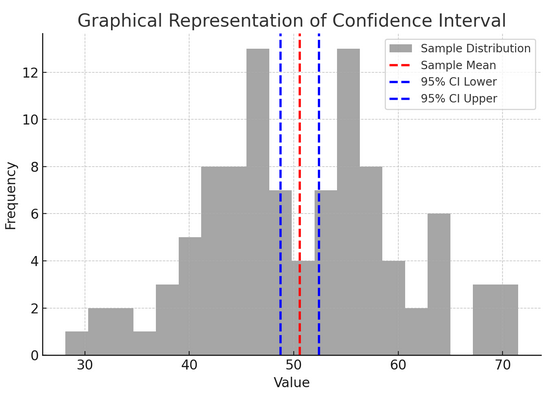
La figure ci-dessus illustre le concept d'intervalle de confiance (IC) dans les statistiques, en utilisant une distribution d'échantillon et son intervalle de confiance à 95 % autour de la moyenne de l'échantillon.
Voici une répartition des composants critiques dans la figure :
- Distribution de l'échantillon (histogramme gris) : Cela représente la distribution de 100 points de données générés aléatoirement à partir d'une distribution normale avec une moyenne de 50 et un écart type de 10. L'histogramme représente visuellement la façon dont les points de données sont répartis autour de la moyenne.
- Moyenne de l’échantillon (ligne pointillée rouge) : Cette ligne indique la valeur moyenne (moyenne) des données d'échantillon. Il sert d’estimation ponctuelle autour de laquelle nous construisons l’intervalle de confiance. Dans ce cas, il représente la moyenne de toutes les valeurs de l’échantillon.
- Intervalle de confiance de 95 % (lignes pointillées bleues) : Ces deux lignes marquent les limites inférieure et supérieure de l'intervalle de confiance à 95 % autour de la moyenne de l'échantillon. L'intervalle est calculé à l'aide de l'erreur type de la moyenne (SEM) et d'un score Z correspondant au niveau de confiance souhaité (1.96 pour une confiance de 95 %). L'intervalle de confiance suggère que nous sommes sûrs à 95 % que la moyenne de la population se situe dans cette fourchette.
9. Corrélation et causalité
Corrélation et causalité se confondent souvent, mais ils sont différents :
- Corrélation: Indique une relation ou une association entre deux variables. Quand l’un change, l’autre a tendance à changer aussi. La corrélation est mesurée par un coefficient de corrélation allant de -1 à 1. Une valeur plus proche de 1 ou -1 indique une relation forte, tandis que 0 suggère l'absence de liens.
- Causalité : Cela implique que les changements dans une variable entraînent directement des changements dans une autre. Il s'agit d'une assertion plus robuste que la corrélation et nécessite des tests rigoureux.
Ce n’est pas parce que deux variables sont corrélées que l’une provoque l’autre. Il s’agit d’un cas classique où il ne faut pas confondre « corrélation » et « causalité ».
10. Régression linéaire simple
étapes régression linéaire est un moyen de modéliser la relation entre deux variables en ajustant une équation linéaire aux données observées. Une variable est considérée comme une variable explicative (indépendante) et l’autre est une variable dépendante.
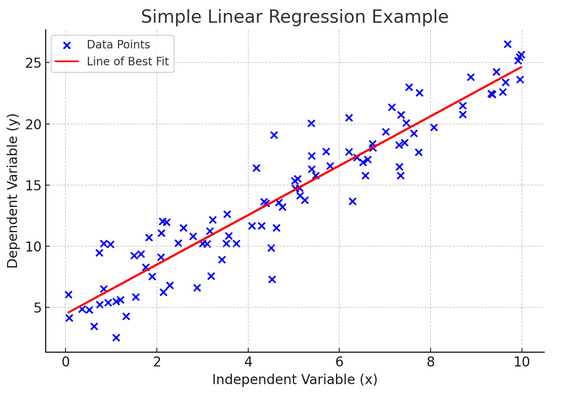
La régression linéaire simple nous aide à comprendre comment les changements dans la variable indépendante affectent la variable dépendante. Il s'agit d'un outil de prédiction puissant qui constitue la base de nombreux autres modèles statistiques complexes. En analysant la relation entre deux variables, nous pouvons faire des prédictions éclairées sur la manière dont elles interagiront.
La régression linéaire simple suppose une relation linéaire entre la variable indépendante (variable explicative) et la variable dépendante. Si la relation entre ces deux variables n’est pas linéaire, alors les hypothèses de régression linéaire simple peuvent être violées, conduisant potentiellement à des prédictions ou des interprétations inexactes. Ainsi, vérifier une relation linéaire dans les données est essentiel avant d’appliquer une régression linéaire simple.
11. Régression linéaire multiple
Considérez la régression linéaire multiple comme une extension de la régression linéaire simple. Pourtant, au lieu d’essayer de prédire un résultat avec un seul chevalier en armure étincelante (prédicteur), vous avez toute une équipe. C'est comme passer d'un match de basket en tête-à-tête à un effort d'équipe entier, où chaque joueur (prédicteur) apporte des compétences uniques. L’idée est de voir comment plusieurs variables influencent ensemble un seul résultat.
Cependant, une équipe plus grande s’accompagne du défi de la gestion des relations, appelées multicolinéarité. Cela se produit lorsque les prédicteurs sont trop proches les uns des autres et partagent des informations similaires. Imaginez deux joueurs de basket-ball essayant constamment de tirer le même coup ; ils peuvent se gêner mutuellement. La régression peut rendre difficile la perception de la contribution unique de chaque prédicteur, ce qui peut fausser notre compréhension des variables significatives.
12. Régression logistique
Alors que la régression linéaire prédit des résultats continus (comme la température ou les prix), régression logistique est utilisé lorsque le résultat est définitif (comme oui/non, gagner/perdre). Imaginez essayer de prédire si une équipe va gagner ou perdre en fonction de divers facteurs ; la régression logistique est votre stratégie de prédilection.
Il transforme l'équation linéaire de sorte que sa sortie se situe entre 0 et 1, représentant la probabilité d'appartenir à une catégorie particulière. C'est comme avoir une lentille magique qui convertit les scores continus en une vision claire de « ceci ou cela », nous permettant de prédire des résultats catégoriques.
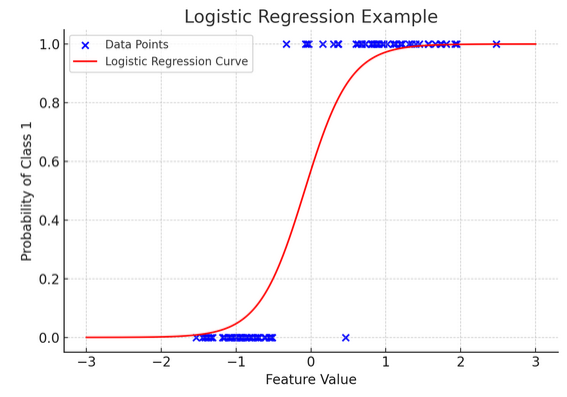
La représentation graphique illustre un exemple de régression logistique appliquée à un ensemble de données de classification binaire synthétique. Les points bleus représentent les points de données, avec leur position le long de l'axe des x indiquant la valeur de la caractéristique et l'axe des y indiquant la catégorie (0 ou 1). La courbe rouge représente la prédiction du modèle de régression logistique de la probabilité d'appartenir à la classe 1 (par exemple, « gagner ») pour différentes valeurs de caractéristiques. Comme vous pouvez le constater, la courbe passe en douceur de la probabilité de classe 0 à la classe 1, démontrant la capacité du modèle à prédire des résultats catégoriels sur la base d'une caractéristique continue sous-jacente.
La formule de régression logistique est donnée par :

Cette formule utilise la fonction logistique pour transformer le résultat de l'équation linéaire en une probabilité comprise entre 0 et 1. Cette transformation nous permet d'interpréter les résultats comme des probabilités d'appartenance à une catégorie particulière en fonction de la valeur de la variable indépendante xx.
13. Tests ANOVA et Chi carré
ANOVA (analyse de variance) ainsi que Tests du Chi carré sont comme des détectives dans le monde des statistiques, nous aidant à résoudre différents mystères. jet nous permet de comparer les moyennes de plusieurs groupes pour voir si au moins un est statistiquement différent. Considérez cela comme une dégustation d'échantillons de plusieurs lots de biscuits pour déterminer si un lot a un goût sensiblement différent.
D'autre part, le test du Chi carré est utilisé pour les données catégorielles. Cela nous aide à comprendre s'il existe une association significative entre deux variables catégorielles. Par exemple, existe-t-il une relation entre le genre de musique préféré d’une personne et sa tranche d’âge ? Le test du Chi carré permet de répondre à ces questions.
14. Le théorème central limite et son importance dans la science des données
La Théorème central limite (CLT) est un principe statistique fondamental qui semble presque magique. Cela nous indique que si vous prélevez suffisamment d'échantillons dans une population et calculez leurs moyennes, ces moyennes formeront une distribution normale (la courbe en cloche), quelle que soit la distribution originale de la population. C'est incroyablement puissant car cela nous permet de faire des déductions sur les populations même lorsque nous ne connaissons pas leur répartition exacte.
En science des données, le CLT sous-tend de nombreuses techniques, nous permettant d'utiliser des outils conçus pour des données normalement distribuées, même lorsque nos données ne répondent pas initialement à ces critères. C'est comme trouver un adaptateur universel pour les méthodes statistiques, rendant de nombreux outils puissants applicables dans davantage de situations.
15. Compromis biais-variance
In modélisation prédictive ainsi que machine learning, compromis biais-variance est un concept crucial qui met en évidence la tension entre deux principaux types d’erreurs qui peuvent faire dérailler nos modèles. Le biais fait référence aux erreurs provenant de modèles trop simplistes qui ne capturent pas bien les tendances sous-jacentes. Imaginez que vous essayez de tracer une ligne droite sur une route courbe ; vous raterez la cible. À l’inverse, les écarts par rapport à des modèles trop complexes capturent le bruit dans les données comme s’il s’agissait d’un modèle réel – comme tracer chaque virage sur un sentier cahoteux, en pensant que c’est la voie à suivre.
L'art consiste à équilibrer ces deux éléments pour minimiser l'erreur totale, en trouvant le point idéal où votre modèle est juste : suffisamment complexe pour capturer les modèles précis mais suffisamment simple pour ignorer le bruit aléatoire. C'est comme accorder une guitare ; le son ne sera pas correct s'il est trop serré ou trop lâche. Le compromis biais-variance il s’agit de trouver l’équilibre parfait entre les deux. Le compromis biais-variance est l’essence même du réglage de nos modèles statistiques pour qu’ils donnent le meilleur d’eux-mêmes dans la prévision précise des résultats.
Conclusion
De l’échantillonnage statistique au compromis biais-variance, ces principes ne sont pas de simples notions académiques mais des outils essentiels pour une analyse approfondie des données. Ils dotent les futurs data scientists des compétences nécessaires pour transformer de vastes données en informations exploitables, en mettant l'accent sur les statistiques comme épine dorsale de la prise de décision et de l'innovation basées sur les données à l'ère numérique.
Avons-nous oublié un concept de base en matière de statistiques ? Faites-nous savoir dans la section commentaire ci-dessous.
Explorez notre guide de statistiques de bout en bout pour que la science des données connaisse le sujet !
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

