Mit dem Wachstum von Roblox in den letzten mehr als 16 Jahren sind auch der Umfang und die Komplexität der technischen Infrastruktur gewachsen, die Millionen immersiver 3D-Ko-Erlebnisse ermöglicht. Die Anzahl der von uns betreuten Maschinen hat sich in den letzten zwei Jahren mehr als verdreifacht, von etwa 36,000 zum 30. Juni 2021 auf heute fast 145,000. Um diese ständig verfügbaren Erlebnisse für Menschen auf der ganzen Welt zu unterstützen, sind mehr als 1,000 interne Dienste erforderlich. Um uns dabei zu helfen, Kosten und Netzwerklatenz zu kontrollieren, stellen wir diese Maschinen als Teil einer maßgeschneiderten und hybriden privaten Cloud-Infrastruktur bereit und verwalten sie, die hauptsächlich vor Ort ausgeführt wird.
Unsere Infrastruktur unterstützt derzeit mehr als 70 Millionen täglich aktive Benutzer auf der ganzen Welt, einschließlich der Entwickler, die auf die von Roblox angewiesen sind Wirtschaft für ihre Geschäfte. Alle diese Millionen Menschen erwarten ein sehr hohes Maß an Zuverlässigkeit. Angesichts der immersiven Natur unserer Erlebnisse ist die Toleranz gegenüber Verzögerungen oder Latenzen, ganz zu schweigen von Ausfällen, äußerst gering. Roblox ist eine Plattform für Kommunikation und Verbindung, auf der Menschen in immersiven 3D-Erlebnissen zusammenkommen. Wenn Menschen als ihre Avatare in einem immersiven Raum kommunizieren, fallen selbst geringfügige Verzögerungen oder Störungen deutlicher auf als bei einem Text-Thread oder einer Telefonkonferenz.
Im Oktober 2021 kam es zu einem systemweiten Ausfall. Es begann klein, mit einem Problem in einer Komponente in einem Rechenzentrum. Während unserer Ermittlungen verbreitete sich das Problem jedoch schnell und führte schließlich zu einem 73-stündigen Ausfall. Damals teilten wir beides Details darüber, was passiert ist und einige unserer ersten Erkenntnisse aus diesem Thema. Seitdem untersuchen wir diese Erkenntnisse und arbeiten daran, die Widerstandsfähigkeit unserer Infrastruktur gegenüber den Arten von Ausfällen zu erhöhen, die in allen Großsystemen aufgrund von Faktoren wie extremen Verkehrsspitzen, Wetter, Hardwarefehlern, Softwarefehlern oder einfach nur auftreten Menschen machen Fehler. Wenn solche Fehler auftreten, wie stellen wir sicher, dass sich ein Problem in einer einzelnen Komponente oder Komponentengruppe nicht auf das gesamte System ausbreitet? Diese Frage beschäftigt uns seit zwei Jahren und während die Arbeit noch andauert, zahlt sich das, was wir bisher getan haben, bereits aus. Beispielsweise haben wir im ersten Halbjahr 2023 im Vergleich zum ersten Halbjahr 125 2022 Millionen Engagement-Stunden pro Monat eingespart. Heute teilen wir die Arbeit, die wir bereits geleistet haben, sowie unsere längerfristige Vision für den Aufbau ein widerstandsfähigeres Infrastruktursystem.
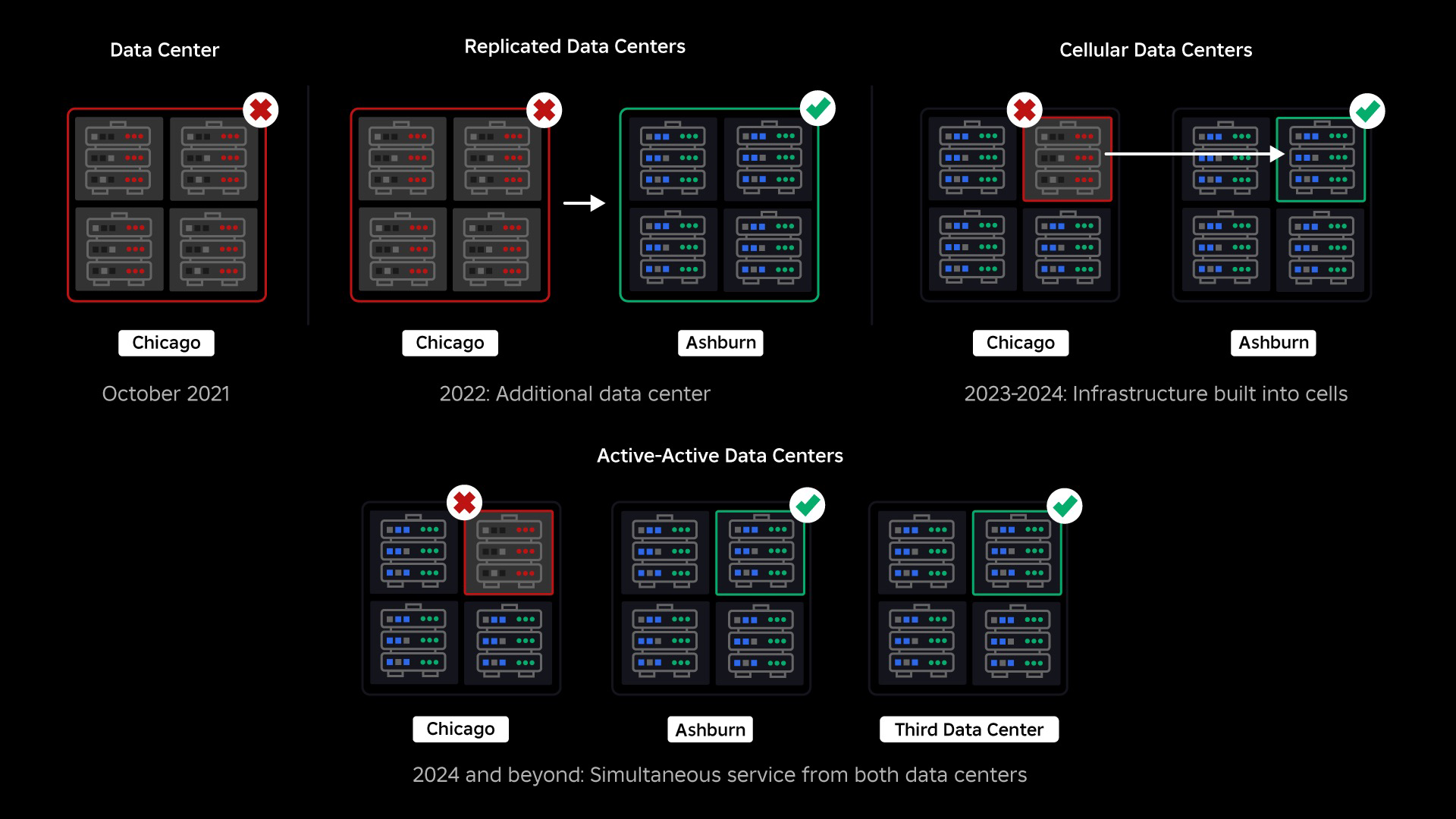
Aufbau eines Backstops
In großen Infrastruktursystemen kommt es mehrmals täglich zu kleineren Ausfällen. Wenn bei einer Maschine ein Problem auftritt und diese außer Betrieb genommen werden muss, ist das beherrschbar, da die meisten Unternehmen mehrere Instanzen ihrer Back-End-Dienste unterhalten. Wenn also eine einzelne Instanz ausfällt, übernehmen andere die Arbeitslast. Um diese häufigen Fehler zu beheben, werden Anfragen im Allgemeinen so eingestellt, dass sie bei einem Fehler automatisch erneut versuchen.
Dies wird zu einer Herausforderung, wenn ein System oder eine Person zu aggressiv erneut versucht, was dazu führen kann, dass sich diese kleinen Fehler über die gesamte Infrastruktur auf andere Dienste und Systeme ausbreiten. Wenn das Netzwerk oder ein Benutzer den Versuch beharrlich genug wiederholt, wird es schließlich jede Instanz dieses Dienstes und möglicherweise auch andere Systeme weltweit überlasten. Unser Ausfall im Jahr 2021 war das Ergebnis von etwas, das in großen Systemen ziemlich häufig vorkommt: Ein Fehler fängt klein an, breitet sich dann im System aus und wird so schnell groß, dass es schwer ist, ihn zu beheben, bevor alles ausfällt.
Zum Zeitpunkt unseres Ausfalls verfügten wir über ein aktives Rechenzentrum (mit Komponenten darin, die als Backup dienten). Wir brauchten die Möglichkeit, manuell ein Failover auf ein neues Rechenzentrum durchzuführen, wenn ein Problem das bestehende Rechenzentrum zum Absturz brachte. Unsere erste Priorität bestand darin, sicherzustellen, dass wir über eine Backup-Bereitstellung von Roblox verfügen, also haben wir dieses Backup in einem neuen Rechenzentrum in einer anderen geografischen Region erstellt. Dies bietet zusätzlichen Schutz für den schlimmsten Fall: Ein Ausfall breitet sich auf so viele Komponenten innerhalb eines Rechenzentrums aus, dass es völlig funktionsunfähig wird. Wir verfügen jetzt über ein Rechenzentrum, das die Arbeitslasten verwaltet (aktiv) und eines im Standby-Modus, das als Backup dient (passiv). Unser langfristiges Ziel besteht darin, von dieser Aktiv-Passiv-Konfiguration zu einer Aktiv-Aktiv-Konfiguration überzugehen, bei der beide Rechenzentren Arbeitslasten verarbeiten und ein Lastausgleichsdienst die Anforderungen basierend auf Latenz, Kapazität und Zustand zwischen ihnen verteilt. Sobald dies umgesetzt ist, erwarten wir eine noch höhere Zuverlässigkeit für ganz Roblox und einen Ausfall nahezu augenblicklich statt über mehrere Stunden. 
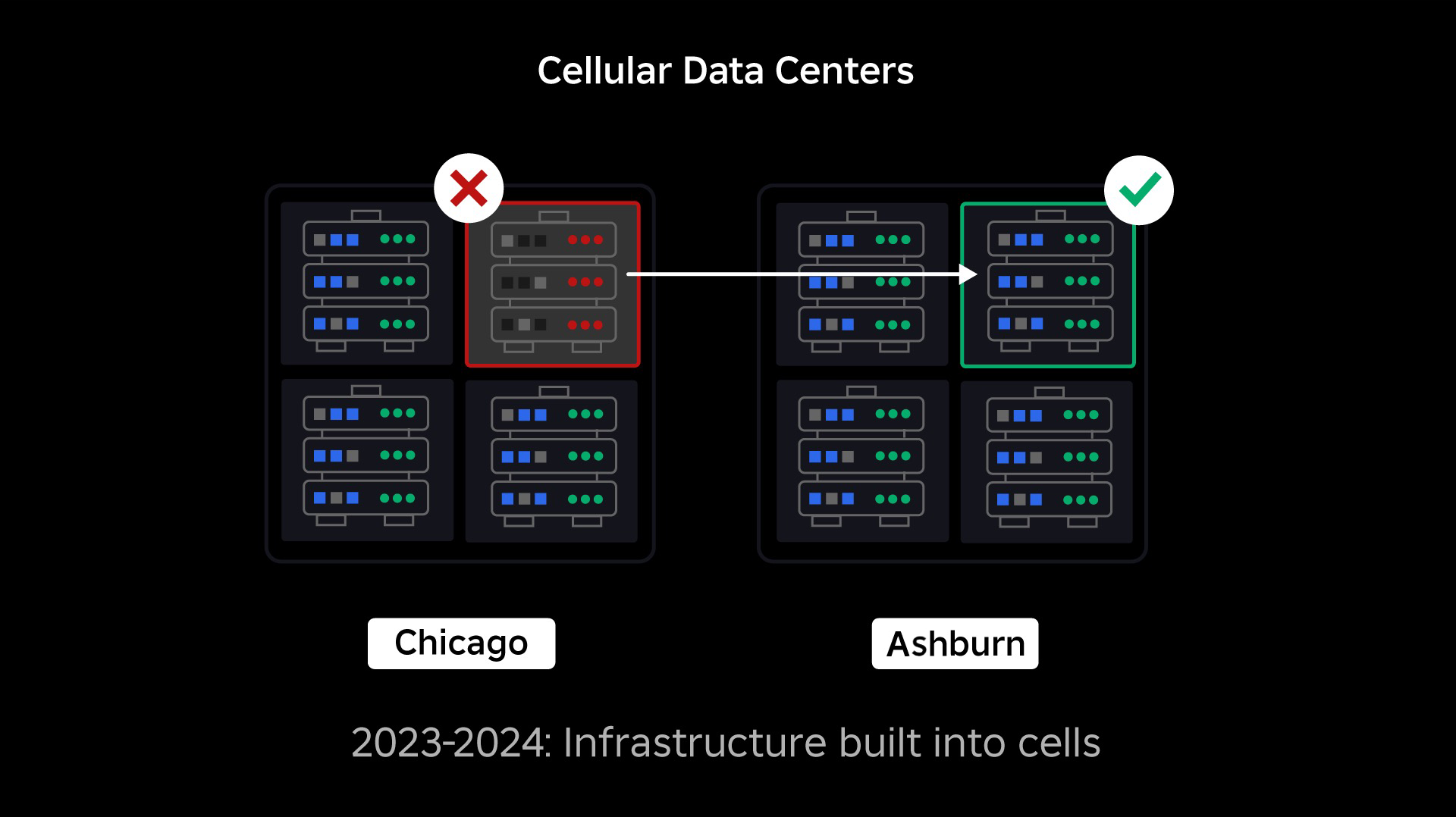
Übergang zu einer Mobilfunkinfrastruktur
Unsere nächste Priorität bestand darin, in jedem Rechenzentrum starke Sprengschutzwände zu errichten, um die Möglichkeit eines Ausfalls eines gesamten Rechenzentrums zu verringern. Zellen (einige Unternehmen nennen sie Cluster) sind im Wesentlichen eine Reihe von Maschinen und dienen dazu, diese Wände zu erschaffen. Für zusätzliche Redundanz replizieren wir Dienste sowohl innerhalb als auch zwischen Zellen. Letztendlich möchten wir, dass alle Dienste bei Roblox in Zellen laufen, damit sie sowohl von starken Explosionswänden als auch von Redundanz profitieren können. Wenn eine Zelle nicht mehr funktionsfähig ist, kann sie bedenkenlos deaktiviert werden. Durch die zellenübergreifende Replikation kann der Dienst weiter ausgeführt werden, während die Zelle repariert wird. In einigen Fällen kann die Zellreparatur eine vollständige Neubereitstellung der Zelle bedeuten. In der gesamten Branche ist das Löschen und erneute Bereitstellen einer einzelnen Maschine oder einer kleinen Gruppe von Maschinen ziemlich üblich, dies jedoch nicht für eine ganze Zelle, die etwa 1,400 Maschinen enthält.
Damit dies funktioniert, müssen diese Zellen weitgehend einheitlich sein, damit wir Arbeitslasten schnell und effizient von einer Zelle in eine andere verschieben können. Wir haben bestimmte Anforderungen festgelegt, die Dienste erfüllen müssen, bevor sie in einer Zelle ausgeführt werden. Beispielsweise müssen Dienste in Containern zusammengefasst werden, wodurch sie viel portabler werden und niemand Konfigurationsänderungen auf Betriebssystemebene vornehmen kann. Wir haben eine Infrastructure-as-Code-Philosophie für Zellen übernommen: In unserem Quellcode-Repository nehmen wir die Definition von allem auf, was sich in einer Zelle befindet, damit wir sie mit automatisierten Tools schnell von Grund auf neu erstellen können.
Derzeit erfüllen nicht alle Dienste diese Anforderungen. Deshalb haben wir daran gearbeitet, Dienstbesitzer dabei zu unterstützen, diese Anforderungen nach Möglichkeit zu erfüllen, und wir haben neue Tools entwickelt, um die Migration von Diensten in Zellen zu vereinfachen, wenn sie bereit sind. Beispielsweise „streift“ unser neues Bereitstellungstool eine Dienstbereitstellung automatisch über Zellen hinweg, sodass Dienstbesitzer nicht über die Replikationsstrategie nachdenken müssen. Dieses Maß an Genauigkeit macht den Migrationsprozess viel anspruchsvoller und zeitaufwändiger, aber auf lange Sicht wird sich ein System auszahlen, bei dem:
- Es ist viel einfacher, einen Fehler einzudämmen und zu verhindern, dass er sich auf andere Zellen ausbreitet.
- Unsere Infrastrukturingenieure können effizienter sein und schneller agieren; Und
- Die Ingenieure, die die Dienste auf Produktebene entwickeln, die letztendlich in den Zellen bereitgestellt werden, müssen nicht wissen oder sich darüber Gedanken machen, in welchen Zellen ihre Dienste ausgeführt werden.
Größere Herausforderungen lösen
Ähnlich wie Brandschutztüren zur Eindämmung von Flammen verwendet werden, fungieren Zellen als starke Sprengwände innerhalb unserer Infrastruktur, um dabei zu helfen, jedes Problem einzudämmen, das einen Ausfall in einer einzelnen Zelle auslöst. Letztendlich werden alle Dienste, aus denen Roblox besteht, redundant innerhalb und zwischen Zellen bereitgestellt. Sobald diese Arbeit abgeschlossen ist, könnten sich Probleme immer noch so weit ausbreiten, dass eine ganze Zelle funktionsunfähig wird. Es wäre jedoch äußerst schwierig, dass sich ein Problem über diese Zelle hinaus ausbreitet. Und wenn es uns gelingt, Zellen austauschbar zu machen, wird die Genesung deutlich schneller vonstatten gehen denn wir können ein Failover auf eine andere Zelle durchführen und verhindern, dass sich das Problem auf die Endbenutzer auswirkt.
Schwierig wird es, diese Zellen so weit zu trennen, dass die Möglichkeit der Fehlerausbreitung verringert wird und gleichzeitig die Leistung und Funktionalität erhalten bleibt. In einem komplexen Infrastruktursystem müssen Dienste miteinander kommunizieren, um Abfragen, Informationen, Arbeitslasten usw. auszutauschen. Wenn wir diese Dienste in Zellen replizieren, müssen wir darüber nachdenken, wie wir die Querkommunikation verwalten. In einer idealen Welt leiten wir den Datenverkehr von einer ungesunden Zelle zu anderen gesunden Zellen um. Aber wie gehen wir mit einer „Frage des Todes“ um – und zwar einer solchen? verursacht eine Zelle, um ungesund zu sein? Wenn wir diese Abfrage an eine andere Zelle umleiten, kann dies dazu führen, dass diese Zelle genau so fehlerhaft wird, wie wir es vermeiden möchten. Wir müssen Mechanismen finden, um „guten“ Datenverkehr von ungesunden Zellen zu verlagern und gleichzeitig den Datenverkehr zu erkennen und zu unterdrücken, der dazu führt, dass Zellen ungesund werden.
Kurzfristig haben wir Kopien von Rechendiensten für jede Rechenzelle bereitgestellt, sodass die meisten Anfragen an das Rechenzentrum von einer einzelnen Zelle bedient werden können. Wir sorgen auch für einen Lastausgleich des Datenverkehrs zwischen den Zellen. Mit Blick auf die weitere Zukunft haben wir mit dem Aufbau eines Service-Discovery-Prozesses der nächsten Generation begonnen, der von einem Service-Mesh genutzt wird und den wir hoffentlich im Jahr 2024 fertigstellen werden Es hat keine negativen Auswirkungen auf die Failover-Zellen. Im Jahr 2024 wird es außerdem eine Methode geben, abhängige Anfragen an eine Dienstversion in derselben Zelle weiterzuleiten, wodurch der zellenübergreifende Datenverkehr minimiert und dadurch das Risiko einer zellenübergreifenden Ausbreitung von Fehlern verringert wird.
Zu Spitzenzeiten werden mehr als 70 Prozent unseres Back-End-Service-Verkehrs über Zellen abgewickelt, und wir haben viel über die Erstellung von Zellen gelernt. Wir rechnen jedoch mit weiteren Untersuchungen und Tests, während wir unsere Dienste bis 2024 weiter migrieren darüber hinaus. Je weiter wir fortschreiten, desto stärker werden diese Sprengwände.
Migration einer Always-On-Infrastruktur
Roblox ist eine globale Plattform, die Benutzer auf der ganzen Welt unterstützt. Daher können wir Dienste nicht außerhalb der Hauptverkehrszeiten oder in „Ausfallzeiten“ verschieben, was den Prozess der Migration aller unserer Maschinen in Zellen und der Ausführung unserer Dienste in diesen Zellen zusätzlich erschwert . Wir haben Millionen von Always-on-Erlebnissen, die weiterhin unterstützt werden müssen, auch wenn wir die Maschinen, auf denen sie laufen, und die Dienste, die sie unterstützen, verschieben. Als wir mit diesem Prozess begannen, standen uns nicht Zehntausende Maschinen ungenutzt zur Verfügung, auf die wir diese Arbeitslasten migrieren konnten.
Allerdings verfügten wir über eine kleine Anzahl zusätzlicher Maschinen, die wir in Erwartung künftigen Wachstums gekauft hatten. Zunächst haben wir mit diesen Maschinen neue Zellen gebaut und dann die Arbeitslasten dorthin migriert. Wir legen sowohl Wert auf Effizienz als auch auf Zuverlässigkeit. Anstatt also loszuziehen und weitere Maschinen zu kaufen, sobald uns die „Ersatzmaschinen“ ausgegangen sind, haben wir mehr Zellen gebaut, indem wir die Maschinen, von denen wir migriert hatten, gelöscht und neu bereitgestellt haben. Anschließend migrierten wir die Workloads auf diese neu bereitgestellten Maschinen und begannen den Prozess von vorne. Dieser Prozess ist komplex – wenn Maschinen ausgetauscht und für den Einbau in Zellen freigegeben werden, geschieht dies nicht auf ideale, geordnete Weise. Sie sind physisch über mehrere Datenhallen hinweg fragmentiert, so dass wir sie stückweise bereitstellen müssen, was einen Defragmentierungsprozess auf Hardwareebene erfordert, um die Hardwarestandorte mit großen physischen Fehlerdomänen in Einklang zu bringen.
Ein Teil unseres Infrastruktur-Engineering-Teams konzentriert sich auf die Migration bestehender Workloads aus unserer alten oder „Pre-Cell“-Umgebung in Zellen. Diese Arbeit wird fortgesetzt, bis wir Tausende verschiedener Infrastrukturdienste und Tausende von Back-End-Diensten in neu erstellte Zellen migriert haben. Wir gehen davon aus, dass dies aufgrund einiger erschwerender Faktoren das gesamte nächste Jahr und möglicherweise bis 2025 dauern wird. Erstens erfordert diese Arbeit den Bau robuster Werkzeuge. Beispielsweise benötigen wir Tools, um eine große Anzahl von Diensten automatisch neu auszugleichen, wenn wir eine neue Zelle bereitstellen – ohne Auswirkungen auf unsere Benutzer. Wir haben auch Dienste gesehen, die auf Annahmen über unsere Infrastruktur aufgebaut wurden. Wir müssen diese Dienste überarbeiten, damit sie nicht von Dingen abhängen, die sich in Zukunft ändern könnten, wenn wir in Zellen vordringen. Wir haben außerdem sowohl eine Möglichkeit zur Suche nach bekannten Entwurfsmustern implementiert, die mit der Mobilfunkarchitektur nicht gut funktionieren, als auch einen methodischen Testprozess für jeden migrierten Dienst. Diese Prozesse helfen uns, alle Benutzerprobleme zu vermeiden, die durch die Inkompatibilität eines Dienstes mit Zellen verursacht werden.
Heute werden fast 30,000 Maschinen von Zellen verwaltet. Es ist nur ein Bruchteil unserer gesamten Flotte, aber bisher verlief der Übergang sehr reibungslos und ohne negative Auswirkungen auf die Spieler. Unser oberstes Ziel besteht darin, dass unsere Systeme jeden Monat eine Benutzerverfügbarkeit von 99.99 Prozent erreichen, was bedeutet, dass wir nicht mehr als 0.01 Prozent der Interaktionsstunden stören. Branchenweit können Ausfallzeiten nicht vollständig vermieden werden, aber unser Ziel ist es, Ausfallzeiten bei Roblox so weit zu reduzieren, dass sie nahezu unbemerkt bleiben.
Zukunftssicher machen, während wir skalieren
Während sich unsere ersten Bemühungen als erfolgreich erweisen, ist unsere Arbeit an Zellen noch lange nicht abgeschlossen. Während Roblox weiter wächst, werden wir weiterhin daran arbeiten, die Effizienz und Ausfallsicherheit unserer Systeme durch diese und andere Technologien zu verbessern. Im weiteren Verlauf wird die Plattform immer widerstandsfähiger gegen Probleme, und alle auftretenden Probleme sollten für die Menschen auf unserer Plattform zunehmend weniger sichtbar und störend sein.
Zusammenfassend haben wir bisher:
- Bau eines zweiten Rechenzentrums und Erreichen des Aktiv/Passiv-Status erfolgreich.
- Wir haben Zellen in unseren aktiven und passiven Rechenzentren erstellt und mehr als 70 Prozent unseres Back-End-Service-Verkehrs erfolgreich in diese Zellen migriert.
- Legen Sie die Anforderungen und Best Practices fest, die wir befolgen müssen, um alle Zellen einheitlich zu halten, während wir den Rest unserer Infrastruktur weiter migrieren.
- Ein kontinuierlicher Prozess des Aufbaus stärkerer „Blast-Wände“ zwischen den Zellen wurde in Gang gesetzt.
Da diese Zellen austauschbarer werden, kommt es zu weniger Übersprechen zwischen den Zellen. Dies eröffnet uns einige sehr interessante Möglichkeiten im Hinblick auf die zunehmende Automatisierung rund um die Überwachung, Fehlerbehebung und sogar die automatische Verlagerung von Arbeitslasten.
Im September haben wir außerdem damit begonnen, Aktiv/Aktiv-Experimente in unseren Rechenzentren durchzuführen. Dies ist ein weiterer Mechanismus, den wir testen, um die Zuverlässigkeit zu verbessern und Failover-Zeiten zu minimieren. Diese Experimente haben dazu beigetragen, eine Reihe von Systementwurfsmustern zu identifizieren, vor allem im Zusammenhang mit dem Datenzugriff, die wir überarbeiten müssen, während wir uns auf die vollständige Aktiv-Aktiv-Entwicklung konzentrieren. Insgesamt war das Experiment erfolgreich genug, um es für den Datenverkehr einer begrenzten Anzahl unserer Benutzer laufen zu lassen.
Wir freuen uns, diese Arbeit weiter voranzutreiben, um der Plattform mehr Effizienz und Ausfallsicherheit zu verleihen. Diese Arbeit an Zellen und der Aktiv-Aktiv-Infrastruktur wird es uns zusammen mit unseren anderen Bemühungen ermöglichen, uns zu einem zuverlässigen, leistungsstarken Versorgungsunternehmen für Millionen von Menschen zu entwickeln und weiter zu skalieren, während wir daran arbeiten, eine Milliarde Menschen in Wirklichkeit zu verbinden Zeit.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/

