Τα μοντέλα παραγωγής γλώσσας έχουν αποδειχθεί εξαιρετικά επιδέξια στην επίλυση εργασιών λογικής και αναλυτικής επεξεργασίας φυσικής γλώσσας (NLP). Επιπλέον, η χρήση του άμεση μηχανική μπορούν να βελτιώσουν σημαντικά την απόδοσή τους. Για παράδειγμα, αλυσίδα της σκέψης (CoT) είναι γνωστό ότι βελτιώνει την ικανότητα ενός μοντέλου για πολύπλοκα προβλήματα πολλαπλών βημάτων. Για να ενισχύσετε επιπλέον την ακρίβεια σε εργασίες που περιλαμβάνουν συλλογισμό, α αυτοσυνέπεια Έχει προταθεί μια προσέγγιση προτροπής, η οποία αντικαθιστά την άπληστη με τη στοχαστική αποκωδικοποίηση κατά τη δημιουργία γλώσσας.
Θεμέλιο του Αμαζονίου είναι μια πλήρως διαχειριζόμενη υπηρεσία που προσφέρει μια επιλογή από μοντέλα θεμελίωσης υψηλής απόδοσης από κορυφαίες εταιρείες τεχνητής νοημοσύνης και την Amazon μέσω ενός μόνο API, μαζί με ένα ευρύ σύνολο δυνατοτήτων για την κατασκευή γενετική AI εφαρμογές με ασφάλεια, απόρρητο και υπεύθυνη τεχνητή νοημοσύνη. Με την συμπέρασμα παρτίδας API, μπορείτε να χρησιμοποιήσετε το Amazon Bedrock για να εκτελέσετε συμπεράσματα με μοντέλα θεμελίωσης σε παρτίδες και να λάβετε απαντήσεις πιο αποτελεσματικά. Αυτή η ανάρτηση δείχνει πώς να εφαρμόσετε την προτροπή αυτοσυνέπειας μέσω συμπερασμάτων παρτίδας στο Amazon Bedrock για να βελτιώσετε την απόδοση του μοντέλου σε εργασίες αριθμητικής και συλλογιστικής πολλαπλής επιλογής.
Επισκόπηση της λύσης
Η προτροπή για αυτοσυνέπεια των γλωσσικών μοντέλων βασίζεται στη δημιουργία πολλαπλών απαντήσεων που συγκεντρώνονται σε μια τελική απάντηση. Σε αντίθεση με τις προσεγγίσεις μιας γενιάς όπως η CoT, η διαδικασία αυτοσυνέπειας δείγματος και περιθωριοποίησης δημιουργεί μια σειρά από ολοκληρώσεις μοντέλων που οδηγούν σε μια πιο συνεπή λύση. Η δημιουργία διαφορετικών αποκρίσεων για μια δεδομένη προτροπή είναι δυνατή λόγω της χρήσης μιας στοχαστικής και όχι άπληστης στρατηγικής αποκωδικοποίησης.
Το παρακάτω σχήμα δείχνει πώς η αυτοσυνέπεια διαφέρει από το άπληστο CoT στο ότι δημιουργεί ένα διαφορετικό σύνολο συλλογιστικών μονοπατιών και τις συγκεντρώνει για να δώσει την τελική απάντηση.

Στρατηγικές αποκωδικοποίησης για τη δημιουργία κειμένου
Το κείμενο που δημιουργείται από μοντέλα γλώσσας μόνο για αποκωδικοποιητή ξεδιπλώνεται λέξη προς λέξη, με το επόμενο διακριτικό να προβλέπεται με βάση το προηγούμενο πλαίσιο. Για μια δεδομένη προτροπή, το μοντέλο υπολογίζει μια κατανομή πιθανότητας που δείχνει την πιθανότητα κάθε διακριτικού να εμφανίζεται στη συνέχεια στην ακολουθία. Η αποκωδικοποίηση περιλαμβάνει τη μετάφραση αυτών των κατανομών πιθανοτήτων σε πραγματικό κείμενο. Η δημιουργία κειμένου διαμεσολαβείται από ένα σύνολο παραμέτρους συμπερασμάτων που είναι συχνά υπερπαράμετροι της ίδιας της μεθόδου αποκωδικοποίησης. Ένα παράδειγμα είναι το θερμοκρασία, το οποίο διαμορφώνει την κατανομή πιθανοτήτων του επόμενου διακριτικού και επηρεάζει την τυχαιότητα της παραγωγής του μοντέλου.
Άπληστη αποκωδικοποίηση είναι μια ντετερμινιστική στρατηγική αποκωδικοποίησης που σε κάθε βήμα επιλέγει το διακριτικό με τη μεγαλύτερη πιθανότητα. Αν και απλή και αποτελεσματική, η προσέγγιση κινδυνεύει να πέσει σε επαναλαμβανόμενα μοτίβα, επειδή αγνοεί τον ευρύτερο χώρο πιθανοτήτων. Η ρύθμιση της παραμέτρου θερμοκρασίας στο 0 κατά τον χρόνο συμπερασμάτων ισοδυναμεί ουσιαστικά με την εφαρμογή άπληστης αποκωδικοποίησης.
Δειγματοληψία εισάγει τη στοχαστικότητα στη διαδικασία αποκωδικοποίησης επιλέγοντας τυχαία κάθε επόμενο διακριτικό με βάση την προβλεπόμενη κατανομή πιθανοτήτων. Αυτή η τυχαιότητα οδηγεί σε μεγαλύτερη μεταβλητότητα εξόδου. Η στοχαστική αποκωδικοποίηση αποδεικνύεται πιο ικανή στην αποτύπωση της ποικιλομορφίας των πιθανών εξόδων και συχνά αποδίδει πιο ευφάνταστες απαντήσεις. Οι υψηλότερες τιμές θερμοκρασίας εισάγουν περισσότερες διακυμάνσεις και αυξάνουν τη δημιουργικότητα της απόκρισης του μοντέλου.
Τεχνικές προτροπής: CoT και αυτοσυνέπεια
Η συλλογιστική ικανότητα των γλωσσικών μοντέλων μπορεί να αυξηθεί μέσω άμεσης μηχανικής. Συγκεκριμένα, η CoT έχει αποδειχθεί ότι προκαλέσουν συλλογισμό σε πολύπλοκες εργασίες NLP. Ένας τρόπος για την εφαρμογή του α μηδενική λήψη Το CoT γίνεται μέσω άμεσης αύξησης με την οδηγία «σκέψου βήμα προς βήμα». Ένα άλλο είναι να εκτεθεί το μοντέλο σε παραδείγματα ενδιάμεσων συλλογιστικών βημάτων προτροπή λίγων βολών μόδα. Και τα δύο σενάρια χρησιμοποιούν συνήθως άπληστη αποκωδικοποίηση. Το CoT οδηγεί σε σημαντικά κέρδη απόδοσης σε σύγκριση με απλές οδηγίες που προτρέπουν σε εργασίες αριθμητικής, κοινής λογικής και συμβολικής συλλογιστικής.
Προτροπή αυτοσυνέπειας βασίζεται στην υπόθεση ότι η εισαγωγή της διαφορετικότητας στη διαδικασία συλλογισμού μπορεί να είναι επωφελής για να βοηθήσει τα μοντέλα να συγκλίνουν στη σωστή απάντηση. Η τεχνική χρησιμοποιεί στοχαστική αποκωδικοποίηση για την επίτευξη αυτού του στόχου σε τρία βήματα:
- Προτρέψτε το γλωσσικό μοντέλο με παραδείγματα CoT για να προκαλέσει συλλογισμό.
- Αντικαταστήστε την άπληστη αποκωδικοποίηση με μια στρατηγική δειγματοληψίας για να δημιουργήσετε μια ποικιλία από μονοπάτια συλλογισμού.
- Συγκεντρώστε τα αποτελέσματα για να βρείτε την πιο συνεπή απάντηση στο σύνολο απαντήσεων.
Η αυτοσυνέπεια φαίνεται να ξεπερνά τις προτροπές CoT σε δημοφιλείς δείκτες αναφοράς αριθμητικής και κοινής λογικής. Ένας περιορισμός της προσέγγισης είναι το μεγαλύτερο υπολογιστικό της κόστος.
Αυτή η ανάρτηση δείχνει πώς η προτροπή αυτοσυνέπειας βελτιώνει την απόδοση των παραγωγικών γλωσσικών μοντέλων σε δύο συλλογιστικές εργασίες NLP: αριθμητική επίλυση προβλημάτων και απάντηση ερωτήσεων για συγκεκριμένο τομέα πολλαπλών επιλογών. Δείχνουμε την προσέγγιση χρησιμοποιώντας συμπέρασμα παρτίδας στο Amazon Bedrock:
- Έχουμε πρόσβαση στο Amazon Bedrock Python SDK στο JupyterLab σε ένα Amazon Sage Maker παράδειγμα σημειωματάριου.
- Για αριθμητικό συλλογισμό, προτρέπουμε Command Cohere σχετικά με το σύνολο δεδομένων GSM8K των μαθηματικών προβλημάτων του δημοτικού σχολείου.
- Για συλλογισμό πολλαπλής επιλογής, ζητάμε AI21 Labs Jurassic-2 Mid σε ένα μικρό δείγμα ερωτήσεων από την εξέταση AWS Certified Solutions Architect – Associate.
Προϋποθέσεις
Αυτή η περιήγηση προϋποθέτει τις ακόλουθες προϋποθέσεις:

Το εκτιμώμενο κόστος για την εκτέλεση του κώδικα που εμφανίζεται σε αυτήν την ανάρτηση είναι 100 $, υποθέτοντας ότι εκτελείτε μια φορά ζητώντας αυτοσυνέπεια με 30 διαδρομές συλλογισμού χρησιμοποιώντας μία τιμή για τη δειγματοληψία με βάση τη θερμοκρασία.
Σύνολο δεδομένων για τον έλεγχο των δυνατοτήτων αριθμητικής συλλογιστικής
GSM8K είναι ένα σύνολο δεδομένων μαθηματικών προβλημάτων του δημοτικού σχολείου που έχουν συναρμολογηθεί από τον άνθρωπο και παρουσιάζουν υψηλή γλωσσική ποικιλομορφία. Κάθε πρόβλημα απαιτεί 2-8 βήματα για να λυθεί και απαιτεί την εκτέλεση μιας ακολουθίας στοιχειωδών υπολογισμών με βασικές αριθμητικές πράξεις. Αυτά τα δεδομένα χρησιμοποιούνται συνήθως για τη συγκριτική αξιολόγηση των δυνατοτήτων αριθμητικής συλλογιστικής πολλαπλών βημάτων των μοντέλων παραγωγής γλώσσας. ο Σετ τρένου GSM8K περιλαμβάνει 7,473 εγγραφές. Το παρακάτω είναι ένα παράδειγμα:
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
Ρυθμίστε την εκτέλεση συμπερασμάτων παρτίδας με το Amazon Bedrock
Το συμπέρασμα δέσμης σάς επιτρέπει να εκτελείτε πολλαπλές κλήσεις συμπερασμάτων στο Amazon Bedrock ασύγχρονα και να βελτιώσετε την απόδοση των συμπερασμάτων μοντέλων σε μεγάλα σύνολα δεδομένων. Η υπηρεσία βρίσκεται σε προεπισκόπηση από τη σύνταξη αυτού του παρόντος και είναι διαθέσιμη μόνο μέσω του API. Αναφέρομαι σε Εκτέλεση συμπερασμάτων παρτίδας για πρόσβαση σε API συμπερασμάτων παρτίδας μέσω προσαρμοσμένων SDK.
Αφού κατεβάσετε και αποσυμπιέσετε το Python SDK σε μια παρουσία σημειωματάριου SageMaker, μπορείτε να το εγκαταστήσετε εκτελώντας τον ακόλουθο κώδικα σε ένα κελί σημειωματάριου Jupyter:
Μορφοποιήστε και ανεβάστε δεδομένα εισόδου στο Amazon S3
Τα δεδομένα εισόδου για συμπέρασμα παρτίδας πρέπει να προετοιμαστούν σε μορφή JSONL με recordId και modelInput κλειδιά. Το τελευταίο θα πρέπει να ταιριάζει με το πεδίο σώματος του μοντέλου που θα χρησιμοποιηθεί στο Amazon Bedrock. Συγκεκριμένα, κάποιοι υποστηριζόμενες παράμετροι συμπερασμάτων για την εντολή Cohere are temperature για την τυχαιότητα, max_tokens για μήκος εξόδου και num_generations για τη δημιουργία πολλαπλών απαντήσεων, οι οποίες περνούν όλες μαζί με το prompt as modelInput:
Βλέπω Παράμετροι συμπερασμάτων για μοντέλα θεμελίωσης για περισσότερες λεπτομέρειες, συμπεριλαμβανομένων άλλων παρόχων μοντέλων.
Τα πειράματά μας σχετικά με την αριθμητική συλλογιστική εκτελούνται στη ρύθμιση λίγων λήψεων χωρίς προσαρμογή ή τελειοποίηση της εντολής Cohere. Χρησιμοποιούμε το ίδιο σύνολο οκτώ παραδειγμάτων με λίγες λήψεις από την αλυσίδα της σκέψης (Πίνακας 20) και αυτοσυνέπεια (Πίνακας 17) χαρτιά. Τα μηνύματα προτροπής δημιουργούνται συνενώνοντας τα υποδείγματα με κάθε ερώτηση από το σετ τρένων GSM8K.
Ορίσαμε max_tokens σε 512 και num_generations έως 5, το μέγιστο επιτρεπόμενο από την εντολή Cohere. Για άπληστη αποκωδικοποίηση, ορίσαμε temperature στο 0 και για αυτοσυνέπεια, εκτελούμε τρία πειράματα σε θερμοκρασίες 0.5, 0.7 και 1. Κάθε ρύθμιση αποδίδει διαφορετικά δεδομένα εισόδου σύμφωνα με τις αντίστοιχες τιμές θερμοκρασίας. Τα δεδομένα μορφοποιούνται ως JSONL και αποθηκεύονται στο Amazon S3.
Δημιουργήστε και εκτελέστε εργασίες συμπερασμάτων παρτίδας στο Amazon Bedrock
Η δημιουργία θέσεων εργασίας συμπερασμάτων παρτίδας απαιτεί έναν πελάτη Amazon Bedrock. Καθορίζουμε τις διαδρομές εισόδου και εξόδου S3 και δίνουμε σε κάθε εργασία επίκλησης ένα μοναδικό όνομα:
Οι δουλειές είναι δημιουργήθηκε μεταβιβάζοντας τον ρόλο IAM, το αναγνωριστικό μοντέλου, το όνομα εργασίας και τη διαμόρφωση εισόδου/εξόδου ως παραμέτρων στο Amazon Bedrock API:
Καταχώρηση, παρακολούθηση, να στάθμευση Οι εργασίες συμπερασμάτων παρτίδας υποστηρίζονται από τις αντίστοιχες κλήσεις API τους. Κατά τη δημιουργία, οι θέσεις εργασίας εμφανίζονται πρώτα ως Submitted, στη συνέχεια ως InProgress, και τέλος ως Stopped, Failed, ή Completed.
Εάν οι εργασίες ολοκληρωθούν επιτυχώς, το περιεχόμενο που δημιουργείται μπορεί να ανακτηθεί από το Amazon S3 χρησιμοποιώντας τη μοναδική θέση εξόδου του.
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
Η αυτοσυνέπεια ενισχύει την ακρίβεια του μοντέλου στις αριθμητικές εργασίες
Η προτροπή αυτοσυνέπειας του Cohere Command υπερέχει από μια άπληστη γραμμή βάσης CoT όσον αφορά την ακρίβεια στο σύνολο δεδομένων GSM8K. Για αυτοσυνέπεια, δειγματίζουμε 30 ανεξάρτητες συλλογιστικές διαδρομές σε τρεις διαφορετικές θερμοκρασίες, με topP και topK ορίστε τους προεπιλεγμένες τιμές. Οι τελικές λύσεις συγκεντρώνονται επιλέγοντας το πιο συνεπές περιστατικό μέσω της πλειοψηφίας. Σε περίπτωση ισοπαλίας, επιλέγουμε τυχαία μία από τις απαντήσεις της πλειοψηφίας. Υπολογίζουμε την ακρίβεια και τις τιμές τυπικής απόκλισης με μέσο όρο πάνω από 100 εκτελέσεις.
Το παρακάτω σχήμα δείχνει την ακρίβεια στο σύνολο δεδομένων GSM8K από το Cohere Command που ζητήθηκε με άπληστο CoT (μπλε) και αυτοσυνέπεια σε τιμές θερμοκρασίας 0.5 (κίτρινο), 0.7 (πράσινο) και 1.0 (πορτοκαλί) ως συνάρτηση του αριθμού των δειγμάτων συλλογιστικές διαδρομές.
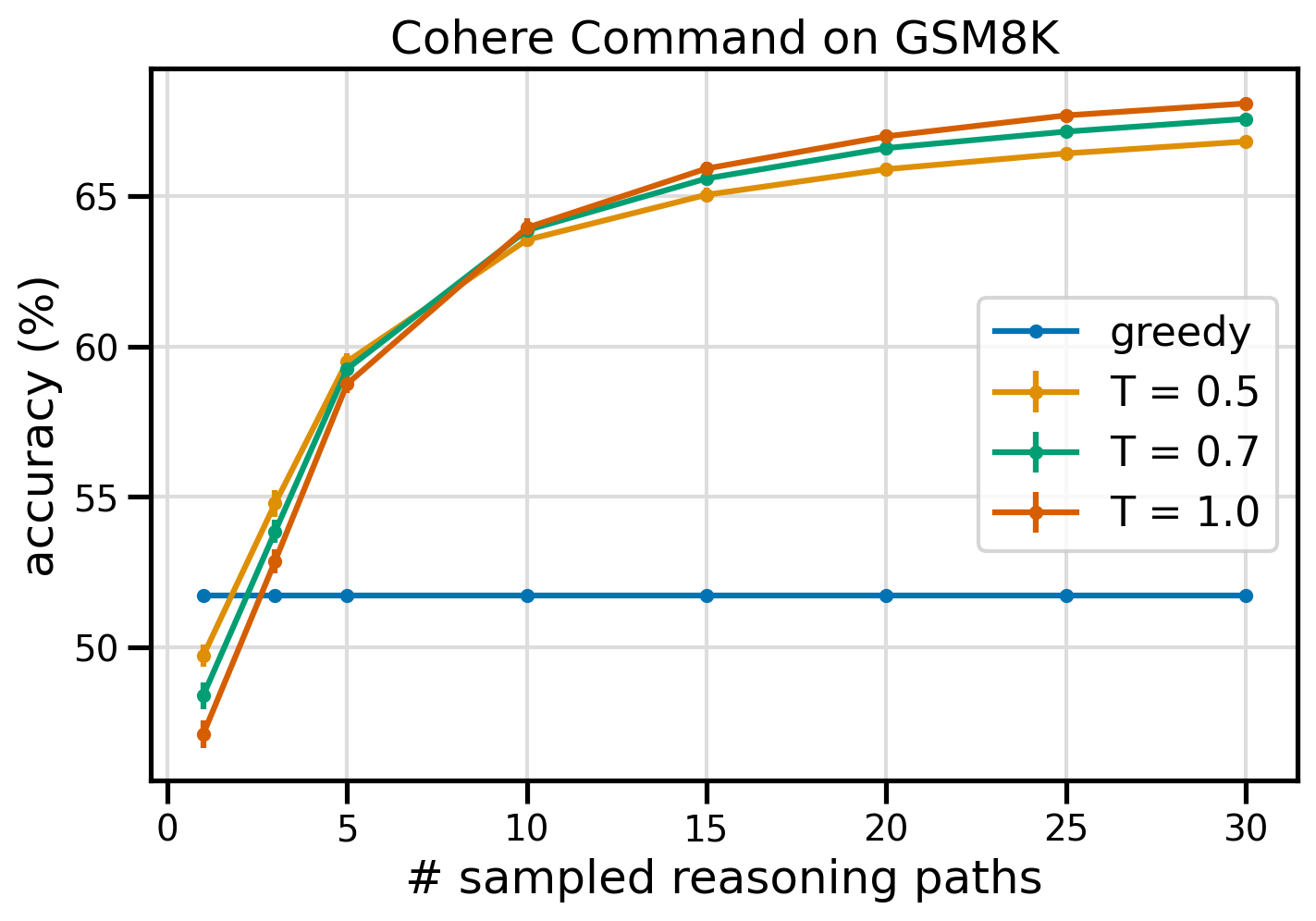
Το προηγούμενο σχήμα δείχνει ότι η αυτοσυνέπεια ενισχύει την αριθμητική ακρίβεια σε σχέση με το άπληστο CoT όταν ο αριθμός των μονοπατιών δειγματοληψίας είναι τόσο μικρός όσο τρεις. Η απόδοση αυξάνεται με συνέπεια με περαιτέρω μονοπάτια συλλογιστικής, επιβεβαιώνοντας τη σημασία της εισαγωγής διαφορετικότητας στη γενιά της σκέψης. Η εντολή Cohere λύνει το σύνολο ερωτήσεων GSM8K με ακρίβεια 51.7% όταν ζητηθεί με CoT έναντι 68% με 30 αυτοσυνεπείς διαδρομές συλλογισμού στο T=1.0. Και οι τρεις τιμές θερμοκρασίας που εξετάστηκαν αποδίδουν παρόμοια αποτελέσματα, με τις χαμηλότερες θερμοκρασίες να είναι συγκριτικά πιο αποτελεσματικές σε λιγότερα δείγματα μονοπατιών.
Πρακτικές εκτιμήσεις σχετικά με την αποτελεσματικότητα και το κόστος
Η αυτοσυνέπεια περιορίζεται από τον αυξημένο χρόνο απόκρισης και το κόστος που προκύπτει κατά τη δημιουργία πολλαπλών εξόδων ανά προτροπή. Ως πρακτική απεικόνιση, το συμπέρασμα παρτίδας για άπληστη παραγωγή με το Cohere Command σε 7,473 εγγραφές GSM8K ολοκληρώθηκε σε λιγότερο από 20 λεπτά. Η εργασία πήρε 5.5 εκατομμύρια μάρκες ως είσοδο και δημιούργησε 630,000 μάρκες εξόδου. Στο ρεύμα Τιμές συμπερασμάτων Amazon Bedrock, το συνολικό κόστος που προέκυψε ήταν περίπου 9.50 $.
Για αυτοσυνέπεια με την εντολή Cohere, χρησιμοποιούμε την παράμετρο συμπερασμάτων num_generations για να δημιουργήσετε πολλαπλές ολοκληρώσεις ανά προτροπή. Από τη στιγμή που γράφεται αυτό το άρθρο, το Amazon Bedrock επιτρέπει το πολύ πέντε γενιές και τρεις ταυτόχρονες Submitted εργασίες συμπερασμάτων παρτίδας. Οι θέσεις εργασίας προχωρούν στο InProgress κατάσταση διαδοχικά, επομένως η δειγματοληψία περισσότερων από πέντε διαδρομών απαιτεί πολλαπλές κλήσεις.
Το παρακάτω σχήμα δείχνει τους χρόνους εκτέλεσης για το Cohere Command στο σύνολο δεδομένων GSM8K. Ο συνολικός χρόνος εκτέλεσης εμφανίζεται στον άξονα x και ο χρόνος εκτέλεσης ανά διαδρομή συλλογιστικής δειγματοληψίας στον άξονα y. Η άπληστη παραγωγή εκτελείται στο συντομότερο χρόνο, αλλά συνεπάγεται υψηλότερο κόστος χρόνου ανά διαδρομή δειγματοληψίας.

Η δημιουργία Greedy ολοκληρώνεται σε λιγότερο από 20 λεπτά για το πλήρες σετ GSM8K και δοκιμάζει μια μοναδική διαδρομή συλλογισμού. Η αυτοσυνέπεια με πέντε δείγματα απαιτεί περίπου 50% περισσότερο χρόνο για να ολοκληρωθεί και κοστίζει περίπου 14.50 $, αλλά παράγει πέντε διαδρομές (πάνω από 500%) σε αυτό το διάστημα. Ο συνολικός χρόνος εκτέλεσης και το κόστος αυξάνονται σταδιακά με κάθε επιπλέον πέντε διαδρομές δειγματοληψίας. Μια ανάλυση κόστους-οφέλους προτείνει ότι 1–2 εργασίες συμπερασμάτων παρτίδας με 5–10 δειγματοληπτικά μονοπάτια είναι η συνιστώμενη ρύθμιση για την πρακτική εφαρμογή της αυτοσυνέπειας. Αυτό επιτυγχάνει βελτιωμένη απόδοση του μοντέλου, διατηρώντας ταυτόχρονα το κόστος και την καθυστέρηση.
Η αυτοσυνέπεια ενισχύει την απόδοση του μοντέλου πέρα από την αριθμητική συλλογιστική
Ένα κρίσιμο ερώτημα για να αποδειχθεί η καταλληλότητα της προτροπής αυτοσυνέπειας είναι εάν η μέθοδος επιτυγχάνει σε περαιτέρω εργασίες NLP και γλωσσικά μοντέλα. Ως επέκταση σε περίπτωση χρήσης που σχετίζεται με το Amazon, εκτελούμε μια ανάλυση μικρού μεγέθους σε δείγματα ερωτήσεων από το Πιστοποίηση AWS Solutions Architect Associate. Αυτή είναι μια εξέταση πολλαπλών επιλογών για την τεχνολογία και τις υπηρεσίες AWS που απαιτεί γνώση του τομέα και την ικανότητα να αιτιολογήσετε και να αποφασίσετε ανάμεσα σε πολλές επιλογές.
Ετοιμάζουμε ένα σύνολο δεδομένων από SAA-C01 και SAA-C03 δείγματα ερωτήσεων εξετάσεων. Από τις 20 διαθέσιμες ερωτήσεις, χρησιμοποιούμε τις πρώτες 4 ως παραδείγματα λίγων λήψεων και ζητάμε από το μοντέλο να απαντήσει στις υπόλοιπες 16. Αυτή τη φορά, εκτελούμε συμπεράσματα με το μοντέλο AI21 Labs Jurassic-2 Mid και δημιουργούμε το πολύ 10 μονοπάτια συλλογιστικής στο θερμοκρασία 0.7. Τα αποτελέσματα δείχνουν ότι η αυτοσυνέπεια ενισχύει την απόδοση: αν και το άπληστο CoT παράγει 11 σωστές απαντήσεις, η αυτοσυνέπεια επιτυγχάνει σε άλλες 2.
Ο παρακάτω πίνακας δείχνει τα αποτελέσματα ακρίβειας για 5 και 10 διαδρομές δειγματοληψίας με μέσο όρο σε 100 διαδρομές.
| . | Άπληστη αποκωδικοποίηση | Τ = 0.7 |
| # δειγματοληπτικά μονοπάτια: 5 | 68.6 | 74.1 0.7 ± |
| # δειγματοληπτικά μονοπάτια: 10 | 68.6 | 78.9 ± 0.3 |
Στον παρακάτω πίνακα, παρουσιάζουμε δύο ερωτήσεις εξετάσεων που απαντώνται λανθασμένα από το άπληστο CoT ενώ η αυτοσυνέπεια πετυχαίνει, επισημαίνοντας σε κάθε περίπτωση τα σωστά (πράσινα) ή λανθασμένα (κόκκινα) ίχνη συλλογισμού που οδήγησαν το μοντέλο να παράγει σωστές ή λανθασμένες απαντήσεις. Αν και δεν είναι σωστή κάθε διαδρομή δειγματοληψίας που δημιουργείται από αυτοσυνέπεια, η πλειονότητα συγκλίνει στην αληθινή απάντηση καθώς αυξάνεται ο αριθμός των μονοπατιών δειγματοληψίας. Παρατηρούμε ότι 5-10 διαδρομές είναι συνήθως αρκετές για να βελτιωθούν σε σχέση με τα άπληστα αποτελέσματα, με μειωμένες αποδόσεις όσον αφορά την αποτελεσματικότητα πέρα από αυτές τις τιμές.
| Ερώτηση |
Μια διαδικτυακή εφαρμογή επιτρέπει στους πελάτες να ανεβάζουν παραγγελίες σε έναν κάδο S3. Τα προκύπτοντα συμβάντα Amazon S3 ενεργοποιούν μια συνάρτηση Lambda που εισάγει ένα μήνυμα σε μια ουρά SQS. Μια μεμονωμένη παρουσία EC2 διαβάζει μηνύματα από την ουρά, τα επεξεργάζεται και τα αποθηκεύει σε έναν πίνακα DynamoDB που διαιρείται με μοναδικό αναγνωριστικό παραγγελίας. Τον επόμενο μήνα η επισκεψιμότητα αναμένεται να αυξηθεί κατά 10 και ένας αρχιτέκτονας λύσεων εξετάζει την αρχιτεκτονική για πιθανά προβλήματα κλιμάκωσης. Ποιο στοιχείο είναι ΠΕΡΙΣΣΟΤΕΡΟ να χρειάζεται ανακατασκευή για να μπορέσει να κλιμακωθεί για να καλύψει τη νέα κίνηση; Α. Συνάρτηση λάμδα |
Μια εφαρμογή που εκτελείται σε AWS χρησιμοποιεί μια ανάπτυξη συμπλέγματος Amazon Aurora Multi-AZ DB για τη βάση δεδομένων της. Κατά την αξιολόγηση των μετρήσεων απόδοσης, ένας αρχιτέκτονας λύσεων ανακάλυψε ότι οι αναγνώσεις της βάσης δεδομένων προκαλούν υψηλές εισόδους/εξόδους και προσθέτουν καθυστέρηση στα αιτήματα εγγραφής έναντι της βάσης δεδομένων. Τι πρέπει να κάνει ο αρχιτέκτονας λύσεων για να διαχωρίσει τα αιτήματα ανάγνωσης από τα αιτήματα εγγραφής; A. Ενεργοποιήστε την προσωρινή αποθήκευση ανάγνωσης στη βάση δεδομένων Aurora. |
| Σωστή απάντηση | C – Ένα μόνο στιγμιότυπο EC2 δεν θα κλιμακωθεί και είναι ένα μόνο σημείο αστοχίας στην αρχιτεκτονική. Μια πολύ καλύτερη λύση θα ήταν να έχετε παρουσίες EC2 σε μια ομάδα Αυτόματης Κλιμάκωσης σε 2 ζώνες διαθεσιμότητας να διαβάζουν μηνύματα από την ουρά. Οι άλλες απαντήσεις είναι όλες διαχειριζόμενες υπηρεσίες που μπορούν να ρυθμιστούν ώστε να κλιμακώνονται ή να κλιμακώνονται αυτόματα. | C – Τα Aurora Replicas παρέχουν έναν τρόπο εκφόρτωσης της κυκλοφορίας ανάγνωσης. Τα Aurora Replicas μοιράζονται τον ίδιο υποκείμενο χώρο αποθήκευσης με την κύρια βάση δεδομένων, επομένως ο χρόνος καθυστέρησης είναι γενικά πολύ χαμηλός. Τα Aurora Replicas έχουν τα δικά τους τελικά σημεία, επομένως η εφαρμογή θα πρέπει να ρυθμιστεί ώστε να κατευθύνει την κυκλοφορία ανάγνωσης στα νέα τελικά σημεία. |
| Άπληστη αποκωδικοποίηση | Η απευθείας κλιμάκωση της παρουσίας EC2 ενδέχεται να μην είναι δυνατή, καθώς ενδέχεται να μην είναι δυνατή η αλλαγή μεγέθους της παρουσίας. Η κλιμάκωση της συνάρτησης λάμδα μπορεί να μην είναι επαρκής, καθώς οι λειτουργίες Lambda έχουν όριο εκχώρησης μνήμης 6 GB. Η κλιμάκωση της ουράς SQS μπορεί να μην είναι επαρκής, καθώς το SQS έχει όριο 10,000 μηνυμάτων. Οι πίνακες DynamoDB μπορούν να κλιμακωθούν παρέχοντας περισσότερες μονάδες χωρητικότητας. Η σωστή απάντηση είναι Δ. | Τροποποίηση της εφαρμογής για ανάγνωση από την κατάσταση αναμονής Multi-AZ (επιλογή Β) είναι η καλύτερη προσέγγιση. Η παρουσία αναμονής αναπαράγεται ασύγχρονα από την κύρια εμφάνιση, επομένως οι λειτουργίες ανάγνωσης δεν θα παρεμβαίνουν στις λειτουργίες εγγραφής. Ενεργοποίηση προσωρινής αποθήκευσης ανάγνωσης (επιλογή Α) ή Η δημιουργία ενός αντιγράφου Aurora (επιλογή C) δεν θα λύσει το ζήτημα της διαμάχης I/O. Η δημιουργία μιας δεύτερης βάσης δεδομένων Aurora και η σύνδεσή της ως αντίγραφο ανάγνωσης (επιλογή Δ) δεν θα λύσει ούτε το ζήτημα της διαμάχης I/O. Η σωστή απάντηση είναι η Β. |
| Δείγμα διαδρομής #1 | Η κλιμάκωση του στιγμιότυπου EC2 στο 10 φορές το τρέχον μέγεθός του μπορεί να μην είναι εφικτή, είτε από πλευράς κόστους είτε από άποψη απόδοσης. Θα απαιτούσε ένα μεγαλύτερο παράδειγμα, το οποίο μπορεί να είναι ακριβό. Μια πιο οικονομική προσέγγιση μπορεί να είναι η χρήση ενός σμήνος μικρότερων περιπτώσεων (π.χ. Auto Scaling Group) για να μοιραστείτε το φορτίο. Σε αυτήν την περίπτωση, το στιγμιότυπο EC2 πιθανότατα θα χρειαστεί να ανακατασκευαστεί. Η σωστή απάντηση είναι Γ. | Η τροποποίηση της εφαρμογής για χρήση των κατάλληλων τελικών σημείων δεν είναι πρακτική λύση, καθώς θα απαιτούσε αλλαγές στον κώδικα της εφαρμογής. Η σωστή απάντηση είναι C: Δημιουργήστε ένα αντίγραφο Aurora και τροποποιήστε την εφαρμογή για να χρησιμοποιήσετε τα κατάλληλα τελικά σημεία. |
| Δείγμα διαδρομής #2 | Η κλιμάκωση μιας μεμονωμένης παρουσίας EC2 είναι πιο δύσκολη και προβληματική από την κλιμάκωση των άλλων στοιχείων υπηρεσίας. Το Amazon SQS, το Lambda και το DynamoDB μπορούν όλα να κλιμακωθούν αυτόματα για να αντιμετωπίσετε το αυξημένο φορτίο. Η σωστή απάντηση είναι Γ. |
(ΝΤΟ) Δημιουργήστε ένα αντίγραφο Aurora και τροποποιήστε την εφαρμογή για να χρησιμοποιήσετε τα κατάλληλα τελικά σημεία. Διαμορφώνοντας ένα Aurora Replica, μπορείτε να διαχωρίσετε την κυκλοφορία ανάγνωσης από την κυκλοφορία εγγραφής. Τα αντίγραφα Aurora χρησιμοποιούν διαφορετικές διευθύνσεις URL τελικού σημείου, επιτρέποντάς σας να κατευθύνετε την κυκλοφορία ανάγνωσης στο αντίγραφο αντί στην κύρια βάση δεδομένων. Το αντίγραφο μπορεί να επεξεργαστεί αιτήματα ανάγνωσης παράλληλα με αιτήματα εγγραφής στην κύρια βάση δεδομένων, μειώνοντας το I/O και την καθυστέρηση. |
εκκαθάριση
Η εκτέλεση συμπερασμάτων παρτίδας στο Amazon Bedrock υπόκειται σε χρεώσεις σύμφωνα με την τιμολόγηση του Amazon Bedrock. Όταν ολοκληρώσετε την καθοδήγηση, διαγράψτε την παρουσία του φορητού υπολογιστή SageMaker και αφαιρέστε όλα τα δεδομένα από τους κάδους S3 για να αποφύγετε μελλοντικές χρεώσεις.
Κρίσεις
Αν και η επίδειξη λύση δείχνει βελτιωμένη απόδοση των μοντέλων γλώσσας όταν ζητείται με αυτοσυνέπεια, είναι σημαντικό να σημειωθεί ότι η αναλυτική παρουσίαση δεν είναι έτοιμη για παραγωγή. Πριν ξεκινήσετε την παραγωγή, θα πρέπει να προσαρμόσετε αυτήν την απόδειξη της ιδέας στη δική σας εφαρμογή, έχοντας υπόψη τις ακόλουθες απαιτήσεις:
- Περιορισμός πρόσβασης σε API και βάσεις δεδομένων για την αποτροπή μη εξουσιοδοτημένης χρήσης.
- Συμμόρφωση με τις βέλτιστες πρακτικές ασφάλειας AWS σχετικά με την πρόσβαση ρόλων IAM και τις ομάδες ασφαλείας.
- Επικύρωση και απολύμανση των εισροών χρήστη για την αποφυγή επιθέσεων έγκαιρης έγχυσης.
- Παρακολούθηση και καταγραφή των ενεργοποιημένων διεργασιών για να καταστεί δυνατή η δοκιμή και ο έλεγχος.
Συμπέρασμα
Αυτή η ανάρτηση δείχνει ότι η προτροπή αυτοσυνέπειας βελτιώνει την απόδοση των μοντέλων παραγωγής γλώσσας σε σύνθετες εργασίες NLP που απαιτούν αριθμητικές και λογικές δεξιότητες πολλαπλής επιλογής. Η αυτοσυνέπεια χρησιμοποιεί στοχαστική αποκωδικοποίηση με βάση τη θερμοκρασία για να δημιουργήσει διάφορες συλλογιστικές διαδρομές. Αυτό αυξάνει την ικανότητα του μοντέλου να προκαλεί ποικίλες και χρήσιμες σκέψεις για να καταλήξει σε σωστές απαντήσεις.
Με το συμπέρασμα παρτίδας του Amazon Bedrock, το γλωσσικό μοντέλο Cohere Command ζητείται να δημιουργήσει αυτοσυνεπείς απαντήσεις σε ένα σύνολο αριθμητικών προβλημάτων. Η ακρίβεια βελτιώνεται από 51.7% με άπληστη αποκωδικοποίηση σε 68% με δειγματοληψία αυτοσυνέπειας 30 μονοπατιών συλλογισμού σε T=1.0. Η δειγματοληψία πέντε διαδρομών βελτιώνει ήδη την ακρίβεια κατά 7.5 τοις εκατό μονάδες. Η προσέγγιση μπορεί να μεταφερθεί σε άλλα γλωσσικά μοντέλα και συλλογιστικές εργασίες, όπως αποδεικνύεται από τα αποτελέσματα του μοντέλου AI21 Labs Jurassic-2 Mid σε μια εξέταση πιστοποίησης AWS. Σε ένα σύνολο ερωτήσεων μικρού μεγέθους, η αυτοσυνέπεια με πέντε δειγματοληπτικά μονοπάτια αυξάνει την ακρίβεια κατά 5 τοις εκατό σε σχέση με το άπληστο CoT.
Σας ενθαρρύνουμε να εφαρμόσετε προτροπή αυτοσυνέπειας για βελτιωμένη απόδοση στις δικές σας εφαρμογές με μοντέλα παραγωγής γλώσσας. Μάθε περισσότερα για Command Cohere και AI21 Labs Jurassic μοντέλα διαθέσιμα στο Amazon Bedrock. Για περισσότερες πληροφορίες σχετικά με το συμπέρασμα παρτίδας, ανατρέξτε στο Εκτέλεση συμπερασμάτων παρτίδας.
Ευχαριστίες
Ο συγγραφέας ευχαριστεί τους τεχνικούς κριτές Amin Tajgardoon και Patrick McSweeney για τα χρήσιμα σχόλια.
Σχετικά με το Συγγραφέας

Λουκία Σανταμαρία είναι Sr. Applied Scientist στο ML University της Amazon, όπου έχει επικεντρωθεί στην αύξηση του επιπέδου ικανότητας ML σε όλη την εταιρεία μέσω της πρακτικής εκπαίδευσης. Η Lucía έχει διδακτορικό στην αστροφυσική και είναι παθιασμένη με τον εκδημοκρατισμό της πρόσβασης σε τεχνολογικές γνώσεις και εργαλεία.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/enhance-performance-of-generative-language-models-with-self-consistency-prompting-on-amazon-bedrock/

