Introducción
En IA, han surgido dos desafíos distintos: implementar grandes modelos en entornos de nube, incurrir en costos de computación formidables que impiden la escalabilidad y la rentabilidad, y acomodar dispositivos de borde con recursos limitados que luchan por soportar modelos complejos. El hilo común entre estos desafíos es el imperativo de reducir el tamaño del modelo sin comprometer la precisión. La cuantización de modelos, una técnica popular, ofrece una posible solución, pero plantea preocupaciones sobre posibles compensaciones en materia de precisión.

El entrenamiento consciente de la cuantificación surge como una respuesta convincente. Integra perfectamente la cuantificación en el proceso de entrenamiento del modelo, lo que permite reducciones significativas del tamaño del modelo, a veces de dos a cuatro veces o más, al tiempo que preserva la precisión crítica. Este artículo profundiza en la cuantificación, comparando la cuantificación posterior al entrenamiento (PTQ) y el entrenamiento consciente de la cuantificación (QAT). Además, proporcionamos información práctica que demuestra cómo ambos métodos se pueden implementar de manera efectiva utilizando SuperGradients, una biblioteca de capacitación de código abierto desarrollada por Deci.
Además, exploramos la optimización de Redes neuronales convolucionales (CNN) para plataformas móviles e integradas, abordando los desafíos únicos de tamaño y demandas computacionales. Nos centramos en la cuantificación, examinando el papel de la representación numérica en la optimización de modelos para plataformas móviles e integradas.
OBJETIVOS DE APRENDIZAJE
- Comprender el concepto de cuantificación de modelos en IA.
- Conozca los niveles de cuantificación típicos y sus compensaciones.
- Diferenciar entre entrenamiento consciente de la cuantificación (QAT) y cuantificación posterior al entrenamiento (PTQ).
- Explore las ventajas de la cuantificación de modelos, incluida la eficiencia de la memoria y el ahorro de energía.
- Descubra cómo la cuantificación de modelos permite una implementación más amplia del modelo de IA.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Comprender la necesidad de la cuantificación de modelos
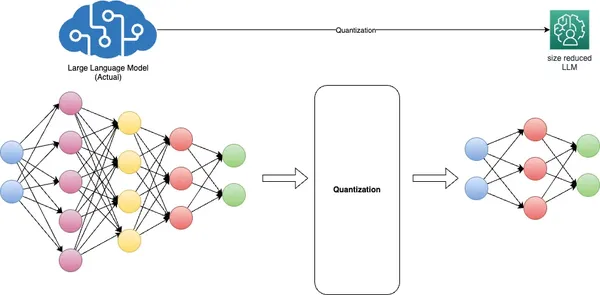
La cuantificación de modelos, una técnica fundamental en el aprendizaje profundo, tiene como objetivo abordar desafíos críticos relacionados con el tamaño del modelo, la velocidad de inferencia y la eficiencia de la memoria. Lo logra convirtiendo pesos de modelos de representaciones de punto flotante de alta precisión, generalmente de 32 bits (FP32), a formatos de punto flotante (FP) o enteros (INT) de menor precisión, como 16 bits u 8 bits. .
Los beneficios de la cuantificación son dobles. En primer lugar, reduce significativamente la huella de memoria del modelo y mejora la velocidad de inferencia sin causar una degradación sustancial de la precisión. En segundo lugar, optimiza el rendimiento del modelo al reducir los requisitos de ancho de banda de la memoria y mejorar la utilización de la caché.
La representación INT8 a menudo se denomina coloquialmente "cuantizada" en el contexto de las redes neuronales profundas, pero también se utilizan otros formatos como UINT8 e INT16, según la arquitectura del hardware. Los diferentes modelos requieren distintos enfoques de cuantificación, que a menudo exigen conocimientos previos y ajustes meticulosos para equilibrar la precisión y la reducción del tamaño del modelo.
La cuantificación presenta desafíos, particularmente con formatos enteros de baja precisión como INT8, debido a su rango dinámico limitado. Exprimir el amplio rango dinámico de FP32 en solo 255 valores de INT8 puede provocar una pérdida de precisión. Para mitigar este desafío, el escalado por canal o por capa ajusta la escala y los valores de punto cero del peso y los tensores de activación para que se ajusten mejor al formato cuantificado.
Además, el entrenamiento consciente de la cuantificación simula el proceso de cuantificación durante el entrenamiento del modelo, lo que permite que el modelo se adapte elegantemente a una precisión más baja. El apretón, o estimación del alcance, es un aspecto vital de este proceso, que se logra mediante la calibración.
En esencia, la cuantificación de modelos es indispensable para implementar modelos de IA eficientes, logrando un delicado equilibrio entre precisión y eficiencia de recursos, particularmente en dispositivos de vanguardia con recursos computacionales limitados.
Técnicas para la cuantificación de modelos
Nivel de cuantificación
La cuantización convierte los pesos y activaciones de punto flotante de alta precisión de un modelo en valores de punto fijo de menor precisión. El "nivel de cuantificación" se refiere al número de bits que representan estos valores de punto fijo. Los niveles de cuantificación típicos son la cuantificación de 8 bits, 16 bits e incluso binaria (1 bit). La elección de un nivel de cuantificación apropiado depende del equilibrio entre la precisión del modelo y la eficiencia de la memoria, el almacenamiento y la computación.
Entrenamiento consciente de la cuantificación (QAT) en detalle
El entrenamiento consciente de la cuantificación (QAT) es una técnica utilizada durante el entrenamiento de redes neuronales para prepararlas para la cuantificación. Ayuda al modelo a aprender a operar de manera efectiva con datos de menor precisión. Así es como funciona QAT:
- Durante QAT, el modelo se entrena con restricciones de cuantificación. Estas restricciones incluyen la simulación de tipos de datos de menor precisión (por ejemplo, enteros de 8 bits) durante los pasos hacia adelante y hacia atrás.
- Se utiliza una función de pérdida consciente de la cuantificación, que considera el error de cuantificación para penalizar las desviaciones del comportamiento del modelo de precisión total.
- QAT ayuda al modelo a aprender a hacer frente a la pérdida de precisión inducida por la cuantificación ajustando sus pesos y activaciones en consecuencia.
Cuantización posterior al entrenamiento (PTQ) versus entrenamiento consciente de la cuantificación (QAT)
PTQ y QAT son dos enfoques distintos para la cuantificación de modelos, cada uno con sus ventajas e implicaciones.

Cuantización post-entrenamiento (PTQ)
PTQ es una técnica de cuantificación que se aplica después de que un modelo ha sido entrenado completamente con precisión estándar, generalmente en representación de punto flotante. En PTQ, los pesos y activaciones del modelo se cuantifican en formatos de menor precisión, como enteros de 8 bits o flotantes de 16 bits, para reducir el uso de memoria y mejorar la velocidad de inferencia. Si bien PTQ ofrece simplicidad y compatibilidad con modelos preexistentes, puede provocar una pérdida moderada de precisión debido a la conversión posterior al entrenamiento.
Entrenamiento consciente de la cuantificación (QAT)
QAT, por otro lado, es un enfoque más matizado de la cuantificación. Implica ajustar el modelo PTQ teniendo en cuenta la cuantificación. Durante QAT, el proceso de cuantificación, que abarca escalado, recorte y redondeo, se integra perfectamente en el proceso de capacitación. Esto permite entrenar explícitamente el modelo para conservar su precisión incluso después de la cuantificación. QAT optimiza los pesos del modelo para emular con precisión la cuantificación del tiempo de inferencia. Durante el entrenamiento, emplea módulos de cuantificación "falsos" para imitar el comportamiento de la fase de prueba o inferencia, donde los pesos se redondean o fijan a representaciones de baja precisión. Este enfoque conduce a una mayor precisión durante la inferencia del mundo real, ya que el modelo es consciente de la cuantificación desde el principio.
Algoritmos de cuantificación
Existen varios algoritmos y métodos para cuantificar redes neuronales. Algunas técnicas de cuantificación estándar incluyen:
- Cuantificación de peso Implica cuantificar los pesos del modelo a valores de menor precisión (por ejemplo, enteros de 8 bits). La cuantificación del peso puede reducir significativamente la huella de memoria del modelo.
- Cuantización de activación: Además de cuantificar los pesos, las activaciones se pueden cuantificar durante la inferencia. Esto reduce aún más los requisitos computacionales y el uso de memoria.
- Cuantización dinámica: En lugar de utilizar una escala de cuantificación fija, la cuantificación dinámica permite el escalado dinámico de los rangos de cuantificación durante la inferencia, lo que ayuda a mitigar la pérdida de precisión.
- Entrenamiento consciente de la cuantificación (QAT): Como se mencionó anteriormente, QAT es un método de entrenamiento que incorpora restricciones de cuantificación y permite que el modelo aprenda a operar con datos de menor precisión.
- Cuantización de precisión mixta: Esta técnica combina diferentes cuantificaciones de precisión para pesos y activaciones, optimizando la precisión y la eficiencia.
- Cuantización post-entrenamiento con calibración: En la cuantificación posterior al entrenamiento, la calibración se utiliza para determinar los rangos de cuantificación de pesos y activaciones para minimizar la pérdida de precisión.
En resumen, la elección entre la cuantificación posterior a la capacitación y la capacitación consciente de la cuantificación (QAT) depende de las necesidades de implementación específicas y del equilibrio entre el rendimiento y la eficiencia del modelo. PTQ ofrece un enfoque más sencillo para reducir el tamaño del modelo. Aún así, puede sufrir una pérdida de precisión debido a la falta de coincidencia inherente entre el modelo original de precisión total y su contraparte cuantificada. Por otro lado, QAT integra restricciones de cuantificación directamente en el proceso de capacitación, asegurando que el modelo aprenda a operar de manera efectiva con datos de menor precisión desde el principio.
Esto da como resultado una mejor retención de la precisión y un control más preciso sobre el proceso de cuantificación. Cuando es primordial mantener una alta precisión, QAT suele ser la opción preferida. Permite que los modelos de aprendizaje profundo logren el delicado equilibrio entre el rendimiento óptimo y la utilización eficiente de los recursos de hardware. Es particularmente adecuado para la implementación en dispositivos con recursos limitados donde la precisión no puede verse comprometida.
Beneficios de la cuantización de modelos
- Inferencia más rápida: Los modelos cuantificados son más rápidos de implementar y ejecutar, lo que los hace ideales para aplicaciones en tiempo real como reconocimiento de voz, procesamiento de imágenes y vehículos autónomos. La precisión reducida permite cálculos más rápidos, lo que lleva a una menor latencia.
- Menores costos de implementación: Los tamaños de modelo más pequeños se traducen en menores requisitos de almacenamiento y memoria, lo que reduce significativamente el costo de implementar soluciones de IA, especialmente en servicios basados en la nube donde los costos de almacenamiento y computación son consideraciones importantes.
- Mayor accesibilidad: La cuantificación permite implementar la IA en dispositivos con recursos limitados, como teléfonos inteligentes, dispositivos IoT y plataformas informáticas de vanguardia. Esto amplía el alcance de la IA a una audiencia más amplia y abre nuevas oportunidades para aplicaciones en áreas remotas o subdesarrolladas.
- Privacidad y seguridad mejoradas: Al reducir el tamaño de los modelos, la cuantificación puede facilitar el procesamiento de IA en el dispositivo, reduciendo la necesidad de enviar datos confidenciales a servidores centralizados. Esto mejora la privacidad y la seguridad al minimizar la exposición de los datos a amenazas externas.
- Impacto medioambiental: Los modelos más pequeños reducen el consumo de energía, lo que hace que los centros de datos y la infraestructura de la nube sean más eficientes energéticamente. Esto ayuda a mitigar el impacto ambiental de las implementaciones de IA a gran escala.
- Escalabilidad: Los modelos cuantificados son más accesibles para distribuir e implementar, lo que permite escalar eficientemente los servicios de IA para adaptarse a las crecientes demandas de los usuarios y al tráfico sin inversiones significativas en infraestructura.
- Compatibilidad: Los modelos cuantificados suelen ser más compatibles con una gama más amplia de hardware, lo que hace que la implementación de soluciones de IA en diversos dispositivos y plataformas sea más accesible.
- Aplicaciones en tiempo real: El tamaño reducido del modelo y la inferencia más rápida hacen que los modelos cuantificados sean adecuados para aplicaciones en tiempo real como la realidad aumentada, la realidad virtual y los juegos, donde la baja latencia es crucial para una experiencia de usuario perfecta.
Estos beneficios en conjunto hacen de la cuantificación de modelos una técnica vital para optimizar AI implementaciones, garantizando eficiencia y accesibilidad en una amplia gama de aplicaciones y dispositivos.
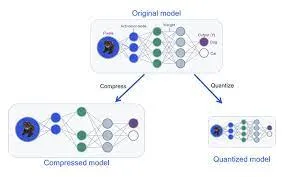
Ejemplos del mundo real
- Healthcare: En el sector de la salud, la cuantificación de modelos ha permitido implementar soluciones de imágenes médicas impulsadas por IA en dispositivos de vanguardia. Las máquinas de ultrasonido portátiles y las aplicaciones de teléfonos inteligentes ahora utilizan modelos cuantificados para diagnosticar enfermedades cardíacas y detectar tumores. Esto reduce la necesidad de equipos costosos y especializados y permite a los profesionales de la salud brindar diagnósticos oportunos y precisos en entornos remotos o con recursos limitados.
- Vehículos autónomos: Los modelos cuantificados desempeñan un papel crucial en los vehículos autónomos, donde la toma de decisiones en tiempo real es imperativa. Los vehículos autónomos pueden funcionar de manera eficiente con hardware integrado al reducir el tamaño de los modelos de aprendizaje profundo para tareas de percepción y control. Esto mejora la seguridad, la capacidad de respuesta y la capacidad de navegar en entornos complejos, haciendo realidad la conducción autónoma.
- Procesamiento del lenguaje natural (PNL): En el campo de la PNL, los modelos cuantificados han permitido la implementación de modelos de lenguaje en parlantes inteligentes, chatbots y dispositivos móviles. Esto permite la comprensión y generación de idiomas en tiempo real, lo que hace que los asistentes de voz y las aplicaciones de traducción de idiomas sean más accesibles y respondan a las consultas de los usuarios.
- Automatización Industrial: La automatización industrial aprovecha los modelos cuantificados para el mantenimiento predictivo y el control de calidad. Los dispositivos perimetrales equipados con modelos cuantificados pueden monitorear el estado de la maquinaria y detectar defectos en tiempo real, minimizando el tiempo de inactividad y mejorando la eficiencia de producción en las plantas de fabricación.
- Minorista y comercio electrónico: Los minoristas utilizan modelos cuantificados para la gestión de inventario y la participación del cliente. Los modelos de reconocimiento de imágenes en tiempo real implementados en las cámaras de las tiendas pueden rastrear la disponibilidad de los productos y optimizar el diseño de las tiendas. De manera similar, los sistemas de recomendación cuantificados brindan experiencias de compra personalizadas en plataformas de comercio electrónico, mejorando la satisfacción del cliente y las ventas.
Estos ejemplos del mundo real ilustran la versatilidad y el impacto de la cuantificación de modelos en diversas industrias, lo que hace que las soluciones de IA sean más accesibles, eficientes y rentables.
Desafíos y Consideraciones
En la cuantificación de modelos, varios desafíos y consideraciones críticos configuran el panorama de las implementaciones eficientes de IA. Un desafío fundamental radica en lograr el delicado equilibrio entre precisión y eficiencia. La cuantificación agresiva, si bien mejora la eficiencia de los recursos, puede provocar una pérdida significativa de precisión, lo que hace imperativo adaptar el enfoque de cuantificación a las demandas específicas de la aplicación.
Además, no todos los modelos de IA son igualmente susceptibles de cuantificación, y la complejidad de los modelos desempeña un papel fundamental en su sensibilidad a las reducciones de precisión durante la cuantificación. Esto requiere evaluar cuidadosamente si la cuantificación se adapta a un modelo y caso de uso determinados. La elección entre cuantificación posterior al entrenamiento (PTQ) y entrenamiento consciente de la cuantificación (QAT) es igualmente crítica. Esta decisión afecta significativamente la precisión, la complejidad del modelo y los cronogramas de desarrollo, lo que subraya la necesidad de que los desarrolladores tomen decisiones bien informadas que se alineen con los requisitos de implementación de su proyecto y los recursos disponibles. Estas consideraciones en conjunto enfatizan la importancia de una planificación y evaluación meticulosas al implementar la cuantificación de modelos, ya que influyen directamente en las intrincadas compensaciones entre la precisión del modelo y la eficiencia de los recursos en las aplicaciones de IA.
Compensaciones de precisión
- Un examen detallado de las compensaciones entre la precisión del modelo y la cuantificación: esta sección profundiza en el intrincado equilibrio entre mantener la precisión del modelo y lograr la eficiencia de los recursos a través de la cuantificación. Explora cómo una cuantificación agresiva puede conducir a una pérdida de precisión y las consideraciones necesarias para tomar decisiones informadas con respecto al nivel de cuantificación que se adapta a aplicaciones específicas.
Desafíos del entrenamiento consciente de la cuantificación
- Desafíos comunes que enfrentan al implementar QAT y estrategias para superarlos: abordamos los obstáculos que encuentran los desarrolladores al integrar la capacitación consciente de la cuantificación (QAT) en el proceso de capacitación del modelo. También proporcionamos información sobre estrategias y mejores prácticas para superar estos desafíos, garantizando una implementación exitosa de QAT.
Limitaciones de hardware
- Discusión del papel de los aceleradores de hardware en la implementación de modelos cuantificados: esta sección explora el papel de los aceleradores de hardware, como GPU, TPU y hardware de IA dedicado, en la implementación de modelos cuantificados. Enfatiza la importancia de la compatibilidad y optimización del hardware para lograr una inferencia eficiente y de alto rendimiento con modelos cuantificados.
Detección de objetos en tiempo real en una Raspberry Pi utilizando MobileNetV2 cuantificado
1: Configuración del hardware

- Presente su modelo de Raspberry Pi (por ejemplo, Raspberry Pi 4).
- Módulo de cámara Raspberry Pi (o cámara web USB para modelos más antiguos)
- Fuente de alimentación
- Tarjeta microSD con sistema operativo Raspberry Pi
- Cable HDMI, monitor, teclado y mouse (para configuración inicial)
- Enfatice la necesidad de implementar un modelo liviano en Raspberry Pi debido a sus limitaciones de recursos.
2: Instalación del software
- Configure Raspberry Pi con Raspberry Pi OS (anteriormente Raspbian).
- Instale Python y las bibliotecas necesarias:
sudo apt update
sudo apt install python3-pip
pip3 install opencv-python-headless
pip3 install opencv-python
pip3 install numpy
pip3 install tensorflow==2.73: Recopilación y preprocesamiento de datos
- Recopile o acceda a un conjunto de datos para la detección de objetos (por ejemplo, conjunto de datos COCO).
- Etiquetar objetos de interés en imágenes mediante herramientas como LabelImg.
- Convertir anotaciones al formato requerido (por ejemplo, TFRecord) para TensorFlow.
4: Importar bibliotecas necesarias
import argparse # For command-line argument parsing
import cv2 # OpenCV library for computer vision tasks
import imutils # Utility functions for working with images and video
import numpy as np # NumPy for numerical operations
import tensorflow as tf # TensorFlow for machine learning and deep learning5: Cuantización del modelo
- Cuantifique un modelo MobileNetV2 previamente entrenado usando TensorFlow:
import tensorflow as tf # Load the pre-trained model
model = tf.keras.applications.MobileNetV2(weights='imagenet', input_shape=(224, 224, 3)) # Quantize the model
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quantized_model = converter.convert() # Save the quantized model
with open('quantized_mobilenetv2.tflite', 'wb') as f: f.write(tflite_quantized_model)Step 5: Deployment and Real-time Inference6: análisis de argumentos
- "argparse" se utiliza para analizar argumentos de línea de comandos. Aquí, está configurado para aceptar la ruta al modelo personalizado, el archivo de etiquetas y un umbral de confianza.
# Parse command-line arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True, help="path to your custom trained model")
ap.add_argument("-l", "--labels", required=True, help="path to your class labels file")
ap.add_argument("-c", "--confidence", type=float, default=0.2, help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
7: Carga de modelos y carga de etiquetas
- El código carga el modelo de detección de objetos personalizado y las etiquetas de clase.
# Load your custom-trained model and labels
print("[INFO] loading model...")
model = tf.saved_model.load(args["model"]) # Load the custom-trained TensorFlow model
with open(args["labels"], "r") as f: CLASSES = f.read().strip().split("n") # Load class labels from a file
8: Inicialización de la transmisión de vídeo
- Configura la transmisión de video, que captura fotogramas de la cámara predeterminada.
# Initialize video stream
print("[INFO] starting video stream...")
cap = cv2.VideoCapture(0) # Initialize the video stream (0 for the default camera)
fps = cv2.getTickFrequency()
start_time = cv2.getTickCount()
9: Bucle de detección de objetos en tiempo real
- El bucle principal captura fotogramas de la transmisión de vídeo, realiza la detección de objetos utilizando el modelo personalizado y muestra los resultados en el fotograma.
- Los objetos detectados se dibujan como cuadros delimitadores con etiquetas y puntuaciones de confianza.
while True: # Read a frame from the video stream ret, frame = cap.read() frame = imutils.resize(frame, width=800) # Resize the frame for better processing speed # Perform object detection using the custom model detections = model(frame) # Loop over detected objects for detection in detections['detection_boxes']: # Extract bounding box coordinates startY, startX, endY, endX = detection[0], detection[1], detection[2], detection[3] # Draw bounding box and label on the frame label = CLASSES[0] # Replace with your class label logic confidence = 1.0 # Replace with your confidence score logic color = (0, 255, 0) # Green color for bounding box (you can change this) cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2) text = "{}: {:.2f}%".format(label, confidence * 100) cv2.putText(frame, text, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) # Display the frame with object detection results cv2.imshow("Custom Object Detection", frame) key = cv2.waitKey(1) & 0xFF if key == ord("q"): break # Break the loop if 'q' key is pressed # Clean up
cap.release() # Release the video stream
cv2.destroyAllWindows() # Close OpenCV windows
10: Evaluación del desempeño
- Mida la velocidad de inferencia y la utilización de recursos en Raspberry Pi utilizando herramientas de monitoreo de tiempo y sistema (htop).
- Analice cualquier compensación entre precisión y eficiencia observada durante el proyecto.
11: Conclusión e ideas
- Resuma los hallazgos esenciales y enfatice cómo la cuantificación del modelo permitió la detección de objetos en tiempo real en un dispositivo con recursos limitados como Raspberry Pi.
- Resalte la practicidad de este proyecto y las aplicaciones del mundo real, como la implementación de detección de objetos en cámaras de seguridad o robótica.
Siguiendo estos pasos y utilizando el código Python proporcionado, los estudiantes pueden construir un sistema de detección de objetos en tiempo real en una Raspberry Pi, demostrando los beneficios de la cuantificación de modelos para aplicaciones eficientes de IA en dispositivos periféricos.
Conclusión
La cuantificación de modelos es una técnica fundamental que influye profundamente en el panorama de la implementación de la IA. Potencia los dispositivos móviles y de borde con recursos limitados al permitirles ejecutar aplicaciones de IA de manera eficiente y mejora la escalabilidad y rentabilidad de los servicios de IA basados en la nube. El impacto de la cuantificación repercute en todo el ecosistema de la IA, haciendo que la IA sea más accesible, receptiva y respetuosa con el medio ambiente.
Además, la cuantificación se alinea con las tendencias emergentes de IA, como el aprendizaje federado y la IA en el borde, abriendo nuevas fronteras de innovación. Mientras somos testigos de la evolución continua de la IA, la cuantificación de modelos se erige como una herramienta vital que garantiza que la IA pueda llegar a una audiencia más amplia, ofrecer información en tiempo real y adaptarse a las demandas cambiantes de diversas industrias. En este panorama dinámico, la cuantificación de modelos sirve como puente entre el poder de la IA y la practicidad de su implementación, forjando un camino hacia soluciones de IA más eficientes, accesibles y sostenibles.
Puntos clave
- La cuantificación de modelos es vital para implementar grandes modelos de IA en dispositivos con recursos limitados.
- Los niveles de cuantificación, como 8 o 16 bits, reducen el tamaño del modelo y mejoran la eficiencia.
- Prensador de entrenamiento con reconocimiento de cuantificación (QAT) El entrenamiento con reconocimiento de cuantificación cuantifica el entrenamiento durante el entrenamiento.
- La cuantificación posterior al entrenamiento (PTQ) simplifica pero puede reducir la precisión, lo que requiere un ajuste fino.
- La elección depende de las necesidades de implementación específicas y del equilibrio entre precisión y eficiencia, lo cual es crucial para dispositivos con recursos limitados.
Preguntas frecuentes
R: La cuantificación de modelos en IA es una técnica que implica reducir la precisión de los pesos y activaciones de un modelo de red neuronal. Convierte valores de punto flotante de alta precisión en representaciones de punto fijo o enteros de menor precisión, lo que hace que el modelo sea más eficiente en memoria y más rápido de ejecutar.
R: Los niveles de cuantificación comunes incluyen cuantificación de 8 bits, 16 bits y binaria (1 bit). La elección del nivel de cuantificación depende del equilibrio entre la precisión del modelo y la eficiencia de la memoria/almacenamiento/cómputo requerida para una aplicación específica.
R: QAT incorpora restricciones de cuantificación durante el entrenamiento, lo que permite que el modelo se adapte a cálculos de menor precisión. PTQ, por otro lado, cuantifica un modelo previamente entrenado después de un entrenamiento estándar, lo que potencialmente requiere un ajuste fino para recuperar la precisión perdida.
R: La cuantificación de modelos ofrece ventajas como una menor huella de memoria, una mejor velocidad de inferencia, eficiencia energética, una implementación más amplia en dispositivos con recursos limitados, ahorro de costos y mayor privacidad y seguridad debido a tamaños de modelo más pequeños.
R: Elegir QAT cuando mantener la precisión del modelo es una prioridad. QAT garantiza una mejor retención de la precisión al integrar restricciones de cuantificación durante el entrenamiento, lo que lo hace ideal cuando la precisión es primordial. PTQ es más sencillo, pero puede requerir ajustes adicionales para recuperar la precisión. La elección depende de las necesidades de implementación específicas.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/11/model-quantization-for-large-scale-deployment/

