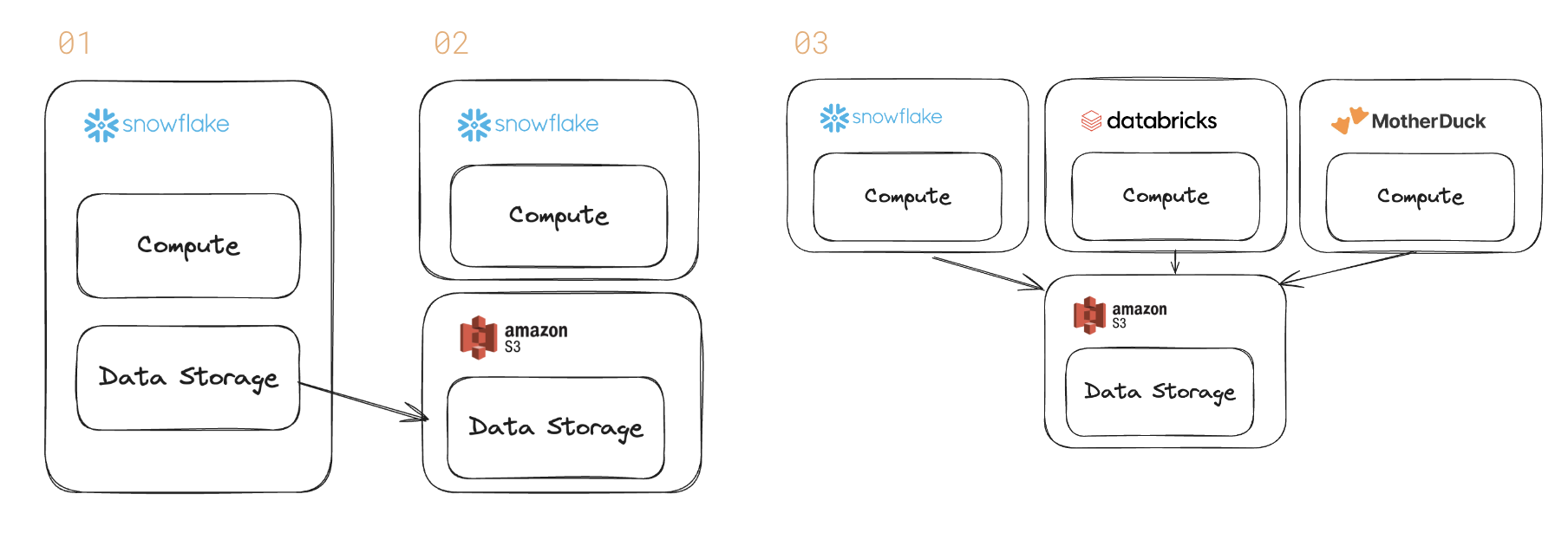
Die Datenbank wird entbündelt. In der Vergangenheit verkaufte eine Datenbank wie Snowflake sowohl Datenspeicher als auch eine Abfrage-Engine (und die Rechenleistung zur Ausführung der Abfrage). Das ist Schritt 1 oben.
Kunden drängen jedoch auf eine stärkere Trennung von Rechenleistung und Speicher. Der jüngste Gewinnaufruf von Snowflake verdeutlichte diesen Trend. Größere Kunden bevorzugen offene Formate für die Interoperabilität (Schritt 2 und 3).
Viele große Kunden wünschen sich offene Dateiformate, um ihnen die nötigen Optionen zu bieten. Daher ist Dateninteroperabilität sehr wichtig und unsere KI-Produkte können im Allgemeinen auch auf Daten reagieren, die sich im Cloud-Speicher befinden.
Wir gehen davon aus, dass eine Reihe unserer großen Kunden Iceberg-Formate übernehmen und ihre Daten aus Snowflake verschieben werden, wodurch uns die Speichereinnahmen und auch die mit der Verlagerung dieser Daten in Snowflake verbundenen Recheneinnahmen entgehen.
Anstatt die Daten in einer Datenbank zu sperren, bevorzugen Kunden es, sie in offenen Formaten wie Apache Arrow, Apache Parquet, Apache Iceberg zu haben.
Mit der zunehmenden Datennutzung innerhalb eines Unternehmens nehmen auch die Anforderungen an diese Daten zu.
Anstatt sie jedes Mal für einen anderen Zweck zu kopieren, sei es für explorative Analysen, Business Intelligence oder KI-Workloads, warum nicht die Daten zentralisieren und dann viele verschiedene Systeme darauf zugreifen lassen?
Das spart Geld: Der Speicher kostet für Snowflake insgesamt etwa 280 bis 300 Millionen US-Dollar.
Zur Erinnerung: Etwa 10 bis 11 % unseres Gesamtumsatzes entfallen auf die Speicherung.
Es vereinfacht aber auch Architekturen.
Es läutet auch eine Epoche ein, in der die Abfrage-Engines mit Preis und Leistung um unterschiedliche Arbeitslasten konkurrieren werden. Snowflake eignet sich möglicherweise besser für groß angelegte BI; Databricks‘ Spark für KI-Datenpipelines; MutterEnte für interaktive Analysen.
Data-Warehouse-Anbieter haben das vermarktet Trennung von Speicher und Rechenleistung in der Vergangenheit. Bei dieser Botschaft ging es jedoch darum, das System zu skalieren, um größere Datenmengen innerhalb des eigenen Produkts verarbeiten zu können.
Kunden fordern eine tiefere Trennung – eine Welt, in der Datenbanken keine Gebühren für die Speicherung erheben.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.tomtunguz.com/why-databases-wont-charge-storage/

